缓存一致性问题
在掌握了 Cache Aside 与缓存击穿、雪崩、穿透之后,我们需要深入缓存场景下最棘手的一类问题:数据库与缓存如何同步、先删缓存还是先更新数据库、以及为什么「一致性」在缓存场景下很难做到强一致。
这部分我们将围绕数据库与缓存的同步策略、操作顺序的并发影响、以及一致性的本质难点展开,帮助你在架构层面正确权衡一致性与性能。
数据库与缓存如何同步
数据库与缓存是两套独立的存储:数据库以持久化与事务为核心,缓存以速度与吞吐为核心。二者之间没有天然的「原子写」或「事务」语义,任何「先写 A 再写 B」的流程都存在中间状态:若在「写 A 完成、写 B 未完成」时发生故障或并发读,就会出现 A 与 B 不一致。因此,「同步」的本质是在「写路径」上约定顺序与失败处理,在「读路径」上约定何时以谁为准,并通过 TTL、重试、异步补偿等手段将不一致窗口控制在可接受范围内。
业界常用的同步策略可以概括为「写时删缓存、读时回填」:写请求只更新数据库,然后删除缓存中的对应 Key,不直接更新缓存;读请求先查缓存,未命中则查数据库并将结果写回缓存。 这样,写路径只负责「失效」缓存,回填由读请求在「当时数据库中的最新值」上完成,避免了「写时更新缓存」在并发写下的时序错乱。 若要进一步提高可靠性,可在「删除缓存」失败时做重试:将删除操作投递到消息队列或本地重试队列,由后台任务异步执行,直到成功或达到重试上限;同时为缓存设置 TTL,即使删除逻辑异常,过期后也会自动失效,下次读请求会从数据库加载新值,实现最终一致性。
更彻底的解耦方式是基于 binlog 的异步失效:业务代码只写数据库,不直接操作缓存;中间件(如 Canal、Debezium、Maxwell)监听数据库的 binlog 或变更事件,将「某表某行变更」解析为事件并投递到消息队列;独立的消息消费者根据事件内容删除或更新对应的缓存 Key。这样,缓存的维护与业务写路径完全解耦,删除逻辑由「数据变更」驱动,且 binlog 具备可重放性,故障恢复后仍可追平。代价是架构复杂度与组件依赖增加,且存在传递延迟(通常为毫秒到秒级),适合对一致性要求高、且基础设施完善的项目。
text
方案一(应用内):UPDATE db → DEL cache_key → 若 DEL 失败则投递重试队列
方案二(binlog):业务只 UPDATE db → CDC 解析 binlog → MQ → 消费者 DEL cache_key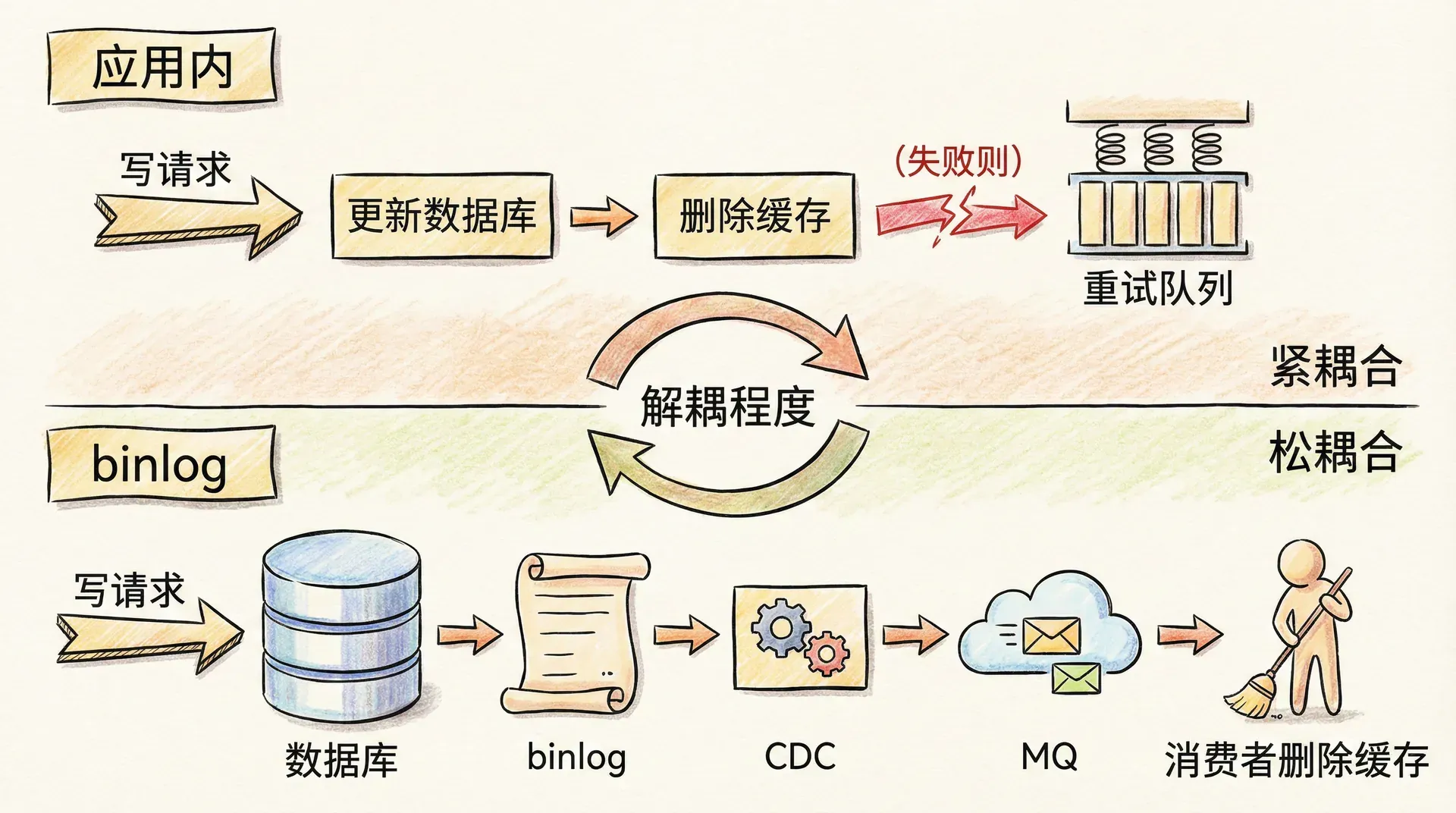
先删缓存还是先更新数据库
「先删缓存再更新数据库」与「先更新数据库再删缓存」在并发下的表现有本质差异。若采用先删缓存再更新数据库:在删除缓存之后、数据库更新完成之前,若有读请求到达,会因缓存未命中而查数据库,此时读到的仍是旧值,并将其写回缓存;随后数据库更新完成,但缓存中已被回填为旧数据,且该旧缓存会一直保留到下次失效或删除,不一致窗口较长。因此,先删缓存再更新数据库,在读写并发时更容易出现「读请求把旧数据写回缓存」的脏读问题。
若采用先更新数据库再删缓存:在数据库更新完成之后、删除缓存完成之前,若有读请求到达,可能仍会命中旧缓存并返回旧值,存在短暂的不一致窗口;但一旦删除缓存成功,后续读请求会因未命中而从数据库加载新值并回填,不一致会自然消除。与「先删缓存再更新数据库」相比,先更新数据库再删缓存的脏读窗口更短,且「删除缓存」若失败,可以通过重试或 TTL 兜底恢复,而先删缓存再更新数据库时,若数据库更新失败或延迟,缓存已被删,大量读请求会直接打数据库,压力与不一致风险都更大。因此,在工程上普遍推荐先更新数据库,再删除缓存,并配合删除失败重试与 TTL 兜底。
延迟双删是在「先删缓存再更新数据库」基础上的一种补救:在更新数据库之后,延迟一段时间(如几百毫秒到一秒)再执行一次删除缓存,目的是清除「在第一次删缓存与数据库更新完成之间」被并发读请求回填进缓存的旧数据。延迟时间需要大于「主从同步延迟(若读走从库)+ 单次读请求耗时 + 网络缓冲」,否则第二次删除可能仍早于脏数据回填,难以精确设定,且第二次删除也可能失败,因此通常作为对一致性要求较高场景的补充手段,而非唯一依赖。
text
先删缓存再更新 DB:DEL cache → UPDATE db → 期间读请求会回填旧缓存,不一致窗口长
先更新 DB 再删缓存:UPDATE db → DEL cache → 期间可能读到旧缓存,但删成功后即恢复
延迟双删:DEL cache → UPDATE db → sleep(delay) → DEL cache(清除并发回填的旧数据)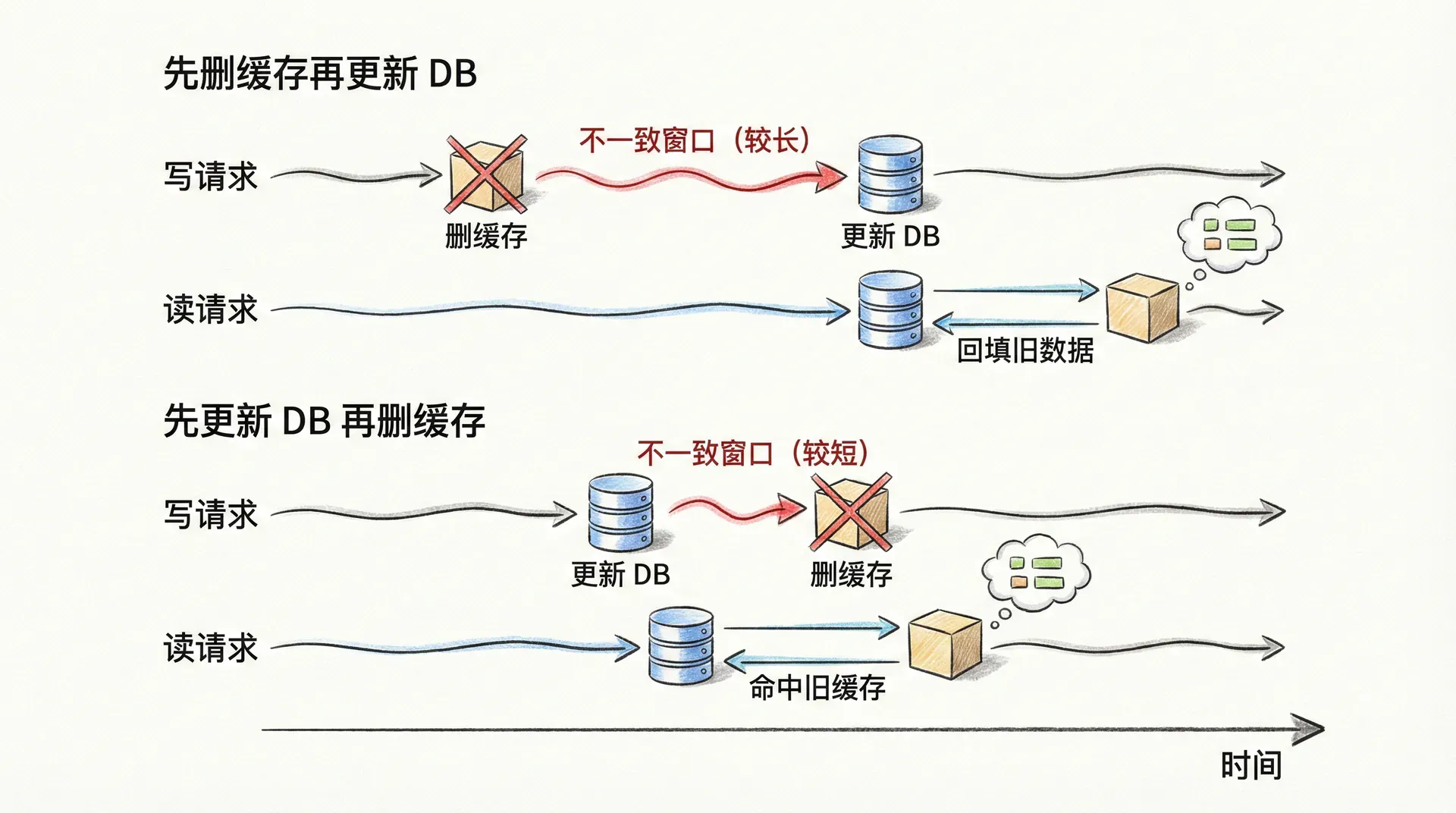
为什么「一致性」很难
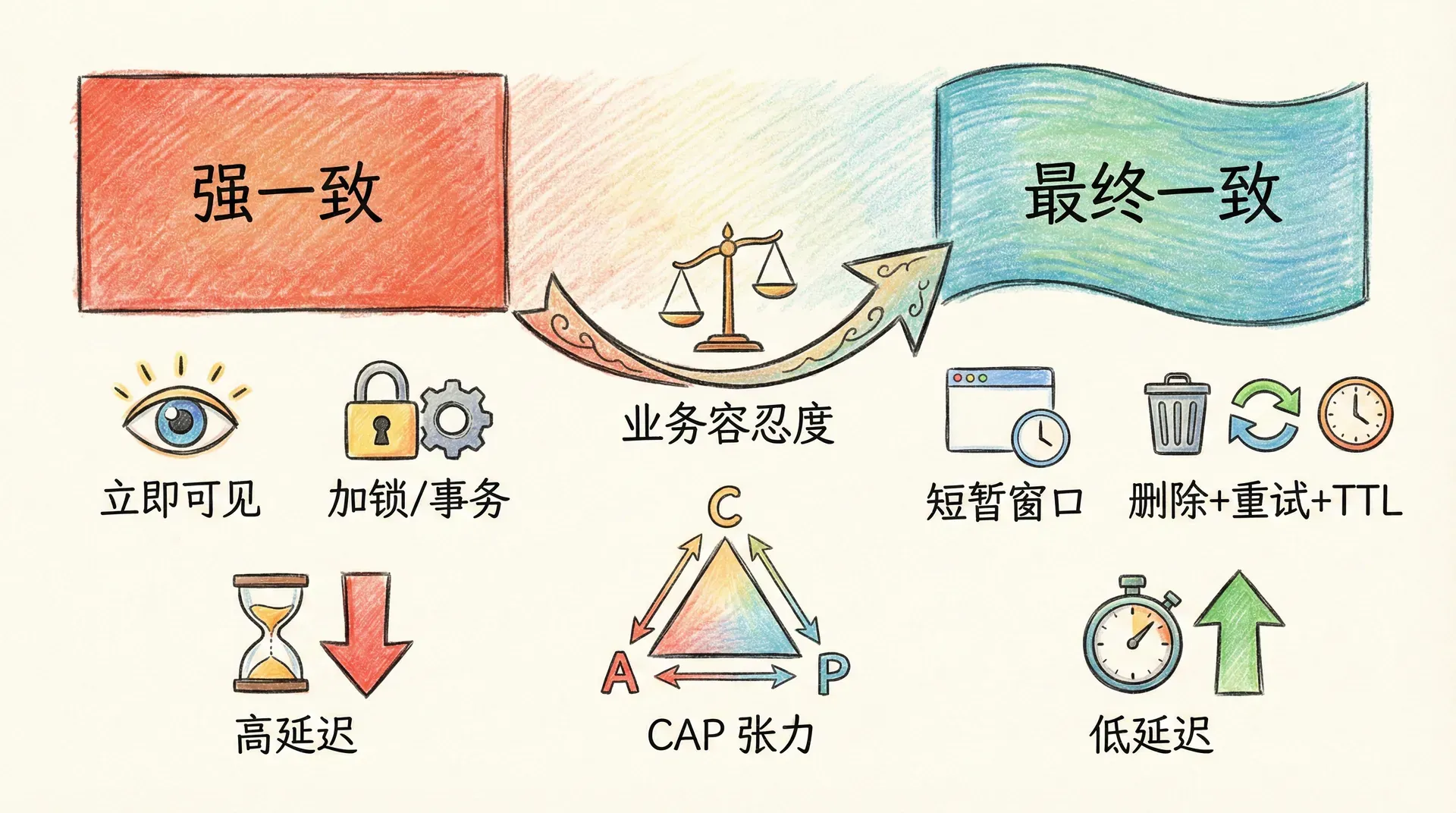
缓存一致性问题之所以难,根源在于数据库与缓存是两个独立系统,对同一份逻辑数据的更新必然分解为多步操作(如先更新数据库、再删除缓存),这几步之间没有分布式事务或原子性保证。网络延迟、进程 GC、队列积压等因素会导致操作乱序或延迟,在高并发下极易出现「写请求的删除缓存晚于读请求的回填」或「读请求在写请求更新数据库之前就回填了缓存」等时序问题。因此,在不引入强一致协议(如分布式锁、两阶段提交)的前提下,只能通过「约定顺序 + 重试 + TTL」将不一致窗口压到尽可能小,无法做到「写入后立即可见」的强一致。
从设计目标看,数据库与缓存本就存在张力:数据库追求 ACID、持久化与一致性,缓存追求低延迟与高吞吐,二者在「何时落盘」「何时可见」上天然不同步。若要在缓存层实现强一致,通常需要让每次写请求在更新数据库后、删除缓存完成前阻塞读请求,或让读请求在缓存未命中时串行化地回填,这会显著增加延迟与复杂度,甚至把缓存变成「带缓存的数据库」,失去缓存的意义。因此,业界普遍接受最终一致性:允许在极短时间窗口内读到旧值,但通过删除缓存、重试与 TTL 保证在一段时间(如秒级)后达到一致,从而在「一致性」与「性能」之间取得平衡。
CAP 定理从分布式系统角度给出了另一种解释:在存在网络分区或延迟的前提下,一致性(C)、可用性(A)与分区容错性(P)难以同时满足。缓存作为「可失效的副本」,在设计上更偏向可用性与分区容错性,通过允许短暂不一致来保证高可用与低延迟;若强求「缓存与数据库始终一致」,则需要在每次写时同步失效或更新所有副本,延迟与故障域都会上升。因此,不必追求缓存与数据库的强一致,而是根据业务容忍度选择策略:对库存、支付等强一致场景,可考虑读主库、加锁或分布式事务;对点赞、动态等可接受秒级不一致的场景,采用「先更新数据库再删缓存 + TTL」即可。在下一讲中,我们将进入 Redis 的另一种经典应用:分布式 Session,届时会讨论 Session 为何不能放内存、Redis Session 的实现方式以及登录态在分布式系统中的流转。