连续随机变量与密度函数
前面学习离散随机变量时,一个常见动作是列出每个取值的概率。例如掷骰子的点数可以写成 P(X=1),P(X=2),…,P(X=6)。连续随机变量不能这样处理。等待时间、测量误差、随机抽取一人的身高,这些量在模型里通常可以落在一段实数区间内,单个精确数值本身不再承载正概率。
连续型模型的基本问题变成:随机变量落在某个区间里的概率是多少?密度函数就是回答这个问题的工具。它本身不是概率表,而是一张“概率在数轴上如何分布”的图。真正的概率来自曲线下面积。
![连续随机变量教学图,测量结果流向数轴,密度曲线在区间 [a,b] 下方填充表示区间面积等于概率,并用细竖线标注点概率为 0](https://media.edu-free.com/uploads/continuous_random_variable_density_interval_probability_38b245c97c.png) 连续随机变量的概率通过区间上的密度面积累积,单个取值点的概率为 0。
连续随机变量的概率通过区间上的密度面积累积,单个取值点的概率为 0。
连续随机变量在问区间
如果 X 表示某个电子元件的寿命,问题“X 是否恰好等于 1000.000000… 小时”通常没有实际意义。测量仪器会四舍五入,真实寿命也不会只在几个指定点上跳动。更自然的问题是:
- X 是否在 900 到 1100 小时之间?
- X 是否小于保修期 1000 小时?
- X 是否落在中间 50% 的典型区间内?
在本课程里,若随机变量 X 的分布可以由某个非负函数 fX 通过积分表示,我们称 X 是连续型随机变量,并称 fX 为 的概率密度函数。
连续型不是说现实世界的测量值永远有无限精度,而是说我们选择用连续数轴上的模型描述它。模型关心区间概率,积分给出这些区间概率。
下面的交互把这个想法做成了一个小探测器。调节区间端点时,变化的是曲线下被填充的面积,而不是端点处某一根线的高度。
密度函数是什么
概率密度函数常记为 fX(x) 或简写为 f(x)。它需要满足两个基本条件:
f(x)≥0
∫−∞∞f(x)dx=1
第一个条件说密度不能为负;第二个条件说整条数轴上的总面积必须是 1。如果 a<b,则区间概率由积分给出:
P(a≤X≤b)=∫abf(x)dx
这里的等号端点可以换成开区间。原因会在后面单独说明。
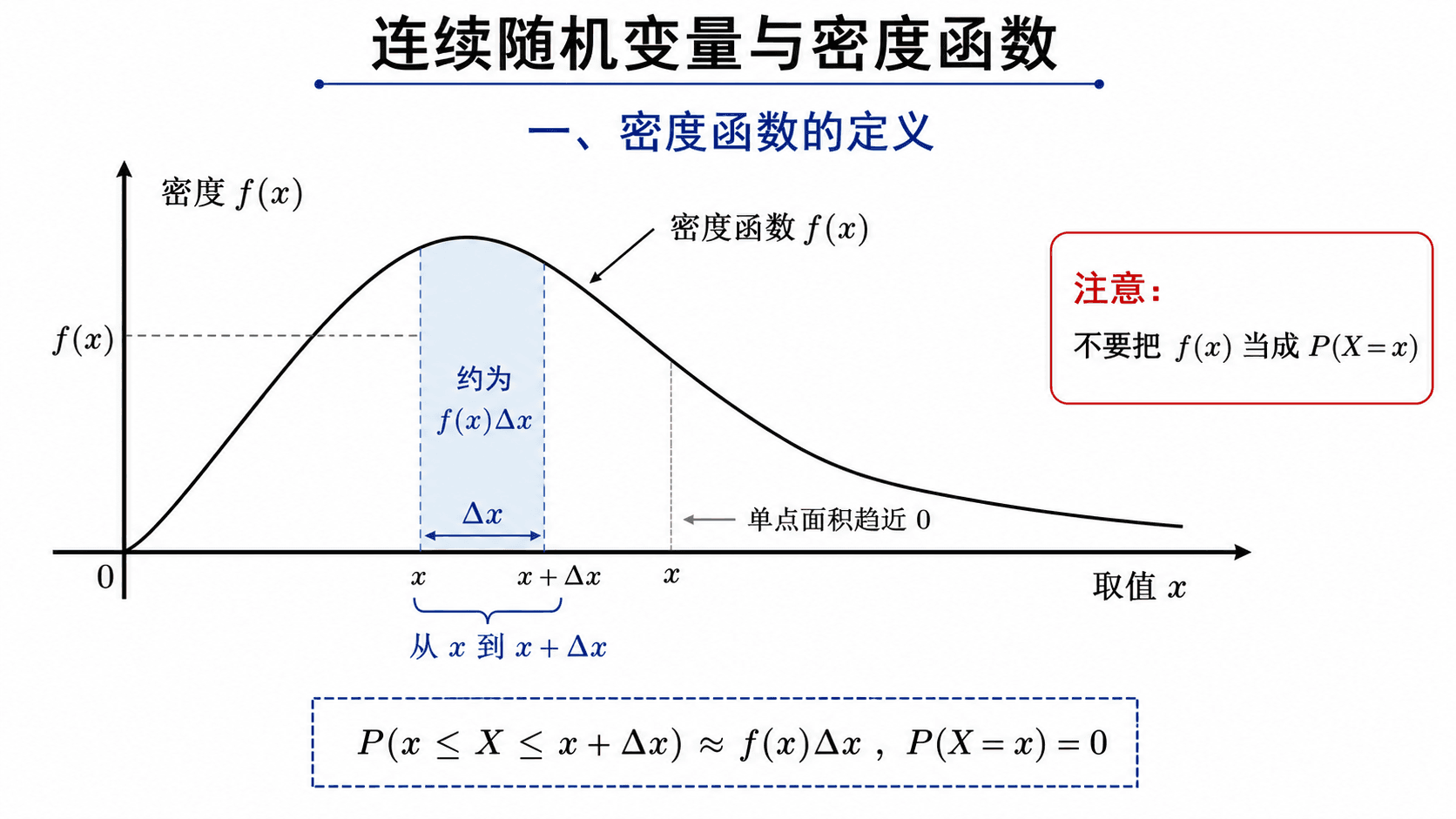 密度函数表示单位长度上的概率密度,区间概率可用窄矩形面积近似;单点概率为 0。
密度函数表示单位长度上的概率密度,区间概率可用窄矩形面积近似;单点概率为 0。
密度的单位也提醒我们不要把它直接当成概率。如果 X 用“分钟”度量,那么 f(x) 的单位是“每分钟”。只有再乘上一小段长度 Δx,才近似得到这一小段区间里的概率:
P(x<X<x+Δx)≈f(x)Δx
密度值可以大于 1。比如 f(x)=2 在 0≤x≤1/2 上、其他地方为 0,总面积仍然是 1。概率不能超过 1,但密度的高度不是概率。
例题:用密度求区间概率
设 X 的密度函数为
f(x)={2x,0,0≤x≤1
求 P(0.2≤X≤0.5)。
先检查这是一个合法密度。函数在支撑区间 [0,1] 上非负,并且
∫012xdx
从密度到分布函数
分布函数仍然是最稳的语言:
FX(x)=P(X≤x)
如果 X 有密度 fX,那么 FX(x) 就是从左侧一直累积到 x 的面积:
FX(x)=∫−∞xfX
反过来,在 FX 可导的点上,密度是分布函数的导数:
fX(x)=FX′(x)
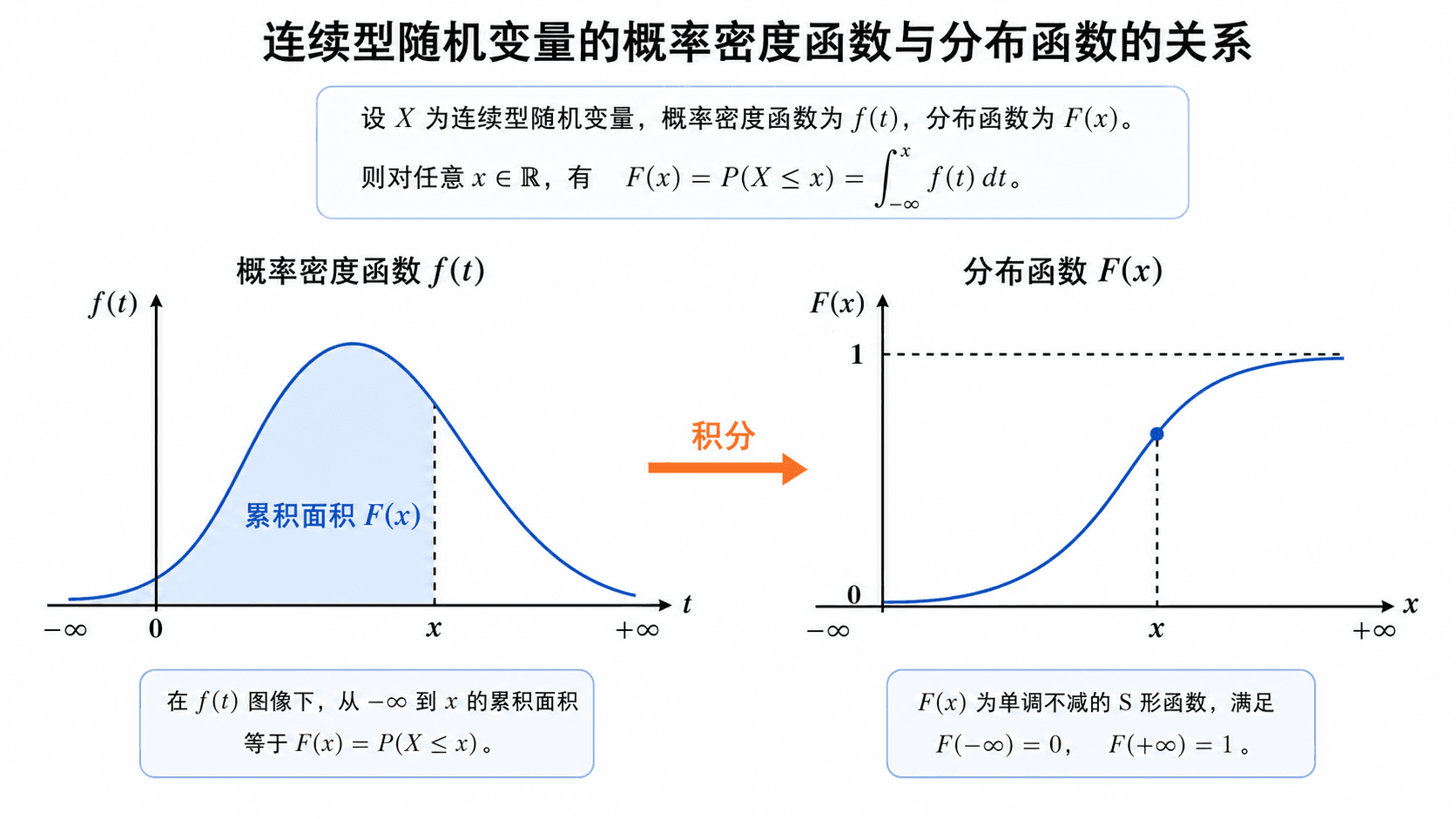 密度函数下从负无穷到 x 的面积等于分布函数 F(x),CDF 随 x 单调上升并趋近于 1。
密度函数下从负无穷到 x 的面积等于分布函数 F(x),CDF 随 x 单调上升并趋近于 1。
下面的交互固定使用一个三角形密度。移动 x 时,左边的阴影面积和右边 CDF 上的点同步变化。这个图也提醒我们:PDF 可以先上升再下降,但 CDF 必须一直不下降。
分位数
连续分布里也常问“中位数”和“分位数”。若 0<p<1,一个 p 分位数 qp 通常满足
F(qp)=p
中位数就是 p=0.5 的分位数。用 CDF 找分位数,比盯着 PDF 的峰值更可靠。PDF 的最高点表示局部密度最大,不一定是中位数,也不一定是均值。
归一化:让总面积等于 1
有时题目先给出一个非负函数形状 g(x),再要求我们找常数 c,使 f(x)=cg(x) 成为密度函数。这个步骤叫归一化。
如果
A=∫−∞∞g(x)dx
并且 0<A<∞,那么应取
c=A1
这样
∫−∞∞cg(x)dx=cA=1
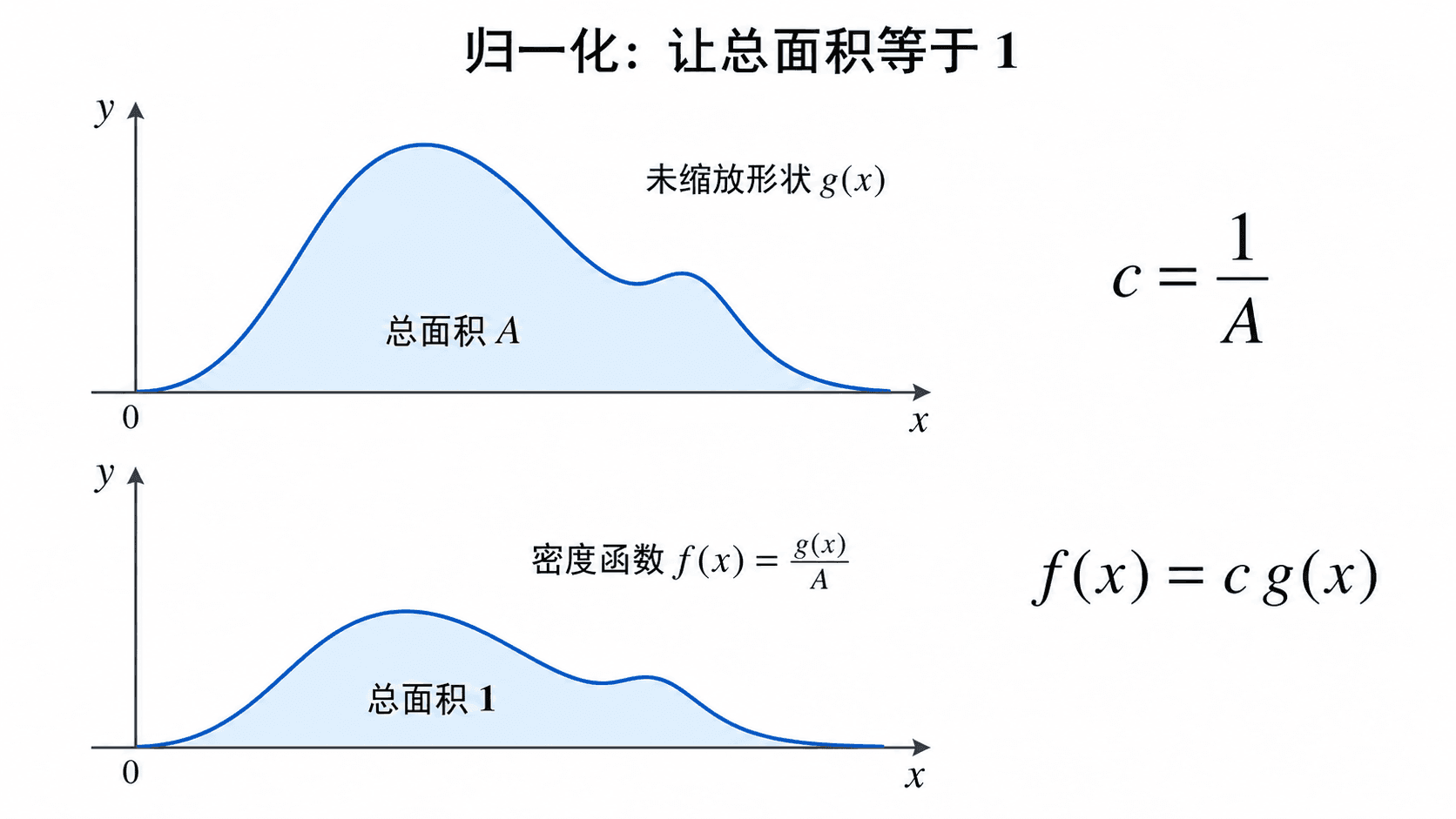 通过选择归一化常数 c=1/A,将非负形状 g(x) 缩放为总面积等于 1 的密度函数。
通过选择归一化常数 c=1/A,将非负形状 g(x) 缩放为总面积等于 1 的密度函数。
这个实验台用数值积分近似面积。调节 p,q 后,同一个非负形状会被不同的常数缩放;只有缩放后的曲线才是概率密度。
例题:求归一化常数
设
g(x)={x(2−x),0,0
令 f(x)=cg(x)。求 c,并计算 P(0.5≤X≤1.5)。
先求未归一化形状的总面积:
A=∫02x(2−
分段密度的处理方式
连续型题目里,密度常常按区间分段给出。处理分段密度时,先画出支撑区间,再看积分区间跨过了哪些分段点。跨段时不能把一个表达式从头用到尾。
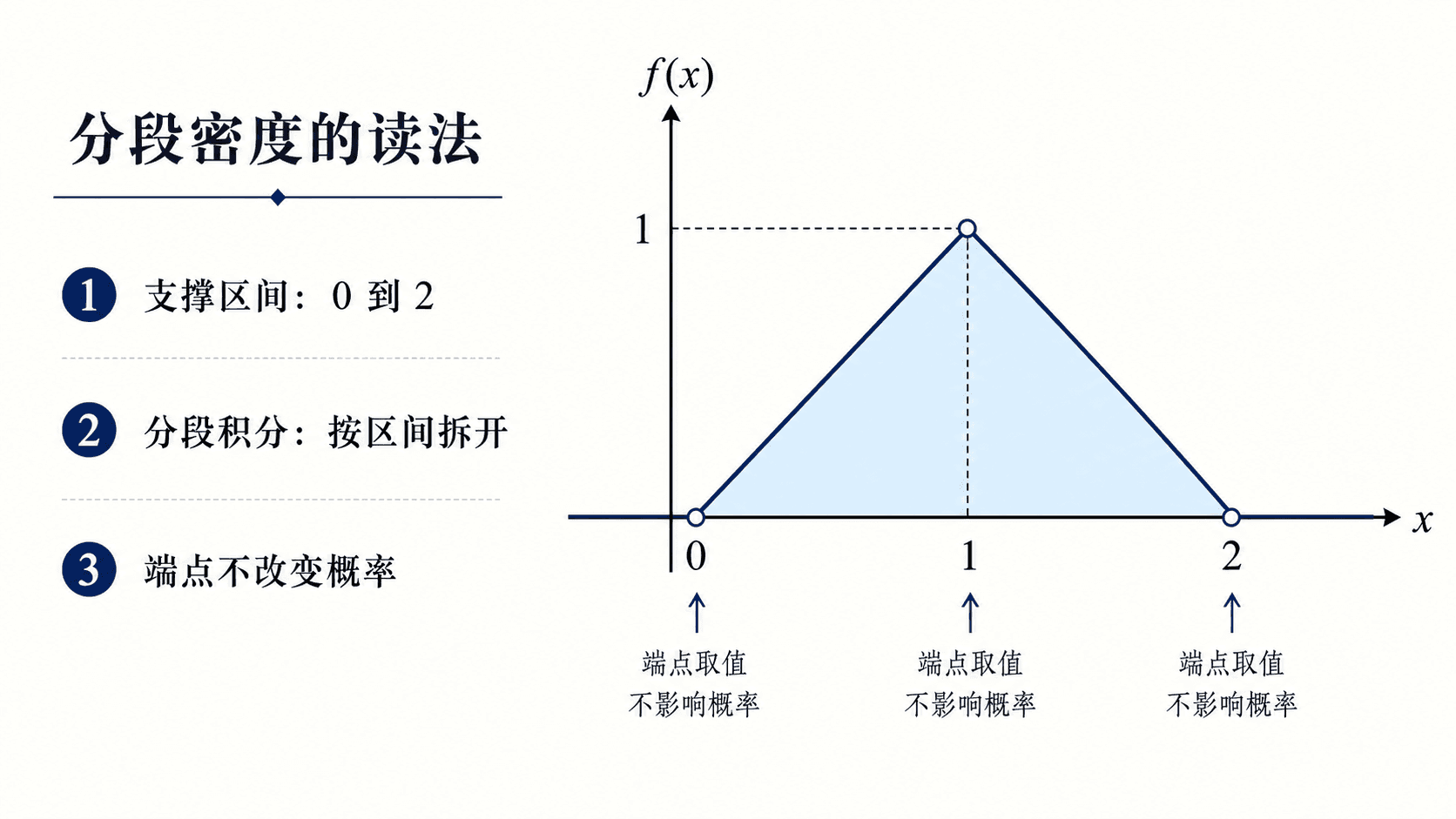 分段密度函数在 0 到 2 上有非零取值,计算概率时按区间分段积分,端点取值不影响结果。
分段密度函数在 0 到 2 上有非零取值,计算概率时按区间分段积分,端点取值不影响结果。
以前面交互中的三角形密度为例:
f(x)=⎩⎨
它的总面积是两个直角三角形面积之和:
21⋅1⋅1+21⋅1
若要求 P(0.4≤X≤1.6),积分区间跨过分段点 1,所以要拆开:
P(0.4≤X≤1.6)=∫0.41xdx+
计算得
(2x2)
对应的 CDF 也要分段写:
F(x)=⎩
分段密度题的稳定做法是:先找支撑区间,再找分段点,最后把概率区间切成不跨段的小积分。
点概率为零与端点
对连续型随机变量,只要概率由密度积分给出,就有
P(X=a)=∫aaf(x)dx=0
这句话很容易被误读。它不是说 X=a 不可能发生,而是说“恰好等于某个指定实数”这个事件在连续模型中没有面积。许多单点事件各自概率为零,但它们合在一起形成区间后,可以有正概率。
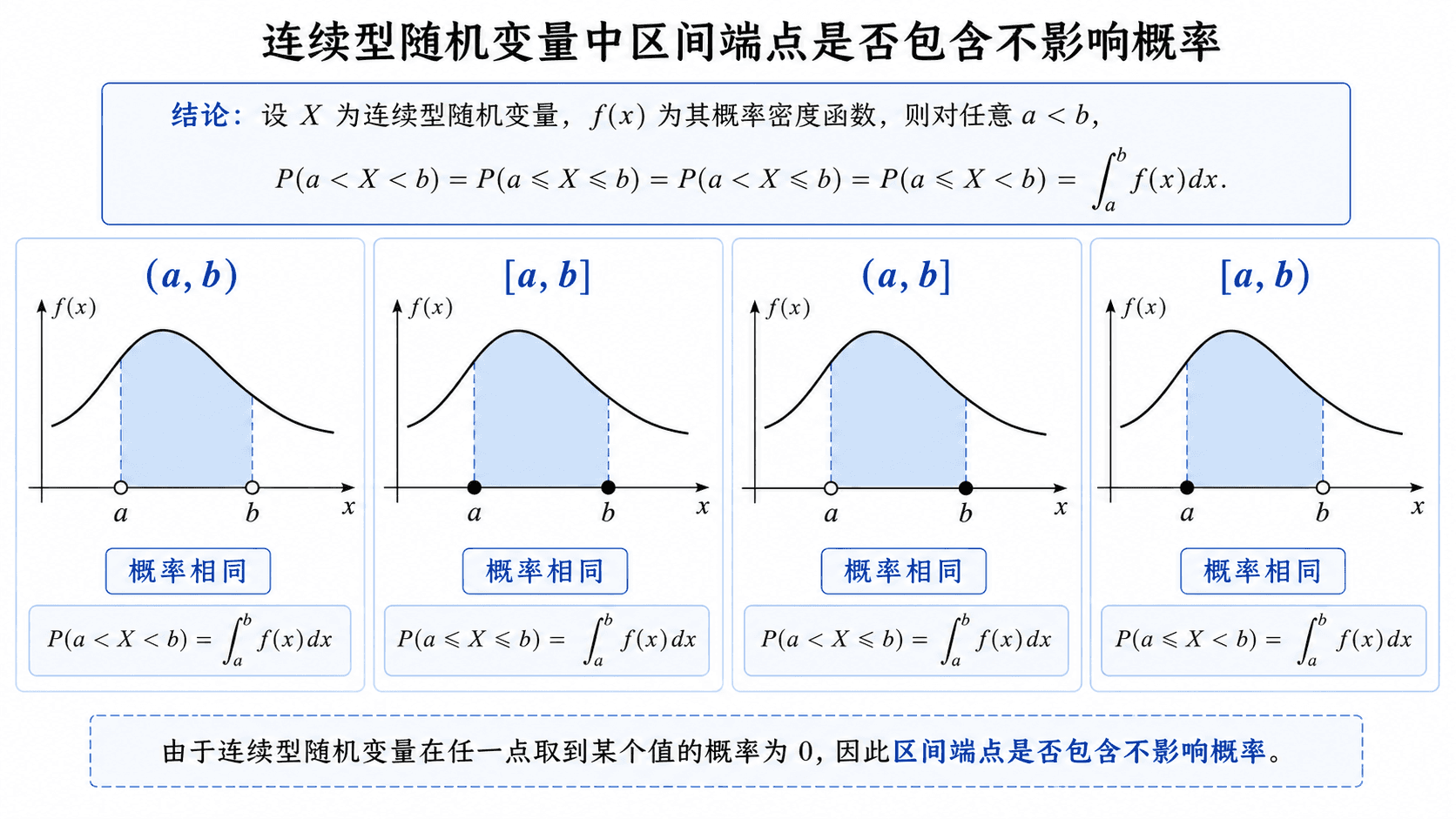 连续型随机变量在端点处的概率为零,因此 (a,b)、[a,b]、(a,b]、[a,b) 的区间概率相同。
连续型随机变量在端点处的概率为零,因此 (a,b)、[a,b]、(a,b]、[a,b) 的区间概率相同。
于是对 a<b,以下四个概率相同:
P(a<X<b)=P(a≤X<b)=P(a<
点概率为零还有一个小后果:只改动密度函数在有限个点上的取值,不会改变任何区间概率。因为积分只看面积,单点高度没有宽度。
不要把“点概率为零”理解成“每个取值都不能出现”。连续模型抽到某个实际数值时,总会出现一个结果;只是模型不会给任何预先指定的精确点分配正概率。
常见误区
把密度高度当成概率
如果图上 f(3)=1.2,这不表示 P(X=3)=1.2,也不表示某个事件概率超过 1。它只表示在 3 附近单位长度上的概率密度较高。要得到概率,必须给出一段宽度并积分。
忽略支撑区间
密度函数常在某个区间外等于 0。积分上下限如果伸到支撑区间之外,区间外那部分不贡献面积。计算前先标出“哪里有密度”,能少犯很多边界错误。
用 PDF 的峰值判断中位数
峰值说明哪里最密集,中位数说明 CDF 在哪里达到 0.5。对不对称密度,这两个位置可能相差很远。
忘记检查总面积
题目给出的函数如果没有总面积 1,它还不是密度。先归一化,再谈概率。
小结与练习
连续随机变量的核心计算只有一句话:概率是密度曲线下面的面积。CDF 是面积从左到右的累积,PDF 是 CDF 在可导处的斜率。点概率为零,所以区间端点是否包含不影响结果。遇到分段密度,先切分区间;遇到未归一化函数,先把总面积调成 1。
练习
设
f(x)={3x2,0,
计算 P(0.3≤X≤0.8)。
这是合法密度,因为 ∫013x2dx=1。所求概率为
设 g(x)=x 在 0≤x≤4 上,其他地方为 0。求常数 c,使 成为密度。
先求总面积:
A=∫04xdx=8所以 c=1/8,即 在 上。
设
F(x)=⎩⎨
求对应密度 f(x),并计算 P(0.2≤X≤0.6)。
在 0<x<1 上,密度是 CDF 的导数:
f(x)=F′(x)=3x设 X 有本章三角形密度。判断 P(0≤X≤1)、P(0<X<1)、 是否相同。
三者相同。因为 X 是连续型随机变量,P(X=0)=P(X=1)=0。这些端点是否被包含,不改变曲线下面积。共同概率为
∫