随机变量与常见分布
你已经会用条件概率描述“知道新信息后,概率怎样改变”。这一节往前走一步:如果随机结果本身不是一个数字,我们先把它翻译成数字,再观察这些数字会怎样出现。
比如一次投篮可能进也可能不进,一封邮件可能被点击也可能没有被点击,一次通勤可能花 18 分钟也可能花 42 分钟。随机变量做的事,就是给这些结果安排一个数值;分布做的事,是说明这些数值各自有多可能。
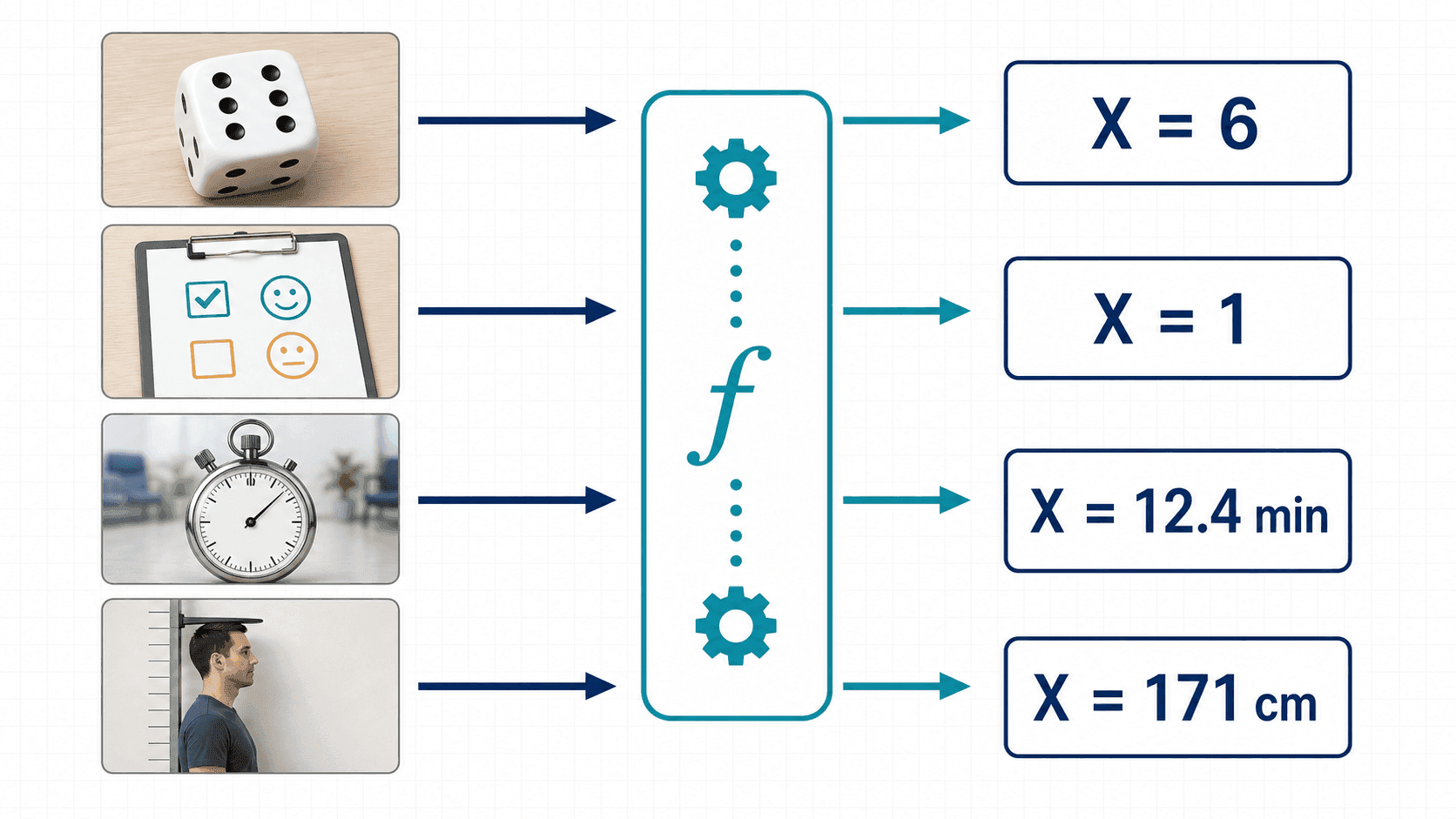
从一个问题开始
一家咖啡店想估计“上午 8 点到 9 点之间,排队顾客会等多久”。店长不只关心某一天的等待时间,而是关心等待时间作为一个随机量的整体规律:大多数时候接近几分钟?偶尔会不会特别久?如果多开一台收银机,等待时间的波动会不会变小?
这里有三个层次:
- 随机现象:每位顾客到店后会遇到不同队伍。
- 随机变量:用 表示一位顾客的等待时间,单位是分钟。
- 分布:说明 可能取哪些值,以及这些值出现的概率怎样分布。
随机变量不是“会随机变化的字母”,而是一个规则:它把随机结果转成数字。只有变成数字以后,我们才方便比较中心、波动和极端情况。
这句话听起来抽象,但它解决了一个真实问题:现实世界的结果常常不是天生可算的。一次检测是阳性还是阴性,一次广告是否转化,一次设备是否故障,这些都可以先翻译成 1 或 0;等待时间、身高、误差、收入则本来就是数值。
随机变量:把随机结果翻译成数
如果一次随机试验的结果记作 ,随机变量 会给每个结果分配一个数 。入门阶段不需要纠结这个符号,只要抓住“结果到数字”的映射。
随机变量常分成两类。
离散随机变量可以直接问 。连续随机变量通常不能问“刚好等于某个值”的概率,因为精确到无限小数的某一点概率通常是 0;我们更常问 这样的区间概率。
连续随机变量的曲线高度不是概率。概率对应的是曲线下的一段面积,所以“落在某个区间里”才是更自然的问题。
概率分布在说什么
对离散随机变量,分布可以写成表格。假设 是一次售后电话的满意评分,可能值是 1、2、3、4、5,每个值对应一个概率。所有概率加起来必须是 1。
对连续随机变量,分布常用曲线描述。曲线下总面积是 1,某个区间下面积就是落入该区间的概率。
例题:把情境改写成随机变量
一家网站记录“一个访客是否完成注册”。如果完成注册记为 1,未完成记为 0。设 表示一次访问的注册结果。
先找随机现象。这里的随机现象是“一位访客来到网站后,是否完成注册”,结果有完成和未完成两种。
再规定数值翻译。完成注册记为 ,未完成注册记为 ,这样非数字结果就变成了可以计算的随机变量。
最后判断变量类型。 只能取 0 和 1,是离散随机变量;如果完成注册的概率是 ,那么这个 就适合用伯努利分布描述。
期望与方差:中心和分散
分布告诉我们“哪些值会出现、各有多可能”。接下来最自然的两个问题是:长期看,中心大约在哪里?这些值离中心有多散?
期望回答第一个问题。对离散随机变量,期望是所有可能值按概率加权后的平均。
这里的 是可能取到的值, 是取到这个值的概率。期望不是预测下一次一定会出现什么,而是描述很多次重复以后平均会靠近哪里。
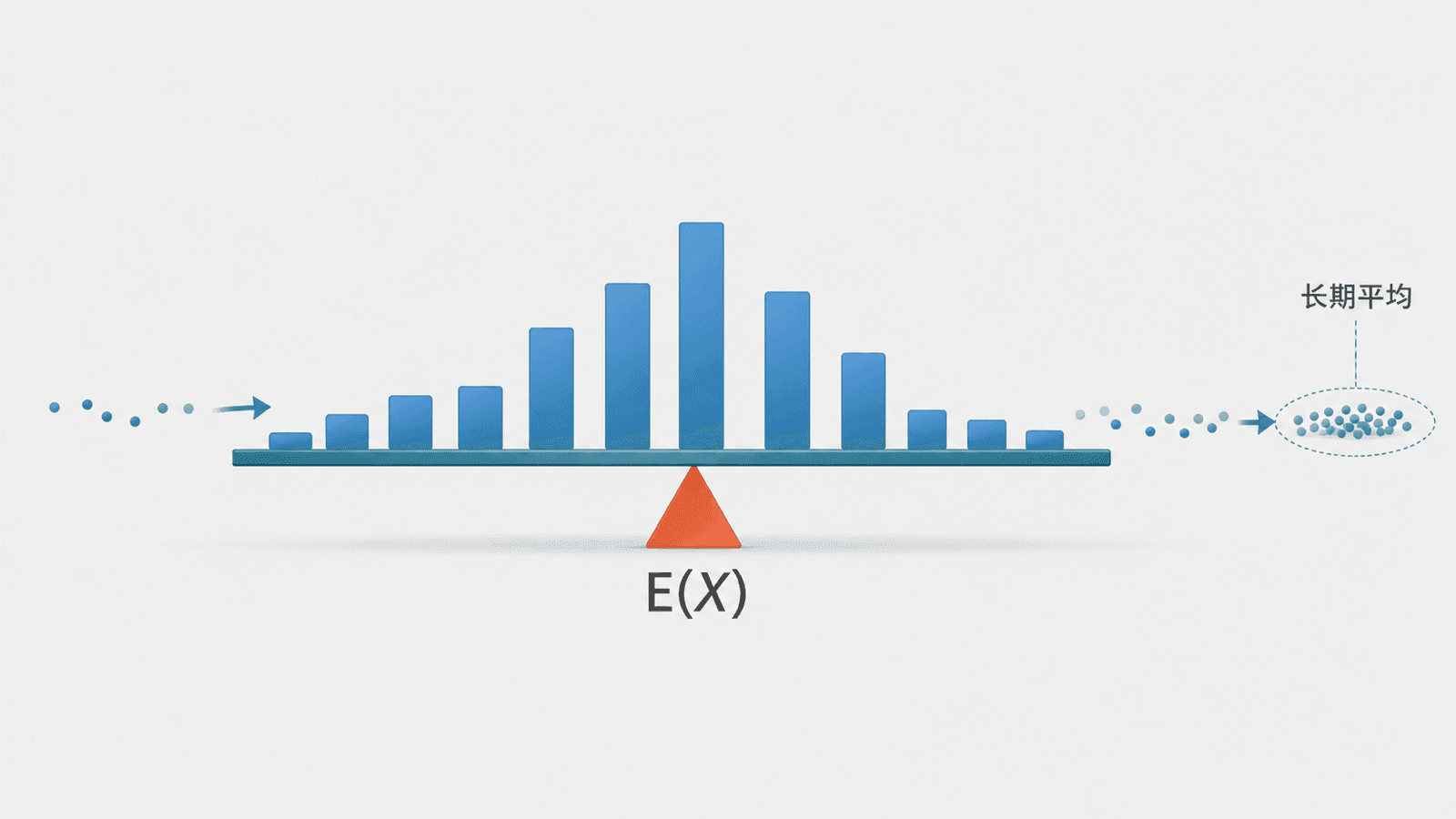
方差回答第二个问题。它把每个值离期望的距离平方后,再按概率平均。
其中 。标准差是方差的平方根,单位会回到原来的单位,所以解释时通常比方差更直观。
例题:两种通勤方案怎么比
方案 A 每天都比较稳定: 可能是 20、25、30 分钟,概率分别是 0.25、0.50、0.25。方案 B 大多数时候快,但偶尔严重堵车: 可能是 15、25、45 分钟,概率分别是 0.45、0.45、0.10。
先算期望:
方案 B 的平均时间更短,但它有 10% 的概率到 45 分钟。如果你不能迟到,方差和极端值就很重要;如果你只关心长期平均,方案 B 可能更有吸引力。
期望和方差常常要一起看。期望像“长期中心”,方差像“围绕中心摇晃的幅度”。只看期望,容易忽略风险;只看方差,又可能忘了整体水平。
常见误区
- 误区一:期望一定是可能出现的值。掷一枚公平硬币,把正面记为 1、反面记为 0,期望是 0.5,但一次结果不会出现 0.5。
- 误区二:方差越小就一定越好。考试成绩、机器误差、通勤时间里,小波动通常让人安心;但投资收益、创作传播等场景中,较大波动可能意味着更高机会,也可能意味着更高风险。
- 误区三:同一个平均数说明两组数据差不多。两组数据可以有相同均值,却一组很集中,另一组很分散。
伯努利分布:一次是或否
伯努利分布描述一次只有两种结果的试验。我们把“成功”记为 1,把“失败”记为 0。这里的成功不一定带有好坏含义,只是你关心的事件发生了。
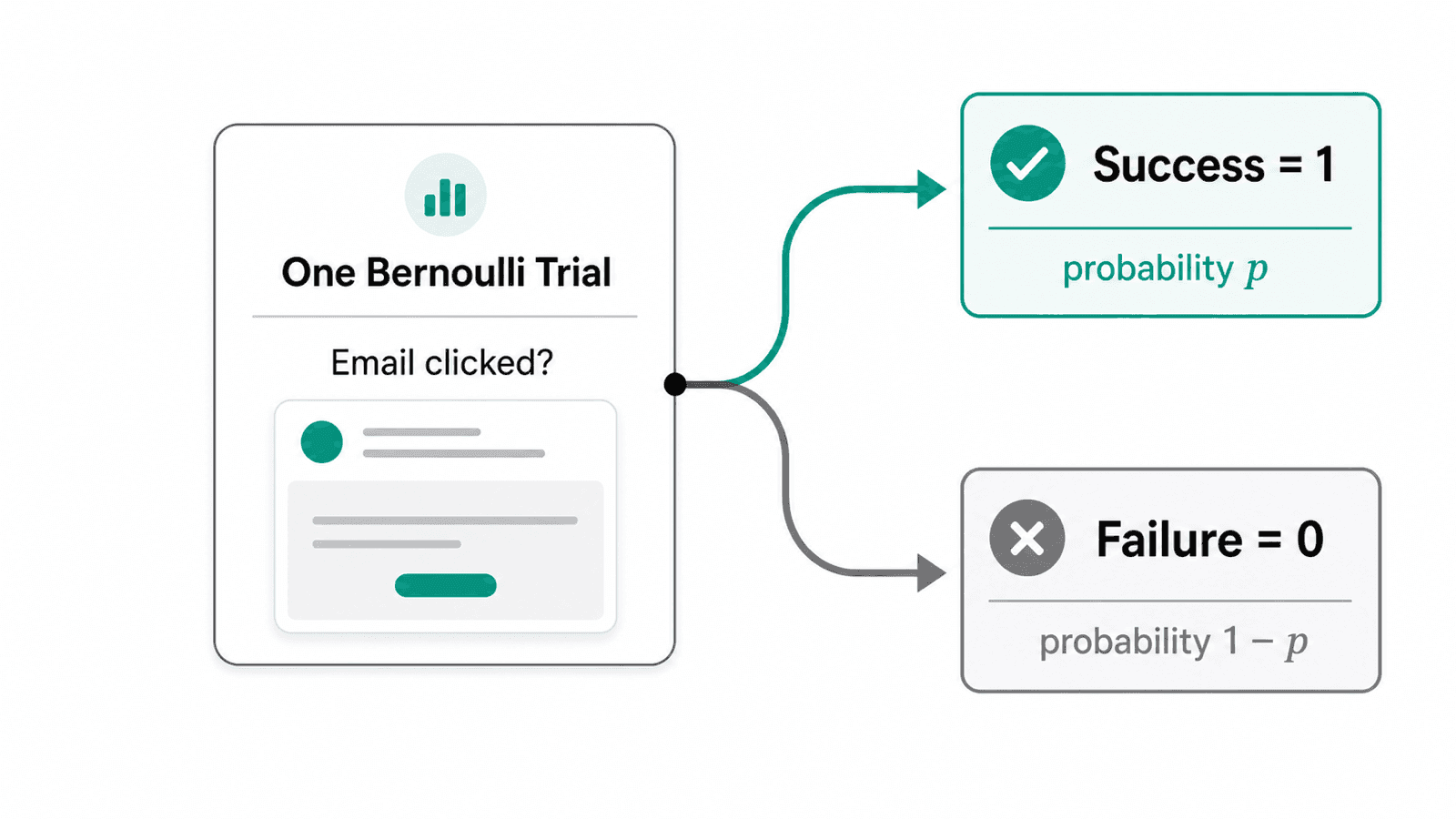
如果 服从参数为 的伯努利分布,意思是:
它的期望和方差是:
这些公式有很好的直觉。把发生记为 1、不发生记为 0,长期平均自然会接近发生比例 。
适合描述什么
伯努利分布适合一次试验、两种结果的情境:
- 一件产品是否合格。
- 一位用户是否点击。
- 一名学生是否答对某道判断题。
- 一次检测是否呈阳性。
伯努利分布只描述“一次”。如果你关心 100 位用户中有多少人点击,那已经不是单个伯努利变量,而是多个伯努利试验的成功次数,通常会走向二项分布。
二项分布:固定次数里的成功个数
二项分布描述的是:重复做 次相同的伯努利试验,每次成功概率都是 ,并且各次试验相互独立。随机变量 记录成功的次数。
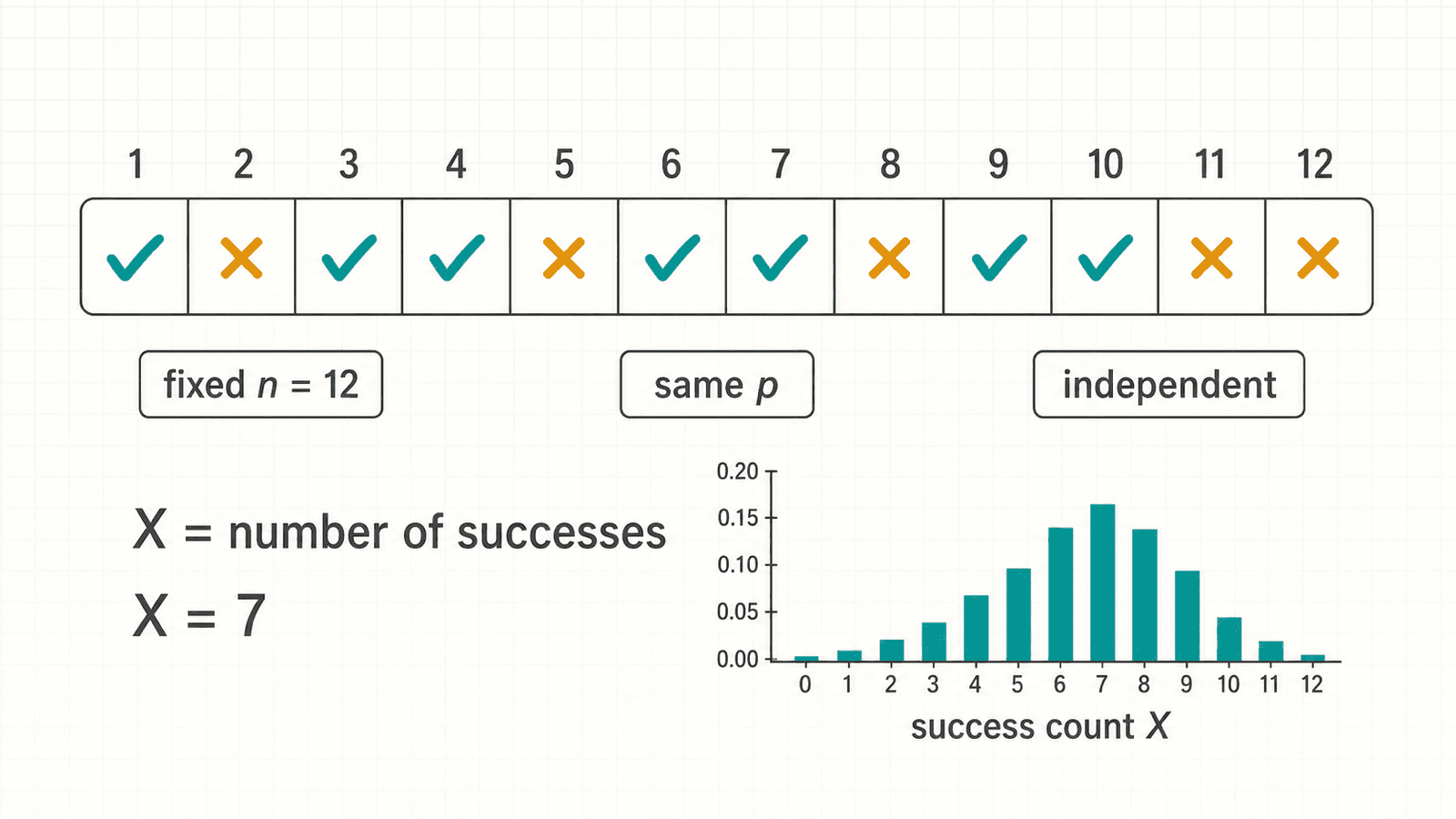
记作:
刚好成功 次的概率是:
这个式子由三部分组成:选出哪 次成功,成功的概率乘起来,失败的概率乘起来。
例题:抽检中缺陷件的个数
某工厂生产的零件中,每件有 2% 的概率存在缺陷。质检员随机抽检 20 件。设 表示其中缺陷件的个数。假设每件是否有缺陷可以近似看作独立。
先判断试验结构。每件零件只有“有缺陷”和“无缺陷”两种结果,可以把有缺陷记为成功。
再确认二项分布条件。抽检件数固定为 ,每件缺陷概率近似相同为 ,题目允许把不同零件近似看作独立。
因此 。如果要求“恰好 1 件有缺陷”,代入公式得到:
计算时先理解数量级。平均缺陷件数是 ,所以 0 件或 1 件较常见,很多件缺陷会很少见。
二项分布的三个检查点
使用二项分布前,先问三个问题:
二项分布最常见的误用,是只看到“成功次数”就直接套公式,却忘了检查独立性和相同成功概率。比如从很小的一批产品里不放回抽样,每抽走一件都会改变剩余组成,这时要谨慎。
均匀分布:区间内同等可能
均匀分布描述一种连续情境:在某个区间内,没有哪个等长小段更特殊。若 在 到 之间均匀分布,记作:
它的密度是平的:

“平”不表示每个具体数值有相同的正概率。连续分布里单个点的概率仍然通常是 0。均匀分布真正表达的是:区间长度相同,概率相同。
适合描述什么
均匀分布适合在一个范围内没有额外偏好的情境:
- 计算机生成 0 到 1 之间的随机数。
- 一个活动在 10:00 到 10:30 的任意时刻随机开始。
- 在一条长度为 1 米的线段上随机选一个位置。
- 初步建模时,把未知但有范围的误差先看成区间内同等可能。
现实数据很少因为“看起来在一个范围内”就自动均匀。均匀分布需要“等长区间同样可能”的理由,而不只是知道最大值和最小值。
正态分布:许多小影响叠加后的连续变化
正态分布也叫钟形分布。它常用来描述连续变量:多数值靠近中心,离中心越远越少见,并且左右大致对称。
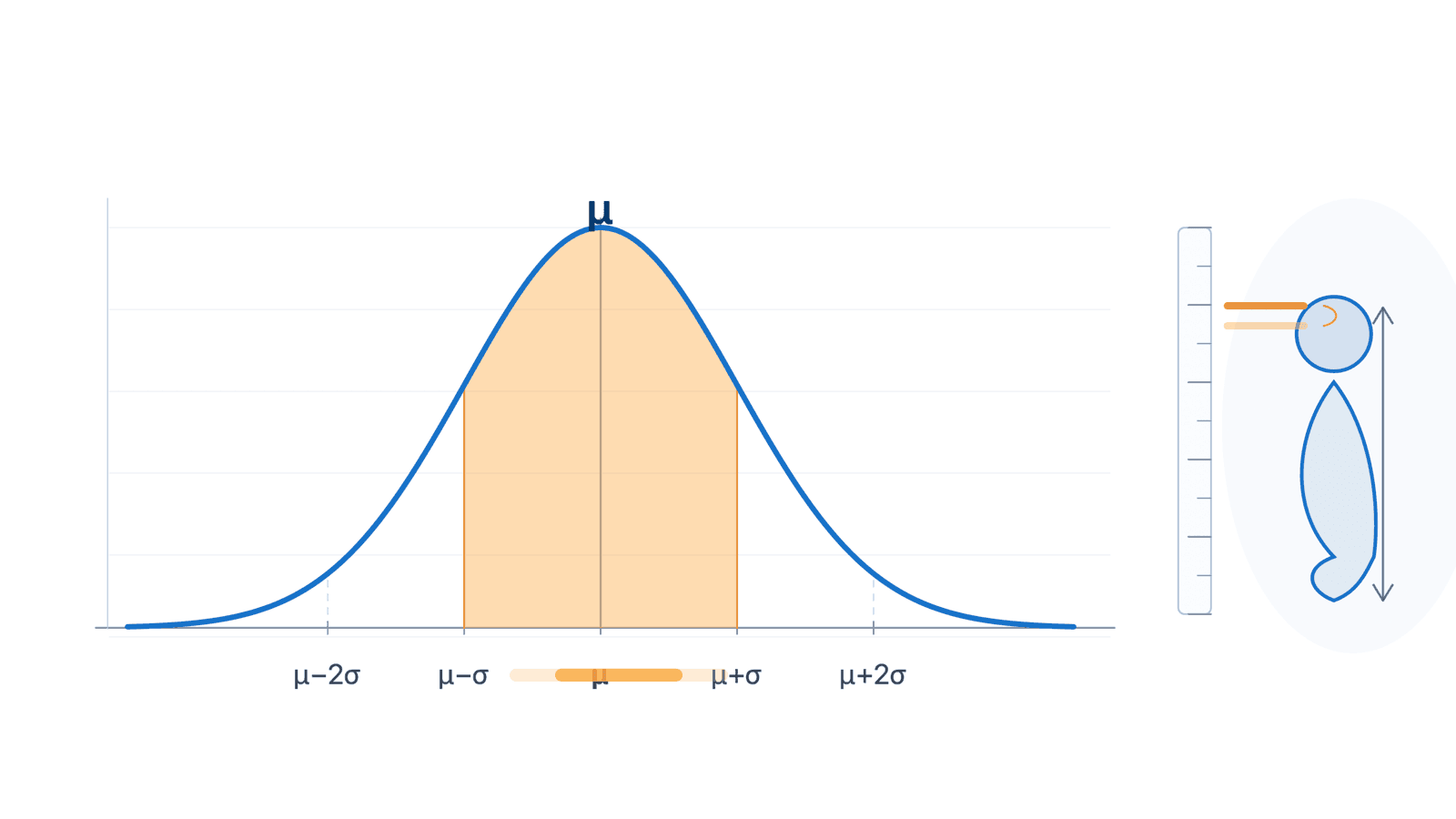
如果 服从均值为 、标准差为 的正态分布,记作:
均值 决定曲线中心,标准差 决定曲线宽窄。标准差越大,曲线越扁越宽;标准差越小,曲线越高越窄。
为什么正态分布常见
正态分布常出现在“许多小影响叠加”的情境中。一个人的身高受遗传、营养、环境和测量误差等因素影响;一次测量误差可能由仪器、读数、温度和操作细节共同造成。当每个影响都不独占全局时,总体形状常会接近钟形。
这并不表示所有数据都是正态的。收入、等待时间、城市人口、网页停留时长常常明显偏斜;考试分数也可能因为题目太简单、太难或分层明显而不近似正态。
区间概率与标准化
正态分布的问题常常问“落在某个区间里的概率”。如果要把不同正态分布放在同一把尺子上,可以用标准化:
标准化后的 表示某个值离均值有多少个标准差。比如 表示比均值高 2 个标准差。
正态曲线中,概率是面积。某一点的曲线高度可以帮助比较“附近密不密”,但它本身不是 。
如何选择分布
选择分布时,先不要从公式出发,而要从随机机制出发。下面这张图可以当作第一轮筛选。
一个简短决策流程
先问结果是不是数值。如果不是,先规定怎样把结果翻译成数字,例如把发生记为 1、不发生记为 0。
再判断取值是离散还是连续。成功次数、缺陷件数量是离散的;等待时间、身高、误差通常是连续的。
接着看随机机制。一次是或否用伯努利;固定次数的成功个数用二项;区间内等长等概率用均匀;许多小影响叠加且大致对称时考虑正态。
最后检查条件。分布是模型,不是标签。条件不满足时,可以把它当近似,但要知道近似在哪里可能失效。
好的分布选择,通常不是“这个公式我会用”,而是“这个随机机制和题目真的相像”。先看机制,再算概率。
练习
练习 1:随机变量是什么类型
判断下列随机变量是离散还是连续,并说明理由。
- 一天内客服中心接到的投诉数量。
- 一位顾客从进店到结账的等待时间。
- 20 道选择题中答对的题数。
- 随机抽取一台机器,记录它的运行噪声分贝值。
1 和 3 是离散随机变量,因为它们是可以数出来的个数,只能取 0、1、2 这样的分开数值。2 和 4 是连续随机变量,因为等待时间和分贝值在测量上可以落在一个区间里的许多位置。
练习 2:应该用哪种分布
为下列情境选择伯努利分布、二项分布、均匀分布或正态分布中较合适的一种,并说出关键理由。
- 一封促销邮件是否被某位用户打开。
- 随机数生成器产生 0 到 1 之间的一个数。
- 在 50 件独立生产的零件中,有多少件通过最终检测。
- 同一把尺子反复测量同一物体长度时产生的小误差。
1 适合伯努利分布,因为只有打开和未打开两种结果。2 适合均匀分布,因为理想随机数生成器应让 0 到 1 内等长区间同样可能。3 适合二项分布,但要假设 50 件的检测结果近似独立且通过概率相同。4 常用正态分布近似,因为测量误差通常由许多小因素共同造成,并围绕 0 附近波动。
练习 3:二项分布计算
某 App 的新用户有 30% 的概率在第一天完成一次分享。随机观察 8 位新用户,设 表示完成分享的人数。求 的表达式,并解释 、、 分别是什么。
这里可以把“完成分享”记为成功。观察人数固定为 ,每位用户成功概率为 ,题目要求恰好 3 人成功,所以 。若近似认为不同用户相互独立,则 。
练习 4:期望不是下一次结果
一枚不均匀硬币正面概率是 0.6。正面记为 1,反面记为 0。求 ,并说明为什么它不是“下一次会出现 0.6”。
因为 只可能取 1 或 0,所以:
这个 0.6 表示长期重复抛很多次后,0 和 1 的平均值会接近 0.6。单次抛硬币的结果仍然只能是 1 或 0,不会出现 0.6。
练习 5:识别误用
有人说:“这批顾客等待时间在 0 到 20 分钟之间,所以它服从均匀分布。”这句话哪里不够严谨?
只知道取值范围还不够。均匀分布要求等长区间概率相同,例如 0 到 5 分钟、5 到 10 分钟、10 到 15 分钟、15 到 20 分钟这些区间应有相同概率。现实排队时间常常短等待更常见、长等待更少见,所以需要数据或机制支持,不能只凭最大值和最小值判断。