平均数不总是平均:中心与离散
一家公司公布“本组 6 人平均年收入 16.7 万元”。听起来每个人都过得差不多。可是如果原始数据是:
你会马上觉得这句话有点滑。大多数人的收入在 7 到 10 万元之间,只有一个人是 58 万元。平均数是真的,但它给人的感觉不一定真。
这一节要做的事,就是学会问两个问题:一组数据的“中心”在哪里?数据离这个中心有多远?第一个问题对应平均数、中位数、众数;第二个问题对应极差、四分位数和标准差。
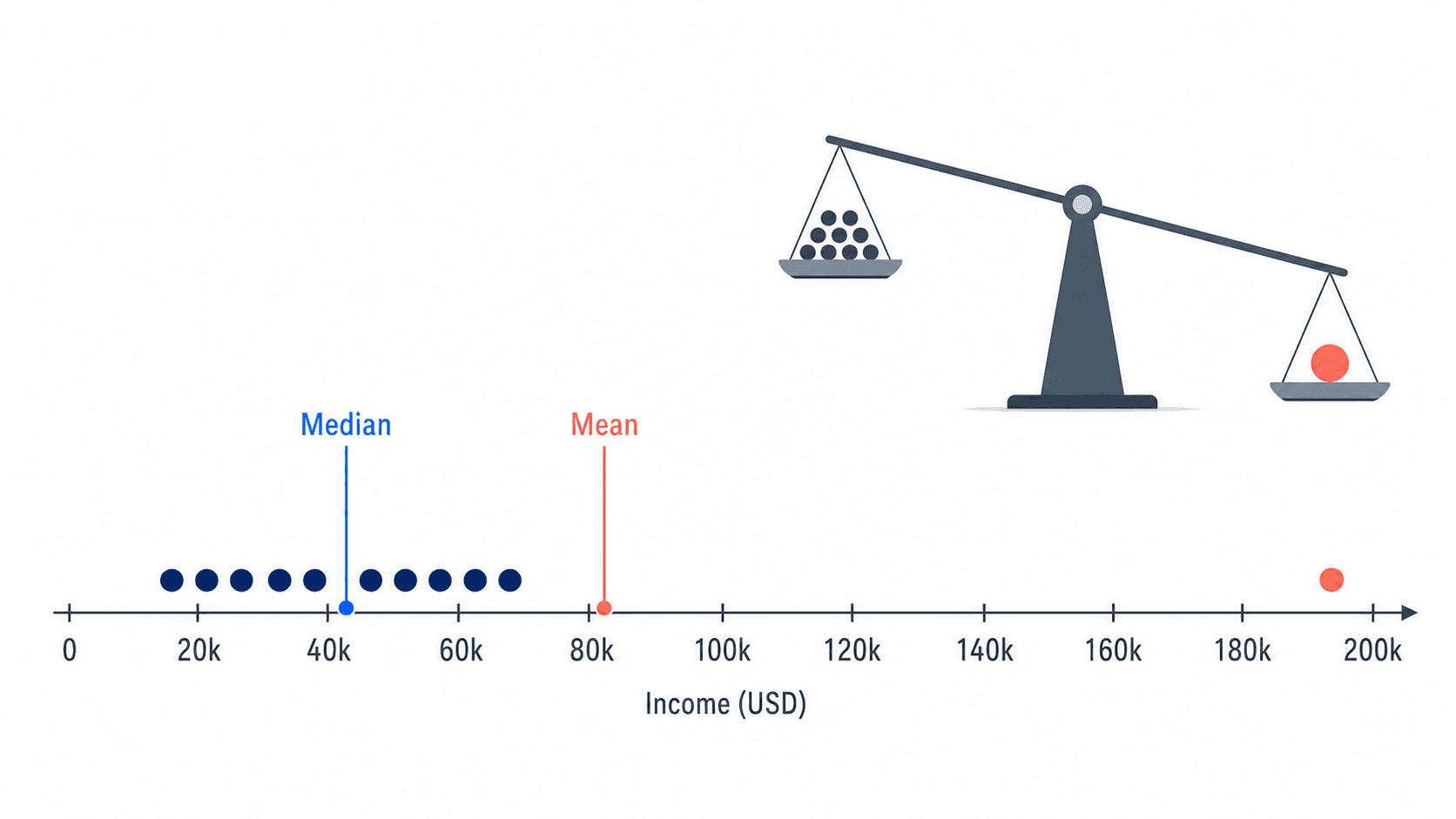
描述一组数据时,不要急着只报一个数。先问它代表哪种中心,再问数据是不是很分散。中心和离散放在一起,才像一张比较完整的数据照片。
三种中心:平均数、中位数、众数
“中心”不是一个固定答案,而是几种不同的看法。平均数把所有数据加起来后均分;中位数把数据排成一列,找正中间的位置;众数找出现次数最多的值。
平均数:把总量重新分摊
平均数的公式是:
刚才那组收入数据的总和是 万元,共有 个人,所以平均数是:
平均数适合回答“如果把总量平均分,每个单位分到多少”。比如一个班 5 次小测的平均分、一个月每天平均用电量、每名顾客平均消费金额,都可以用它。
中位数:排队后看中间
中位数先要求数据有顺序。把收入排好后是:
这里有 个数,中间有两个位置,所以中位数取第 个和第 个的平均:
中位数说的是:至少有一半人不高于它,也至少有一半人不低于它。它不在意最右边那个 离大家有多远,所以比平均数更抗极端值。
众数:哪一个最常出现
在这组收入里, 出现了两次,其他数只出现一次,所以众数是 。众数在“最常见”比“数值大小”更重要时很有用。比如最常买的鞋码、最常见的故障类型、某家店最常卖出的杯型,众数比平均数更自然。

平均数、中位数、众数都可以叫中心,但它们回答的问题不同。看到“平均”两个字时,要追问它是不是 arithmetic mean;看到“典型”两个字时,也要追问它到底是中位数、众数,还是只是一个模糊说法。
极端值会把平均数拉走
极端值不是一定错误的数据。高收入者、豪宅成交、一次异常高的考试分数,都可能是真实发生的。问题在于:它们会让平均数移动得很明显。
下面的交互可以拖动最右侧收入点,观察平均数线和中位数线的变化。
例题:收入数据该报哪个中心
某创业团队 7 名成员的月收入(千元)是:
请分别求平均数、中位数和众数,并判断哪个数更适合描述“普通成员”的收入。
先求平均数。所有收入相加得到 千元,共 人,所以平均数是 千元。
再求中位数。数据已经从小到大排列,共有 个数,正中间是第 个数,所以中位数是 千元。
接着求众数。 和 都出现了两次,其他数只出现一次,所以这组数据有两个众数: 千元和 千元。
最后回到问题。题目问“普通成员”的收入,而 千元明显远离其他人。平均数被它拉高到 千元,不像多数成员的收入;中位数 千元更稳,更适合这个问题。
抗极端值不是说忽略极端值,而是说某个统计量不会被少数极端值轻易拉走。中位数和四分位数通常比平均数、极差更抗极端值。
房价和工资为什么常看中位数
房价、收入、财富这类数据经常右偏:多数数值挤在较低或中等范围,少数特别大的数把右边拖得很长。此时平均数常常高于中位数。
看一条街上 6 套房的成交价(万元):
平均房价是:
中位数是第 个和第 个的平均:
如果你想了解“这条街上典型成交价大概在哪里”, 万元比 万元更接近多数房屋。如果你想算“6 套房总成交额平均分到每套是多少”,平均数才是直接答案。
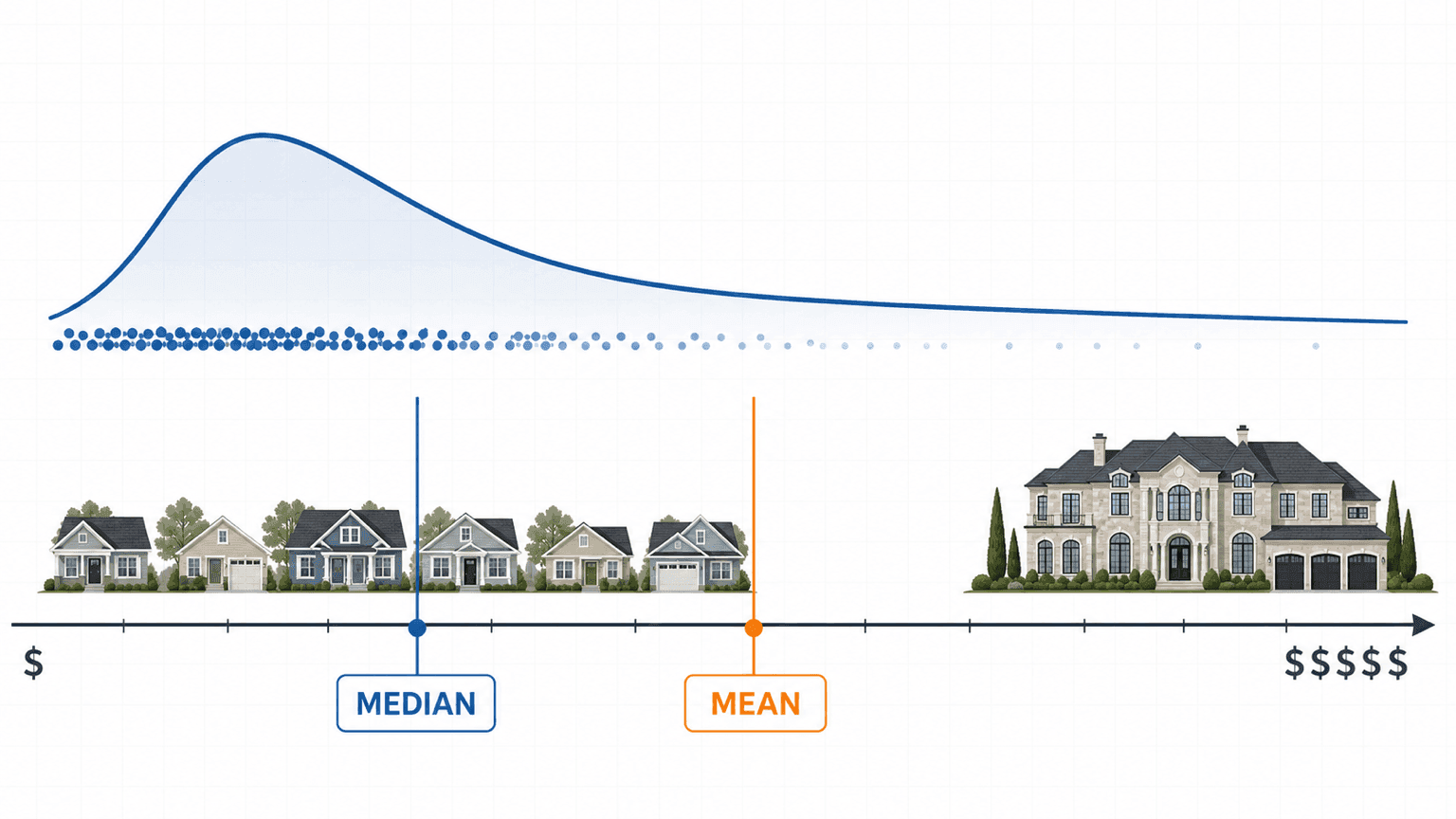
选中心时先看问题
同一组数据可以同时有多个中心。选择哪一个,不取决于哪个名字更熟,而取决于你要回答什么问题。
常见误区是把“平均数”理解成“多数人都接近这个数”。如果数据很偏,平均数可能落在一个并不常见的位置。它仍然是正确计算结果,但不一定是最适合的代表。
离散程度:中心之外还要看距离
只知道中心还不够。下面两组考试成绩都有同样的平均数 分:
A 组成绩围在 附近,B 组从 到 拉得更开。它们的中心一样,但学习状态给人的感觉不同。
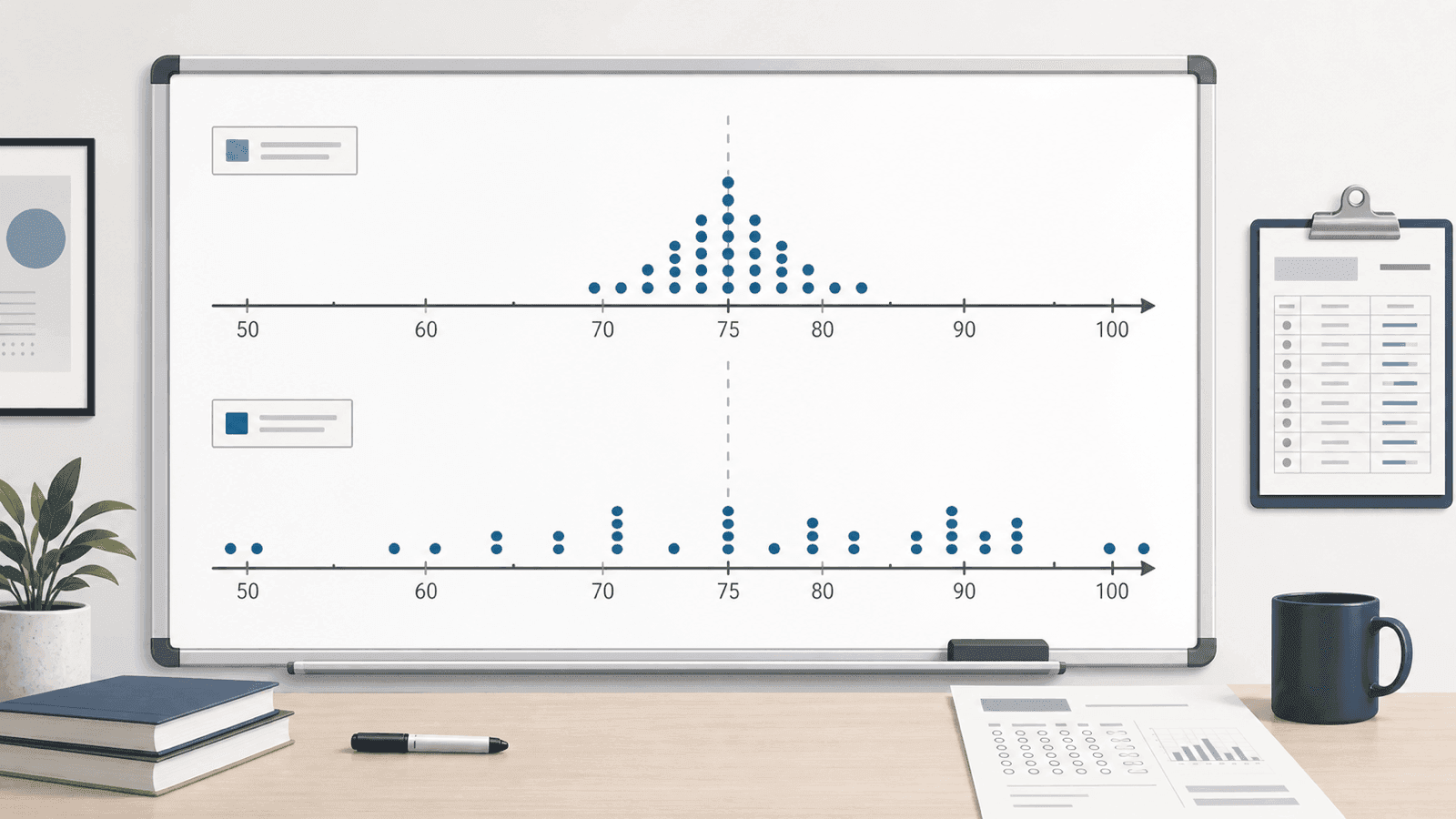
极差:最快看到跨度
极差只看最大值和最小值:
A 组极差是 ,B 组极差是 。极差很直观,但它只受两端影响。只要最大值或最小值很极端,极差就会变得很大,中间数据发生了什么却看不出来。
四分位数:把数据切成四段
四分位数先把数据从小到大排好,再找几个切点:
四分位距是中间一半数据的跨度:
它比极差稳,因为它看的是中间一半,而不是只盯着最小值和最大值。
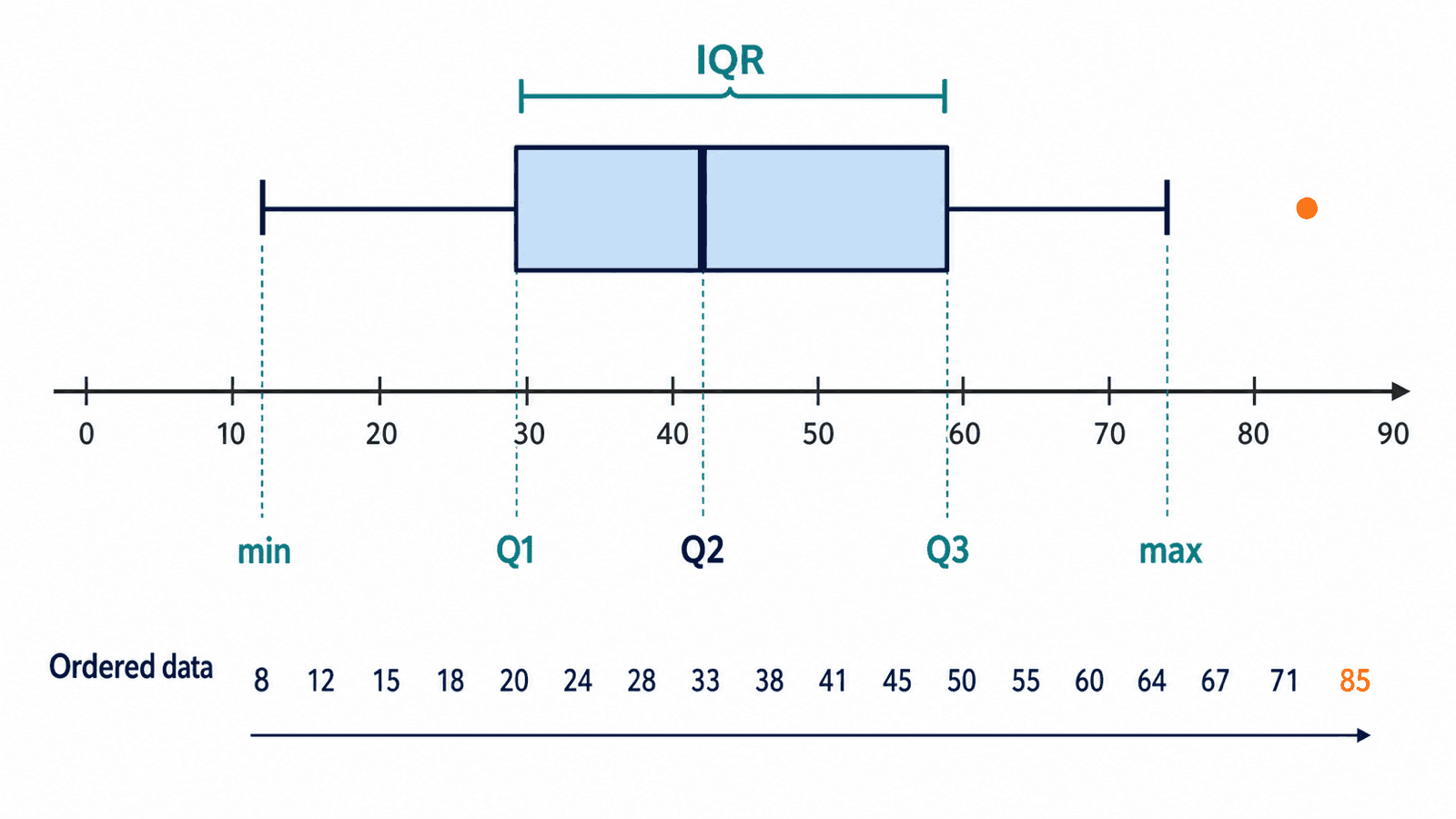
下面的交互会把数据排序、四分位数和箱线图放在一起。切换不同情境时,注意箱体变宽还是变窄,离群点有没有出现。
例题:用四分位数找异常等待时间
某窗口 11 位顾客的等待时间(分钟)排好后是:
求中位数、、、,并用 的规则判断是否有高端异常值。
先找中位数。共有 个数,正中间是第 个,所以 。
去掉中位数后,看左半边 。这 5 个数的中间是 ,所以 。
再看右半边 。这 5 个数的中间是 ,所以 。
计算四分位距:。高端异常值边界是 。
最后比较数据。 大于 ,按这个规则可视为高端异常值; 没有超过边界,所以不算。
标准差:离平均数的典型距离
标准差关心每个数据点离平均数有多远。它的想法不是只看最远的两端,而是把所有偏离都纳入计算。
对于样本数据,常用样本标准差:
公式看起来长,但直觉很朴素:先找平均数,再看每个数离平均数多远,把这些距离综合成一个典型距离。
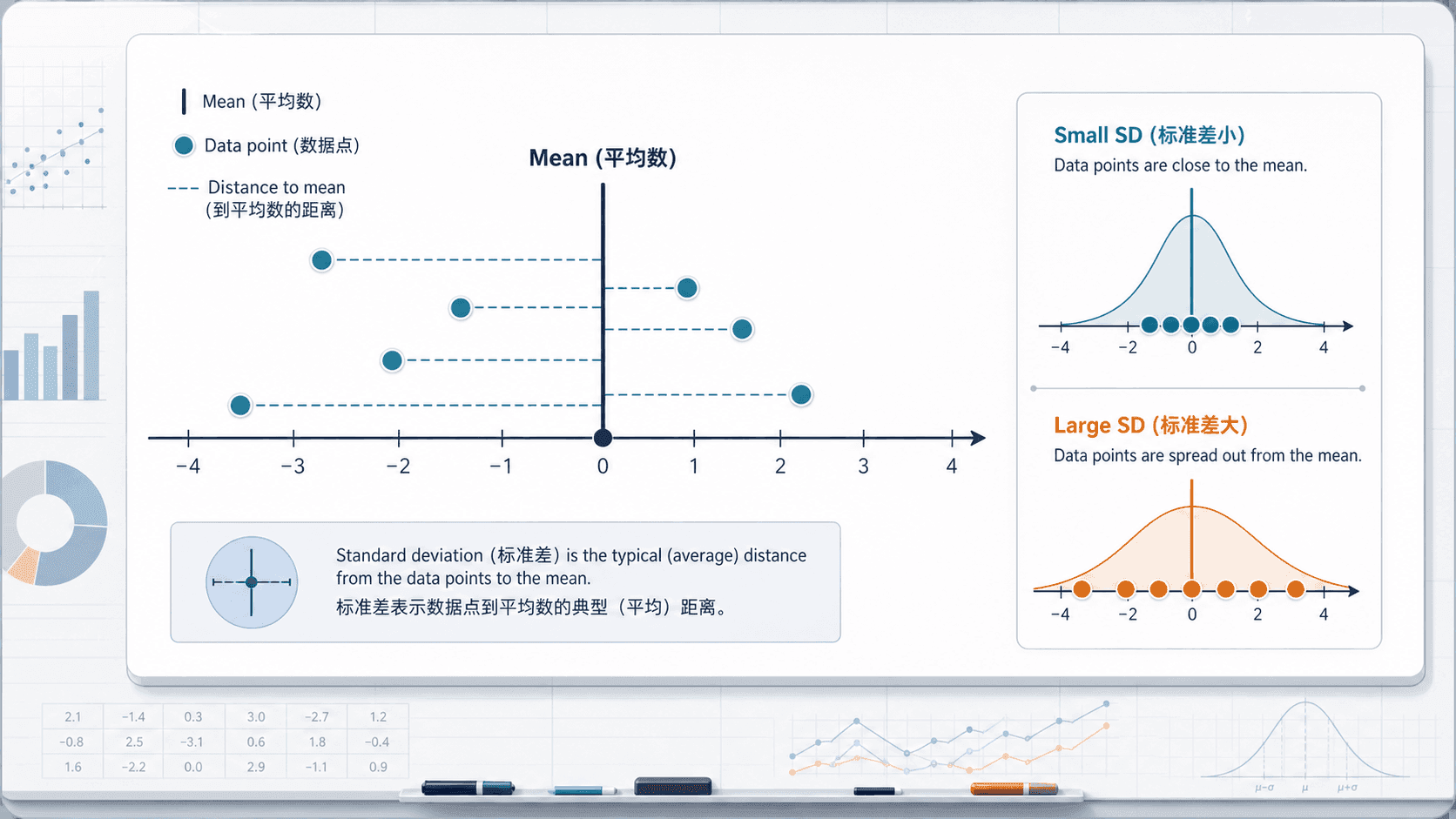
观察标准差时,可以先不急着算。把数据点想成围着平均数站成一排:点越贴近中心线,标准差越小;点越向两边散开,标准差越大。公式只是把这种距离感写成可计算的数。
例题:同样平均分,不同标准差
继续看这两组成绩:
用样本标准差比较它们的分散程度。
A 组相对平均数 的偏差是 ,平方后是 ,平方和是 。
A 组样本标准差是 。这说明 A 组成绩通常离平均数只有几分。
B 组相对平均数 的偏差是 ,平方后是 ,平方和是 。
B 组样本标准差是 。所以 B 组虽然平均数也是 ,但成绩差异明显更大。
标准差的单位和原数据相同。成绩的标准差是“分”,房价的标准差是“万元”,等待时间的标准差是“分钟”。不要把标准差理解成百分比,也不要以为平均数越大,标准差就一定越大。
误区辨析:别让一个数替你下结论
误区一:平均数等于普通水平
如果数据大致对称、没有明显极端值,平均数常常很好用。可是在收入、房价、财富这类右偏数据里,平均数可能高于多数人的实际位置。此时“普通水平”常要看中位数。
误区二:中位数总是比平均数好
中位数更抗极端值,但它也会丢掉总量信息。如果题目问一个班总分平均分摊到每个人,或者公司人均销售额,平均数正是需要的量。
误区三:有异常值就直接删掉
异常值可能来自录入错误,也可能是真实现象。处理前先问:它是不是测量错误?是不是来自同一个总体?它会不会正是我们关心的风险信号?统计不是把不顺眼的数据擦掉,而是解释它为什么在那里。
误区四:极差大就说明所有数据都散
极差只看两端。一个班大多数成绩集中,但有一个学生缺考记为 0,极差会很大。四分位距和标准差能帮助你继续判断:分散是整体性的,还是被少数端点造成的。
读一个统计量时,最好同时说出它的盲点。平均数怕极端值;中位数不看距离;众数可能不存在或不唯一;极差只看两端;标准差对极端值也敏感。
练一练
练习一:收入中心
某小组 8 人年收入(万元)是:
求平均数、中位数、众数。若要描述“多数成员的大致收入”,你会选哪个?
总和是 ,共有 人,所以平均数是 万元。
中间两个数是第 个和第 个,都是 ,所以中位数是 万元。
和 都出现了两次,所以众数是 万元和 万元。
如果要描述多数成员的大致收入,中位数 万元更合适。平均数被 万元拉高,落在一个多数成员并没有接近的位置。
练习二:房价代表值
某社区 7 套房成交价(万元)是:
房产报告说“平均成交价约 105 万元”。这句话哪里可能误导读者?请给出一个更稳的代表值。
平均数是:
计算没有错,但 万元明显远离其他房价,会把平均数抬高。中位数是第 个数 万元,它更接近这批房屋的典型成交位置。报告如果只说“平均成交价 105 万元”,读者可能误以为多数房屋都接近这个价位。
练习三:四分位数和异常值
一组配送时长(分钟)排好后是:
求 、中位数、、,并用 规则判断 是否为高端异常值。
共有 个数,中位数是第 个数 。
左半边是 ,所以 。右半边是 ,所以 。
四分位距是:
高端异常值边界是:
大于 ,所以按这个规则可视为高端异常值。
练习四:同中心不同离散
两组机器每天加工零件数如下:
它们的平均数相同吗?哪一组更稳定?你可以用极差或标准差的直觉说明。
甲组平均数是 ,乙组平均数也是 。
甲组极差是 ,乙组极差是 。两组中心相同,但乙组离平均数更远,波动更大。若用标准差计算,也会得到乙组标准差更大的结论,所以甲组更稳定。
收束:中心要配上离散一起读
这一节的关键词不是“背公式”,而是“别让一个数替你看完整组数据”。平均数适合总量分摊,中位数适合偏态和极端值明显的场景,众数适合最常见类别。极差给你快速跨度,四分位数抓住中间一半,标准差描述数据离平均数的典型距离。
下次看到“平均工资”“平均房价”“平均分”时,可以多问一句:数据有没有偏?有没有极端值?中位数是多少?分散有多大?这几个问题一出来,统计量就不再只是一个漂亮数字,而会变成能被检查的证据。