文件上传
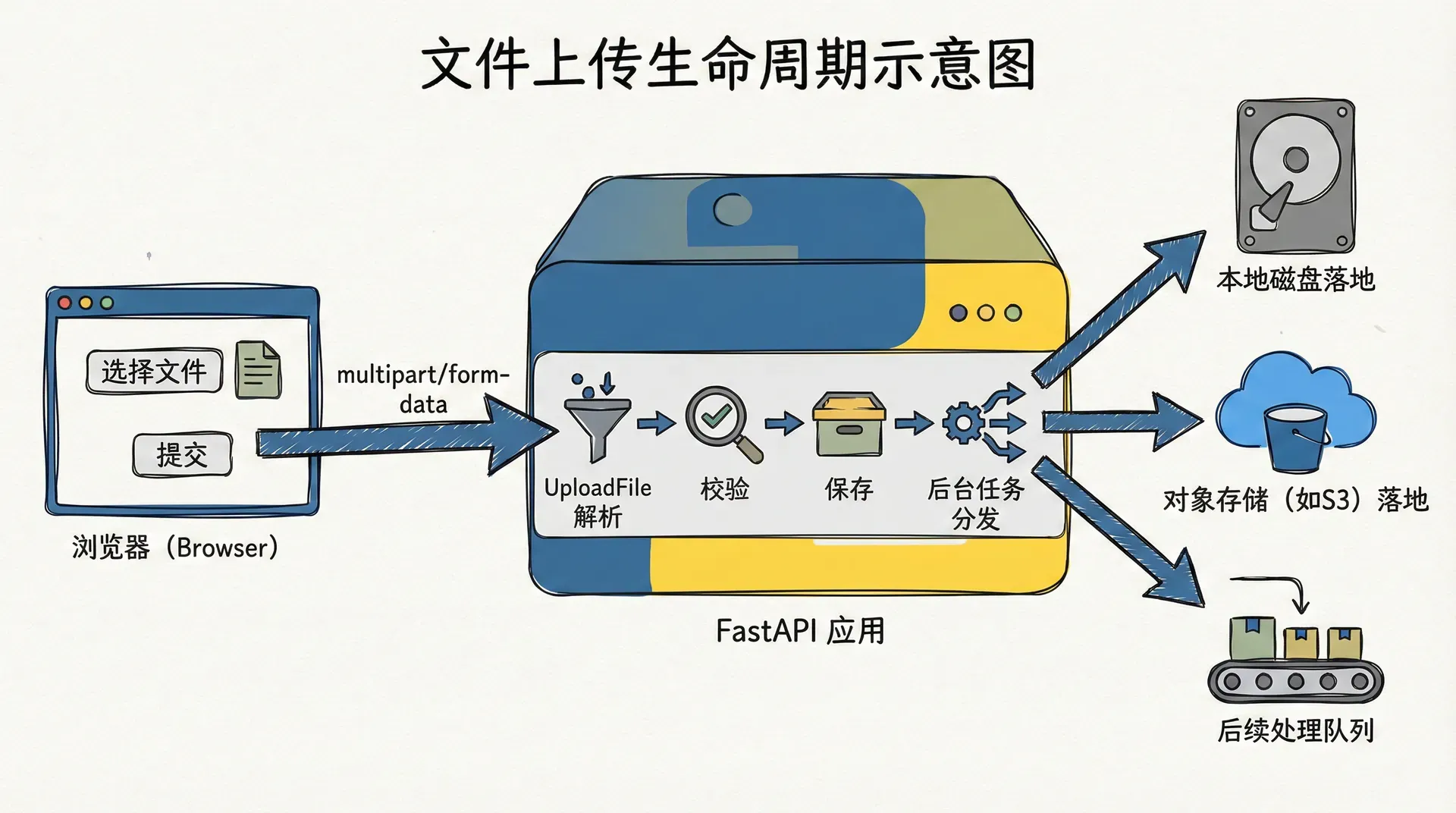
当我们把FastAPI应用从“只处理JSON”的世界带到真实业务环境时,文件上传几乎总会出现在需求列表里。课程封面图片、用户头像、作业附件、导入用的Excel、日志压缩包、甚至音视频内容,这些东西都不可能用纯JSON表达。文件上传看似只是“多了一种请求体格式”,但在工程实践里,它牵扯到安全边界、磁盘与云存储的读写策略、并发请求的内存占用控制、后台处理流程,以及审核与清理机制。
我们这节课的目标,就是和你一起把FastAPI里的文件上传从“能勉强用”打磨到“在生产环境里可以放心托付”的程度。
从最简单的单文件上传开始
为了把注意力集中在FastAPI的行为上,我们先不引入任何复杂逻辑,只写一个最简单的“接收一个文件并告诉调用方它的基本信息”的端点。即便是这样的端点,我们也会顺手用上前面章节里已经习惯的写法,比如用UploadFile而不是裸bytes,用类型提示表达接口契约。
python
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/upload/avatar")
async def upload_avatar(file: UploadFile = File(...)):
return {
"filename": file.filename,
"content_type": file.content_type,
}在这个例子里,我们通过File(...)声明了一个必填字段file,FastAPI会要求请求体是multipart/form-data格式,并且在其中找到名为file的字段。UploadFile给了我们三个非常重要的能力:访问filename和content_type这样的元数据,通过类文件接口读取内容,以及在内部以临时文件的方式存储大文件,从而避免一次性把全部字节读进内存。我们会在本章的后面几个小节里充分利用这些能力。
如果你在浏览器里打开Swagger UI,选择这个端点,会发现界面自动变成了文件选择框。这其实就是OpenAPI规范和FastAPI类型系统配合的成果,我们通过UploadFile = File(...)这一个声明,就同时获得了请求验证、运行时解析和交互式文档。
多文件上传与表单字段的混合
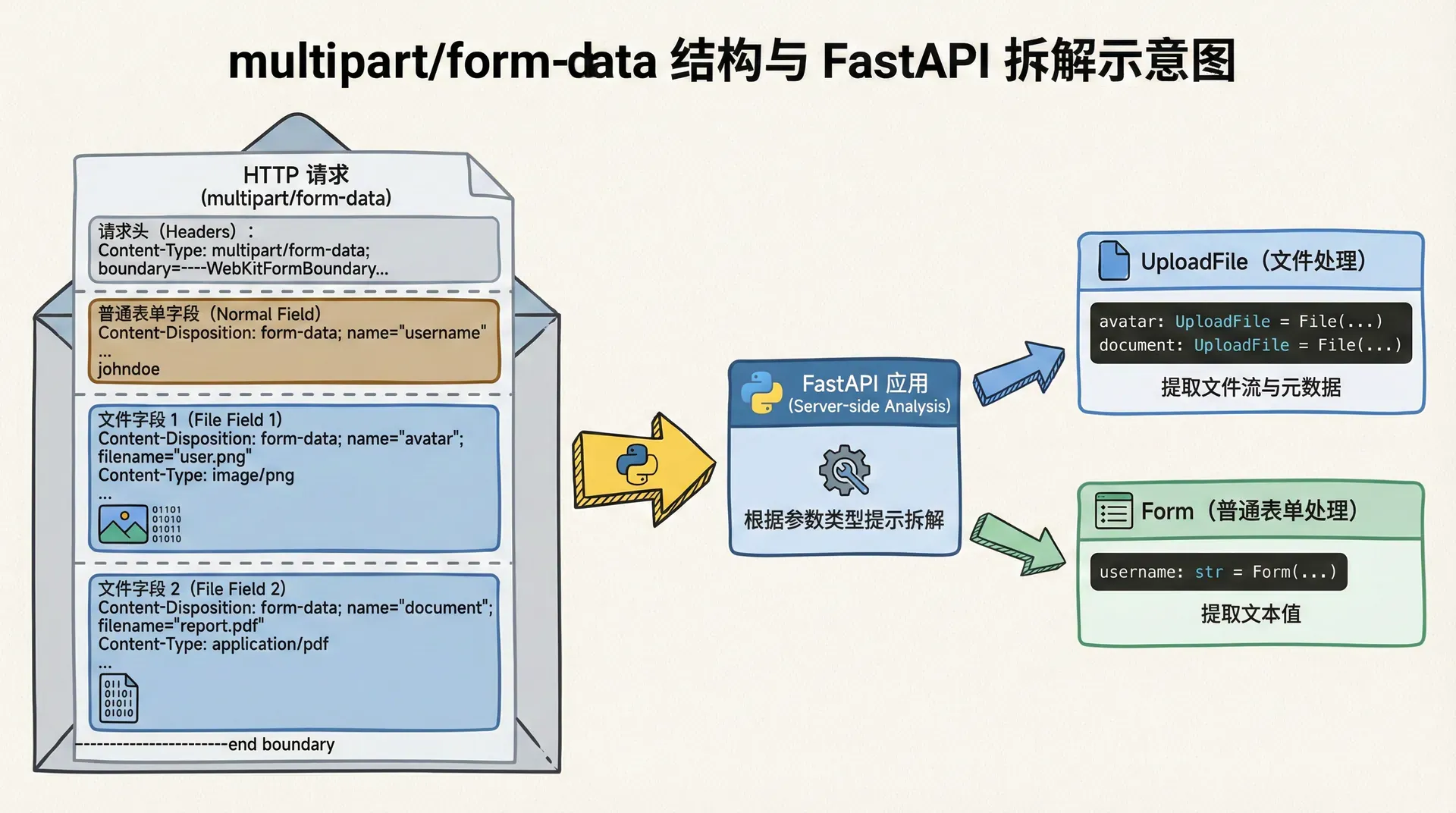
在很多业务场景里,我们并不是只上传一个文件。比如课程资源模块里,一个章节可能需要上传多张插图和若干个附件;又或者,我们需要让用户一次性上传多个作业文件。FastAPI通过列表类型的UploadFile轻松支持这种场景,我们只需要在类型提示里表达“这是一个由文件组成的列表”,框架就会自动把同名字段聚合起来。
python
from typing import List
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/upload/resources")
async def upload_resources(files: List[UploadFile] = File(...)):
return [
{
"filename": f.filename,
"content_type": f.content_type,
}
for f in files
]除了多个文件,我们经常还需要让调用方同时提交一些元数据,比如课程ID、资源类型、标签等。FastAPI本身就基于表单字段来携带文件,因此在同一个端点里混合文件与普通表单字段是非常自然的,只要我们在参数中同时使用Form和File即可。
python
from fastapi import Form
@app.post("/upload/lesson-assets")
async def upload_lesson_assets(
lesson_id: int = Form(...),
description: str = Form(""),
files: List[UploadFile] = File(...)
):
return {
"lesson_id": lesson_id,
"description": description,
"files": [
这样一来,我们就能够在一次请求里完成“资源上传”和“元数据绑定”,前端可以根据课程或章节信息来组织文件,而后端可以在接收时做统一的验证和存储。
文件大小与类型校验:安全性不是附件
允许用户上传任意文件并把它们随意存到服务器上,几乎等于打开了攻击大门。我们至少需要控制三个方面:大小、扩展名和内容类型。大小控制是为了防止恶意耗尽磁盘与内存资源;扩展名与内容类型校验则是为了避免脚本执行、XSS或意外的敏感内容泄漏。
在FastAPI里,我们可以先用配置的方式约定一个“软限制”,比如单个文件不超过5MB,然后在端点内部读取内容前检查长度。如果文件过大,我们立即返回错误,不做进一步处理。
python
from pathlib import Path
from fastapi import FastAPI, File, UploadFile, HTTPException
app = FastAPI()
MAX_FILE_SIZE = 5 * 1024 * 1024 # 5MB
@app.post("/upload/image")
async def upload_image(file: UploadFile = File(...)):
contents = await file.read()
if len(contents)
在这个例子里,我们先读取全部内容检查大小,然后通过seek(0)把文件指针重置回起点,以便后续逻辑仍然可以正常读取。同一时间,我们还希望限制文件扩展名和声明的内容类型,比如图片上传应该只接受.jpg、.jpeg、.png,并且content_type里应该包含image/前缀。
python
ALLOWED_EXTENSIONS = {".jpg", ".jpeg", ".png"}
ALLOWED_MIME_PREFIXES = {"image/"}
def validate_file_type(upload_file: UploadFile) -> None:
suffix = Path(upload_file.filename).suffix.lower()
if suffix not in ALLOWED_EXTENSIONS:
raise HTTPException(status_code=400, detail="不支持的文件扩展名")
if
我们在上传端点里调用这个校验函数,把“文件类型规则”集中到一个地方维护。这样当产品提需求说“视频也要支持”“SVG要不要允许”时,我们不会到处翻条件语句,而是只改一处规则。
保存策略:命名、目录与避免冲突
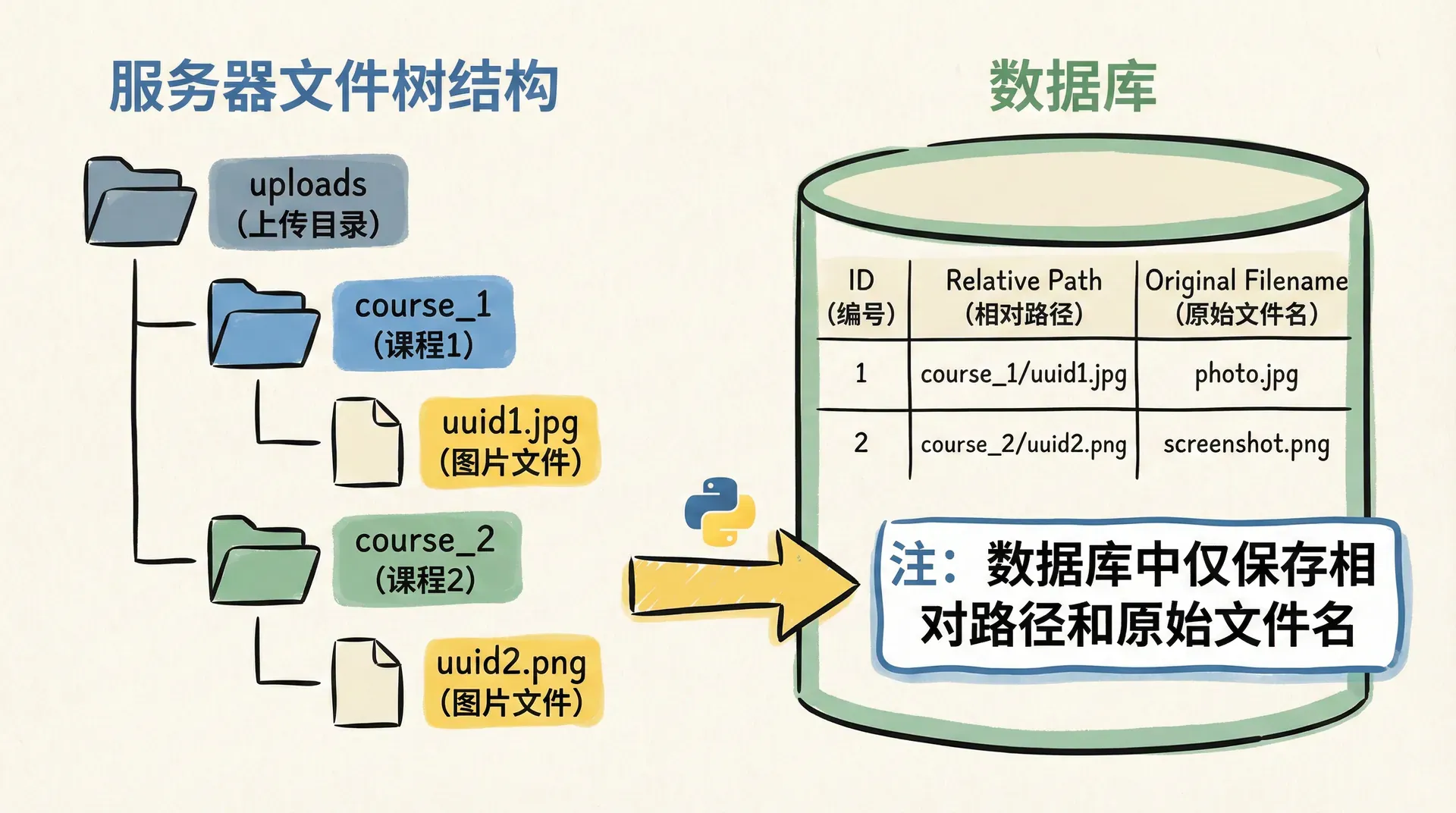
在多数入门示例中,我们把上传文件随便丢到一个固定目录里,文件名直接使用客户端上传的名字。这在真实项目中会很快失控。用户可能上传重名文件、恶意构造包含路径分隔符的文件名,甚至利用我们没有正确处理的字符集在不同操作系统间制造不一致。我们需要为上传文件设计一个稳定、可推导的命名与目录结构。
常见的做法是用内部生成的唯一ID作为文件名,比如UUID或数据库自增ID,把原始文件名和扩展名单独记录在数据库里;同时根据业务维度划分目录,比如按用户、课程或日期分层。下面的例子用UUID和课程ID构建了一个简单但实用的目录结构。
python
import uuid
import shutil
from pathlib import Path
from fastapi import FastAPI, UploadFile, File
app = FastAPI()
UPLOAD_ROOT = Path("uploads")
UPLOAD_ROOT.mkdir(exist_ok=True)
async def save_file_for_course(course_id: int, file: UploadFile) -> str:
course_dir = UPLOAD_ROOT /
通过这种方式,我们在磁盘上获得了一个“课程到文件”的稳定映射,而在数据库或配置中记录的只是文件的内部路径。以后如果需要把某一批课程的封面迁移到对象存储,我们也可以直接按这个结构遍历,而不必从业务逻辑里反推文件路径。
大文件与流式读取:不要一次性把世界读进内存
前面的大小校验示例为了讲解方便使用了await file.read()一次性读入全部内容,但在处理真正的大文件(比如几百MB的视频、日志归档)时,这种做法会把内存压得很紧。更合适的方式是使用流式读取,把文件内容一块一块地处理或者保存。
UploadFile.file本身就是一个类文件对象,我们可以用标准库的shutil.copyfileobj或逐块读取的方式,把内容直接写入目标文件,而不经过大块中间buffer。
python
async def save_large_file(destination: Path, upload_file: UploadFile) -> None:
with destination.open("wb") as out_file:
while True:
chunk = await upload_file.read(1024 * 1024)
if not chunk:
break
out_file.write(chunk)
await upload_file.seek(0)在这种模式下,我们可以在循环里随时检查已经写入的总字节数,超出软限制就立即停止并删除已写入的部分,避免攻击者通过非常大的文件逐步填满磁盘。我们也可以在写入过程中计算哈希值,用于后续的完整性校验或去重。
与流式读取类似的一个实践是把CPU密集型或耗时的文件处理(比如转码、压缩、OCR)交给后台任务。FastAPI通过BackgroundTasks帮助我们轻松做到这一点,我们在请求里只负责保存文件并快速返回,真正的重负荷工作放在后台。
python
from fastapi import BackgroundTasks
def process_file_async(path: str) -> None:
# 这里可以是视频转码、生成缩略图、文本提取等
...
@app.post("/upload/video")
async def upload_video(
background_tasks: BackgroundTasks,
file: UploadFile = File(...)
):
validate_file_type(file)
dest = UPLOAD_ROOT / f"video_
这种模式让我们在请求生命周期内只承担必要的I/O工作,把机器学习推理、转码与复杂分析这种长任务延后执行。配合监控与任务队列,我们就可以把文件上传和处理变成一个稳定、可回溯的流水线。
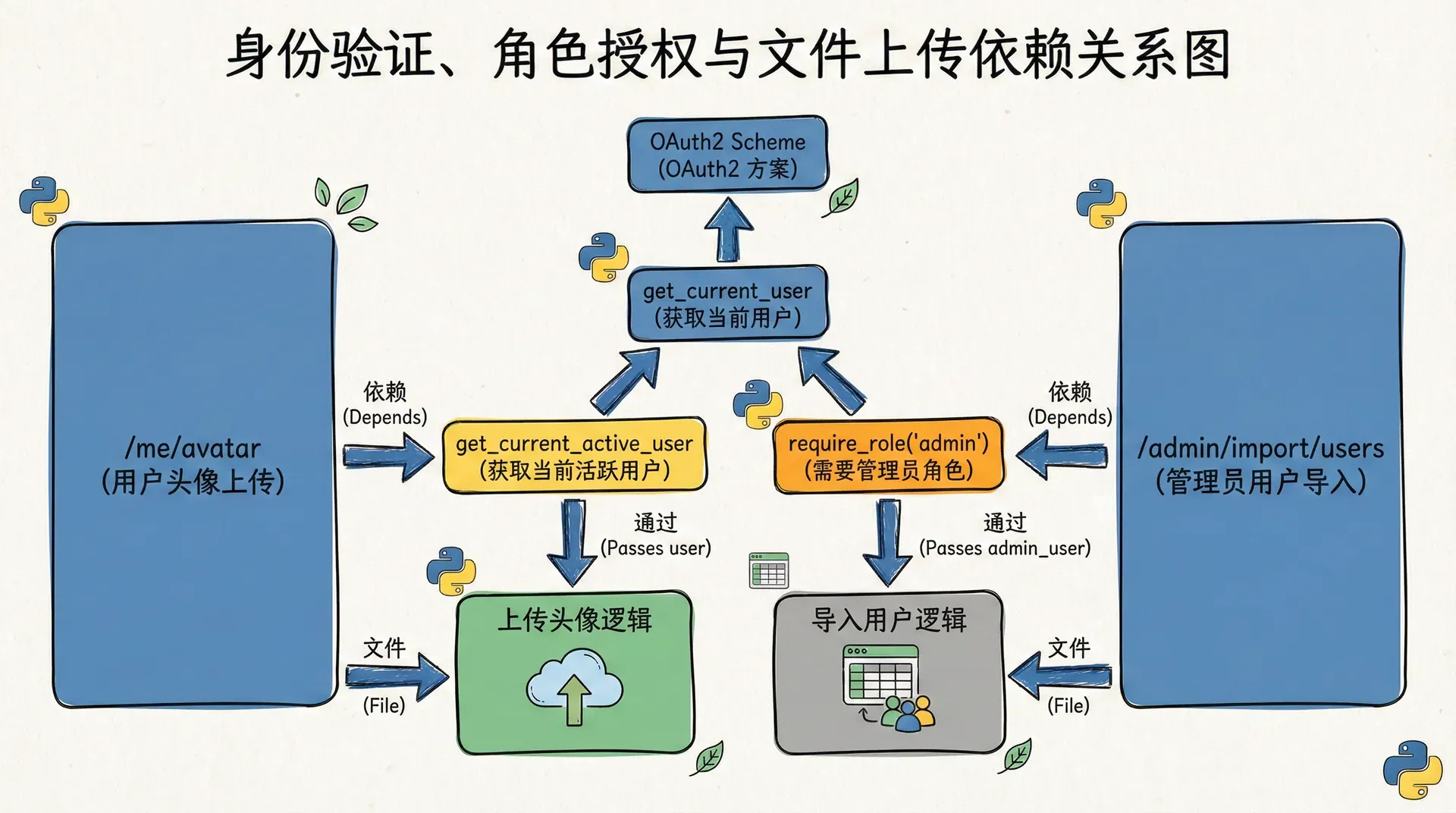
与认证与授权结合:不是所有人都能传所有文件
在前一章里,我们已经把身份验证与角色授权都做成了依赖。现在要做的事情其实非常自然:让上传端点也依赖这些安全组件。对于大部分用户上传接口,我们至少需要要求“已经登录”;对于敏感资源的上传,比如课程资料或后台批量导入,只允许管理员或课程讲师访问。
python
from fastapi import Depends
@app.post("/me/avatar")
async def upload_my_avatar(
file: UploadFile = File(...),
current_user: User = Depends(get_current_active_user),
):
validate_file_type(file)
user_dir = UPLOAD_ROOT / f"user_{current_user.username}"
user_dir.mkdir(exist_ok=True
通过这种方式,我们不再把“上传谁的文件”和“谁有权上传什么”写在混乱的条件语句里,而是遵循同一套依赖注入模式,让上传逻辑自然而然地站在标准的认证与授权基础上。这不仅提升了安全性,也让代码在讲解和代码审查时更容易一眼看出“安全边界画在什么地方”。
与对象存储和CDN的集成:从本地磁盘迈向云端
本地磁盘是开始实验的好地方,但一旦文件数量和访问量增长,我们通常会把文件迁移到对象存储系统,比如S3、MinIO、阿里云OSS或本地私有云实现。这里FastAPI本身并不限制我们使用哪一种方案,它关心的是在接收请求这一端用UploadFile高效安全地获得字节流,在发送响应这一端为调用方返回可访问的URL或标识符。
在对象存储集成场景下,一个常见的模式是:FastAPI端点在接收上传后,不再把文件写入本地磁盘,而是直接把流上传到对象存储桶,然后记录存储键和值。为了保持这一章的重点,我们不会引入具体云厂商的SDK代码,而是抽象出一个“存储服务”依赖,让文件上传端点只依赖这个服务的接口。
python
from typing import Protocol
class StorageService(Protocol):
async def save(self, key: str, file: UploadFile) -> str:
...
class LocalStorageService:
def __init__(self, root: Path):
self.root = root
async def save(self, key: str, file: UploadFile) -> str:
dest
未来如果我们要把存储从本地磁盘切换到S3,只需要实现一个S3StorageService并在依赖中返回它,而上传端点本身可以保持不变。这就是我们在整门课程里一直强调的工程思维:把易变的细节封装在可替换的实现里,把不变的业务意图写在依赖与模型上。
小结
这一部分中,我们带你把FastAPI的文件上传从“能跑通Demo”做到了“几乎可以上生产”。我们先动手体验了UploadFile的基础用法,也了解了表单和文件是如何被解析的。然后,我们加入了安全和资源限制——比如文件大小、类型校验、命名方式等——让上传行为更可控、安全。
紧接着,我们用流式读取和后台任务应对大文件上传,不让内存压力把服务拖垮。安全这块也没落下:上传动作已经与认证授权深度集成,谁能上传、能传什么,都有清晰的依赖把控。最后,存储也不再只是本地磁盘,通过抽象出存储服务接口,为将来上云(对象存储、CDN等)埋好了钩子。
等后面我们开始接数据库、做更完整的实战项目,这套文件上传模式还能直接复用。上传头像、导入导出数据、课件管理,都会受益于这里定下的好习惯:模型清晰、依赖可替换、资源易控边界明确。