代数 I:把工具箱整理成一张能用的地图
代数 I 学完了,到底应该留下什么?
我不会先回答“公式”。公式当然重要,但真正留下来的,应该是一种处理问题的手感:看见一堆文字、数字、图像、限制条件时,你知道先抓什么、怎么翻译、用哪把工具、最后怎样把答案说清楚。
这章不是再往脑子里塞新知识。更像是期末前整理书桌:草稿纸上有方程,错题本里有不等式,函数图像夹在笔记中间,统计题又像从现实世界突然闯进来。我们要做的,是把它们从“散落的一堆题型”,整理成一条能走通的路。
先讲一个很真实的场景
有个同学复习代数 I,翻到最后发现自己什么都“见过”,但一做综合题还是卡住。
他会解一元一次方程,也会背二次函数顶点公式;他知道分母不能为零,也知道方差是看波动。问题是,这些知识像一抽屉没贴标签的工具:需要锤子时摸到螺丝刀,需要扳手时拿出卷尺。
所以代数复习最关键的不是“再背一遍”,而是给工具贴标签:
- 这道题在问一个数,还是问一段范围?
- 它是固定关系,还是输入输出的变化关系?
- 它能不能改写成更好看的形状?
- 结果有没有定义域、单位、现实条件限制?
一旦这些问题能自动冒出来,代数就不再像一堆章节名,而像一套可以调用的操作系统。
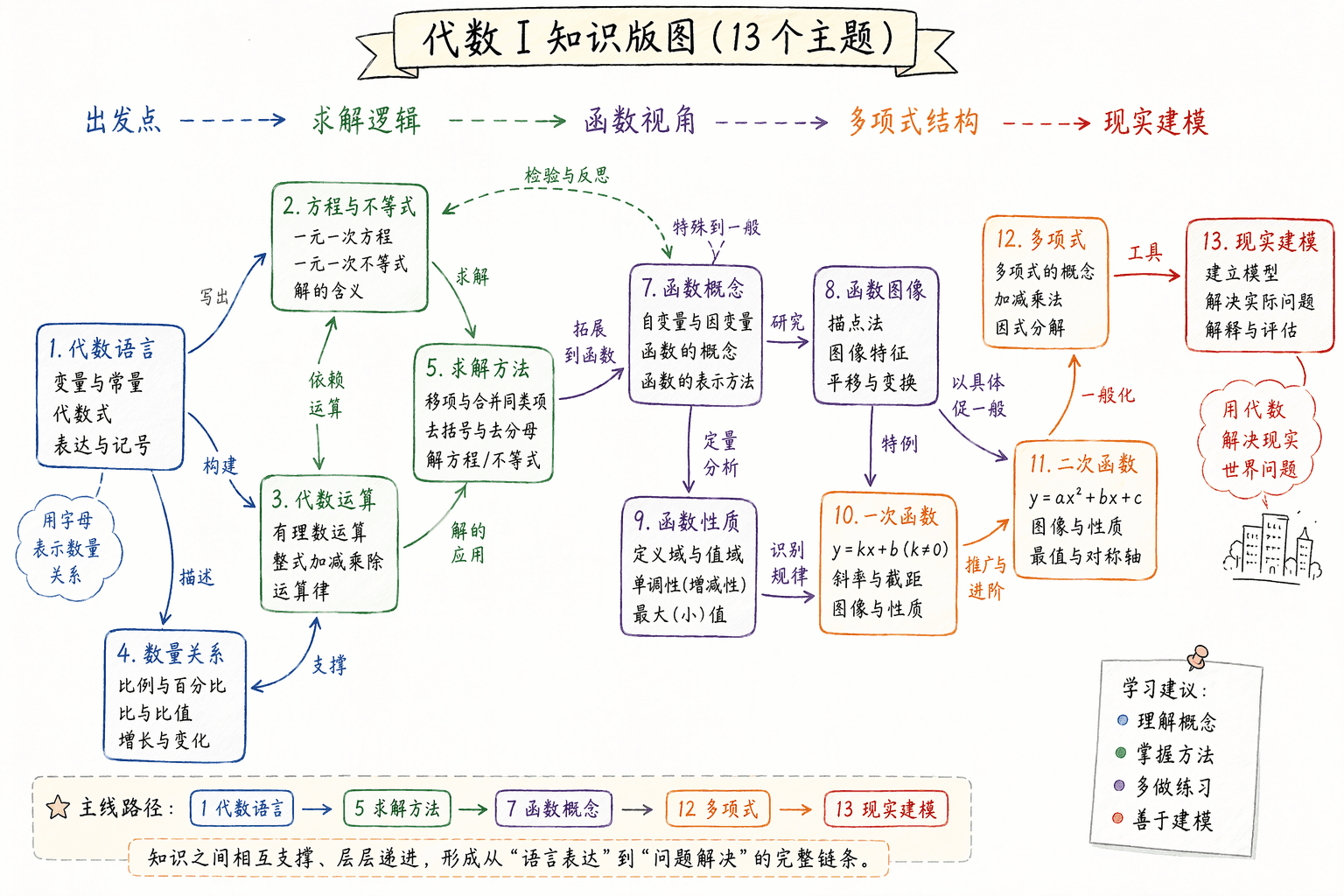
这门课其实在训练一件事
代数 I 的主线可以压成一句话:
用符号描述关系,再用规则处理关系,最后把结果放回问题里解释。
第一站是代数语言。变量不是“神秘字母”,它只是暂时不知道、或者会变化的量。常数是不变的量,表达式是关系的压缩写法。合并同类项、分配律、符号优先级,看起来像基础动作,但很多所谓“粗心”,本质上都是这一层没站稳。比如 和 ,差的不是计算能力,而是你有没有看清底数到底是谁。
第二站是方程与不等式。方程像在问:“什么时候两边能握手?”不等式像在问:“在哪些范围里,一边一直更大?”这里最重要的不是快,而是每一步都等价。方程可以两边同加同减,同乘同除非零数;不等式遇到负数乘除要翻方向。这个规则不花哨,但它决定你最后拿到的是答案,还是一个看起来像答案的误会。
第三站是函数视角。方程更像定点搜索,函数更像看一整条路。比如 ,方程会问“什么时候等于 11”,函数会问“ 每增加 1, 怎么变”。从这里开始,公式、表格、图像可以互相翻译。你不只是会算一个点,而是能读趋势、看斜率、判断截距、解释变化。
第四站是结构工具。多项式运算、因式分解、配方、判别式、韦达定理,本质上都是在帮你把表达式换一个更有用的样子。 可以写成 ,也可以写成 。前者适合找零点,后者适合看顶点。高手不是脑子里公式多,而是知道同一个对象什么时候该换哪张脸。
第五站是现实建模。指数函数讲增长和衰减,二次函数讲最值,有理函数提醒我们注意分母和渐近线,统计让我们承认现实数据有波动。到了这一步,代数不再只是纸面推导,而是在帮我们回答真实问题:怎样定价更赚钱?哪组数据更稳定?一个增长过程会不会失控?
遇到题,先别急着开算
很多题做错,不是因为不会算,而是因为一上来就算。代数题最怕“手比脑子快”。一个更稳的流程是下面五步。
读懂并翻译。 谁是未知量?谁是已知量?单位是什么?条件有几个?先把题目翻译成变量、式子、区间或图像。
识别骨架。 它是在求一个数、一个范围、一个最大值,还是在解释一组数据?题型不同,入口完全不同。
选入口,写过程。 方程组可以代入或消元,二次式可以因式分解或配方,分式方程要先盯住分母。过程别跳太狠,尤其是符号和括号。
检验结果。 结果在定义域里吗?端点开闭对吗?有没有增根?现实问题里,答案的数量级和单位合理吗?
一个老板的定价问题
来一道很像现实商业题的综合题。
某工厂卖一种商品,固定成本是 1200 元,每件变动成本是 20 元。市场调查说,如果售价是 元,一天大约能卖出
件,并且 。问:日利润 关于售价 的表达式是什么?售价定多少,利润最大?
这题表面上是利润,背后其实四个知识点在一起工作:
- 线性函数:销量 随售价 变化;
- 多项式运算:收入和成本要展开整理;
- 二次函数:利润会形成一条抛物线;
- 定义域:售价只能在 里面选。
收入是售价乘销量:
成本是固定成本加变动成本:
所以利润是:
配方以后:
这句话很直观:因为平方项永远不小于 0,前面又有一个负号,所以 时, 最大,只能等于 0。于是最大利润是 2000 元。
再别忘了查边界: 在 里面,所以这个顶点有效。若 ,利润是 1800;若 ,利润是 200。顶点确实最大。
![利润优化抛物线:坐标系中画开口向下抛物线 W=-2(p-60)²+2000,区间[50,90]用实线标出,顶点(60,2000)标注,两端点(50,1800)和(90,200)标出,中文标注,手绘教科书风格](https://media.edu-free.com/uploads/welearn_22181022_6b05958a2f.png)
真正值得带走的五种反应
第一,先问对象是什么。 看到 ,它可以是一个表达式,也可以是一条抛物线,也可以是一道方程的左边。对象不同,处理方式就不同。把 当成整体移动、伸缩,比把每一项硬拆开更清楚。
第二,会换视角。 同一个二次式,因式分解形式适合找零点,顶点形式适合找最值,标准形式适合看系数。你不是在背三种写法,而是在给同一个问题换镜头。
第三,有边界意识。 分母不能为零,被开方数要非负,不等式乘负数要翻方向,含参题要注意参数让方程变形。代数里最容易出事的地方,往往不在中间计算,而在这些边界。
第四,会估算和自检。 如果利润算成负几万,长度算成负数,概率算到大于 1,就该停下来。自检不一定是重做一遍,而是抓住高风险位置:定义域、端点、验根、单位。
第五,把错题当诊断报告。 做错一道题,不只是“我粗心了”。更有用的问法是:我错在翻译,错在变形,错在选工具,还是错在最后表达?错因被说清楚,下一次才有机会真的避开。
代数 II 会怎么接上来
代数 I 结束,不是代数故事结束,而是基础设施搭好了。
后面你会遇到更高次的多项式、更复杂的有理函数、指数函数的反面角色对数函数,还有描述周期的三角函数。它们看起来新,但学习框架不会变:定义域、值域、图像行为、特殊点、变换规律。
方程也会变复杂。你会见到复数根、更高次方程、多元系统。判别式的思路、韦达定理的逻辑、因式分解的习惯,都会继续出现。
统计会和概率合流,数据不再只是算均值和方差,而会开始讨论随机事件、预测和不确定性。建模也会更系统:对数描述增长变慢,三角函数描述周期,矩阵处理多变量关系。
但核心仍然是同一句话:看清对象,建立关系,选择工具,验证解释。
综合例题
例题一:含参二次方程
已知关于 的方程
求方程有两个不等实数根时 的范围;若两根之差的绝对值等于 3,求 的值及两根。
这类题不要一上来求根。先问:题目真正给了什么信息?“两个不等实数根”在二次方程里就是判别式大于 0。
计算判别式:
例题二:二次函数在区间上的最小值
设
求 在区间 上的最小值。
这题的关键不在配方本身,而在“顶点有没有落进区间”。
先配方:
所以抛物线开口向上,顶点是 ,对称轴是 。
![动端点最小值问题:两个并排抛物线图,左图区间[0,a]完全在对称轴x=1左侧,最小值标在右端点a处;右图区间含对称轴,最小值标在顶点(1,-4)处,中文标注,手绘教科书风格](https://media.edu-free.com/uploads/welearn_61513986_9d161a7218.png)
例题三:有理方程
解方程:
有理方程第一反应不是通分,而是先看分母。因为你后面所有操作,都必须尊重定义域。
分母限制:
所以 且 。
例题四:均值相同,方差不同
某校统计了两个班各 5 名学生每周课外活动时长,单位是小时:
分别计算均值与方差,并判断哪个班更稳定。
很多人看到“平均数一样”就想下结论,但统计题最怕只看中心、不看分散。
A 班均值:
练习
练习一: 已知方程 有两个正实数根,求 的范围。
两个正实数根要同时满足三件事:有实根、两根和为正、两根积为正。
由判别式:
练习二: 求函数 的定义域,以及垂直渐近线和水平渐近线。
先看分母:,所以定义域是 ,也就是
练习三: 数据 的均值和标准差各是多少?
均值:
方差:
小结
如果把代数 I 看成一部连续剧,第一集是 ,中间有方程组、函数、指数、多项式、二次方程、分式和统计,最后一集不是“公式大全”,而是一个更稳定的你。
你开始知道:题目不是拿来硬算的,而是先被翻译;表达式不是死的,它可以换形状;图像不是插图,它能告诉你趋势和边界;统计结论不能说太满,因为数据总带着波动。
代数能力就是在这样的循环里长出来的:看清对象,选对工具,严格推导,诚实收口。带着这套习惯进入代数 II,后面的新内容会多,但你一定不会完全陌生。