连接数据库
到目前为止,我们在课程里操作的数据基本都停留在内存层,比如fake_db字典、模拟用户表或者临时列表。这种方式很适合讲解FastAPI的基础概念,但一旦我们想让应用在真实世界里长久运行,就必须把数据放进可靠的持久化存储里。
对于绝大多数后端系统来说,这个存储就是关系型数据库:SQLite承担本地开发和快速试验,PostgreSQL和MySQL则承担生产环境的主要压力。
这一部分中,我们会和你一起把“FastAPI + 关系数据库”的组合走一遍完整路径。我们会从最简单的SQLite入手,在本地用一个文件来承载课程与用户数据,然后引入SQLAlchemy作为ORM层,把表结构和Python类连接起来,再通过依赖注入把数据库会话安全地传递给每一个请求。 之后,我们会把这些实践平滑迁移到PostgreSQL和MySQL上,讨论连接字符串、驱动选择、同步与异步引擎的差别,以及如何通过迁移工具管理数据库架构的演进。
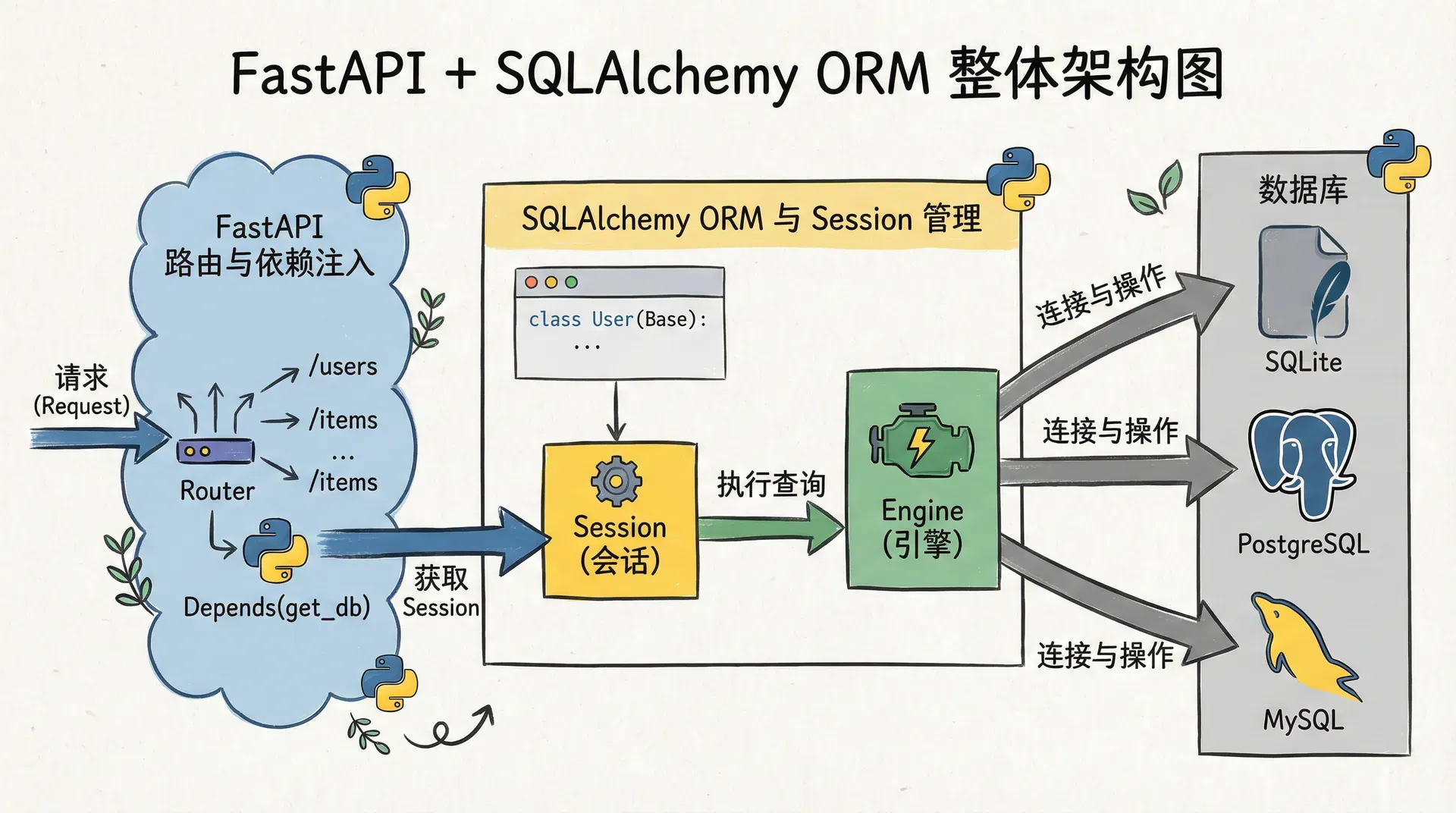
用SQLite在本地搭建第一套持久化数据层
SQLite是我们走进数据库世界的一个理想起点。它不需要单独安装数据库服务器,只需要一个文件就可以完成数据存储,非常适合本地开发、原型验证和轻量级应用。更重要的是,它和PostgreSQL、MySQL一样遵循SQL语义,我们在它上面学会的表设计、查询写法和事务思维,几乎可以原样迁移到其他数据库。
在这部分里,我们会先用SQLAlchemy的同步API来完成一套最基础的“课程表”建模与CRUD接口。即使我们后面想切换到异步引擎,这套建模和会话管理的思路依然适用。
python
from pathlib import Path
from typing import List
from fastapi import FastAPI, Depends, HTTPException, status
from pydantic import BaseModel, Field
from sqlalchemy import create_engine, Column, Integer, String, Text
from sqlalchemy.orm import declarative_base, sessionmaker, Session
app = FastAPI()
DB_PATH = Path("data")
DB_PATH.mkdir(exist_ok=True)
SQLALCHEMY_DATABASE_URL = f"sqlite:///{DB_PATH / 'courses.db'}"
engine = create_engine(
SQLALCHEMY_DATABASE_URL,
connect_args={"check_same_thread": False},
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
class Course(Base):
__tablename__ = "courses"
id = Column(Integer, primary_key=True, index=True)
title = Column(String(100), nullable=False, index=True)
description = Column(Text, nullable=False)
level = Column(String(20), nullable=False)
def init_db():
Base.metadata.create_all(bind=engine)
init_db()在这一小段代码里,我们做了几件关键的事情。首先,我们通过create_engine创建了一条指向SQLite文件的数据库连接,这个URL如果换成postgresql+psycopg2://或mysql+mysqlclient://就可以连接其他数据库了。然后,我们定义了SessionLocal这个会话工厂,用它在每个请求中创建独立的会话对象。最后,我们用了SQLAlchemy的声明式基类Base来定义Course表,把列与Python属性一一对应起来。这是工程层面非常重要的一步:只要类型和约束写清楚,后续增删改查都在这个契约之下。
会话依赖:让每个请求都在自己的事务里工作
数据库会话(Session)是我们与数据库交互的入口,它维护着对象到行的映射、事务边界以及连接池的使用。一个常见的新手错误是把Session当作全局变量在整个应用里共享,这不仅会造成并发问题,也会让事务边界模糊。FastAPI的依赖注入给了我们一个非常自然的模式:为每个请求创建一个独立的Session,用完就关闭,所有需要数据库访问的路由函数都通过依赖来获得会话对象。
python
def get_db() -> Session:
db = SessionLocal()
try:
yield db
finally:
db.close()这个get_db函数正是我们在依赖章节里讲过的典型“资源获取-释放”模式。它通过yield在依赖链中提供一个Session实例,在请求结束后自动关闭连接。现在我们可以用它来实现一组完整的课程CRUD接口。
python
class CourseCreate(BaseModel):
title: str = Field(..., min_length=2, max_length=100)
description: str = Field(..., min_length=10)
level: str = Field(..., min_length=3, max_length=20)
这组接口和我们之前写的内存版CRUD在结构上非常相似,最大的区别在于,我们现在把持久化和事务管理交给了Session,而不是随意地对字典进行修改。db.commit()负责提交事务,db.refresh(course)则确保我们拿到的是数据库最终状态(包括自增ID等)。这样一来,即使后面我们要引入更复杂的约束或触发器,这一层的逻辑也不会失效。
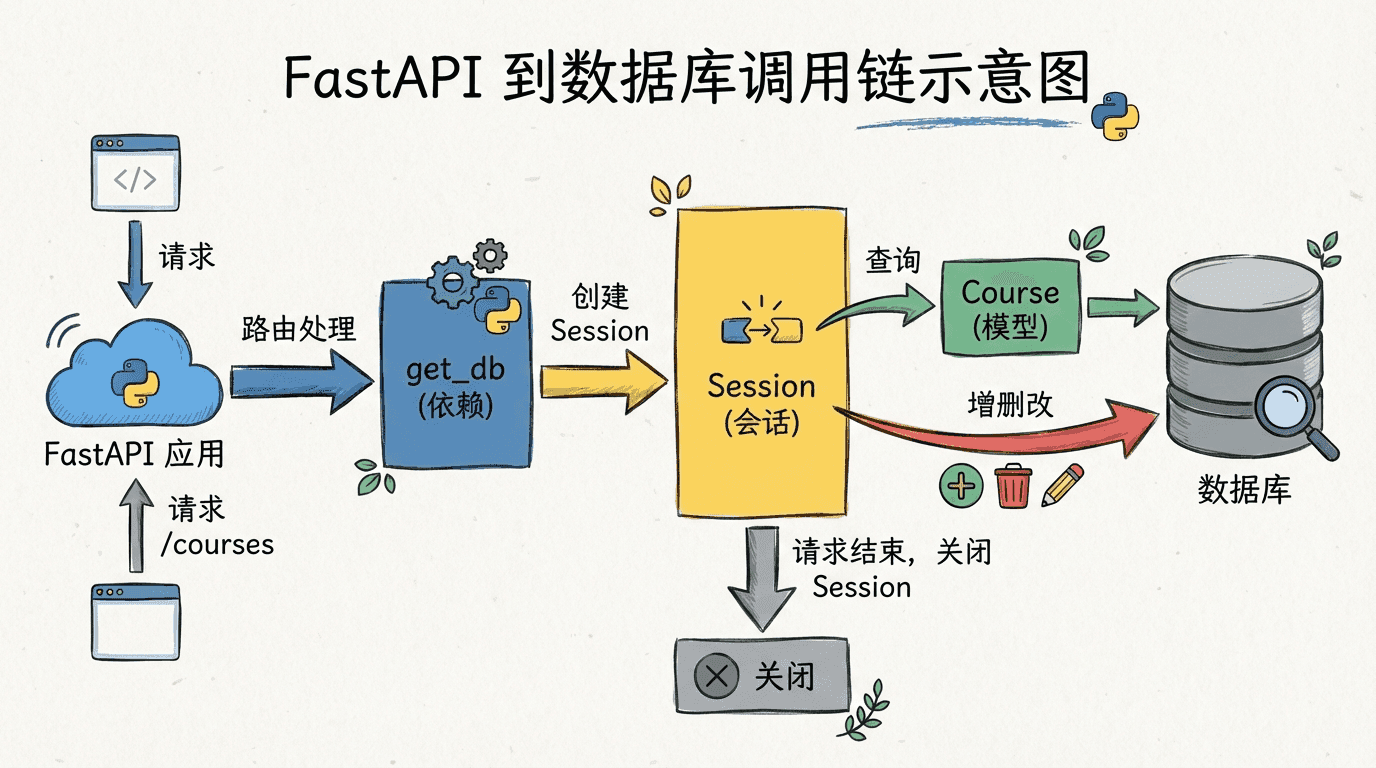
把SQLite迁移到PostgreSQL和MySQL
当我们在本地用SQLite把模型和接口打磨好之后,通常的下一步就是迁移到PostgreSQL或MySQL等更适合生产环境的数据库。迁移的核心其实非常简单:更换连接URL,安装对应驱动,必要时微调少量方言相关配置。SQLAlchemy的设计就是要让这种迁移成本尽可能低。
对于PostgreSQL,我们可以使用psycopg2或asyncpg作为驱动,在同步引擎下URL大致是这样的:
python
SQLALCHEMY_DATABASE_URL = "postgresql+psycopg2://user:password@localhost:5432/fastapi_db"
engine = create_engine(SQLALCHEMY_DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)对于MySQL,我们可以使用mysqlclient或pymysql。URL形式会稍有不同:
python
SQLALCHEMY_DATABASE_URL = "mysql+pymysql://user:password@localhost:3306/fastapi_db?charset=utf8mb4"
engine = create_engine(
SQLALCHEMY_DATABASE_URL,
pool_pre_ping=True,
)一旦我们把URL和引擎创建逻辑调整为针对PostgreSQL或MySQL,其余的模型定义和路由逻辑往往不需要修改,尤其是在我们没有使用特定方言特性的前提下。这正是“先在SQLite上把结构打磨好,再切换到生产库”的工程价值所在:模型的演进与数据库的迁移被松散耦合了。
当然,不同数据库在类型映射、索引策略和锁机制上都存在差异,随着项目增长,我们会逐渐引入PostgreSQL特有的JSONB、数组、Partial Index,以及MySQL里的特定优化。但在入门阶段,我们先把“单表CRUD + 连接池管理 + 事务边界”打稳,比一开始就追求各种高级特性要更重要。
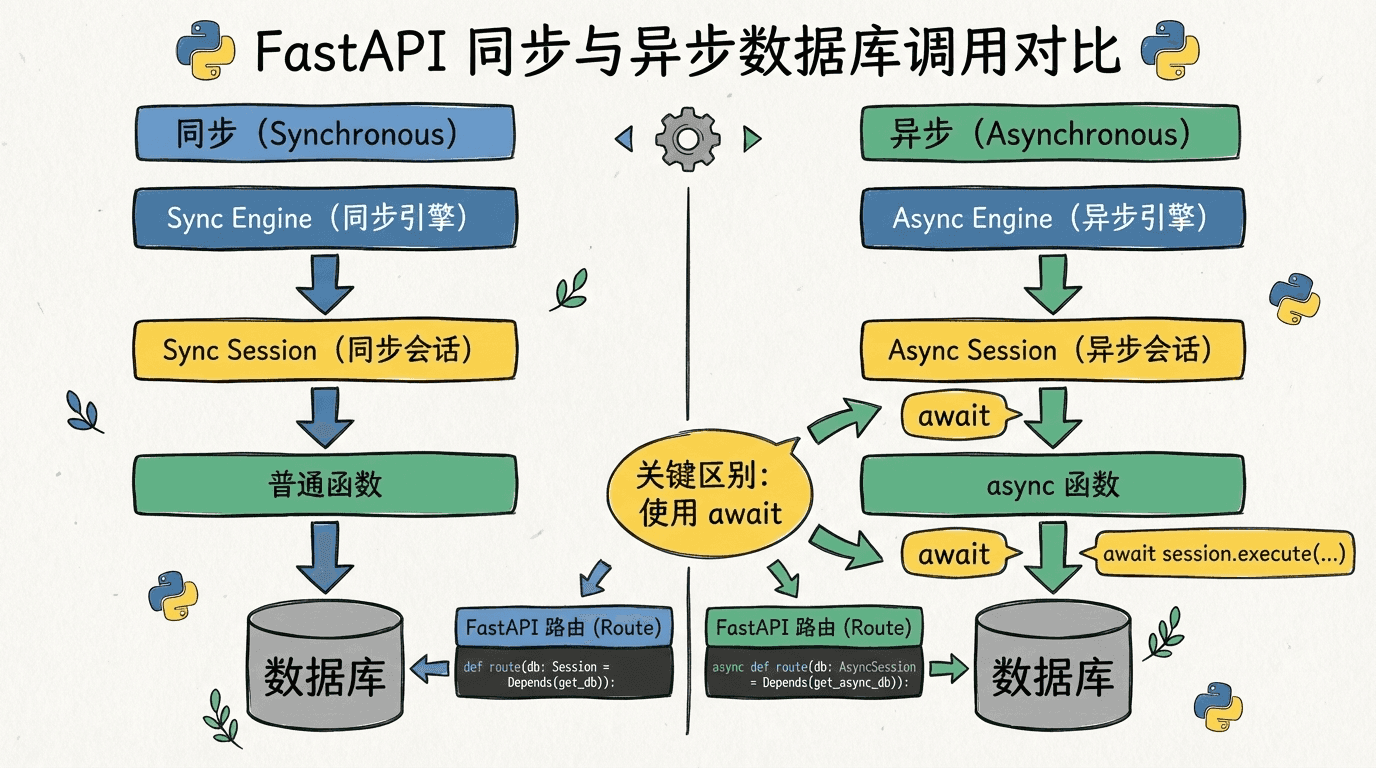
走进异步世界:SQLAlchemy 2.x 与 async engine
在FastAPI中,我们推荐在高并发I/O密集型场景下采用异步数据库访问。SQLAlchemy 1.4开始引入统一的2.0风格API和异步引擎,2.x版本则进一步把这种风格正式化。异步访问的好处在于:当我们的API需要同时面对大量请求时,等待数据库响应的时间不会阻塞整个事件循环,进而用更少的资源处理更多的并发连接。
我们先构造一个面向PostgreSQL的异步引擎示例。即使你目前只用SQLite,理解这一套模式也会为后续在生产环境里的扩展打下基础。
python
from typing import AsyncGenerator
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
ASYNC_DATABASE_URL = "postgresql+asyncpg://user:password@localhost:5432/fastapi_db"
async_engine = create_async_engine(
ASYNC_DATABASE_URL,
echo=False,
)
AsyncSessionLocal = sessionmaker(
async_engine,
expire_on_commit=False,
class_
在这个异步版本的get_async_db中,我们不再手动关闭Session,而是用async with上下文管理器。每个请求都会获得一个独立的AsyncSession,在请求结束时会话自动释放。接下来,我们把课程接口改写为异步版本。
python
from sqlalchemy import select
@app.post("/async/courses", response_model=CourseOut, status_code=status.HTTP_201_CREATED)
async def create_course_async(payload: CourseCreate, db: AsyncSession = Depends(get_async_db)):
course = Course(
title=payload.title,
description=payload.description,
level=payload.level,
)
db.add(course)
await
可以看到,逻辑与同步版本非常接近,只是所有的数据库操作都前置了await,查询通过select构造器和execute实现。这样一来,我们在路由层只需关注“这段逻辑是I/O密集的,因此路由函数使用async def”,而不需要纠结于具体驱动的阻塞行为,这就是抽象良好的库带给我们的好处。
事务边界与错误处理:不要把半成品写进数据库
当我们的业务逻辑变复杂,会遇到很多需要跨多条语句保证原子性的场景,比如创建课程的同时创建默认章节,或者为一组用户批量开通权限。这个时候,事务边界设计就变得尤其重要。SQLAlchemy的Session本身就以事务为单位工作,我们只要谨慎使用commit和rollback,就可以在FastAPI路由中清晰地表达原子操作。
在同步世界里,一个常见的模式是用try/except包裹数据库操作,出错时回滚事务并抛出HTTPException,让调用方知道这次操作没有成功。
python
from sqlalchemy.exc import SQLAlchemyError
@app.post("/courses/with-chapter", response_model=CourseOut)
def create_course_with_default_chapter(
payload: CourseCreate,
db: Session = Depends(get_db)
):
try:
course = Course(
title=payload.title,
description=payload.description,
level=payload.level,
)
db.add(course)
在异步世界中,逻辑完全类似,只是需要使用await db.rollback()和await db.commit()。关键在于,我们必须确保一旦出错,事务会被完整回滚,而不是留下一半成功、一半失败的状态。这对后续排查问题和保持数据一致性非常重要。
当我们的应用引入了依赖注入中的数据库会话时,我们可以进一步把“事务包装器”做成一个装饰器或依赖,使得路由函数内部只关注业务对象的创建和修改,而不必每次都手写try/except。在课程的这个阶段,我们先把事务思维植入脑海:任何跨多步写操作的流程,都应该明确划定“要么全部成功,要么全部失败”的边界。
把数据库接入认证、授权与文件上传
随着课程推进,我们已经有了认证授权模块、Pydantic模型体系和文件上传流水线。现在让数据库加入这张网是顺理成章的事情。我们不再用fake_users_db来存储用户,而是用users表;不再把课程放在内存里,而是通过ORM模型与数据库交互;文件上传之后的元数据(例如路径、大小、类型、所属课程或用户)也应该记录在数据库里,以便后续列表展示和权限控制。
在代码层面,这意味着我们的认证依赖get_current_user将从数据库Session中查询用户,而不是从字典查;课程路由中的过滤与分页逻辑会通过SQL表达;文件上传成功后会插入一条记录,记录文件的所有关键属性。更重要的是,这些操作都通过同一个get_db或get_async_db依赖获得会话,从而保证在测试与重构时有统一的入口可以替换。
我们可以设想这样一个请求路径:用户带着JWT访问POST /courses,认证依赖从数据库恢复用户身份,授权依赖判断当前用户是否是讲师或管理员,路由通过Session创建课程记录,文件上传端点通过同一个Session为课程添加封面记录。这整条链路中,每一个对数据库的读写都站在已经建立好的会话与事务边界之上,而不是各自为战。
小结
本部分中,我们把FastAPI从简单的“内存实验室”真正接入了数据库,学会了用SQLAlchemy模型定义表结构,依赖注入获取Session,实现课程的增删改查(CRUD)。切换SQLite、Postgres、MySQL,也只要一行配置,实验和上线很顺滑。
我们还实践了事务和错误处理,明白了“要么全成,要么全撤”的重要性。异步数据库访问、认证和文件上传也一起串联起来,让数据存储完整融入整个应用流程。 接下来,不管是写自动化测试,还是数据库优化、多表设计,这套数据库接入方式都会一直陪你用下去。数据库已经成了整个项目的中枢,不再是单独的技术点,而是支撑所有功能的基础。