相关不等于因果
想象一条新闻标题这样写:某城市冰淇淋销量越高,水边救援记录也越多。这个说法听起来像在暗示“冰淇淋让人更容易遇到危险”。但你很快会觉得哪里不对:天气热的时候,买冰淇淋的人变多,下水游玩的人也变多。两个量确实一起变化,可它们未必互相导致。
统计里经常会遇到这种情况:我们先看到两个变量一起升高、一起降低,或者一个升高时另一个降低。这个现象叫相关。相关很有用,它能提醒我们“这里可能有线索”。但相关不是因果证明。要判断一个变量是否真的导致另一个变量变化,还要继续问:有没有隐藏变量?时间顺序对不对?有没有反向解释?数据是观察来的,还是实验来的?
这一节的目标不是让你立刻会做复杂回归,而是学会读散点图、理解相关系数的方向和强弱,并在看到“因为……所以……”之前多停一秒。
先看散点图
散点图用一个点表示一个个体或一次观察。横轴放一个变量,纵轴放另一个变量。比如每个学生都有“每周学习时间”和“考试成绩”,每名学生就是图上的一个点。
如果点大致从左下到右上排列,说明横轴变量较大时,纵轴变量通常也较大,这叫正相关。如果点大致从左上到右下排列,说明横轴变量较大时,纵轴变量通常较小,这叫负相关。如果点像一团云一样没有明显方向,就说线性相关很弱,或者没有明显线性相关。
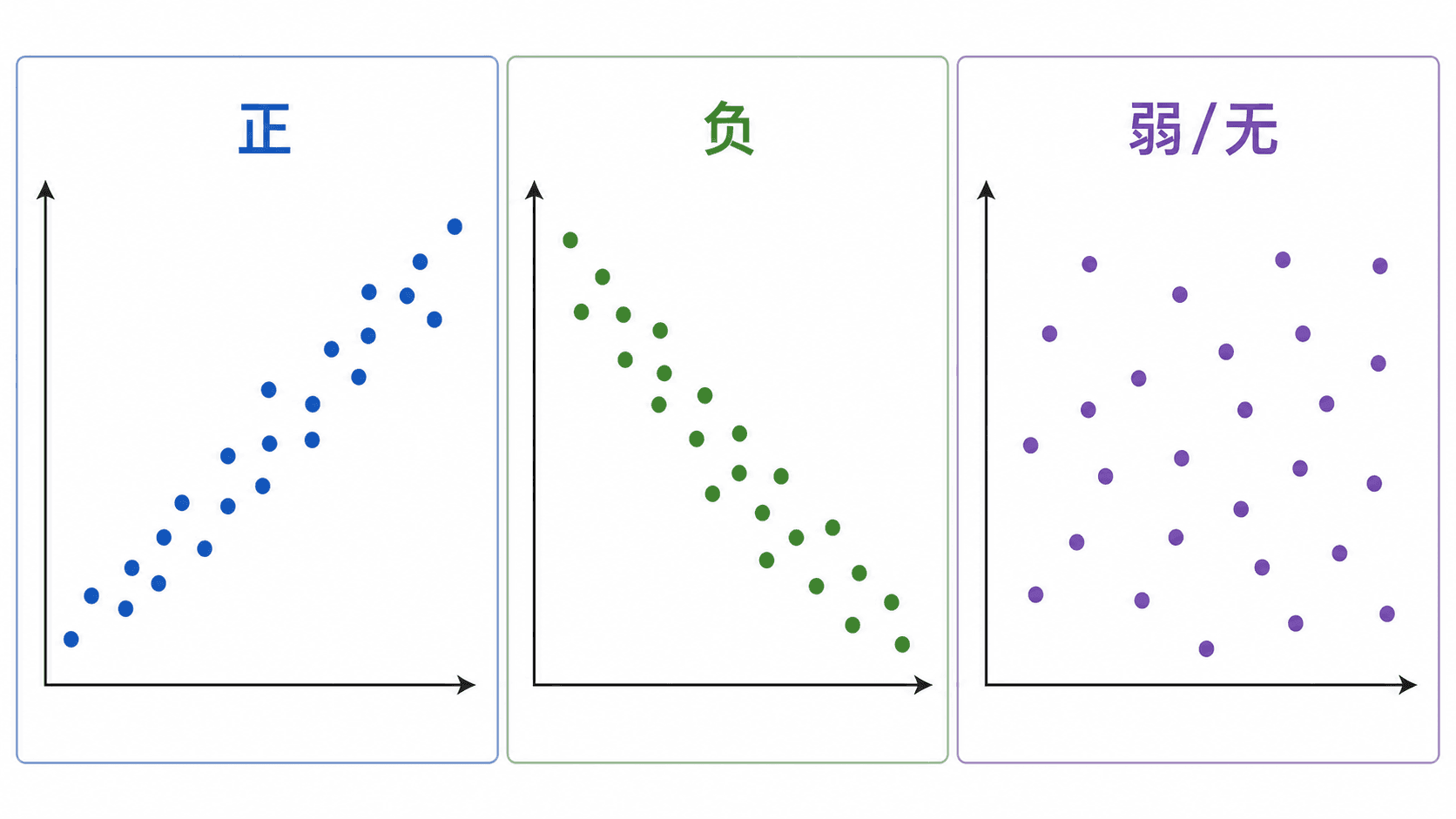
散点图最值得看的不是某一个点,而是整团点云的形状。你可以先问四个问题:
- 点云大致往哪个方向倾斜?
- 点云贴得紧,还是散得开?
- 有没有特别远的异常点?
- 点云像直线,还是像弯曲的曲线?
下面这个小实验可以调节点云的方向和噪声。你会看到:方向决定正负,点云的松紧影响相关强弱。
散点图比一句“相关系数是多少”更早一步。先看图,再看数,能帮你发现异常点、弯曲关系和分组结构。只看一个数字,容易把不同形状的数据误读成同一种关系。
相关系数的直觉
相关系数通常记作 ,它把两个定量变量的线性相关方向和强弱压缩成一个介于 和 之间的数。
当 接近 时,点云紧贴着向右上方倾斜的直线,表示强正相关。当 接近 时,点云紧贴着向右下方倾斜的直线,表示强负相关。当 接近 时,说明线性相关很弱,但这不等于两个变量完全没有关系,因为关系可能是弯的。
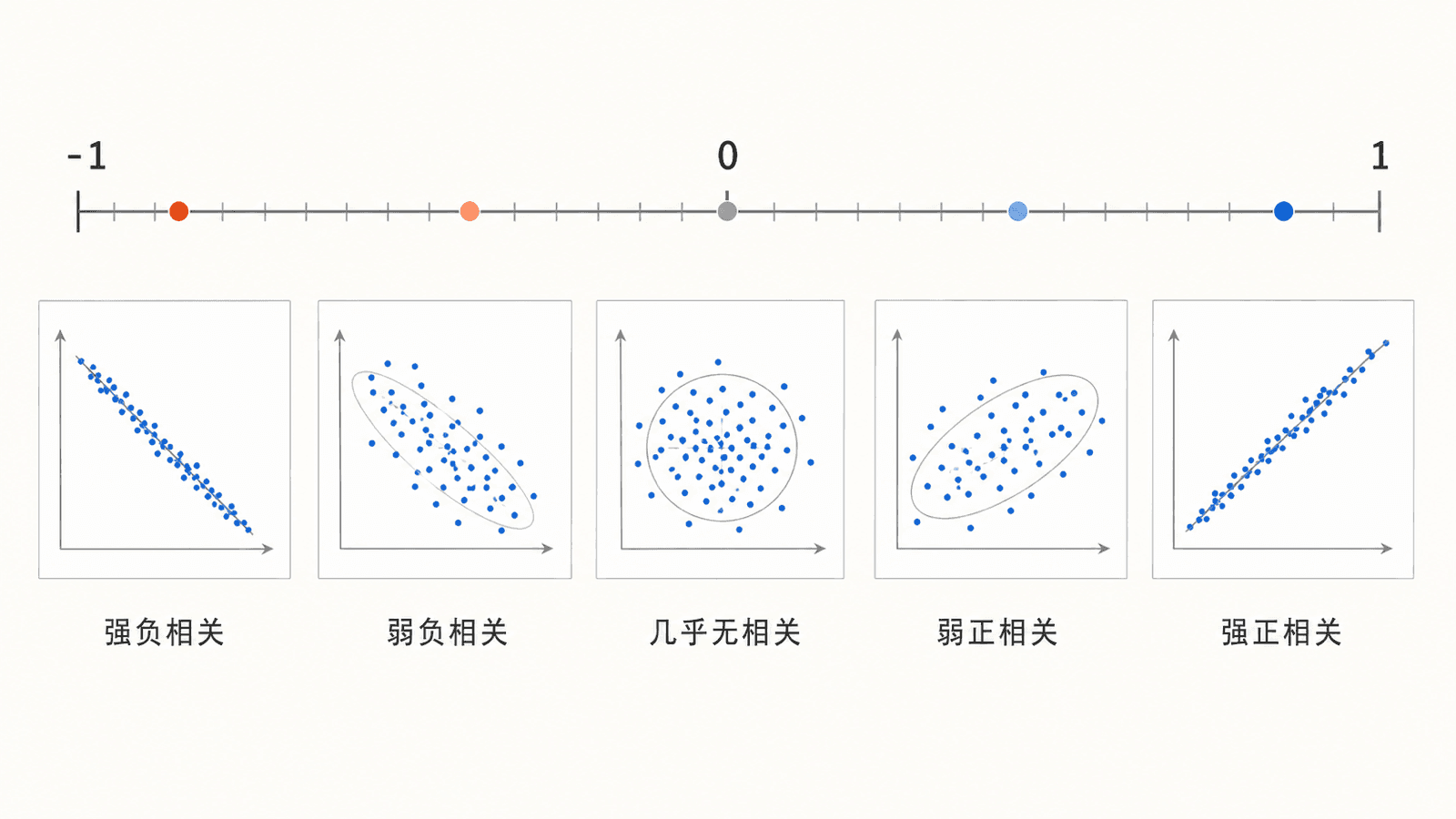
你可以把相关系数想成“点云像不像一条斜直线”的分数。方向由正负号给出,贴近程度由绝对值大小给出。常见的计算公式是:
这个公式看起来长,但直觉不复杂。每个 和 都先被转成“离平均值多少个标准差”。如果一个点的 高于平均值时 也常常高于平均值,或者 低于平均值时 也低于平均值,乘积多半为正, 就偏正。如果一个高、另一个低,乘积多半为负, 就偏负。
例题:读懂一个相关系数
某班记录了 30 名学生最近两周的自主学习时间和一次小测成绩,得到相关系数 。这句话能说明什么?不能说明什么?
先看符号。 是正数,所以学习时间较长的学生,成绩通常也较高。这里说的是一种总体趋势,不是每个学生都严格如此。
再看大小。 离 比较近,说明这组数据里线性正相关较强,散点图大概率会呈现向右上方倾斜的点云。
接着限制结论。这个数字只说明两个变量在这组观察数据里一起变化,不能直接证明“多学一定导致成绩提高”。原有基础、学习方法、作业质量、睡眠和课程难度都可能参与其中。
最后写出谨慎表达。可以说“在这 30 名学生中,自主学习时间和小测成绩呈较强正相关”,不要直接写成“自主学习时间导致小测成绩提高”。
一个好习惯是把“相关”写成观察语言,把“因果”留给更强的证据。观察语言像“较高者通常也较高”“呈正相关”;因果语言像“导致”“提升”“减少”“因为”。
隐藏变量:第三个量可能在背后推
隐藏变量,也常叫潜在变量或混杂因素,是同时影响两个被观察变量的第三个因素。它没有出现在你的表格里,却可能解释两个变量为什么一起变化。
冰淇淋销量和水边救援记录的例子里,气温就是一个隐藏变量。气温升高时,冰淇淋销量上升;气温升高时,下水游玩的人也变多,救援记录可能跟着上升。观察数据里冰淇淋和救援记录相关,但更合理的解释是它们都被气温推动。
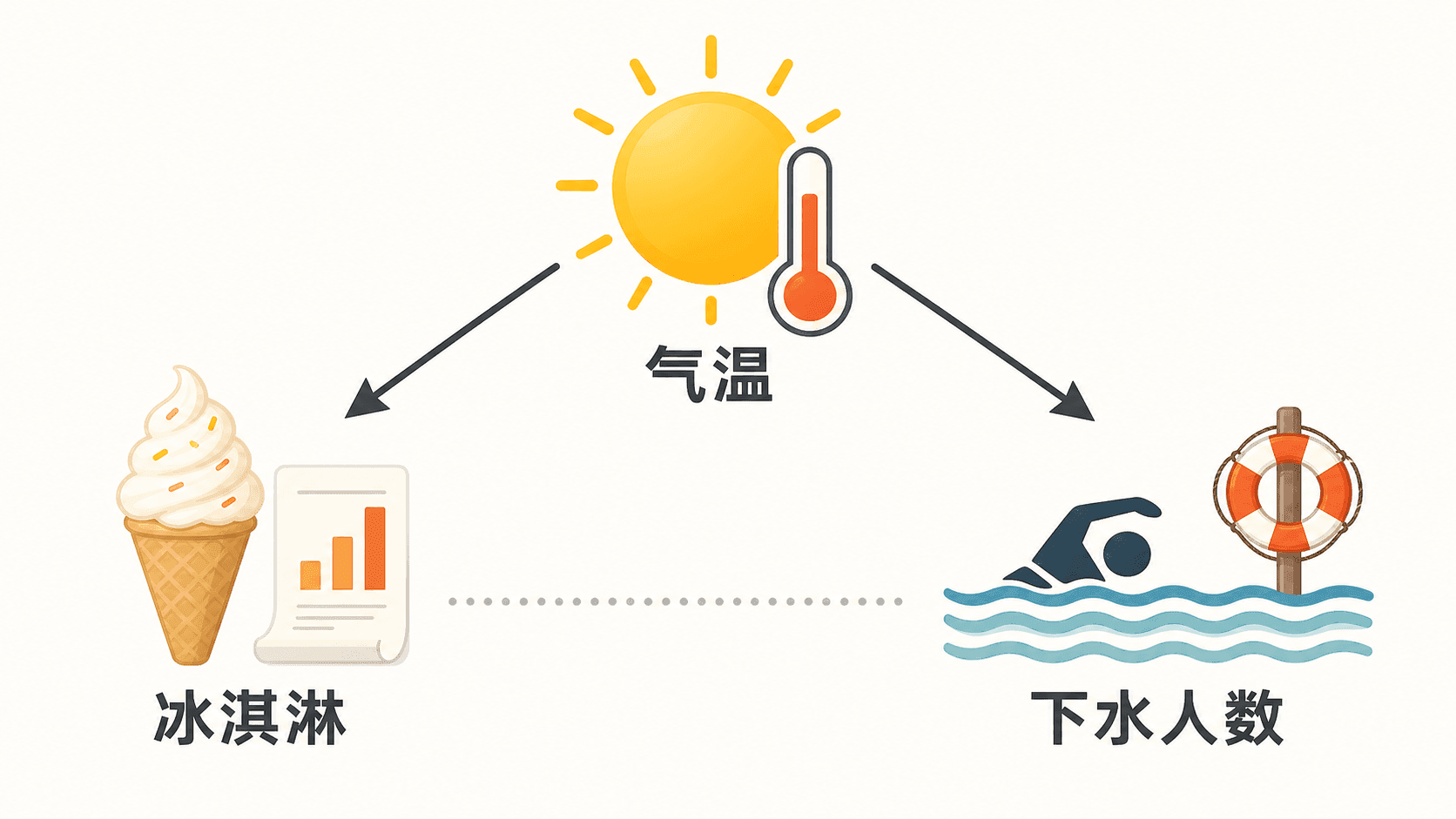
下面的交互把气温作为背后的共同原因。先看所有月份混在一起时的散点,再打开“按气温分组查看”。你会看到:分组以后,原本很显眼的相关可能变弱。
看到相关时,先不要只问“是不是 A 导致 B”。也要问“有没有 C 同时影响 A 和 B”。这个 C 常常是年龄、季节、收入、健康状态、先前能力、地区差异或选择方式。
真实情境:咖啡、吸烟与肺部健康
在观察性健康数据里,人们曾看到咖啡饮用量和某些肺部健康风险一起变化。如果直接说“咖啡导致风险增加”,就太快了。一个关键问题是:喝咖啡较多的人群中,吸烟比例是否也更高?如果吸烟同时影响咖啡习惯和肺部健康,吸烟就可能成为混杂因素。
这种例子提醒我们:观察性数据可以提出怀疑,但要接近因果结论,通常需要更精细的研究设计,例如控制混杂因素、比较相似人群、追踪时间顺序,或者在伦理允许时做随机对照实验。
四种常见解释
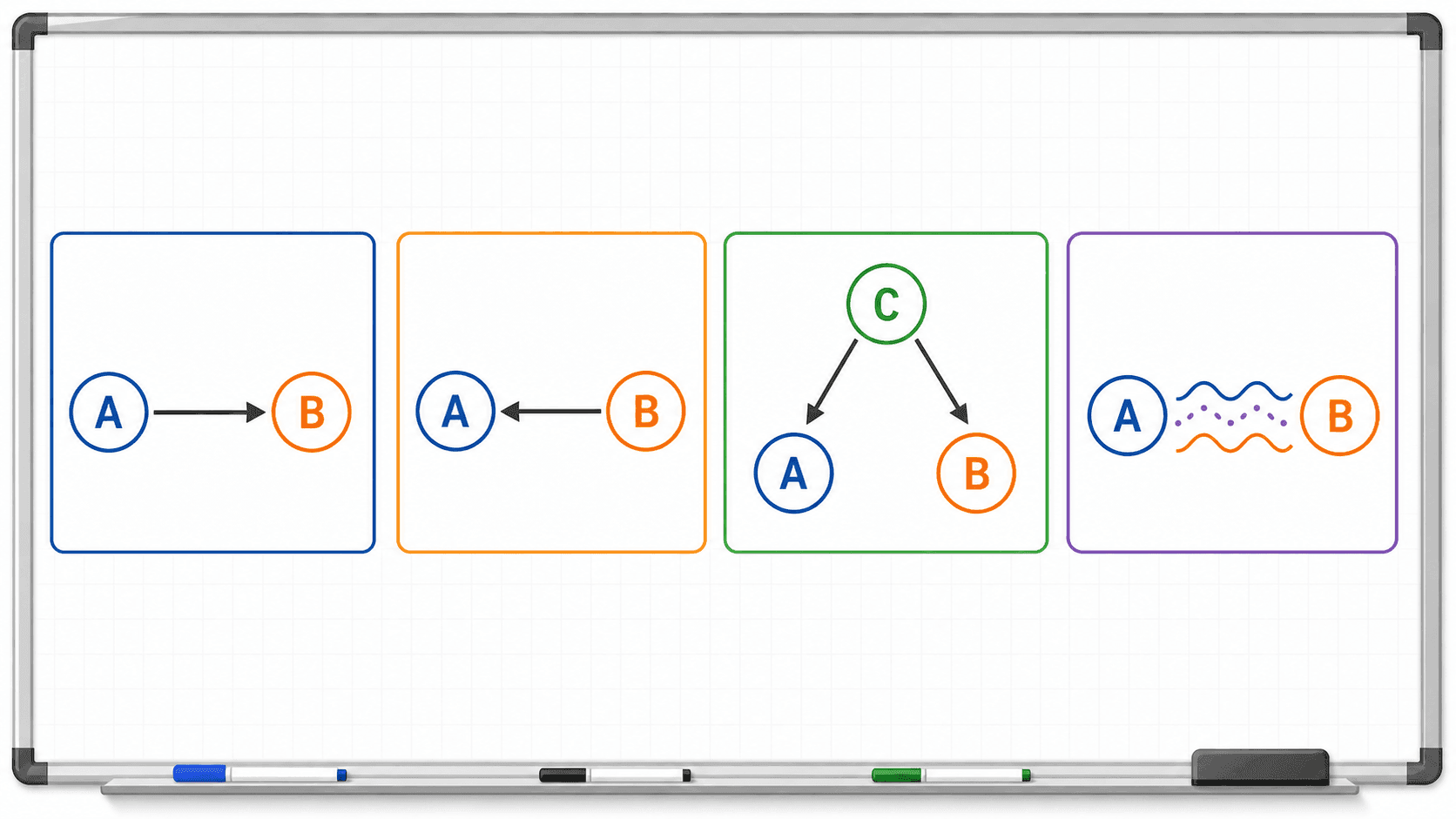
当两个变量 A 和 B 相关时,至少有四种可能:
- A 影响 B。
- B 影响 A。
- 第三个变量 C 同时影响 A 和 B。
- 它们只是样本中碰巧一起变化,或者测量方式制造了假象。
比如“运动 App 使用频率和体重下降相关”。可能是使用 App 帮助人坚持运动,也可能是已经决定减重的人更愿意装 App,还可能是收入、时间安排、健康意识同时影响两者。只凭相关,无法把这些解释排除掉。
“A 和 B 相关”不能自动改写成“A 导致 B”。这个改写看起来只换了几个字,实际却把证据等级提高了很多。
相关数字也会骗人
相关系数抓的是线性关系。如果点云沿一条弯曲的 U 形分布, 可能接近 ,但图上明明有关系。异常点也会强烈影响相关系数:一个远离其他点的点,可能把原本不明显的趋势拉成明显相关。
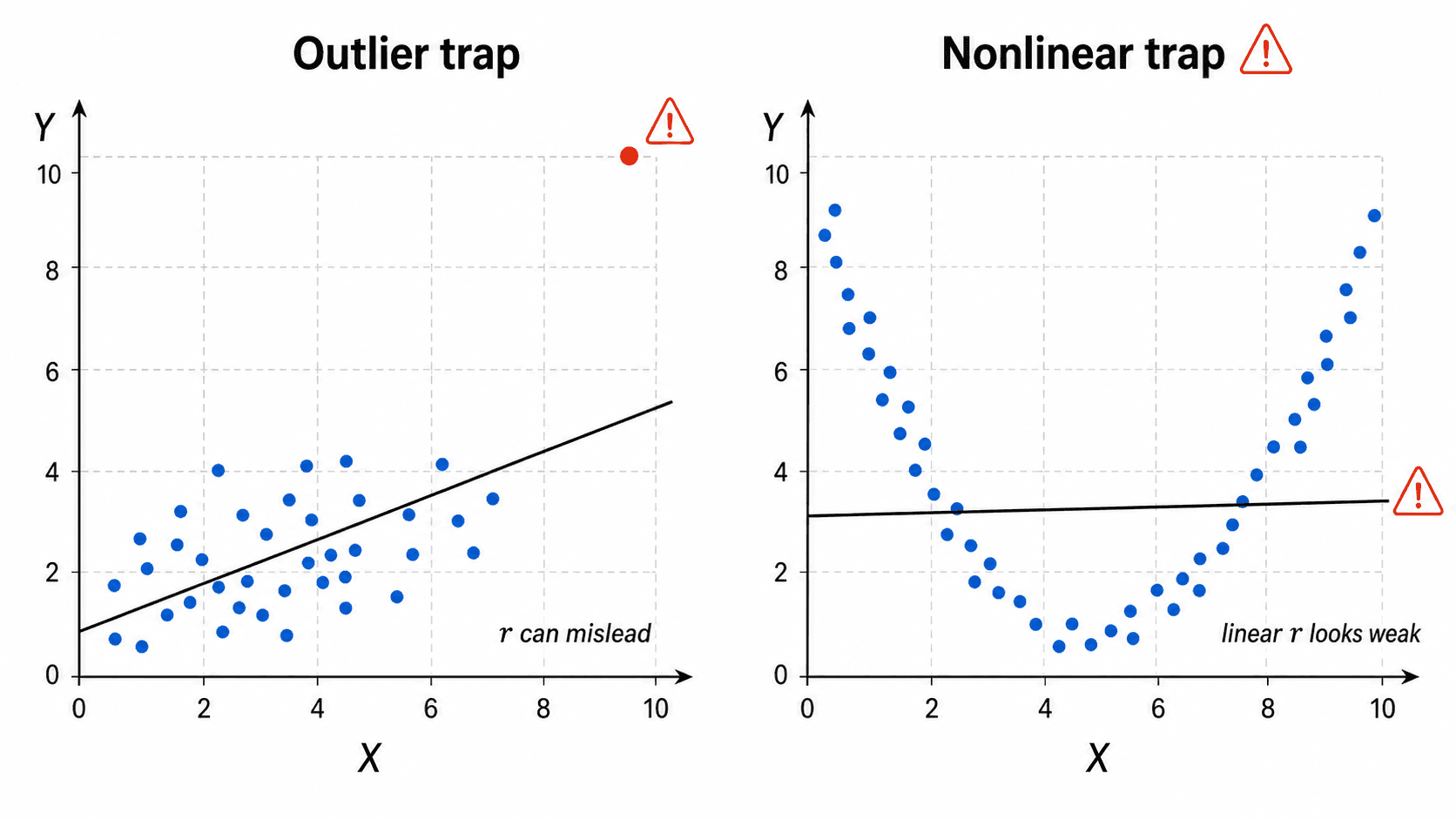
这就是为什么统计课会反复强调“先画图”。有些数据集会拥有差不多的平均数、标准差和相关系数,但散点图完全不同。只看摘要数字,就像只看影子的长度来判断一个人的姿势,信息太少。
例题:异常点改变结论
某研究小组记录 12 家小店的广告费用和当月销售额。前 11 家店的点分布很散,几乎看不出关系;第 12 家是一家大型门店,广告费和销售额都远高于其他店。把 12 家全算进去时,相关系数为 。这时应该怎样解释?
先回到散点图。前 11 家店没有明显线性趋势,第 12 家店离其他点很远,它不是普通波动,而是一个会影响整体计算的异常点。
再判断变量背景。大型门店和小店可能不是同一类对象。它的面积、客流、地段和库存都不同,广告费与销售额同时更高,不一定说明广告本身造成销售增长。
然后分开描述。可以分别报告“全部 12 家的相关系数较高”和“排除大型门店后,小店之间的线性关系不明显”,不能只挑一个数字作为最终故事。
最后给出下一步。如果想研究广告效果,应比较更相似的门店,或设计实验让不同门店随机采用不同广告方案,再观察销售变化。
异常点不一定是错误数据。它可能是真实但特殊的对象。问题不在于“删不删”,而在于你是否说明它为什么特殊,以及结论对它有多敏感。
从相关到因果,证据要加码
如果我们真的想说“一个变量导致另一个变量变化”,通常需要更强的证据。最理想的情况是随机实验:把相似个体随机分到不同处理组,让其他因素尽量平均分布,再比较结果差异。
现实中很多问题不能随便做实验。比如不能为了研究危害而随机让人吸烟,也不能随意改变一个城市的教育资源。这时,研究者会用观察性数据做更谨慎的设计:控制混杂因素,比较相似个体,利用时间先后,寻找自然实验,或者用多组证据互相验证。
可以用下面的检查清单帮助自己慢下来:
- 时间顺序:原因是否发生在结果之前?
- 替代解释:有没有反向因果或共同原因?
- 可比性:两组对象除了被研究变量外是否足够相似?
- 分组结构:合并数据后看到的趋势,在分组内是否仍然存在?
- 机制:是否有合理解释说明为什么 A 会影响 B?
- 证据等级:这是随机实验、观察性研究,还是只是一张相关图?
更谨慎的写法
把强因果句改成观察句,是统计表达里的基本功。
练习
练习一:判断方向
某地记录一周内每天的最高气温和热饮销量。气温越高,热饮销量通常越低。这个关系更可能是正相关、负相关,还是无明显相关?
这是负相关。横轴如果放最高气温,纵轴放热饮销量,点云大致会从左上往右下倾斜。它说明气温较高的日子热饮销量通常较少,但单靠这组数据还不能精确说明销量变化完全由气温导致。
练习二:找隐藏变量
一项观察发现:儿童的鞋码越大,阅读测试分数通常越高。能不能说“鞋码变大会提高阅读能力”?如果不能,一个可能的隐藏变量是什么?
不能这样说。一个明显的隐藏变量是年龄。年龄较大的儿童通常鞋码更大,也接受了更长时间的阅读训练,所以阅读分数更高。鞋码和阅读分数相关,但鞋码本身不是合理原因。
练习三:改写因果句
把下面这句话改写得更谨慎: “睡眠时间越长,考试成绩越高,所以多睡觉会直接提高成绩。”
可以改成:“在这组学生数据中,睡眠时间和考试成绩呈正相关。要判断睡眠是否会提高成绩,还需要考虑学习时间、压力、基础水平、健康状况等因素,并尽量比较其他条件相似的学生。”这个说法保留了观察结果,同时没有把相关直接升级为因果。
练习四:解释相关系数
某组数据的相关系数为 。这说明两个变量一定没有关系吗?
不一定。 说明线性相关很弱,方向略微偏负。但两个变量可能存在非线性关系,也可能被异常点、分组结构或测量误差影响。正确做法是先看散点图,再结合背景判断。
小结
相关是观察到的共同变化,因果是关于变化原因的判断。散点图能帮助我们看方向、强弱、异常点和形状;相关系数能把线性关系压缩成一个从 到 的数字。它们都很有用,但都不能单独证明因果。
遇到“两个量一起变化”的说法时,先保留线索,再检查证据。也许 A 真的影响 B,也许 B 影响 A,也许 C 在背后同时推动两者。统计判断的成熟,往往就体现在这一步停顿里。