函数综合建模:选择合适的函数描述现实问题
前面几章分别学习了指数、对数、多项式、有理函数、根式函数,以及它们的图像、方程和变换。本章把这些工具放回现实问题里:给出一组数据、一段情境或一个目标,我们怎样判断该用哪一种函数来描述?
建模不是看到数据后“猜一个看起来像的公式”。更可靠的做法是同时看五件事:数据形状、变化率、约束条件、单位含义和问题目标。同一组点可能被几条曲线贴得不错,但只有符合情境、能解释参数、误差表现合理的模型,才值得使用。
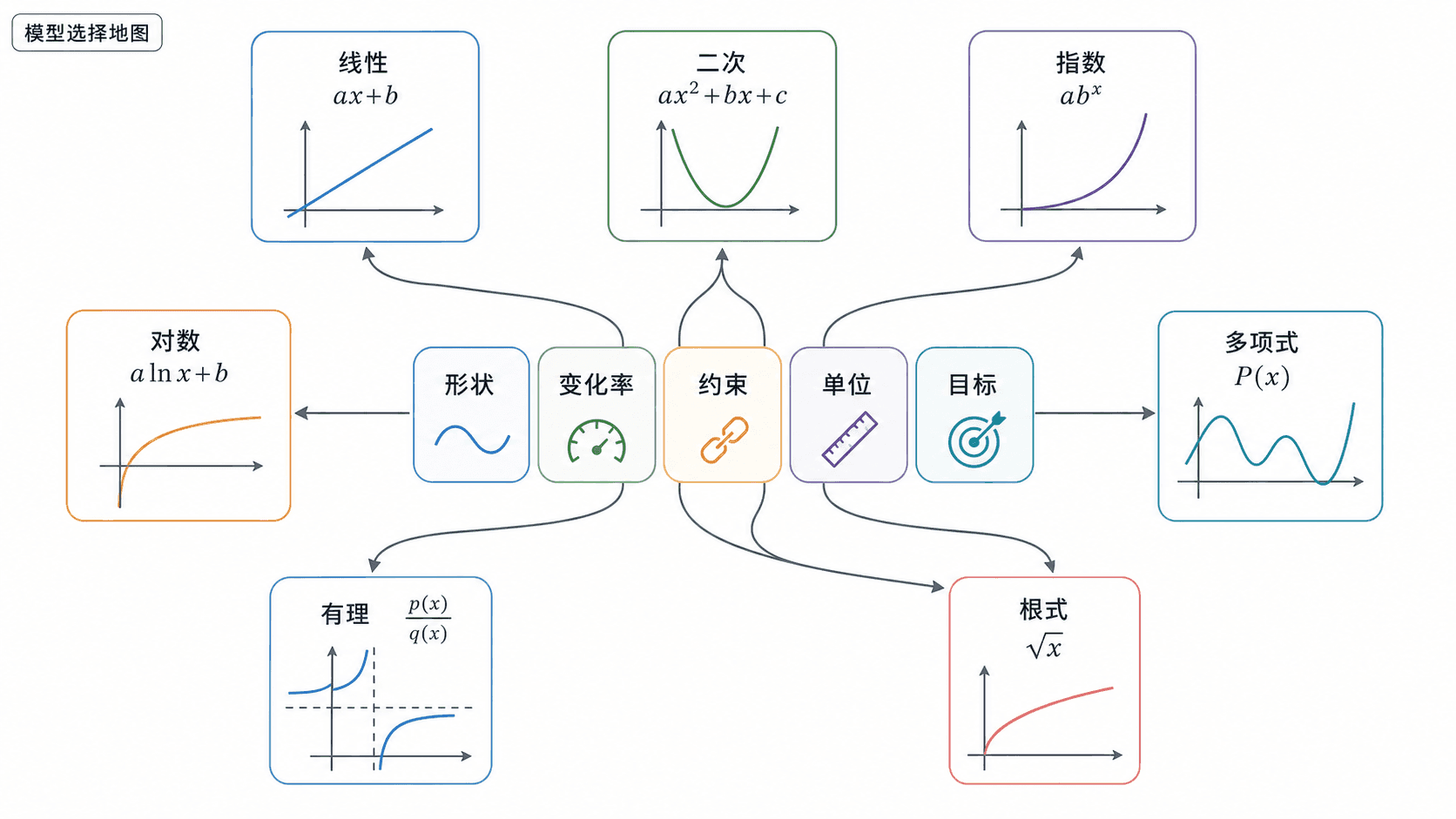
图:选择函数模型时,把数据、变化率、约束和问题目标一起看。
建模不是公式竞赛
一个函数模型把现实中的两个变量联系起来。输入变量通常是时间、距离、数量、浓度、价格或温度,输出变量通常是成本、人口、面积、速度、收益或风险。模型的任务不是复制现实的全部细节,而是在给定范围内抓住主要关系。
例如一家打印店的收费可能近似满足
这里 是打印页数, 是总费用。这个模型说明每多打印一页,费用增加 元,另有固定服务费 元。若题目只讨论 到 页,这个线性模型很自然;若讨论机器磨损、批量折扣或长期运营,它就可能不够。
建模时先问“这个公式在现实中想解释什么”,再问“它是否贴合数据”。只看图像像不像,容易选出一个短期漂亮、长期荒唐的模型。
模型的三种来源
有些模型来自结构关系。固定单价加固定费用自然给出线性函数;面积随边长平方变化自然给出二次函数;平均成本常出现“总成本除以数量”的有理函数。
有些模型来自变化规律。每小时增加同样多,偏向线性;每小时增加同样百分比,偏向指数;每次输入乘以同一倍数,输出增加差不多同样多,偏向对数。
有些模型来自数据拟合。我们并不知道真实机制,只能先画散点图,尝试几个候选函数,再用残差和情境判断哪个更稳。
先读现实问题
在动笔设函数前,先把题目翻译成变量和限制。下面这张“问诊卡”比直接套公式更有用。
定义域先于拟合
如果输入是人数、件数、页数,实际定义域通常是非负整数。我们可以用连续函数近似分析,但最终解释时要回到整数。
如果输入是时间,通常 。如果输出是高度、质量、浓度或成本,负值往往没有意义。一个模型在代数上能算出负数,不代表现实允许负数。
例如物体从高处落下的高度可用二次函数近似:
这个式子只在物体接触地面前有意义。当地面高度设为 时,模型给出 的部分不能解释成“地下高度”,而应当说明模型的使用区间已经结束。
单位会暴露错误
若 的单位是秒, 的单位是米,那么线性模型 中 的单位是米/秒, 的单位是米。指数模型 中, 的单位是米, 必须是无单位倍数;如果写成 ,通常需要说明 是按“每小时”“每年”等固定单位计量。
对数模型尤其要注意。 里的 本身应当是无单位的比例,或者已经除以某个基准量。例如声音强度等级常用“强度与基准强度的比值”进入对数,而不是直接对“瓦/平方米”取对数。
模型参数不是装饰。一个参数如果无法用单位和情境解释,往往说明变量设定或函数形式还没有想清楚。
用变化线索缩小函数族
不同函数家族最可靠的识别线索,不只是“图像长得像”,而是“变化方式怎样”。下面的表不是死记规则,而是帮助你把观察转化成候选模型。
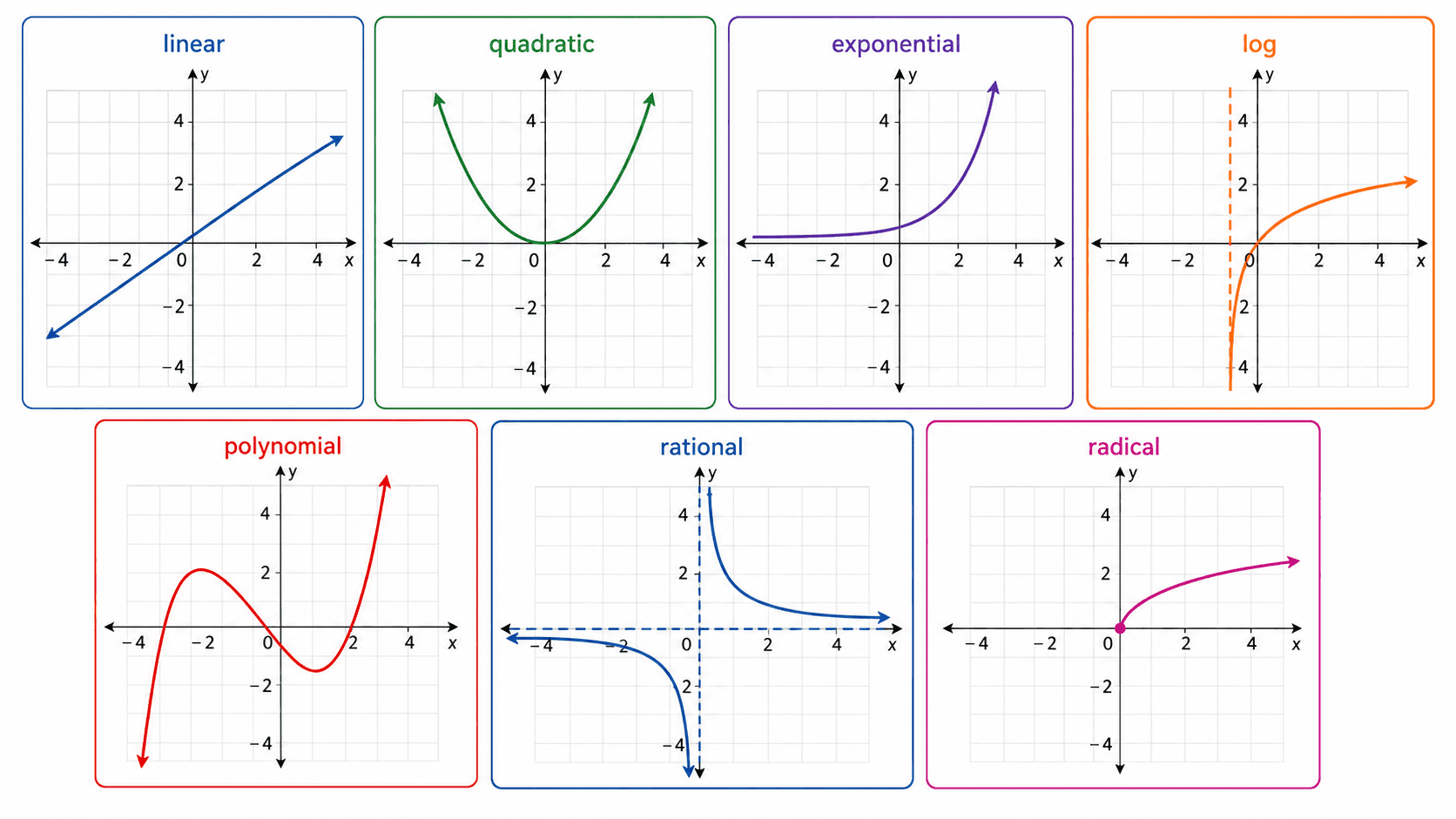
图:常见函数家族的图像轮廓不同,变化方式也不同。
线性与指数的关键区别
线性变化看“差”。如果 每增加 , 大约都增加 ,那么线性模型有理由成为第一候选。
指数变化看“比”。如果 每增加 , 大约都乘以 ,那么指数模型更自然。
假设某产品上线后的用户数如下:
相邻差值约为 ,并不稳定;相邻比值约为 ,更稳定。因此可先试
这个模型的意思是每周约增长 。但如果产品市场有限,长期增长不可能无限持续,这个指数模型只能用于短期预测。
二次与多项式要看转折
二次函数只有一个最高点或最低点。抛物线运动、固定周长下的矩形面积、收益随价格先增后减等问题,常出现二次模型。
高次多项式能出现多个转折和多个零点。它适合表达“图像要穿过这些点”“端行为这样”“某些零点有重数”等结构条件。但用高次多项式拟合数据时要小心:次数越高,越容易贴住已知点,也越容易在点与点之间摆动得不合理。
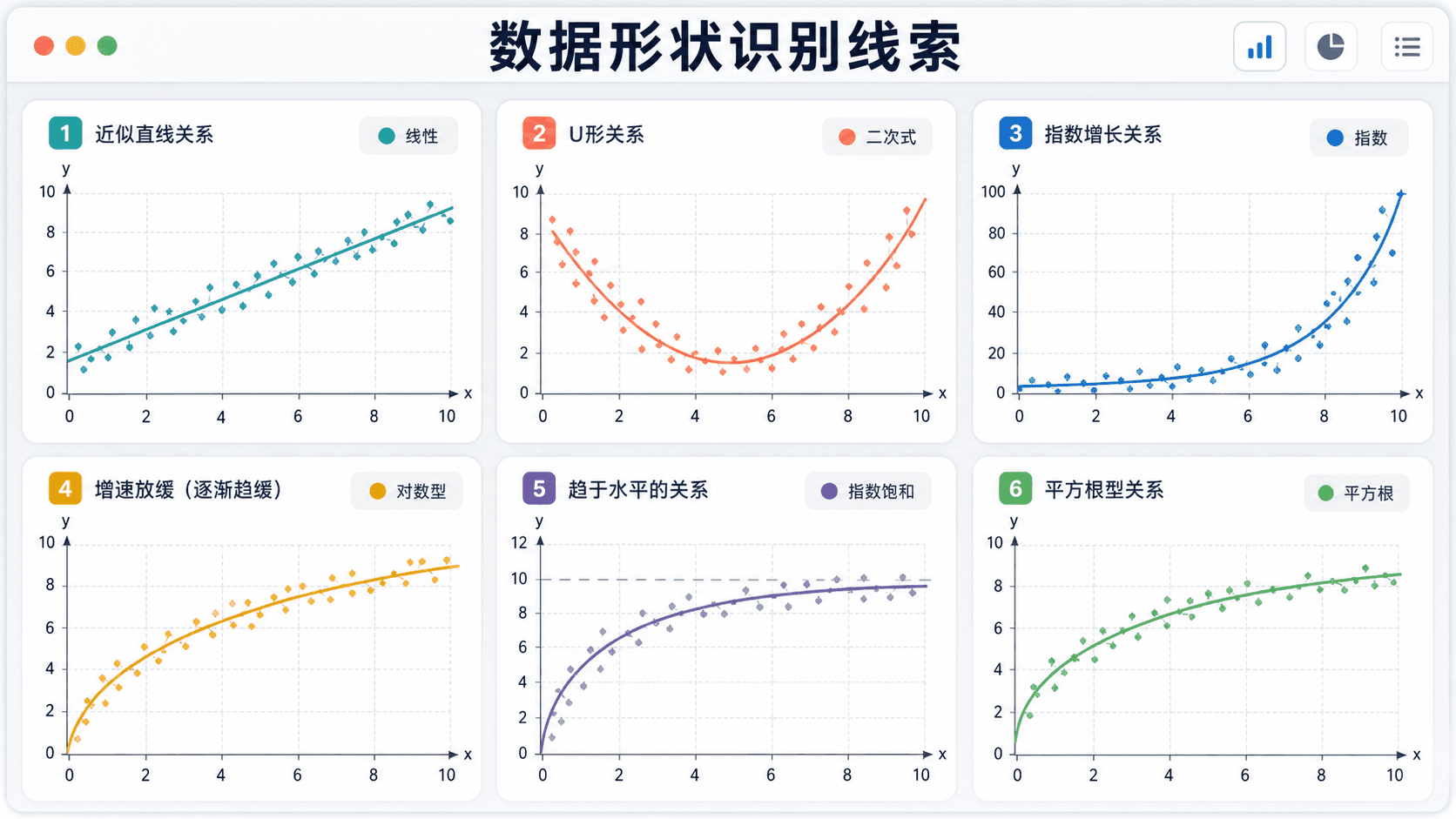
图:散点图的整体形状可以帮助排除不合适的模型。
对数、根式和有理函数经常被混淆
对数函数和根式函数都可能“先快后慢”。区别在于来源:对数常来自指数的反问题,或者输入按倍数变化时输出加法变化;根式常来自平方、面积、能量、距离等幂关系的反解。
有理函数也可能有“先快后慢”的样子,但它通常带有渐近线或分母限制。例如平均成本
其中 是产量, 是每件平均成本。随着 增大,平均成本接近 元,但不会低于变量成本 元。这条水平渐近线有现实意义。
建模流程
完整建模可以按六步走。实际做题时不一定每步都写很多字,但心里要过一遍。
明确问题目标。题目要预测、解释、比较、优化还是求临界值?不同目标会影响模型选择。优化题常需要顶点或极值,短期预测常更重视误差,解释题更重视参数含义。
定义变量和单位。写出输入、输出、单位、合理定义域和值域。若变量需要平移,例如从实验开始计时,说明 的含义。
看情境结构和数据形状。先用语言判断是否有固定费用、比例增长、反比、面积、平方根、渐近线或最大值;若有数据,再画散点图和变化率表。
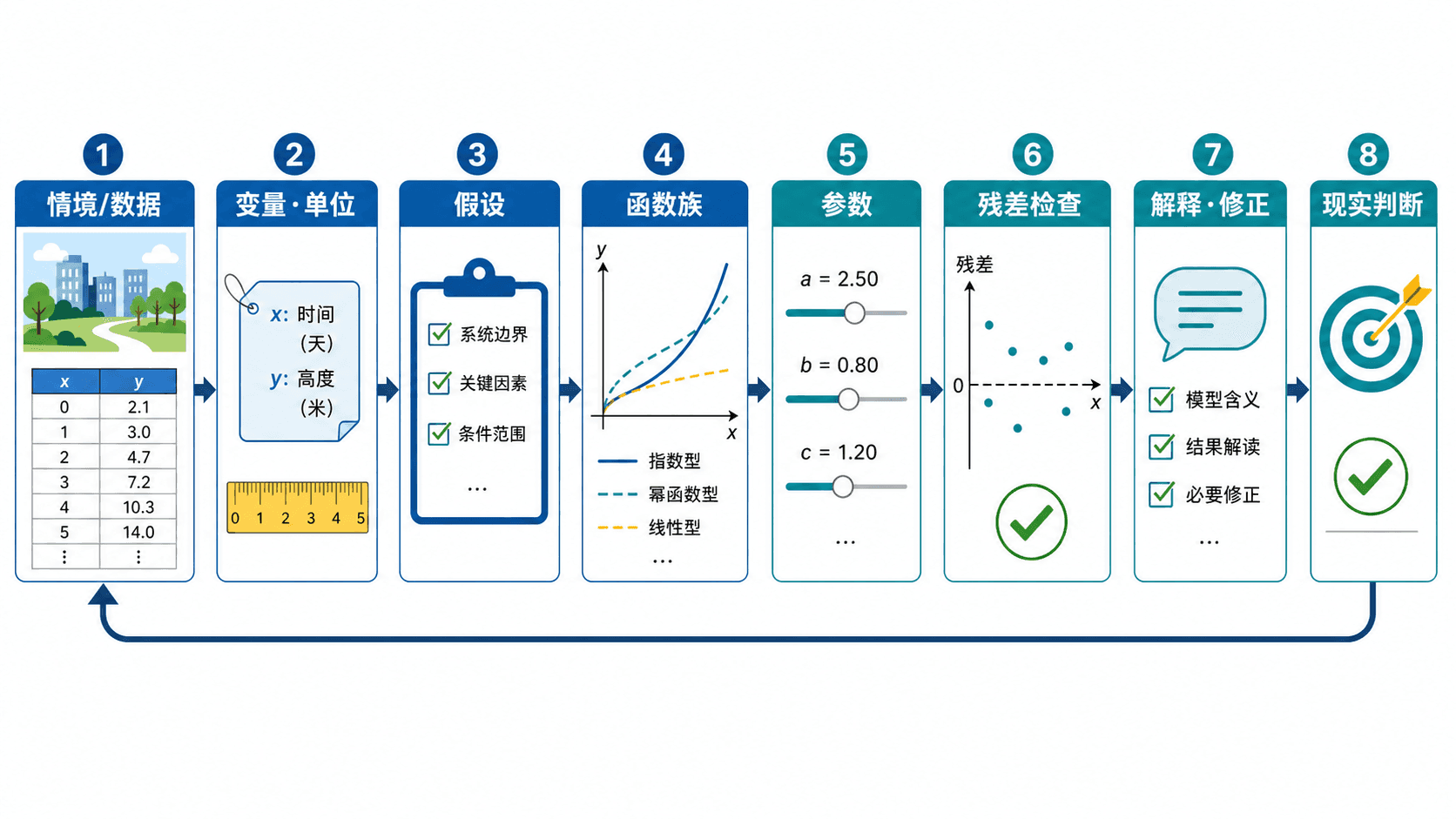
图:从现实问题到模型解释,需要反复检查变量、假设、参数和误差。
变化率表是一种低技术但很强的工具
当输入等间隔时,先看差分:
如果 接近常数,线性模型优先。如果二阶差分
接近常数,二次模型优先。如果比值
接近常数,并且 都为正,指数模型优先。
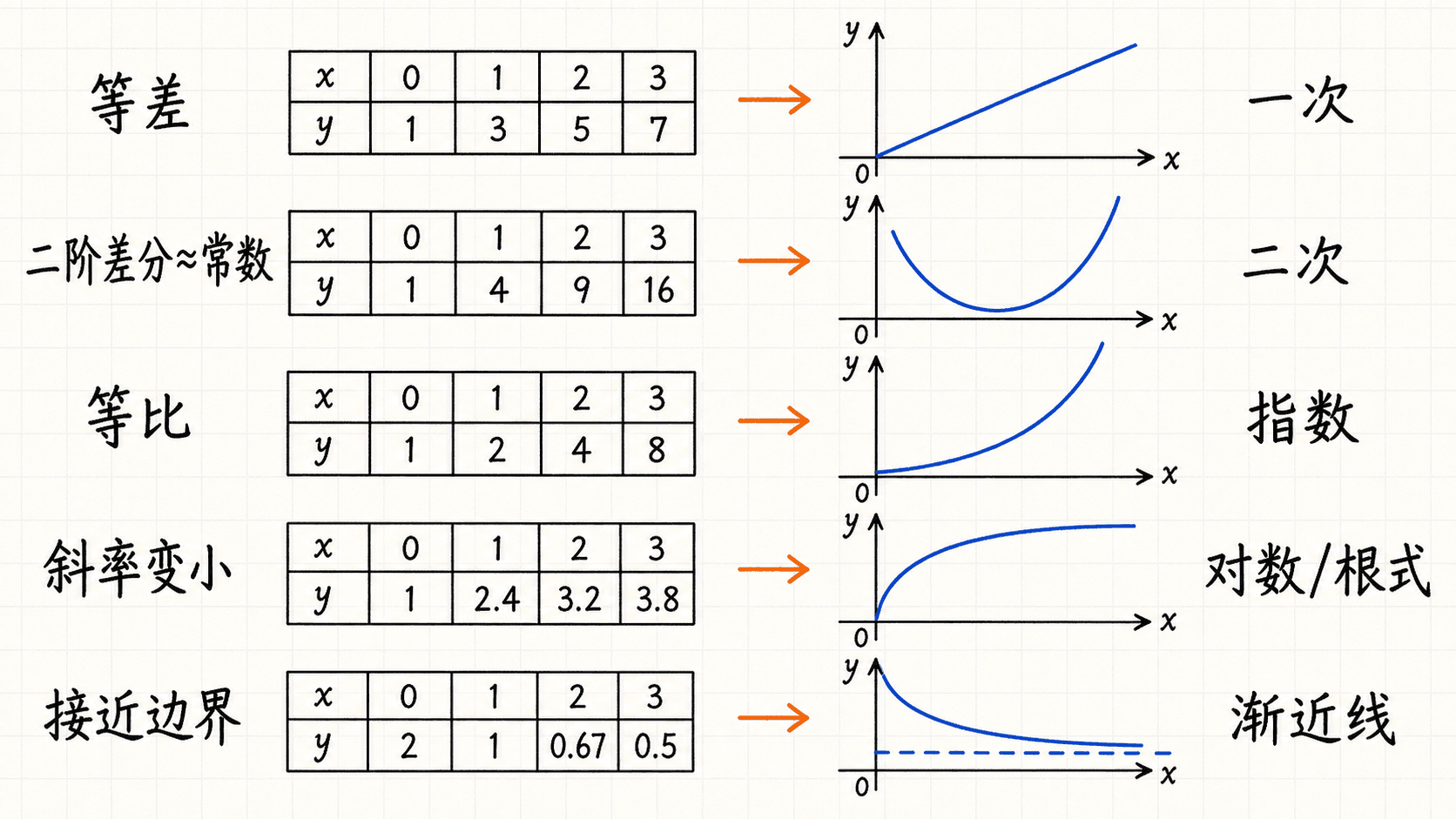
图:差分、二阶差分和比值分别对应不同的变化线索。
例题:从数据选择候选模型
某实验记录了水杯中热水与室温的温差 随时间 的变化。室温保持不变,数据如下:
问题:用什么函数描述温差随时间变化比较合适?
先看情境。温差越大,散热通常越快;温差越小,散热变慢。输出 应为正,并且会逐渐接近 。这已经提示我们关注指数衰减,而不是线性衰减。
再看相邻比值。每隔 分钟,温差比值约为 ,相当稳定。这比相邻差值更稳定。
如果有人用线性模型连接 和 ,会得到大约
它在 分钟时预测温差为 ,再往后会变成负数。短时间内它可能误差不大,但长期行为和散热机制不合适。
当“每段减少同样百分比”比“每段减少同样数量”更稳定时,指数模型通常比线性模型更有解释力。
例题:约束条件比拟合更早
某工厂生产小零件。每天开机固定成本为 元,每个零件的材料和加工成本为 元。若当天生产 个零件,平均成本 怎样建模?
这里不要先画曲线,而要先读结构。总成本是
平均成本是总成本除以产量:
化简得到
这个模型有几个关键信息。
首先, 不能为 ,因为没有产量时“每件平均成本”没有定义。其次,随着产量增加,平均成本下降,但会逐渐接近 元。最后,水平渐近线 表示单件可变成本,不是随便画出来的线。
若只用几个产量数据做拟合,线性函数也许在某个小区间内看起来不错。例如在 到 之间,平均成本确实近似下降。但线性模型向右延伸会继续下降,甚至可能预测负成本,这与固定成本被摊薄的结构不一致。
图:现实结构会把问题推向不同函数家族。
再看一个根式模型
一个圆形油污在水面扩散,面积 与半径 的关系是 。如果已知面积随时间变化,现在想用面积估计半径,就会得到
这个根式模型的定义域是 。它的图像随着面积增大而上升,但增长越来越慢。这个“变慢”不是因为对数,而是因为半径是面积的平方根。
比较模型与检查误差
模型比较通常不能只靠肉眼。拟合后要计算预测值 和残差 :
残差为正,表示模型低估;残差为负,表示模型高估。常见误差指标有平均绝对误差和均方根误差:
RMSE 对大误差更敏感。若某个模型整体误差小,但在关键区间偏差很大,也未必适合题目目标。
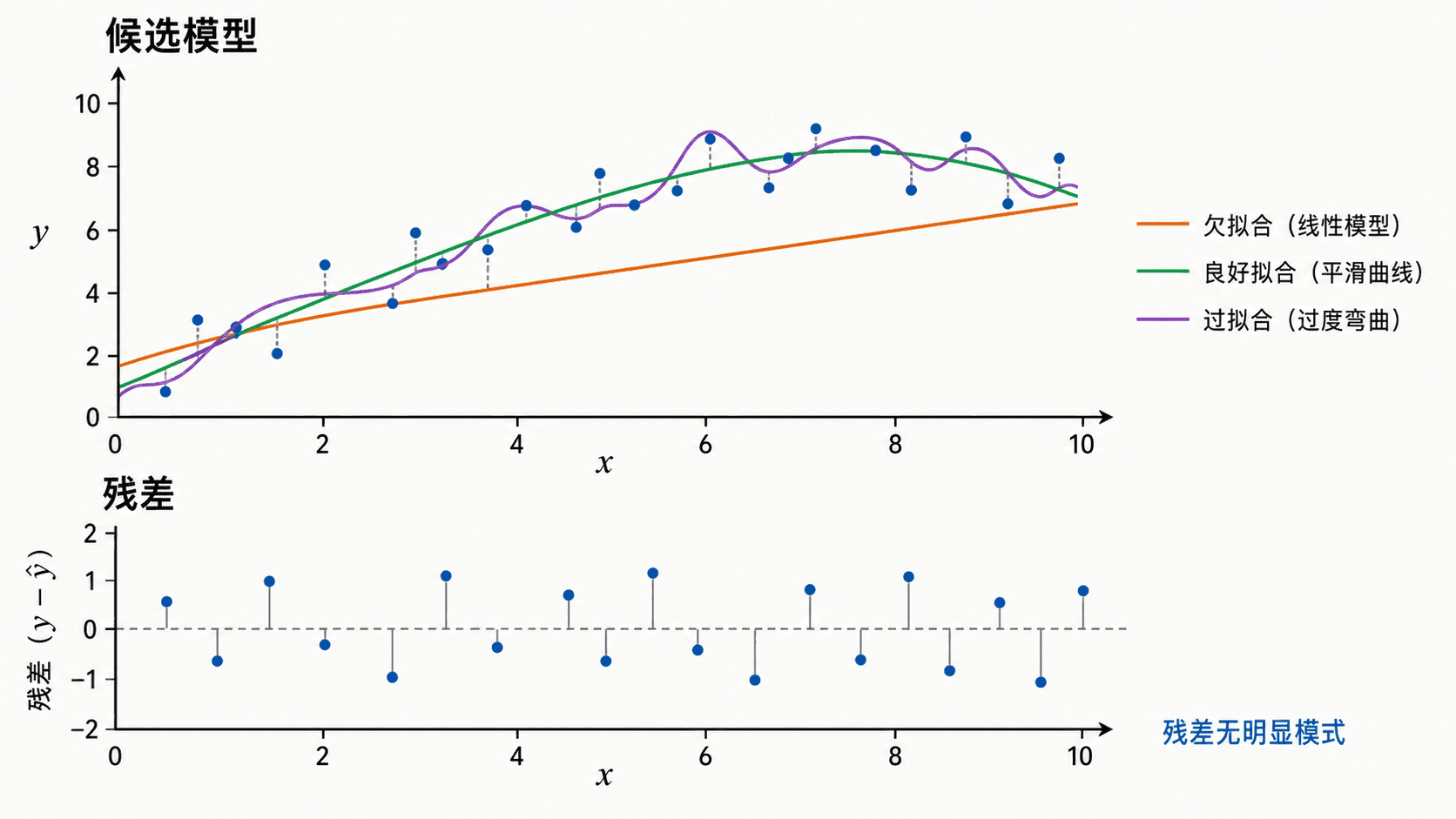
图:残差图能显示模型是否遗漏了系统性形状。
好残差不是“全部为零”
真实数据通常有测量误差和偶然波动,所以残差不可能全为零。更重要的是残差有没有明显模式。
如果残差围绕 上下随机分布,说明模型抓住了主要趋势。如果残差先正后负再正,可能说明线性模型漏掉了曲率。如果残差越来越分散,可能说明误差大小随输入变化。如果只有一个点异常大,需要回到数据来源,判断它是测量错误、特殊事件,还是模型遗漏了关键变量。
不要把“误差最小”自动等同于“模型最好”。高次多项式可能把已知数据贴得很紧,却在数据范围外快速摆动。建模要在误差、解释、简洁性和使用范围之间做选择。
一个比较示例
某平台记录一条学习视频发布后的累计观看量:
观看量一直增加,但增加速度逐渐变慢。若用指数增长,长期会越来越快,不符合“增长变慢”的形状。若用线性模型,可能在中间段还行,但早期和后期都有系统偏差。
注意输入天数每次大约翻倍,而观看量的增加量大致为 ,不是严格相等,但“输入按倍数增加时,输出按加法增加”的趋势比较接近。可以先尝试对数模型:
若取 和 两个点估计,得
所以
模型为
这个模型不是说视频会永远按对数增长,而是在这段观察窗口中,它比指数增长更符合“热度逐渐减弱”的情境。真正使用时还要算残差,并检查是否存在推荐算法、节假日或外部转发带来的异常点。
常见误区
误区一:增长就是指数
只要函数在增加,就叫指数增长,这是常见误会。指数增长要求“按固定比例增长”。若每月多卖 件,是线性;若每月销量乘以 ,才是指数的线索。
误区二:图像弯曲就用二次
二次函数只有一个转折,且二阶差分接近常数。若数据有明显渐近线,可能是有理或指数衰减;若先快后慢且输入必须为正,可能是对数或根式;若有多个转折,才考虑更高次多项式。
误区三:对数模型可以随便取非正输入
对数函数要求输入为正。若原始变量可能为 ,可以考虑平移,例如 ,但这个 必须有情境含义或明确说明只是数学处理,不能随意添加。
误区四:高次多项式越贴合越好
如果 个点的横坐标不同,总能找到一个次数不超过 的多项式穿过这些点。但这不代表它能解释现实。数据越少、噪声越大,越要警惕过拟合。
误区五:外推时忘记模型范围
在 到 秒内合适的模型,不一定适合 小时后。在 到 件商品内近似线性的成本,不一定适合几万件。每次预测都要说明是否在观察范围内,若超出范围,结论要降级为谨慎估计。
综合练习
下面的练习不只问“求函数”,还要求说明为什么选它。写解答时至少包含变量、函数族、参数含义和一条验证理由。
练习一:选模型
某植物实验记录第 天的高度 :
线性、二次、指数三种模型中,哪一种更值得先尝试?
相邻时间间隔相同,输出比值约为 ,比差值更稳定,所以指数模型更值得先尝试。可以设 ,由每 天约乘以 得 ,所以 。这个模型适合实验早期增长;若植物接近成熟,高度不会无限指数增长。
练习二:用约束排除
某水池放水,剩余水量 随时间 减少。已知放水速度不是恒定的,水越少流得越慢,且 不能为负。有人用线性模型预测 分钟后水量为 升。你会怎样评价?
线性模型可能在短时间内近似可用,但预测负水量说明它已经超出合理范围。由于水越少流得越慢,模型应考虑变化率减小,可能需要根式、指数衰减或由物理关系得到的模型。至少应把模型限制在水量降到 之前,并说明不能用它解释负值。
练习三:识别有理模型
一辆车行驶固定距离 千米,平均速度为 千米/小时,所需时间为 小时。写出模型并说明函数类型。
时间等于路程除以速度,所以
这是有理函数,也是反比例模型。定义域为 。当速度增大时,时间减少;当速度接近 时,时间急剧增大;当速度很大时,时间接近 ,但现实中速度还有交通和安全限制。
练习四:比较两个候选
一组数据的散点图呈上升趋势。线性模型的 RMSE 为 ,二次模型的 RMSE 为 。二次模型一定更好吗?
不一定。二次模型误差略小,但还要看残差图、参数含义、数据范围和问题目标。如果线性模型残差没有明显模式,且二次项没有情境解释,线性模型可能更简洁、更稳。若线性残差呈明显弯曲模式,而二次残差随机分布,则二次模型更有理由。
收束:选择模型的底线
选择函数模型时,可以把下面这几句话当作最后检查。
如果变化是“每次加同样多”,先看线性;如果变化率本身近似线性,先看二次;如果是“每次乘同样比例”,先看指数;如果输入按倍数变化、输出按加法变化,先看对数;如果问题由零点、转折和端行为控制,考虑多项式;如果分母、平均量、反比或渐近线很明显,考虑有理函数;如果从平方、面积、距离或体积关系反解,考虑根式函数。
然后再用定义域、单位、参数、残差和外推范围检查。一个好模型不只会计算答案,还能说明它为什么在这个情境中有意义,在哪些地方不能继续使用。