数据分析与统计基础
统计不是一堆公式在纸上打架,它更像是在一桌乱七八糟的证据里,帮你判断“这件事大概是什么样”。
比如班里刚考完数学。老师把成绩发下来,大家最关心的不是每一个人的分数,而是三个问题:
- 这个班大概考得怎么样?
- 大家水平差不多,还是有人特别高、有人特别低?
- 学习时间、刷题量、成绩之间有没有关系?
你看,统计学一上来就很生活。它不要求现实世界像代数题那样干净,恰恰相反,它承认现实里有噪声、有异常值、有误差,然后给你一套工具,把混乱的数据看出一点秩序。
这一节我们就围绕四件事聊:集中趋势看“典型水平”,离散程度看“稳定不稳定”,统计图表把数字变成图像,散点图和线性回归看两组数据之间有没有线索。
集中趋势:先找一个能代表大家的数
平均数、中位数、众数
假设你问:“这个班成绩怎么样?”如果老师回答“每个人成绩都不同,你自己慢慢看”,那基本等于没回答。我们需要一个代表值。
最常见的代表值有三个:平均数、中位数、众数。它们不是谁比谁高级,而是性格不同。
平均数最像“全班一起摊账”。所有分数加起来,再除以人数:
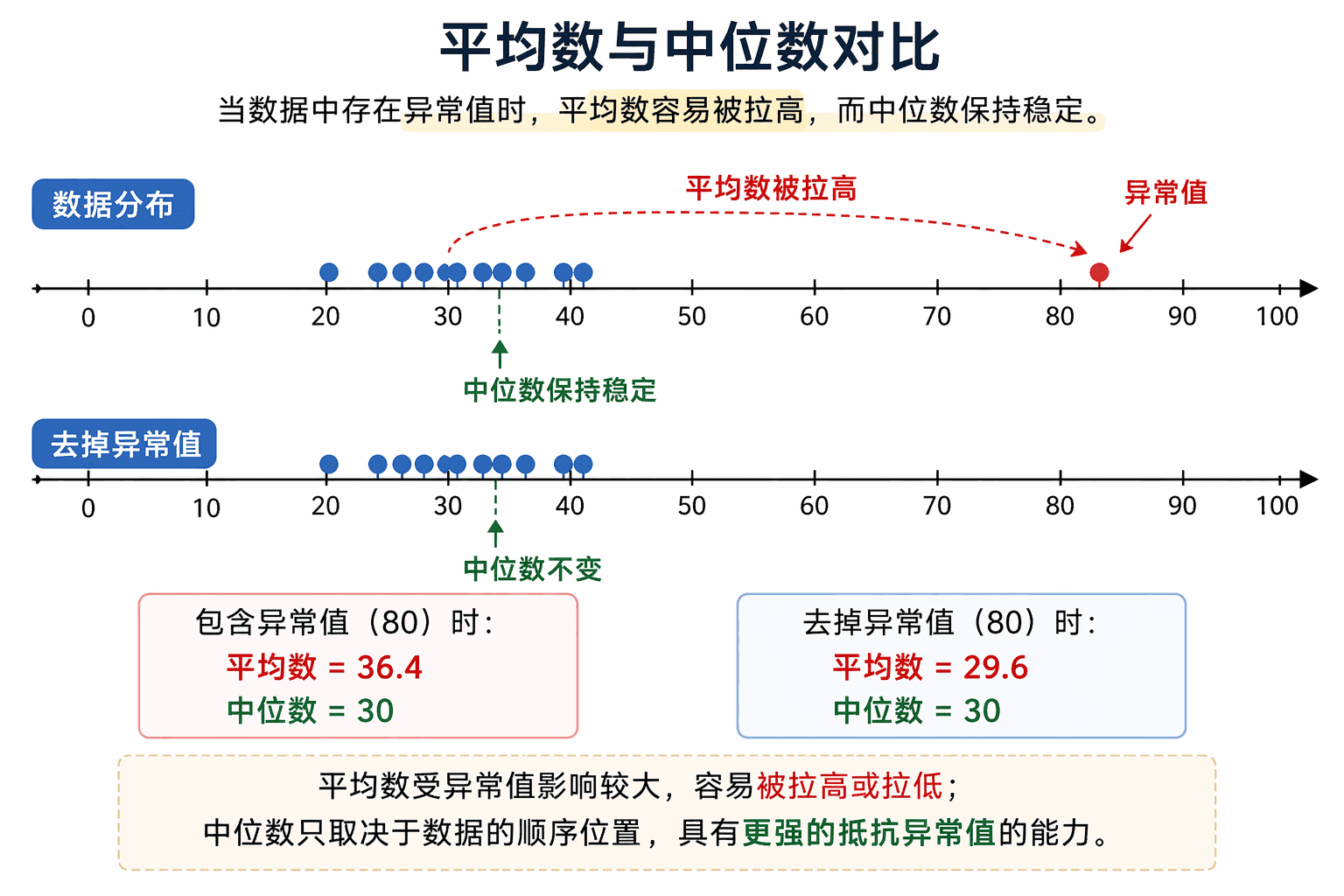
它的优点是公平:每一个数据都算进去。它的缺点也正是这个:每一个数据都算进去,所以特别怕极端值。
比如一组成绩是 ,平均分大约是 ,看起来很合理。现在突然来了一个考 分的新同学,平均分一下掉到 左右。你会发现,平均数不是说谎,它只是太容易被极端值拽走了。
中位数的想法就稳很多。先把数据从小到大排队,然后看中间那个。如果数据个数是奇数,就取正中间;如果是偶数,就取中间两个的平均值。
它不像平均数那样关心每个人具体差多少,只关心谁站在队伍中间。所以房价、收入这类数据常常用中位数。一个小区里如果有几套天价豪宅,平均房价会被抬得很夸张;中位数更接近普通人实际会遇到的价格。
众数更像“投票最多的选项”。奶茶店统计甜度,五分糖点得最多,那众数就是五分糖。它特别适合分类数据,比如尺码、颜色、选项、偏好。对连续成绩这种数据,众数有时不明显,甚至可能没有。
有一个很实用的判断:
- 数据比较对称,平均数、中位数、众数通常差不多。
- 数据右边拖着长尾,比如少数人收入特别高,常见关系是平均数 中位数 众数。
- 数据左边拖着长尾,方向就反过来。
所以别一看到“平均”就默认它最客观。统计里更重要的问题是:你想让这个数代表什么?
如果数据里有明显异常值,又想描述“普通水平”,优先看看中位数;如果你关心总体资源或总量分摊,平均数往往更有用。
离散程度:只知道平均还不够
有一次看球评,两个球员赛季场均得分都是 分。听起来差不多吧?但一个人每场稳定在 分,另一个人可能一场 分、一场 分。场均一样,球队用起来完全不是一个体验。
这就是离散程度要解决的问题:数据到底有多散。
最简单的指标是极差,也就是最大值减最小值。组 A 是 ,极差是 ;组 B 是 ,极差是 。这当然很直观。
但极差有点粗糙,因为它只看两头。中间的人怎么分布,它完全不管。
所以我们需要方差。方差的思路是:先算平均数,再看每个数据离平均数有多远,把这些距离平方后求平均。
为什么要平方?因为有的偏差是正的,有的是负的,直接相加会互相抵消。平方之后,离得越远,惩罚越重。
不过方差有个小麻烦:如果原单位是“分”,方差单位就变成“分²”,读起来很别扭。于是我们再开根号,得到标准差:
标准差的直觉非常好用:它大概表示数据点平均偏离均值多少。
还是那两组: 的标准差很小,说明大家挤在平均数附近; 的标准差很大,说明数据摊得很开。

换到生活里也很容易理解。两个城市年平均气温都是 ,但城市 A 标准差 ,城市 B 标准差 。A 城像四季温和,B 城可能夏天很热、冬天很冷。平均数一样,真实体感完全不同。
平均数回答“中心在哪里”,标准差回答“大家离中心远不远”。只报平均数,经常会漏掉最关键的故事。
统计图表:别让数字躺在表格里装睡
一列数字看久了,人会麻。好的图表不是为了好看,而是为了让数据的形状先跳出来。
茎叶图
茎叶图适合小数据集。它有点像把数字拆成“十位”和“个位”来排队。
比如运动时间 。用十位做“茎”,个位做“叶”,你既能看到分布大概集中在哪,也没有丢掉原始数据。
它的优点是信息保留得完整;缺点是数据一多就拥挤。
直方图
直方图适合大数据集。它把数值分成一段一段区间,比如 、、,再看每个区间有多少数据。
注意它和条形图不一样。条形图常用来比分类,比如苹果、香蕉、橙子;直方图用来展示连续数值的分布,所以柱子之间通常是挨着的。
你看直方图,重点不是一个具体数字,而是整体形状:是不是对称?有没有偏斜?有没有两个峰?有没有异常尾巴?
箱线图
箱线图更像一张“数据体检报告”。它用五个数压缩一组数据:
中间那个箱子从 到 ,叫四分位距:
它表示中间 的数据在哪里。离箱子太远的点,常常会被标成异常值。
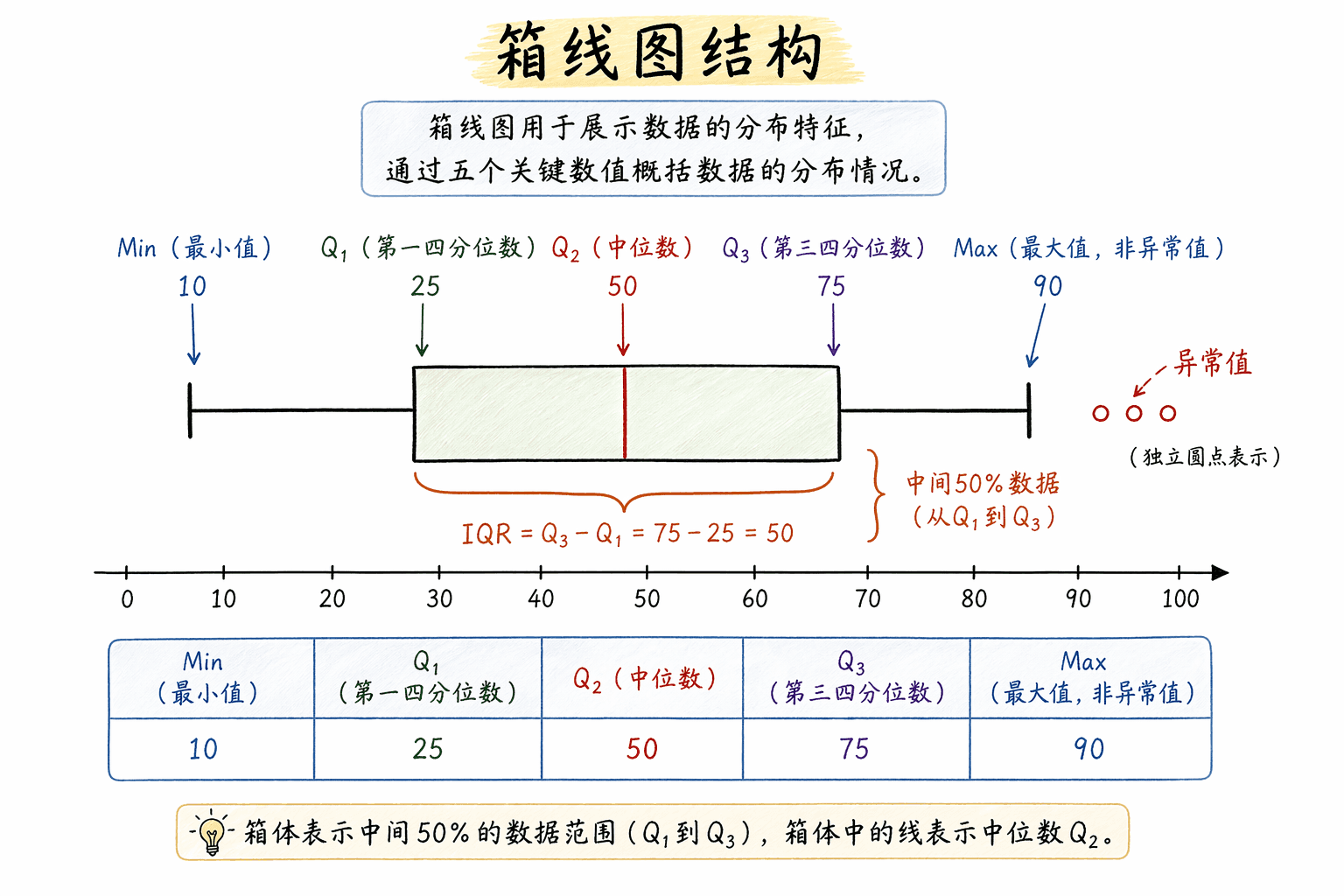
箱线图最适合并排比较。比如两个班成绩放在一起,你很快就能看出:哪个班中位数高,哪个班更稳定,哪个班异常值更多。
散点图:两件事是不是一起变化
前面都在分析一组数据。现实里更常见的问题是两组数据之间有没有关系:
学习时间越长,成绩越好吗?广告投得越多,销售额越高吗?屏幕时间越长,睡眠越少吗?
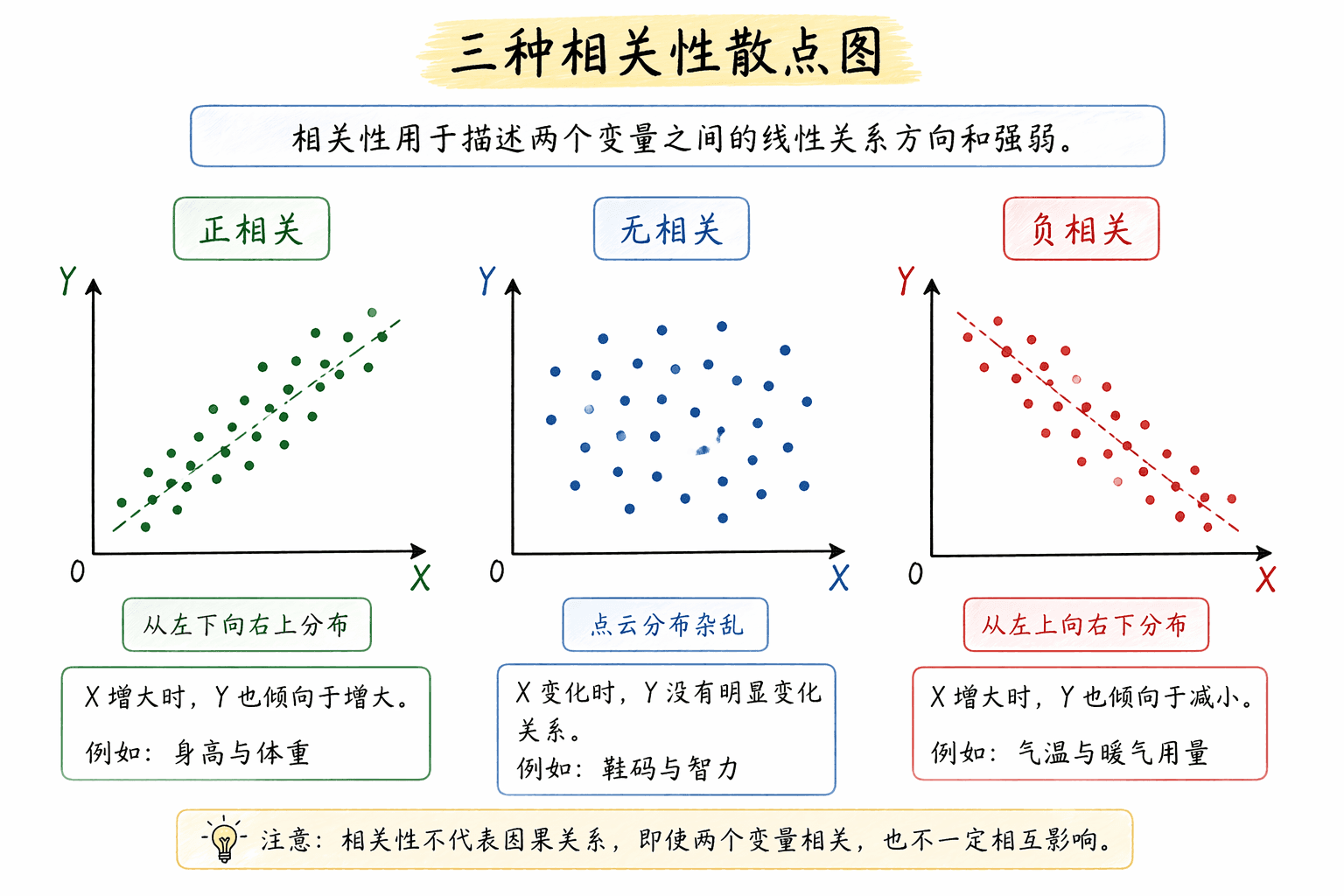
这时候用散点图。每个对象有一对数据 ,就在坐标系里点一个点。点多了以后,你看的是点云整体往哪里走。
- 从左下到右上,是正相关。
- 从左上到右下,是负相关。
- 乱成一团,是没有明显线性相关。
如果只靠眼睛看,有时会吵起来:“我觉得挺相关的”“我觉得也就那样”。所以统计学引入相关系数 ,范围是 。
接近 ,强正相关;接近 ,强负相关;接近 ,说明线性关系很弱。粗略地说, 可以看作强相关, 是中等相关, 就比较弱。
相关不等于因果。冰淇淋销量和溺水人数可能一起上升,但不是冰淇淋导致溺水,而是夏天同时让人更想吃冰淇淋、也更常去游泳。
线性回归:给点云画一条“最合适”的线
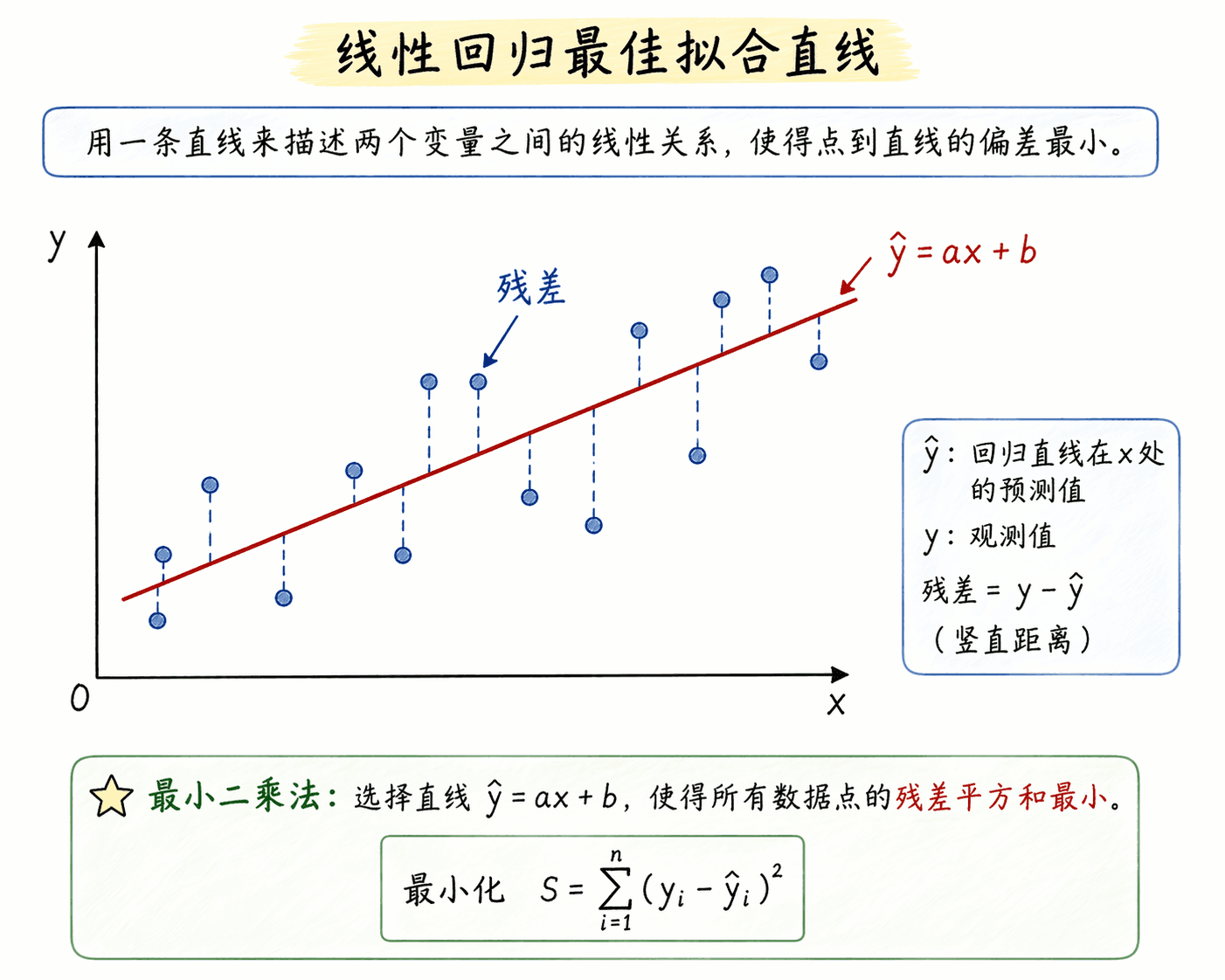
如果散点图看起来确实像一条斜着的路,我们就会想画一条直线来描述它:
这里 读作“y 的预测值”。这条线不是随便画的,它要让所有点到直线的竖直距离,也就是残差,整体尽量小。常用标准是让残差平方和最小,这叫最小二乘法。
斜率和截距可以用公式算:
公式看起来有点长,但含义不复杂。斜率 表示 每增加 个单位,预测的 平均增加多少;截距 表示 时的预测值。
回归线可以用来预测,但这里有个坑:预测最好在原始数据范围内做,这叫插值。如果拿 万元广告费的数据,去预测 万元广告费会卖多少,那就是外推。外推经常很危险,因为现实关系不一定一直线性。
衡量回归线拟合得好不好,可以看决定系数 。它等于 ,范围是 。比如 ,可以理解为:这个线性模型大约解释了 的 变化,剩下 还来自别的因素和噪声。
例题与解答
例题一:平均数会不会被异常值骗到
某外卖平台记录了 10 位骑手同一时段的送餐时间,单位是分钟:
求平均数、中位数和众数,并判断哪个更能代表典型送餐时间。
先排序:。排序是为了看中位数,也方便发现 这个明显偏大的值。
例题二:平均一样,稳定性怎么比
两位同学各参加 5 次竞赛。小明成绩为 ,小红成绩为 。两人平均分都是 ,谁更稳定?
小明的方差为
例题三:屏幕时间和睡眠时间
某校收集了 8 名同学每天屏幕使用时间和睡眠时间:
描述相关性,并说明能不能直接得出因果结论。
随着屏幕时间 增大,睡眠时间 明显减小,所以这是负相关。
这些点大体贴近一条向右下方倾斜的直线,实际计算可得 ,属于强负相关。
例题四:回归预测能不能乱用
某品牌连续 6 个月的广告费和销售额如下。已知最佳拟合直线为 ,。
解释斜率含义,预测广告费 万元时的销售额,并说明能否预测广告费 万元时的销售额。
斜率 表示广告费每增加 万元,销售额平均增加约 万元。截距 表示广告费为 时模型预测的基础销售额。
练习
练习一:数据 的平均数、中位数和众数分别是多少?
排序后是 。平均数为 ,中位数是第 4 个数 ,众数也是 。因为 把平均数往右拉高了,所以中位数和众数更接近这组数据的典型水平。
练习二:数据 的标准差是多少?
平均数为 。方差
练习三:相关系数 说明什么?
,所以方向是负相关;,所以强度较弱。也就是说, 增大时 有下降倾向,但这个线性关系不强。
练习四:若回归方程为 ,原始数据的 范围是 。用 和 预测,哪个更可靠?
在原始数据范围内,属于插值,预测相对可靠:
远超原始范围,属于外推,模型不保证仍然成立,所以不可靠。
小结
统计这套工具,真正要训练的是判断力。
平均数、中位数、众数都能描述“典型水平”,但它们适合的场景不同;极差、方差、标准差告诉你数据是不是稳定,只看平均数很容易错过波动;茎叶图、直方图、箱线图把数字的形状画出来,让你先看见分布;散点图、相关系数和线性回归帮助你观察两组数据之间的关系。
最后记住两句很重要的话:相关不等于因果,模型不等于现实。统计不是替你下结论,而是帮你更清醒地看证据。