期望、方差、矩与分布摘要
前面几章已经认识了许多分布。一个完整分布能回答任意区间、任意取值集合上的概率问题,但在建模、比较和估计时,我们常常先问更短的问题:这个随机变量大约在什么位置?波动有多大?是否偏向一侧?尾部会不会给出罕见但很大的数值?
期望、方差和矩就是这类问题的答案。它们不能替代完整分布,却能把分布压缩成几组有解释力的数字。好的压缩不是把细节都丢掉,而是保留当前问题最需要的线索。
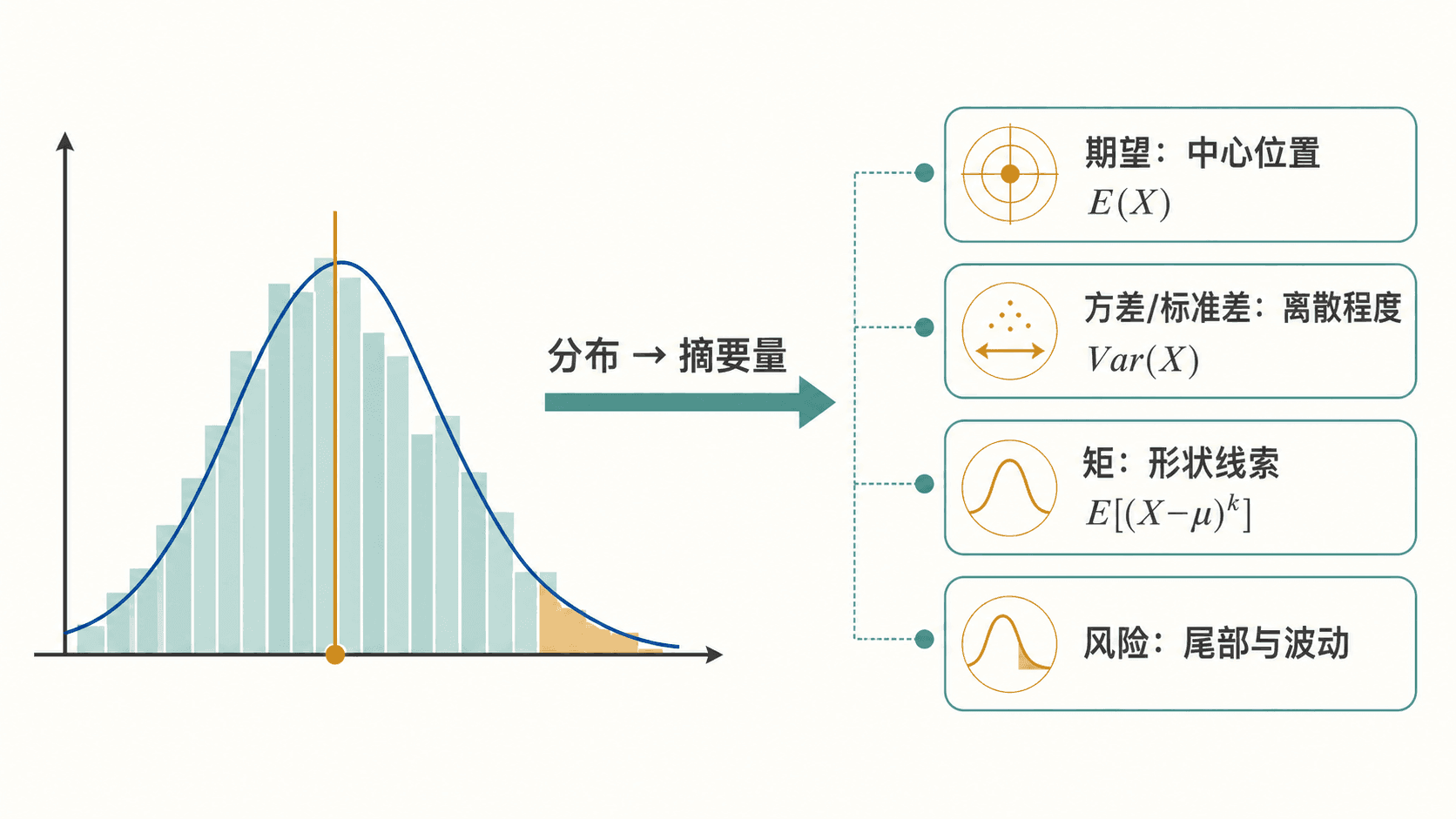 同一个分布可以从中心位置、离散程度、形状和尾部风险几个角度做摘要。
同一个分布可以从中心位置、离散程度、形状和尾部风险几个角度做摘要。
期望不一定是随机变量可能取到的值,也不一定是最可能出现的值。它首先是分布加权后的长期平均位置。
摘要量在回答什么问题
设 X 是一个随机变量。完整地描述 X,需要给出它的分布函数、概率质量函数或密度函数。摘要量只给出分布的某些切面。
最常用的几个问题是:
- 中心在哪里:用期望 E(X) 描述。
- 离中心有多远:用方差 Var(X) 或标准差 σX 描述。
- 分布是否偏斜:用三阶中心矩或标准化三阶矩描述。
- 尾部是否厚重:用高阶矩、分位数或尾概率辅助判断。
摘要量的好处是计算、比较和估计都方便。两个分布如果期望不同,我们通常已经知道它们的“平均水平”不同;如果期望相同但方差不同,它们的稳定性就不同。
摘要量也有明显限制。均值和方差相同的两个分布,形状仍然可能完全不同。比如一个分布可能左右对称,另一个可能大部分概率在低值处、少量概率拖出很长右尾。因此,本章会反复区分两件事:摘要量能提示什么,不能保证什么。
期望是分布的重心
离散随机变量的期望
如果离散随机变量 X 的可能取值为 x1,x2,…,概率质量函数为 p,那么它的期望定义为
E(X)=x∑xpX(x)
这个公式像“带权平均”。取值 x 是位置,概率 pX(x) 是权重。概率越大,这个取值对平均位置的拉动越强。
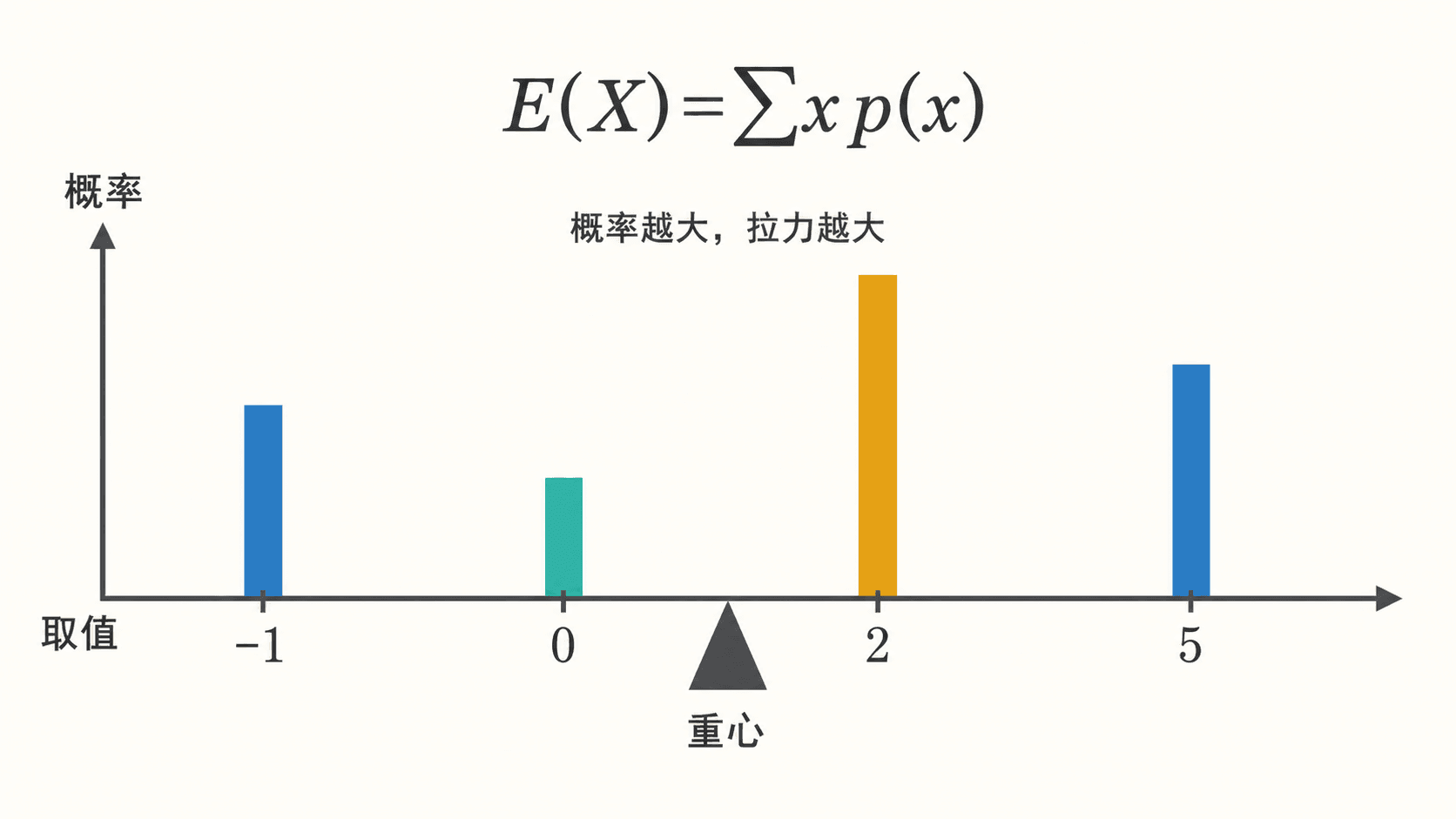 离散期望可以看成概率质量在数轴上的重心。
离散期望可以看成概率质量在数轴上的重心。
这里的求和必须能收敛。对于非负随机变量,期望可以是有限数,也可以是 +∞。对于一般随机变量,通常要求 E(∣X∣)<∞,这样正负部分不会互相用“无穷减无穷”的方式抵消。
连续随机变量的期望
如果连续随机变量 X 有密度函数 fX(x),期望写成积分:
E(X)=∫−∞∞xfX(x)dx
密度函数本身不是概率,但 fX(x)dx 可以理解为靠近 x 的一小段概率质量。积分就是把所有位置按概率质量加权后累加。
期望不是“应该出现的值”
考虑一个很简单的随机变量:
P(X=0)=0.99,P(X=100)=0.01
它的期望是
E(X)=0⋅0.99+100⋅0.01=1
但 X 从来不会取到 1。这说明期望描述的是长期平均位置,而不是一次试验中“最应该出现”的结果。
例题:一个简单收益模型
某活动的净收益 X 有三种结果:亏损 20 元、收益 10 元、收益 50 元,对应概率分别为 0.2,0.5,0.3。求期望收益。
先把取值和概率配对。这里的取值是 −20,10,50,对应概率是 0.2,0.5,0.3。
这里的“16 元”不表示每次都能赚 16 元,也不表示 16 元是某个实际结果。它只是长期平均。
期望的线性性
期望最常用、也最省力的性质是线性性。只要相关期望存在,就有
E(aX+bY+c)=aE(X)+bE(Y)+c
这里不要求 X 和 Y 独立。独立性会在方差和联合分布中发挥作用,但期望的线性性本身不需要它。
为什么线性性有用
许多随机总量可以写成很多小量的和:
T=X1+X2+⋯+Xn
直接求 T 的分布可能很麻烦。期望线性性允许我们先求每个小量的期望,再相加:
E(T)=E(X1)+E(X2)+
这一步不需要知道这些小量之间是否独立。它把“求总量的平均”变成了“求每个局部贡献的平均”。
指示随机变量
指示随机变量是线性性的好搭档。对事件 A,定义
IA={1,0,A
它的期望是
E(IA)=1⋅P(A)+0⋅P(A
所以只要一个总量可以写成“发生了多少个事件”,就可以把它拆成指示变量之和。
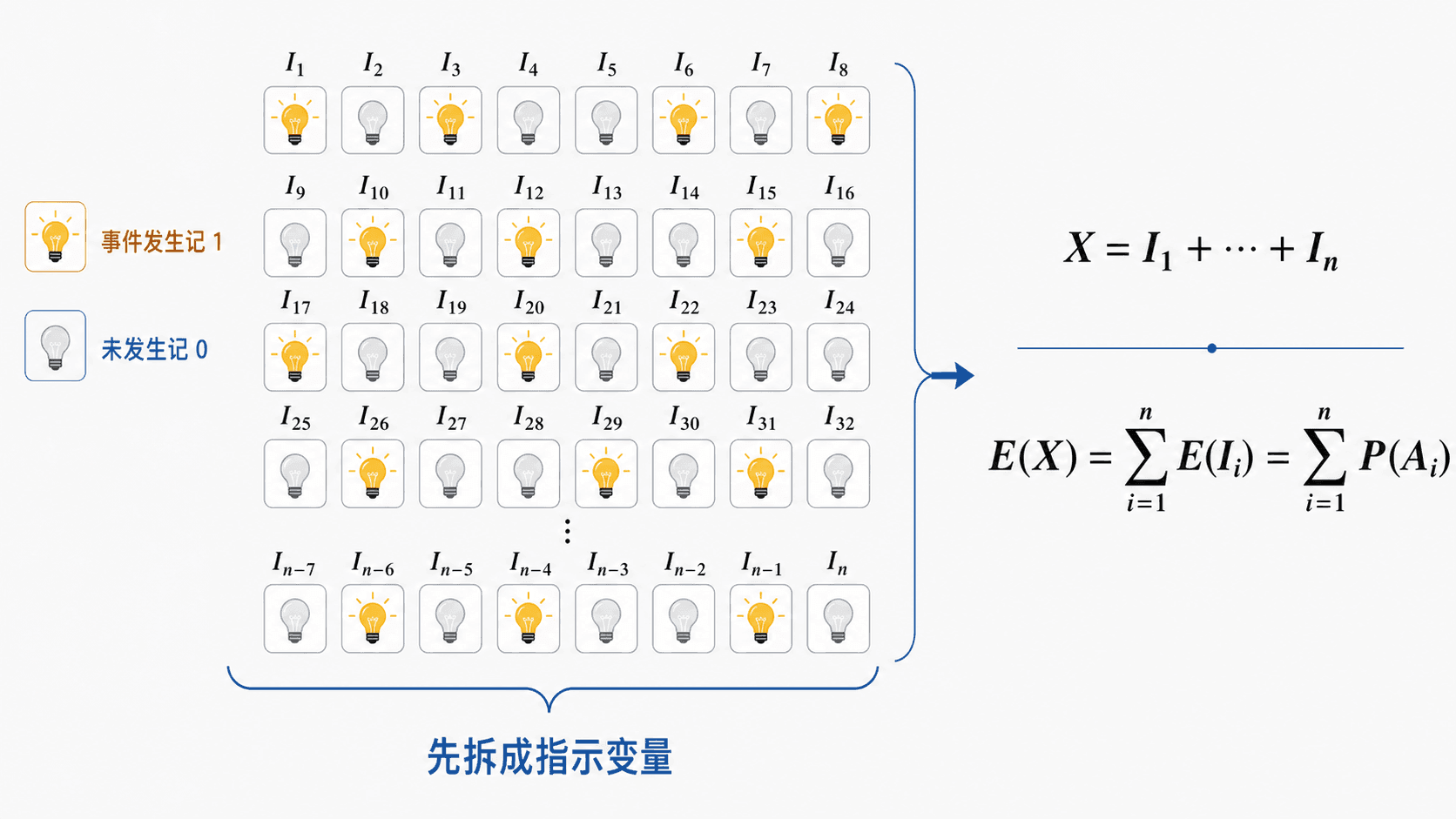 指示变量把复杂计数拆成很多个 0-1 贡献,期望就变成概率求和。
指示变量把复杂计数拆成很多个 0-1 贡献,期望就变成概率求和。
例题:随机排列中的固定点
把 1,2,…,n 随机打乱。若数字 i 仍在第 i 个位置,称为一个固定点。求固定点个数的期望。
设 X 为固定点个数。直接写出 X 的分布不太方便。定义
Ii={1,0,
那么
X=I1+I2+⋯+In
对每个 i,数字 i 留在原位的概率是 1/n,因此
E(Ii)=n1
由期望线性性,
E(X)=i=1∑nE(Ii)=
无论 n 多大,随机排列的固定点个数期望都是 1。这里没有要求事件“第 i 个数字固定”彼此独立。
方差衡量围绕期望的波动
期望给出中心位置,但它不说明随机变量离中心有多远。方差定义为
Var(X)=E[(X−E(X))2]
如果记 μ=E(X),也可以写成
Var(X)=E[(X−μ)2]
平方有两个作用:让正负偏离都变成非负数;让较大的偏离受到更重惩罚。
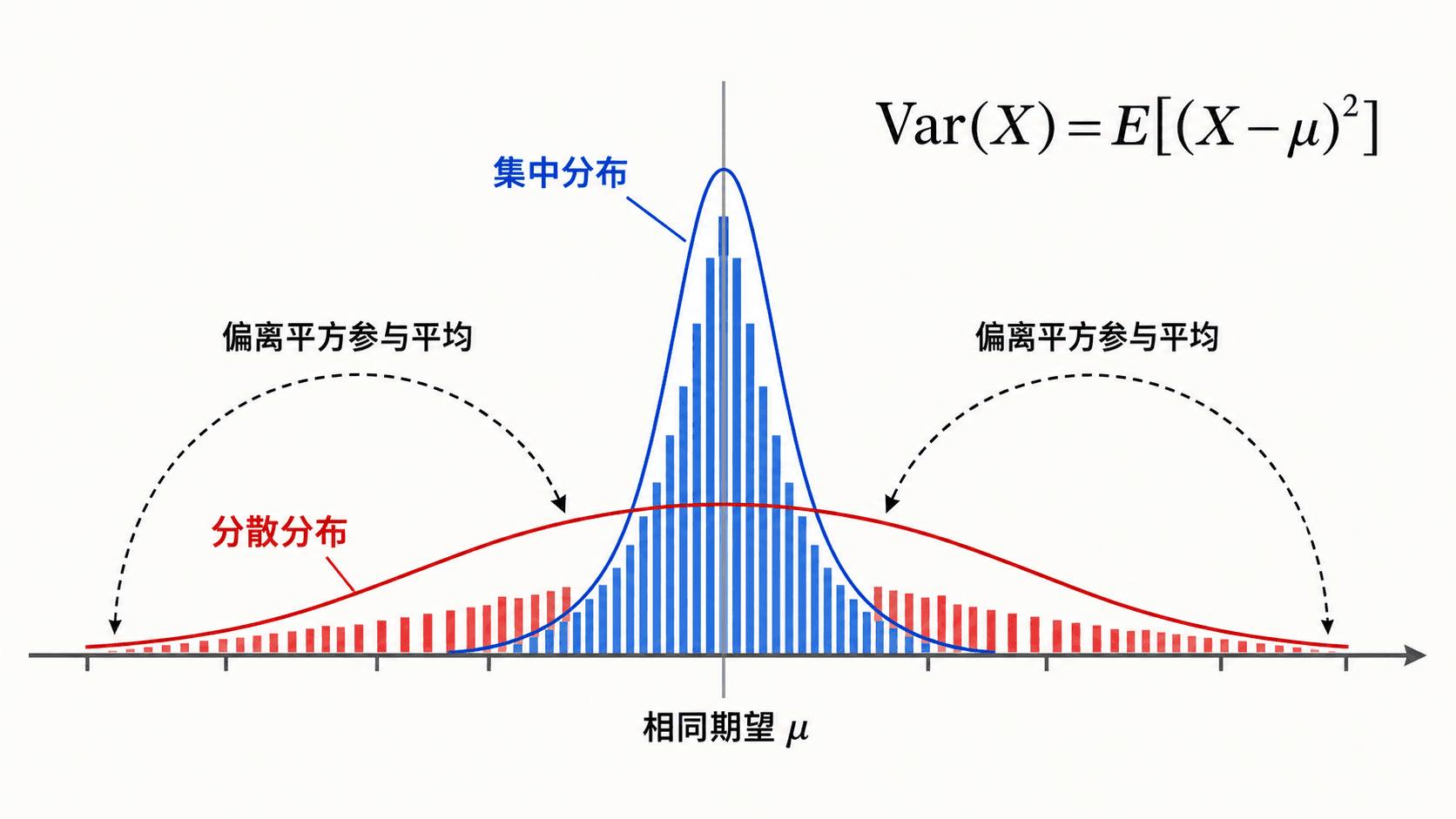 相同期望只说明中心相同,方差决定概率质量离中心的平均平方距离。
相同期望只说明中心相同,方差决定概率质量离中心的平均平方距离。
标准差回到原单位
方差的单位是 X 单位的平方。若 X 的单位是元,方差单位就是平方元,这不方便解释。标准差定义为
σX=Var(X)
标准差与 X 使用相同单位,因此在解释波动时更直观。
计算公式
方差常用下面的等价公式计算:
Var(X)=E(X2)−[E(X)]2
推导只用展开平方:
E[(X−μ)2]=E(X2−2μX
因为 μ=E(X),所以
E[(X−μ)2]=E(X2)−μ2
线性变换下的方差
对常数 a,b,
E(aX+b)=aE(X)+b
而方差满足
Var(aX+b)=a2Var(X)
加上常数只会平移分布,不改变离散程度;乘以 a 会把所有偏离放大 ∣a∣ 倍,平方偏离因此放大 a2 倍。
方差没有普通线性性。一般不能把 Var(X+Y) 直接写成 Var(X)+Var(Y)。只有在合适的独立或零协方差条件下,方差才可以这样拆。协方差会在下一章正式出现。
例题:同一期望下的不同波动
比较两个随机收益:
P(A=10)=1
以及
P(B=0)=0.5,P(B=20)=0.5
它们的期望都是 10:
E(A)=10,E(B)=0⋅0.5+20⋅0.5=10
但 A 没有波动:
Var(A)=0
而 B 的方差为
Var(B)=(0−10)2⋅0.5+(20−10)
标准差为
σB=10
如果只看期望,A 和 B 一样;如果关心稳定性,它们很不同。
矩把分布形状压缩成数字
期望和方差都是矩的特例。矩提供了一套统一语言,用来描述位置、尺度和形状。
原点矩
k 阶原点矩是
E(Xk)
一阶原点矩就是期望 E(X)。二阶原点矩 E(X2) 常用于计算方差。
中心矩
k 阶中心矩是
E[(X−μ)k]
其中 μ=E(X)。一阶中心矩总是 0,二阶中心矩就是方差。
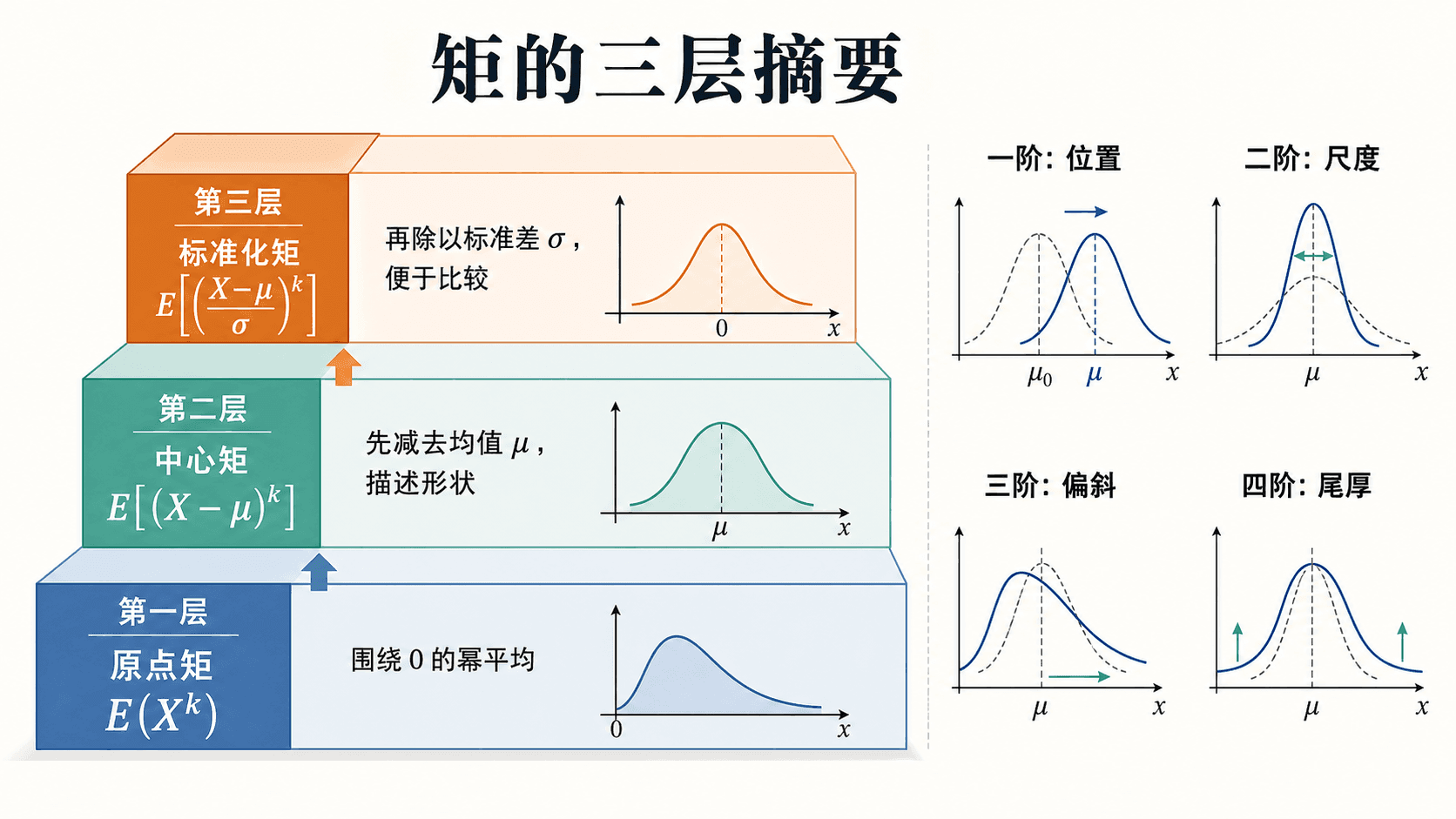 矩的不同形式对应不同摘要任务:位置、尺度、偏斜和尾部。
矩的不同形式对应不同摘要任务:位置、尺度、偏斜和尾部。
标准化矩
为了比较不同单位或不同尺度的分布,常把中心偏离除以标准差:
E[(σX−μ)k]
三阶标准化矩常用于描述偏斜方向。它为正时,分布往往有较长右尾;它为负时,分布往往有较长左尾。
四阶标准化矩常用于观察尾部厚度。数值越大,通常意味着更容易出现离均值较远的值。但这只是摘要,不应把它当成完整的尾部描述。
期望存在性与重尾
并不是所有随机变量都有有限期望或有限方差。有些分布的尾部很厚,极端值出现得不频繁,却足以让积分或级数发散。
例如某些 Pareto 型分布在参数较小时可能有有限期望但没有有限方差;Cauchy 分布甚至没有通常意义下的期望。遇到重尾模型时,先检查矩是否存在,再使用均值和方差解释。
“期望公式能写出来”和“期望是有限数”是两回事。对离散分布要检查级数,对连续分布要检查积分。
常见分布的期望和方差
下面的表把前两章出现过的常见分布放在一起。参数化方式不同会改变公式,使用时要先确认教材或软件采用哪一种记号。
这张表不是要求死记。更好的用法是把公式和分布结构连起来:
- Bernoulli 的方差 p(1−p) 在 p=0 或 p=1 时为 0,因为结果完全确定。
- Binomial 的期望 np 来自 个 Bernoulli 指示变量相加。
非线性函数的期望
线性函数的期望很好处理:
E(aX+b)=aE(X)+b
但非线性函数一般不能把期望直接“塞进去”。通常有
E[g(X)]=g(E(X))
例如 g(x)=x2 时,
E(X2)=[E(X)]2+Var(X)
只要 X 有正方差,E(X2) 就大于 [E(X)]2。
Jensen 不等式正是研究这种差别的入口。若 g 是凸函数,在适当条件下有
E[g(X)]≥g(E(X))
本章只需要记住直觉:非线性函数会改变平均的计算方式。先求平均再代入函数,和先变换再求平均,通常不是一回事。
风险解释:均值不够,尾部也要看
在风险问题中,期望常被解释为长期平均收益或平均损失。这个解释有用,但不够。
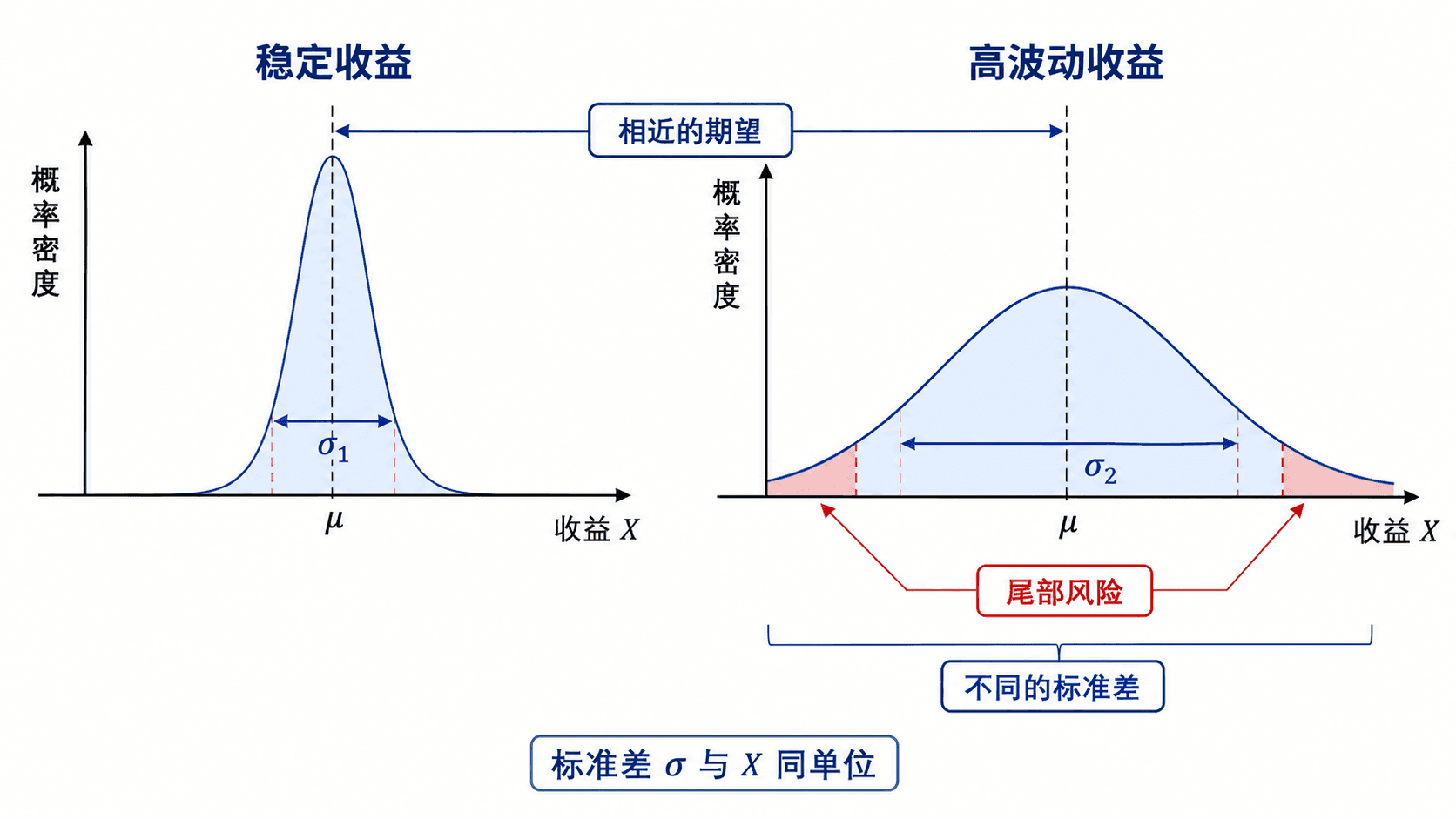 相近的期望可以伴随很不同的标准差和尾部风险。
相近的期望可以伴随很不同的标准差和尾部风险。
看两个项目:
P(X=2)=1
以及
P(Y=−18)=0.1,P(Y=4.22)=0.9
Y 的期望为
E(Y)=(−18)⋅0.1+4.22⋅0.9=1.998
它和 X 的期望几乎一样。但 Y 有 10% 的概率出现较大亏损,X 没有这种尾部风险。
方差和标准差能提示波动大小,分位数和尾概率能直接描述极端损失。实际建模时,常把这些摘要放在一起看,而不是只报告一个平均数。
均值回答“长期平均在哪里”,方差和标准差回答“通常偏离多远”,尾概率回答“坏结果有多容易出现”。三者合在一起,才更接近风险问题的语言。
解题方法小结
计算期望、方差和矩时,可以按下面顺序检查。
先确认随机变量类型。离散变量通常用求和,连续变量通常用积分。混合型随机变量要分开处理概率质量和密度部分。
写清楚分布。离散情形列出取值和概率;连续情形写出密度和积分区间。
求期望时优先寻找结构。若目标是总数,考虑拆成指示变量;若目标是多个部分之和,使用期望线性性。
求方差时先算 和 ,再用 。不要把方差当作普通线性函数。
练习
练习一:期望不一定可取
随机变量 X 满足 P(X=0)=0.8,P(X=5)=0.2。求 ,并说明它是否一定是 的可能取值。
期望为
E(X)=0⋅0.8+5⋅0.2=11 不是 X 的可能取值。它表示长期重复试验时的平均位置。
练习二:方差计算
随机变量 X 满足 P(X=−1)=0.25,P(X=1)=0.5,。求 、 和 。
先算期望:
E(X)=(−1)⋅0.25+1⋅0.5+3⋅0.25=1再算二阶原点矩:
练习三:指示变量
一个班有 n 名同学,每人独立以概率 p 提交作业。令 X 为提交作业的人数。不写出 X 的完整分布,求 E(X)。
设 Ii 表示第 i 名同学是否提交作业,提交时为 1,否则为 0。于是
X=I练习四:线性变换
设 E(X)=4,Var(X)=9。令 Y=2X−3。求 和 。
由期望线性性,
E(Y)=E(2X−3)=2E(X)−3=5方差对平移不变,对倍数平方放大:
练习五:非线性期望
设 E(X)=2,Var(X)=5。求 E(X2),并说明它为什么不等于 。
由方差公式,
Var(X)=E(X2)−[E(X)]2所以