Redis 性能问题与坑
高可用与扩展之后,我们来看 Redis 在实际运行中常见的性能问题与坑:大 Key、热点 Key 与内存淘汰策略。这些问题若不在设计阶段规避,很容易在流量增长后导致延迟飙升、内存打满或服务不可用。本讲从大 Key 与热点 Key 的成因与应对说起,再谈内存淘汰策略的选型,帮助你在生产环境中少踩坑。
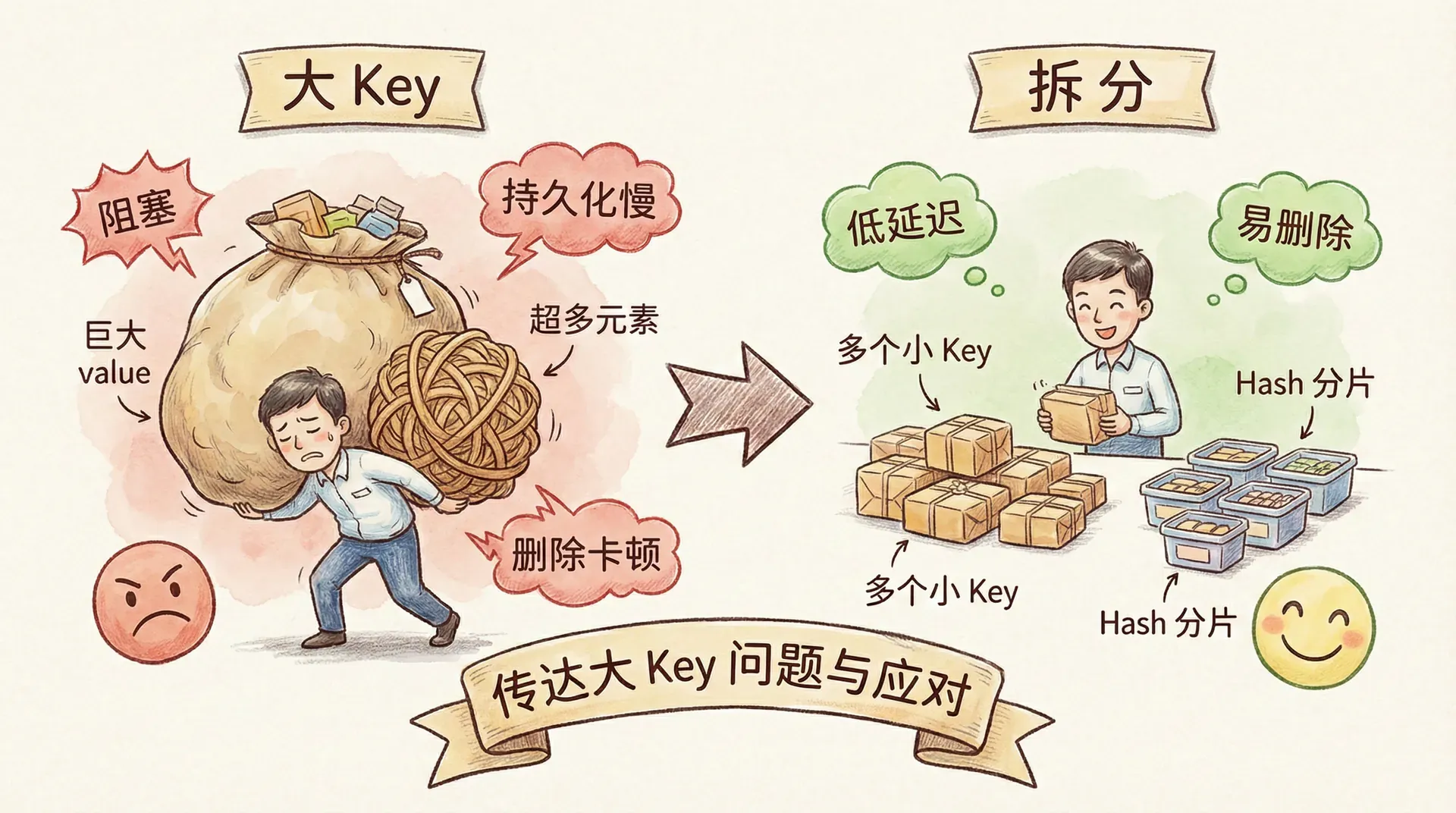
大 Key 问题
大 Key 指的是单个 Key 对应的 value 体积过大(如 String 超过 10KB,Hash/List/Set/ZSet 元素个数超过数千)。大 Key 会带来几类问题:一是单次读写耗时长,阻塞主线程,影响其他请求;二是持久化与复制时,RDB 与 AOF 重写、主从同步都会传输或处理大对象,拉长 fork、网络与恢复时间;三是删除大 Key 时,DEL 会阻塞主线程直到删除完成,可能造成长时间卡顿。
应对思路包括:在设计阶段避免产生大 Key,将大对象拆成多个小 Key(如按 ID 分片),或使用 Hash 的 field 分片、List 的按页存储;若已存在大 Key,删除时用 UNLINK(异步删除)或 SCAN + HDEL/SREM/ZREM 分批删除,避免阻塞。监控上可用 redis-cli --bigkeys 扫描大 Key,或通过慢查询、内存分析定位;第四讲中提到的「扁平化设计、控制单 Key 大小」正是为了从源头避免大 Key。
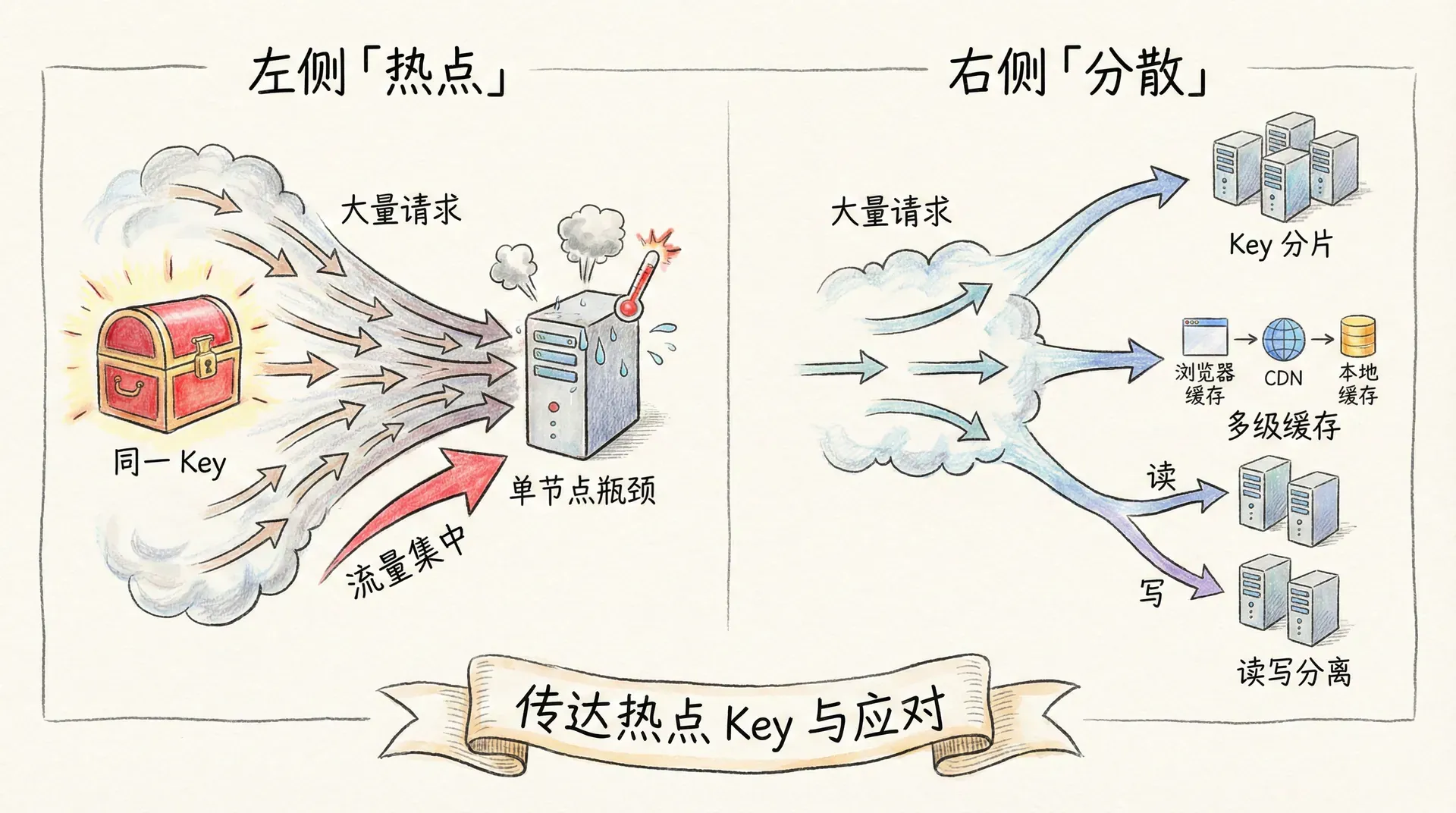
热点 Key
热点 Key 指的是少数 Key 在短时间内被极高频率访问(如单 Key QPS 过万),导致单节点 CPU 或网络成为瓶颈。常见于秒杀商品、热门帖子、明星用户等场景。热点 Key 的发现可以通过业务预估、客户端/Proxy 层统计、或 Redis 的 redis-cli --hotkeys(需开启 LFU 且 4.0+)与 MONITOR 分析。应对思路包括:多级缓存,将热点数据加载到应用本地缓存(如 Caffeine、Guava),减少对 Redis 的访问;Key 分片,将同一逻辑 Key 拆成多个物理 Key(如 hot:item:123#1、hot:item:123#2),由客户端随机或轮询选择,将流量分散到多节点;读写分离,若使用主从,将热点读请求分散到从节点。热点 Key 的本质是「流量集中」,解决思路是「分散」:分散到本地、分散到多 Key、分散到多节点。
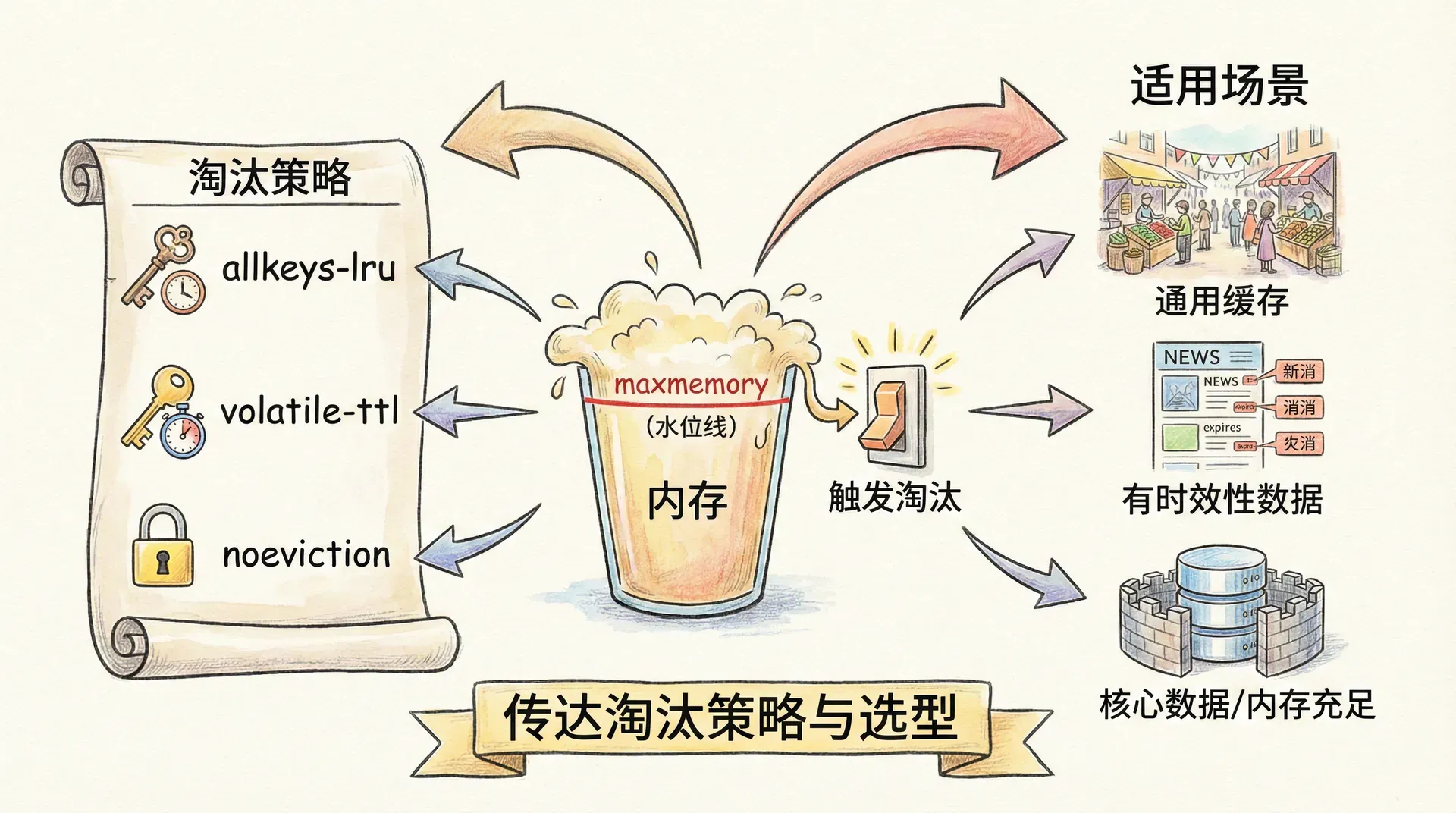
内存淘汰策略
当 Redis 内存使用达到 maxmemory 上限时,会根据配置的淘汰策略删除部分 Key,为新写入腾出空间。策略大致分为几类:allkeys-lru 从所有 Key 中淘汰最近最少使用的,适合纯缓存、热点明显的场景;allkeys-lfu 淘汰访问频率最低的,适合访问频率差异大的场景;volatile-lru、volatile-lfu、volatile-ttl 仅从设置了过期时间的 Key 中淘汰,适合「缓存 + 持久」混合场景,保证未设置 TTL 的 Key 不被误删;noeviction 为默认策略,内存满时拒绝写入并返回错误,适合「数据绝对不能丢」的场景。策略的选择需要结合业务:纯缓存、允许淘汰则用 allkeys-lru 或 allkeys-lfu;有持久化 Key 且希望只淘汰有过期时间的则用 volatile-*;若数据不可丢则用 noeviction 并配合监控与扩容。LRU/LFU 在 Redis 中为近似实现(采样比较,非严格链表),可通过 maxmemory-samples 调整采样数量,在精度与 CPU 之间权衡。在下一讲中,我们将看 Redis 在真实后端架构中的角色:Redis + MySQL、Redis + 微服务,以及 Redis 什么时候该「退场」,并收束整门课。