数据到底在说什么
一条新闻说“某地学生平均睡眠时间下降了”,一张成绩单显示你这次考了 86 分,一个体检表记录身高 171.2 厘米,一次民调显示 52% 的受访者支持某个方案,一项医疗实验比较了两组病人的恢复结果。
这些材料看起来很不一样:有的是数字,有的是选择,有的是表格,有的是图。统计学关心的不是“怎样把数字算得更复杂”,而是一个更朴素的问题:我们怎样从观察到的材料出发,做出尽量可靠的判断?

数据不会自己说出结论。它更像证据:能支持某种判断,也可能留下疑问。
数据不是答案,数据是证据。统计学要训练的,是先问清楚证据来自哪里、记录了什么、想说明谁,再决定能不能用它支持一个判断。
从一个问题开始
假设你在新闻里看到一句话:“抽样调查显示,本市高中生每天平均运动 42 分钟。”这句话很短,但里面至少藏着五个统计问题。
- 调查真正想讨论的是哪些人?
- 实际问到了哪些人?
- 每个人被记录了什么?
- 这些记录是怎样变成“42 分钟”的?
- 这个数字能不能代表所有本市高中生?
如果不问这些问题,“42 分钟”只是一个孤立的数字。问过这些问题以后,它才开始变成证据。
五个词先放在桌面上
我们先用一个小例子固定语言。某校想了解高一年级学生的通勤时间,于是从高一年级 620 名学生中随机抽取 60 名学生,记录每个人从家到学校所用的分钟数。
这五个词不是背诵用的标签。它们是一套检查顺序:先看对象,再看记录,再看范围,最后看证据能支持什么。
个体、变量和数据
个体是被观察的对象。它可以是一个人,也可以是一所学校、一家医院、一场比赛、一条新闻、一件产品。关键不在于“是不是人”,而在于它是不是研究中被逐个观察的单位。
变量是个体身上被记录的特征。学生有身高、成绩、每天运动时间;选民有年龄、投票选择、是否参加投票;病人有治疗方式、血压、是否复发。变量像一个问题,问到每个个体身上,就得到一个变量值。
数据是一批变量值的集合。一个人的身高“171.2 厘米”只是一个记录;全班 48 人的身高记录放在一起,才形成一组数据。
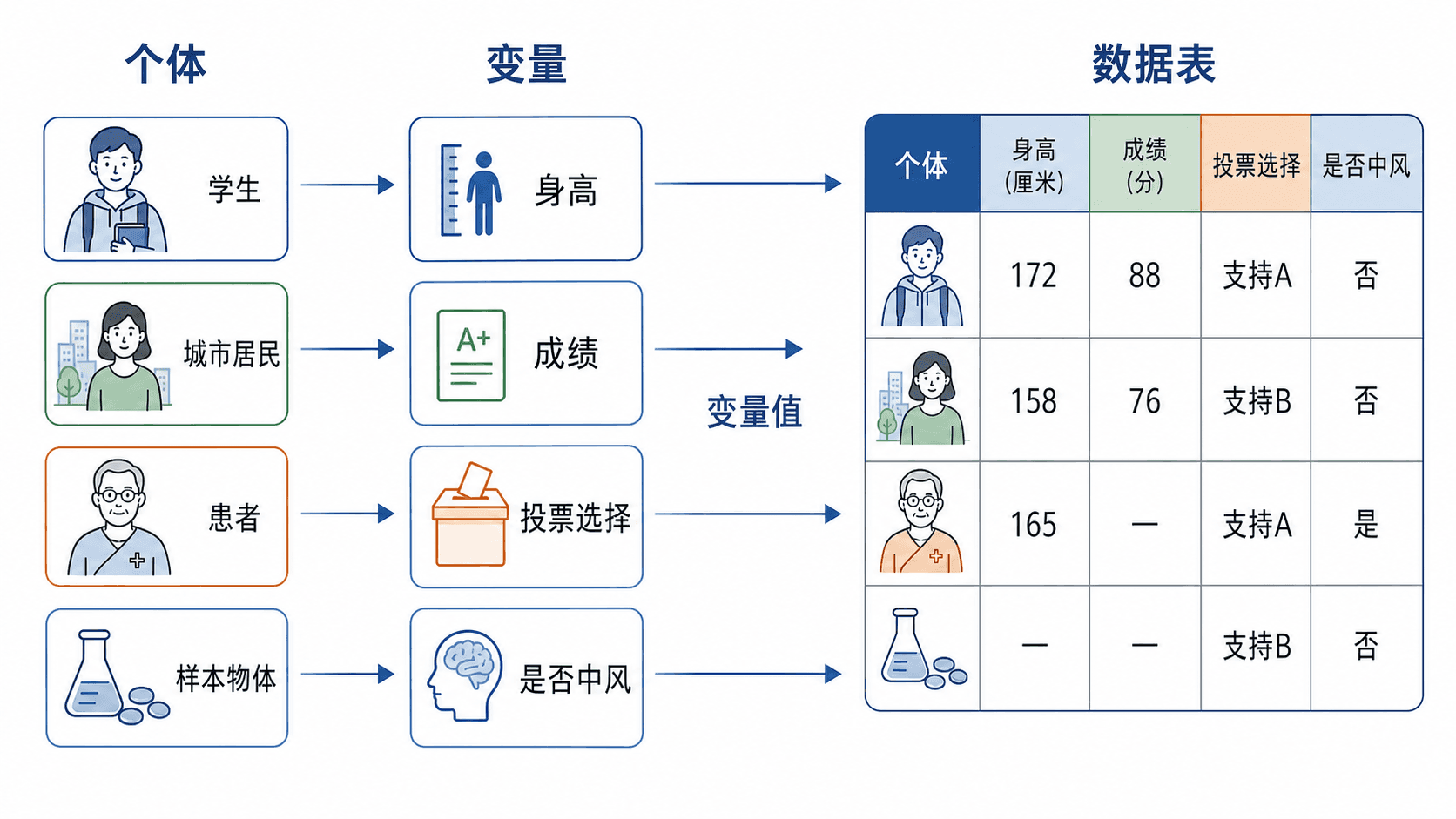
个体是被观察的对象,变量是观察角度,数据是一批观察结果。
一行数据通常对应一个个体
很多数据表都可以按“行”和“列”来读。通常,一行对应一个个体,一列对应一个变量。
在这张表里,学生 A、B、C 是个体;身高、数学成绩、每周运动次数、是否参加校队是变量;表格里的每个具体值是变量值;整张表是数据。
不要把“数据”简单理解成“数字”。“是否参加校队”“投票给哪个方案”“血型”“是否复发”都可以进入数据表。它们不是用来加减的数字,但仍然是观察结果。
变量不只是数字
变量大致可以先分成两类:定量变量和分类变量。
定量变量记录数量或大小,通常可以比较大小、求差值或计算平均数。例如身高、通勤时间、考试分数、一次实验的温度。
分类变量记录类别或状态,通常不能直接做加减。例如是否通过、投票选择、血型、治疗组别、新闻主题。
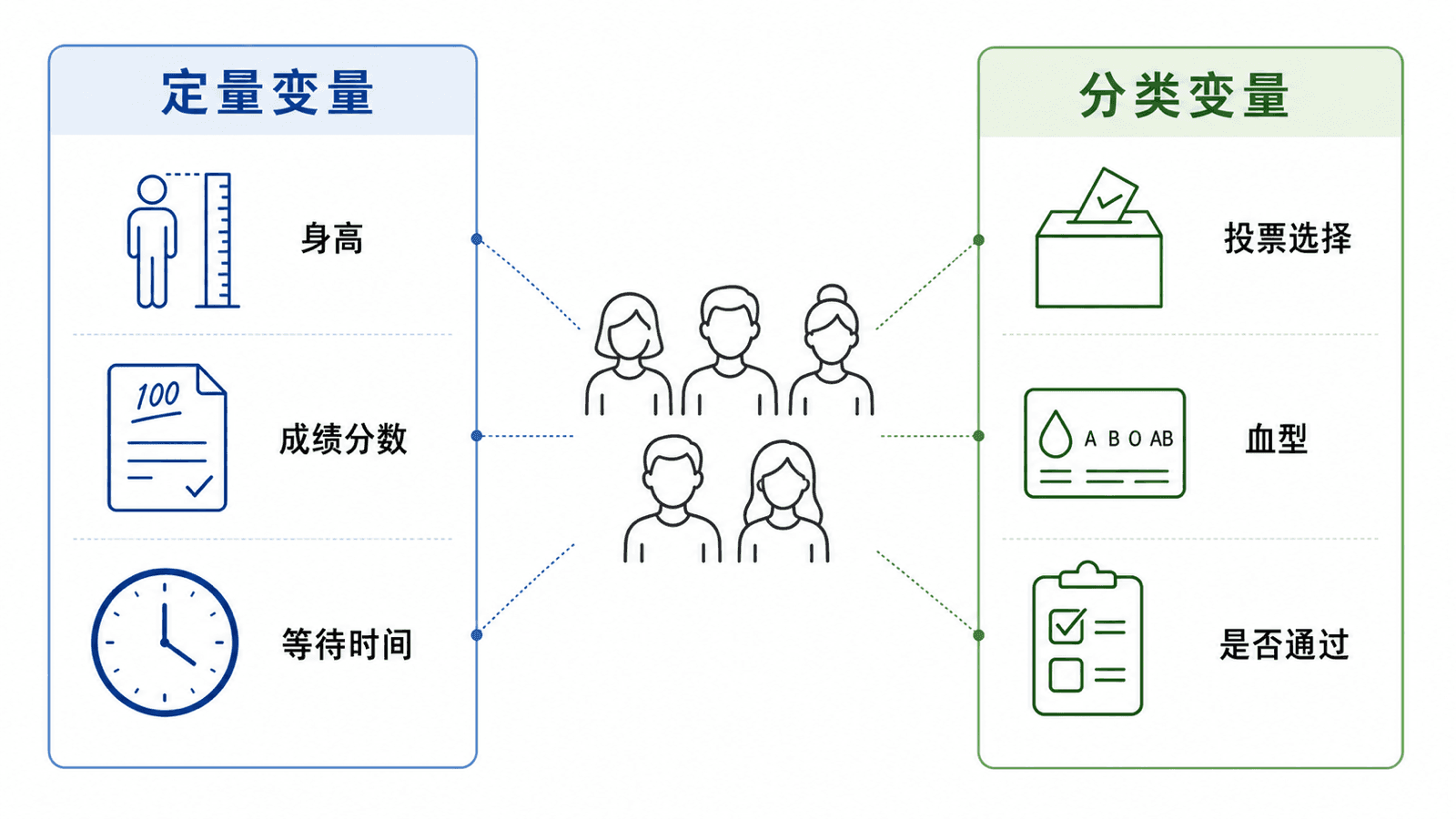
变量可以是数量,也可以是类别。先认清变量类型,后面才知道该用什么方式整理。
同一个场景里常常有多种变量
以一次考试为例,可能记录的变量包括:
- 分数:定量变量。
- 是否及格:分类变量。
- 考试用时:定量变量。
- 错题主要类型:分类变量。
- 是否参加课后辅导:分类变量。
如果研究问题是“谁需要补习”,分数和错题类型都可能有用;如果研究问题是“考试时间是否太紧”,考试用时就更关键。
统计学不是先算平均数,而是先问:为了回答这个问题,应该记录哪些变量?
总体和样本
总体是研究问题真正想覆盖的全部对象。样本是实际被观察到的那一部分对象。
新闻里说“本市高中生平均运动 42 分钟”,总体可能是“本市所有高中生”。但调查通常不可能真的问到每一个高中生,于是只抽取一部分学生作为样本。

样本是我们看见的一部分,总体是我们想判断的整体。统计推断就在这两者之间发生。
样本很有用,因为它让我们不用观察每一个对象也能形成判断。样本也很危险,因为样本如果选得偏,得到的数据就会把我们带向错误方向。
样本量大,不等于样本好
一个样本有 10 万人,看起来很有气势。但如果这 10 万人都来自同一个网站、同一个学校、同一个收入群体,样本可能仍然偏。另一个样本只有 1200 人,如果抽取方式覆盖了不同地区、年龄和背景,反而可能更接近总体。
民调就是典型例子。一次投票调查想判断“所有有投票资格的居民”的意见,但真正回答问卷的人只是样本。样本如果只来自特别愿意表达意见的人,或者只来自某类联系方式容易找到的人,结论就可能偏离总体。
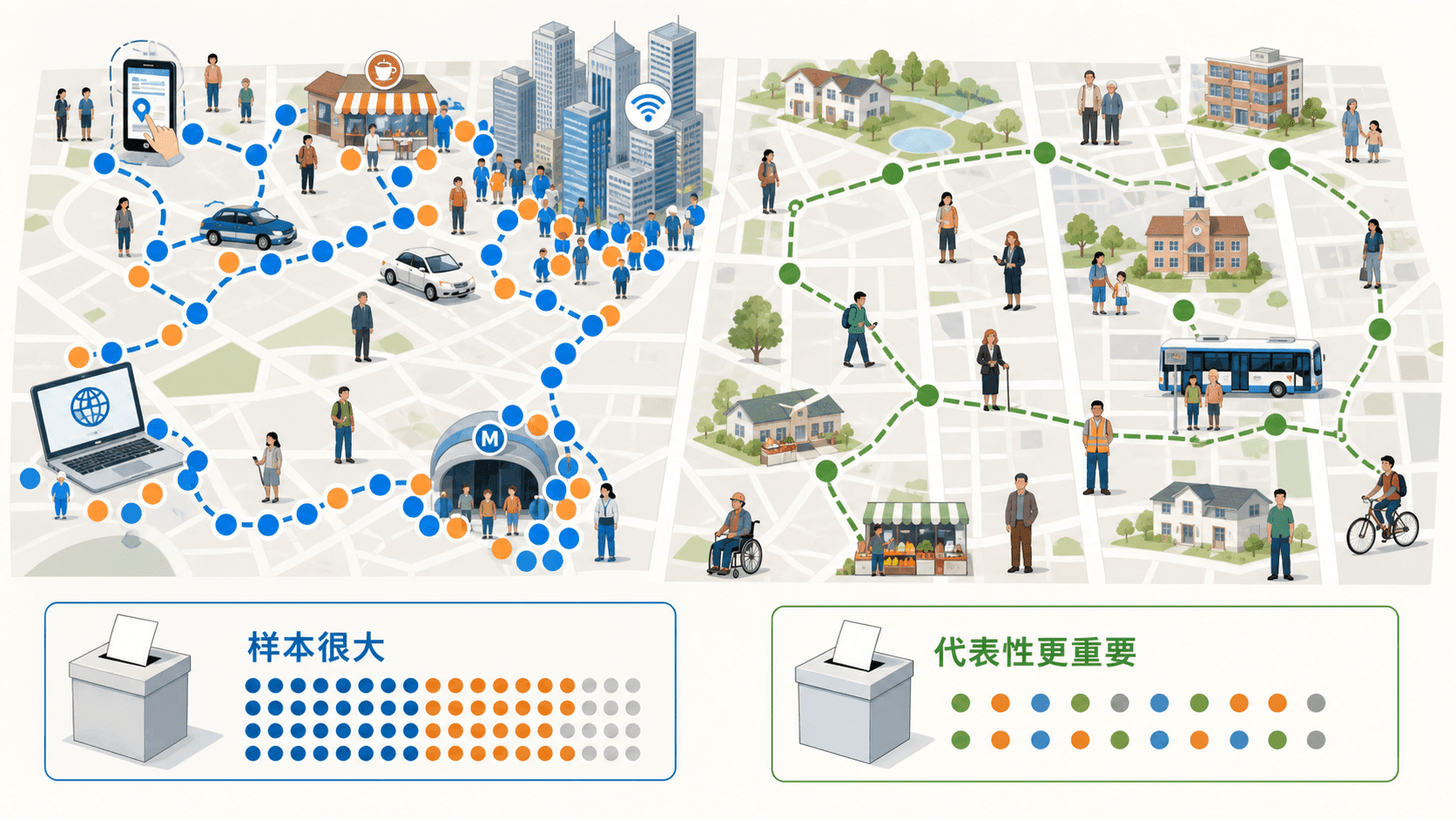
样本大小会影响证据强弱,但代表性决定证据有没有对准总体。
数据怎样支持判断
统计判断通常有一个从问题到证据的链条。
先把研究问题说清楚。比如“这项治疗是否能减少一年内中风的风险”,比“这个治疗有没有用”更容易转化为可观察的变量。
再确定总体和个体。如果研究的是有特定中风风险的病人,总体就不是所有人,个体也不是医院或医生,而是每一名符合条件的病人。
接着选择变量。这里至少要记录治疗方式,以及一年内是否中风。治疗方式是分类变量,是否中风也是分类变量。
然后收集样本数据。样本中每位病人都有一行记录,记录其所在组别和结果。
最后比较整理后的数据。比较时通常看比例,而不只看人数,因为两组人数可能不完全一样。
一个医疗实验的例子
某项医疗实验收集了 451 名有中风风险的病人。研究者把病人随机分成两组:224 人进入治疗组,接受支架和常规医疗管理;227 人进入对照组,只接受常规医疗管理。一年后,治疗组有 45 人中风,对照组有 28 人中风。
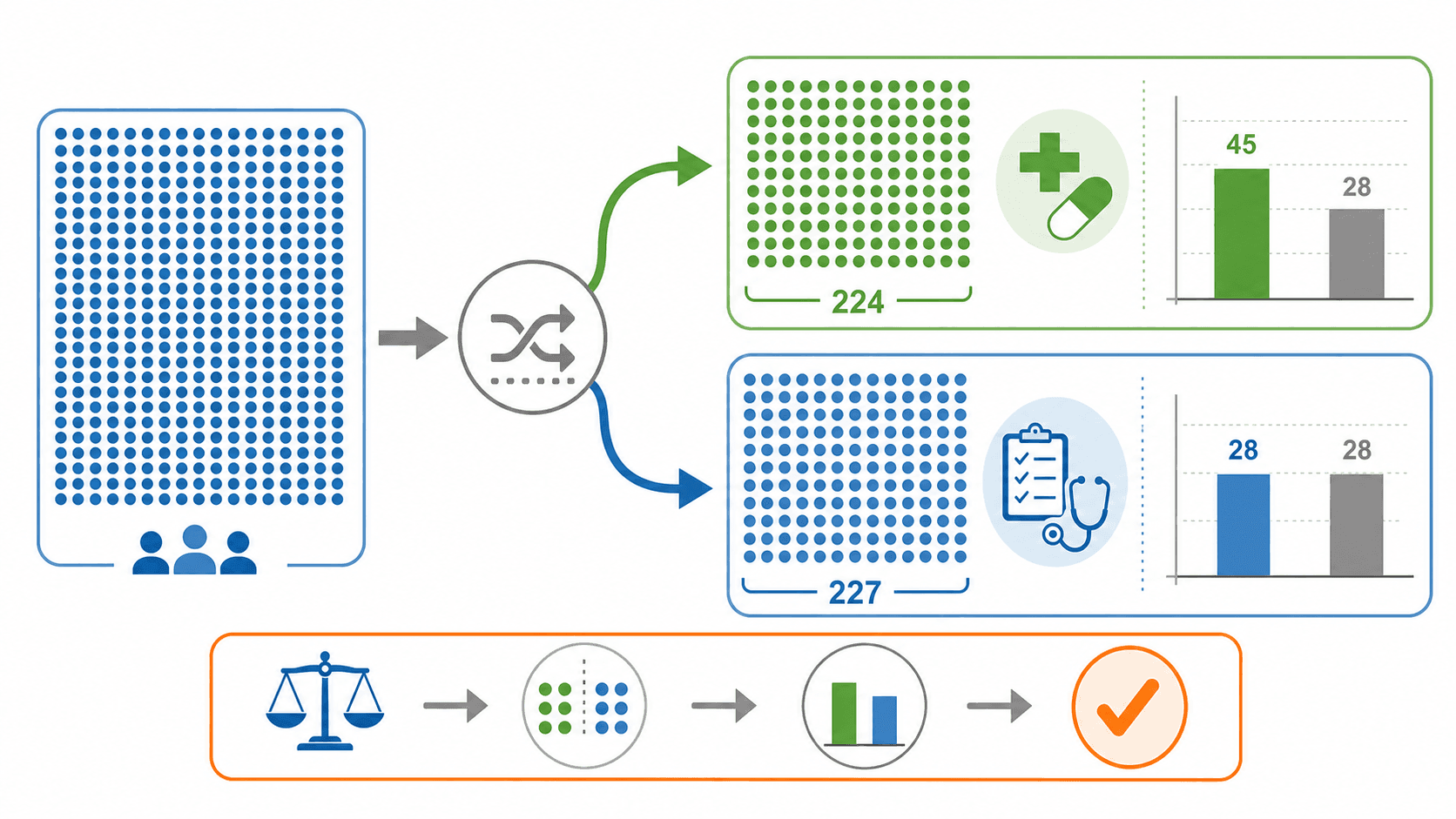
同样是“看结果”,医学实验更关心两组是否可比较,以及结果差异能支持什么判断。
如果只看人数,45 比 28 多。但两组人数不同,更合适的是比较比例。
这组数据没有支持“治疗组更少中风”的说法,反而显示治疗组一年内中风比例更高。注意,这里仍然不能只凭一个比例差就完成全部医学判断。我们还要继续问:实验设计是否可靠?随机分组是否执行得好?差异可能由随机波动造成吗?有没有其他安全指标?
好的统计判断不是从数据直接跳到结论,而是把“问题、总体、样本、变量、比较方式和不确定性”一层一层摆清楚。
常见误区辨析
误区一:有数字就客观
数字看起来冷静,但数字也可能来自错误的问题、偏的样本、混乱的定义或不完整的记录。
比如“平均成绩提高了 5 分”听起来是好消息。可如果这次考试更容易,或者低分学生没有参加,平均数提高并不能直接说明学习水平提高。
误区二:样本越大,结论越真
样本大通常能减少随机波动,但不能自动消除偏差。如果一个调查只让愿意主动扫码的人填写,它可能把“愿意扫码的人”的意见说得很准,却不一定代表所有人。
误区三:数据表里的一列就是答案
变量本身不是答案。变量只是观察角度。把“身高”记录下来,不等于已经回答了“这个班是否比另一个班高”;把“投票选择”记录下来,也不等于已经知道全体居民会怎么投。
误区四:两个比例不同,就说明有确定差异
样本数据会波动。两个样本比例不同,可能反映总体中的真实差异,也可能只是样本抽取造成的摇晃。后面的课程会学习怎样估计这种摇晃有多大。
例题:把一句话拆成统计语言
题目:某新闻写道:“为了了解本市初中生对校内手机管理规定的看法,研究者从 12 所学校中抽取 800 名初中生,记录他们是否支持这项规定,以及每天使用手机的时长。”
请指出个体、变量、数据、总体和样本。
先找总体。新闻想了解的是“本市初中生”对规定的看法,所以总体是本市所有初中生,而不是这 12 所学校,也不是全国初中生。
再找样本。实际被记录的是抽取出的 800 名初中生,所以样本是这 800 名学生。
接着找个体。每一名初中生都是一条观察单位,因此个体是每一名初中生。
然后找变量。题目至少记录了两个变量:是否支持手机管理规定、每天使用手机的时长。
最后判断数据是什么。800 名学生在这两个变量上的具体记录合在一起,就是这项调查的数据。
一句判断要留一点余地
如果样本中 61% 的学生支持这项规定,我们可以说:“在这 800 名受访学生中,支持比例是 61%。”如果要说“本市初中生大约有 61% 支持”,就已经从样本走向总体,需要继续讨论抽样方式和误差。
本章小结
这一节最重要的不是某个公式,而是几个检查问题:
- 我们想判断的总体是谁?
- 实际观察到的样本是谁?
- 每个个体身上记录了哪些变量?
- 数据是怎样从变量值汇集成表格或图表的?
- 这些数据能支持什么判断,又还不能支持什么判断?
以后看到新闻、成绩、身高、投票或医学实验的数据时,先不要急着问“结论是什么”。先问:“这份数据到底在替谁说话?它说的是哪一个变量?它来自怎样的样本?它只是描述样本,还是想推断总体?”
统计学的起点不是计算,而是把证据摆正。只有先摆正对象、变量、样本和总体,后面的图表、平均数、概率和推断才有意义。
练习
练习 1
某学校想了解全校学生的早餐习惯,从每个年级随机抽取 40 名学生,记录他们当天是否吃早餐、早餐花费和第一节课是否迟到。指出总体、样本、个体和变量。
总体是该校全体学生。样本是从各年级抽取出的学生。个体是每一名学生。变量包括当天是否吃早餐、早餐花费、第一节课是否迟到。其中早餐花费是定量变量,另外两个是分类变量。
练习 2
一次线上投票显示,参与投票的 20 万人中有 68% 支持某项城市建设方案。有人说:“样本已经很大,所以全市居民一定有 68% 支持。”这句话的问题在哪里?
问题在于把“大样本”直接当成“好样本”。20 万人确实很多,但如果他们是自愿参加线上投票的人,就可能和全市居民总体不同。这个数据能准确描述参与投票者的意见,但要代表全市居民,还需要看抽样方式是否覆盖不同年龄、地区、职业和上网习惯的人。
练习 3
一份班级数据表有 45 行,列名包括“学生编号、身高、是否近视、每周运动小时数、最喜欢的运动项目”。这张表中哪些变量是定量变量,哪些是分类变量?
身高和每周运动小时数是定量变量,因为它们表示可以测量或计数的数量。是否近视和最喜欢的运动项目是分类变量。学生编号通常只是识别个体的标签,不适合当作可比较大小的定量变量来解释。
练习 4
某医院比较两种护理方案。A 方案有 80 名病人,其中 12 人复发;B 方案有 120 名病人,其中 15 人复发。只看复发人数,A 方案的 12 人少于 B 方案的 15 人。这样比较是否合适?应该怎样改进?
不合适,因为两组人数不同。应该比较复发比例。A 方案复发比例是 ,B 方案复发比例是 。按比例看,A 方案并不更低。进一步判断还要看分组方式、样本量和差异是否可能来自随机波动。