数据从哪里来:调查、实验与偏差
一条新闻说:“调查显示,78% 的学生希望学校延长自习室开放时间。”这句话听起来很像一个结论,但统计里会先追问几件朴素的事:调查了谁?怎样找到这些人?没有回答的人和回答的人会不会不一样?问题是怎么问的?
如果这些问题答不上来,后面的百分比再精确,也可能只是把偏差算得很漂亮。统计不是从公式开始的,它从数据是怎样来的开始。
先问:谁进入了数据
数据不是从现实里自动流出来的。有人决定观察谁、问什么、记录什么,也有人因为各种原因没有被观察到。研究设计就是在正式计算前,把这些决定说清楚,并尽量减少它们带来的偏差。
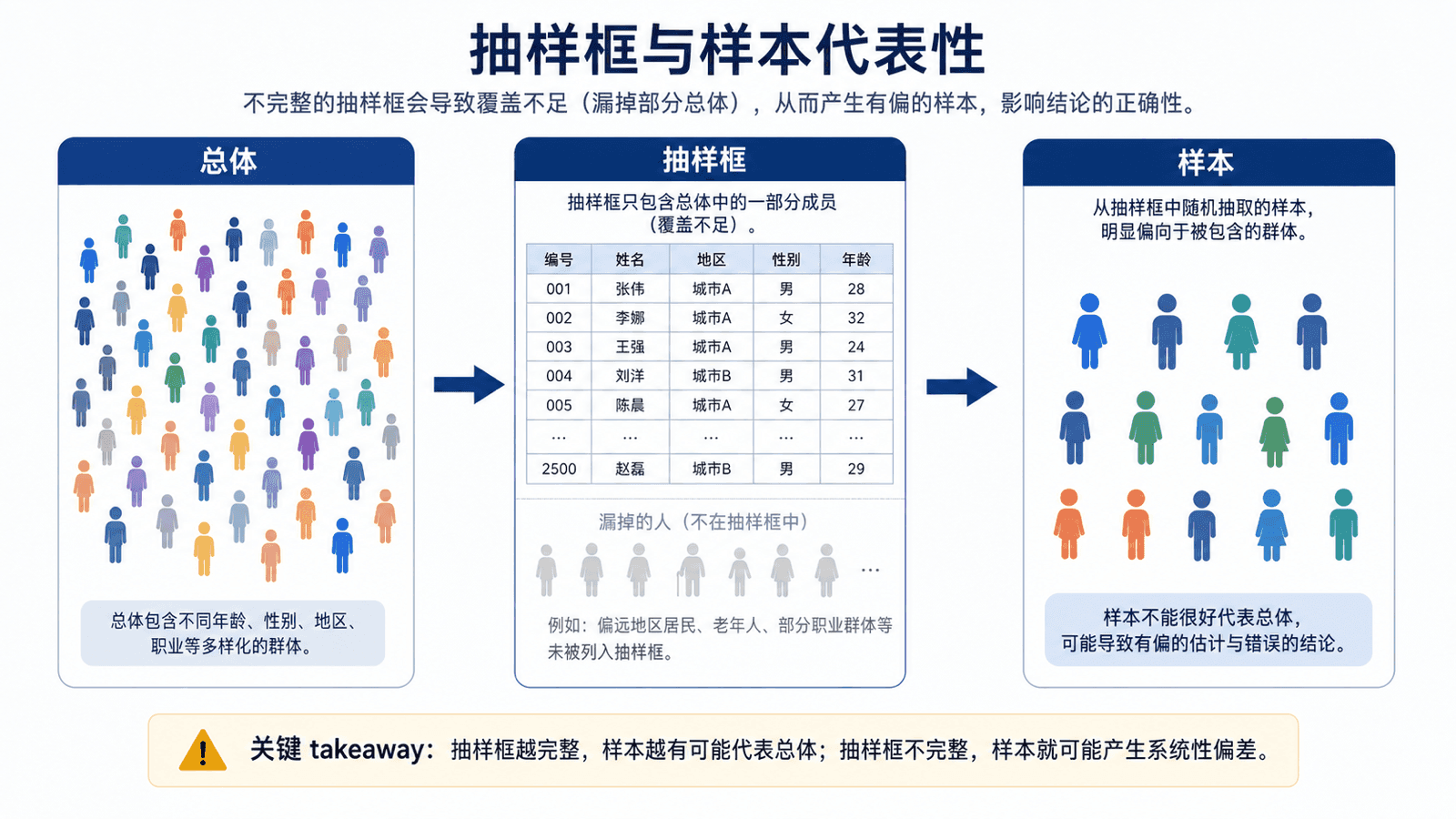
总体、样本和抽样框
总体是你真正想了解的全部对象。样本是你实际观察到的一部分对象。抽样框是你用来找到样本的名单、平台、地点或规则。
如果你想了解全校学生的午餐满意度,总体是全校学生;如果你只在食堂门口发问卷,样本是愿意停下来回答的人;抽样框实际上变成了“那天中午经过食堂门口的人”。这三个范围一旦不一致,结论就要小心。
样本比例常写作 ,总体真实比例常写作 。抽样带来的偏离可以写成:
这里的误差不一定是算错了。即使每一份问卷都真实填写,只要选人的方式偏了, 也可能长期偏向某个方向。
判断一组数据时,先不要急着问平均数是多少。先问总体是谁,样本从哪里来,抽样框有没有漏人。这三个问题能帮你判断数据是否有资格代表你真正关心的对象。
样本大,不等于样本好
一个样本可能有几十万人,却仍然不可靠。历史上有过很大的民意调查,因为主要联系的是拥有电话、汽车或订阅杂志的人,又遇到大量非回应,最后预测严重失误。问题不在于人数少,而在于被联系到的人和真正的投票人并不相同。
相反,一个几百人的随机样本,如果来自清楚的总体、抽样框覆盖充分、回应率可接受,反而可能比一个巨大的自愿投票更有用。样本大小能减少随机波动,却不能自动修复系统性偏差。
抽样调查:从一小部分人推整体
抽样调查的目标,是用一部分人的回答推测更大的总体。它适合研究态度、习惯、使用频率、满意度等问题。好调查要做两件事:让每类人有合理机会进入样本,并让问题尽量不把答案往某个方向推。
几种常见抽样方式
便利样本不是永远没用。它可以帮你发现问题、试运行问卷、收集初步想法。但如果你要用它推断总体,就必须承认它的边界。
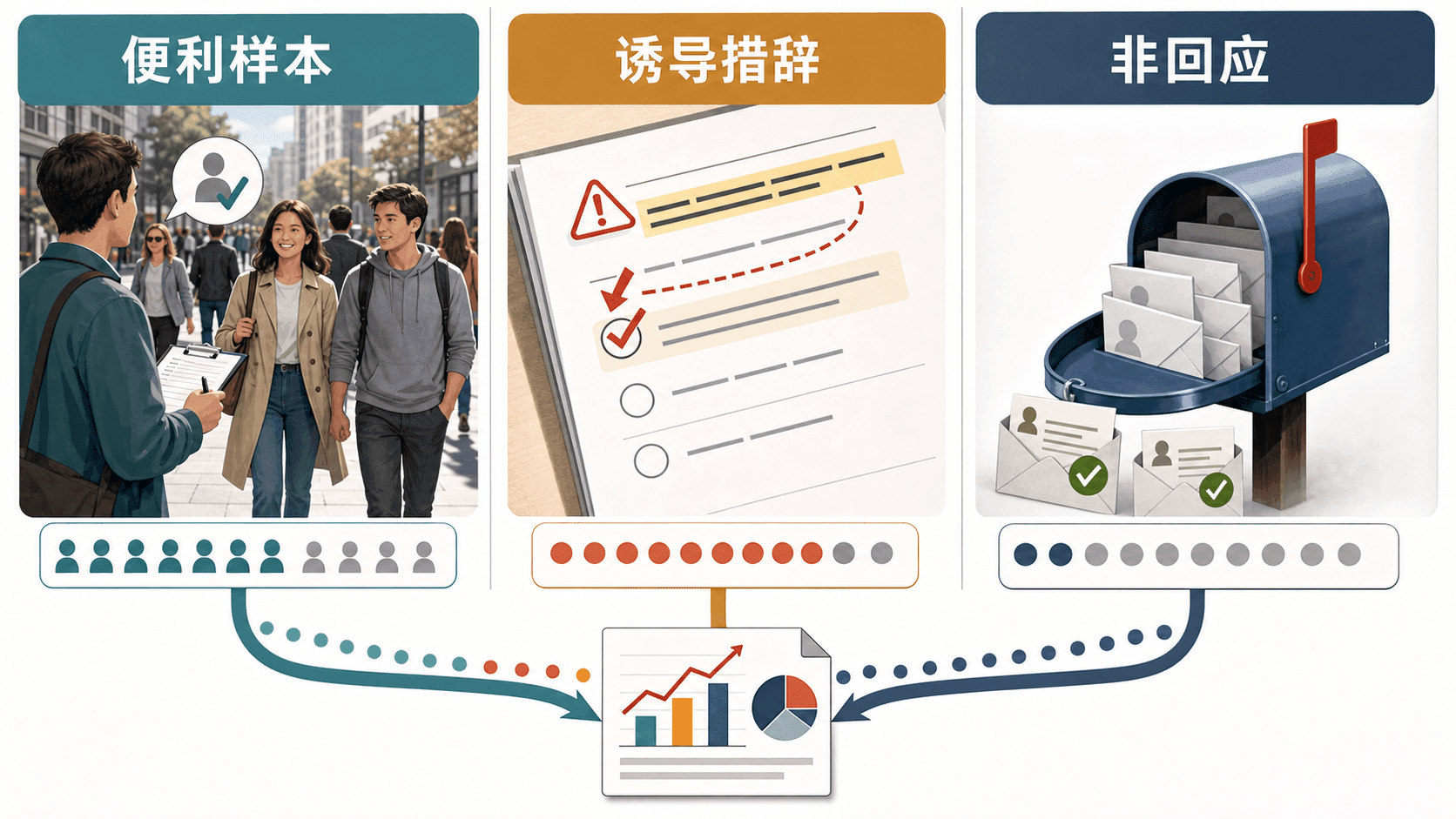
偏差常从三个入口进来
覆盖偏差来自抽样框。比如只用线上问卷调查全校学生,就可能漏掉很少看通知的人。
非回应偏差来自没有回答的人。比如对食堂不满意的人更愿意填写问卷,满意度估计就可能偏低;也可能相反,只有关系好的同学愿意帮忙填,结果又会偏高。
措辞偏差来自问题本身。问“你是否支持浪费经费用于改造自习室?”和问“你是否支持改善自习环境?”得到的答案很可能不同,因为问题已经把情绪放进去了。
下面这个交互可以反复抽样。先保持样本量不变,只切换抽样方式;再保持抽样方式不变,调节回应率。你会看到:增加样本量常能让结果更稳定,但如果抽样框或回应机制偏了,稳定下来的也可能是偏差。
设计一个调查,可以按四步来
假设你要调查“本校学生每天睡眠是否达到 8 小时”。不要一上来就把问卷发到班级群里,可以先把设计问题拆开。
先确定总体。这里关心的是本校所有学生,而不是某一个年级、某一个社团,或者愿意在群里填问卷的人。
再确定抽样框。你需要知道可以从哪里联系到学生,例如学籍名单、班级名单或分层后的年级名单,并检查有没有明显漏掉的人。
接着选择抽样方式。如果各年级作息差异很大,可以按年级分层,再从每一层随机抽取学生。
最后检查题目措辞。相比“你是否经常熬夜影响学习?”,更中性的问法是“过去 7 天里,你平均每天睡眠约多少小时?”
随机抽样和随机分派不是同一件事。随机抽样回答“样本能不能代表总体”,随机分派回答“两个比较组一开始能不能公平”。这两个词都带“随机”,但服务的问题不同。
观察性研究:记录现实,不随便按开关
有些问题不能或不该由研究者安排处理。我们不能随机要求一部分人长期吸烟,也不能随机让一部分学生睡很少。此时研究者通常只能观察已经发生的差异,这叫观察性研究。
观察性研究能发现关系,也能提出很有价值的线索。它的难点是:人们不是随机地选择生活方式、治疗方案或学习方法的。那些选择背后常常藏着别的变量。
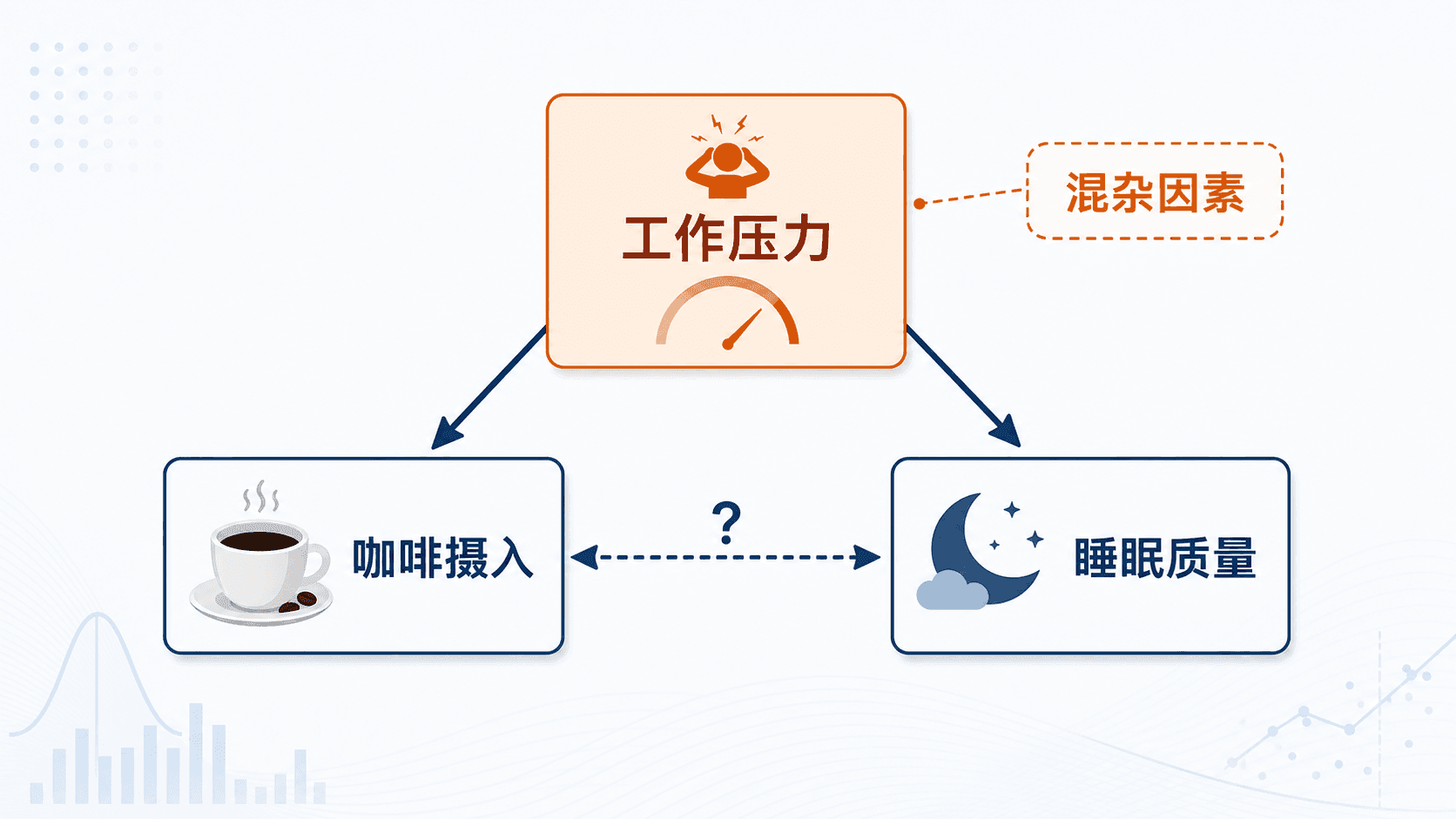
混杂因素:站在背后的第三个量
假设你记录同学的咖啡摄入和睡眠质量,发现喝咖啡多的人睡得更差。能不能直接说咖啡导致睡眠变差?还不能。
工作压力可能同时影响两件事:压力大的人更可能喝咖啡,也更可能睡不好。这样一来,咖啡和睡眠之间的关系就被工作压力搅在一起。工作压力就是混杂因素。
混杂因素不一定能被完全看见。家庭背景、健康状况、学习基础、时间安排、主动性,都可能同时影响“选择了什么”和“结果怎样”。观察性研究越接近现实,越要认真面对这些变量。
观察性研究能说什么
它可以说“在这组数据中,变量 A 和变量 B 一起变化”。如果研究设计细致,还可以控制一些已知变量,让解释更可信。可是只凭观察性数据,通常不能轻易说“A 导致 B”。
“相关”不是“因果”的简写。两个变量一起变化,可能是一个影响另一个,也可能是另一个影响前一个,还可能是第三个变量同时影响了它们。把观察到的关系直接写成原因,是统计推理里最常见也最危险的跳步。
例子:补习班真的让成绩提高了吗
如果你比较参加补习班和没有参加补习班的学生,发现参加补习班的平均成绩更高,这仍然是观察性比较。因为学生不是随机进入补习班的。家庭资源、原本成绩、学习动机和家长关注度,都可能影响是否补习,也可能影响成绩。
这并不说明补习班一定没用。它说明:这组数据本身还不足以把“补习班效果”和“学生原本差异”分开。
随机对照实验:把比较做公平
实验的核心不是把人带进实验室,而是研究者主动安排处理,并把比较做得尽可能公平。随机对照实验是因果判断里很重要的一种设计,因为它用随机分派来削弱混杂因素。
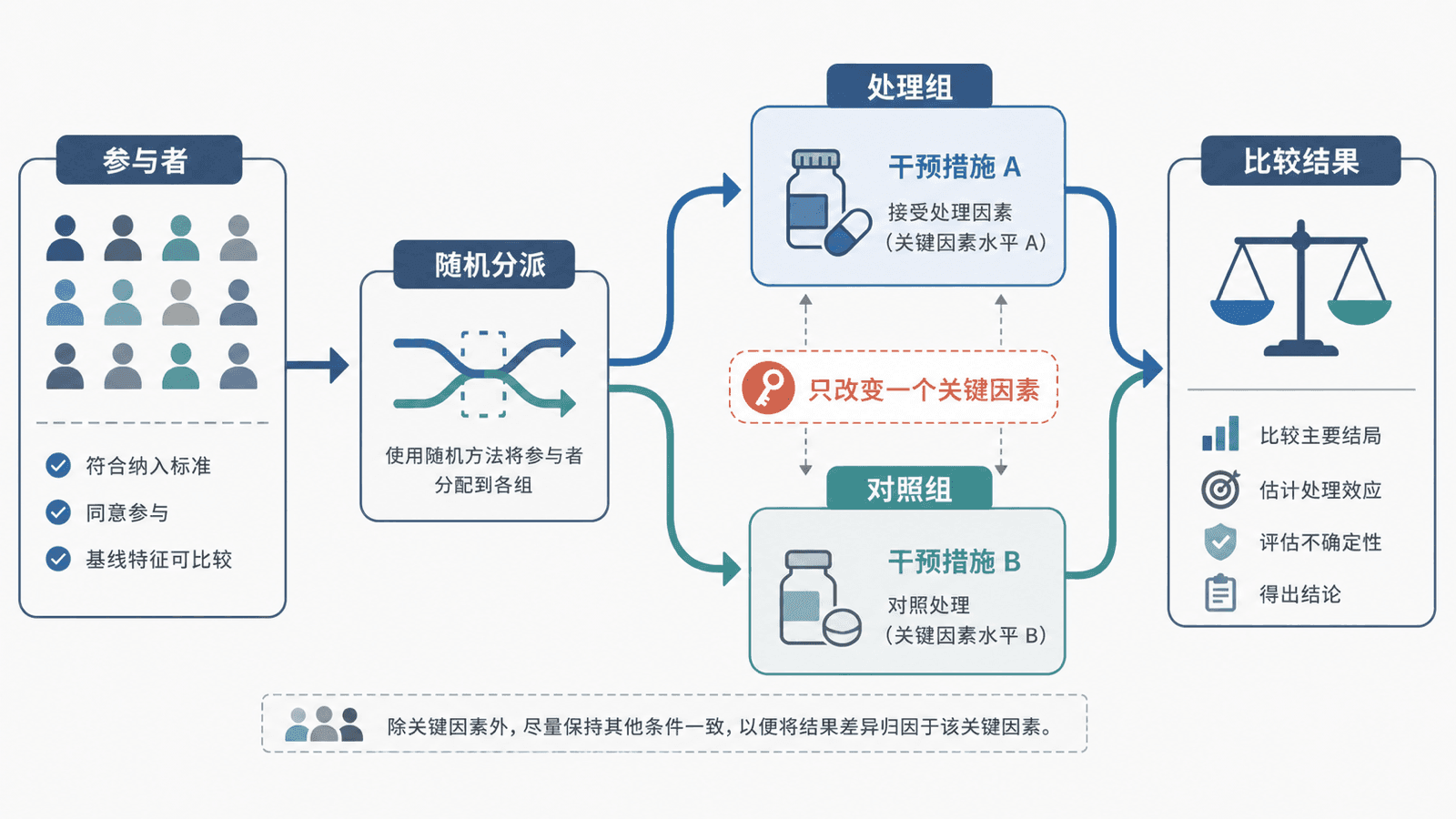
处理组和对照组
处理组接受研究者关心的处理,对照组作为比较基准。处理可以是一种药物、一种教学方法、一个页面版本,也可以是一项提醒服务。
如果两组除了处理以外尽量相同,那么最后结果的差异就更有资格被解释为处理带来的影响。随机分派的作用,就是让各种已知和未知的背景差异在两组中大致平衡。
实验中常看的量是结果差异:
这个差异不一定完全等于真实效果,因为仍会有随机波动、执行偏差和测量误差。但和普通观察性比较相比,它离因果解释更近。
用实验检验一种学习方法
假设学校想知道“每天 10 分钟检索练习”是否能提高单词测验成绩。一个比较公平的实验可以这样设计。
先招募符合条件的学生,并在实验前记录基础水平。基础水平不是用来挑人,而是帮助之后检查两组是否大致平衡。
再把学生随机分派到两组。一组每天做 10 分钟检索练习,另一组按原方法复习。
接着保持其他条件尽量一致。两组学习的单词、测验时间、评分方式都应相同,避免把别的差异混进来。
最后比较两组的测验结果。如果处理组明显更高,而且实验执行可靠,我们才更有理由说这种练习方法起了作用。
下面的交互会模拟两种研究方式。你可以先选择“自愿选择处理”,再切换到“随机分派”。注意观察:当基础水平和选择行为有关时,自愿选择会把处理效果和原本差异混在一起;随机分派则更容易把它们分开。
好的实验设计像一场公平比较:先让两组起点尽量相似,再只改变一个关键因素,最后用同一把尺子测量结果。公式负责计算差异,设计负责让这个差异值得解释。
对照组、安慰剂与盲法
很多实验里,对照组不能只是“什么都不做”。如果参与者知道自己得到了新药、特别训练或额外关注,他们的期待、行为和报告方式可能改变。安慰剂和盲法就是为了减少这些影响。
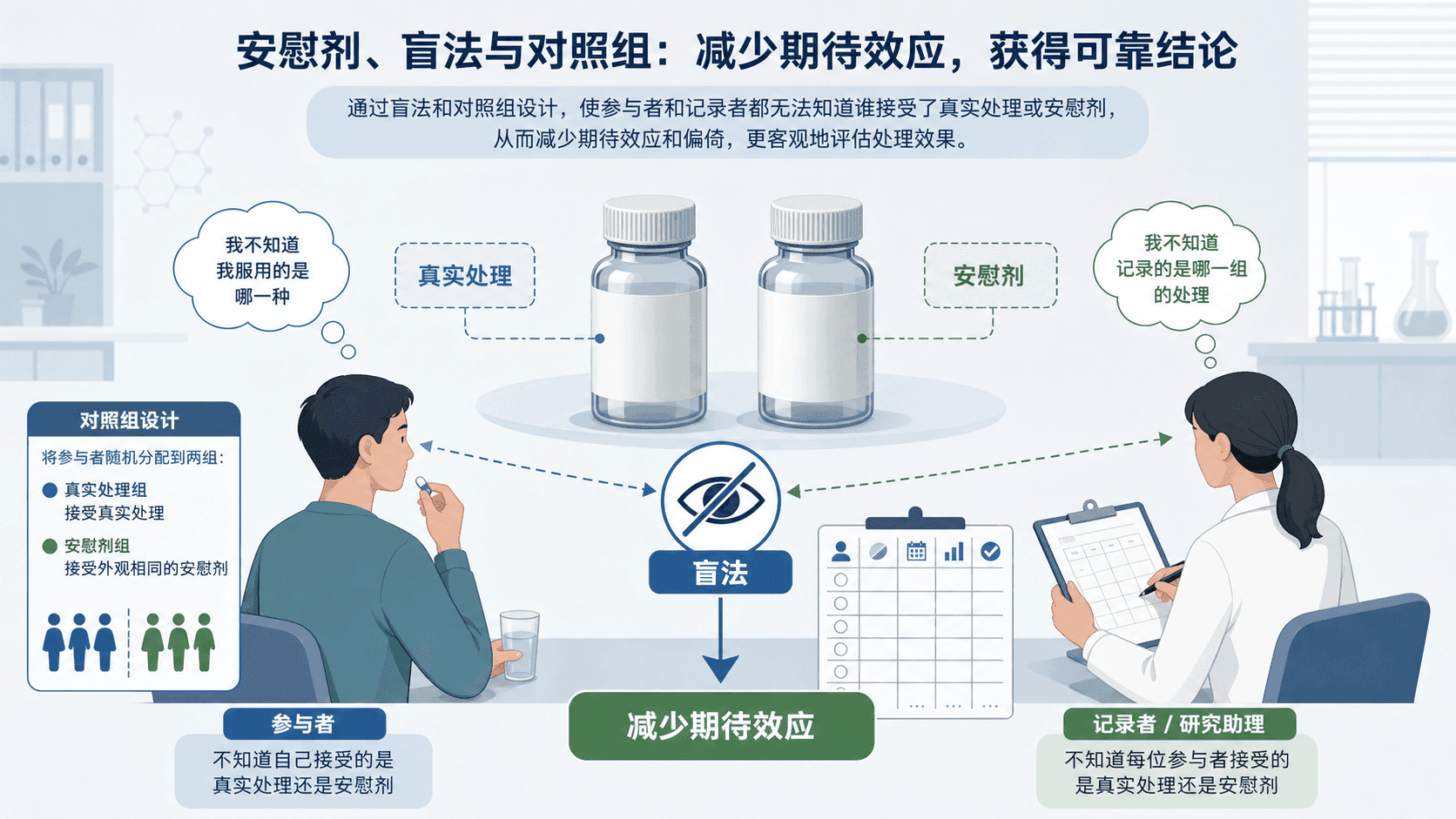
安慰剂不是欺骗的代名词
安慰剂通常看起来像真实处理,但不含研究者真正想测试的有效成分。它的作用是让对照组也经历相似的服用、等待和被关注过程。这样,研究者比较的就更接近“有效成分本身”带来的差异。
但安慰剂不是所有场景都合适。如果已有有效治疗,把病人只放到安慰剂组可能不道德。此时常用的是“新治疗”和“标准治疗”比较,或者在标准治疗基础上增加新处理。
盲法减少期待效应
单盲通常表示参与者不知道自己在哪一组。双盲通常表示参与者和直接记录结果的人都不知道分组。盲法不是为了制造神秘感,而是为了减少期待效应和记录偏差。
安慰剂、对照组和盲法都在服务同一个目标:让“处理本身的影响”从其他影响里分离出来。它们不是实验的装饰,而是因果判断的保护栏。
例题:哪种结论站得住
某学习 App 想知道“每日提醒”是否能提高用户连续学习天数。它先查看后台数据,发现主动打开提醒功能的用户,平均连续学习 14 天;没有打开提醒的用户,平均连续学习 9 天。于是产品经理说:“提醒功能让用户多学习了 5 天。”
这个结论哪里需要小心?如果要更接近因果判断,应该怎样改设计?
先判断研究类型。这里用户是否打开提醒是自己选择的,研究者只是查看已有数据,所以这是观察性比较,不是随机对照实验。
再找可能的混杂因素。主动打开提醒的人,可能本来就更有学习计划、更重视打卡,也可能目标更明确。这些因素会同时影响“是否打开提醒”和“连续学习天数”。
接着判断原结论能说到哪里。数据可以支持“打开提醒的用户连续学习天数更高”,但不能直接支持“提醒功能使用户多学习 5 天”。
最后改成实验设计。可以把新用户随机分派为两组,一组默认开启每日提醒,另一组不开启或使用普通通知;两组使用同样的统计窗口和结果指标,再比较连续学习天数。
如果实验后处理组平均连续学习 12 天,对照组平均 10 天,而且两组执行过程稳定,那么“提醒带来的平均差异”更接近 2 天,而不是后台观察到的 5 天。这个差别正是混杂因素可能造成的。
常见误区:数据看起来多,不代表设计好
误区一:只要人数多,结论就可靠
人数多能减少随机波动,但不能保证样本代表总体。一个大型自愿投票可能比一个小型随机调查更偏,因为愿意投票的人本来就更激动、更关注问题。
误区二:随机抽样可以证明因果
随机抽样让样本更像总体,主要服务于“能不能推广”。要讨论因果,还需要看是否随机分派处理、是否有对照组、是否控制混杂因素。
误区三:观察性研究没有价值
观察性研究很有价值,尤其在无法实验或不该实验的问题上。它可以发现长期趋势、提出假设、追踪风险因素。它的边界是:因果话语要更谨慎。
误区四:对照组就是没用的一组
对照组不是陪跑。没有对照组,就很难知道结果变化是处理带来的,还是时间、期待、自然恢复、练习效应或外部环境带来的。
最危险的统计句式之一是“数据显示,所以一定是因为”。更稳妥的顺序是:先说明数据来自哪种设计,再说明这种设计允许我们说到什么程度。
练习:先判断设计,再决定能说什么
练习 1:图书馆问卷
学校想了解全校学生对图书馆座位数量的满意度。调查员只在考试周晚上 8 点到图书馆门口发问卷。这个调查最可能有什么偏差?
它很可能有覆盖偏差和便利样本问题。考试周晚上 8 点在图书馆门口出现的人,可能比普通学生更常用图书馆,也更容易感到座位紧张。这个样本不能直接代表全校学生。
练习 2:运动与成绩
研究者发现,每周运动时间较长的学生,平均成绩也更高。能不能直接说运动提高成绩?写出一个可能的混杂因素。
不能直接说运动提高成绩。可能的混杂因素包括时间管理能力、家庭支持、睡眠习惯、健康状况等。比如时间管理强的学生既更容易安排运动,也更容易保持学习进度。
练习 3:药物实验
一种新药要和安慰剂比较。研究者让病人自己选择是否服用新药,然后比较两组恢复率。这个设计最大的问题是什么?
最大的问题是没有随机分派。自己选择新药的人可能病情更轻、更愿意尝试新方案,或者经济条件不同。恢复率差异会混入这些原本差异,不能干净地解释为药物效果。
练习 4:把设计补完整
你想检验一种新的背单词 App 是否能提高一周后的测验成绩。请写出处理组、对照组和结果变量。
处理组可以使用新的背单词 App,对照组使用原来的复习方式或一个标准版本 App。结果变量可以是一周后的单词测验成绩。为了更接近因果判断,应把参与者随机分派到两组,并让两组学习同一批单词、在同一时间测验。
练习 5:随机抽样还是随机分派
“从全校名单中随机抽取 300 名学生填写睡眠问卷”和“把 300 名学生随机分成两组,一组使用新作息提醒,一组不使用”,这两句话里的随机分别在解决什么问题?
前一句是随机抽样,解决样本能否代表全校学生的问题。后一句是随机分派,解决两组比较是否公平、能否更接近因果判断的问题。两个设计都重要,但它们回答的问题不同。
收束:好问题先问数据从哪里来

学完这一章,再看到百分比、平均数、柱状图或差异比较,可以先停一下。不要急着相信,也不要急着否定。先问数据从哪里来。
如果是抽样调查,重点看总体、抽样框、抽样方式、回应率和题目措辞。如果是观察性研究,重点找混杂因素,谨慎使用因果语言。如果是实验,重点看是否随机分派、是否有对照组、是否需要安慰剂和盲法。
这一章真正想留下的不是某个公式,而是一种顺序:先审设计,再看数字。数据收集方式常常决定了后面的计算能走多远。