Node.js 是什么
当我们第一次接触「用 JavaScript 写后端」时,心里往往会问:JavaScript 不是在浏览器里跑的吗?它凭什么能坐在服务器上,和 Java、Python 一样处理请求、连数据库?要回答这个问题,我们需要先回到语言与运行环境的关系上来。本讲我们会从「JavaScript 为什么能跑在服务器」「Node.js 的设计初衷」「Node.js 与传统后端的差异」这三个角度,把「Node 是什么、为什么能做后端」说清楚,为后续事件循环、模块系统和异步编程打好基础。
JavaScript 为什么能跑在服务器
语言、引擎与宿主
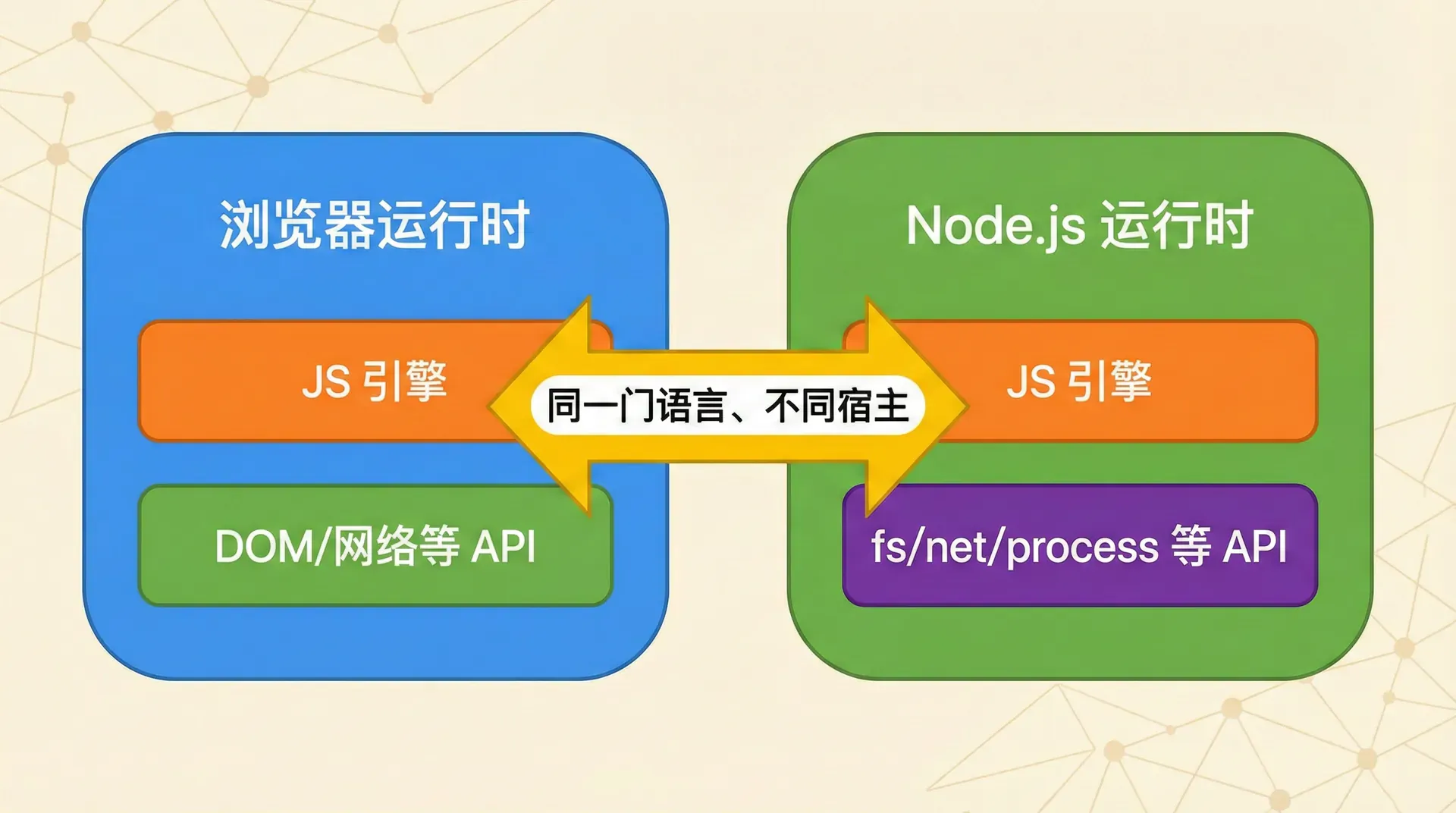
一门编程语言在脱离具体运行环境时,只是一套语法和语义的规范;真正让代码动起来的,是「引擎」或「虚拟机」这类实现。JavaScript 的标准由 ECMA 维护,V8、SpiderMonkey 等则是不同实现。浏览器只是众多「宿主环境」之一:内嵌 JS 引擎,暴露 DOM、fetch、setTimeout 等 API。若换一个宿主——例如服务器——同样内嵌引擎并按服务端需求暴露另一套 API(读文件、开 socket、起子进程),在这台机器上运行的 JavaScript 就不再「看见」DOM,而是「看见」文件系统和网络;语言不变,变的是宿主提供的 API 和执行上下文。
ECMAScript 只规定语言本身,不规定「如何与文件系统交互」或「如何发起 HTTP 请求」。这些属于宿主范畴:浏览器提供 DOM、Fetch 等,Node.js 则提供 fs、http、net、process 等。没有这套 API,即使用 V8 在服务器上跑 JS,也只能做纯计算,无法和操作系统与网络打交道。
V8 与 Node 的选型
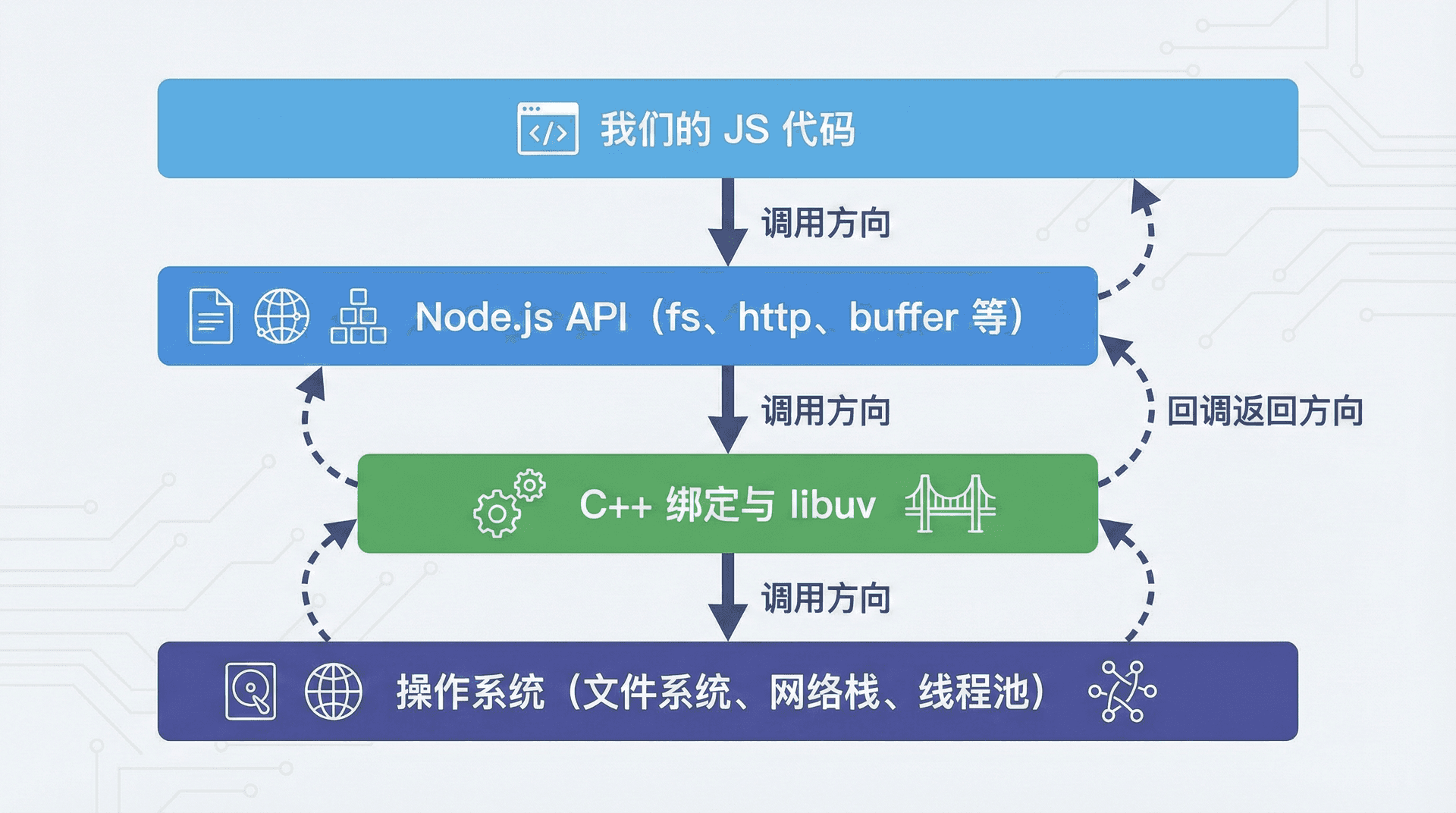
Node.js 选用 V8 作为引擎。V8 由 Google 开发,用 C++ 实现,对 JS 做 JIT、内联缓存等优化,执行效率在动态语言里属第一梯队。执行 node index.js 时,是 Node 的可执行文件在跑:内部启动 V8 解析执行我们的代码,而「系统级」能力(读磁盘、发网络包)由 Node 的 C++ 绑定和 libuv 完成。fs.readFile、http.createServer 等最终都会通过 Node 的 C++ 层落到系统调用或 libuv 的异步 I/O 上。
用代码感受一下
下面这段程序在本机 3000 端口启动一个 HTTP 服务,有请求进来就返回 “Hello from Node.js”:
javascript
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello from Node.js\n');
});
server.listen(3000, () => {
console.log('Server running at http://localhost:3000/');
});require('http')、createServer、listen 都是 Node 提供的 API,背后会调用操作系统的网络栈和 libuv。整条链路从「我们写的 JS」到「系统调用」,中间经过 Node 的 C++ 绑定和 libuv;第五讲和第四讲会分别深入 require 的加载机制与 I/O 的协作细节。
同一门语言、不同宿主
一句话:JavaScript 能跑在服务器上,是因为 Node.js 为它在服务器上实现了一个新运行时,用 V8 执行代码,用 libuv 和 C++ 绑定把 I/O 和系统调用接到 JavaScript 里。我们不会在 Node 里「重新发明」语法,只是用同一门语言写另一类程序;「全栈」指的也正是同一门语言既可跑在浏览器(前端)也可跑在 Node(后端),前后端可共享类型定义(TypeScript)、校验逻辑等。
Node.js 的设计初衷
Ryan Dahl 的动机
2009 年前,高并发网络服务常见做法是多线程或多进程:每连接一线程,线程在等 I/O 时阻塞,连接一多就面临线程暴涨和上下文切换;多进程则带来进程间通信与状态共享的复杂度。同时,前端开发者已习惯 JavaScript 和「事件—回调」思维,在服务端却要换语言和模型。Ryan Dahl 的想法是:用事件驱动、非阻塞 I/O 在单线程里处理大量并发,并用 JavaScript 来写,让前端开发者用同一套语言和思维写服务端。Node.js 的设计初衷,就是「为服务器设计一个以 JavaScript 为业务语言、以事件驱动和非阻塞 I/O 为核心的运行时」,而不是「顺便把 JS 搬到服务器」。
V8 与 libuv
实现这一点需要两方面的基础:一是高性能的 JS 引擎(V8 在 2008 年随 Chrome 开源);二是「非阻塞 I/O + 事件循环」机制,把会阻塞的 I/O 交给操作系统或线程池,完成后再通过回调送回 JavaScript。后者由 libuv 承担:它抽象了各平台的异步 I/O(Linux 的 epoll、macOS 的 kqueue、Windows 的 IOCP,即多路复用),提供事件循环,让主线程不必傻等磁盘或网络,而是去执行别的任务,等 I/O 就绪再执行回调。单线程因此可以发起大量 I/O 请求,在背后并行进行,用很少的线程支撑高并发。
libuv 负责的事可粗分为两类:网络、DNS 等有原生非阻塞接口的,直接用 epoll/kqueue/IOCP;文件读写等在部分系统上没有原生异步的,用线程池模拟,避免阻塞主线程。第四讲会详细区分这两类 I/O。
理解 Node 的设计初衷,能帮我们避免用「多线程后端」的思维写 Node:不显式开很多线程,而是依靠事件循环和异步 I/O 复用单线程。
Node 自 2009 年以来经历了 CommonJS → ES Modules、回调 → Promise → async/await 等演进,核心模型「单线程 + 事件驱动 + 非阻塞 I/O」未变。从设计初衷看,Node 用单线程换简单心智模型和低上下文切换成本,用非阻塞 I/O 和事件循环换高并发能力,用 JavaScript 换前后端在语言和思维上的一致。
Node.js 与传统后端(Java / Python)的差异
执行模型与编程习惯
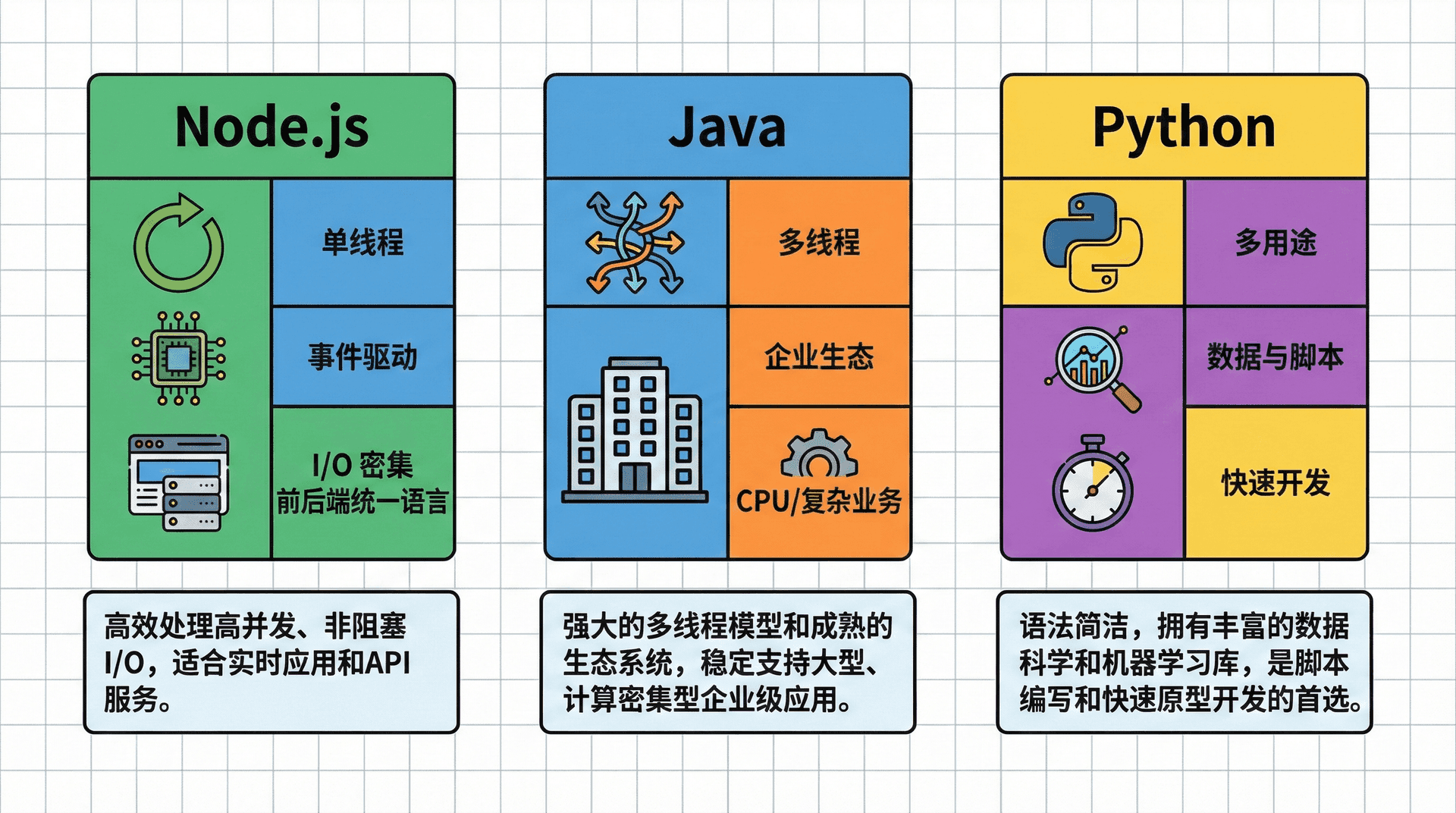
Node.js 是单线程 + 事件循环:主线程只跑 JavaScript,耗时 I/O 委托给 libuv 和底层系统,通过回调和 Promise 把结果送回。Java、Python 的传统用法则是多线程或多进程,每请求往往一线程/进程,线程在等 I/O 时可能阻塞(除非用 NIO 或 asyncio)。在 Node 里我们很少「开线程」,而是「发很多异步 I/O,等它们在事件循环里完成」。Node 的并发来自「大量 I/O 并发 + 单线程调度」,Java/Python 则来自「多线程/多进程 + 每线程可能阻塞」。I/O 密集、连接数大的场景(实时推送、API 网关、BFF)适合 Node;CPU 密集、单请求计算量大的场景,单线程 Node 易成瓶颈。
在 Node 里,读文件、发请求、查数据库等多是异步的(回调或 Promise),我们不会在业务代码里「阻塞等待」;在传统同步风格里则是「调方法、等返回、再往下」。这种思维转变在第六讲「回调函数与异步编程的起点」和第七讲「Promise 与 async/await」中会系统学习。
生态与选型
Node 生态与前端紧密相连:npm 上有大量构建与前端工程相关的包,也有 Express、Fastify、Koa 等 Web 框架和数据库驱动,适合全栈 JS/TS、I/O 与实时性项目。Java 更偏企业级(Spring、中间件、监控运维);Python 在数据科学、脚本、Django/Flask 等场景占优。类型上,JS 是动态类型,实践中常配合 TypeScript 或 JSDoc;Java 静态类型,Python 可配合类型注解与 mypy。
选型时看业务是 I/O 密集还是 CPU 密集、团队语言、类型与生态需求。需要与前端共享逻辑或类型、做实时推送或 BFF/API 网关时,Node 通常能发挥优势;单请求内大量计算或强类型、编译期检查需求强时,多线程 Java 或成熟 JVM 生态可能更合适。学 Node 不是为了取代 Java 或 Python,而是多一种工具,在合适场景下写出简洁、可维护的后端代码。
接下来
这节课我们澄清了 JavaScript 能跑在服务器上的原因(新宿主 + V8 + 系统 API),回顾了 Node 的设计初衷(单线程 + 非阻塞 I/O + 事件驱动),并和传统后端做了对比。下一讲会深入运行模型,把「单线程」「非阻塞 I/O」「事件驱动」落到实处,初步接触事件循环,为第三讲的全解析做铺垫。建议在本地用 node 跑一遍上面的 HTTP 示例,访问 http://localhost:3000/,亲眼看到「JavaScript 在服务器上」返回的 “Hello from Node.js”。