事件循环(Event Loop)
在第二讲中,我们把「单线程」「非阻塞 I/O」和「事件驱动」三个概念拆开讲了,并反复提到「事件循环」:主线程不断从事件循环里取任务执行。
本讲要把事件循环彻底拆开,看 Call Stack、任务队列、微任务与宏任务、以及一个请求在 Node.js 中的完整生命周期。只有理解事件循环的细节,写异步代码时才能准确预测「这段回调和那段回调谁先执行」,排查问题时才能从执行顺序上找到根因。
Call Stack
主线程与调用栈
当我们说「主线程在同一时刻只执行一段 JavaScript」时,这段 JavaScript 具体是怎么被执行的?答案是:调用栈(Call Stack)。JavaScript 引擎(在 Node 里是 V8)在执行代码时,会维护一个调用栈:每当我们调用一个函数,就把这个函数的「调用帧」压入栈顶;当这个函数返回(或执行完毕),就把对应的帧弹出栈。例如,若 A 调用了 B,B 又调用了 C,那么在执行 C 的函数体时,栈里从底到顶依次是 A 的帧、B 的帧、C 的帧;当 C 返回后,C 的帧弹出,栈顶变成 B 的帧,以此类推。
在 Node 里,主线程的工作可以概括为:不断从事件循环里取「该执行的任务」,把任务推入 Call Stack 执行,执行完再取下一个任务,如此循环。Call Stack 是「当前正在执行的那条调用链」的具象化;事件循环是「该执行哪个任务」的调度器。同步代码的执行顺序就是 Call Stack 的压栈和出栈顺序。异步回调则不会立刻压入 Call Stack;它们会先被放进事件循环的某个队列里,等事件循环在某一轮「取任务」时,才会把这个回调当作一个任务推入 Call Stack 执行。「这段回调和那段回调谁先执行」取决于它们被放进哪个队列、在事件循环的哪个阶段被取出;下一小节会用「宏任务与微任务」的规则把执行顺序讲清楚。
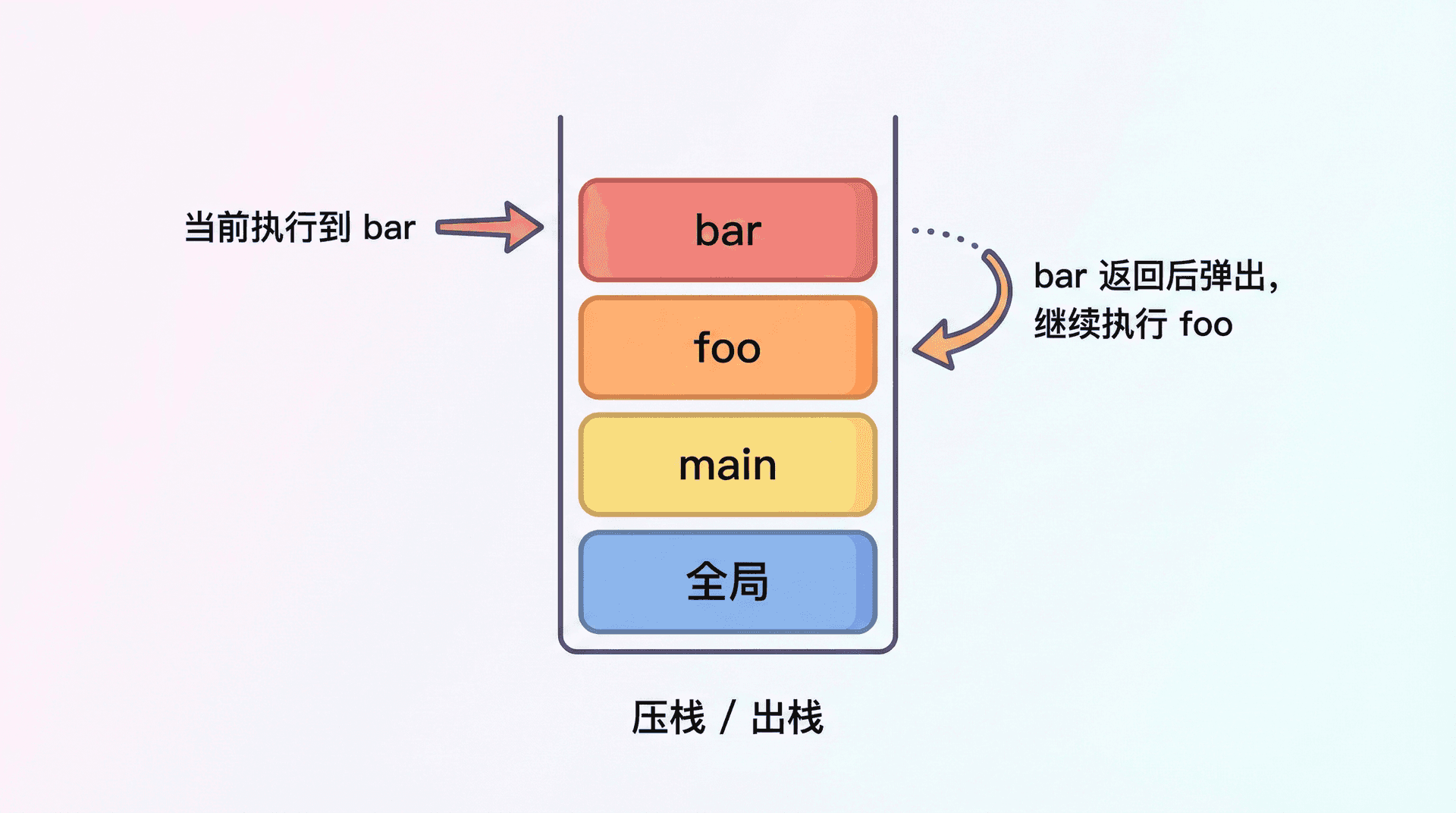
调用栈与错误栈
当我们抛出一个错误或打印堆栈时,看到的「栈跟踪」就是 Call Stack 在那一刻的快照。例如 Error.stack 或 console.trace() 会输出从当前函数一直到最外层调用者的函数名和位置,这正是 Call Stack 从顶到底的顺序。异步错误可能在不同「任务」中抛出,那时 Call Stack 可能已经变了,所以我们需要在回调或 Promise 里显式捕获错误,而不是依赖外层的 try/catch(第十三讲「错误处理与服务健壮性」会展开)。Call Stack 有大小限制;若递归深度过大(例如没有终止条件),Node 会抛出 "Maximum call stack size exceeded" 错误。异步回调是在「新的宏任务」中执行的,每次执行完回调 Call Stack 就清空了;但若在同步代码里写了深层递归,就需要注意栈深度。
任务队列与事件循环的阶段
阶段有哪些
事件循环不是一个简单的「一个队列、不断取」的模型。在 Node.js 里,事件循环被分成了多个阶段,每个阶段有自己的队列和规则;主线程在每一轮循环中会依次经过这些阶段。根据 Node 官方文档,事件循环大致包含以下阶段(顺序依次):timers(执行 setTimeout、setInterval 的回调)、pending callbacks(执行部分系统调用的回调)、idle/prepare(内部使用)、poll(等待 I/O 完成、执行 I/O 回调)、check(执行 setImmediate 的回调)、close callbacks(执行关闭相关的回调,如 socket.on('close'))。我们不需要记住每个阶段的细节,但需要建立「事件循环有多阶段、每阶段有对应类型的任务」的图景。setTimeout(fn, 100) 时,fn 会在至少 100 毫秒后、在某一轮的 timers 阶段被调度执行;setImmediate(fn) 时,fn 会在当前轮或下一轮的 check 阶段被调度执行。写「在 I/O 之后、下一轮 timers 之前执行」的逻辑时,应正确使用 setImmediate 而不是 setTimeout(fn, 0)。
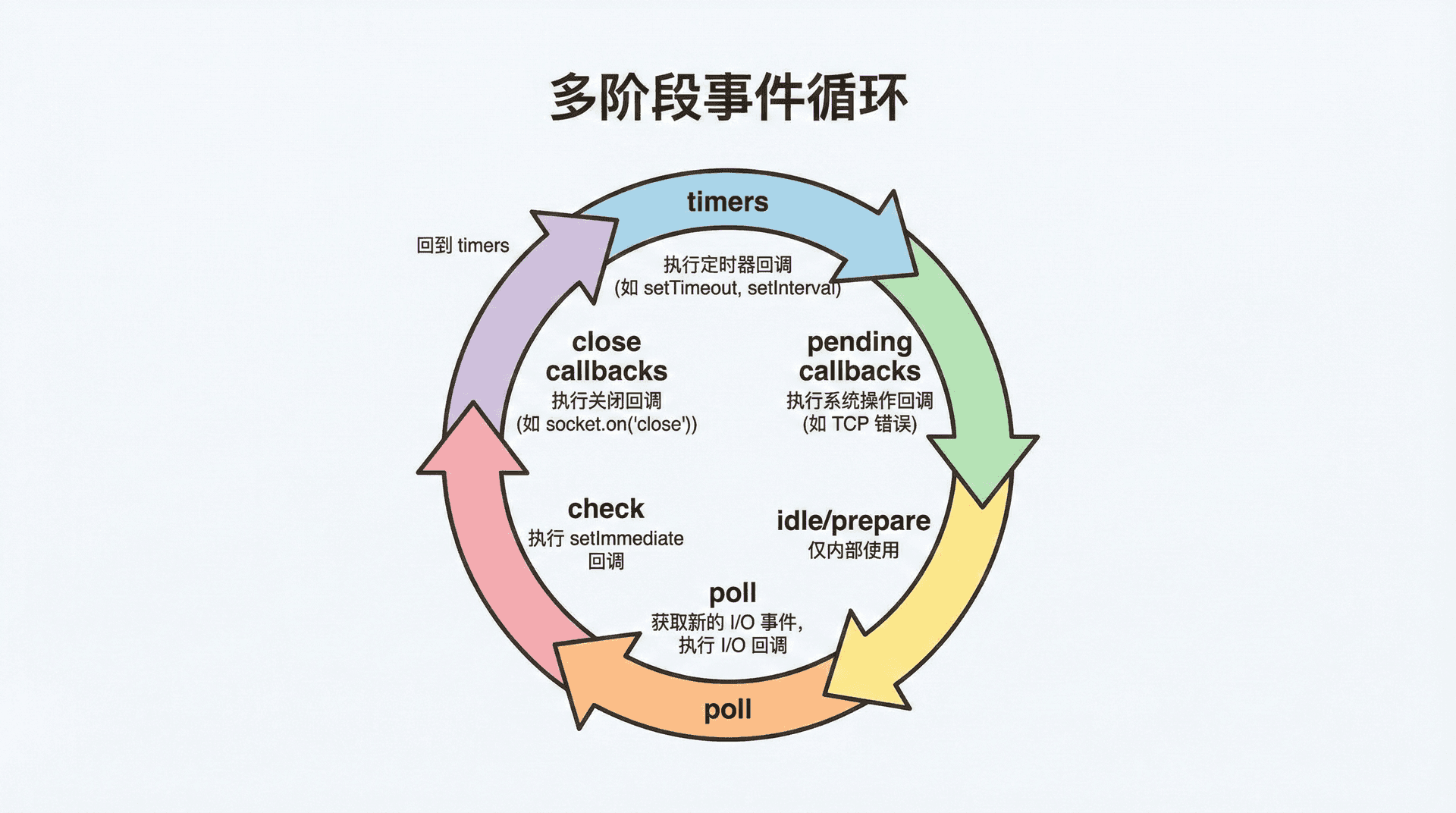
poll 阶段与一轮循环
在轮询(poll)阶段,事件循环会等待 I/O 完成(例如网络数据可读、文件读完成),并执行与这些 I/O 相关的回调。若没有定时器或 setImmediate 在等待,且 poll 队列为空,事件循环可能会在 poll 阶段阻塞一段时间,等待新的 I/O 事件。fs.readFile(path, callback) 读文件完成后,callback 会在 poll 阶段(或后续阶段)被调度执行。在一轮循环中,主线程会依次经过 timers、pending callbacks、idle/prepare、poll、check、close callbacks,在每个阶段可能执行一批回调(即一批宏任务),每执行完一个宏任务就清空微任务队列,再取下一个宏任务。当所有阶段都跑完一遍后,事件循环会进入下一轮,从 timers 阶段重新开始。「setTimeout(fn, 0) 和 setImmediate(fn) 谁先执行」取决于调用时机:若两者都在主模块或同步代码里调用,执行顺序可能因系统负载而不同;若两者都在 I/O 回调里调用,则 setImmediate 的回调会在当前轮的 check 阶段执行,setTimeout(fn, 0) 的回调会在下一轮的 timers 阶段执行,所以 setImmediate 会先执行。业务代码中更常用 Promise 和 async/await,setImmediate 和 process.nextTick 多用于库或框架内部。
宏任务与微任务
除了「阶段」之外,事件循环还区分宏任务(macrotask)和微任务(microtask)。「在一个阶段里被取出执行的一个回调」可以理解为一个宏任务;例如一次 setTimeout 的回调、一次 I/O 完成的回调、一次 setImmediate 的回调,都是宏任务。微任务则包括 Promise 的 then/catch/finally、queueMicrotask(process.nextTick 在 Node 里有更高优先级,有时被单独讨论)。在浏览器和 Node 里,规则一致:每执行完一个宏任务,都要先把当前所有的微任务执行完,再取下一个宏任务。所以 Promise.resolve().then(fn) 时,fn 会在「当前宏任务之后、下一个宏任务之前」执行;setTimeout(fn, 0) 时,fn 会在「下一轮的 timers 阶段」作为宏任务执行。这解释了为什么 Promise.then 的回调往往比 setTimeout(fn, 0) 的回调更早执行。async 函数里 await 之后的代码,本质上也是通过微任务来调度的;第七讲「Promise 与 async/await」会系统展开。
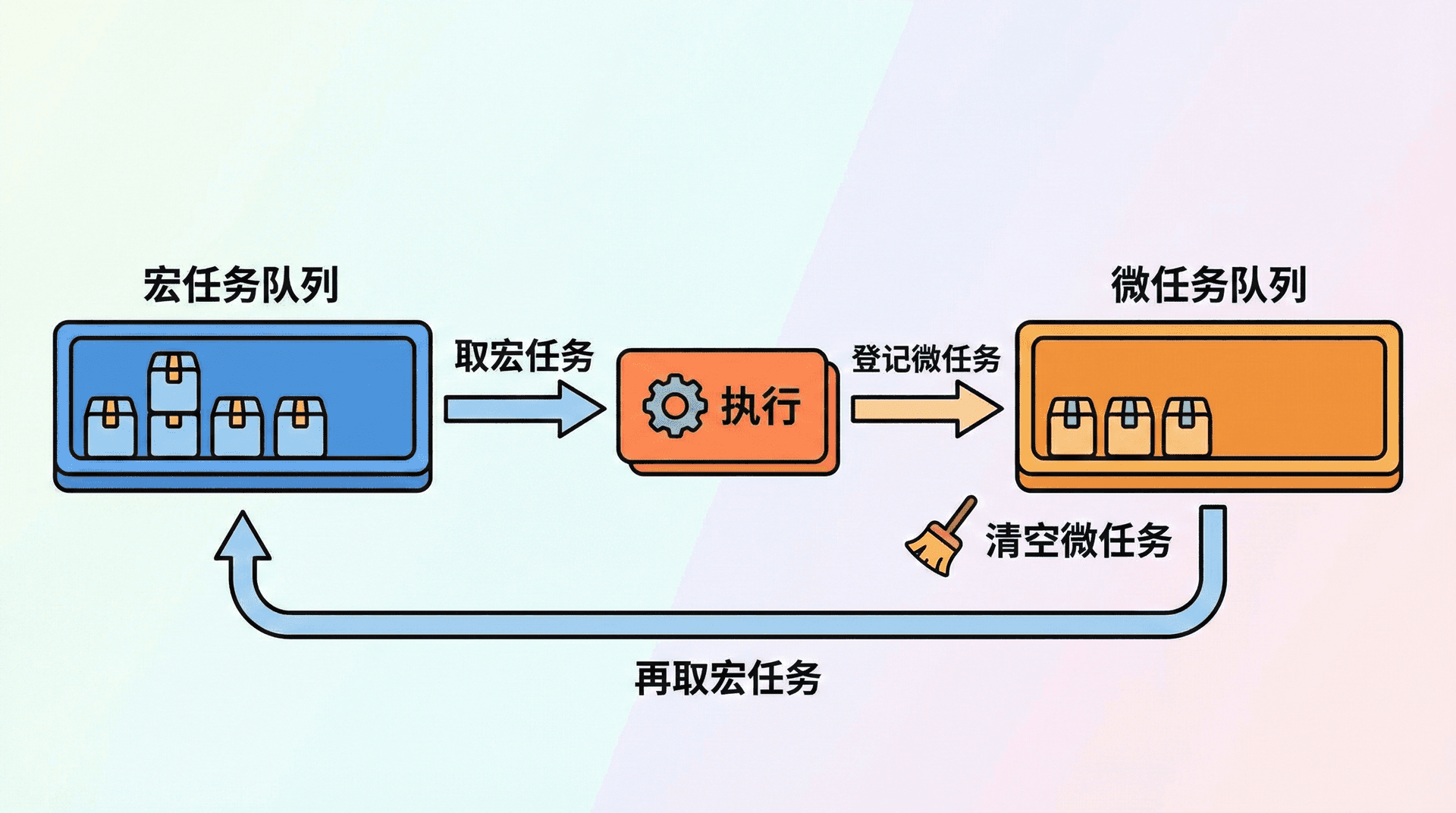
下面这段代码可以帮我们直观感受微任务和宏任务的顺序:同步代码先执行,然后清空微任务(Promise.then),最后执行 setTimeout 的宏任务。
javascript
setTimeout(() => console.log('setTimeout'), 0);
Promise.resolve().then(() => console.log('Promise'));
console.log('同步');运行后输出顺序为:「同步」「Promise」「setTimeout」。因为「同步」是当前宏任务的一部分,执行完后微任务队列里有 Promise 的 then,先清空微任务输出「Promise」,再取下一个宏任务(setTimeout)输出「setTimeout」。若在「同步」和「Promise」之间加一句 process.nextTick(() => console.log('nextTick')),输出顺序会变成「同步」「nextTick」「Promise」「setTimeout」,因为 nextTick 队列在微任务之前被清空。
每执行完一个宏任务,都要先把当前所有的微任务执行完,再取下一个宏任务。所以 Promise.then、queueMicrotask 等微任务会在「当前宏任务之后、下一个宏任务之前」执行。
process.nextTick 与 setImmediate
在 Node 里,process.nextTick(callback) 会把 callback 放进「nextTick 队列」,这个队列的优先级高于微任务:在当前阶段结束后、进入下一阶段之前,会先清空 nextTick 队列。所以执行顺序大致是:执行当前宏任务 → 清空 nextTick → 清空微任务 → 进入下一阶段取下一个宏任务。setImmediate(callback) 则会把 callback 放进 check 阶段的队列,在 poll 阶段结束后执行。若在 I/O 回调里同时写 process.nextTick(fn1) 和 setImmediate(fn2),会先执行 fn1,再执行 fn2。nextTick 和 Promise.then 谁先执行?答案是 nextTick 先执行。写业务代码时应优先使用 Promise 和 async/await,少用 process.nextTick,避免「nextTick 递归」导致事件循环饿死;setImmediate 则适合「在 I/O 之后、下一轮 timers 之前」执行逻辑。
一个请求在 Node.js 中的完整生命周期
从进来到出去的路径
有了 Call Stack、事件循环阶段、宏任务与微任务的概念,我们可以串起「一个 HTTP 请求从进来到出去」的完整路径。假设有一个用原生 http 模块写的服务,监听在 3000 端口。请求的数据到达操作系统内核后,libuv 会收到「可读」事件,在 poll 阶段会把「有数据可读」的回调交给主线程执行;主线程在执行这个回调时,会调用 http 模块的解析逻辑,解析请求行、请求头、请求体,并触发我们通过 createServer 注册的回调。在我们的 handler 里,我们可能会调用 fs.readFile 或发起数据库查询;这时主线程会发起非阻塞 I/O,把「I/O 完成后要执行的回调」登记给 libuv,然后 handler 返回,Call Stack 弹出,主线程回到事件循环,去执行别的任务。等 fs.readFile 或数据库查询完成,libuv 会把我们登记的回调放进事件循环的队列,在某一轮 poll 阶段主线程会取到这个回调并执行;在这个回调里我们可能会写 res.end(data) 把响应发回客户端。所以「一个请求的一生」是由多个宏任务组成的:先是一个「连接可读 / 请求数据可读」的宏任务(解析请求、调用 handler),再可能是多个「I/O 完成」的宏任务,在每个宏任务之间可能穿插微任务。主线程不断在「取宏任务 → 执行 → 清空微任务 → 再取宏任务」之间循环,单线程处理了多个请求的交错逻辑。请求 A 和请求 B 会交错执行:请求 A 的 handler 发起了读文件,主线程去执行请求 B 的 handler,等请求 A 的读文件完成后再执行请求 A 的回调。理解「一个请求的一生」有助于我们把「请求级别的状态」放在闭包或上下文里,而不是依赖全局变量,从而避免请求之间的状态串线。第九讲「HTTP 在 Node.js 中的实现」和第十一讲「中间件模式与框架原理」会看到 Express/Koa 如何在「请求的一生」中插入中间件和路由。
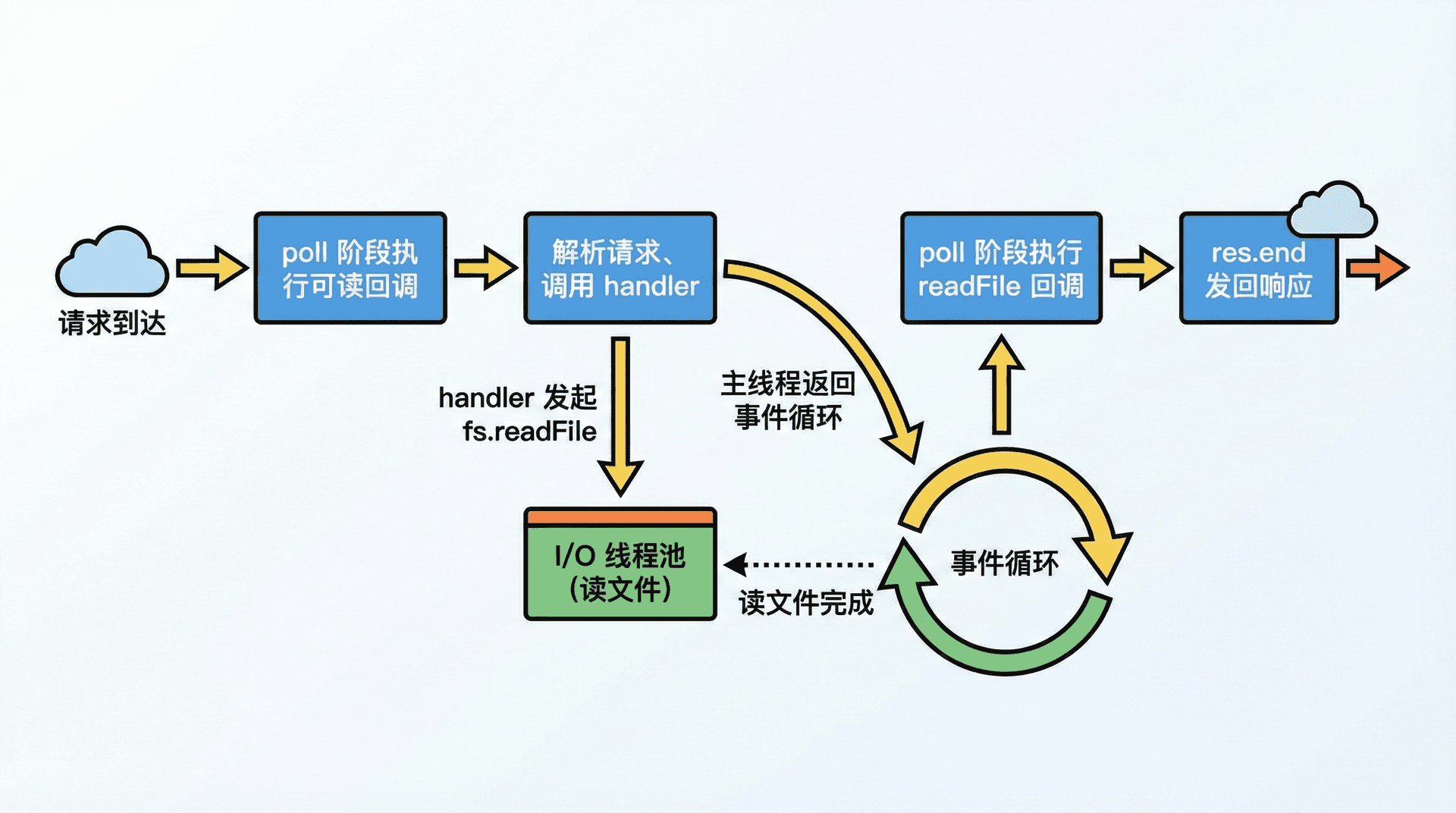
请求与响应对象在事件循环中的流转
在我们的 handler 里,我们会收到 req 和 res 两个对象;它们是由 http 模块在「可读回调」里创建并传给我们的。当 handler 发起 fs.readFile 时,主线程会返回事件循环,但 req 和 res 会随着闭包被「携带」到 readFile 的回调里。所以当 readFile 的回调在 poll 阶段被调度执行时,我们仍然可以访问同一个 req 和 res,在回调里写 res.end(data) 把响应发回客户端。这种「请求级别的状态通过闭包在多个宏任务之间传递」的方式,正是 Node 单线程模型下处理请求的典型模式。后续学习 Express/Koa 时,会看到 req 和 res 是如何在中间件链中传递的。
下面用一段简化的代码说明「请求处理」和「异步 I/O」如何与事件循环配合。请求到达时,在 poll 阶段执行「可读」回调,在回调里解析请求并调用 createServer 注册的 handler;handler 里发起 fs.readFile 后主线程立即返回,不等待;读文件完成后,在 poll 阶段执行 readFile 的回调,在回调里 res.end(data)。
javascript
const http = require('http');
const fs = require('fs');
const server = http.createServer((req, res) => {
// 请求到达 → poll 阶段执行此 handler(可读回调触发)
const path = 'package.json'; // 示例:读当前目录的 package.json
fs.readFile(path, (err, data) =>
主线程在发起 readFile 后不会等待,而是回到事件循环;读文件完成后,我们的回调会在 poll 阶段被调度执行。这样,单线程就在「处理请求 A → 发起 A 的 I/O → 处理请求 B → A 的 I/O 完成、执行 A 的回调」之间切换,实现了高并发。
接下来
这部分我们把事件循环拆成了 Call Stack、任务队列、事件循环阶段、宏任务与微任务、以及一个请求的完整生命周期。Call Stack 是「当前正在执行的那条调用链」;事件循环按阶段取任务,每执行完一个宏任务就清空微任务,再取下一个宏任务;一个 HTTP 请求从进来到出去,由多个宏任务组成,主线程在这些任务之间切换。
有了这节课作为基础,后续学习回调、Promise、async/await 时就能准确理解「这段回调会在事件循环的哪一轮、哪个阶段执行」;学习 HTTP、中间件时就能准确理解「一个请求的一生」是如何由多个宏任务和微任务组成的。 下一个部分我们会深入「异步 I/O 与系统交互原理」,区分同步与异步、阻塞与非阻塞,并看 Node 是如何把 I/O 交给操作系统的,把「事件循环调度 I/O 回调」和「libuv 与操作系统如何完成 I/O」对接起来。