Redis 的设计哲学
在理解了「为什么后端一定会用到 Redis」之后,我们需要进一步追问:Redis 为何选择单线程模型、为何以内存为核心,以及它与传统缓存(如 Memcached)在定位上有何本质区别。这些问题的答案共同构成了 Redis 的设计哲学,也决定了它在实际工程中的适用边界与取舍。
单线程模型为什么快
很多人初次接触 Redis 时会感到困惑:在「多核时代」,单线程岂不是浪费 CPU?事实上,Redis 的高性能恰恰与单线程密切相关。这里的「单线程」指的是命令执行核心:所有客户端的命令在同一个线程中串行执行,不存在多线程并发修改同一份数据结构的情况,因此也无需为哈希表、跳表等内部结构加锁,既避免了锁竞争与死锁风险,也省去了上下文切换带来的 CPU 开销。在内存操作本就极快的前提下,真正的瓶颈往往不在 CPU 计算,而在 I/O 与调度;单线程让「谁在算」变得简单可预测,反而有利于将性能稳定在高位。
那么,单线程如何同时服务成千上万个连接?答案在于 I/O 多路复用。Redis 使用操作系统提供的事件驱动接口(在 Linux 上通常是 epoll),将「等待连接上有数据可读」这件事交给内核完成,应用层只在一个线程里通过 epoll_wait 等待「哪些连接就绪」,然后依次处理这些连接上的命令。这样一来,一个线程就能高效管理数万甚至十万级连接,而无需为每个连接分配一个线程。从编程模型上看,这相当于把「多连接」转化为「多事件」,由内核负责通知,由单线程顺序处理,既避免了传统阻塞 I/O 下「一连接一线程」的资源爆炸,也避免了多线程下对共享数据结构的加锁与同步。
c
// 简化:Redis 主循环中通过 epoll 等待就绪事件,再处理命令
// 实际源码见 ae.c / ae_epoll.c
epoll_wait(epfd, events, MAX_EVENTS, timeout);
for (each ready fd) {
read_from_client(fd);
process_command();
write_to_client(fd);
}因此,Redis 的「快」可以概括为三方面的配合:内存操作带来的极低延迟、单线程命令执行带来的无锁与无上下文切换、以及 I/O 多路复用带来的高并发连接处理能力。三者叠加,使得单机 Redis 在合理配置下能够达到十万级 QPS,且延迟稳定在亚毫秒级。
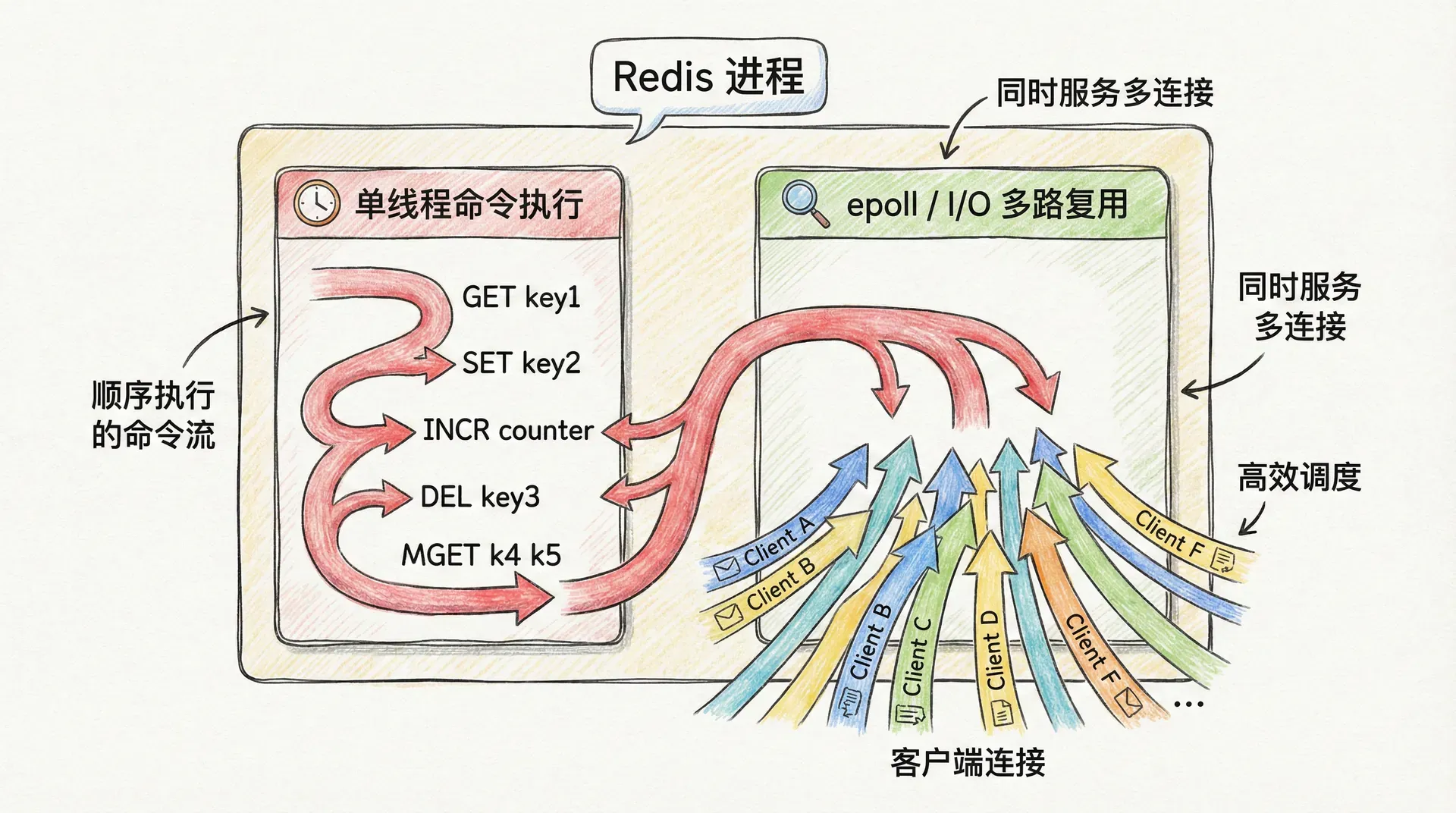
与此密切相关的是对「单线程」范围的准确理解。Redis 在 6.0 之后引入了多线程 I/O(网络读写的并行化),但命令的解析与执行仍然在单线程中完成,因此数据结构的访问依旧无需加锁。持久化(RDB 快照、AOF 重写)则由子进程或后台线程执行,不占用主线程。所以,当我们说「Redis 单线程」时,指的是其核心执行路径的串行化设计,而非整个进程只有一个线程;这一限定对于理解其性能与语义都至关重要。
内存数据库的取舍
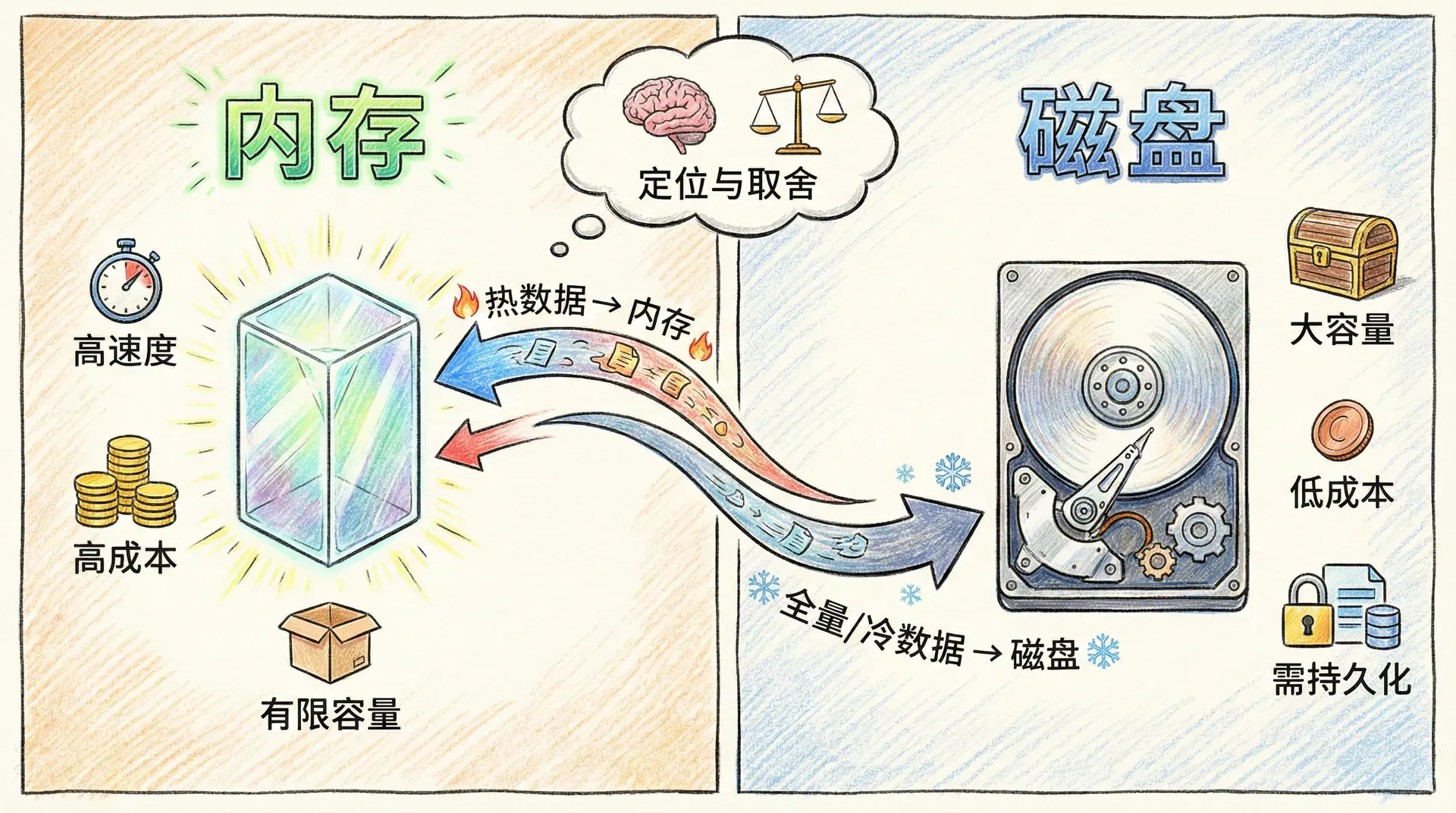
以内存为主要存储介质,意味着数据访问延迟极低,但同时也带来容量、成本与持久化三大取舍。内存价格远高于磁盘,单机容量通常在数十 GB 到数百 GB 量级,无法像磁盘数据库那样以 TB 为单位线性扩展;因此,内存数据库必须明确自己的边界,把「热数据」或「可丢失的缓存」放在内存,而把「全量数据」或「强持久化」交给磁盘型存储。Redis 在设计上接受这一前提:它提供可选的持久化(RDB、AOF),但持久化的首要目标是「故障恢复」与「可回溯」,而非替代 MySQL 成为系统唯一真相源。在架构上,内存数据库与磁盘数据库是互补关系,而非替代关系。
在持久化层面,Redis 提供了两种机制。RDB(快照) 在某一时刻将内存中的数据序列化到磁盘,文件紧凑、恢复速度快,但两次快照之间的写入会随进程崩溃而丢失,因此更适合对丢失容忍度较高的缓存场景或配合 AOF 做混合恢复。AOF(追加写日志) 则记录每一次写操作,重启时重放日志即可恢复,数据安全性更高(例如配置为每秒同步一次时,最多丢失一秒写入),但文件体积较大、恢复时间较长。Redis 4.0 起支持的 RDB+AOF 混合 模式在 AOF 文件中用 RDB 格式存储某一时刻的全量,再追加增量写操作,在恢复速度与数据安全之间取得平衡。生产环境中,若需要持久化,通常建议开启 AOF 并选用 everysec 同步策略,在性能与安全之间折中。
conf
# 示例:Redis 持久化相关配置(仅作说明,非完整配置)
appendonly yes
appendfsync everysec
aof-use-rdb-preamble yes当内存使用达到 maxmemory 上限时,Redis 会按照配置的淘汰策略(如 allkeys-lru、volatile-lru)移除部分键,以便为新写入腾出空间。这一机制使得 Redis 可以作为「有界缓存」使用:内存中只保留热点或最近使用的数据,超出的部分自动淘汰,而不需要应用层自己实现 LRU。与此同时,RDB 快照与 AOF 重写都会触发 fork,在瞬间可能使内存占用接近翻倍,因此容量规划时需要预留余量,并关注内存碎片与 mem_fragmentation_ratio,必要时开启 activedefrag 做碎片整理。这些都是在「内存数据库」这一前提下的典型取舍:用内存换时间,用策略与配置换可控的资源边界。
Redis 与传统缓存的区别
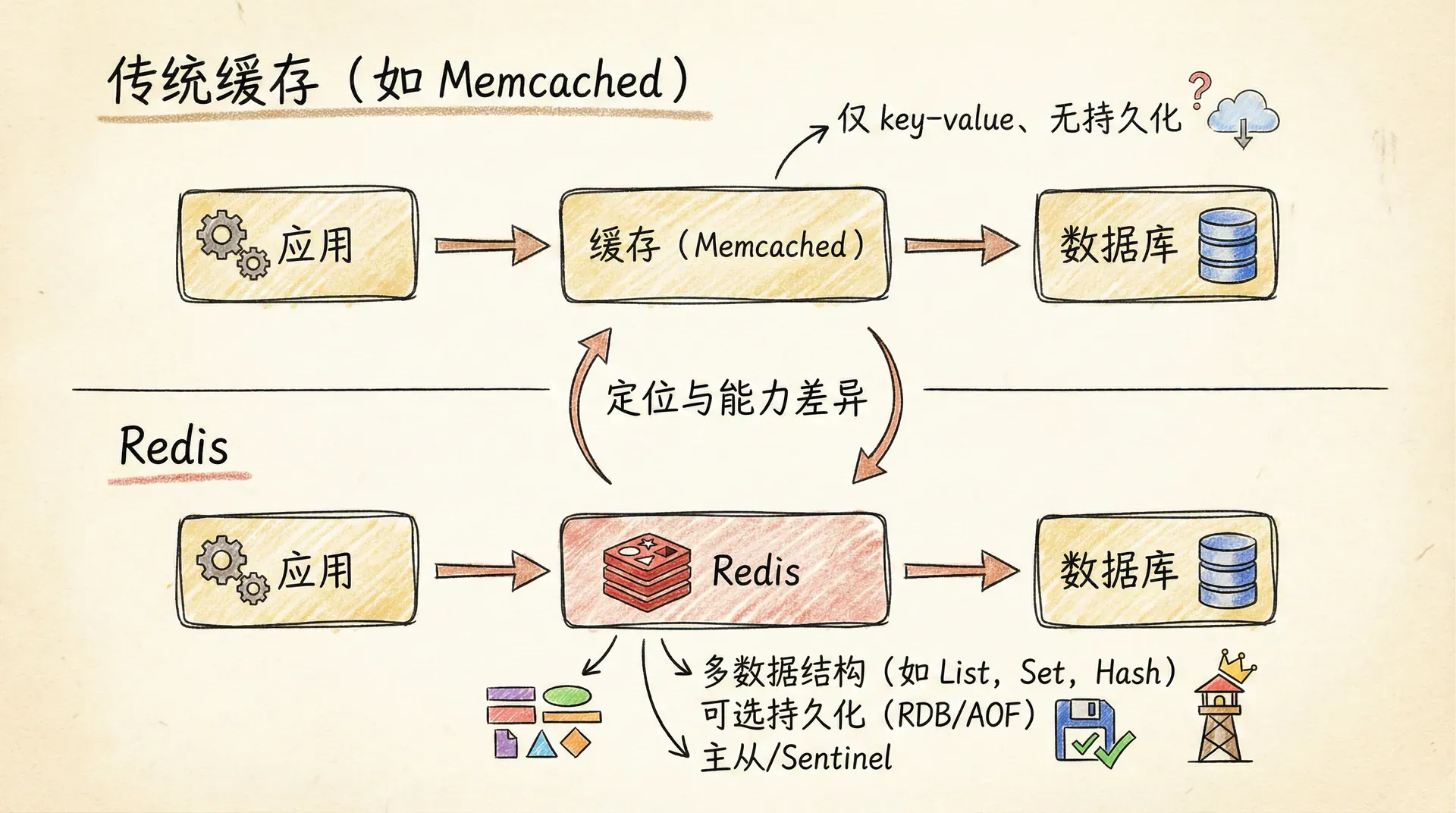
传统缓存(以 Memcached 为代表)的定位非常明确:在应用与数据库之间放一层简单的 key-value 存储,用内存加速读请求,降低数据库压力。键和值都是字符串,值有大小上限(如 1MB),不支持复杂数据结构,也不提供持久化;服务重启后数据全部丢失,因此从设计上就被视为「可重建的缓存层」。Redis 在诞生之初也常被当作缓存使用,但它的设计走得更远:除了字符串,还提供 Hash、List、Set、Sorted Set 等结构,并在此基础上支持过期时间、发布订阅、Lua 脚本、事务等能力,因此被称为「数据结构服务器」。这一差异决定了二者在应用场景上的分野。
从数据结构上看,Memcached 的 value 是扁平字节串,若要存储一个用户对象,只能序列化成 JSON 再整存整取;而 Redis 可以用 Hash 按字段读写,例如只更新用户的「最后登录时间」而不必反序列化整个对象,既减少网络传输,也降低并发更新时的冲突面。Sorted Set 则直接支持按分数排序与范围查询,适合排行榜、延迟队列等场景,这些在纯 key-value 缓存中往往需要在应用层用多键或复杂逻辑实现。因此,当业务需要「不只是缓存一份字节块,而是要在服务端做聚合、排序、过期策略」时,Redis 的结构化能力会显著降低复杂度,这也是「用结构换复杂度」的体现。
在持久化与高可用方面,Redis 支持 RDB 与 AOF,可在宕机后恢复数据;支持主从复制与 Sentinel,便于做故障转移与读扩展。Memcached 则不做持久化,也不提供内置的主从或集群方案,更依赖客户端或代理做分片与扩容。因此,若场景允许「缓存可丢、重启后从数据库重建」,Memcached 的简单与多线程大 value 性能仍有其优势;若需要「缓存可恢复、或希望用 Redis 承担部分有状态能力(如 Session、分布式锁)」,则 Redis 的持久化与高可用设计更贴合需求。二者并非简单的谁替代谁,而是「纯缓存、极简」与「缓存 + 数据结构 + 可持久化」两条路线的不同选择。
综合来看,Redis 的设计哲学可以概括为:在「内存 + 单线程 + I/O 多路复用」的技术底座上,用丰富的数据结构与可选的持久化、高可用,既满足「缓存」的加速需求,又承担「数据结构服务器」的建模与简化职责。理解这些取舍与边界,有助于在后端架构中正确摆放 Redis 的位置,并在下一讲中更好地理解其核心数据结构为何如此设计。