从样本推总体:抽样误差与置信区间
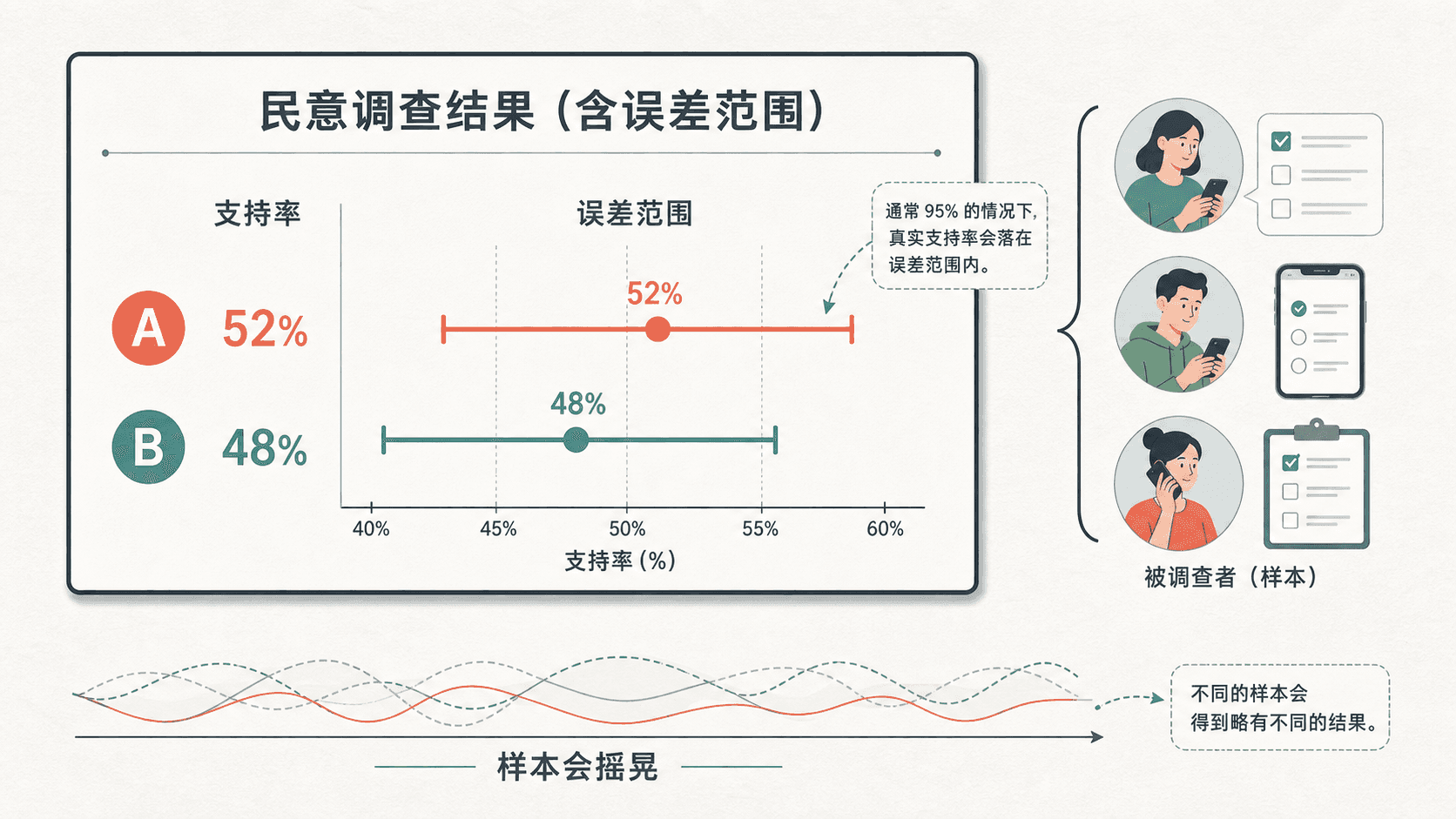
某次民调访问了 1000 名选民,结果显示方案 A 的支持率是 ,方案 B 是 。新闻标题说“A 领先”。可是如果明天换另外 1000 人,A 还一定是 吗?
一家工厂从一批 20000 个零件中抽检 400 个,发现 12 个不合格。样本不合格率是 。这是否说明整批零件的真实不合格率就是 ?
这两个问题都在问同一件事:样本只看见总体的一部分,样本结论会因为“抽到谁”而摇晃。统计推断不是假装这种摇晃不存在,而是把摇晃的大小算出来,再用区间表达不确定性。
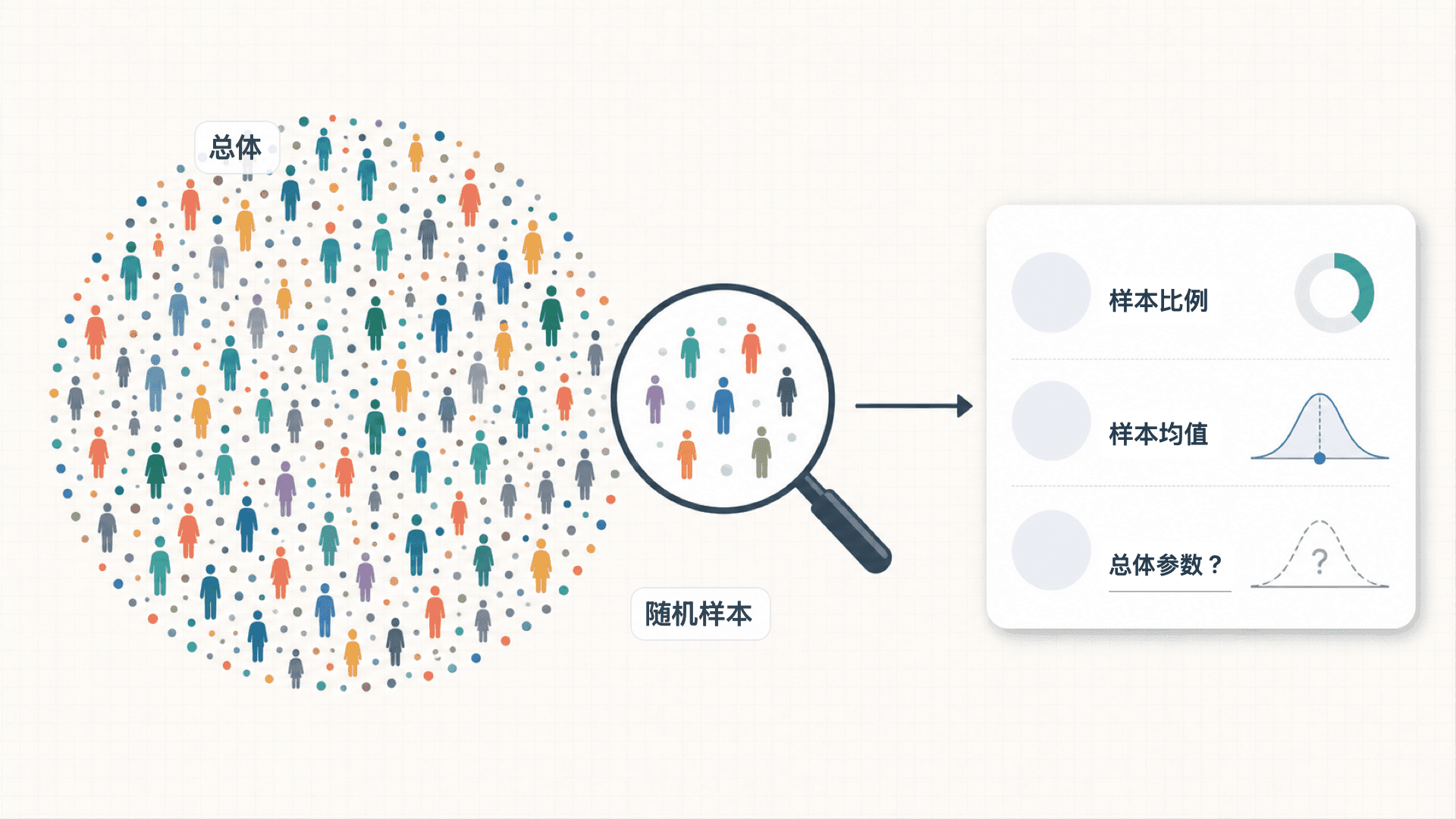
这一节只讨论最基本的一样本推断:用样本比例估计总体比例,用样本均值估计总体均值。你要抓住三句话:点估计给出一个数,标准误描述这个数会摇多大,置信区间把估计和不确定性一起报出来。
从样本统计量到总体参数
总体参数是我们真正关心但通常看不全的数。样本统计量是从样本中算出来、用来估计总体参数的数。
样本比例适合“是/否”“合格/不合格”“支持/不支持”这类变量。如果样本中有 个成功,样本量是 ,则:
样本均值适合用数值度量的变量。如果样本数据是 ,则:
点估计就是用一个样本统计量估计总体参数。它很有用,但它没有告诉我们“这个估计大概能差多少”。所以,只报 或 常常不够,还需要说明抽样误差。
例题:识别参数和统计量
某平台想估计全部活跃用户中“愿意开启新推荐功能”的比例。它随机邀请 1200 名活跃用户试用,其中 684 人选择开启。
先找总体。研究目标是全部活跃用户,所以总体是平台当前所有活跃用户,而不是被邀请的 1200 人。
再找总体参数。题目关心“愿意开启”的真实比例,这个未知比例记作 。
接着找样本统计量。样本中有 684 人开启,样本量是 1200,所以样本比例是:
最后说清楚含义。 是这一次样本给出的点估计,不是总体比例的精确值。换一批用户,样本比例可能是 、 或其他附近的数。
抽样误差:样本结论为什么会摇晃
如果抽样过程有随机性,同一个总体中反复抽样,样本统计量一般不会每次一样。样本比例会围绕总体比例上下波动,样本均值也会围绕总体均值上下波动。这种由“只抽了一部分”造成的随机差异,叫抽样误差。
抽样误差不是调查员犯错,也不是样本作假。即使名单完整、随机抽样严格、每个人都如实回答,抽样误差仍然存在。原因很简单:不同样本包含的人或产品不同。
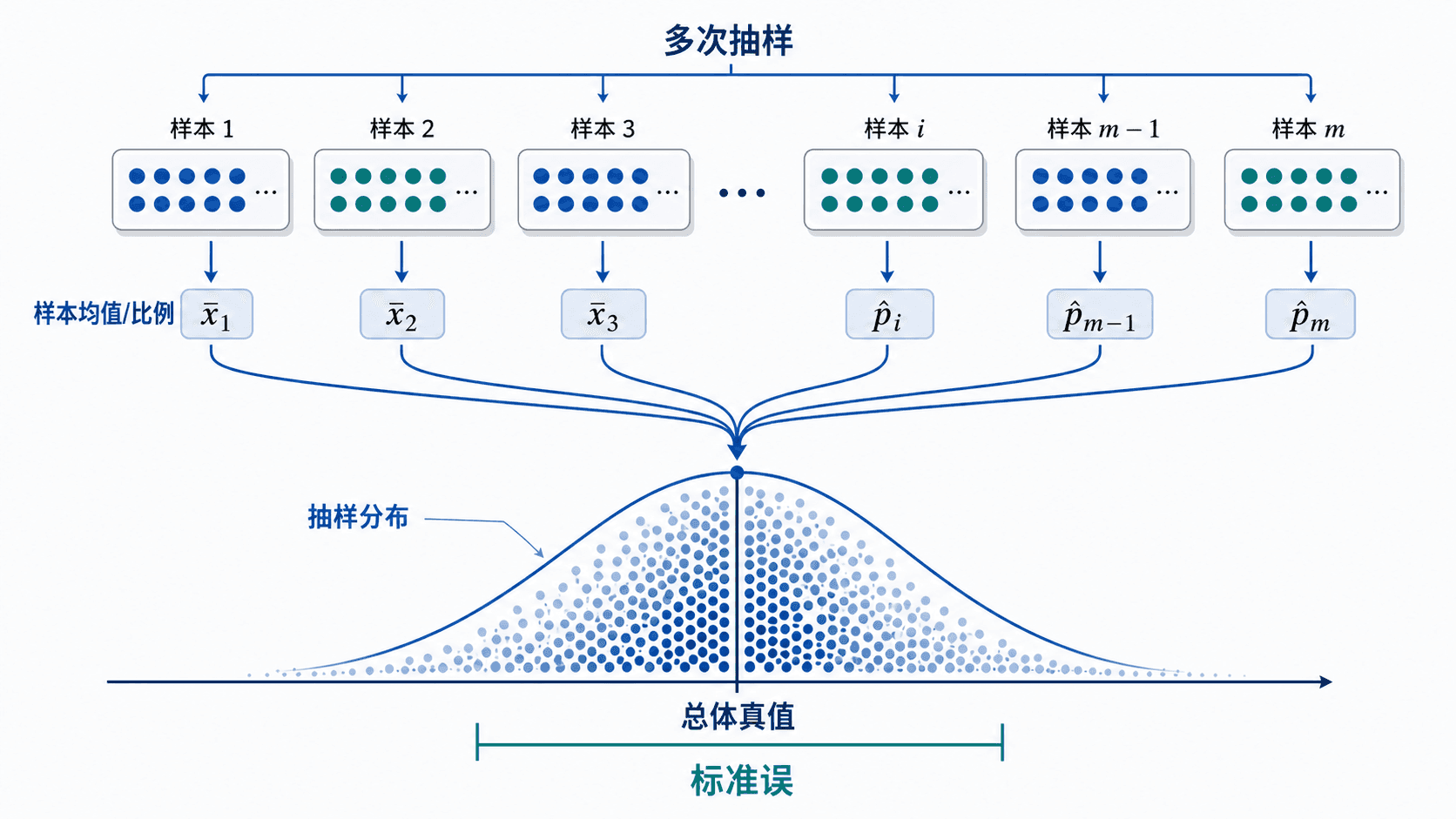
抽样分布不是原始数据的分布,而是“很多次抽样得到的统计量”的分布。它回答的是:如果重复抽很多次, 或 会怎样分散?
抽样误差和抽样偏差不是一回事。随机误差会让样本结果在真值附近摇晃;偏差会让样本系统性偏向某个方向。增加样本量通常能减小随机摇晃,但不能自动修正一个偏掉的抽样框或诱导性问卷。
抽样波动的两个直觉
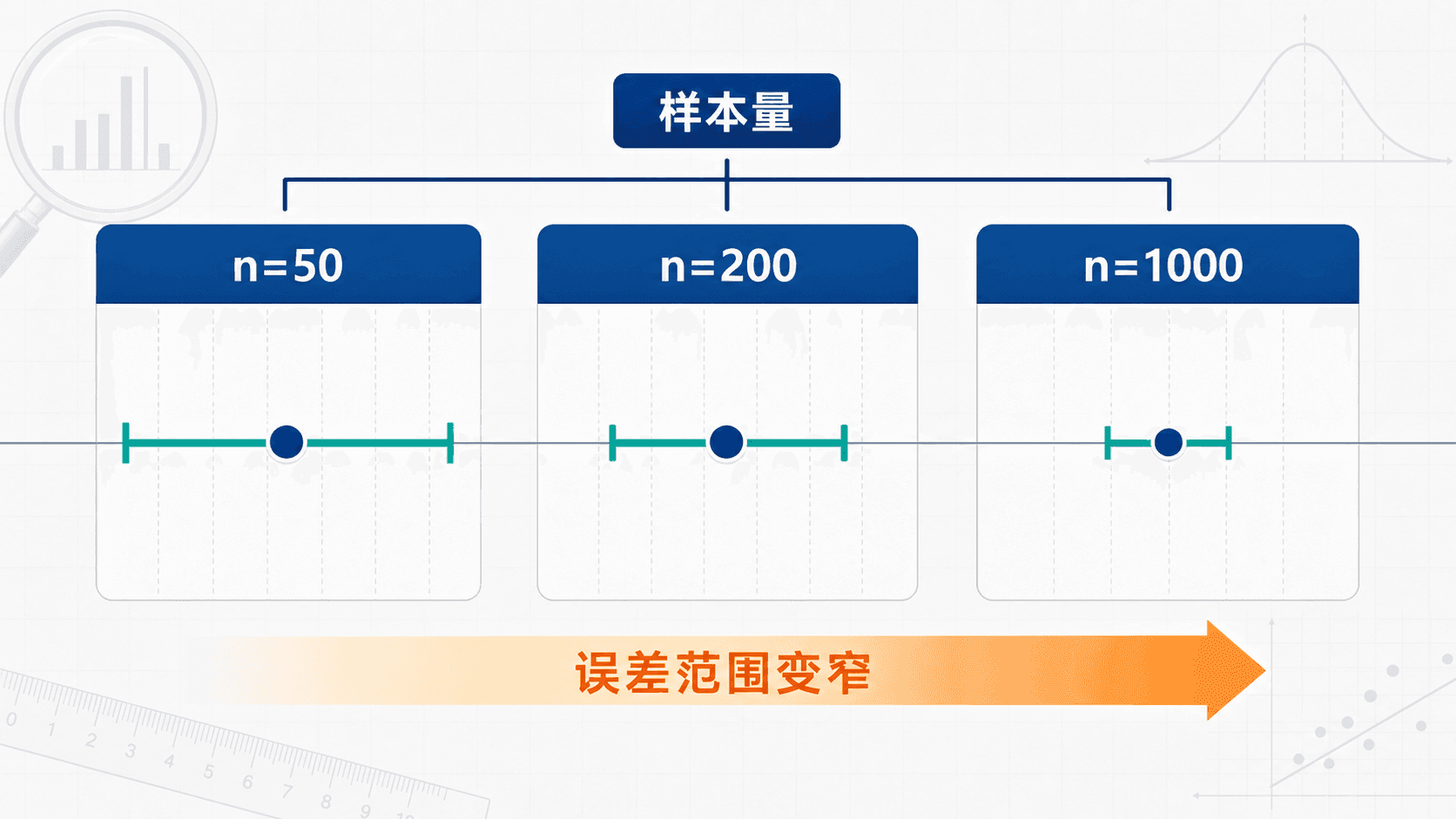
第一,样本量越大,样本统计量通常越稳。掷 10 次硬币可能有 8 次正面,掷 1000 次时正面比例通常会更靠近 。
第二,比例越接近 ,样本比例越容易摇。若总体比例是 ,大多数人都属于同一类,样本比例空间较窄;若总体比例是 ,两类差不多,样本之间的差异更明显。
标准误:把摇晃程度量出来
标准误是样本统计量的典型抽样波动大小。它和标准差有关,但对象不同:标准差描述个体数据分散;标准误描述样本统计量分散。
对于样本比例,如果总体比例是 ,理论标准误是:
实际做置信区间时, 往往未知,所以常用样本比例 代替:
对于样本均值,如果总体标准差 已知,理论标准误是:
现实里 常常未知,于是用样本标准差 估计:
这些公式里都有 。所以样本量变大时,标准误会变小;但不是 翻倍,误差就减半,而是按平方根变窄。
例题:样本比例的标准误
一次产品抽检中,从一批零件中随机抽取 个,发现 个不合格。估计不合格率的标准误。
先计算样本不合格率。样本中不合格数是 ,样本量是 :
用样本比例代入标准误公式:
计算得到:
用百分数解释。 大约是 个百分点,表示这类样本不合格率的典型抽样波动约为 个百分点。
置信区间:用一段范围表达估计
置信区间的基本形状是:
中间的乘积叫误差范围:
在入门课程里,样本量足够大时,比例的 95% 置信区间常用 作为临界值。为了心算,也常近似为 。
样本均值的置信区间通常使用 临界值,因为总体标准差一般未知:
样本量较大时,95% 置信区间里的 会接近 。样本量较小时, 通常更大,区间会更宽。
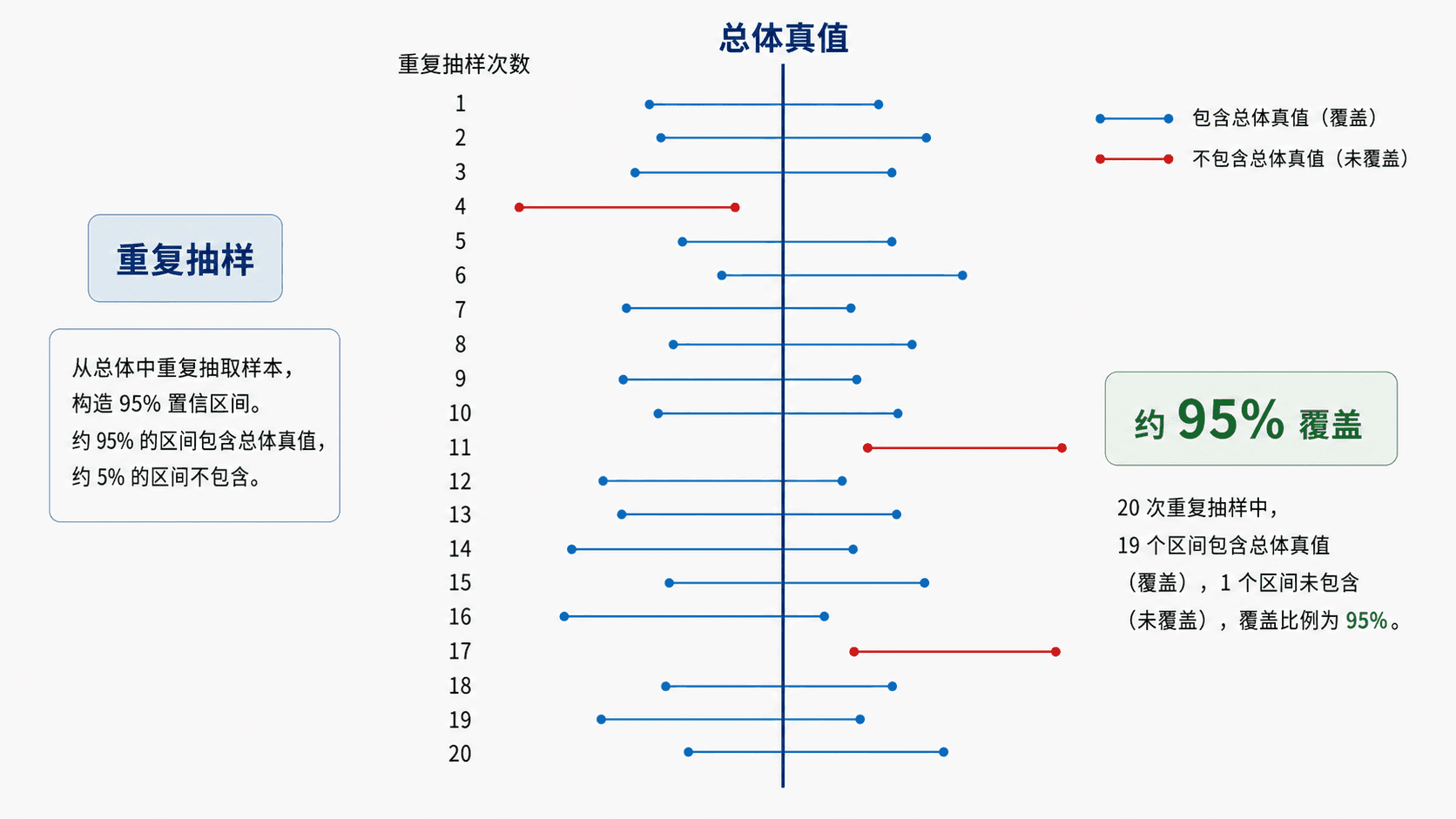
95% 置信水平说的是方法的长期表现:如果用同一种抽样和计算方法重复很多次,大约 95% 的区间会覆盖总体真值。对已经算出的某一个区间,真值要么在里面,要么不在里面。
例题:民调支持率的 95% 置信区间
某民调随机访问 名选民,其中 人支持方案 A。用近似方法给出方案 A 支持率的 95% 置信区间。
先计算样本比例:
检查成功和失败数。支持人数 ,不支持或未支持人数 ,都远大于 10,所以用正态近似较合适。
计算标准误:
计算误差范围:
写出区间:
用百分数说,方案 A 的支持率估计约为 到 。
这个区间说明 这个点估计有抽样不确定性。如果方案 B 是 ,不能只看 就断言 A 已经稳定领先。比较两方差距时,差值本身也有抽样误差,差值的误差范围通常比单个支持率的误差范围更大。
例题:平均灌装量的 95% 置信区间
某饮料厂随机抽取 瓶饮料,样本平均灌装量为 ml,样本标准差为 ml。估计该生产线的平均灌装量。假设可用 。
题目关心的是总体均值 ,点估计是样本均值 。
计算样本均值的标准误:
计算误差范围:
写出置信区间:
用情境解释。我们可以说:根据这次抽样,该生产线的平均灌装量大约在 ml 到 ml 之间。
民调和抽检:区间比单点更诚实
民调中的“误差范围”常常就是置信区间半宽。若某候选人的支持率是 个百分点,意思不是支持率会在明天自动落入这个范围,而是这次样本给出的估计精度大约只有这么细。小于误差范围的差距,需要谨慎解读。
还有几个细节很容易被忽略。第一,整体样本的误差范围不等于每个子群体的误差范围。1000 人样本中如果只有 160 名年轻受访者,年轻人子样本的误差范围会明显更宽。第二,民调误差范围主要描述抽样误差,不自动包括问题措辞、未回应、加权、可能选民模型等误差。第三,两个民调之间从 到 的变化,可能只是抽样波动,也可能是真变化,需要看更多连续结果。

产品抽检也一样。抽到 个零件,其中 个不合格,点估计是 。用 95% 近似区间计算:
误差范围约为:
所以区间约为:
也就是 到 。这个范围比单独的 更适合拿去讨论风险。如果合同规定不合格率必须低于 ,这次抽检结果就不能让人完全放心,因为区间中有不少值高于 。
区间不是为了让结论变含糊,而是为了让结论和证据强度匹配。样本给出的信息强,区间会窄;样本给出的信息弱,区间会宽。
常见误区辨析
误区一:样本比例就是总体比例
样本比例是估计值,不是总体真值。样本越大,估计通常越稳,但只要不是普查,就仍有抽样波动。
误区二:95% 置信区间表示这个区间有 95% 概率含真值
在常见的频率学派表述中,总体参数是固定未知数;随机的是抽样过程和由样本算出的区间。一个具体区间算出来以后,它是否覆盖真值已经是事实,只是我们不知道。
误区三:置信区间越宽越差
宽区间不是“算坏了”的同义词。它可能诚实反映了样本量小、数据分散或置信水平高。真正危险的是证据很弱却报得很精确。
误区四:样本量占总体比例越高,结果一定越准
很多大总体问题里,关键常常是样本的绝对数量和抽样方式,而不是样本占总体的百分比。对几千万选民做随机样本,1000 人已经能给出有用估计;但如果样本来自自愿投票,再多也可能偏。
误区五:误差范围包括所有错误
常规误差范围主要量化随机抽样误差。抽样框漏掉某些人、问题带引导性、受访者不愿回答、测量仪器校准错误,这些都可能造成非抽样误差,不能靠公式自动消失。
不要把“区间里有我要的值”当成“已经证明我要的值正确”。置信区间给的是与样本相容的一段范围,它帮助我们判断证据强弱,不替代研究设计和背景判断。
练习
练习 1:样本比例与置信区间
某学校随机调查 名学生,发现 人每周至少运动三次。请计算样本比例,并用 近似给出 95% 置信区间。
样本比例为:
标准误为:
误差范围为:
所以 95% 置信区间约为:
也就是约 到 。
练习 2:样本均值的标准误
某平台抽取 名用户,记录他们一天使用某功能的次数。样本均值为 次,样本标准差为 次。请计算样本均值的标准误,并用 给出近似 95% 置信区间。
样本均值的标准误为:
误差范围为:
置信区间为:
可以解释为:根据这次抽样,全部同类用户一天使用该功能的平均次数大约在 到 次之间。
练习 3:样本量如何影响误差范围
假设一个比例问题中,样本比例接近 。样本量从 增加到 ,95% 置信区间的误差范围大约会怎样变化?
比例标准误近似为:
当 接近 时,分子基本不变,标准误主要按 变化。样本量从 到 ,变为原来的 倍,因此标准误和误差范围大约变为原来的:
也就是误差范围大约减半。注意,这不是因为样本量增加了 ,而是因为样本量变成了 倍。
练习 4:判断民调说法
某民调显示甲候选人支持率 ,乙候选人支持率 ,报告给出的单个支持率误差范围是 个百分点。有人说:“甲领先 4 个百分点,超过 3 个百分点,所以甲已经稳胜。”这句话哪里需要谨慎?
需要谨慎的地方有两个。第一,单个支持率的误差范围不是两人差距的误差范围;差距的误差范围通常更大。第二,民调误差范围主要描述抽样误差,不包括所有非抽样误差。甲领先 4 个百分点说明样本中甲较高,但不能只凭“4 大于 3”就断定稳胜。更稳妥的做法是看差距的置信区间、多个民调的趋势和调查方法。
练习 5:抽检结论
某批产品抽检 件,发现 件不合格。有人说:“样本不合格率是 ,所以整批产品没有不合格品。”这句话为什么不对?
抽检没有发现不合格品,只能说明这 件样本中没有不合格品,不能证明整批产品的不合格率就是 。如果真实不合格率很低,随机抽 100 件没有抽到不合格品是可能的。样本量、抽样方式和可接受风险都要一起考虑。这里尤其不能用普通正态近似公式机械计算,因为成功或失败数太少,不满足至少若干个成功和失败的近似条件。