缓存(Cache)
在完成了 Key 设计与数据建模之后,我们进入 Redis 最经典的应用场景:缓存。缓存的目标是在应用与数据库之间加一层「热数据」存储,用内存换时间,降低数据库压力与响应延迟;但如何读、如何写、如何应对失效与异常,直接决定了缓存的正确性与可用性。 这部分我们将围绕 Cache Aside 模式、读缓存与写缓存的策略、以及缓存击穿、雪崩、穿透的成因与应对展开,帮助你在工程中正确使用 Redis 做缓存。
Cache Aside 模式
Cache Aside(旁路缓存)是业界最常用的缓存读写模式:应用层「主动」管理缓存,缓存不作为数据的唯一来源,数据库才是真相源。读请求时,先查缓存,命中则直接返回;未命中则查数据库,并将结果写回缓存,供后续请求命中。写请求时,不直接更新缓存,而是先更新数据库,再删除缓存中的对应 Key,让下次读请求时从数据库加载并回填缓存。这一「读时回填、写时删缓存」的策略,避免了「写时更新缓存」在并发写场景下的时序错乱,也避免了「写时先删缓存再更新数据库」在并发读写下导致的旧数据被回填进缓存的脏读问题。
为什么写时选择「删除缓存」而不是「更新缓存」?在并发写场景下,多个写请求的完成顺序无法保证;若每个写请求都去更新缓存,后完成的请求可能覆盖先完成请求写入的数据,导致缓存中保留的是旧值。 删除缓存则是幂等操作,且将「何时回填」推迟到下一次读请求,由「当时数据库中的最新值」来决定缓存内容,从而在语义上更安全。 为什么推荐「先更新数据库,再删除缓存」?若先删缓存再更新数据库,在删缓存与数据库更新完成之间,若有读请求进来,会因缓存未命中而读数据库,此时读到的可能是旧值,并将其写回缓存;随后数据库更新完成,但缓存中已是旧数据,形成短暂不一致。先更新数据库再删缓存,虽然理论上仍可能在「数据库已更新、缓存未删」的极短窗口内被读到旧缓存,但概率更低,且一旦删除成功,后续读请求会从数据库拉取新值并回填,一致性会自然恢复。
text
读请求:GET cache_key → 命中则返回;未命中则 SELECT ... → SET cache_key value EX ttl
写请求:UPDATE db ... → DEL cache_key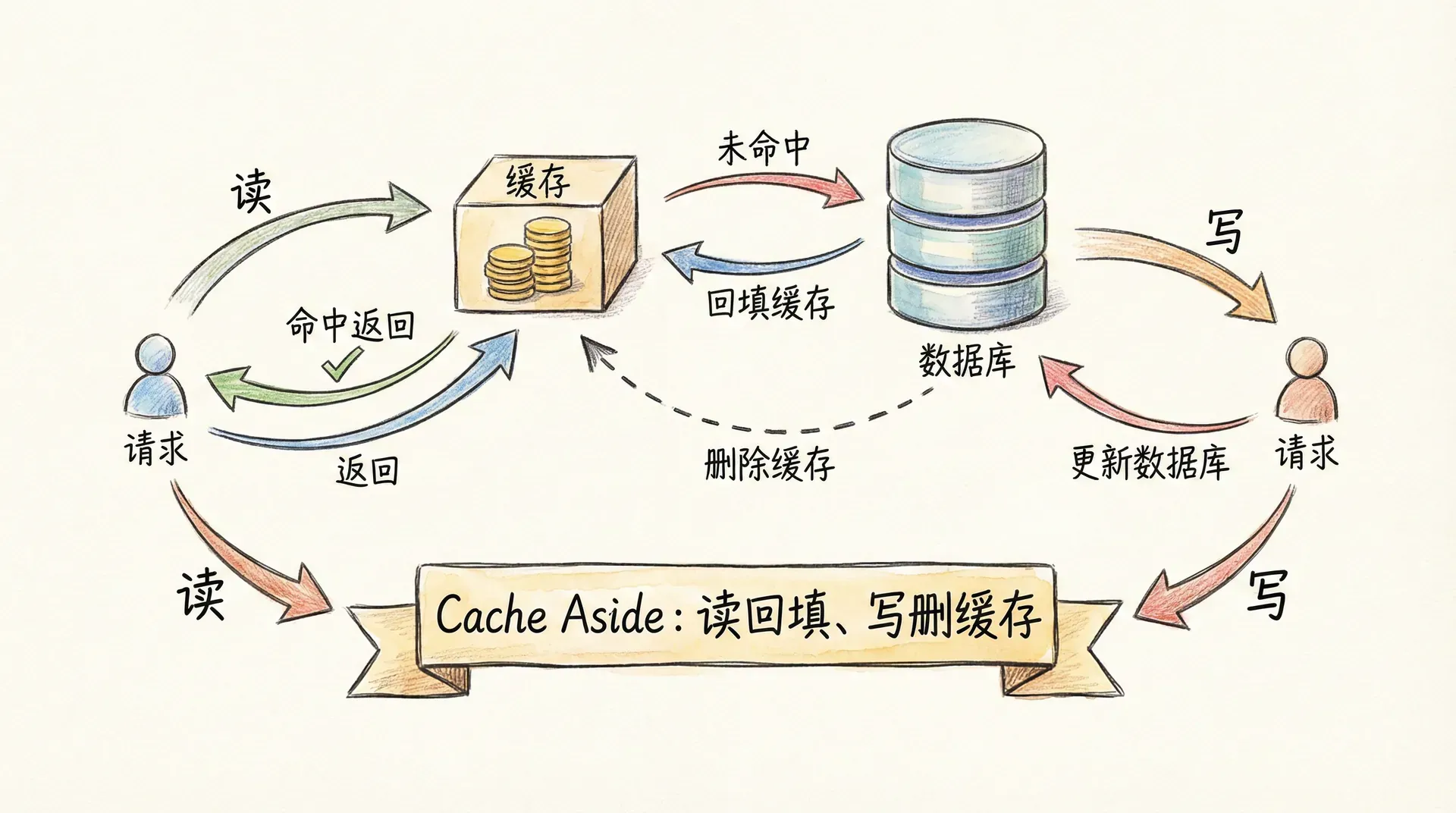
与此密切相关的是删除缓存失败或延迟时的兜底。若「先更新数据库,再删除缓存」中的删除缓存失败,缓存会长期保留旧值,直到过期或手动清理。工程上通常会对删除缓存做重试(同步重试或通过消息队列异步重试),并设置合理的缓存 TTL;即使删除失败,旧数据也会在 TTL 到期后失效,下次读请求会从数据库加载新值,最终一致性仍可恢复。在极高一致性要求的场景下,还可通过订阅数据库 binlog 或变更事件,在数据变更后异步失效或更新缓存,将「删除缓存」与业务写请求解耦,避免业务代码中删除失败影响主流程。
读缓存与写缓存
「读缓存」指的是上述 Cache Aside 的读路径:先查缓存,未命中再查库并回填。这一路径中,缓存是「读加速」层,写请求不直接更新缓存,只负责失效缓存。「写缓存」在狭义上指另一种策略:写请求在更新数据库的同时更新缓存(Write Through 或 Write Behind)。Write Through 指每次写都同步更新数据库和缓存,保证二者一致,但写延迟较高;Write Behind 指先写缓存(或先写内存队列),再异步落库,写延迟低但存在丢数据风险。在实际后端中,Cache Aside 的「写时删缓存」更常见,因为「更新缓存」在并发写下难以保证时序,而「删缓存」把回填时机交给读请求,逻辑更简单、一致性问题更可控。
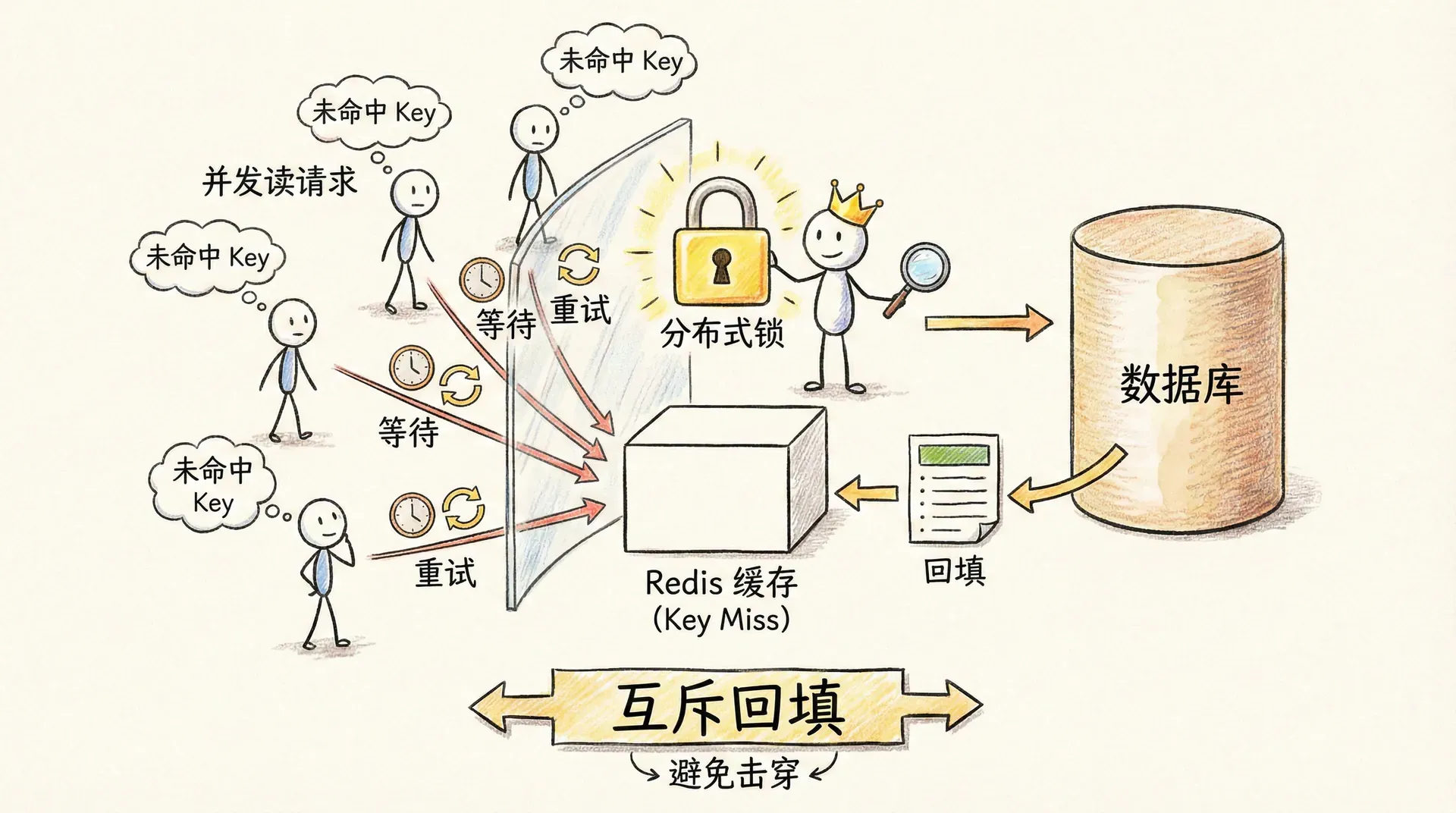
在读路径上,除了「未命中则查库并回填」,还需要考虑回填时的并发。当某个 Key 过期或被删除后,若同时有大量请求到达,可能都会发现缓存未命中,继而同时去查数据库并写回缓存,造成缓存击穿(后文详述)。常见的缓解方式是在回填时加互斥:第一个请求发现未命中后,先获取分布式锁(如 Redis SET key NX EX),再查库并回填缓存,最后释放锁;其他请求若未拿到锁,可短暂等待后重试读缓存,或直接查库(根据业务对一致性与延迟的要求权衡)。这样,同一时刻只有一个请求会回填该 Key,避免大量请求同时打穿到数据库。
text
读回填(带互斥):GET cache_key
→ 命中则返回
→ 未命中:SET lock_key NX EX 5
→ 拿到锁:SELECT ... → SET cache_key value EX ttl → DEL lock_key → 返回
→ 未拿到锁:sleep 50ms → 重试 GET cache_key(或直接查库)在写路径上,若业务允许短暂不一致,可选用「先更新数据库,再删除缓存」;若删除缓存失败,可记录日志或投递到重试队列,避免阻塞主流程。设置缓存 TTL 是最后的兜底:即使删除逻辑异常,过期后也会自动失效,避免永久脏数据。
缓存击穿、雪崩、穿透
缓存击穿指的是某个热点 Key 在过期或失效的瞬间,大量请求同时发现缓存未命中,转而同时访问数据库,导致数据库瞬时压力过大甚至被打挂。本质上是「单个 Key 失效 + 高并发」叠加的结果。应对思路包括:对热点 Key 不设置过期时间或设置较长的 TTL,由定时任务或业务逻辑在后台异步更新;若必须设置 TTL,可在基础过期时间上加随机偏移(如 ttl = 3600 + random(0, 300)),避免同一批 Key 同时过期;在回填时使用互斥锁,保证同一时刻只有一个请求回填该 Key,其他请求等待或重试读缓存。逻辑过期是另一种思路:缓存中存的数据带一个「逻辑过期时间」,读取时若发现已过逻辑过期时间,则异步触发回填,当前请求仍返回旧值(或等待回填完成),从而避免大量请求同时查库。
缓存雪崩指的是大量 Key 同时失效,或 Redis 服务整体不可用,导致大量请求在短时间内无法命中缓存,全部涌向数据库,造成数据库压力激增甚至雪崩式宕机。常见原因包括:为大量 Key 设置了相同或相近的 TTL,在某一时刻同时过期;Redis 单点故障或网络分区导致缓存层不可用。应对思路包括:为 Key 的 TTL 添加随机偏移,将过期时间打散,避免同一时刻大批量失效;使用 Redis 高可用方案(主从、Sentinel、Cluster),降低单点故障概率;在应用层做熔断与降级,当缓存或数据库异常时快速失败或返回降级数据,避免连锁反应。
缓存穿透指的是请求访问的数据在缓存和数据库中都不存在,每次请求都会穿透缓存直接打到数据库。若有人恶意构造大量不存在的 Key(如随机 ID),会持续给数据库造成压力。应对思路包括:缓存空对象,即对「查库结果为空」的情况也写入缓存(如存空串或特殊标记),并设置较短的 TTL,避免同一不存在 Key 被反复查库;使用布隆过滤器(Bloom Filter)在应用层或缓存层预先判断 Key 是否可能存在,若布隆过滤器判断不存在,则直接返回,不访问缓存和数据库。需注意布隆过滤器有误判率:判断为「存在」时可能实际不存在,判断为「不存在」时则一定不存在,因此适合与「缓存空对象」配合使用,在过滤掉大量非法请求的同时,对可能存在的 Key 仍走正常缓存与数据库路径。
text
TTL 打散:base_ttl = 3600; ttl = base_ttl + random(0, 600)
布隆过滤器:请求 Key → 若 filter 判断不存在则直接返回 404;否则走缓存/数据库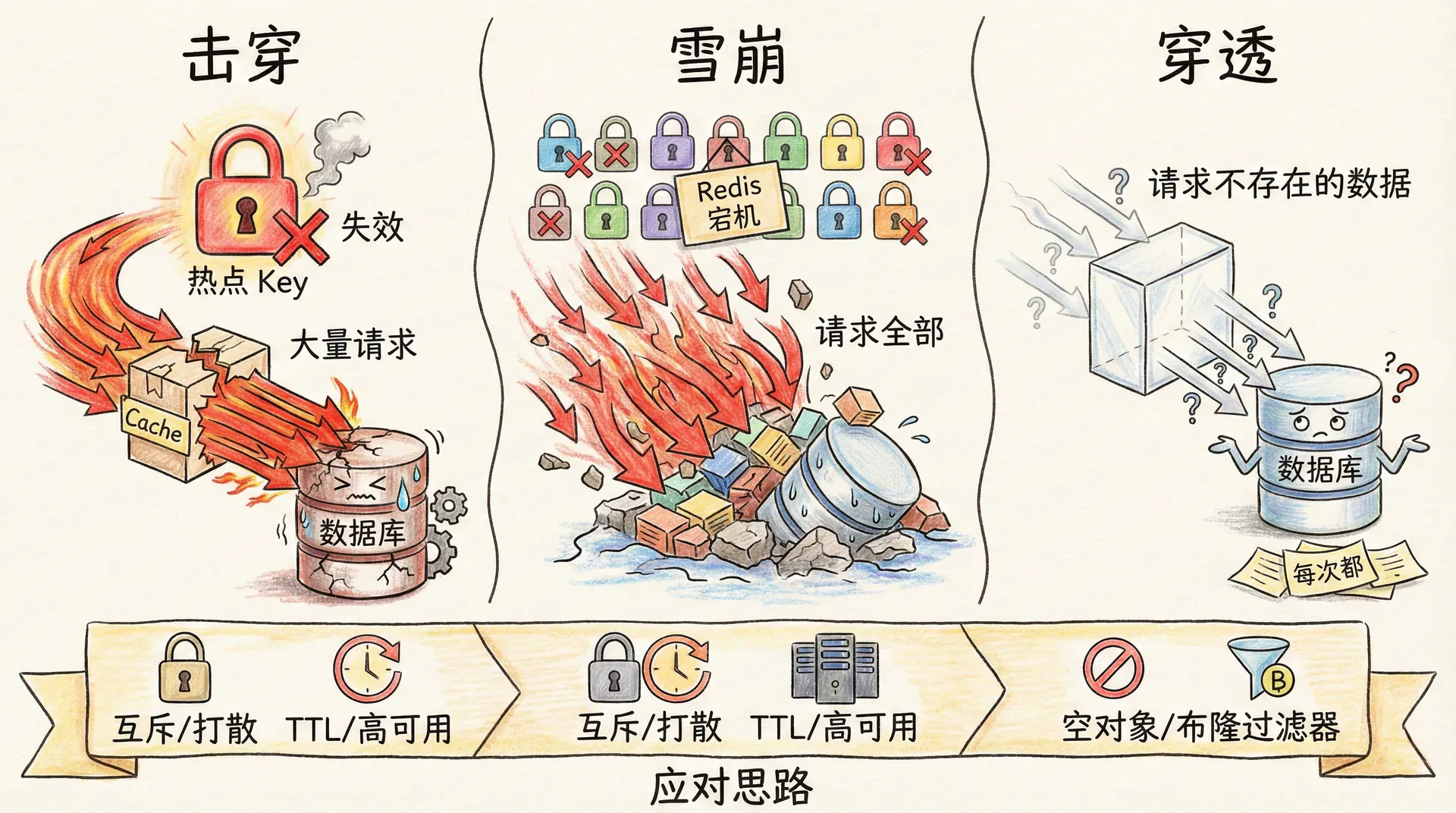
综合来看,缓存的正确使用离不开「读写策略」与「失效与异常应对」的配合。Cache Aside 的「读回填、写删缓存」奠定了基调;读回填时的互斥与写路径上的删除与重试,降低了击穿与脏数据的风险;TTL 打散、高可用与熔断缓解了雪崩;空对象与布隆过滤器缓解了穿透。在下一讲中,我们将深入缓存一致性问题:数据库与缓存如何同步、先删缓存还是先更新数据库的深层原因、以及为什么「强一致」在缓存场景下很难做到。