Key 设计与数据建模
在掌握了 Redis 的五类核心数据结构之后,我们需要把「选哪种结构」落到「如何命名、如何建模、以及 Redis 的边界在哪里」上。Key 设计与数据建模直接决定了后续的可维护性、可观测性与性能边界;命名混乱或建模不当,会在多业务共用、排查问题、扩容与淘汰时付出高昂代价。 这部分我们将围绕 Key 命名规范、扁平化设计、以及 Redis 不适合做什么展开,帮助你在架构层面正确摆放 Redis 的位置。
Key 命名规范
Redis 的 Key 是二进制安全的字符串,理论上可以包含任意字节;但在工程实践中,Key 的命名需要兼顾可读性、可管理性与工具链兼容性。业界普遍采用「分层命名」:用英文冒号将 Key 拆成多段,从左到右依次表示业务模块、实体类型、实体标识或逻辑含义,必要时在末尾标注 value 类型。例如 user:profile:10001 表示用户模块下、用户画像、用户 ID 为 10001 的数据;cache:article:42:html 表示缓存模块下、文章、ID 42、HTML 片段。这样,通过 Key 的前缀就能快速区分业务归属与数据含义,便于监控、排查与权限隔离。
在命名时,应尽量使用小写字母、数字与冒号,避免空格、换行、单双引号等特殊字符,以免在命令行、日志与监控系统中出现转义或截断问题。Key 的长度需要在「语义清晰」与「内存与网络开销」之间权衡:过长的 Key 会占用更多内存(Redis 会为每个 Key 存储元数据),也会增加网络传输量;过短则难以理解。通常建议在保证语义的前提下控制在百字节以内,用约定好的缩写(如 uid、art、cfg)替代冗长单词。此外,为 Key 设置过期时间(TTL)是防止「Key 无限期占用内存」的重要手段;缓存类 Key 应根据业务设置合理过期时间(如验证码 5 分钟、会话 24 小时),并可对过期时间加随机偏移,避免大量 Key 同时过期导致缓存雪崩。
redis
user:profile:10001
cache:article:42:html
session:web:abc123
ratelimit:api:user:10001:minute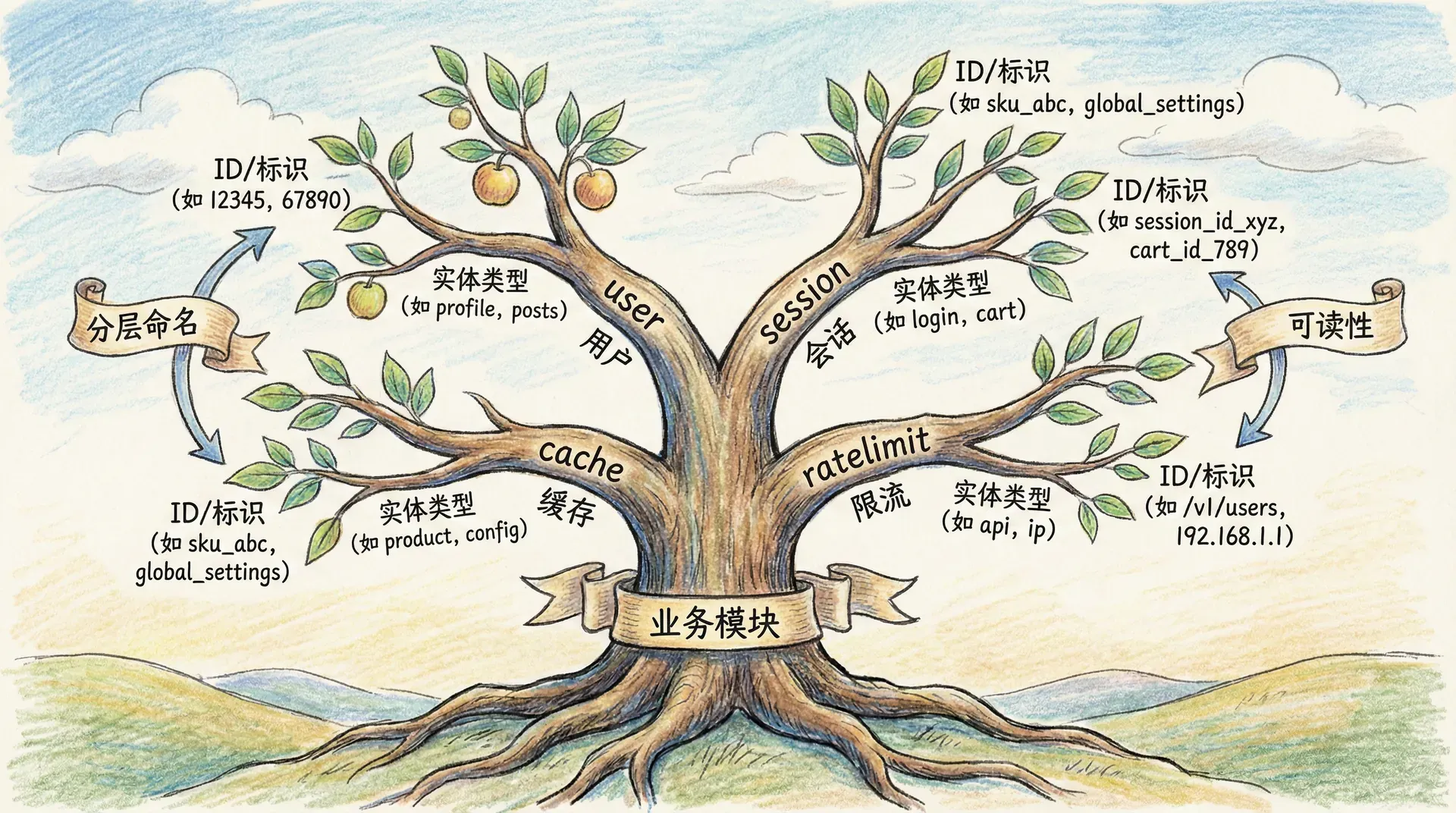
与此密切相关的是多应用或多环境共用同一 Redis 实例时的冲突问题。若不同应用使用相同的 Key 命名空间,很容易出现互相覆盖或误删;因此,建议用「业务名或应用名」作为最左侧前缀,例如 order:lock:12345 与 payment:lock:12345 即使 ID 相同也不会冲突。在实践中,可将各模块的 Key 前缀统一定义在配置或常量中,避免硬编码散落各处,也便于后续做 Key 级别的监控与审计。
扁平化设计
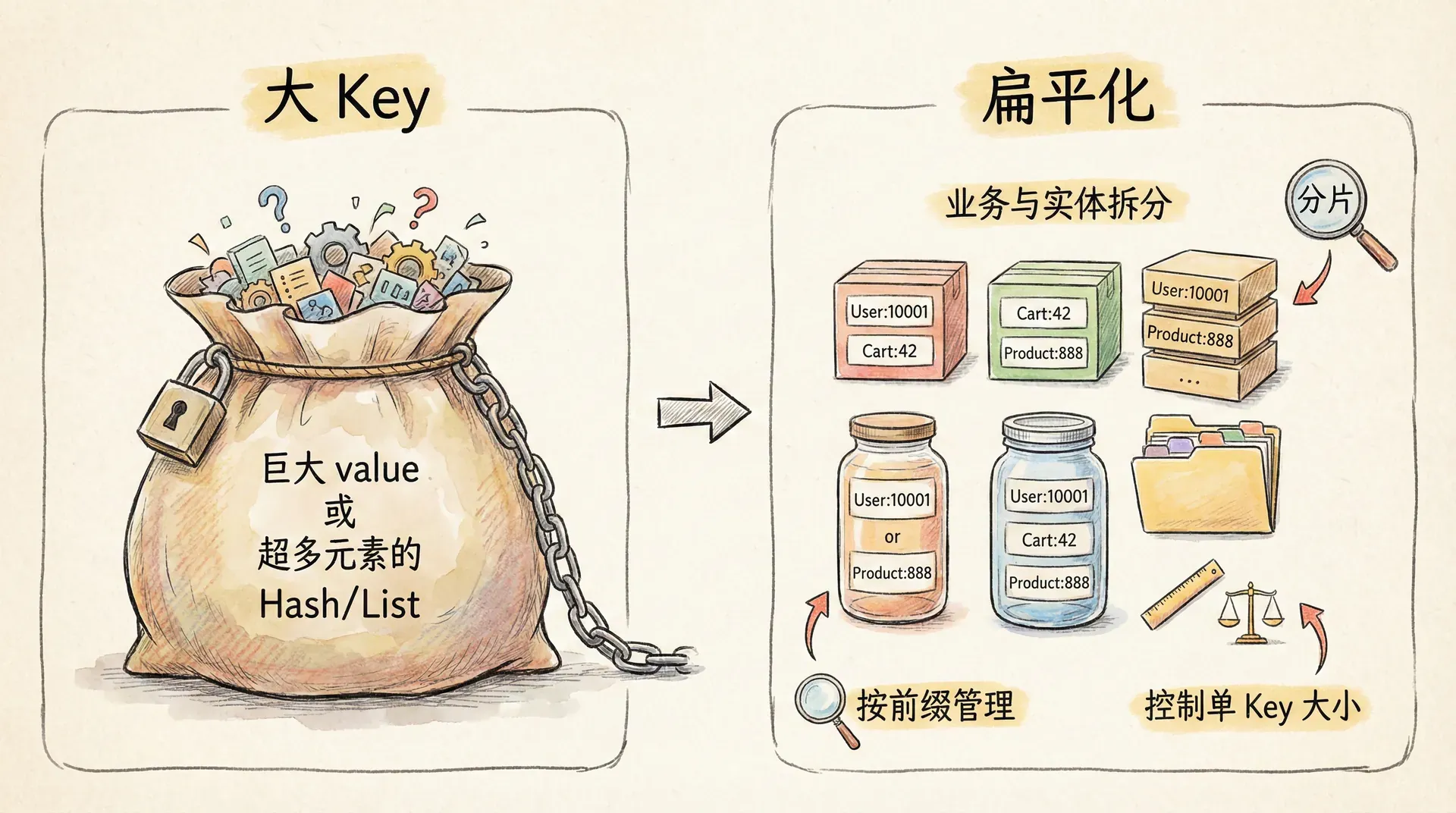
「扁平化」在这里有两层含义:一是 Key 本身的层级要清晰但不要过深,二是单个 Key 对应的 value 不要承载过多嵌套或过大的数据。Key 的层级过深(例如 a:b:c:d:e:f:id)会降低可读性,且 Redis 并不提供「按前缀批量删除」的原子语义,只能通过 SCAN 扫描后再删除,前缀过长也会增加扫描时的匹配成本。因此,通常用两到四段即可表达「业务:实体:标识」或「业务:实体:标识:类型」,不必为了「分类细致」而无限细分。
在 value 层面,应避免「大 Key」:单个 String 的 value 不宜超过 10KB,Hash、List、Set、Sorted Set 的元素个数不宜超过数千量级。过大的 Key 会导致单次读写、序列化、网络传输的成本升高,也会在持久化(RDB fork、AOF 重写)时拉长主线程阻塞时间;删除大 Key 时若直接用 DEL,可能造成长时间阻塞。对于「一个对象有很多字段」的场景,若字段数量可控且需要按字段更新,用 Hash 是合适的;若字段数量很大或需要按 Key 设置不同的 TTL,则应将对象拆成多个 Key(如 user:10001:base、user:10001:ext),用多个 Hash 或 String 分片存储,避免单个 Key 膨胀。
redis
HMSET user:10001 name "张三" age 28 city "北京"
HGET user:10001 name
HSET cache:article:42 title "标题" content "..." summary "..."
EXPIRE cache:article:42 3600与「嵌套」相对的是「用 Key 表达关系、用结构表达聚合」。例如,用户与文章的「点赞关系」可以用 Set 存储:user:10001:likes 存用户点赞的文章 ID 集合,article:42:likers 存点赞该文章的用户 ID 集合;需要「某用户是否点赞某文章」时用 SISMEMBER,需要「某文章被多少人点赞」时用 SCARD,而不是在一个 Key 里塞入整张关系表。这种「关系用 Set、属性用 Hash、有序用 Sorted Set」的建模方式,既保持了 Key 的扁平与结构的清晰,也便于利用 Redis 的原生命令做聚合与过期控制。
Redis 不适合做什么
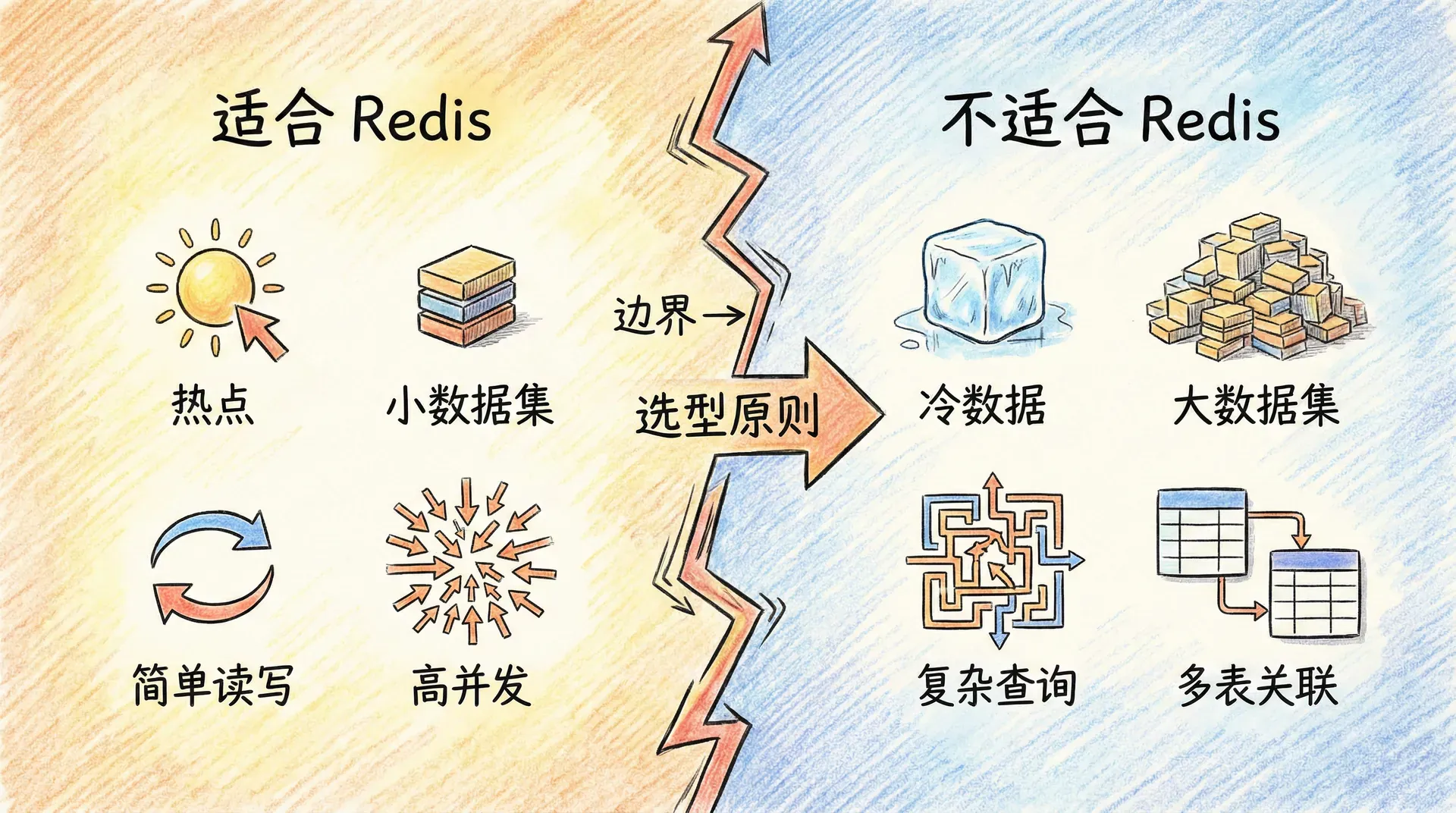
理解 Redis 的适用边界,与理解其适用场景同样重要。Redis 是内存型存储,数据量受物理内存限制,单机成本随数据量线性增长;因此,冷数据(访问频率很低的数据)不适合放在 Redis 中。若将大量历史订单、日志、归档数据塞进 Redis,会占用宝贵内存而很少被命中,性价比极低;这类数据应放在磁盘型数据库或对象存储中,需要加速时再对热点做缓存。
大数据集的存储与扫描也不是 Redis 的强项。例如,将数百万用户的关注关系全部放进 Redis,即使用 Set 存储,单用户关注数可能达到数万,Key 与成员的总内存占用会非常高,且 KEYS、SMEMBERS、HGETALL 等 O(n) 命令在数据量大时会阻塞主线程。Redis 更适合「小而热」的数据:热点 Key、近期活跃数据、需要快速访问的聚合结果;对于「大而全」的底表,应放在关系型或分布式存储中,Redis 只缓存热点或索引。
复杂查询与多表关联同样不适合在 Redis 中实现。Redis 没有 SQL,没有 join、没有聚合函数、没有二级索引;若要「按某字段筛选、排序、分页」,只能将数据取到应用层再处理,或事先在 Redis 中维护多份按不同维度组织的数据(如 Sorted Set 按分数、按时间),这会显著增加建模与一致性维护成本。对于需要复杂条件查询、多表关联、报表分析的场景,应使用关系型数据库或 OLAP 存储,Redis 作为缓存或会话等辅助存储即可。
redis
SCAN 0 MATCH user:* COUNT 100
HSCAN user:10001 0 COUNT 50在线扩容方面,Redis 在单机模式下无法水平扩展,Cluster 模式虽然支持分片,但扩容涉及槽位迁移与数据搬迁,需要规划与运维配合;因此,若预期数据量会持续增长,应在架构设计阶段就考虑「数据如何分片、热点如何隔离」,避免后期被动扩容。综合来看,Redis 最适合「高并发、低延迟、数据结构清晰、数据量可控」的场景;对于「大而冷、大而全、复杂查询、强持久化与事务」的需求,应优先考虑其他存储,让 Redis 守住「内存换时间、结构换复杂度」的边界。
在下一讲中,我们将进入 Redis 最经典的应用之一:缓存。届时会讨论 Cache Aside 模式、读缓存与写缓存的策略、以及缓存击穿、雪崩、穿透的成因与应对,把本讲中的 Key 设计与建模落到具体的缓存场景中。