用图表看数据:分布、形状与异常值
如果只给你一串数字,你通常很难马上判断它在说什么。
比如一组同学记录了自己昨天的屏幕时间:
1.0, 1.3, 1.8, 2.0, 2.1, 2.4, 2.5, 2.8, 3.1, 3.2, 3.3, 3.5, 3.7, 4.0, 7.8
你可以立刻算平均数,但算完以后仍然会有很多问题:大多数人集中在哪里?有没有特别高的值?这组数据是平缓分布,还是被某个极端值拉长了尾巴?如果先画图,这些问题会更早浮出水面。
统计里很容易出现一种习惯:一拿到数据就开始计算。这个习惯并不坏,但顺序要放对。图表不是计算之后的装饰,而是计算之前的侦察。
这一节的目标很简单:先让图像开口,再让数字补充。我们会用频数表、条形图、直方图、折线图和散点图观察数据,并练习用“形状、中心、离散程度、偏态、异常值”这几个词描述一组数据。
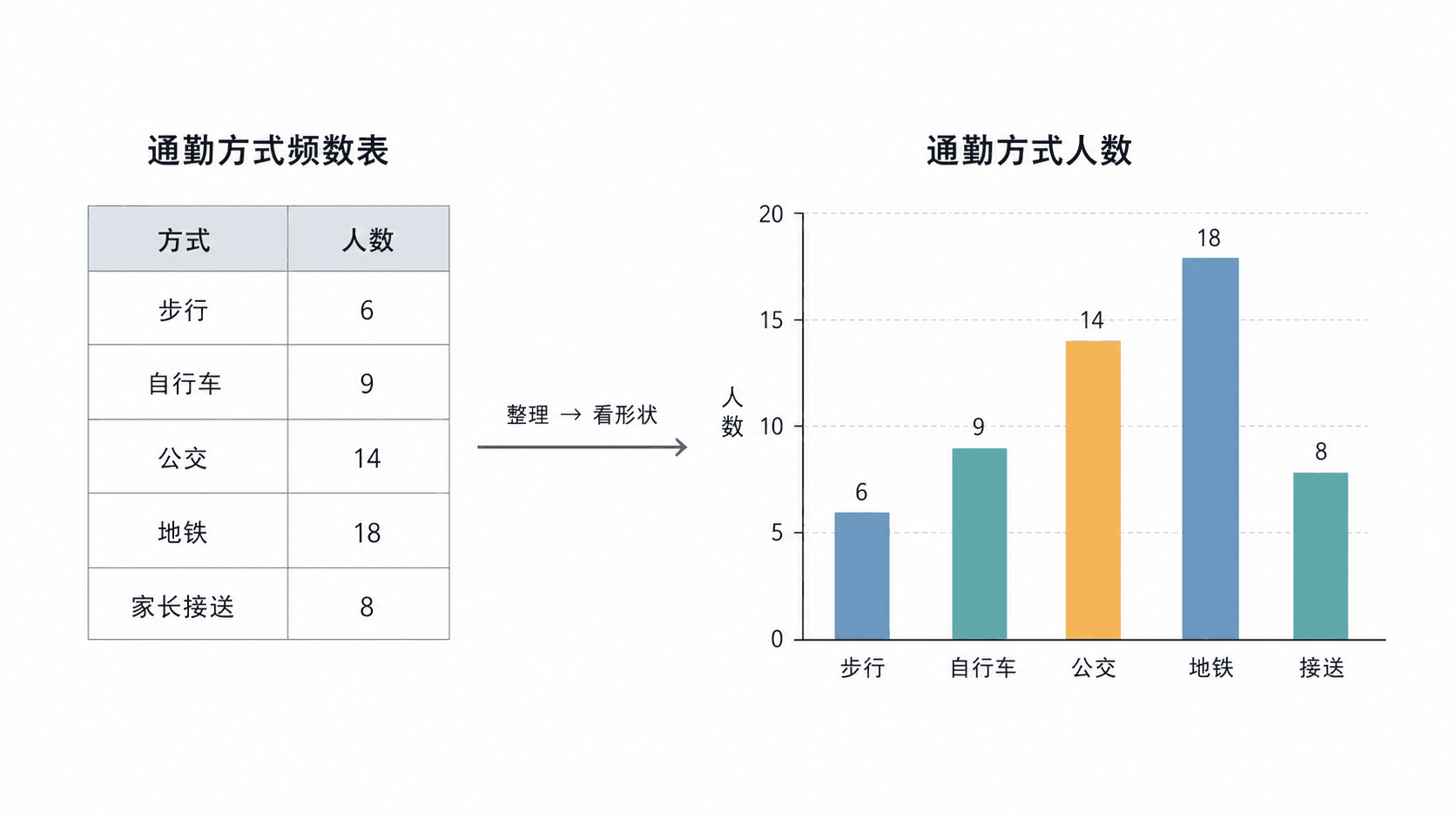
从一串记录到频数表
原始数据通常长得很散。比如调查 30 位同学今天怎么来学校,得到的是一串回答:
公交, 步行, 地铁, 自行车, 公交, 家长接送, 步行, 公交, 地铁, 自行车, 公交, 公交, 步行, 地铁, 公交, 家长接送, 自行车, 公交, 步行, 地铁, 公交, 公交, 自行车, 步行, 地铁, 公交, 家长接送, 步行, 公交, 自行车
这串回答本身包含信息,但信息还没有被整理。频数表做的第一件事,就是数清每个类别出现了多少次。
频数是“出现了几次”。相对频率是“在全部观察里占多大比例”。如果总共有 30 个观察,公交出现 11 次,那么公交的相对频率就是:
频数表适合核对具体数量,条形图适合比较类别高低。把同一张表画成条形图后,“公交最多、家长接送最少”会比在表格里更容易看出来。
例题:把调查结果整理成图表
某班 24 位同学选择最常用的学习工具,结果如下:
纸质笔记, 电子笔记, 纸质笔记, 视频课, 纸质笔记, 电子笔记, 题库, 纸质笔记, 视频课, 电子笔记, 纸质笔记, 题库, 电子笔记, 纸质笔记, 视频课, 纸质笔记, 电子笔记, 纸质笔记, 题库, 视频课, 电子笔记, 纸质笔记, 纸质笔记, 电子笔记
请制作频数表,并判断应该用什么图展示。
先确认变量类型。这里记录的是“最常用的学习工具”,它是类别,不是可以加减平均的数值,所以先按类别计数。
再逐类数频数。纸质笔记出现 10 次,电子笔记出现 7 次,视频课出现 4 次,题库出现 3 次,总数是 24。
接着计算相对频率。纸质笔记的相对频率是 ,电子笔记是 ,视频课是 ,题库是 。
最后选择图表。因为变量是类别,条形图比直方图合适;条与条之间应留出间隔,表示这些类别并不是连续区间。
看到类别数据时,先做频数表,再考虑条形图。条形图比较的是类别之间的多少,不表示类别之间有连续距离。
选对图表:变量类型先说话
不同图表回答的问题不同。选图表之前,先问两个问题:变量是类别还是数值?你要看一个变量、时间变化,还是两个变量之间的关系?
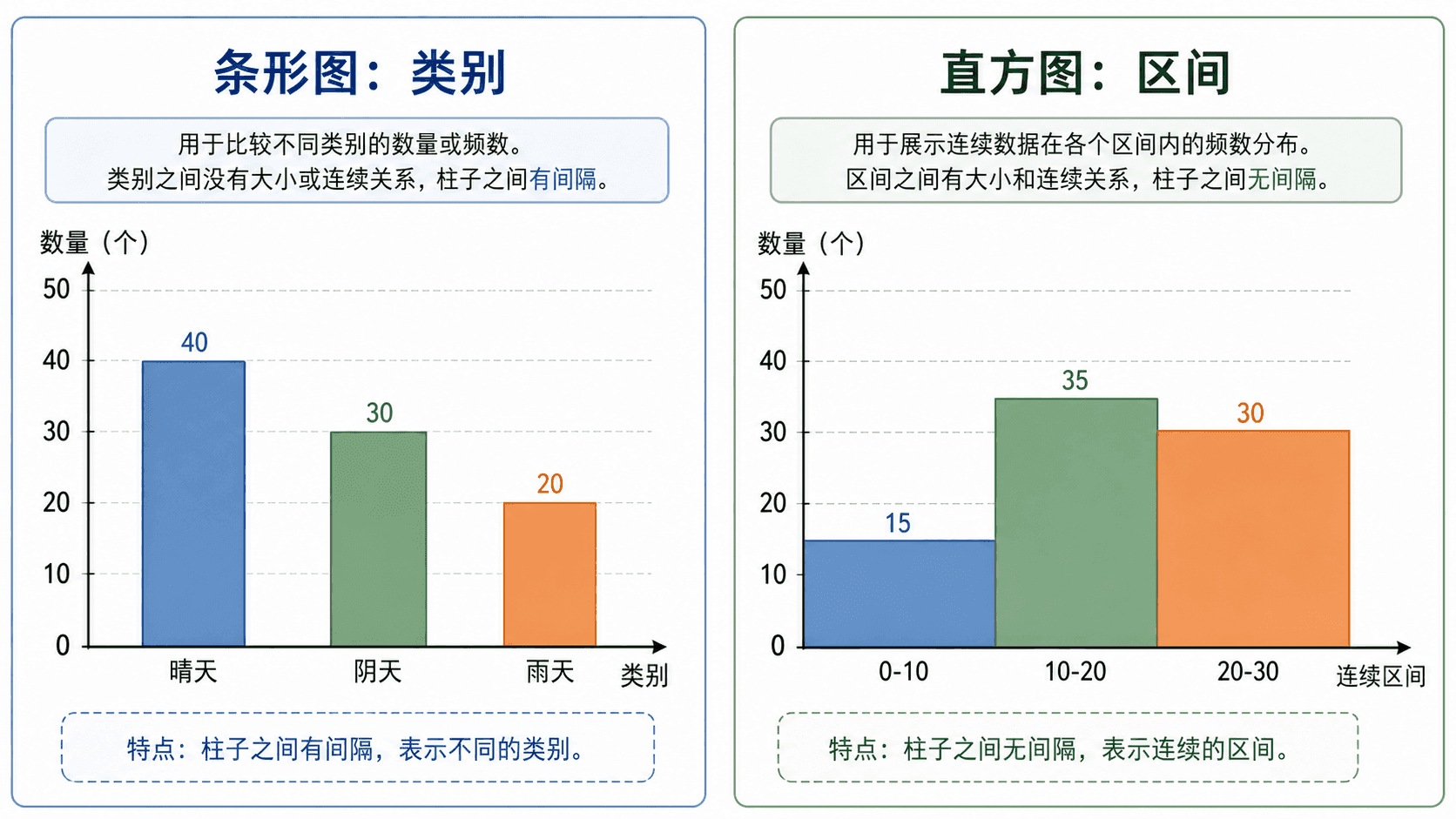
条形图和直方图最容易被混淆。条形图的横轴是类别,类别之间没有自然连续距离,所以条之间通常有空隙。直方图的横轴是数值区间,区间一个接一个覆盖数轴,所以柱子通常贴在一起。
不要把“柱子长得像”当作同一种图。条形图问的是“类别之间怎么比”,直方图问的是“数值在不同区间里怎么分布”。如果把成绩区间画成有空隙的类别图,读者可能会忘记这些区间其实连在同一条数轴上。
直方图:看分布的形状
直方图把数值数据切成连续区间,再数每个区间里有多少个观察。它牺牲了单个数据点的细节,换来整体形状。
仍看屏幕时间数据:
1.0, 1.3, 1.8, 2.0, 2.1, 2.4, 2.5, 2.8, 3.1, 3.2, 3.3, 3.5, 3.7, 4.0, 7.8
如果按 1 小时为组距,可以整理成:
这张表比原始数据清楚,但直方图会更直接:大多数值集中在 2 到 4 小时附近,右侧有一个 7.8 小时的远点,分布向右拖出一条长尾。
形状、中心、离散程度
描述直方图时,可以按三个层次来读。
形状指整体轮廓。它可能近似对称,也可能右偏或左偏;可能只有一个高峰,也可能有两个高峰。黄石公园 Old Faithful 间歇泉的等待时间常被用作统计教学案例,因为等待时间直方图会出现两个明显高峰,提示数据背后可能混着两种不同节奏。
中心指典型位置。刚入门时,可以先粗略看“多数柱子集中在哪里”。后面再用平均数、中位数等数字细化。
离散程度指数据散得有多开。两个数据集中心差不多,但一个集中在中心附近,另一个从低到高铺得很宽,它们传递的信息就很不一样。
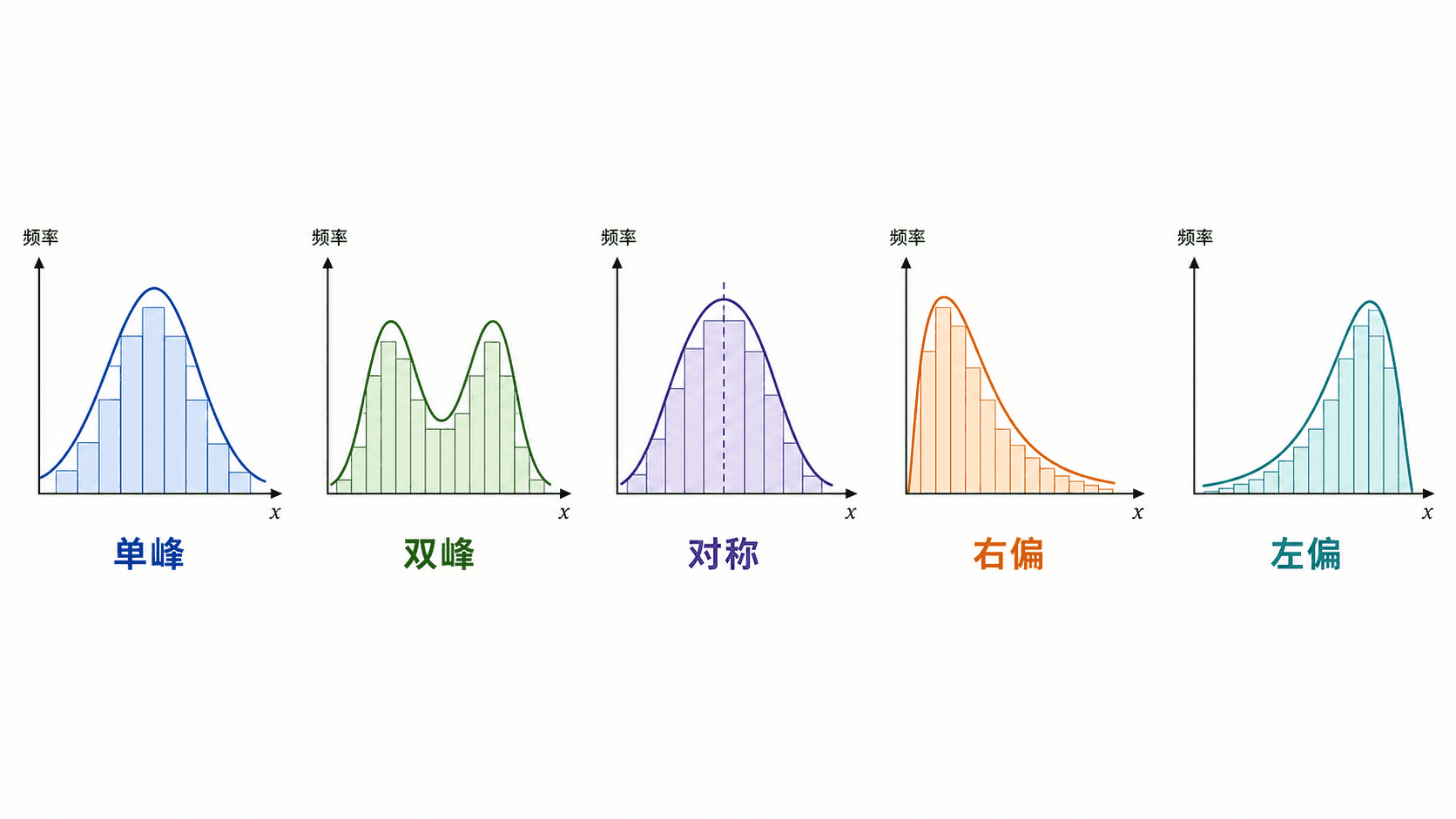
偏态的方向看“尾巴”拖向哪边。右偏不是说右边柱子更高,而是说少数较大的值把右侧尾巴拉长;左偏也是同理。
分箱宽度会影响你看到的故事
直方图不是唯一答案。组距太窄,图会变得锯齿状,很容易把随机波动误看成结构;组距太宽,重要细节又会被抹平。一个稳妥做法是试几个合理组距,看看主要结论是否稳定。
不要为了让图“证明”某个结论而挑分箱。分箱可以帮助观察,也可能制造错觉。好的读图习惯是:说明组距,试验不同组距,并把注意力放在稳定出现的形状上。
折线图:看时间里的变化
折线图适合展示同一个量按时间顺序变化。它的横轴通常是日期、周次、月份或年份,点与点之间用线连接,是因为这些观察有自然顺序。
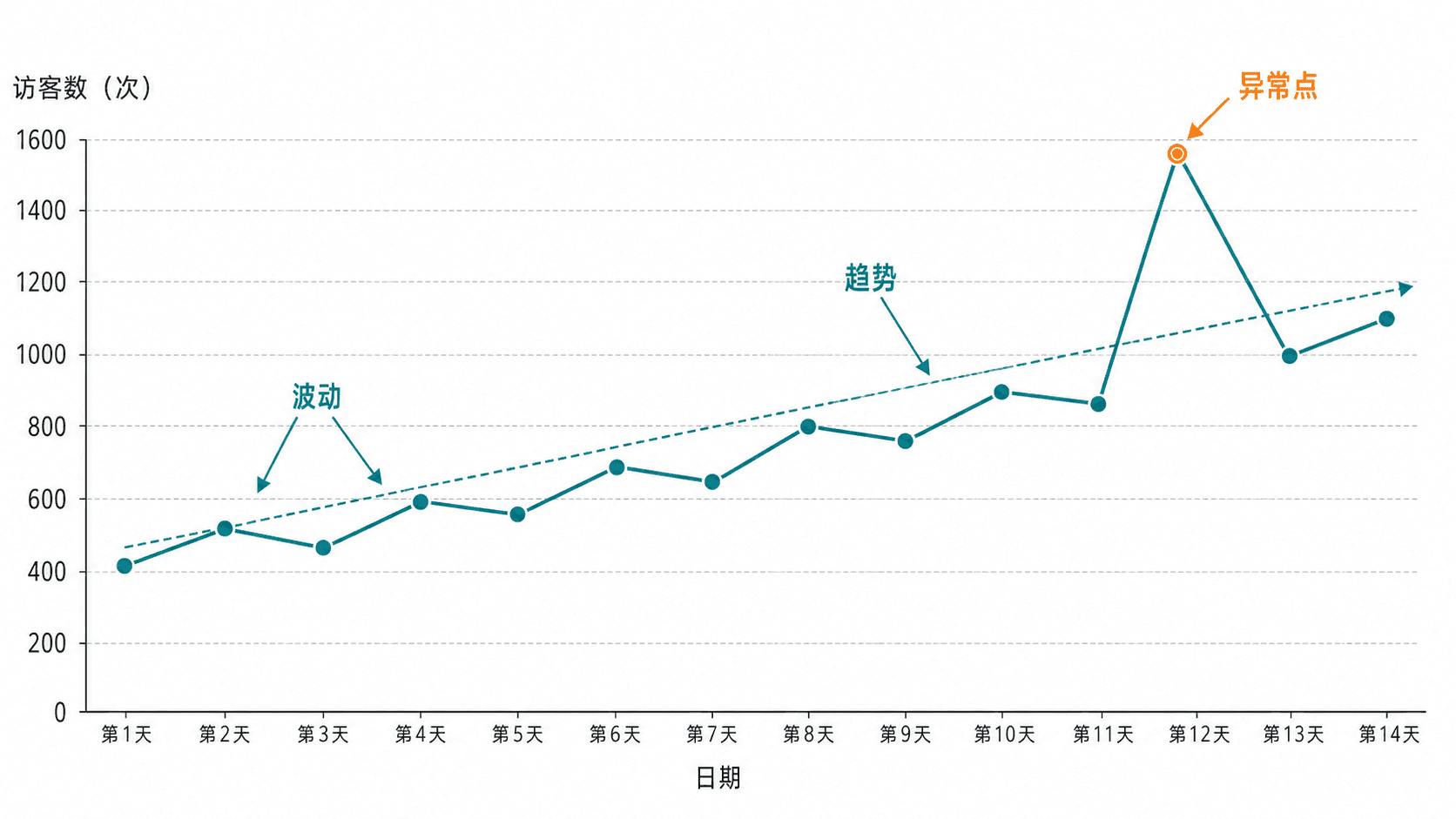
读折线图时,先看整体趋势,再看局部波动,最后找突然变化。比如一家书店连续 14 天记录客流量,整体可能慢慢上升,中间有上下波动,某一天因为活动突然冲高。这个冲高点不一定是错误,它可能是一个需要解释的事件。
折线图有一个常见误用:把没有顺序的类别硬连起来。比如把“篮球、足球、羽毛球、游泳”的喜好人数连成一条线,线段会暗示类别之间有连续变化,但这些类别并没有这种顺序。这里应该用条形图。
例题:读一张折线图
某校图书馆记录一周每天晚自习人数:
请描述这组数据,而不是只报最大值和最小值。
先看时间顺序。周一到周四人数大致在 86 到 94 之间,波动不大,说明工作日中段比较稳定。
再找突然变化。周五人数升到 138,比前几天高出很多,这可能与考试、讲座或集体活动有关,不能只把它当成普通波动。
最后看周末。周六和周日降到 72 和 69,低于工作日,说明周末使用模式可能不同。
用一句话总结:这张折线图显示工作日前四天较稳定,周五出现尖峰,周末明显下降;接下来应该调查周五是否有特殊事件。
散点图:看两个变量怎样一起动
当每个个体身上记录了两个数值变量时,散点图很有用。一个点代表一个个体,横坐标放一个变量,纵坐标放另一个变量。
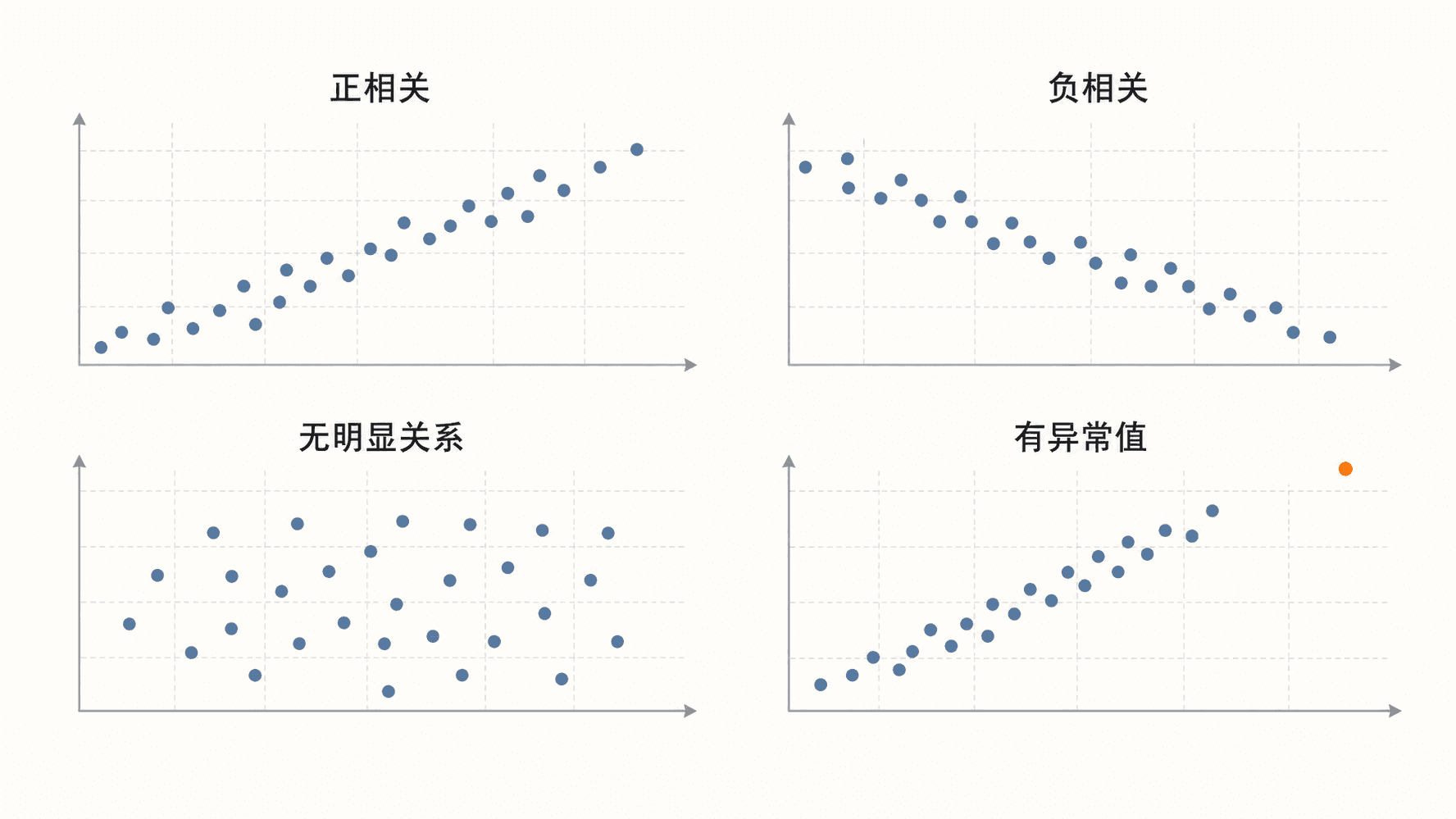
散点图通常先看四件事。
方向:点云整体往右上走,是正方向;往右下走,是负方向。
强弱:点越贴近一条窄带,关系越强;点散得越开,关系越弱。
形状:关系可能接近直线,也可能弯曲。看见弯曲关系时,直接套直线描述会丢掉重要信息。
异常点:有些点远离主体点云,可能是记录错误,也可能是真实但特殊的个体。
Anscombe 四重奏是一个经典提醒:有些数据集的平均数、方差、相关系数和回归直线几乎一样,但散点图形状完全不同。这个例子要表达的不是“数字没用”,而是“只看数字会漏掉结构”。
散点图能提示两个变量是否一起变化,但不能单独证明因果。学习时间和测验分数可能同向变化,仍然需要继续问:有没有基础差异、课程难度、学习方法或其他变量在同时影响结果?
异常值:先调查,再决定
异常值是远离主体数据的观察值。它可能来自录入错误、测量错误,也可能是真实世界里少见但重要的情况。统计上最危险的做法,是看见它“不顺眼”就删除。
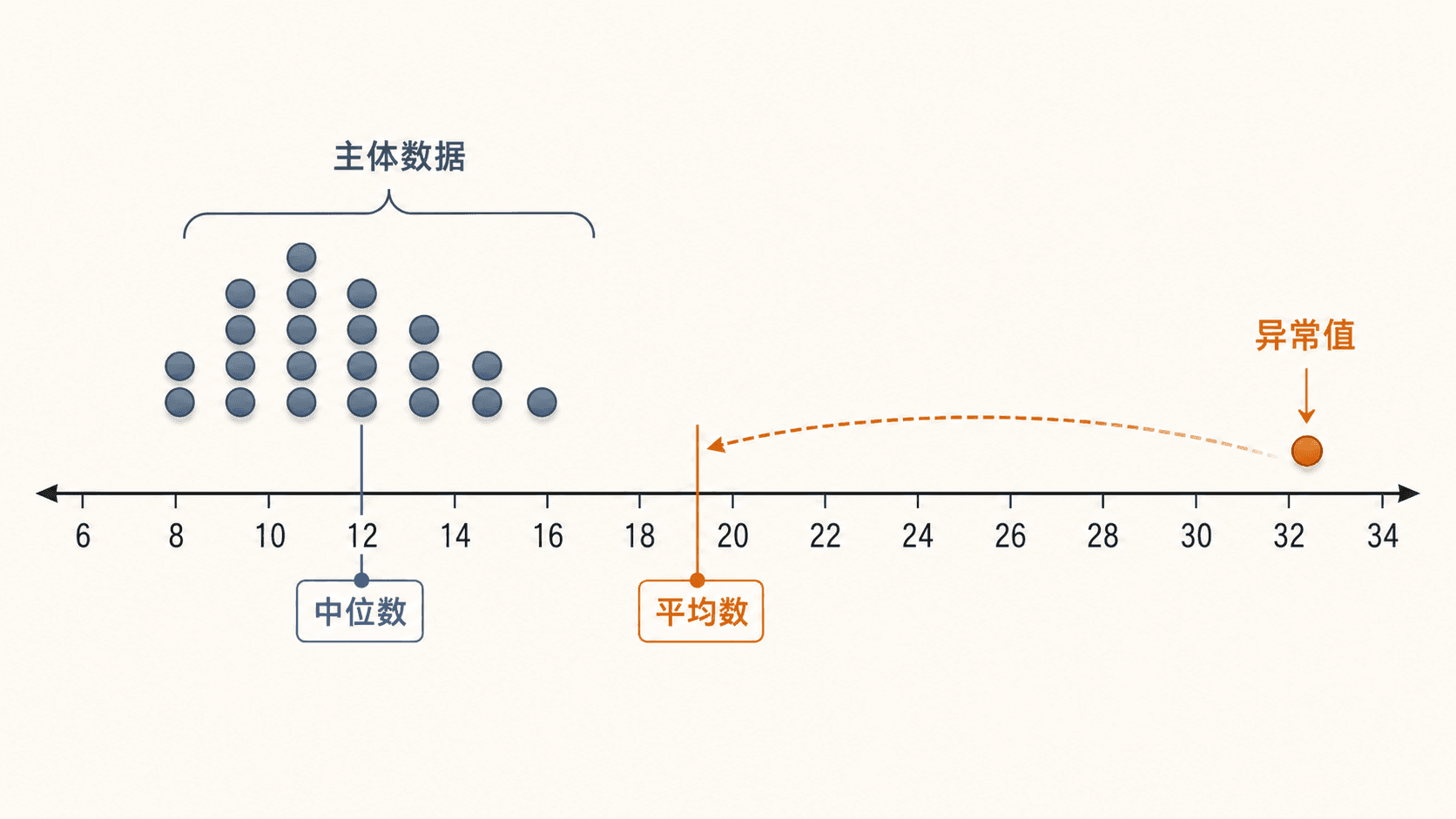
看这组每日运动分钟数:
8, 9, 9, 10, 10, 11, 12, 12, 13, 14, 32
大多数值在 8 到 14 分钟之间,32 分钟显得很远。我们可以先算两个中心指标,看看它对数字有什么影响。
中位数是排序后正中间的第 6 个值,也就是 11。平均数被 32 拉高到了 12.7,而中位数仍在主体数据附近。
异常值判断的四步
先看图。用点图、直方图或散点图找出远离主体的观察值,不要只靠肉眼盯表格。
再回到情境。问这个值是否可能真实存在。32 分钟运动可能真实,320 分钟如果出现在“课间运动”记录里就需要核查。
接着检查数据来源。查看是否有单位混乱、录入多写一位、重复记录或测量设备异常。
最后决定如何报告。如果它是真实特殊值,应保留并说明影响;如果确认是错误,应记录修改理由,而不是悄悄删除。
异常值不是“坏数据”的同义词。它只是提醒我们:这里有一个观察和主体不一样。删不删,取决于证据和研究问题,不取决于它让图表好不好看。
先看图像,再算数
图表观察可以压缩成四个问题:形状怎样?中心在哪里?散得开不开?有没有异常值?
这四个问题不会替代计算,但会决定你接下来该算什么。一个近似对称、没有明显异常值的数据集,平均数常常能很好地代表中心;一个明显右偏、带极端大值的数据集,中位数也许更稳。两个变量的散点图如果弯曲,直接算线性相关系数就要小心。
一个小对比
两组测验分数的平均数都是 80。
只看平均数,它们一样;看图或看范围,差异马上出现。A 组集中,B 组分散,而且有一个超过 100 的特殊分数需要调查。这个例子说明,平均数回答的是“平衡点在哪里”,不是“所有人表现都差不多”。
一个稳妥的顺序是:先画图,描述形状、中心、离散程度和异常值;再选择合适的数字摘要;最后回到情境解释这些数字。这样计算不容易跑在理解前面。
常见误区辨析
误区一:图表越复杂越专业
好图表不是元素多,而是问题清楚。一个干净的条形图,常常比带阴影、立体效果和复杂配色的图更容易读。三维柱状图尤其容易让高度判断变形,初学统计时尽量不用。
误区二:折线图可以连接所有东西
折线图的线表示顺序中的连续变化。时间数据可以连,温度随日期变化可以连;运动类别、颜色偏好、交通方式之间没有连续顺序,连线反而会制造不存在的趋势。
误区三:直方图最高的柱子就是平均数
最高的柱子表示频数最多的区间,它更接近“众数区间”的概念。平均数是平衡点,可能不在最高柱子里。尤其在偏态分布中,平均数会被长尾拉走。
误区四:看见异常值就删除
异常值要先查原因。数据错误可以修正,真实特殊值应该保留并说明。比如医院里一个特别高的用药剂量可能是录入错误,也可能对应一位重症患者;这两种情况不能同样处理。
误区五:坐标轴怎么截都可以
条形图的纵轴如果从非零处开始,差异可能被夸大。折线图有时可以截轴以观察小波动,但必须清楚标出,并提醒读者变化的实际幅度。图表的尺度是读者理解数据的一部分,不是随手设置的背景。
练习:让图先说话
练习 1:选择图表
某班记录 40 位同学最喜欢的早餐类型:包子、面包、粥、鸡蛋、米粉。应该先做什么图?为什么?
这是一类类别数据,应该先做频数表,再用条形图比较各早餐类型的频数。直方图不合适,因为“包子、面包、粥”不是连续数值区间。
练习 2:读直方图形状
某次跑步训练的完成时间大多集中在 12 到 16 分钟,但少数同学用了 25 分钟以上。这个分布可能有什么形状?读图时要注意什么?
它可能是右偏分布,因为少数较大的完成时间把右侧尾巴拉长。读图时要同时说明主体集中区间和右侧长尾,不要只报一个平均时间。若后续要选中心指标,中位数可能比平均数更能代表多数人的完成时间。
练习 3:异常值是否删除
一组每日阅读时间为 18, 20, 22, 23, 24, 25, 26, 110 分钟。110 分钟看起来很远。你会直接删除它吗?
不应该直接删除。先检查它是否录入错误,比如是否把 10 写成 110;再问情境上是否可能真实存在,比如周末有人连续读了一本书。如果确认真实,就应保留并说明它会拉高平均数;如果确认错误,再记录依据并修正。
练习 4:比较平均数相同的两组数据
两组数据如下:
它们的平均数都是多少?只说平均数够不够?
A 组平均数是 ,B 组平均数是 。只说平均数不够,因为 A 组集中在 10 附近,B 组散得更开。图像会显示 B 组的离散程度明显更大。
练习 5:散点图怎么描述
一张散点图中,横轴是每天学习时间,纵轴是小测分数。点云整体往右上方走,但有几个学习时间很长、分数仍然偏低的点。你会怎样描述?
可以说这张散点图显示学习时间和小测分数大致呈正方向关系,但关系不是完全稳定,存在几个偏离主体趋势的点。描述时不要直接说“学习时间导致分数提高”,还要考虑学习方法、基础差异、题目难度等因素。
练习 6:折线图还是条形图
如果要展示一周内每天午餐排队人数的变化,用折线图还是条形图更合适?如果要展示不同窗口今天卖出的份数呢?
一周内每天午餐排队人数有时间顺序,用折线图可以观察趋势和波动。不同窗口今天卖出的份数是类别比较,用条形图更合适;不要把不同窗口硬连成折线。
收束:图表先问,数字后答
频数表把原始记录整理成可核对的数量。条形图比较类别。直方图看数值分布的形状、中心、离散程度和异常值。折线图看时间里的趋势和波动。散点图看两个数值变量之间的方向、强弱、形状和异常点。
下一次拿到数据时,先别急着按计算器。先问:我面对的是类别、数值、时间还是两个变量?图像显示数据集中在哪里、散到哪里、有没有长尾和远点?这些问题问清楚以后,平均数、中位数、极差和标准差才会有落脚点。