分布式 Session
在解决了缓存与一致性问题之后,我们进入 Redis 的另一种经典应用:分布式 Session。Session 用于在无状态的 HTTP 之上维持「用户是谁、是否已登录」等状态; 在单机时代,Session 放在应用进程内存中即可,但在多实例、负载均衡与微服务架构下,内存中的 Session 无法跨进程共享,导致用户在不同实例间「掉线」。
这部分我们将围绕 Session 为什么不能放内存、Redis Session 的实现方式、以及登录态在分布式系统中的流转展开,帮助你在架构层面正确设计登录态与会话管理。
Session 为什么不能放内存
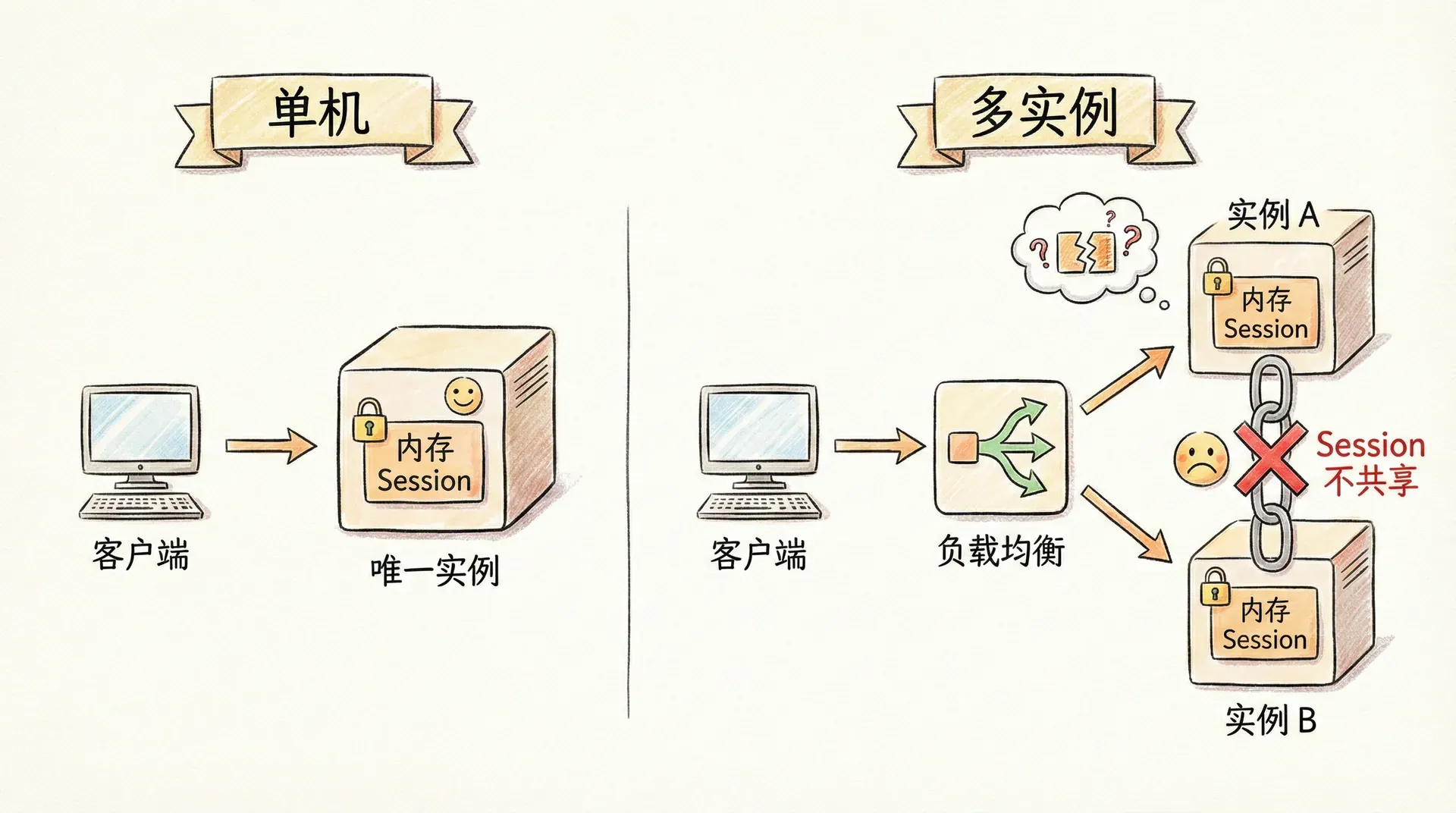
在单机部署时,应用进程的内存是「唯一」的存储:用户登录后,服务端在内存中创建 Session,并将 Session ID 通过 Cookie 或 URL 回传给客户端;后续请求携带该 ID,服务端从内存中取出对应 Session,即可识别用户。此时 Session 的读写都在同一进程内完成,无需跨网络、无需共享,逻辑简单且延迟低。
一旦引入多实例与负载均衡,同一用户的请求可能被分发到不同实例。用户第一次请求被分配到实例 A 并完成登录,Session 被写入 A 的内存;第二次请求若被分配到实例 B,B 的内存中并没有该用户的 Session,服务端无法识别用户,只能要求用户重新登录。这就是「Session 不能放内存」在分布式环境下的本质问题:每个实例的内存是隔离的,Session 数据无法跨实例共享,而负载均衡又无法保证同一用户始终命中同一实例(若强行通过「会话保持」即粘性 Session 保证,则实例宕机时该实例上的所有 Session 会丢失,且负载会不均衡)。
与此密切相关的是扩展性与故障域。若 Session 全部放在应用内存中,随着在线用户数增长,单实例内存会成为瓶颈,且实例重启或宕机时,该实例上的所有用户都会掉线。因此,在分布式架构下,Session 必须从「进程内内存」迁移到「进程外、可被多实例共享」的存储,而 Redis 凭借其低延迟、高并发与丰富的数据结构,成为集中式 Session 存储的主流选择。
Redis Session 的实现方式
Redis Session 的核心思路是用 Redis 替代应用内存作为 Session 的存储后端:用户登录后,服务端不再在本地内存中创建 Session,而是将 Session 数据序列化后写入 Redis,Key 通常为 session:{sessionId} 或 session:{业务前缀}:{sessionId},Value 为序列化后的用户信息、权限、过期时间等;Session ID 仍通过 Cookie(如 JSESSIONID)或响应头回传给客户端,后续请求携带该 ID,任意实例从 Redis 中读取对应 Key 即可恢复会话。这样,所有实例共享同一份 Session 数据,无论请求被分配到哪台机器,都能正确识别用户。
在实现层面,需要解决几件事。一是序列化:Session 中的对象(如用户实体、权限列表)需要序列化为可在 Redis 中存储的格式(如 JSON 或二进制),读取时再反序列化;序列化方式影响存储体积与兼容性,需与客户端、多语言网关等约定一致。二是过期:Session 通常有过期时间(如 30 分钟无操作则失效),Redis 的 Key 可设置 TTL,例如 EXPIRE session:xxx 1800,到期自动删除,无需应用层定时清理。三是与现有框架集成:例如在 Java 中,Spring Session 提供了对 Servlet Session 的透明替换,只需配置 Redis 作为 Session 存储后端,应用代码仍使用 HttpSession.getAttribute() / setAttribute(),底层会读写 Redis;其他语言也有类似中间件或约定,将「Session 存储」从内存切换到 Redis。
text
登录成功:生成 sessionId → 序列化用户信息 → SET session:{sessionId} value EX 1800
请求到达:从 Cookie 取 sessionId → GET session:{sessionId} → 反序列化 → 校验过期
登出或过期:DEL session:{sessionId} 或依赖 TTL 自动删除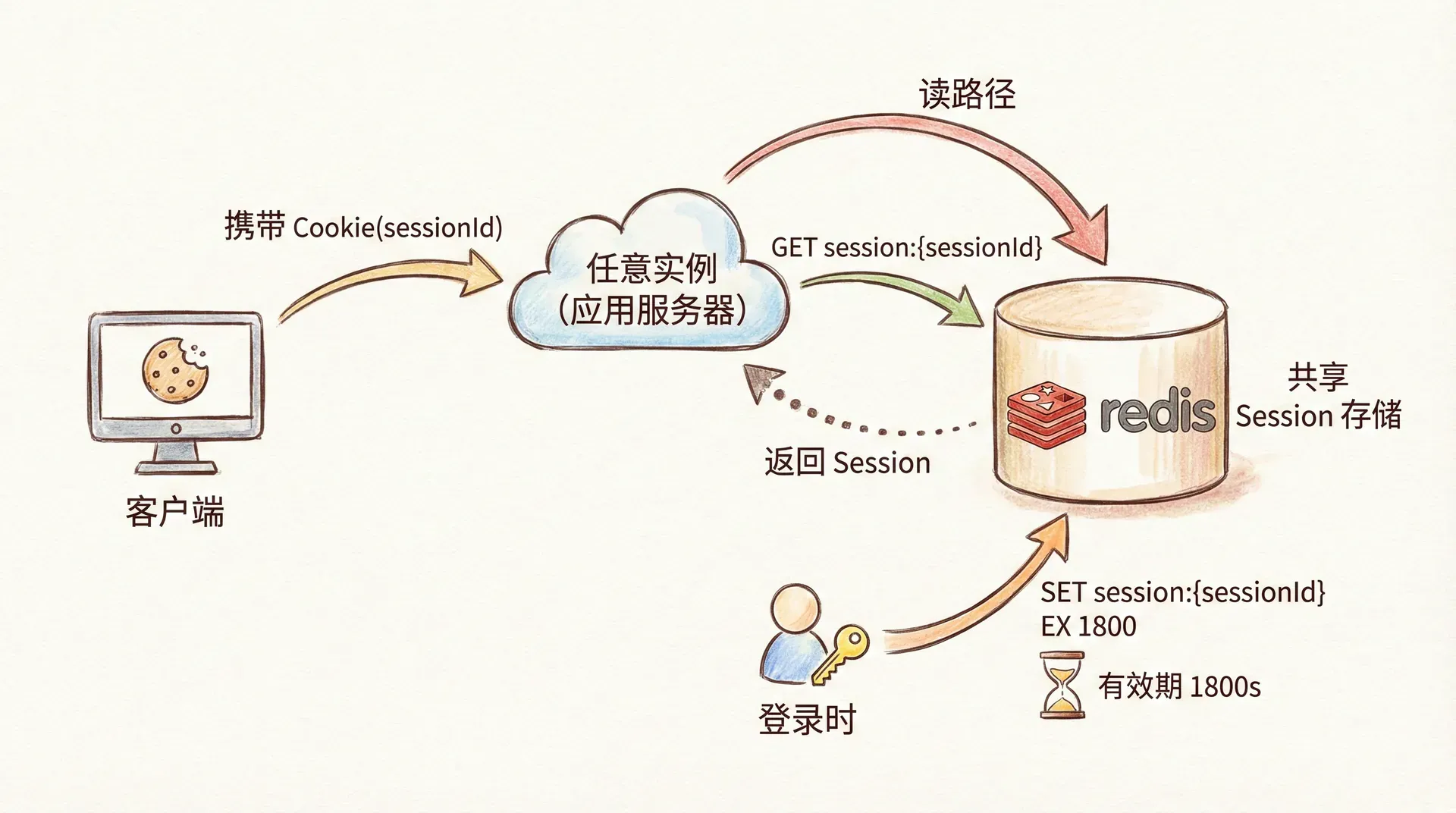
与此密切相关的是安全与性能。Session 数据中可能包含敏感信息(如用户 ID、角色、权限),应避免在 Cookie 中直接存明文,只存 Session ID;Redis 中的 Value 也可做加密或脱敏。在性能上,每次请求都会有一次或多次 Redis 访问(读 Session、可能续期 TTL),因此 Redis 的延迟与可用性会直接影响登录态校验的延迟与可用性;通常会对 Session 读做本地缓存或短 TTL 缓存,在保证一致性的前提下减少对 Redis 的访问。此外,若使用多级缓存(如 Nginx 缓存、应用本地缓存),需注意 Session 变更时的失效策略,避免读到过期或已登出的会话。
登录态在分布式系统中的流转
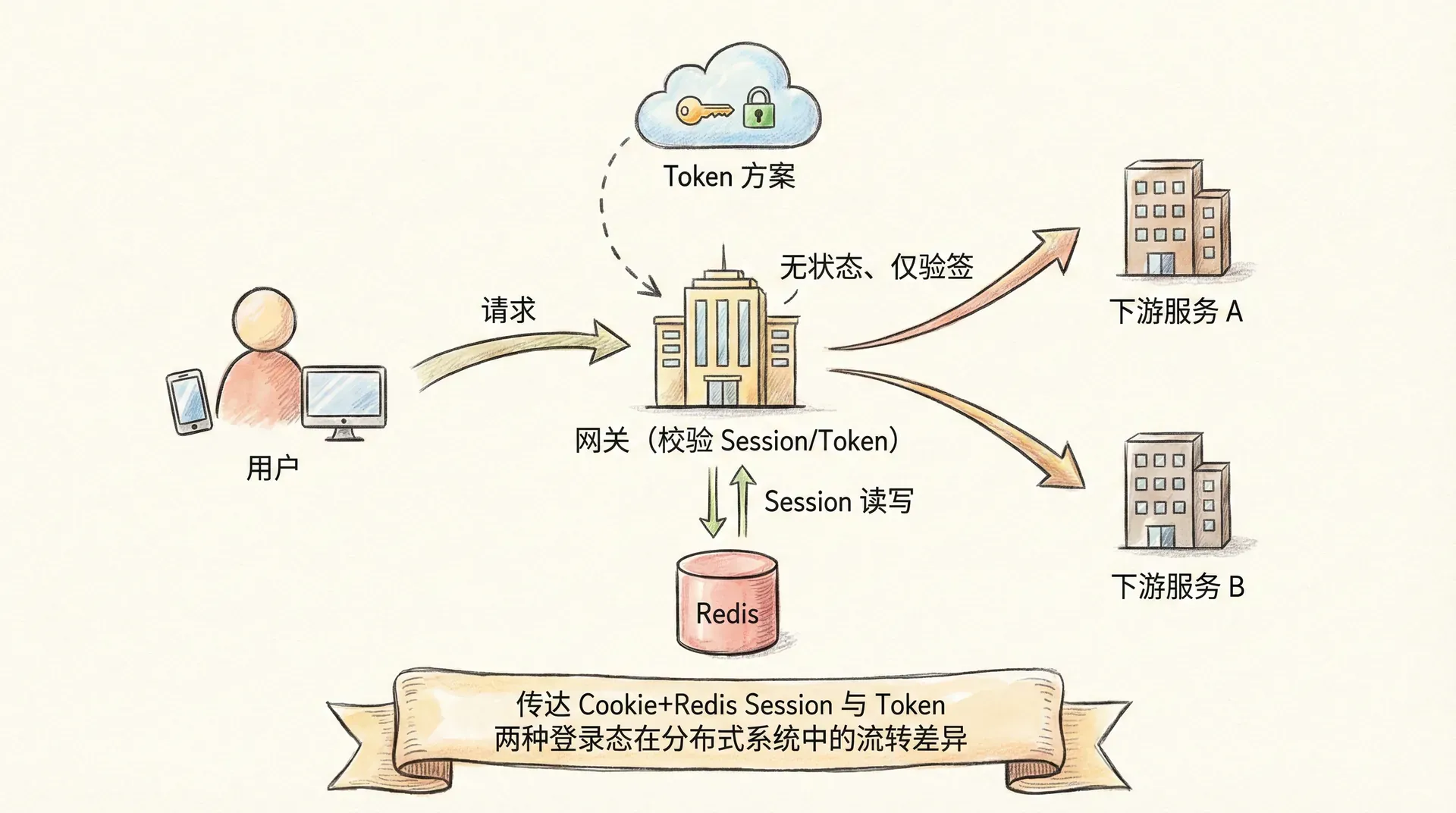
登录态在分布式系统中的「流转」,指的是从用户登录到后续请求被正确识别的整条链路:谁生成登录态、谁存储、谁校验、谁失效。在 Cookie + Session(Redis 存储) 方案下,流转大致如下:用户登录成功后,服务端生成 Session ID,将用户信息写入 Redis(Key 为 session:{sessionId},TTL 如 30 分钟),并通过 Set-Cookie 将 Session ID 下发给浏览器;浏览器在后续请求中自动携带该 Cookie,网关或应用从 Cookie 中取出 Session ID,向 Redis 查询对应 Session,若存在且未过期则认为用户已登录,并将用户信息注入到当前请求上下文中(如 ThreadLocal 或请求属性)。登出时,服务端删除 Redis 中对应 Key,并通知浏览器清除或过期 Cookie,登录态即失效。
另一种常见方案是 Token(如 JWT):登录成功后,服务端不存储 Session,而是签发一个签名的 Token,Token 的 Payload 中编码用户 ID、过期时间等;客户端将 Token 存在 Cookie 或本地存储,每次请求在 Header(如 Authorization: Bearer <token>)中携带;服务端通过验证签名与过期时间即可识别用户,无需查 Redis。Token 方案的优势是无状态:服务端不存会话数据,水平扩展时无需共享存储,且适合跨域与移动端。劣势是 Token 一旦签发,在过期前难以主动失效(如用户改密码、管理员踢人),通常需要配合黑名单(将需失效的 Token ID 写入 Redis)或缩短 Token 有效期并用 Refresh Token 续期,在「无状态」与「可撤销」之间权衡。
在微服务架构下,登录态可能需要在网关与多个下游服务之间传递。常见做法是网关统一做登录校验:请求到达网关时,从 Cookie 或 Header 中取出 Session ID 或 Token,校验通过后,将用户 ID 或关键信息注入到请求头(如 X-User-Id)再转发给下游;下游服务只信任网关注入的信息,不再直接访问 Redis 或验签,从而降低下游与 Session 存储的耦合,也减少重复的 Redis 访问。此时,登录态的「生成与存储」集中在用户中心或网关,流转路径为「客户端 → 网关(校验 Session/Token)→ 下游(使用网关注入的身份信息)」,Redis 若用于 Session 存储,则主要被网关或用户中心访问。
综合来看,分布式 Session 的核心是将「谁已登录」从单机内存迁移到共享存储,Redis 凭借低延迟与 TTL 能力成为主流选择;实现时需关注序列化、过期、与框架的集成以及安全与性能。登录态的流转则需明确「谁生成、谁存储、谁校验、谁失效」,在 Cookie+Redis Session 与 Token 无状态方案之间根据扩展性、可撤销性与跨域需求做权衡。在下一讲中,我们将进入 Redis 的另一种经典应用:计数器与限流,届时会讨论访问计数、接口限流与滑动窗口思想,这些场景同样依赖 Redis 的原子操作与数据结构能力。