Node.js 的运行模型
在前面的学习中,我们建立了「Node.js 是什么、为什么能做后端」的整体图景,并反复提到了「单线程」「非阻塞 I/O」和「事件驱动」这三个词。本讲我们要把这三个词落到实处,看看它们在我们写的每一行代码背后究竟意味着什么。本讲围绕「单线程模型的真实含义」「非阻塞 I/O」以及「事件驱动架构的本质」展开,为第三讲「事件循环全解析」打好基础。很多人会问:单线程的话,一个请求卡住了是不是整个服务就卡住了?若「卡住」指的是主线程在执行耗时同步代码或死循环,事件循环确实无法执行别的回调;若指的是某次 I/O 很慢,主线程并不会在那次 I/O 上等待,而是去执行别的请求的回调,所以单次 I/O 慢不会拖垮整个服务。
单线程模型的真实含义
主线程与业务逻辑
当我们说 Node.js 是「单线程」时,更准确的说法是:执行我们写的 JavaScript 代码的,始终只有一个线程,即「主线程」。在这条线程上,同一时刻只会执行一段 JavaScript;没有多线程并发执行多段 JS 的问题,因此我们不需要在业务代码里写锁。但 Node 进程里除了这条「跑 JS 的线程」之外,还有 libuv 的线程池(负责部分文件 I/O 等没有原生异步接口的操作)和操作系统在处理网络 I/O 时用到的内核机制(如 epoll),这些都不会占用主线程。所以「单线程」指的是「跑我们业务逻辑的只有一条线程」,而不是「整个进程只有一条线程」。
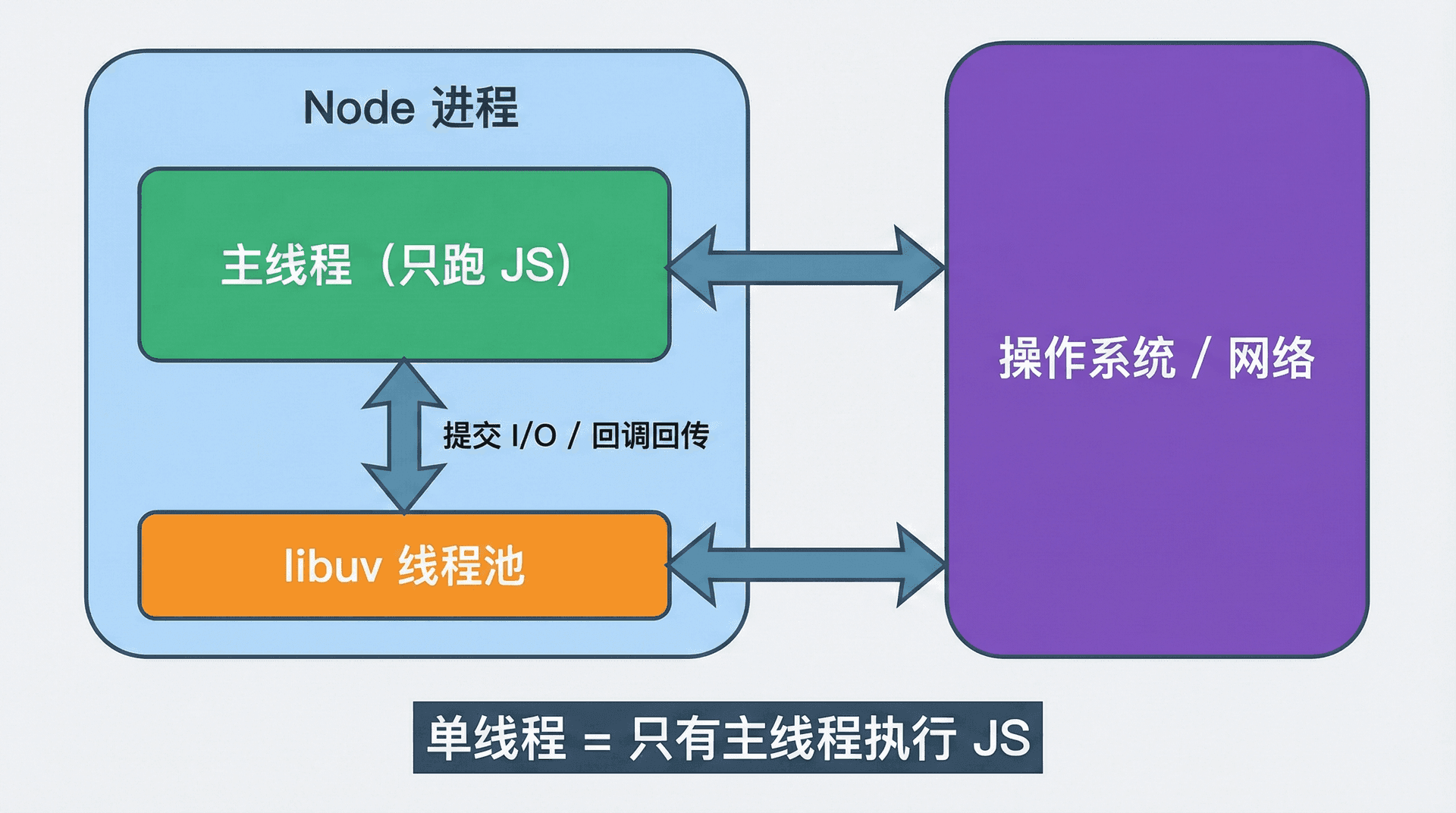
因为我们知道「同一时刻只有一段 JS 在执行」,所以我们不会在业务代码里写锁;反过来,若某段 JS 里写了死循环或非常耗时的同步计算,主线程会一直被占用,事件循环无法执行别的回调,其他请求就会卡住。单线程还意味着:我们写的所有回调、Promise 的 then、async 里 await 之后的代码,最终都会在这同一条主线程上「一个接一个」执行;事件循环的职责就是在「该执行哪一段」之间做调度。所以「Node 用单线程支撑高并发」指的是「用一条线程在大量 I/O 之间切换」:主线程发起 I/O 后就去执行别的逻辑,等 I/O 完成后再回来执行对应的回调。
主线程与共享状态
同一时刻只有一段 JavaScript 在执行,所以模块里的变量、全局对象在同一时刻只会被这一段 JS 读写,不会出现竞态。这种模型让我们不需要加锁,但也要求我们注意:不要在回调之间依赖不可靠的共享可变状态,应尽量把「请求相关的状态」放在闭包或请求上下文中,而不是依赖全局变量。
主线程之外还有什么
在 Node 进程里,主线程之外还有 libuv 的线程池。默认情况下 libuv 会维护一个大小有限的工作线程池(通常约 4 个,与 CPU 核数有关),用于执行那些「没有原生异步接口」的操作(如部分文件系统的读写)。当我们调用 fs.readFile 时,Node 会把读请求提交给 libuv,libuv 再决定走操作系统的异步接口还是丢给线程池;等读完成后,libuv 会把我们传入的回调放进事件循环的队列,等待主线程在下一轮执行。线程池的大小是有限的,所以「Node 用单线程支撑高并发」主要指的是网络 I/O 和主线程不阻塞;文件 I/O 等依赖线程池的操作,并发度会受到线程池大小的限制。在大多数 Web 场景下,瓶颈在数据库或外部 API,单线程 + 事件循环的模型仍然能很好地发挥作用。
单线程模型的真实含义是:执行我们写的 JavaScript 的,始终只有一条主线程;同一时刻只会执行一段 JS,因此我们不需要在业务代码里写锁。但 Node 进程里还有 libuv 的线程池和操作系统内核在参与 I/O,所以「单线程」不等于「整个进程只有一个线程」。
为什么单线程还能高并发
高并发的关键不在于「同时执行很多段业务逻辑」,而在于「在等待 I/O 的时候不闲着」。在 Node 的单线程模型里,主线程不会「等」I/O:它发起 I/O 请求后,把「I/O 完成后要执行的回调」登记下来,然后继续去执行别的代码;等操作系统或 libuv 通知「某个 I/O 完成了」,事件循环再把对应的回调交给主线程执行。主线程只负责「发起 I/O」和「在 I/O 完成后执行回调」,从而在单位时间内可以处理非常多的请求。I/O 密集的场景(Web API、BFF、实时推送)适合 Node;CPU 密集的场景下主线程会长时间占用,单线程就会成为瓶颈,后续会讲到如何用子进程或 Worker Threads 把 CPU 密集任务挪出主线程。
非阻塞 I/O
阻塞与非阻塞的定义
在一次 I/O 操作中,若调用的接口「会等到 I/O 完成才返回」,这次调用就是阻塞的:在 I/O 完成之前,当前线程什么都干不了。若调用的是「提交 I/O 请求就立即返回,等 I/O 完成后再通过回调或事件通知我们」的接口,就是非阻塞的。Node.js 的设计目标,就是让所有「会等」的 I/O 都变成非阻塞的:我们在 JS 里发起的读文件、写文件、网络请求、DNS 查询等,通常都会立即返回,把「等」和「结果怎么交回」交给 libuv 和事件循环。libuv 利用操作系统提供的非阻塞接口(如 epoll、kqueue、IOCP),把「等待 I/O」从主线程挪到内核或线程池。非阻塞 I/O 的核心是「提交请求就返回,结果通过回调或事件交回」。
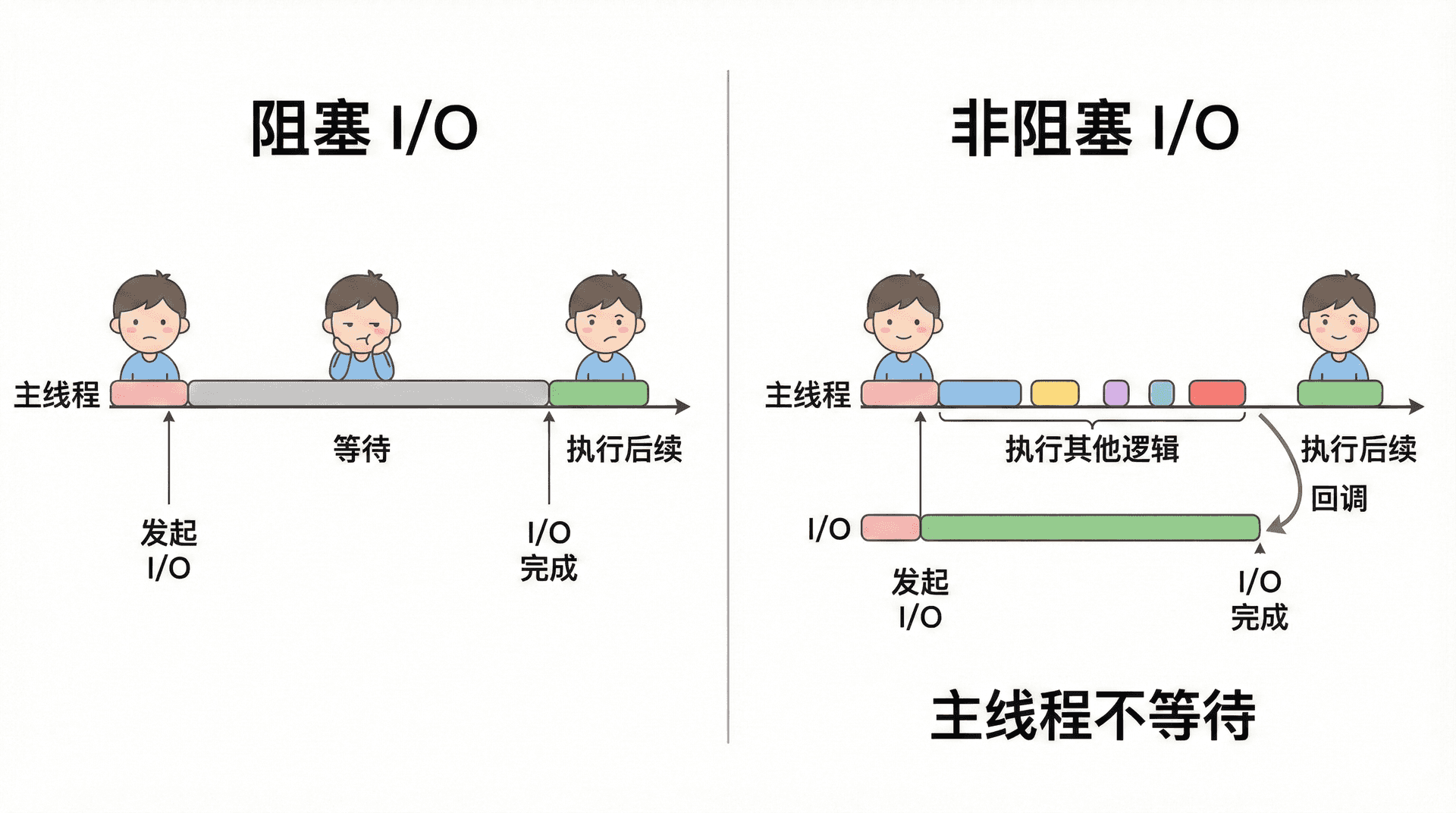
在 Node 里绝大多数 I/O API 都是非阻塞的,例如 fs.readFile(path, callback)、http.request(options, callback) 都会立即返回,结果通过 callback 传回。Node 也提供了同步版本如 fs.readFileSync,会阻塞主线程直到操作完成,一般只适合启动时加载配置等少数场景,在请求处理路径上应避免使用。对于调用方来说,非阻塞调用意味着「调用立即返回,结果稍后通过回调或 Promise 拿到」;这种风格和事件驱动、单线程模型是高度契合的。
同步 API 与阻塞
Node 为部分模块提供了同步方法,例如 fs.readFileSync、fs.existsSync,会阻塞主线程直到操作完成。在服务器端我们应尽量避免在请求处理路径上使用它们;同步 API 适合进程启动时加载配置文件、脚本型工具里一次性读写等。排查「服务突然变慢」或「请求超时」时,可用 Node 的 --trace-sync-io 选项观察是否有同步 I/O 在请求路径上执行。
用代码感受非阻塞 I/O
下面这段代码演示异步读文件:主线程在调用 fs.readFile 后立即执行后面的 console.log,不会等文件读完;文件读完后,回调会在事件循环的某一轮被调用。运行后会先看到「readFile 已调用,主线程继续执行」,然后才看到「文件内容长度: xxx」,说明主线程没有在 readFile 处阻塞。
javascript
const fs = require('fs');
fs.readFile('package.json', 'utf8', (err, data) => {
if (err) throw err;
console.log('文件内容长度:', data.length);
});
console.log('readFile 已调用,主线程继续执行');I/O 完成之后如何回到 JS
当我们发起一次非阻塞 I/O 后,结果通过回调或 Promise 交回。这条「I/O 完成 → 回调被调度到主线程执行」的路径由 libuv 和事件循环完成:libuv 在 I/O 完成时会把我们登记的回调封装成任务放进事件循环的某个队列,事件循环在每一轮把到期的任务取出来交给主线程执行。所以回调里的代码并不是「I/O 完成的那一刻」就执行,而是「事件循环在某一轮取到这个任务时」才执行;这中间可能已经执行了其他请求的回调或定时器。「这段回调和那段回调谁先执行」取决于事件循环的调度顺序,第三讲会详细展开。
事件驱动架构的本质
什么是事件驱动
「事件驱动」指的是:程序的执行流程不是事先写死的一步步顺序执行,而是由「事件」的发生来驱动——当某个事件发生(例如 I/O 完成、定时器到期、收到网络数据),我们就执行与之关联的回调。在 Node.js 里,事件循环就是负责「等待事件发生」和「把对应回调交给主线程执行」的调度器。主线程不断从事件循环里取任务执行,取到的任务可能来自某次 I/O 完成的回调、某个定时器的回调等;执行完一个任务后再取下一个,如此循环。在事件驱动模型里,我们写的是「当 X 发生时做 A,当 Y 发生时做 B」;我们只负责登记「当某事件发生时要执行什么」,事件循环负责在事件发生时把对应的逻辑调度到主线程执行。主线程从不「等」,只负责「在事件发生时执行对应的逻辑」,从而在大量 I/O 之间高效切换;「Node 是事件驱动的」指的是整个运行模型围绕事件循环 + 非阻塞 I/O + 单线程执行构建,三者缺一不可。
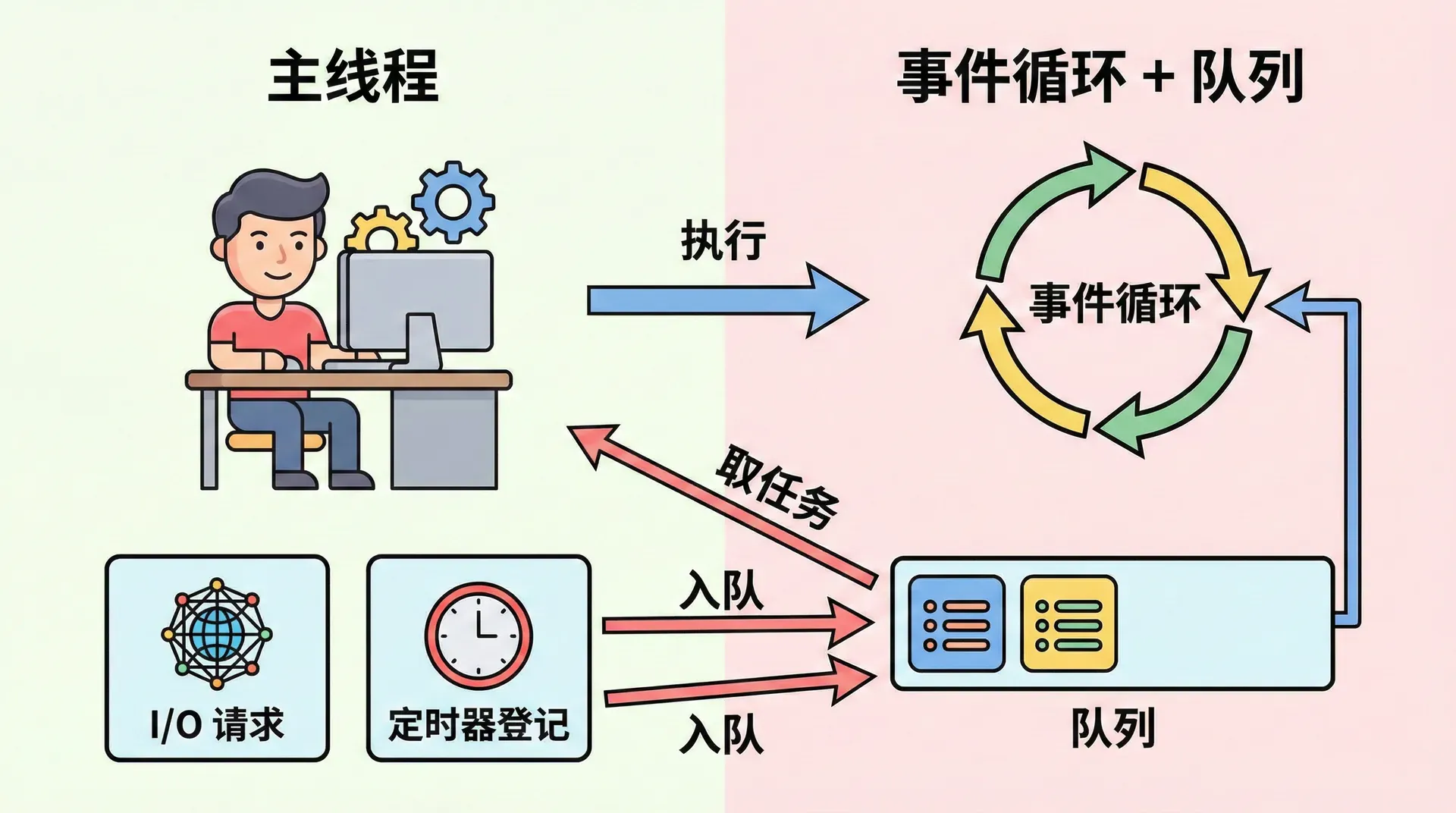
单线程、非阻塞 I/O 与事件驱动三位一体
三者缺一不可:单线程意味着同一时刻只执行一段 JS;非阻塞 I/O 意味着主线程不会在 I/O 上卡住;事件驱动意味着「该执行哪段 JS」由事件循环根据「哪些 I/O 完成了、哪些定时器到期了」来调度。没有非阻塞 I/O,主线程就会在 I/O 上阻塞,事件循环也就没法在等待期间执行别的回调;没有事件循环,我们就没法把「I/O 完成」和「执行对应回调」串起来。在代码层面,我们通过回调、Promise、async/await 登记「当某件事完成时要做的事」,这些都会变成事件循环里的任务在主线程上按某种顺序执行。Node 文档里常把「Event-driven」「Non-blocking I/O」「Event Loop」放在一起,描述的正是这三块。
事件循环在做什么
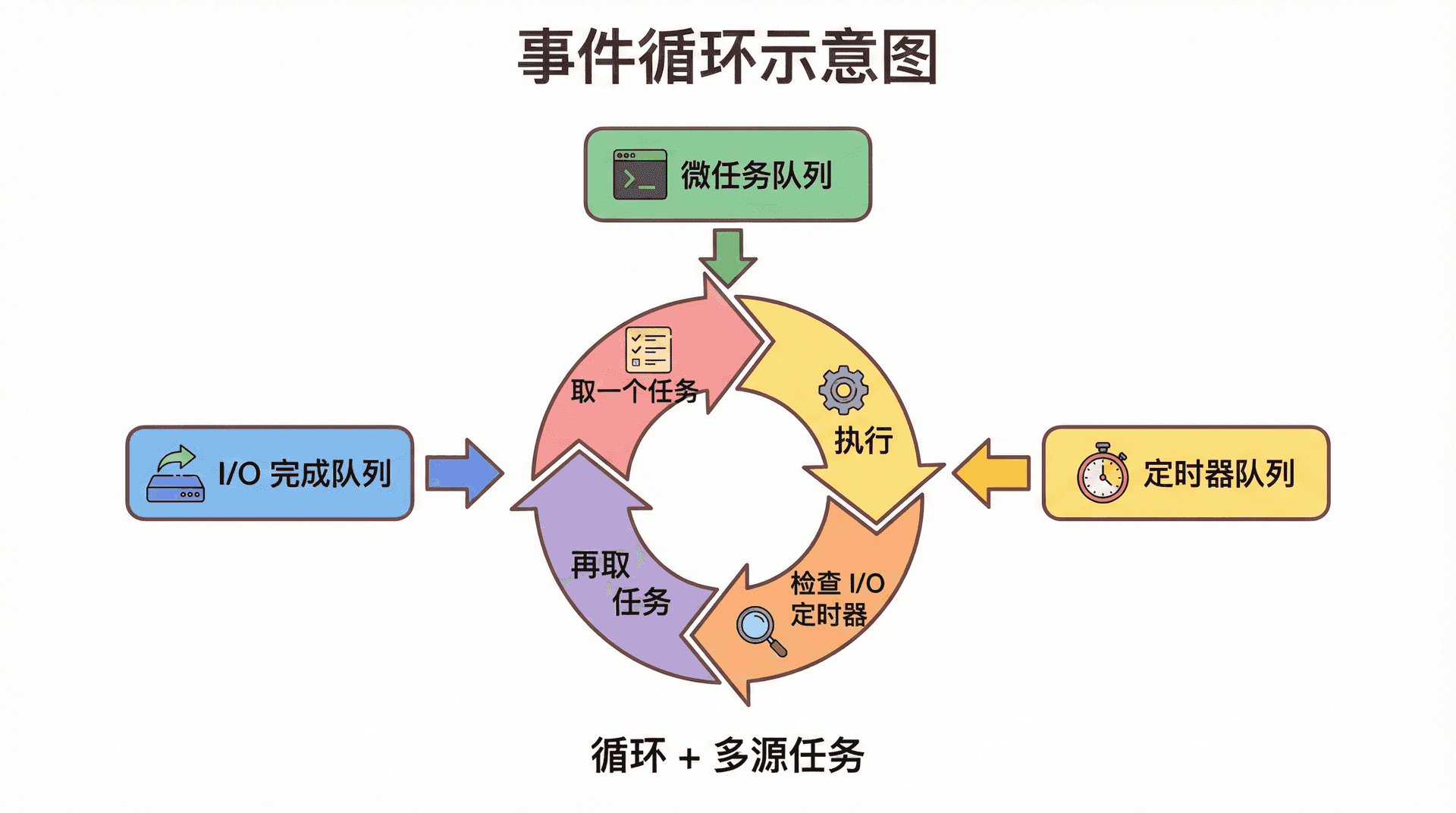
事件循环的具体逻辑会在第三讲完整展开,这里只做概览。事件循环大致在做这样的事:在每一轮循环中,先处理一批「微任务」(例如 Promise 的 then、queueMicrotask),再处理一个「宏任务」(例如 setTimeout 的回调、I/O 完成的回调),然后再处理微任务,如此往复。主线程始终在执行「从队列里取出的一个任务」,执行完再取下一个。主线程的执行顺序由「哪些任务在队列里、按什么顺序被取出」决定,而这些任务又由「I/O 完成」「定时器到期」等事件触发生成。本讲只需建立「事件循环在不断取任务、主线程不断执行任务」的宏观图景即可。
事件循环与 Reactor 模式
Node.js 采用的「单线程 + 事件循环 + 非阻塞 I/O」模型常被称作「Reactor 模式」或「事件驱动模式」。Reactor 的核心思想是:主线程只负责「分发事件」和「执行与事件关联的处理逻辑」,所有会阻塞的操作(如 I/O)都被委托给系统或线程池,等 I/O 就绪后再通过事件把控制权交回主线程。这种模型和 Nginx 用少量 worker 配合 epoll 处理高并发的思路相通;Nginx、Redis、Netty 等高性能服务中都能看到类似的「事件驱动 + 非阻塞 I/O」设计。
用代码感受「事件驱动」
下面这段代码可以帮我们直观感受「事件」和「执行顺序」。我们用一个 setTimeout 和一个 fs.readFile 同时发起两个异步操作;主线程会先执行完同步代码,然后事件循环会按某种顺序执行两个回调。注意:先输出的是 "同步代码结束",然后才是定时器或读文件的回调。
javascript
const fs = require('fs');
setTimeout(() => console.log('setTimeout 回调'), 0);
fs.readFile('package.json', () => console.log('readFile 回调'));
console.log('同步代码结束');运行后我们会先看到 "同步代码结束" 最先输出,然后 "setTimeout 回调" 和 "readFile 回调" 的先后顺序可能因系统负载而不同。这说明主线程在发起两个异步操作后并没有等待,而是继续执行了同步代码,两个回调是在事件循环的后续轮次中被调度的。第三讲会讲 setTimeout 和 I/O 回调分别属于哪种任务类型、在事件循环的哪个阶段执行。
事件驱动与「请求的一生」
当一个 HTTP 请求到达 Node 服务时:主线程在某一轮事件循环中执行到「有新的连接或数据可读」的回调,触发 http 模块解析请求、调用我们注册的 createServer 回调;在回调里我们可能调用 fs.readFile 或发起数据库查询,主线程在提交这些 I/O 后不会等待,而是返回事件循环去执行别的任务;等 I/O 完成后,各自的回调被放进队列,主线程在后续轮次执行这些回调,在回调里写 res.end() 把响应发回客户端。所以「一个请求的一生」是由多个事件驱动的。这种「事件—回调」的思维和前端(用户点击、Ajax 返回)是相通的,也是很多前端开发者转向 Node 后端能较快上手的原因之一。
接下来
这节课我们把「单线程」「非阻塞 I/O」和「事件驱动」三个概念拆开讲了:单线程指执行 JS 的只有一条主线程,主线程之外还有 libuv 线程池和操作系统参与 I/O;非阻塞 I/O 指我们发起的 I/O 请求会立即返回,结果通过回调或 Promise 在事件循环的某一轮交回;事件驱动指程序的执行由「事件发生」驱动,事件循环负责把 I/O 完成、定时器到期等对应的回调调度到主线程执行。 三者配合,使 Node 可以用一条主线程在大量 I/O 之间切换,从而支撑高并发。
下一个部分我们会深入「事件循环(Event Loop)全解析」,把 Call Stack、任务队列、微任务与宏任务、以及一个请求的完整生命周期讲清楚。