显著性检验:差异是真的,还是偶然的
我们已经学过样本、图表、概率模型、抽样误差和置信区间。现在把这些线索合在一起,回答一个现实问题:当两个结果看起来不一样时,这个差异是真的,还是样本随机波动碰巧造成的?

显著性检验不是替我们做决定,而是先问:如果其实没有差异,这样的结果有多意外?
引入问题:差异能不能只靠眼睛判断
一家学习网站把报名按钮从蓝色改成绿色。A 版本有 10000 名访客,其中 610 人报名;B 版本也有 10000 名访客,其中 680 人报名。
如果只看数字,B 版本多了 70 个报名,看起来更好。但我们已经知道,样本会波动。就算两个按钮真的一样好,两组各来 10000 人,也不一定正好得到相同的报名人数。
显著性检验就是为这种判断建立一套流程。它不问“我希望哪个版本赢”,而是先假装没有真实差异,再看眼前结果在这个假设下有多罕见。
显著性检验的核心问题不是“样本里有没有差异”。样本里几乎总会有差异。真正的问题是:这个差异大到什么程度,才不太像普通抽样波动?
在这章里,我们会用两个贯穿例子:网页 A/B 测试和药物实验。它们一个来自产品决策,一个来自医学研究,但背后的统计逻辑很相似:先提出假设,再用样本数据衡量“随机波动能解释到哪里”。
从零假设开始
显著性检验总是从一对假设开始。它们不是随便写的口号,而是把研究问题翻译成可以被数据挑战的数学说法。
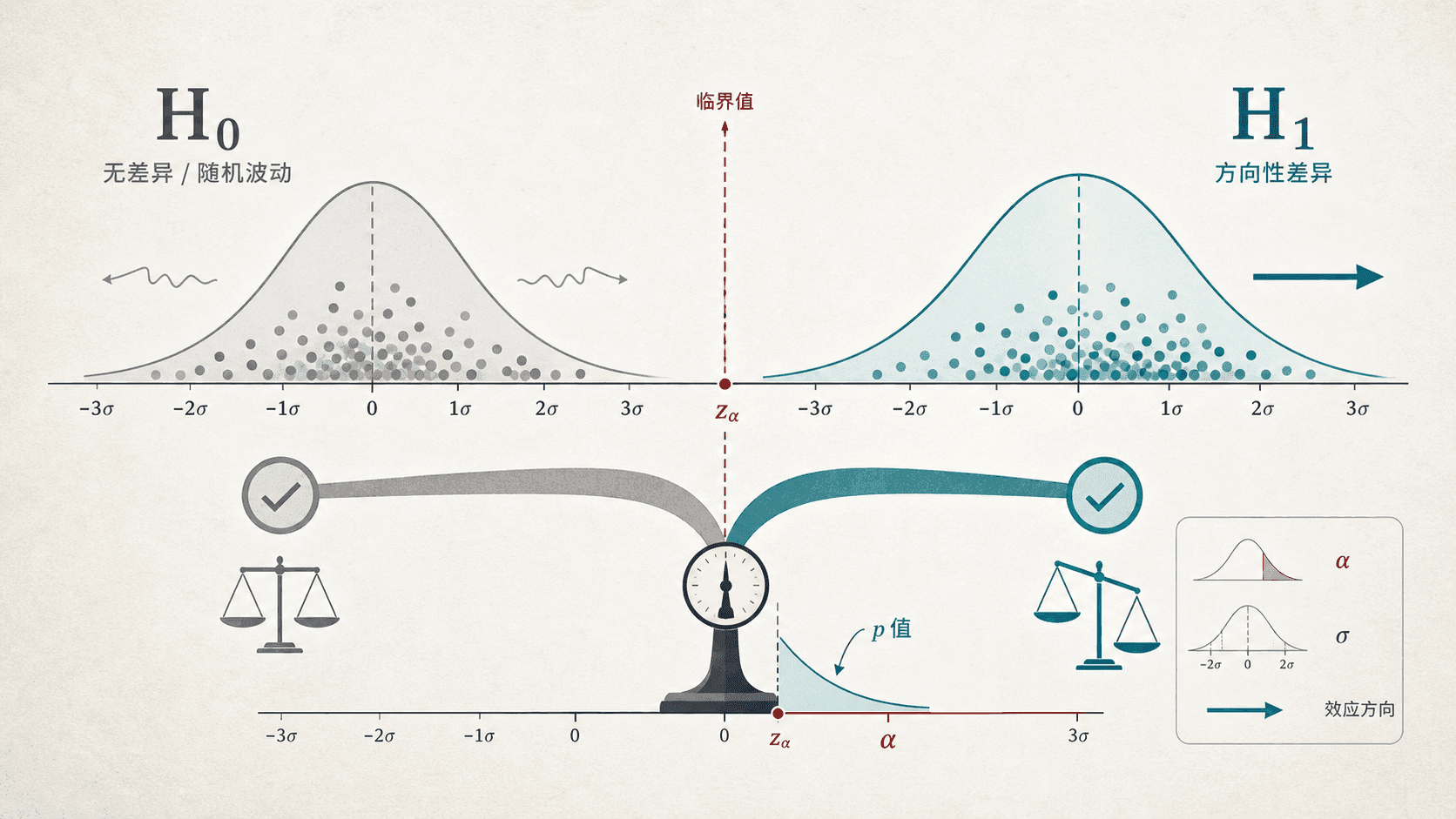
零假设
零假设通常记作 。它是检验时先暂时采用的基线说法,常见形式是“没有差异”“没有效果”“没有变化”。
在 A/B 测试里,零假设可以写成:
这里的 和 是两个版本在总体中的真实转化率。零假设说:两个版本真实转化率相同,样本里的差别只是随机分组和随机访问造成的。
在药物实验里,如果比较药物组和安慰剂组的改善率,零假设可以写成:
这不是说研究者真的相信药物没用,而是先拿“没有效果”当作需要被数据推翻的基线。
备择假设
备择假设通常记作 或 。它表达研究者想寻找的差异或效果。
如果我们只关心两个版本是否不同,可以写成双侧备择假设:
如果实验前就明确只关心 B 是否更高,可以写成单侧备择假设:
双侧和单侧不能等看完数据后再挑。因为它们决定了“更极端结果”怎么计算,也会改变 p 值。
检验规则要在看最终结果前确定。先看数据,再决定做单侧还是双侧,就像射箭后再画靶心,会让结果显得比实际更有说服力。
检验不是证明
显著性检验的语言很谨慎:当结果足够罕见时,我们说“拒绝零假设”;当结果不够罕见时,我们说“不能拒绝零假设”。
这两个说法都不是证明。拒绝 不等于 一定为真;不能拒绝 也不等于 一定为真。检验给的是证据强弱,不是最终审判。
p 值:在零假设世界里的尾部面积
p 值是显著性检验中最容易被误解的数。它的定义可以先用一句话抓住:
在零假设成立的前提下,p 值是得到当前这么极端或更极端结果的概率。
这句话里最重要的是前半句:在零假设成立的前提下。p 值不是在问“零假设有多可能为真”,而是在问“如果零假设为真,数据这样极端有多意外”。
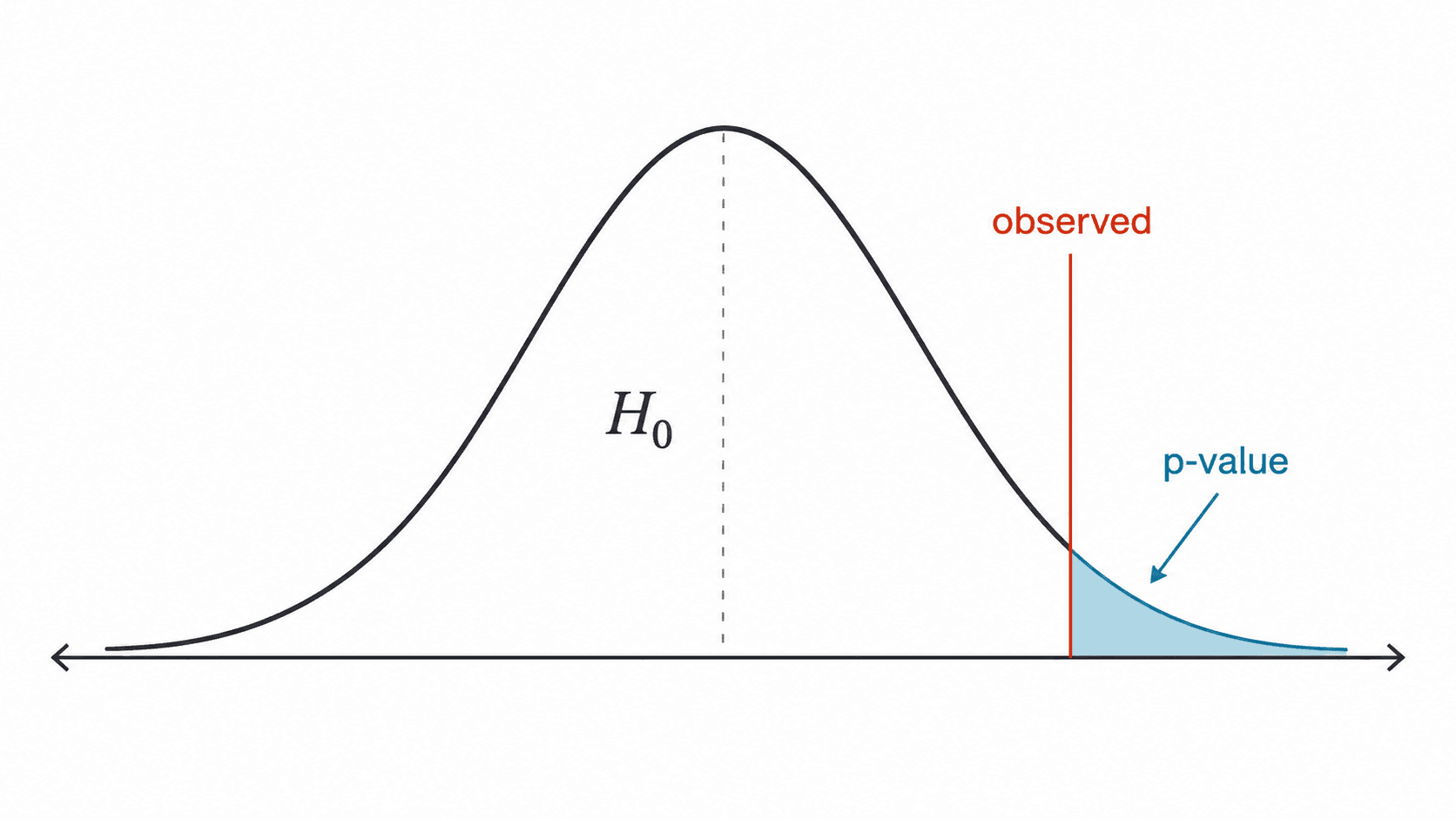
假设某个检验算出 。比较准确的读法是:
如果零假设真的成立,像现在这样极端或更极端的样本结果,大约有 3% 的概率出现。
这不等于“零假设有 3% 的概率是真的”。这两个条件方向完全不同:
和
不是同一个问题。前者是 p 值,后者需要额外的先验信息和建模假设,本章不把它当作显著性检验的输出。
一个硬币直觉
假设有人声称自己能预判硬币正反。你让他猜 10 次,他全猜对了。
如果零假设是“他只是随机猜”,那么全猜对的概率是:
这个结果在随机猜的世界里很罕见,所以你会开始怀疑零假设。但它仍然不是证明。也许他真的有技巧,也许硬币有问题,也许记录过程出了错。统计检验先指出“这件事不寻常”,后面的解释仍要靠实验设计和背景知识。
显著性水平:先画线,再看数据
显著性水平通常记作 。它是研究者在检验前定下的阈值:如果零假设是真的,我们愿意承担多大概率错误地拒绝它。
常见选择是:
当 时,我们说结果在这个显著性水平下“统计显著”,并拒绝零假设。当 时,我们不能拒绝零假设。
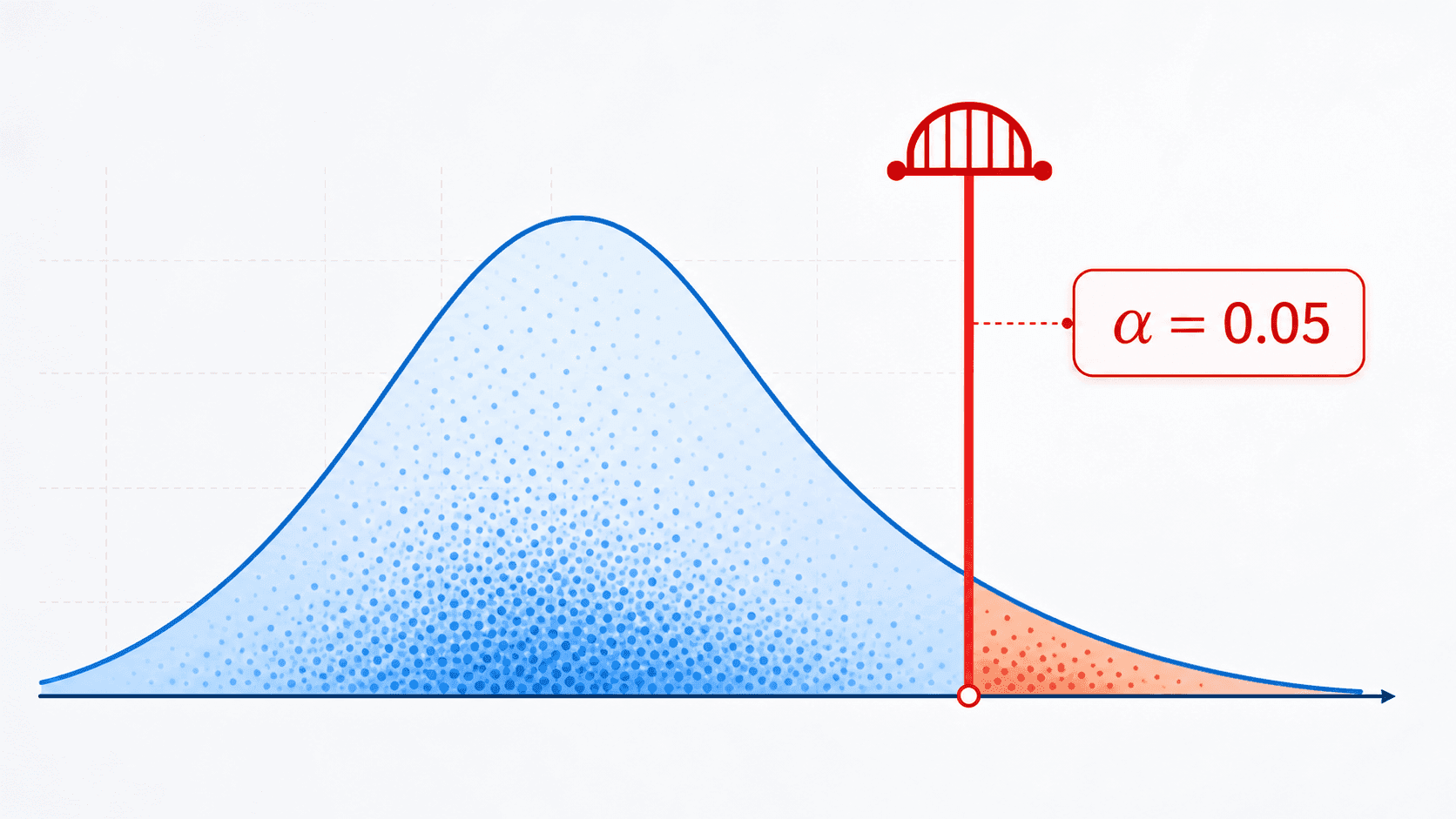
把 想成赛前画好的线会更自然。你不能看完比赛成绩再移动终点线。 的含义也不是“我们有 95% 把握备择假设为真”,而是在零假设成立时,长期重复使用这条规则,大约 5% 的检验会因为随机波动而误报。
两类错误
显著性检验会犯错,因为样本有随机性。
降低 可以减少第一类错误,但会让真正存在的小差异更难被发现。增加样本量通常能同时让检验更稳定,但样本量本身不解决研究设计偏差、数据质量和实际意义问题。
显著性水平是规则,不是自然定律。医学、安全和公共政策中,错误代价很高,阈值可能要更严格;早期探索性实验中,研究者也可能接受更宽松的阈值,但要诚实说明。
例题:一次 A/B 测试

某产品团队测试报名按钮颜色。A 版本有 10000 名访客,610 人报名;B 版本有 10000 名访客,680 人报名。使用双侧检验,显著性水平设为 。我们要判断:B 的转化率看起来更高,这个差异是否足够不像偶然波动?
先写假设。零假设是两个版本真实转化率相同,。备择假设是两个版本真实转化率不同,。因为题目没有在实验前只声明“B 一定更好”,所以用双侧检验。
计算样本转化率。A 版本的样本转化率是 ,B 版本的样本转化率是 。样本差异是 ,也就是 0.7 个百分点。
在零假设下,两组真实转化率相同,所以用合并比例估计共同转化率:
计算差异的标准误。两组样本量相同,使用两比例检验的标准误:
代入数据后,。
把样本差异转成标准化统计量:
这里 。双侧 p 值约为 。
因为 ,在 5% 显著性水平下拒绝零假设。这个结果说明:如果两个按钮真实转化率一样,观察到 0.7 个百分点或更极端差异的概率不高。
这个结论还不能直接变成“马上全量上线”。团队还要看样本是否随机分流、实验是否中途偷看多次、不同用户是否互相影响、0.7 个百分点的收益是否值得改版成本,以及后续是否需要复验。
统计显著只说明“差异不太像普通随机波动”。它没有自动说明“差异很大”“一定值得做”“长期一定稳定”。业务上的重要性要看效应大小、成本、风险和可重复性。
例题:药物实验
药物实验的统计检验更敏感,因为一个错误结论可能影响治疗决策。假设一项随机对照实验比较新药和安慰剂:药物组 200 人中有 70 人明显改善,安慰剂组 200 人中有 48 人明显改善。
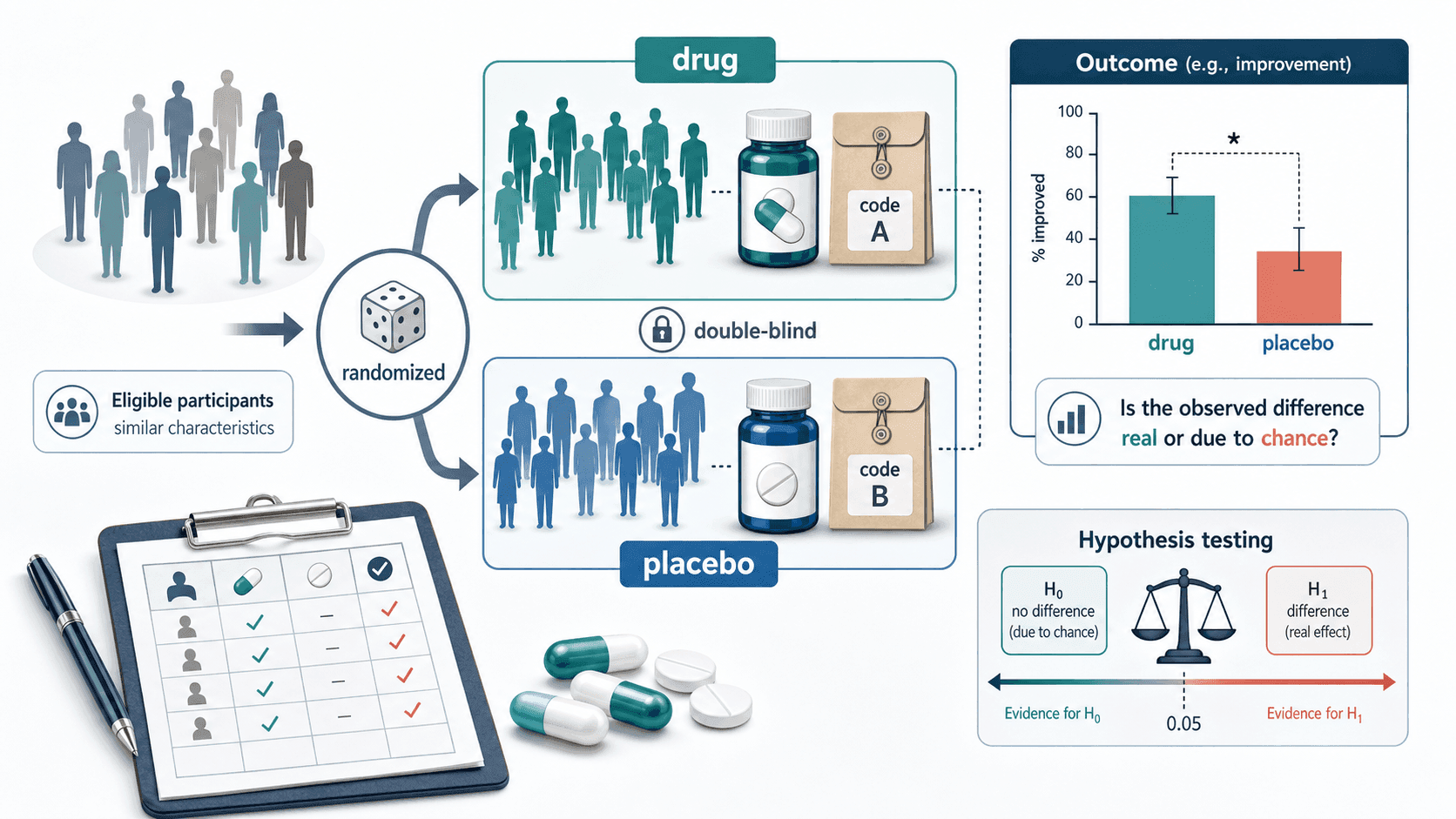
写出假设。零假设是新药改善率与安慰剂相同,。备择假设可以写成 ,因为药物也可能无效甚至更差。
计算样本改善率。药物组改善率是 ,安慰剂组改善率是 。样本差异是 ,也就是 11 个百分点。
在零假设下,两组真实改善率相同。合并改善率为:
用合并比例计算标准误:
得到 。
标准化差异:
双侧 p 值约为 。
若预先设定 ,则 ,可以拒绝“新药与安慰剂改善率相同”的零假设。下一步不是只看 p 值,而是继续看改善幅度、置信区间、不良反应、样本代表性和研究是否可重复。
临床研究尤其强调预先注册方案、随机分组、盲法、主要终点和样本量设计。因为如果研究者看了很多指标,只挑一个 p 值小的结果报告,显著性检验就会被滥用。
常见误解辨析
误解一:p 值是零假设为真的概率
不是。p 值是:
它不是:
把这两个方向混在一起,是 p 值最常见、也最危险的误读。
误解二:p 值越小,效果越重要
也不是。p 值会受效应大小影响,也会受样本量影响。样本量很大时,一个非常小的真实差异也可能得到很小的 p 值;样本量很小时,一个看起来很大的差异也可能无法达到显著。
例如有 100 万名用户时,转化率从 10.0% 到 10.1% 可能统计显著,但业务上是否值得改动,要看这个 0.1 个百分点能带来多少收益和成本。
误解三:没有显著差异,就是没有差异
不能这么说。没有显著差异可能是因为真实差异确实很小,也可能是因为样本量太小、测量噪声太大、实验设计不稳,导致检验没有足够能力发现差异。
更准确的说法是:在当前样本和检验规则下,没有得到足够证据拒绝零假设。
误解四:只要 p 值小,结论就可靠
也不够。p 值小不能修复偏差样本、混杂因素、数据清洗错误、中途反复偷看、只报告显著结果、事后改假设等问题。
坏设计加上小 p 值,仍然是坏证据。显著性检验只处理“如果模型和数据收集过程可信,随机波动能否解释结果”。它不能替代研究设计。
课程收束:从样本到行动
这门课从“数据到底在说什么”开始,到这里回到一个实际判断:面对样本里的差异,我们怎样避免被偶然波动骗到?
显著性检验把前面的内容串起来:
- 样本告诉我们观察到了什么。
- 概率模型告诉我们在某个假设下,样本会怎样波动。
- 抽样误差提醒我们,差异不一定来自真实效果。
- p 值把“当前结果有多意外”量化出来。
- 显著性水平让我们在看数据前设定判断规则。
- 实际决策还要结合效应大小、成本、伦理、可重复性和背景知识。
学完显著性检验后,最重要的变化不是会背公式,而是看到“差异”时会多问一句:这个差异是否大到超出随机波动的合理范围?如果是,它在现实中又是否足够重要?
练习
练习一:写出假设
某学校想知道新的复习课是否提高期末通过率。去年按旧方式复习的通过率是 78%。今年随机抽取参加新复习课的 120 名学生,其中 102 人通过。请写出零假设和一个合适的备择假设。
零假设可以写成 ,意思是新复习课下的真实通过率与旧方式没有差异。若学校只关心是否提高,通过率可以写成单侧备择假设 。如果学校只想知道是否发生变化,不预设方向,则写成 。
练习二:解释 p 值
一次双侧检验得到 ,显著性水平是 。请用一句准确的话解释这个 p 值,并说明是否拒绝零假设。
准确解释是:如果零假设成立,得到当前这么极端或更极端结果的概率约为 8%。因为 ,所以在 5% 显著性水平下不能拒绝零假设。不能拒绝不等于证明零假设为真。
练习三:判断误解
某产品经理说:“这个改版的 p 值是 0.01,所以这个改版有 99% 的概率真的有效,而且效果一定很大。”这句话哪里有问题?
这句话有两个问题。第一, 不是“改版有 99% 概率有效”,它表示在零假设成立时,当前或更极端结果出现的概率约为 1%。第二,p 值小不代表效果一定大。样本量很大时,小差异也可能得到很小的 p 值。还需要看效应大小、置信区间、业务收益、成本和实验设计。
练习四:药物实验的下一步
一项药物实验得到 ,研究者说“药物已经证明有效,可以忽略副作用和样本代表性”。请指出这个结论的问题。
在 的规则下, 可以作为反对零假设的证据,但它不是“已经证明有效”。药物是否值得使用,还要看改善幅度有多大、置信区间有多宽、副作用是否可接受、样本是否代表目标人群、研究是否随机双盲、是否有重复研究支持。显著性只是证据链的一环。