常见连续分布:均匀、指数、正态、Gamma 与 Beta
上一章把连续随机变量的基本语言搭好了:密度不是概率本身,区间概率来自曲线下面积。本章开始把这些语言用到几类反复出现的模型上。
这五个分布族不应只靠公式记忆。更可靠的入口是先问三个问题:随机变量能取哪些值,随机性来自什么机制,参数改变时密度形状怎样变化。回答清楚这三件事,公式通常就有了位置。
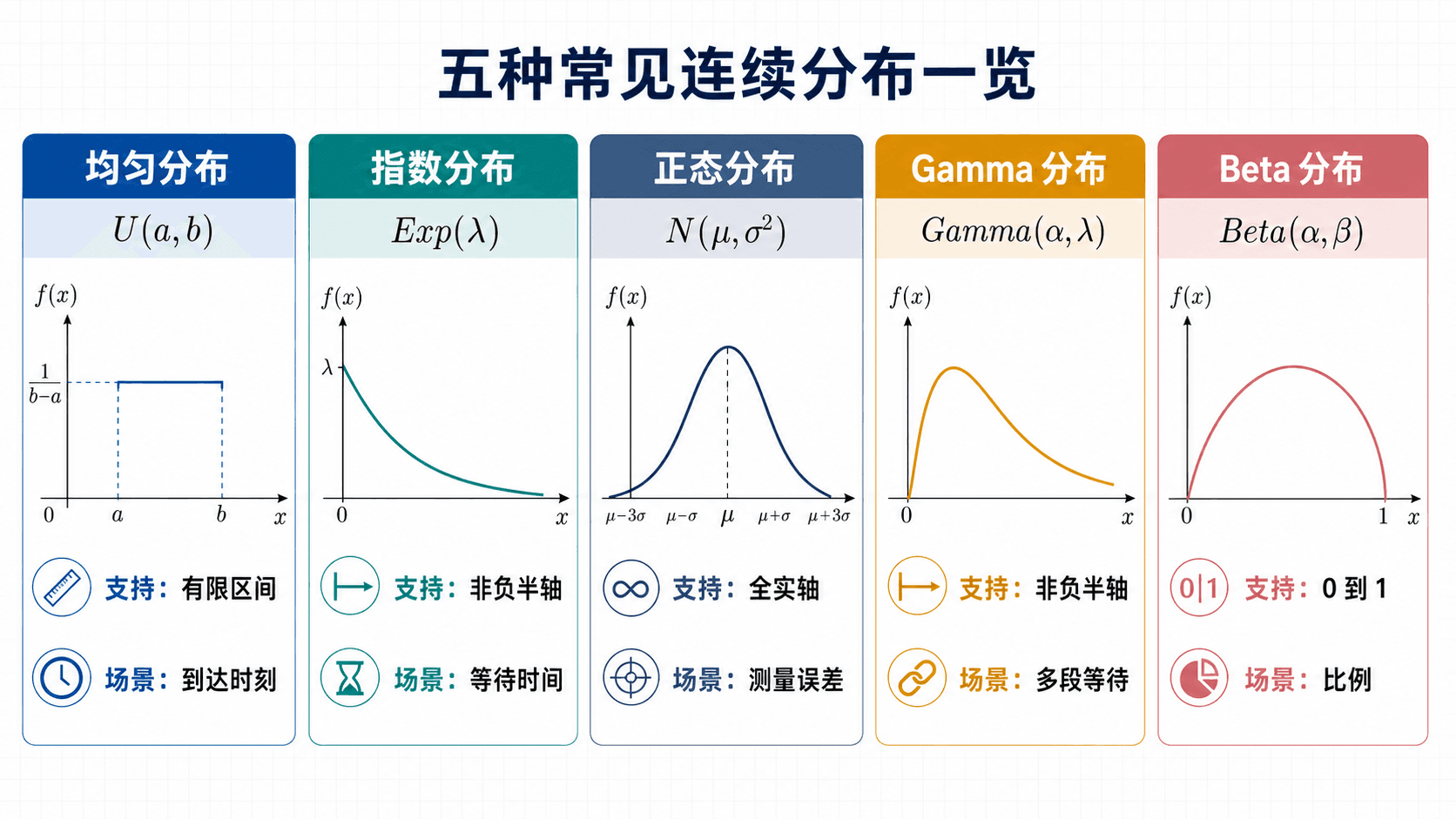 常见连续分布的支持集、形状与建模场景总览。
常见连续分布的支持集、形状与建模场景总览。
先看分布族的角色
连续分布的参数有两层含义。第一层是计算含义,例如密度函数、均值和方差怎样由参数决定;第二层是建模含义,例如参数代表区间端点、平均等待率、中心位置、尺度大小,还是比例证据的强弱。
选分布时先看支持集。考试和建模中最常见的错误之一,是把只能为正的等待时间套成正态分布,或把比例数据套成无界分布。密度曲线长得像只是线索,变量能不能取那些值才是底线。
均匀分布:只知道范围时的等密度
如果 X 在区间 [a,b] 上均匀分布,记作 X∼U(a,b)。它的密度在区间内保持常数,在区间外为 0:
fX(x)=⎩
整个矩形面积必须为 1,所以高度只能是 1/(b−a)。因此均匀分布的区间概率就是长度比例:
P(c≤X≤d)=b−ad−c,a
均匀分布的均值和方差是
E(X)=2a+b,Var(X)=
![连续均匀分布在区间 [a,b] 上的等高密度矩形,并用色块标出子区间 [c,d] 的概率面积。](https://media.edu-free.com/uploads/uniform_distribution_density_area_0293989552.png) 连续均匀分布的区间概率等于密度矩形下对应子区间的面积,即 P(c≤X≤d)=(d−c)/(b−a)。
连续均匀分布的区间概率等于密度矩形下对应子区间的面积,即 P(c≤X≤d)=(d−c)/(b−a)。
例如,一个同学会在 8:00 到 9:00 之间随机到达教室,且没有理由认为哪一分钟更常见。令 X 表示 8:00 后到达的分钟数,则 X∼U(0,60)。在 8:10 到 8:25 之间到达的概率是
P(10≤X≤25)=6025−10=0.25.
连续均匀分布里,P(X=10)=0。所以 P(10≤X≤25)、P( 和 的值相同。端点是否包含通常不改变连续型区间概率。
指数分布:等待下一次到达
指数分布常用于描述“从现在开始等到下一次事件”的时间。若 X∼Exp(λ),这里使用 rate 参数 λ>0,密度为
fX(x)={λe
它的分布函数和生存函数分别是
FX(x)=1−e−λx,S
均值和方差是
E(X)=λ1,Var(X)=λ
λ 越大,事件越频繁,等待时间越短。指数密度在 0 附近最高,然后单调下降,这和“短等待比长等待更常见”的直觉一致。
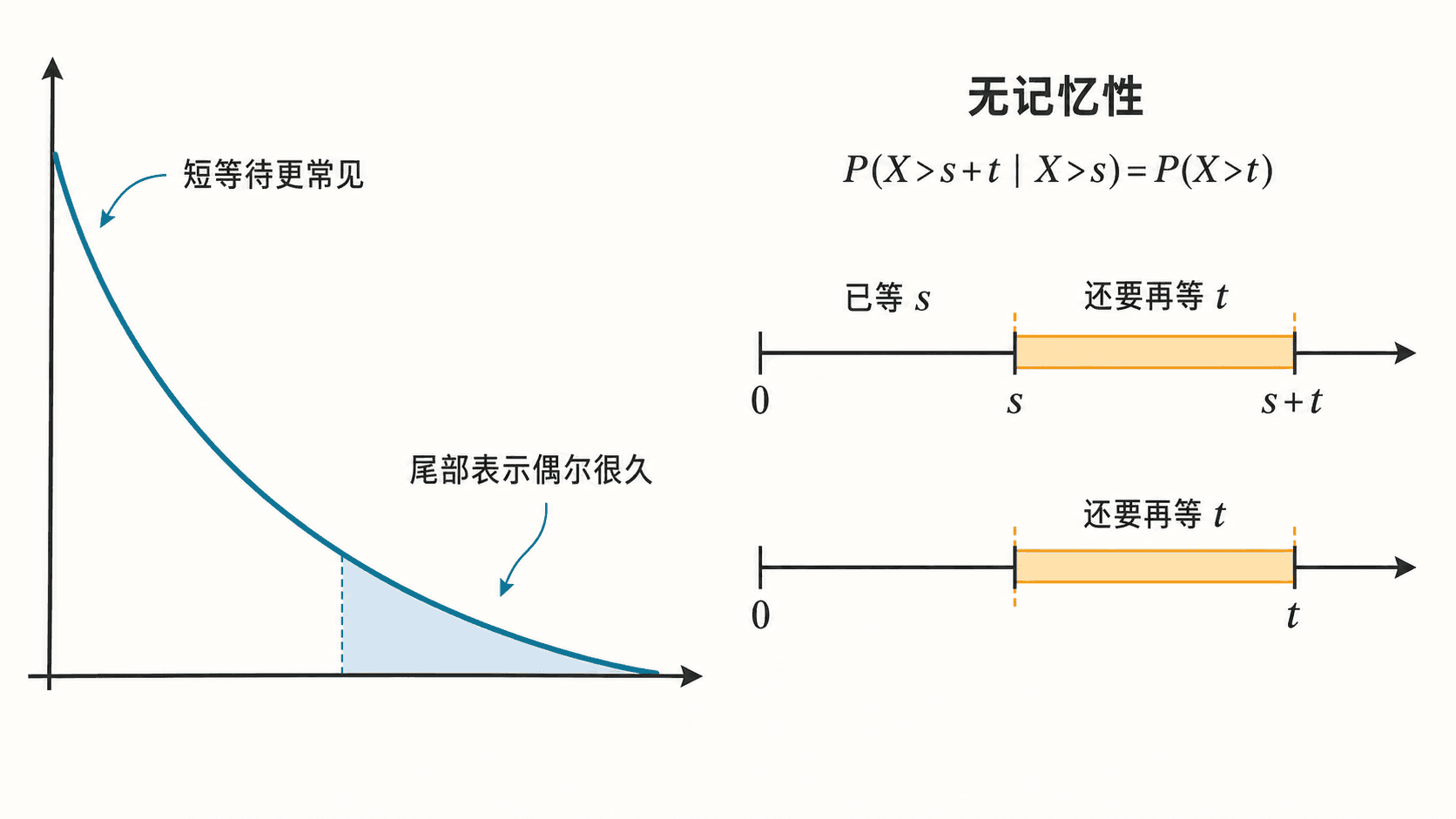 指数分布中短等待更常见,长尾表示偶尔等待很久;无记忆性说明已等待 s 后,未来再等 t 的概率与重新开始等待 t 相同。
指数分布中短等待更常见,长尾表示偶尔等待很久;无记忆性说明已等待 s 后,未来再等 t 的概率与重新开始等待 t 相同。
指数分布最特别的性质是无记忆性:
P(X>s+t∣X>s)=P(X>t),s,t
用生存函数验证这件事很直接:
P(X>s+t∣X>s)=
假设客服中心平均每 8 分钟收到一次电话,并把下一通电话到来的等待时间近似为指数分布。此时 λ=1/8。从现在开始等超过 10 分钟的概率是
P(X>10)=e−10/8≈0.2865.
如果已经等了 5 分钟还没有电话,再等超过 10 分钟的条件概率仍然是 e−10/8。这个结论很强,但也很挑剔:它依赖“到达率稳定、过去没有提供关于未来率变化的信息”这类建模假设。
正态分布:位置、尺度与标准化
正态分布用于描述围绕中心波动的连续量。若 X∼N(μ,σ2),其中 σ>0,密度为
fX(x)=σ2π
参数 μ 控制中心位置,σ 控制曲线宽窄:
E(X)=μ,Var(X)=σ2.
正态分布的概率通常通过标准化计算。令
Z=σX−μ.
则 Z∼N(0,1)。于是
P(l≤X≤r)=P(σl−μ
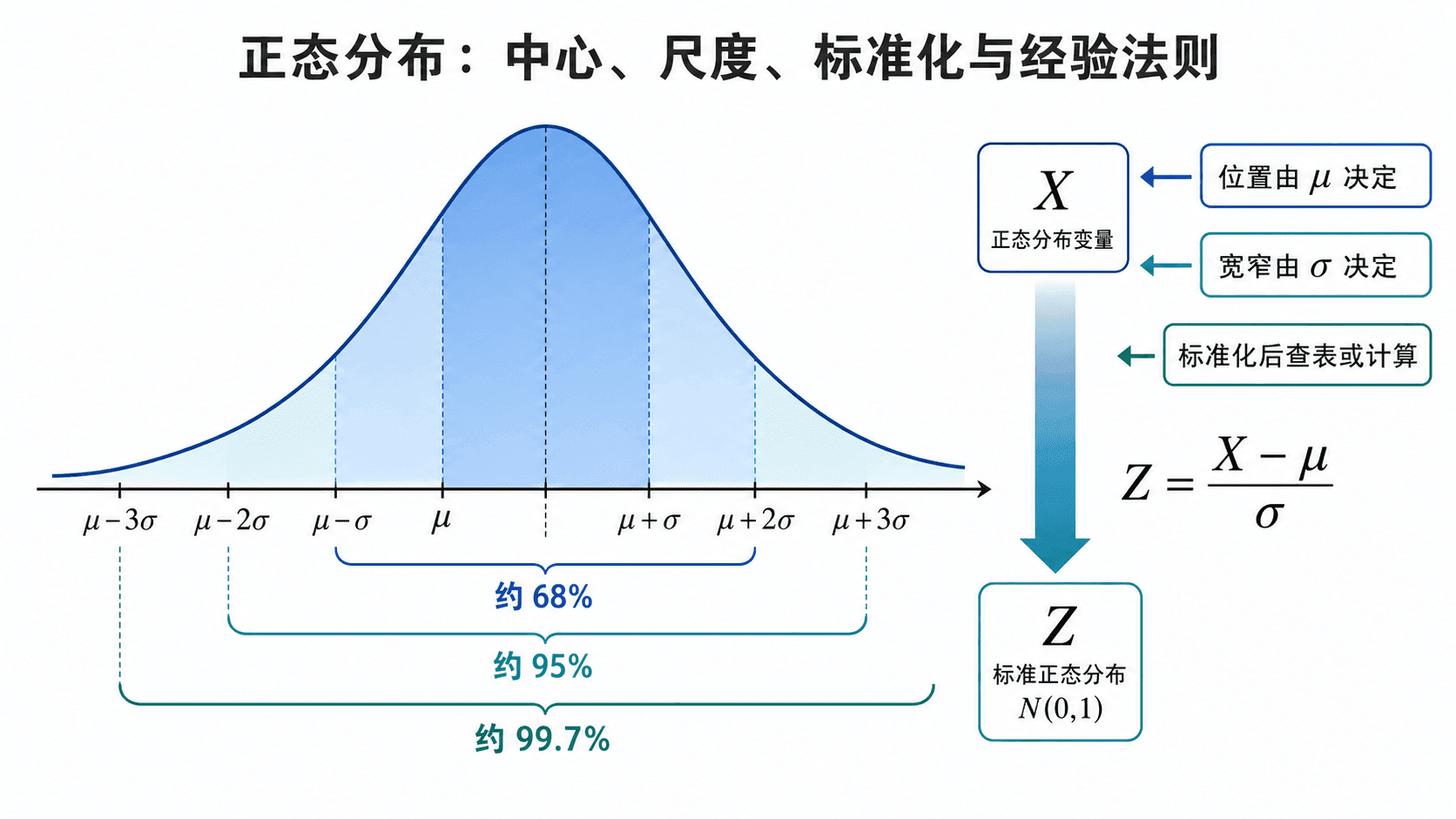 正态分布的中心由 μ 决定,宽窄由 σ 决定;标准化后可查表或计算概率。
正态分布的中心由 μ 决定,宽窄由 σ 决定;标准化后可查表或计算概率。
例题:某测量误差近似服从 N(72,62)。求落在 66 到 84 之间的概率。
先把端点标准化。左端点给出 z1=(66−72)/6=−1,右端点给出 。
钟形曲线不自动等于正态分布。正态模型还隐含对称、尾部下降方式和全实轴支持等假设。身高、测量误差、平均值近似常会用正态,但等待时间、收入、比例这类变量往往需要先看取值范围和偏态。
Gamma 分布:把若干段等待时间相加
Gamma 分布也定义在非负半轴上。它比指数分布更灵活,可以描述从“下一次到达”扩展到“等到第若干次到达”的总等待时间。若 X∼Gamma(α,λ),这里使用形状参数 α>0 和 rate 参数 λ>0,密度为
fX(x)=⎩
其中 Gamma 函数满足 Γ(n)=(n−1)!,当 n 是正整数时把阶乘自然延伸到了密度公式里。Gamma 分布的均值和方差是
E(X)=λα,Var(X)=λ
当 α=1 时,Gamma 分布就是指数分布。当 α=k 是正整数时,它也称为 Erlang 分布,可解释为 k 个独立指数等待时间之和。
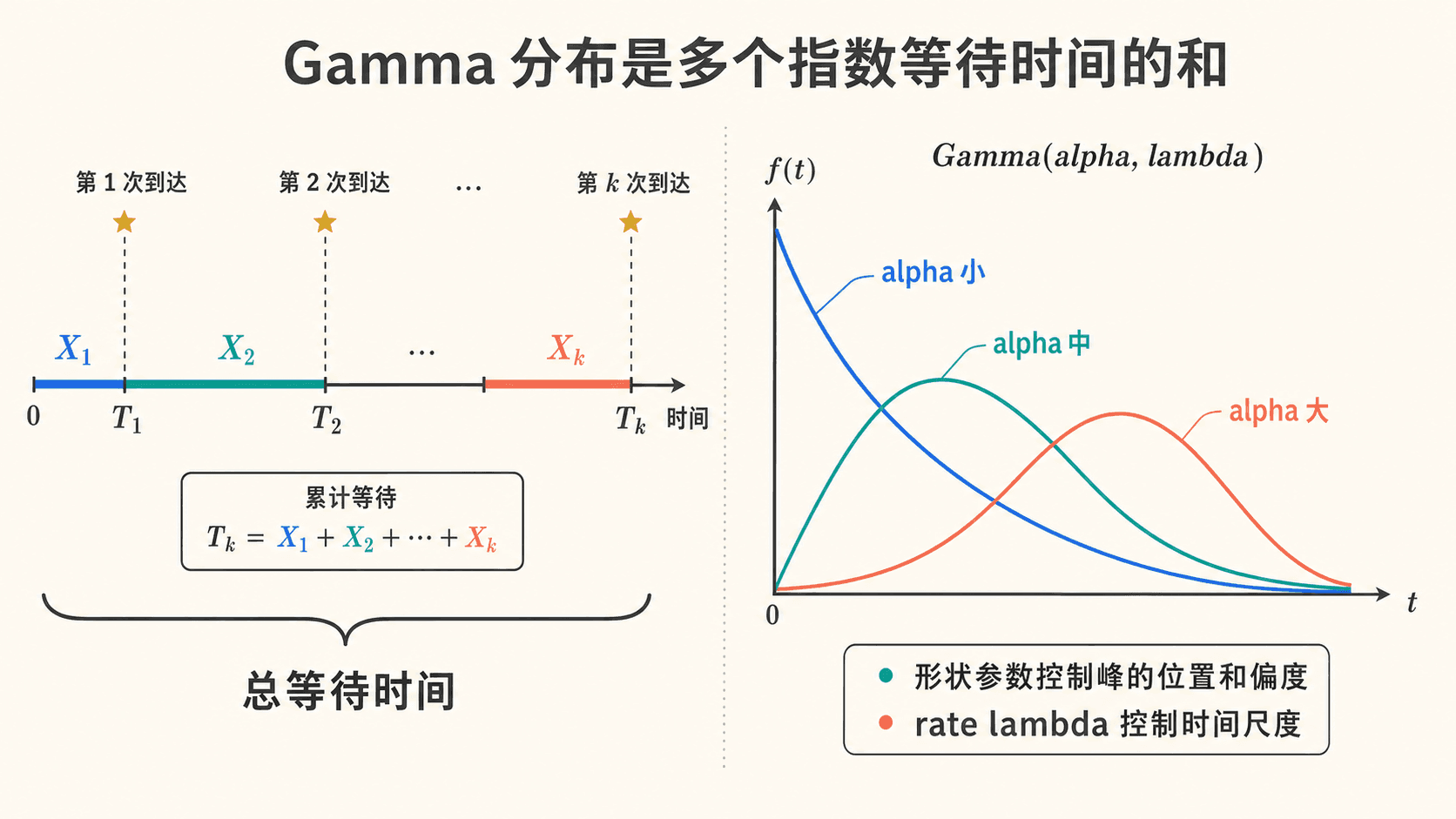 Gamma 分布可理解为多次独立到达的累计等待时间;形状参数控制峰的位置和偏度,rate λ 控制时间尺度。
Gamma 分布可理解为多次独立到达的累计等待时间;形状参数控制峰的位置和偏度,rate λ 控制时间尺度。
例题:某系统事件按每小时平均 3 次的稳定率到达。令 T 表示等到第 4 次事件到达所需时间。求 T 不超过 1 小时的概率。
等到第 4 次事件不超过 1 小时,等价于 1 小时内事件数至少为 4 次。
若到达过程可近似为 Poisson 过程,则 1 小时内事件数 N(1)∼Poisson(3),而 。
这里的计算展示了 Gamma 与 Poisson 的联系:一个看等待时间,一个看固定时间内的到达次数。
Beta 分布:专为比例而生
Beta 分布定义在 [0,1] 上,适合描述比例、概率、命中率、转化率这类有边界的量。若 X∼Beta(α,β),其中 α,β>0,密度为
fX(x)=⎩
归一化常数 B(α,β) 使密度曲线下面积等于 1。它和 Gamma 函数的关系是
B(α,β)=Γ(α+β)Γ(α)Γ(β).
Beta 分布的均值和方差是
E(X)=α+βα,Var(X)=
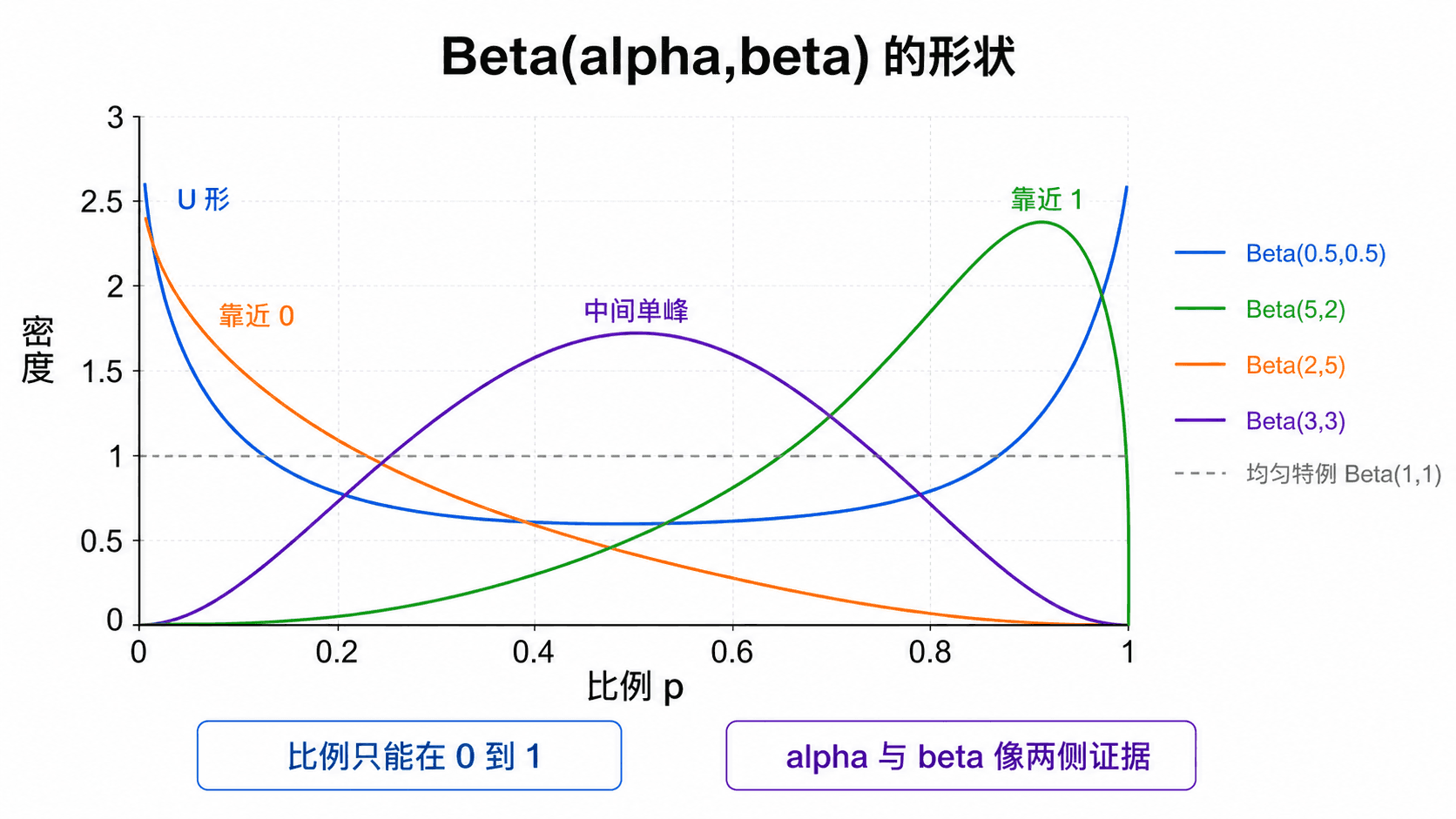 Beta 分布在 0 到 1 上可以表达多种比例形状,α 与 β 可理解为两侧证据。
Beta 分布在 0 到 1 上可以表达多种比例形状,α 与 β 可理解为两侧证据。
参数可以这样理解:α 倾向于把质量推向 1,β 倾向于把质量推向 0,两者总量越大,分布通常越集中。这个解释在后续学习 Bayesian 模型时会变得更正式;在本章,只需把它当作比例建模的形状直觉。
几个典型形状值得记住:
例子:若某产品转化率 p 的不确定性用 Beta(8,2) 表示,则
E(p)=8+28=0.8.
这不是说转化率一定等于 0.8,而是说当前模型把概率质量放在较高比例附近,并且仍保留不确定性。
分布之间的联系与选型
这五个分布族之间有不少直接关系。把这些关系连起来,比单独背五张公式表更稳。
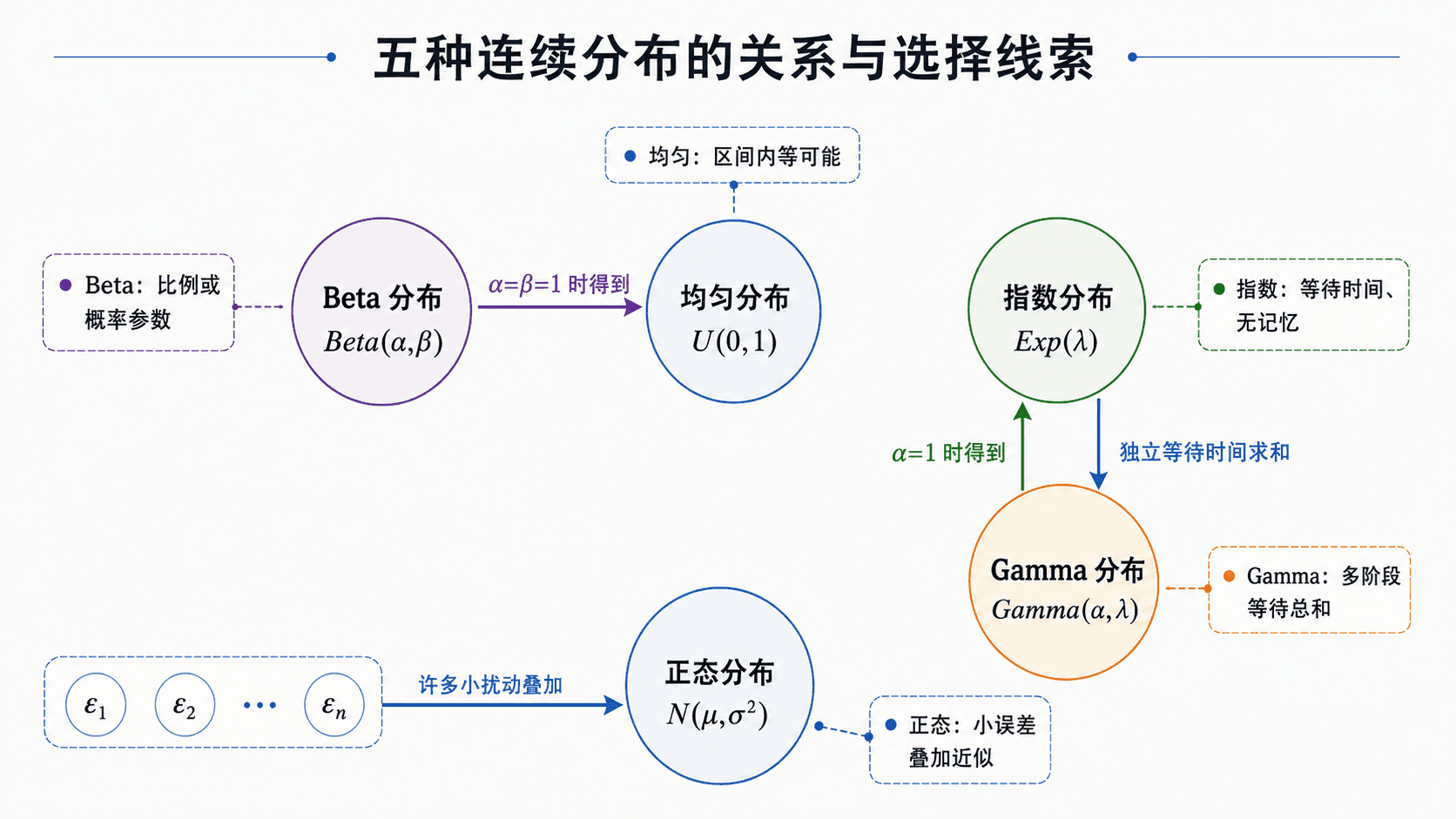 常见连续分布之间的联系与选型线索。
常见连续分布之间的联系与选型线索。
一个实用判断顺序是:先看取值范围,再看生成机制,最后看形状。范围错了,模型通常已经不合适;机制对了,参数才有解释;形状用来检查模型是否和数据的粗略特征一致。
综合例题:从场景到分布
下面的例题不急着计算,重点是把现实描述翻译成分布语言。
“一辆校车会在 7:30 到 7:50 间任意时刻到站,且没有更多信息。”若令 X 表示到站时间相对 7:30 的分钟数,可以先用 U(0,20)。这里的核心线索是有限区间和区间内无偏好。
“一个传感器平均每 5 分钟收到一次独立信号,问下一次信号还要等多久。”可以用 作为第一近似。这里的核心线索是等待下一次到达。
练习
- 设 X∼U(2,10)。求 P(5<X<7)、E(X) 和 。
区间概率是长度比例:
P(5<X<7)=10−27−5=
- 某等待时间 X 服从均值为 4 分钟的指数分布。求 P(X>6)。若已经等了 3 分钟,继续再等超过 6 分钟的条件概率是多少?
指数分布的均值是 1/λ,所以 λ=1/4。
P(X>6)=e−6/4
- 设 X∼N(100,152)。用标准正态分布函数 Φ 表示并近似计算 P(85<X<130)。
标准化端点:
1585−100=−1,15130−100=
- 设 T∼Gamma(3,2),其中第二个参数是 rate。把它解释为等待第 3 次到达的时间,求 P(T≤1)。
若 T 是 rate 为 2 的 Poisson 过程中等待第 3 次到达的时间,则 T≤1 等价于 1 个时间单位内至少到达 3 次。令 N(1)∼Poisson(2),则
- 设 P∼Beta(6,4)。求 E(P) 和 Var(P),并用一句话解释这个模型偏向哪一侧。
均值为
E(P)=6+46=0.6.方差为