Redis 的核心数据结构
在理解了 Redis 的设计哲学之后,我们需要深入其核心:它究竟在内存里存什么、以何种结构存,以及这些结构如何支撑后端的典型场景。Redis 之所以被称为「数据结构服务器」,正是因为它在服务端暴露了多种抽象数据结构,而不仅仅是「字节块」; 客户端通过命令与这些结构交互,获得 O(1) 或 O(log N) 的访问与聚合能力,从而用结构换复杂度。这部分我们将依次梳理 String、Hash、List、Set、Sorted Set 五类核心结构,并说明它们为何共同构成了 Redis 的定位。
String
String 是 Redis 中最基础的类型:一个 key 对应一个 value,value 可以是字符串、整数或二进制数据,最大 512MB。从语义上看,它和传统缓存的 key-value 一致,但 Redis 在命令层做了大量扩展。除了最常用的 SET 与 GET,还有 MSET/MGET 批量读写、INCR/DECR 原子自增自减、APPEND 追加、GETRANGE/SETRANGE 按偏移读写子串等。这些命令使得 String 不仅能「存一份字节」,还能在服务端完成计数、拼接、按范围读取等操作,而无需在应用层多次往返或自己保证原子性。
在实际场景中,String 常被用来缓存整个对象(例如将用户信息序列化为 JSON 后 SET 到 user:10001),或存储会话、配置、分布式锁的 token。INCR 的原子性则天然适合计数器:阅读量、点赞数、限流计数等,只需一条 INCR 命令即可完成「读-改-写」,无需应用层加锁。分布式锁的典型用法是 SET key value NX EX seconds:仅在 key 不存在时设置并附带过期时间,从而用一条命令实现「获取锁」的语义。这些用法都体现了「在服务端完成简单逻辑、减少网络与并发复杂度」的思路。
redis
SET user:10001 '{"name":"张三","age":28}'
GET user:10001
INCR article:42:views
GET article:42:views
SET lock:order:12345 uuid123 NX EX 30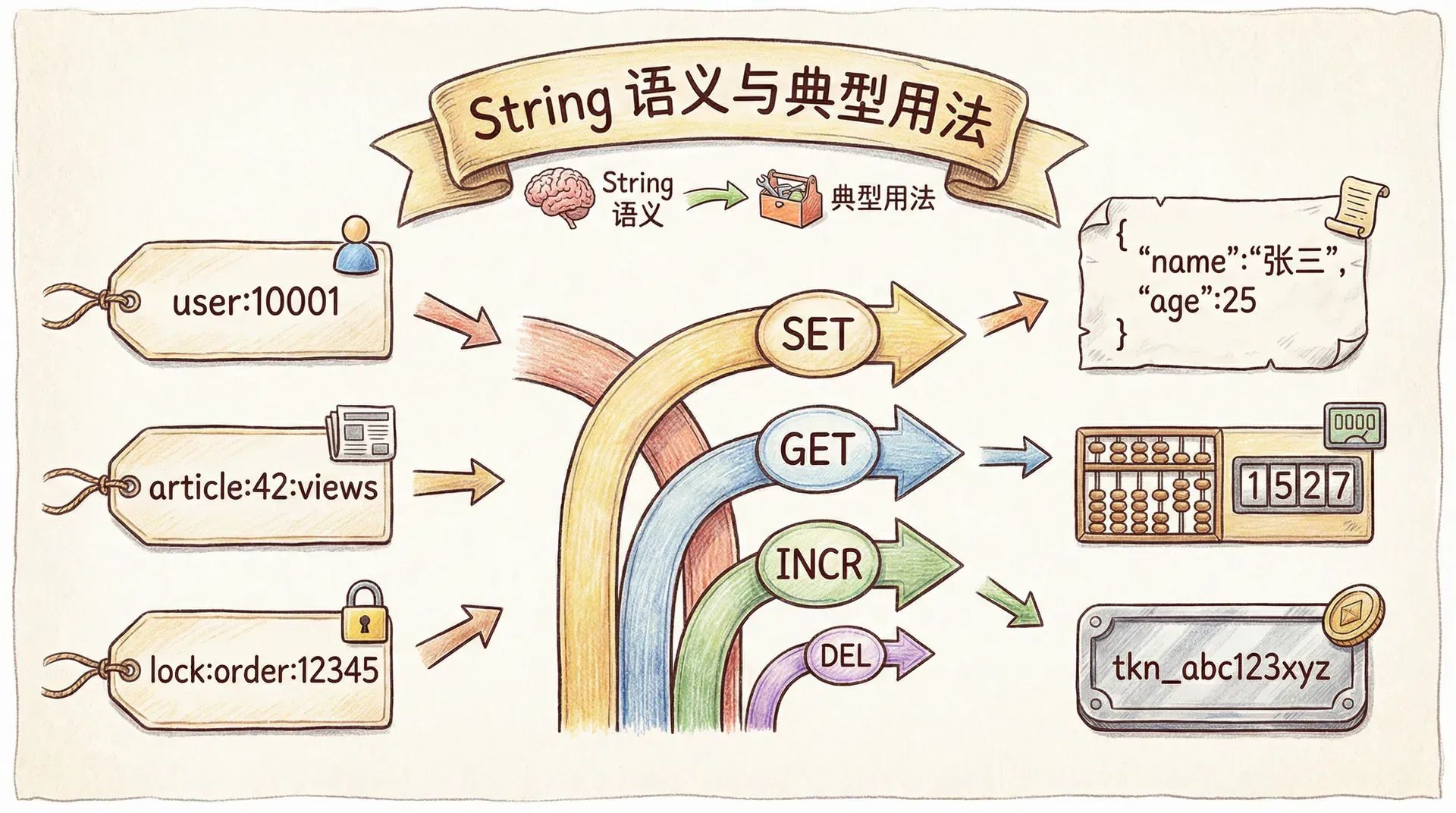
Hash
Hash 在 Redis 中表示「键值对集合」:一个 key 对应多个 field-value,可以理解为「对象」或「字典」。与用 String 存整份 JSON 相比,Hash 允许按 field 读写:只更新「最后登录时间」而不必反序列化整个用户对象,只读取「购物车中某商品数量」而不必拉取整个购物车。在内存与网络层面,这种「零存零取」能显著减少传输量和并发更新时的冲突面。常用命令包括 HSET/HGET、HMSET/HMGET 批量读写、HINCRBY 对数值型 field 自增、HDEL 删除 field、HGETALL 取回整个 Hash(在 field 较多时需谨慎,可改用 HSCAN 迭代)。
典型场景包括用户信息(以用户 ID 为 key,field 为 name、age、avatar 等)、购物车(以用户 ID 为 key,field 为商品 ID,value 为数量)、配置项(以模块名为 key,field 为配置名)。与「一个对象一个 String」相比,Hash 在需要部分更新、部分读取时更省带宽、更清晰;但当对象字段非常多或需要按 key 设置整体过期时间时,仍需在「一个大 Hash」与「多个 String」之间权衡,因为 Redis 的过期是 key 级别的,Hash 的每个 field 不能单独设置 TTL。
redis
HSET user:10001 name "张三" age 28 avatar "https://..."
HGET user:10001 name
HINCRBY cart:10001 item:888 1
HGETALL user:10001List
List 在 Redis 中是一个有序的、可重复的字符串序列,底层是双向链表(或压缩列表),支持从两端插入与弹出。LPUSH/RPUSH 从左侧或右侧插入,LPOP/RPOP 从左侧或右侧弹出,LRANGE 按索引范围取出一段元素,LLEN 获取长度。由于插入和弹出都是 O(1),List 常被用来实现简单的消息队列:生产者 RPUSH 到队尾,消费者 LPOP 从队头取(或使用 BRPOP 阻塞等待);也可以实现栈(LPUSH+LPOP)或时间线(LPUSH 新内容,LRANGE 分页取最近 N 条)。需要注意的是,Redis List 没有「主题」或「分区」概念,一个 key 就是一条队列,多业务需用多 key 或 key 命名区分。
另一个常见用法是文章列表、动态流:用 LPUSH 将新文章 ID 写入 user:10001:feed,用 LRANGE 0 9 取最近 10 条做分页。List 保持插入顺序,因此天然按时间倒序;但无法按「分数」或「权重」排序,若需要按热度或分数排序,应使用 Sorted Set。List 的阻塞命令 BRPOP/BLPOP 可以避免客户端轮询:在队列为空时阻塞等待,有数据时立即返回,适合简单的任务队列或通知队列。
redis
RPUSH queue:email "task1" "task2"
LPOP queue:email
LPUSH user:10001:feed "post:301" "post:302"
LRANGE user:10001:feed 0 9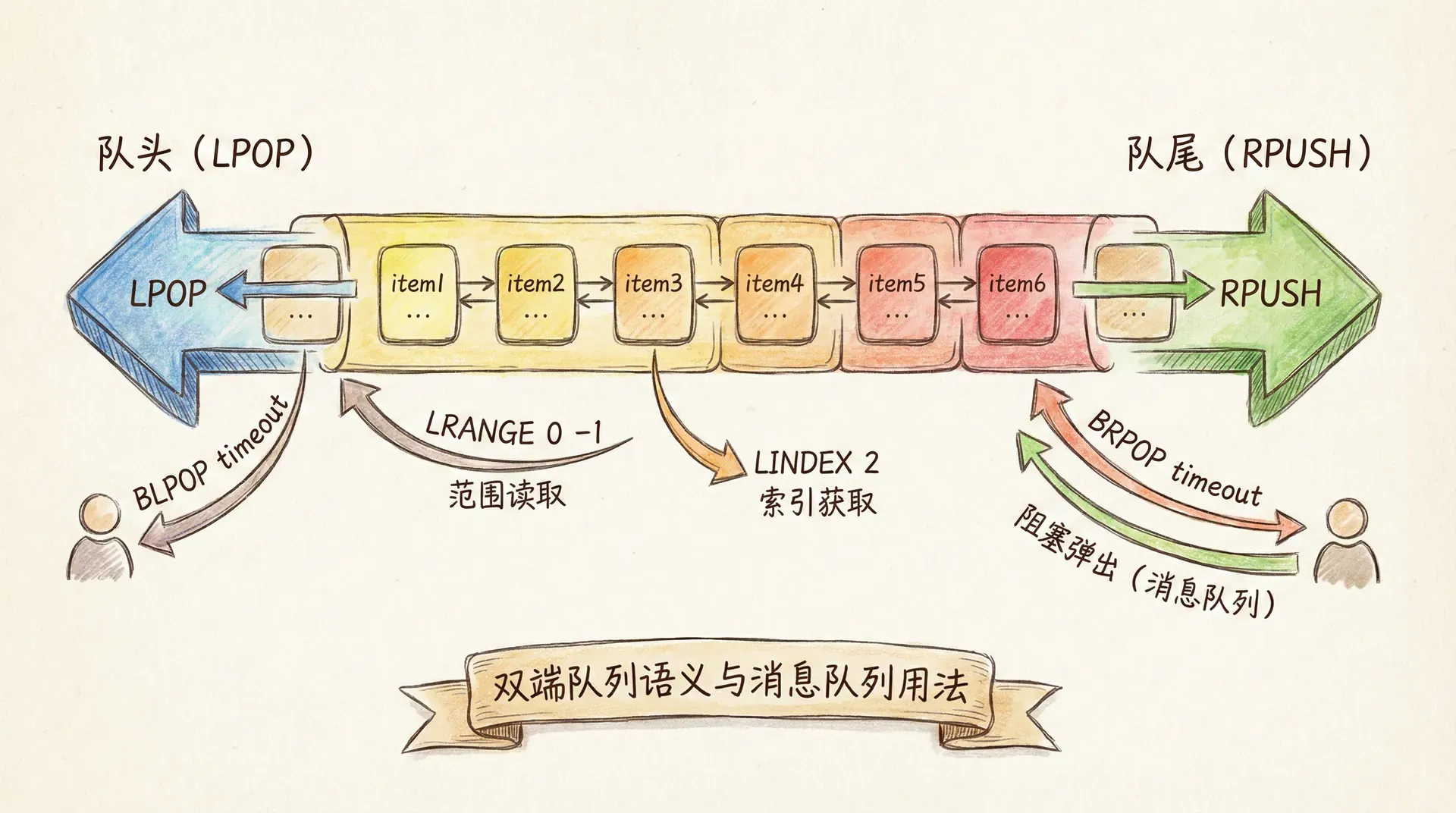
Set
Set 在 Redis 中是无序的、不重复的字符串集合,底层是哈希表或整数集合,支持 O(1) 的添加、删除、存在性判断,以及交集 SINTER、并集 SUNION、差集 SDIFF 等集合运算。这些运算在需要「共同关注」「共同好友」「标签组合」等场景中非常有用:例如用 Set 存用户的关注列表,求两个用户的共同关注即 SINTER user:A:following user:B:following。SADD 添加成员,SREM 删除,SISMEMBER 判断是否在集合内,SMEMBERS 取回全部成员(集合很大时可用 SSCAN 迭代);SRANDMEMBER 随机取若干成员不删除,SPOP 随机弹出,可用于抽奖、随机推荐等。
Set 的「去重」语义天然适合标签、兴趣、ID 集合:用户打过的标签、某篇文章的访问用户 ID(用于去重计数)、某活动的中奖用户 ID 等。与 List 相比,Set 不保证顺序、不允许重复;与 Hash 相比,Set 只有「成员」没有「字段-值」,适合纯集合关系。当需要「按权重排序的集合」时,应使用 Sorted Set 而非 Set。
redis
SADD user:10001:tags "redis" "backend" "database"
SINTER user:10001:tags user:10002:tags
SRANDMEMBER user:10001:tags 3Sorted Set
Sorted Set(有序集合)是 Redis 中功能最丰富的结构之一:每个成员关联一个浮点型的 score,集合按 score 排序,成员不重复。它同时支持「按 score 范围查询」(如取 score 在 80~100 之间的成员)、「按排名查询」(如取前 10 名)、以及「按成员查 score 或排名」(如某用户的分数与排名)。底层采用跳表(skiplist)与哈希表结合:跳表支持 O(log N) 的范围与按排名访问,哈希表支持 O(1) 的「成员→score」查询,二者协同实现「既能按分数区间取,又能按成员快速查」的需求。
典型场景包括排行榜(score 为点赞数、积分、完成时间等;ZREVRANGE 取 Top N)、延迟队列(score 为执行时间戳,消费者用 ZRANGEBYSCORE 取已到期的任务)、滑动窗口限流(score 为请求时间戳,按时间范围统计或删除过期记录)。ZADD 添加或更新成员及其 score,ZINCRBY 对 score 自增(适合实时更新排行榜分数),ZRANGE/ZREVRANGE 按排名区间取,ZRANGEBYSCORE 按分数区间取,ZREM 删除成员。Sorted Set 的「有序 + 去重 + 范围查询」组合,是纯 String 或 Hash 难以高效表达的,也是 Redis 作为「数据结构服务器」的集中体现。
redis
ZADD leaderboard:game 1500 "player:A" 1200 "player:B" 1800 "player:C"
ZREVRANGE leaderboard:game 0 9 WITHSCORES
ZINCRBY leaderboard:game 100 "player:B"
ZRANK leaderboard:game "player:B"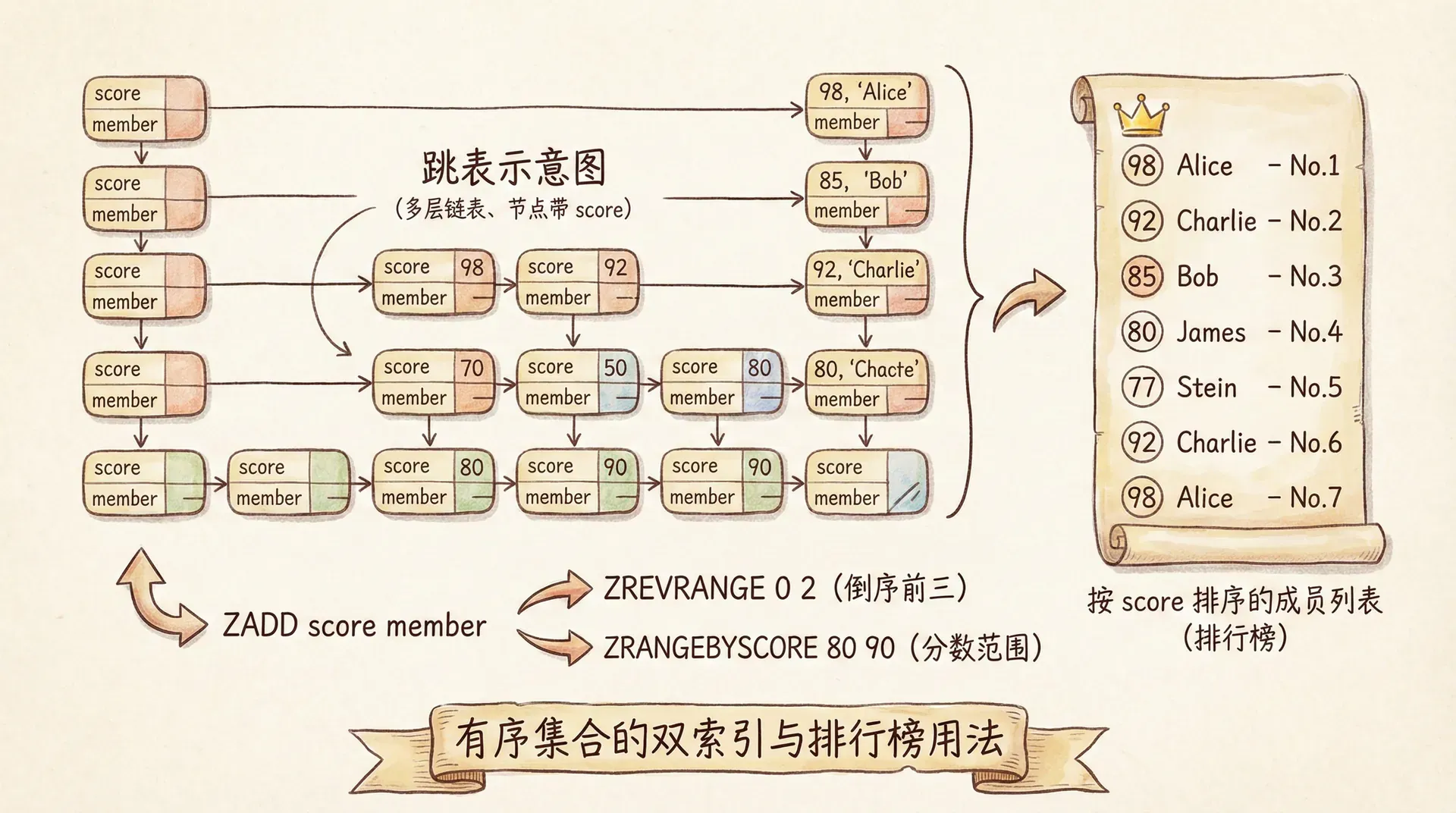
为什么 Redis 是「数据结构服务器」
「数据结构服务器」这一说法,强调的是 Redis 在服务端暴露的是抽象数据结构,而不仅仅是「字节块」或「扁平 key-value」。客户端通过命令与这些结构交互:对 String 做 INCR,对 Hash 做 HGET,对 List 做 LRANGE,对 Set 做 SINTER,对 Sorted Set 做 ZRANGEBYSCORE。这些操作在服务端原子执行,无需应用层自己实现「加锁 + 读 + 改 + 写」;同时,聚合与范围查询在服务端完成,减少网络往返与客户端逻辑,从而「用结构换复杂度」。
与此形成对比的是传统缓存(如 Memcached):key 和 value 都是字符串,若要实现计数器,需 GET 后自增再 SET,并发下需应用层或分布式锁保证原子性;若要实现排行榜,需在应用层维护排序或多次请求后排序。Redis 则把「计数器」「排行榜」「队列」「集合运算」等语义内置为命令与数据结构,业务侧只需选对结构和命令即可。因此,选择 Redis 不仅是「多了一个缓存层」,而是「多了一个可编程的数据结构层」,能够把部分业务逻辑下沉到存储侧,在保证原子性与一致性的前提下简化架构。
从实现层面看,Redis 为每种结构选择了合适的底层实现:String 的简单动态字符串(SDS)、Hash 的压缩列表与哈希表、List 的快速链表与压缩列表、Set 的整数集合与哈希表、Sorted Set 的跳表与哈希表。这些实现兼顾内存占用与操作复杂度,使得大部分命令在 O(1) 或 O(log N) 内完成。 理解这五类结构及其适用场景,是后续做 Key 设计、缓存建模、以及选择「用哪种结构解决什么问题」的基础;在下一部分中,我们将讨论 Key 命名、扁平化设计与 Redis 不适合做什么,从而把「数据结构」落到「数据建模」与「架构边界」上。