可分离变量方程
上一章我们用方向场看解曲线的走向。本章开始求第一类能真正“算出来”的一阶方程:可分离变量方程。
它的核心问题很朴素:如果斜率可以写成一个只依赖自变量的因子,乘上一个只依赖未知函数的因子,我们能不能把两种变量分别放到积分号两边?
答案通常是可以,但有两个前提不能省:先确认哪些地方允许除法,再记住被除掉的常数解。
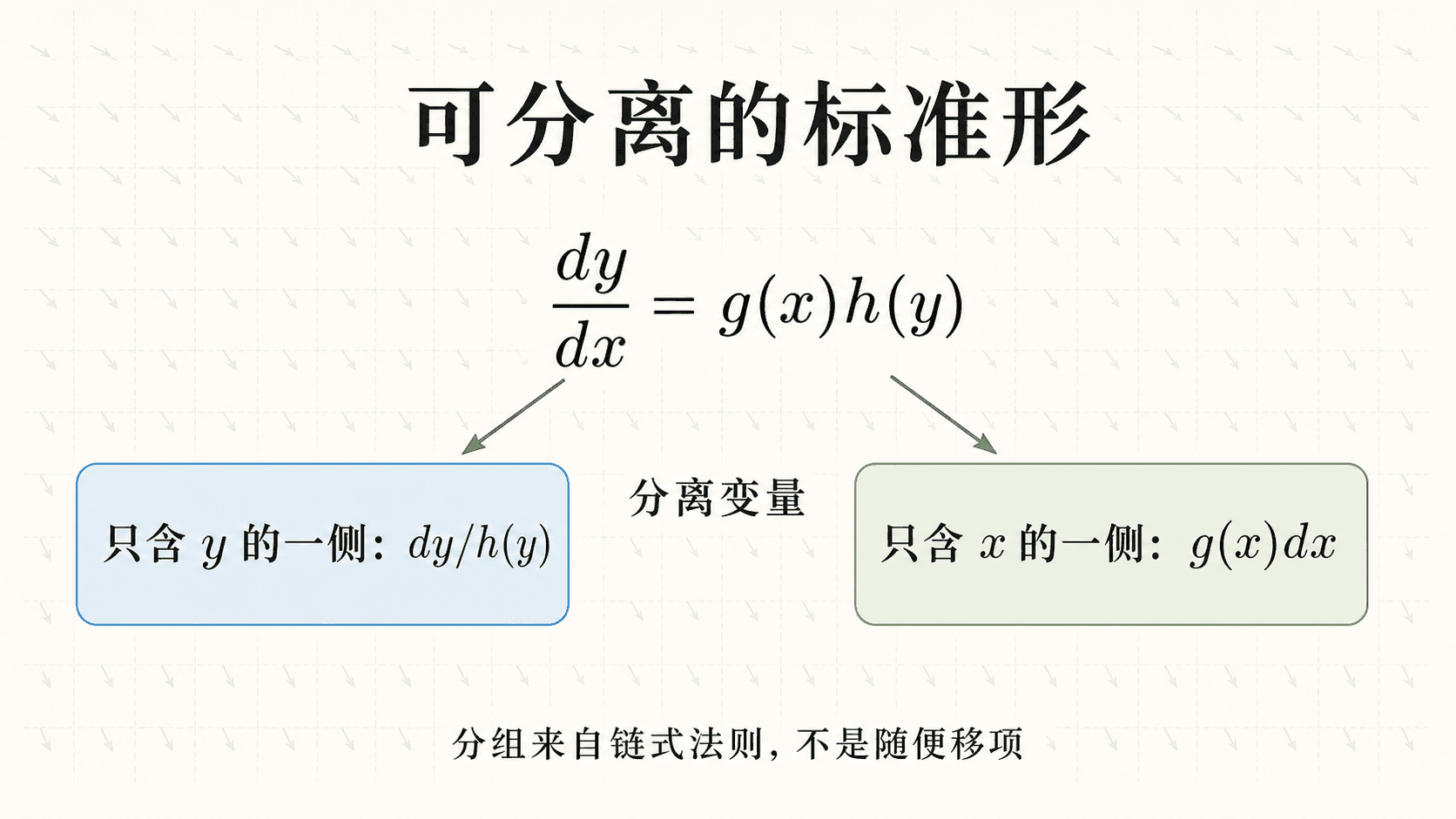 可分离方程的标准形与变量分离:分组来自链式法则,不是随便移项。
可分离方程的标准形与变量分离:分组来自链式法则,不是随便移项。
从斜率可拆开说起
一阶方程
dxdy=f(x,y)
一般不容易直接积分,因为右边同时混着 x 和 y。可分离变量方程是其中比较友好的一类,它的右边可以分解成
dxdy=g(x)h(y).
这里 g(x) 只看当前位置 x,h(y) 只看当前高度 y。例如
dxdy=xy
是可分离的,因为它等于 g(x)=x 和 h(y)=y 的乘积。方程
dxdy=x+y
通常不是可分离的,因为 x+y 没有自然拆成“只含 x 的因子乘只含 y 的因子”。
为了看清分离变量的合法性,先假设在某段解曲线上 h(y)=0。把方程两边除以 h(y),得到
h(y)1dxdy=g(x).
如果取一个函数 H,满足
H′(y)=h(y)1,
那么左边正是复合函数 H(y(x)) 对 x 的导数:
dxdH(y(x))=H′(y)
所以两边对 x 积分,得到
H(y)=∫g(x)dx+C.
平时写成
∫h(y)1dy=∫g(x)dx
只是这种链式法则计算的简写。
微分记号 dxdy 很像一个分数,但本章更稳妥的理解是:先把方程改写成 h(y),再用链式法则确认左边确实是某个关于 的函数对 的导数。
标准形式与合法分离
判断一个方程能否分离时,不要急着动手积分。先做三件事:找标准形,找可能被除掉的常数解,确定当前解曲线所在的区间。
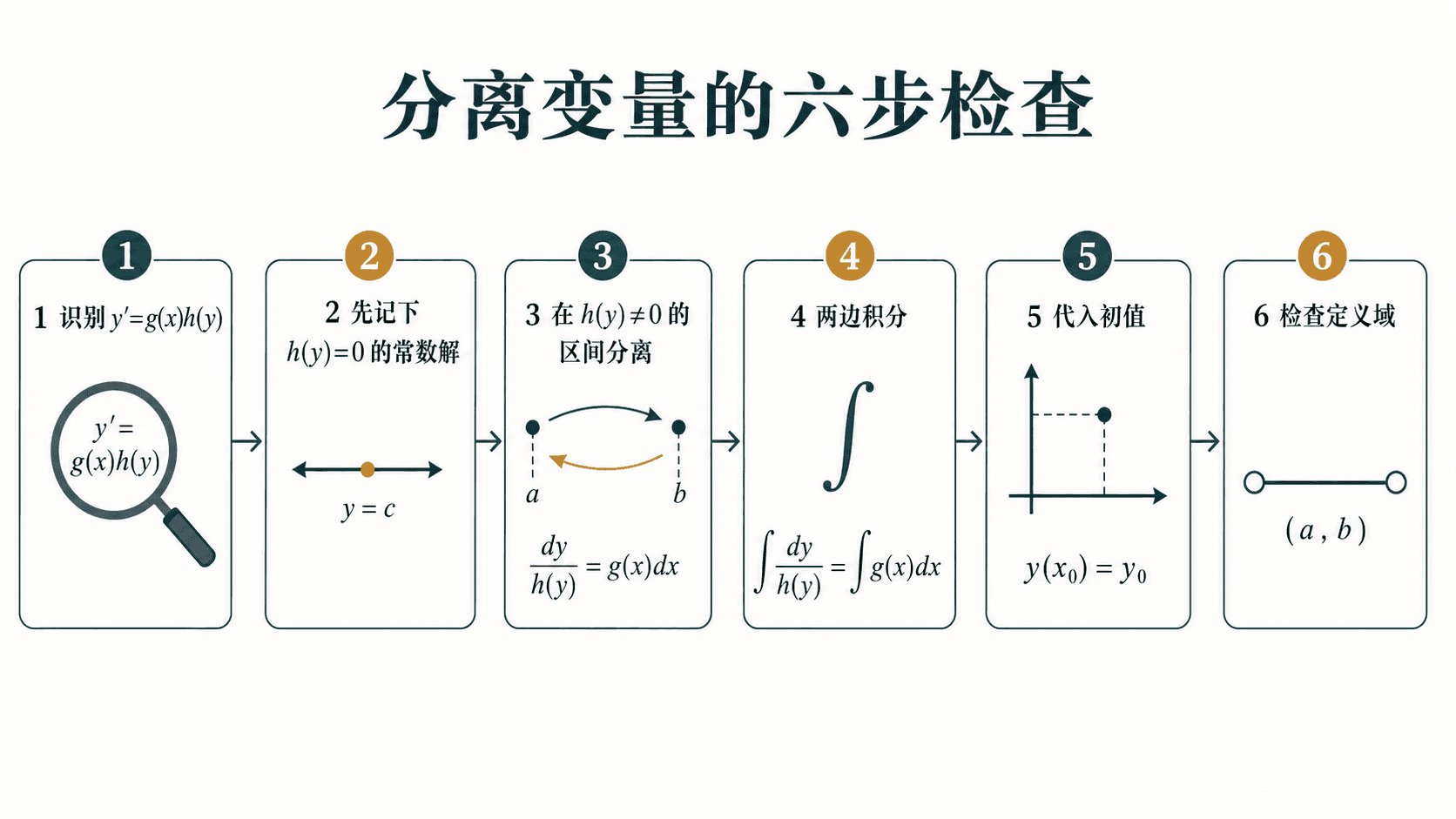 求解可分离变量方程时,从识别标准形式到检查定义域的六步流程。
求解可分离变量方程时,从识别标准形式到检查定义域的六步流程。
设方程已经写成
y′=g(x)h(y).
如果存在数值 a 使得 h(a)=0,那么
y(x)≡a
就是一个常数解。因为此时 y′=0,右边也等于 g(x)h(a)=0。
在非平衡的解曲线上,只要 h(y)=0,就可以分离:
h(y)dy=g(x)dx.
接着分别积分:
∫h(y)1dy=∫g(x)dx+C.
这里两边积分常数只需要合并成一个 C。如果你在左边写 C1,右边写 C2,最后也只会留下差 C。
如果你把 h(y) 除掉,却没有先检查 h(y)=0,就可能丢掉水平直线解。这个错误在 y′=xy、、 这类题里很常见。
来看一个基本例子。
求初值问题
y′=xy,y(0)=2.
先识别标准形。这里 g(x)=x,h(y)=y,所以方程可分离。由于 h(0, 是一个常数解,但它不满足初值 。
这个例子里,常数解 y=0 与初值解分属不同曲线。分离变量法没有把它们混在一起,但我们必须主动把它们记下来。
隐式解、显式解与常数
分离变量以后,不一定总能把 y 解成 x 的显式函数。很多时候,积分给出的关系本身就已经描述了解曲线。
例如
y′=1+y2x,y(0)=
分离变量得到
(1+y2)dy=xdx.
积分后
y+3y3=2x
代入初值:
1+31=C,
所以
y+3y3=2x
这就是一个隐式解。它没有把 y 单独放在等号左边,但已经给出了一条经过 (0,1) 的积分曲线。
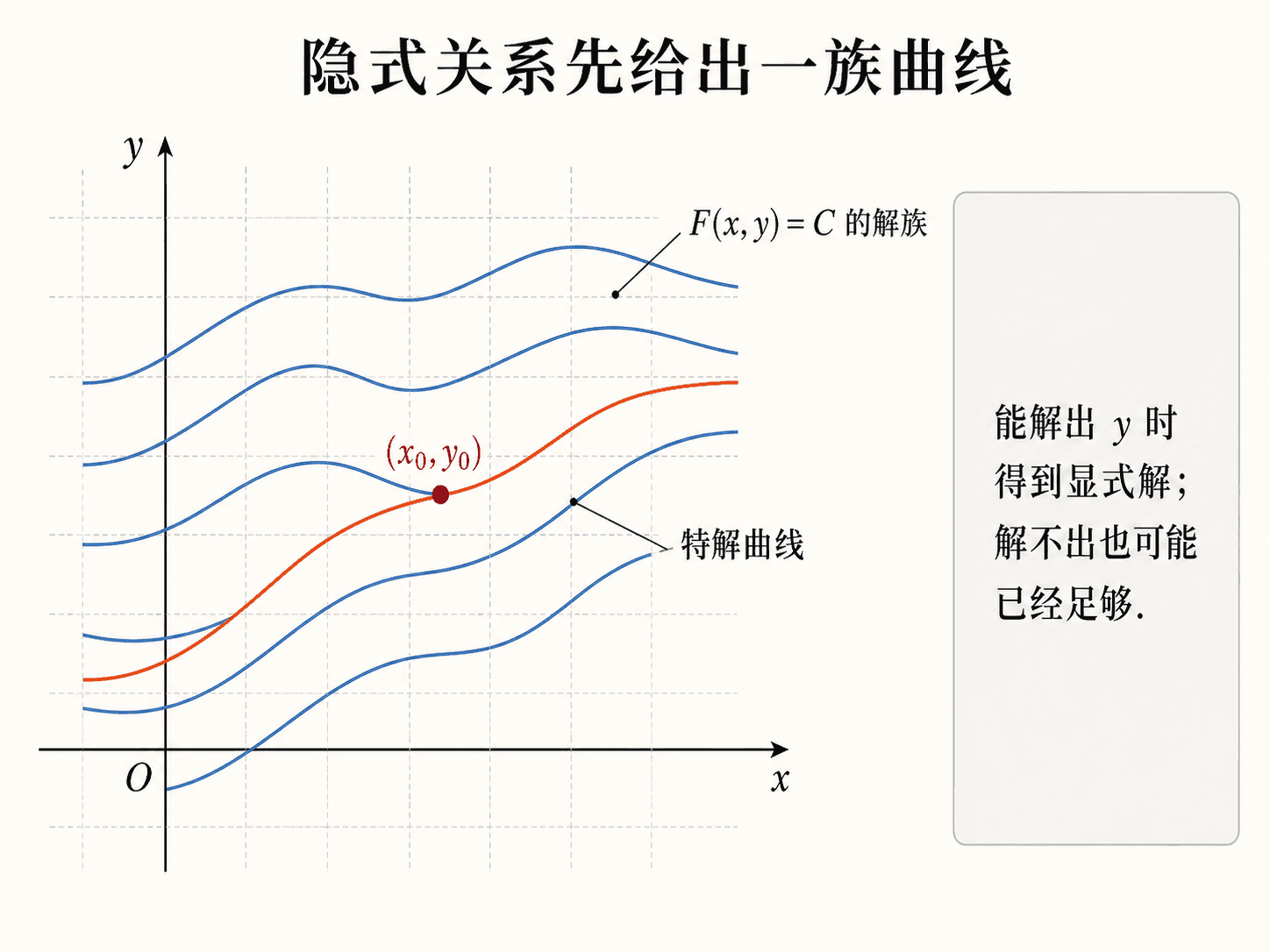 隐式解族 F(x,y)=C 中,通过初值点的曲线就是对应的特解。
隐式解族 F(x,y)=C 中,通过初值点的曲线就是对应的特解。
能写成显式解当然方便,但不是每道题都值得硬解。只要隐式关系能确定经过初值点的解曲线,并且能用于判断趋势、代入检查或数值计算,它就是有效的答案形式。
积分常数的位置也要自然。比如
ln∣y∣=2x2+C
可以指数化为
∣y∣=eCex2/2.
通常把符号和正数常数合并,写成
y=Aex2/2,
其中 A 可以是正数、负数,也可以由常数解补上 A=0。但如果前面除以过 y,就不要忘记说明 A=0 对应的是额外检查得到的常数解,而不是除法步骤本身推出来的。
下面这个交互可以把标准形、初值和解曲线放在一起看。拖动初值时,注意同一个方程会怎样选出不同的积分曲线。
初值问题中的定义域
求出公式后,还要回答一个经常被忽略的问题:这个公式在哪个区间上代表同一条初值解?
一阶初值问题的解通常只要求在包含初始点 x0 的某个区间上成立。如果公式在某处出现分母为零、对数无意义或函数爆破,就不能把解曲线硬跨过去。
看方程
y′=y2,y(0)=1.
分离变量:
y2dy=dx.
积分得到
−y1=x+C.
代入 y(0)=1,得到 C=−1,所以
y=1−x1.
这个公式在 x=1 爆破。因为初始点在 0,这条初值解的最大有效区间是
(−∞,1).
不能把同一个初值解说成在 x>1 也继续成立。虽然公式右侧在 x>1 也有数值,但那已经隔着竖直渐近线,不是从 (0,1) 连续延伸过去的同一条解曲线。
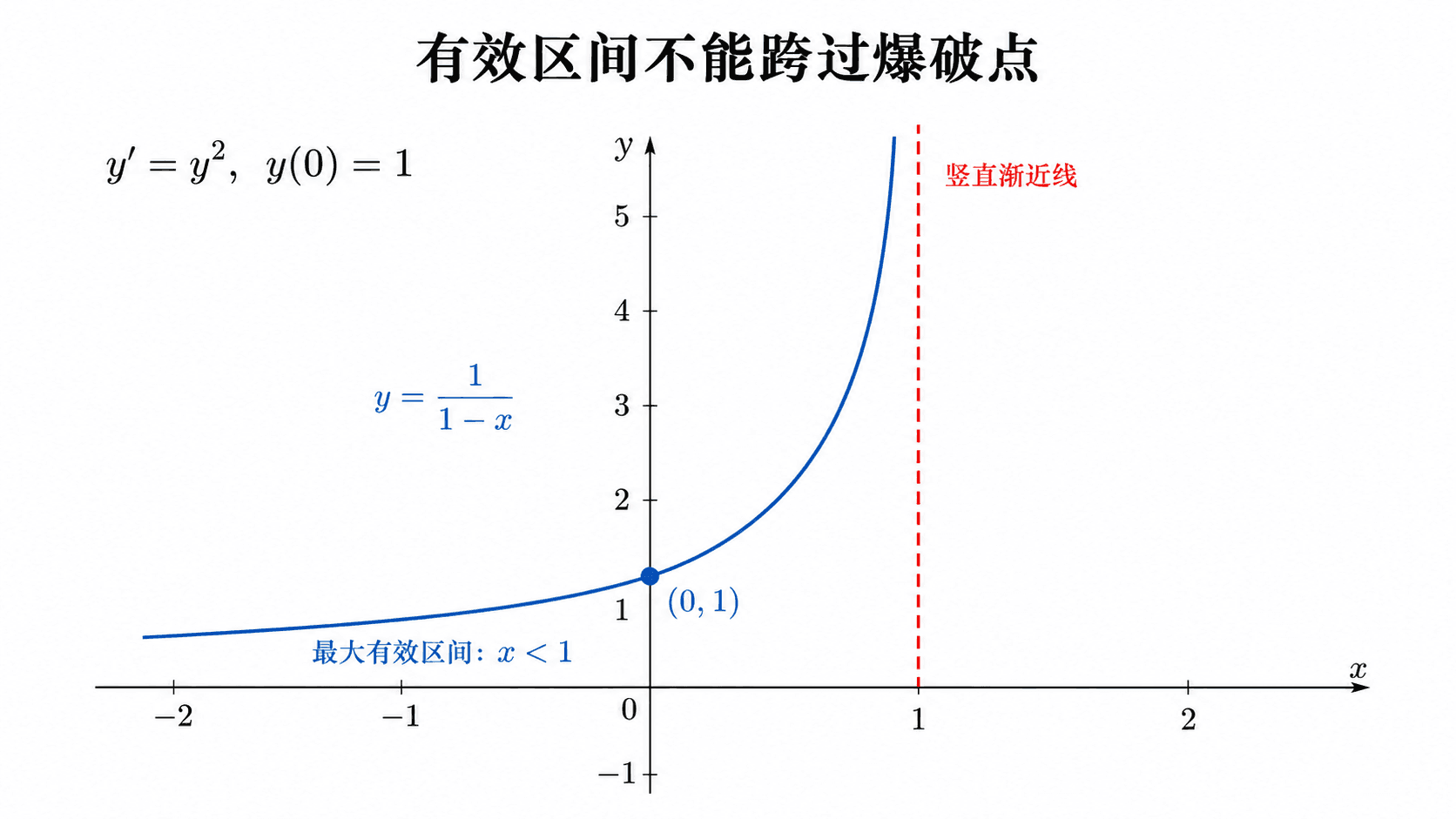 解出显式公式后仍要检查定义域;初值问题的有效区间不能跨过爆破点。
解出显式公式后仍要检查定义域;初值问题的有效区间不能跨过爆破点。
初值解的定义域不是“公式哪里有字面表达就算哪里”。它必须是一个包含初始点的区间,并且解函数和方程右端在这个区间上都保持有意义。
常数解、奇异解与丢解风险
许多可分离方程来自自治因子 h(y)。只要 h(y) 有零点,就有水平的常数解。它们在方向场里通常是分界线,其他解曲线可能靠近它、远离它,或者永远不能穿过它。
以
y′=2xy2
为例。因为 h(y)=y2,所以 y≡0 是常数解。
如果只看非零解,可以分离:
y2dy=2xdx.
积分得到
−y1=x2+C.
这给出一族非零解
y=−x2+C1.
但这族公式永远不能产生 y=0。原因不是 y=0 不存在,而是分离时除以了 y2。
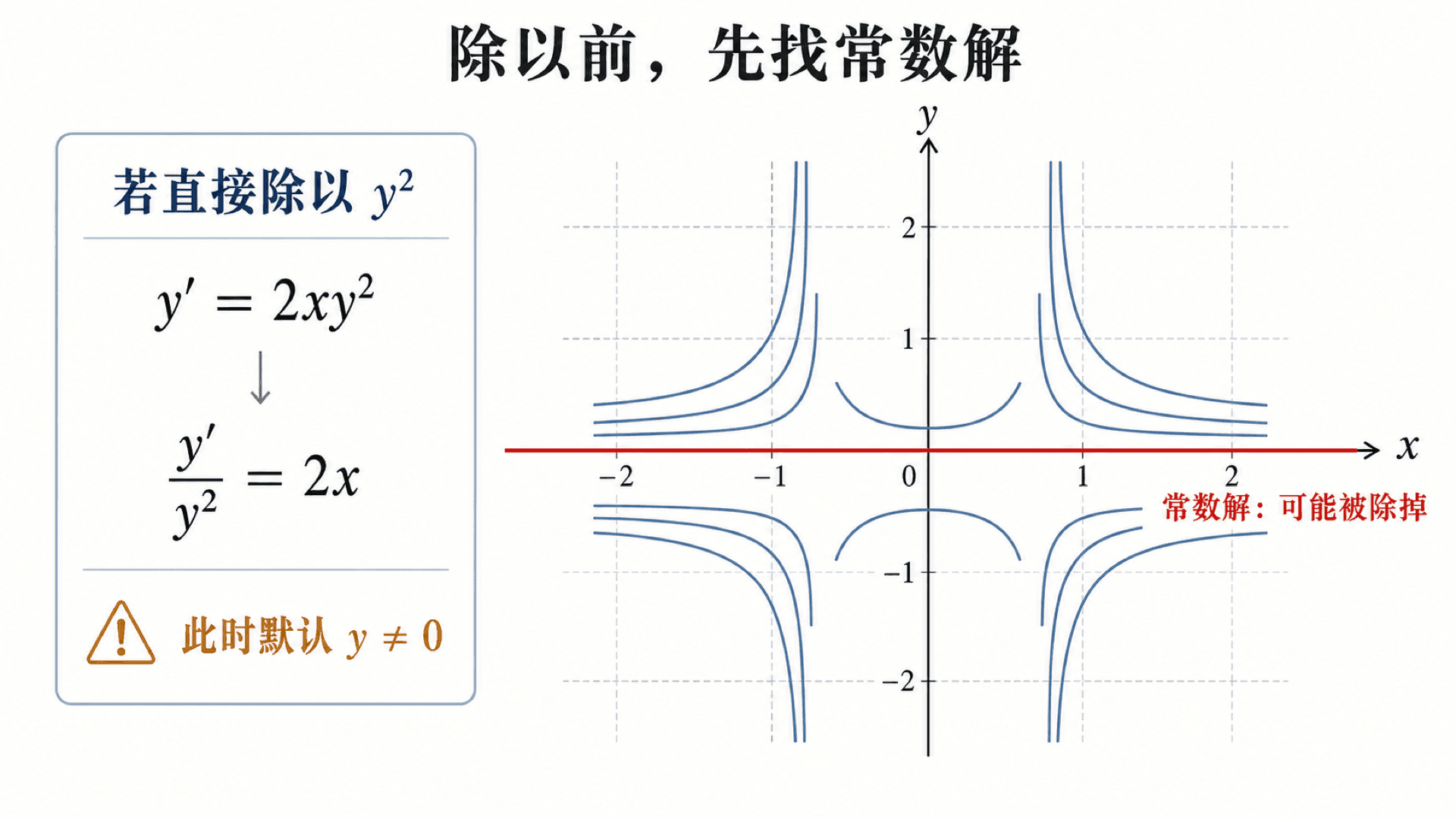 分离变量前先检查 h(y)=0;若直接除以 y2,会把常数解 y=0 从求解过程中排除。
分离变量前先检查 h(y)=0;若直接除以 y2,会把常数解 y=0 从求解过程中排除。
有些教材会把这种额外的水平解称为奇异解,也有教材把“不能由通解某个常数取值得到的解”才叫奇异解。本课程在一阶方程前半部分更关心实际操作:只要分离时除掉了某个因子,就必须回头检查它的零点是否给出额外解。
下面的检查器专门展示这个问题。切换 h(y) 后,先看水平解,再看分离积分得到的非水平解。
指数增长、指数衰减与半衰期
最常见的可分离模型是“变化率与当前量成正比”:
dtdy=ky.
如果 k>0,量会指数增长;如果写成
dtdy=−λy,λ>0,
就是指数衰减。放射性衰变、理想化的药物清除、某些无补充资源的数量减少,都可以用这个模型作第一近似。
求解衰减模型:
dtdy=−λy.
当 y=0 时,
y1dy=−λdt.
积分得到
ln∣y∣=−λt+C.
如果初始量 y(0)=y0>0,那么
y(t)=y0e−λt.
半衰期 T1/2 是使剩余量变成一半的时间:
y0e−λT1/2=2
消去 y0 后,
T1/2=λln2.
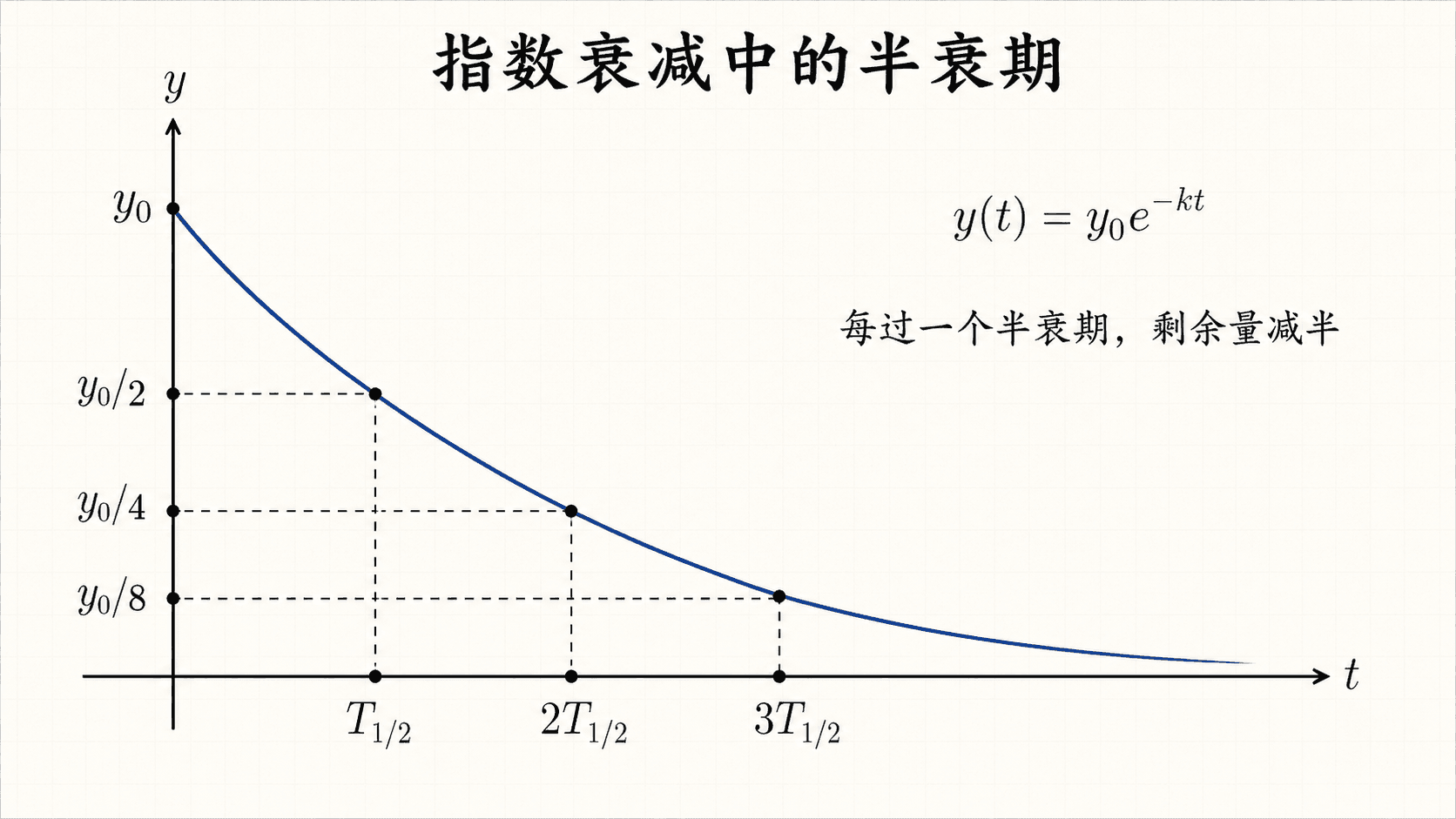 每过一个半衰期,指数衰减量剩余一半。
每过一个半衰期,指数衰减量剩余一半。
这个模型有一个很有用的尺度性质:无论一开始是 100 克还是 1 克,每过一个半衰期,剩余量都乘以 21。这也是指数模型和线性减少模型最不一样的地方。
指数模型的比例参数有单位。若 t 用天计,λ 的单位就是“每天”;若 t 用年计,λ 的数值会随单位改变。写模型时先定清楚时间单位,后面的半衰期才有明确意义。
常见误区
第一类误区是把所有一阶方程都当成可分离方程。判断时必须看右端能不能写成 g(x)h(y)。例如 y′=x+y 通常不能直接分离,而 y 可以。
第二类误区是把 dx 和 dy 当成普通数字随便消去。计算上可以使用微分记号,但解释上要能回到链式法则。只要你能指出左边是某个 H(y(x)) 的导数,分离步骤就有了根据。
第三类误区是忘记绝对值。积分
∫y1dy
给出的是
ln∣y∣.
在代入初值以后,如果已知解保持正或保持负,才把绝对值转化为对应的常数符号。
第四类误区是只写公式,不写区间。像 y′=y2 这样的例子会在有限时间爆破;像含有 ln∣y∣ 的解会自然分成正、负两个区域。初值解应写在包含初始点的有效区间上。
分离变量的答案要经得起代回原方程。特别是经过除法、取对数、开方、指数化之后,最好用原方程和初值各检查一次。能通过这两项检查的,才是当前初值问题的解。
练习
- 判断下列方程哪些可分离,并写出 g(x) 与 h(y):y′=x(1−y),,,。
可分离的是 y′=x(1−y),其中 g(x)=x,h(;,其中 ,;,其中 ,,但要注意 处右端无意义,不是可直接补上的常数解。 通常不能写成两因子的乘积,所以不按可分离方程处理。
- 求解初值问题
y′=(1+x)y2,y(0)=−1.
当 y=0 时,分离变量:
y2dy=
- 方程
y′=t(4−y2)
有哪些常数解?若 y(0)=0,求对应的非平衡解。
由 4−y2=0 得到常数解 y≡2 和 y≡−2。对满足 的解,在 内分离变量:
- 一个放射性样本满足 N′=−λN,半衰期为 8 天。若初始量为 N0,写出 N,并求 天后剩余比例。
半衰期公式给出
8=λln2,因此
λ=8ln
小结
可分离变量方程的主要计算式是
y′=g(x)h(y)⟹∫h(y
但真正稳定的做法不是背这行公式,而是形成一个检查顺序:先找 h(y)=0 的常数解,再在 h(y)=0 的区间分离积分,接着用初值确定常数,最后检查解的有效区间和代回原方程是否成立。
下一章的一阶线性方程会处理另一类常见模型。那时我们会看到,有些方程不能把变量完全分开,但仍然可以通过“把左边凑成乘积求导”来积分。