Node.js 模块系统与工程化
在前面的学习里,我们区分了同步与异步、阻塞与非阻塞,并看了 Node.js 是如何把 I/O 交给操作系统和 libuv 的。从第一讲到第四讲,示例代码里都出现了 require('http')、require('fs') 这样的调用:它们从哪来、怎么加载、背后有什么规则?
因此这节课我们要把 Node.js 的模块系统讲清楚,包括 CommonJS 模块的写法、require 的加载机制、以及在实际项目中如何组织目录和拆分模块。只有理解了「一个文件如何变成模块」「require 如何解析路径并执行代码」,我们在写工程化代码时才能正确拆分职责、避免循环依赖,并为后续学习回调和框架打下基础。
Node 诞生时 JavaScript 标准里还没有模块语法,社区采用了 CommonJS 规范(用 require 加载、用 module.exports 导出);后来 ES Module 被纳入标准、Node 也逐步支持,但在现有生态和大量存量代码里 CommonJS 仍是主流,这里我们以 CommonJS 为主,在需要时会提到与 ES Module 的差异。
CommonJS 模块
一个文件就是一个模块
在 Node.js 里,每一个 .js 文件(在满足一定约定下)都会被当作一个模块来执行。当我们执行 node index.js 时,Node 会把 index.js 当作一个模块加载:先解析文件内容,再包在一个函数里执行,这样这个文件内部就有了自己的作用域,不会和别的文件里的变量冲突。这种「一个文件一个模块」的约定,让我们可以把代码拆成多个文件,通过 require 和 module.exports 在文件之间传递值,从而组织成可维护的工程。与浏览器里「多个 script 标签共享全局」不同,Node 的模块是隔离的:每个文件在自己的「模块作用域」里执行,顶层声明的变量不会自动变成全局对象的属性,因此我们不会因为两个文件都定义了同名变量而互相覆盖。这种隔离是 Node 能够承载大型后端项目的基础之一;我们在第一讲里提到的「同一门语言、不同宿主」,在模块系统上就体现为 Node 采用了与浏览器不同的「模块化」方案。
模块内部默认是「私有的」:在 a.js 里用 const x = 1 定义的变量,在 b.js 里是访问不到的,除非 a.js 通过 module.exports 把 x(或包含 x 的对象)导出,而 b.js 通过 require('./a') 加载 a.js 并拿到导出的引用。这种「默认私有、显式导出」的规则,和浏览器里「所有脚本共用一个全局」形成对比,也让我们在拆分模块时更容易控制「谁能看到什么」。
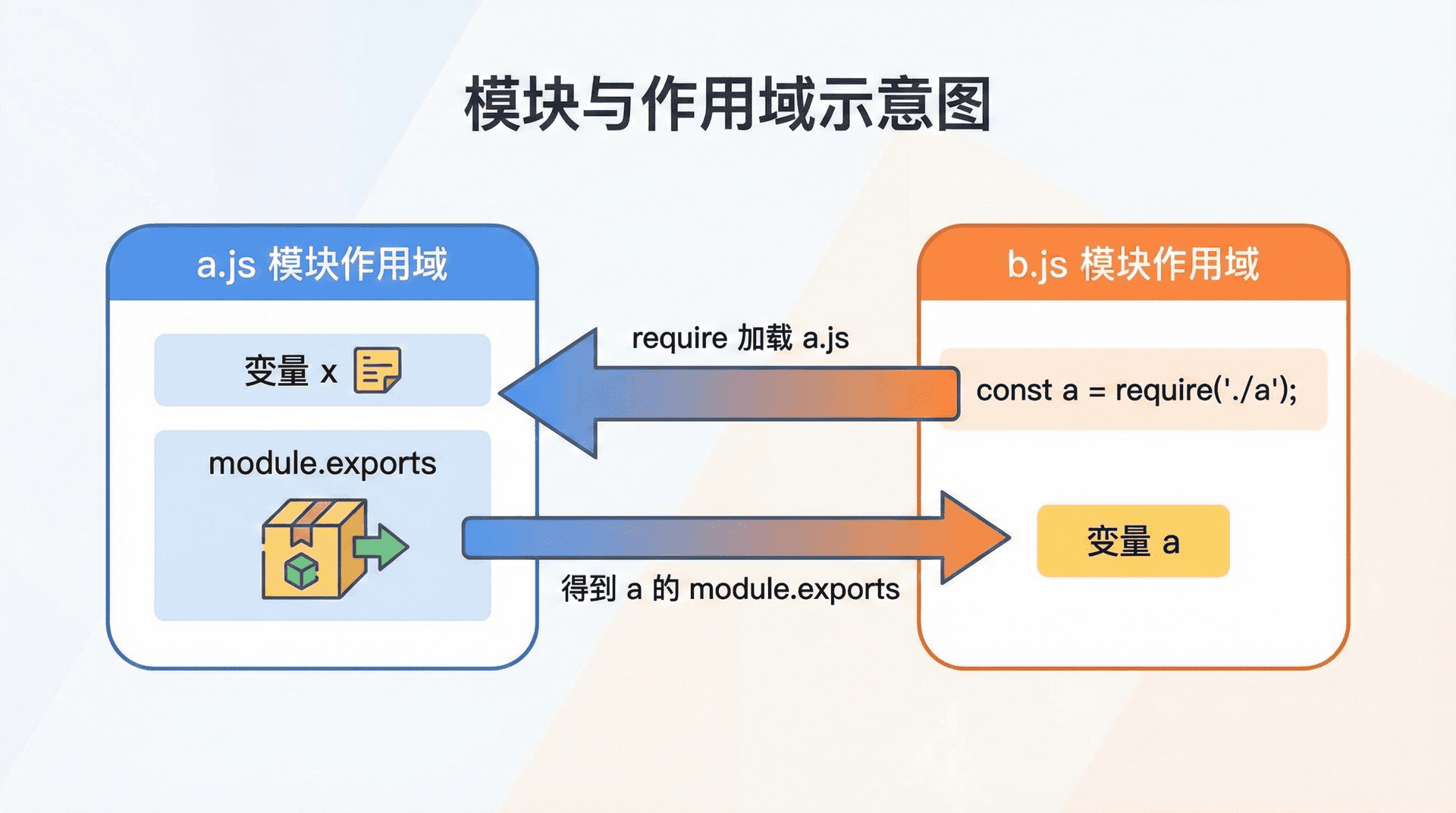
module.exports 与 exports
每个模块在被执行时,Node 会注入几个「全局」变量,其中和导出直接相关的是 module 和 exports。module 是一个对象,代表当前模块本身,其中 module.exports 就是「这个模块对外暴露的值」。当别的文件 require 这个模块时,得到的就是 module.exports 的引用(注意:是引用,不是拷贝)。所以我们写 module.exports = { foo: 1 },在另一个文件里 const a = require('./a'),a 就指向这个对象;若我们之后在 a.js 里修改 module.exports.foo = 2,在 b.js 里看到的 a.foo 也会变成 2,因为引用的是同一块内存。
与此相关的是 Node 提供的缩写:exports。在模块顶层,exports 默认指向 module.exports,所以我们写 exports.foo = 1 等价于 module.exports.foo = 1。但有一点容易踩坑:若我们写 exports = { foo: 1 },这只是把变量 exports 指向了一个新对象,并没有改变 module.exports,所以别的文件 require 进来拿到的还是原来的 module.exports(可能是空对象)。因此,若我们要导出一个新对象,应写 module.exports = { foo: 1 },而不是 exports = { foo: 1 };若只是往现有导出对象上挂属性,用 exports.xxx = ... 或 module.exports.xxx = ... 都可以。在实际写代码时,建议统一用 module.exports,避免混淆。
另一种常见写法是导出单个函数:module.exports = function (a, b) { return a + b; },这样在别的文件里 const add = require('./add') 得到的就是这个函数本身。若想同时导出多个命名项,可以写 module.exports = { add, multiply } 或分多行挂属性。Node 内置模块大多采用「导出对象、对象上挂方法」的形式,例如 require('fs') 得到的是一个对象,上面有 readFile、writeFile 等方法;我们自己的工具模块也可以沿用这种风格,便于扩展和按需解构。
下面这段代码演示模块的导出与引用。
javascript
// utils.js
function add(a, b) {
return a + b;
}
module.exports = { add };
// index.js
const { add } = require('./utils');
console.log(add(1, 2)); // 3运行 node index.js 会得到输出 3。
同步加载与执行顺序
CommonJS 的 require 是同步的:当执行到 require('./a') 时,若模块 a 还未被加载过,Node 会立刻去解析并执行 a.js,等 a.js 执行完后,再把 module.exports 返回,然后当前文件才继续执行下一行。所以「加载」和「执行」是绑在一起的,并且是阻塞的:在 a.js 执行完之前,当前线程不会去执行 require('./a') 后面的代码。这也意味着,若 a.js 里又 require 了 b.js,执行顺序会是:先执行完 b.js,再执行完 a.js,再回到最初的文件继续执行。这种「深度优先、同步执行」的加载顺序,对我们理解模块间的依赖关系和循环依赖很有帮助。
因为 require 是同步的,它适合在程序启动时加载配置、加载其他模块;不适合在请求处理路径上动态 require 大量模块,否则会阻塞主线程。require 在首次加载模块时会读磁盘(解析并执行文件),若我们在每个请求里都 require 一个尚未加载过的大模块,就会在请求路径上引入同步 I/O,主线程会卡住。工程上我们应尽量让所有依赖在进程启动时通过顶层的 require 加载完,请求处理时只使用已经加载好的模块引用;这与第四讲里「在请求路径上避免同步 I/O」的原则一致。
CommonJS 的 require 是同步的:执行到 require 时会立刻加载并执行目标模块,等目标模块执行完后才返回并继续当前文件。因此应尽量在进程启动时完成模块加载,避免在请求处理路径上动态 require 未加载的模块,否则会阻塞主线程。
require 加载机制
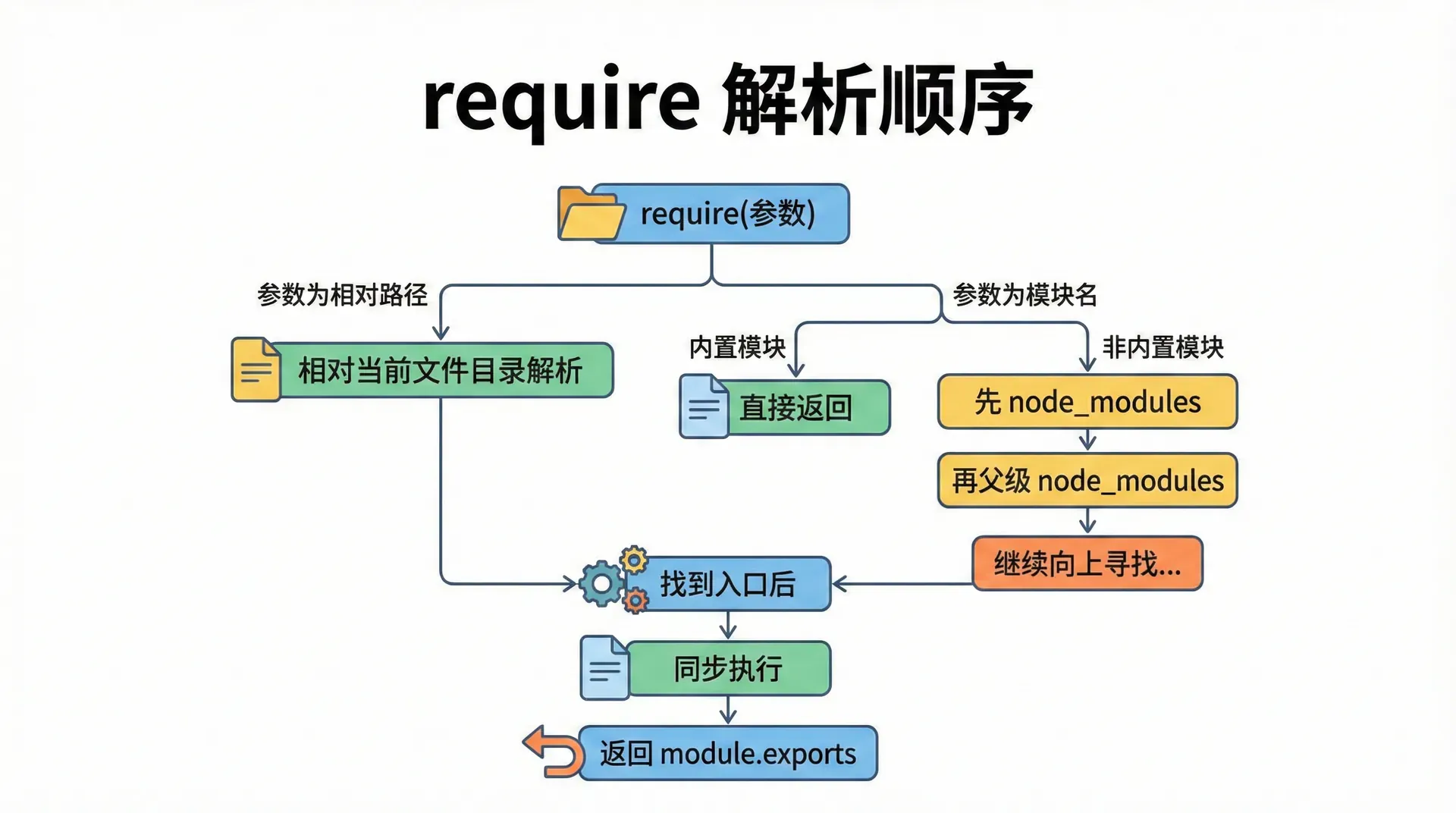
解析规则:从哪里找文件
当我们写 require('./utils') 或 require('http') 时,Node 会根据参数类型采用不同的解析策略。以 ./ 或 ../ 开头的路径是相对路径,Node 会相对于当前文件所在目录去解析。例如在 /project/src/index.js 里写 require('./utils'),Node 会依次尝试 /project/src/utils.js、/project/src/utils/index.js 等(具体规则见 Node 文档),找到第一个存在的文件就加载。扩展名可省略;若当前目录下只有 utils/index.js 而没有 utils.js,Node 会尝试 utils.js、utils.json、utils.node 以及 utils/index.js,只要存在 utils/index.js 加载就会成功。若既有 utils.js 又有 utils 目录,Node 会优先选择 utils.js。这种「扩展名可省略、目录可作模块入口」的规则,让我们可以用「一个目录代表一个模块、入口为 index.js」的方式组织代码。
不以 ./ 或 ../ 开头的,例如 require('http') 或 require('lodash'),会被当作模块名:Node 会先在当前目录下的 node_modules 里找同名目录或包,若找不到再向父级目录的 node_modules 找,一直找到根目录;对于 http 这类 Node 内置模块,则直接使用内置实现,不读磁盘。内置模块(如 http、fs、path)不需要安装;第三方模块(如 lodash、express)需要先通过 npm install 安装到 node_modules,之后才能被 require。写 require('express') 时,Node 会找到 node_modules/express 目录,读取该目录下的 package.json,根据 main 或 exports 字段确定入口文件,再加载这个入口文件。理解解析规则,有助于我们在排查「找不到模块」时,检查路径是否正确、包是否已安装、以及 package.json 的入口是否配置正确。
缓存:同一模块只执行一次
Node 在加载模块时,会维护一张缓存表:以模块的解析后的绝对路径为 key,以该模块的 module.exports 为 value。当某段代码第一次 require('./a') 时,Node 会解析路径、执行 a.js,并把得到的 module.exports 放进缓存;之后无论哪里再次 require('./a')(只要解析到同一个绝对路径),Node 都不会再执行 a.js,而是直接返回缓存里的 module.exports。所以「同一个模块在进程内只会被执行一次」,后续的 require 都是拿缓存。这也意味着,模块内部的顶层代码(例如连接数据库、启动定时器)只会在第一次被加载时执行一次,不会因为被多处 require 而重复执行;同时,模块内部持有的状态(例如一个变量、一个连接池)在进程内是单例的,所有引用该模块的地方共享同一份状态。
理解缓存有助于我们避免两类问题。一类是「以为每次 require 都会重新执行」:若模块里有副作用(如写文件、发请求),多次 require 不会重复执行这些副作用,因为只有第一次会执行模块体。另一类是「以为不同路径会得到不同实例」:若 require('./a') 和 require('/project/src/a') 解析到同一个文件,两次得到的是同一个 module.exports;若通过不同路径指向了不同文件(例如 require('./a') 和 require('./lib/a')),则会得到两个不同的模块实例。在工程里,我们应尽量用统一的相对路径或包名来引用同一模块,避免同一逻辑被加载成多份;只有在「同一逻辑被放在不同路径下、且都被 require」时,才会出现多份实例,产生「状态不一致」或「重复初始化」的问题。
循环依赖
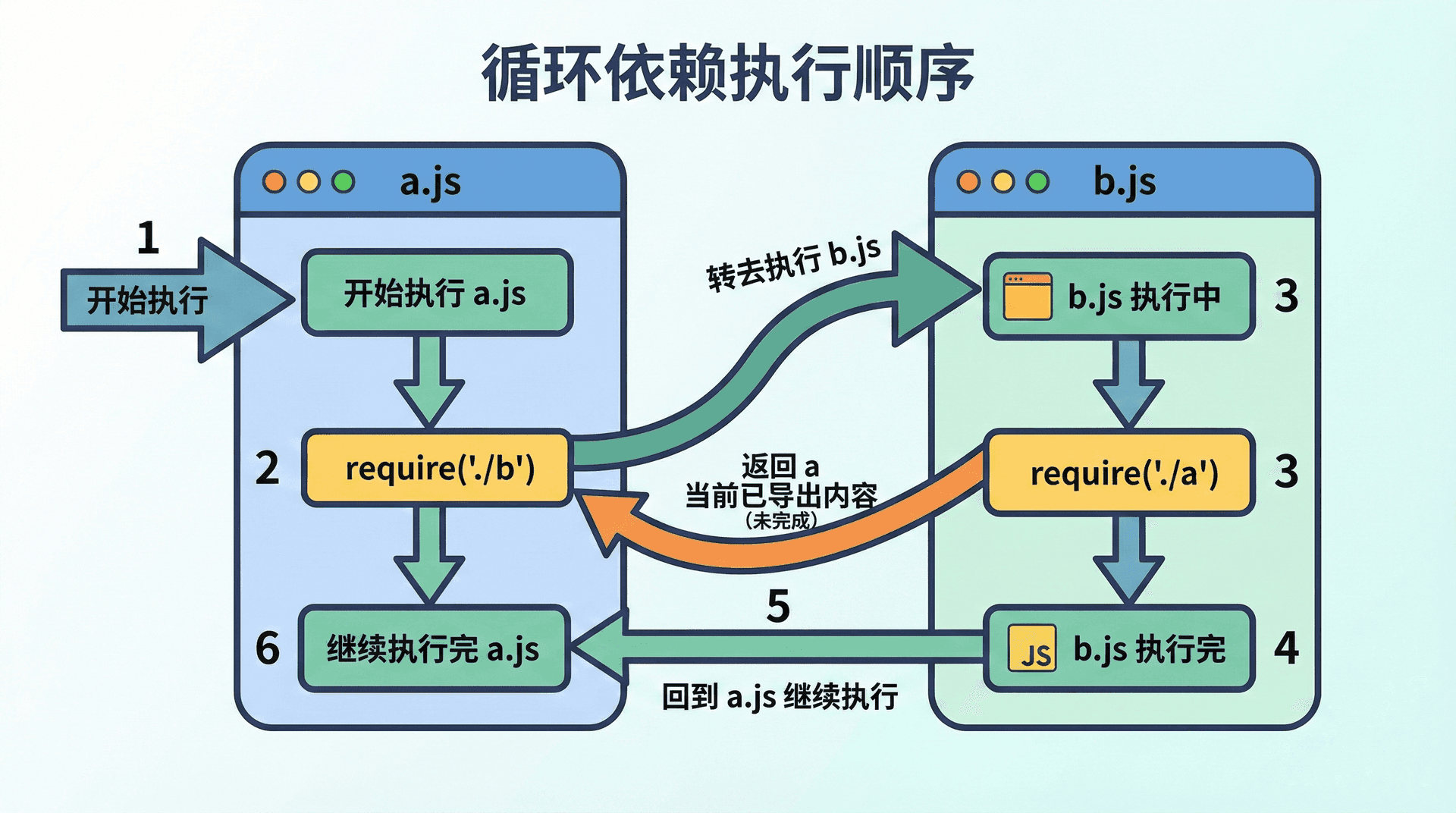
当模块 A 依赖模块 B,模块 B 又依赖模块 A 时,就形成了循环依赖。Node 不会报错,但加载顺序会导致双方拿到的「对方」可能还不完整。假设 a.js 里第一行是 const b = require('./b'),而 b.js 里第一行是 const a = require('./a')。执行顺序会是:开始执行 a.js → 执行到 require('./b') 时转去执行 b.js → b.js 执行到 require('./a') 时,a.js 还未执行完,但 Node 不会重新执行 a.js,而是返回当前已经执行到的 a 的 module.exports(此时可能还是空对象或部分赋值)→ b.js 继续执行,拿到的是「未执行完的 a」→ b.js 执行完后回到 a.js,此时 a.js 拿到完整的 b,再继续执行完 a.js。所以在这种简单的循环依赖里,后加载的那一方(这里是 b.js)会拿到先加载一方(a.js)的「半成品」。若我们在 b.js 里立刻使用 a 的某个导出,而该导出是在 a.js 里较后才赋值的,就可能拿到 undefined。
避免循环依赖的最好办法是从设计上消除环:把共用的逻辑抽到第三个模块,让 A 和 B 都依赖这个第三方模块,而不是互相依赖。若短期内无法消除,可以尽量让双方只使用「在对方模块顶层就已经赋值好的」导出,或者把依赖关系延后(例如在函数内部再 require),这样至少在执行到该函数时,对方模块通常已经执行完了。本讲我们只需要建立「循环依赖会导致一方拿到未完成的对象」的图景,在拆模块时尽量避免环;在第十二讲「Node.js 常见设计模式」中我们会再谈模块化与解耦。
模块的「加载」发生在同步执行 require 的那一时刻;模块体(包括顶层的 require、module.exports 赋值)都在当前这一轮「任务」里执行完,不会把控制权交回事件循环。若模块顶层有异步操作(例如 setTimeout 或 fs.readFile),这些操作会被「登记」到事件循环,但模块体本身会继续执行到结束,然后 require 返回。所以「模块加载」本身不会引入异步;只有在模块内部或调用方里显式使用异步 API 时,才会有回调和事件循环的参与。
下面这段代码演示循环依赖时「未完成导出」的现象。
javascript
// a.js
exports.done = false;
const b = require('./b');
console.log('a: b.done =', b.done);
exports.done = true;
// b.js
exports.done = false;
const a = require('./a');
console.log('b: a.done ='
运行 node a.js,输出会是 b: a.done = false,然后是 a: b.done = true。因为当 b.js 执行到 require('./a') 时,a.js 只执行了 exports.done = false 和 require('./b'),还没执行到后面的 exports.done = true,所以 b.js 拿到的 a.done 是 false。遇到「为什么这里拿到的值是 undefined」时,可以检查是否存在循环依赖以及导出赋值的顺序。
项目结构与模块拆分
目录约定与入口
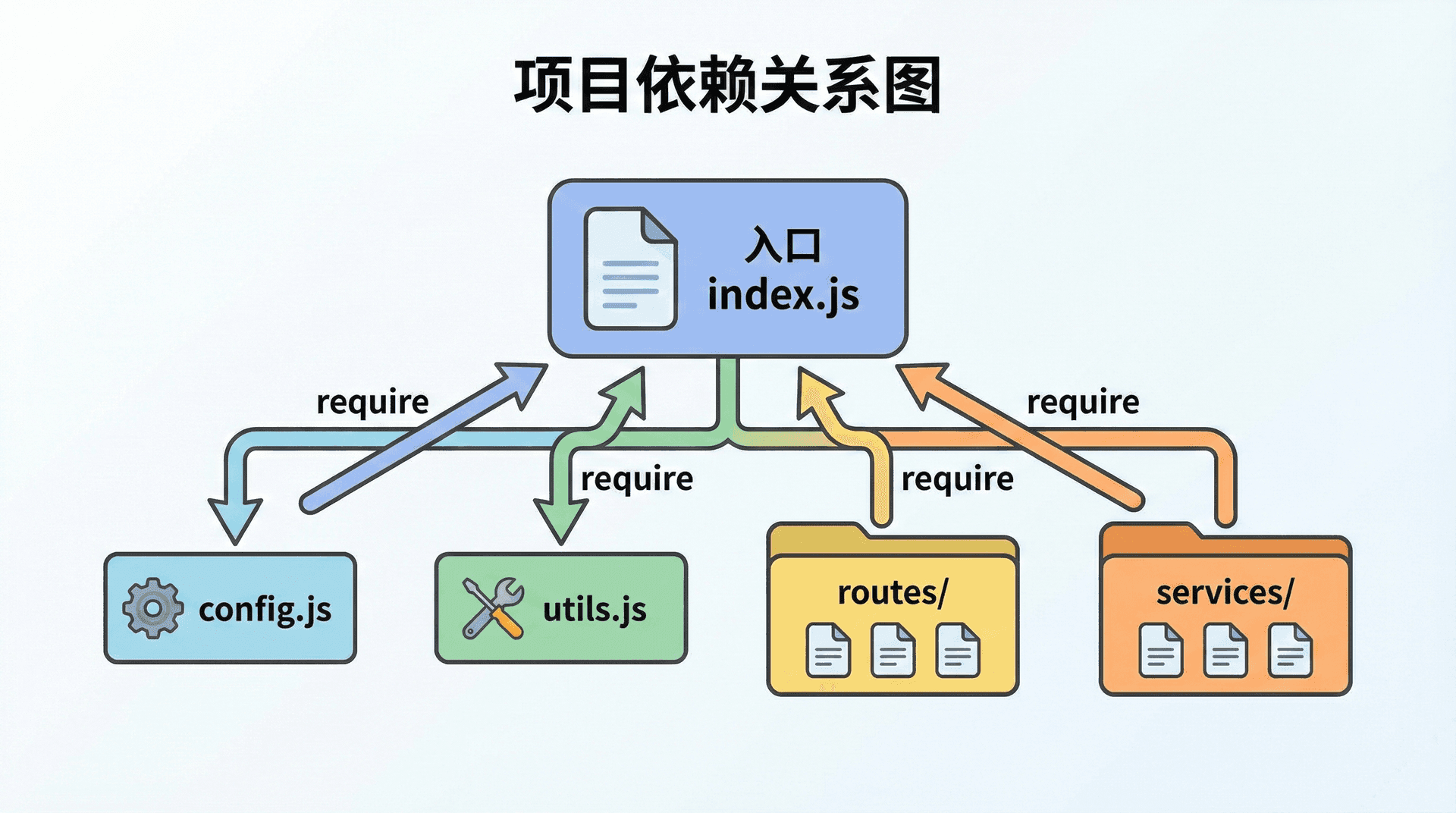
在实际项目中,我们通常不会把全部代码塞在一个文件里,而是按职责拆成多个模块,并约定一个「入口」:例如 index.js 或 src/index.js,作为 node index.js 或 node src/index.js 的起点。入口文件负责把「配置加载」「服务启动」「路由挂载」等串联起来,其余逻辑分布在别的模块里,通过 require 被入口或中间层引用。这种「一个入口 + 多模块」的结构,是 Node 项目最常见的形式。
很多项目会约定 src 或 lib 目录放业务代码,config 或根目录放配置文件,node_modules 放第三方依赖(由 npm 管理,一般不手改)。入口文件放在根目录或 src 下,名字多为 index.js、app.js、server.js 等。若项目规模较大,还会在 src 下再分子目录:例如 src/routes 放路由定义、src/controllers 放处理请求的函数、src/services 放业务逻辑、src/models 或 src/db 放与数据访问相关的代码。这样,当我们需要修改「用户登录」的逻辑时,可以直奔 controllers 或 services 里对应用户的模块,而不必在单一大文件中搜索。与「按职责拆分」一致:目录结构应反映职责划分,让新人或未来的自己能快速定位「这段逻辑在哪」。测试代码则放在 test、tests 或 __tests__ 下,通过测试框架(如 Jest、Mocha)运行,而不是通过 node 直接执行入口。这种约定不是 Node 强制的,但被社区广泛采用,便于协作和工具链(如 ESLint、TypeScript)的统一配置。
按职责拆分模块
拆分模块时,通常按「职责」而不是按「类型」来划分。例如我们把「连接数据库」的逻辑放在 db.js,「处理用户相关请求」的逻辑放在 userController.js 或 routes/user.js,「通用工具函数」放在 utils.js,这样每个文件职责单一,便于测试和维护。若按类型拆(例如「所有 Controller 放一个目录」),也可以,但要注意避免单文件过大;若一个文件超过几百行,就可以考虑按子职责再拆。与前面提到的启动时加载原则一致:我们应尽量在入口或启动阶段把依赖的模块都 require 进来,在请求处理时只使用已加载的引用,避免在请求路径上动态 require 大文件造成阻塞。
和「职责」相关的另一个维度是「层级」。例如我们把与 HTTP 无关的纯逻辑(如校验、计算)放在一层,把「接收请求、解析参数、调用纯逻辑、返回响应」的放在另一层(Controller 或 Route Handler),把「连接数据库、发外部请求」的再放在一层(Service 或 Repository)。这样,纯逻辑不依赖 Node 的 req/res,便于单测;Controller 只做「适配 HTTP」,具体业务交给下层。在第九讲「HTTP 在 Node.js 中的实现」和第十讲「RESTful API 的设计与实现」中,我们会具体看到如何把路由、Controller、Service 拆成模块;本讲我们只需要建立「按职责和层级拆分、入口串联」的图景。
配置文件与环境
配置(如端口、数据库地址、日志级别)通常不适合写死在代码里,而是放在配置文件或环境变量中。常见做法是:在项目根目录或 config 下放 config.js 或 config/default.js,在模块顶层用 require('./config') 加载,这样进程内所有模块共享同一份配置。若需要区分环境(开发、测试、生产),可以按环境名加载不同文件(如 config/production.js),或使用环境变量(如 process.env.NODE_ENV)在代码里分支。加载配置时若使用同步的 fs.readFileSync,应只在启动阶段执行一次,不要在每个请求里读;配置加载属于「启动阶段」的一次性工作,在这里使用同步 API 是可以接受的。一旦 server.listen() 被调用,事件循环开始处理请求,我们就应假定「配置已经就绪」,不再在请求回调里读文件或 require 新模块。
下面这段代码演示一个最小化的项目结构:入口加载配置并启动 HTTP 服务,配置来自 config.js,工具函数来自 utils.js。
javascript
// config.js
module.exports = {
port: process.env.PORT || 3000,
};
// utils.js
module.exports = {
greet(name) {
return `Hello, ${name}`;
},
};
// index.js
const http = require('http');
const
运行 node index.js 后,服务会在配置的端口(默认 3000)启动,收到请求时返回 Hello, Node。
接下来
这节课我们介绍了 Node.js 的模块系统与工程化基础:CommonJS 模块以「一个文件一个模块」为单位,通过 module.exports 导出、通过 require 加载;require 是同步的,会在首次加载时执行目标模块并缓存结果,同一模块在进程内只执行一次。
require 的解析规则是相对路径相对于当前文件目录,模块名先找 node_modules 和内置模块;理解解析与缓存,有助于我们排查「找不到模块」和「重复执行」问题。
循环依赖会导致一方拿到对方未完成导出的对象,应从设计上尽量避免。项目结构上,我们按职责和层级拆分模块,约定入口和配置的加载方式,并避免在请求处理路径上动态 require 大模块。
有了这部分的知识作为基础,我们在写多文件项目时就能正确使用 require 和 module.exports,并合理规划目录;在后续学习 HTTP、路由、中间件时,我们会把「路由」「Controller」「Service」拆成独立模块,那时这部分建立的模块化思维会反复用到。
下一节课我们会进入「回调函数与异步编程的起点」,学习回调模式、Error-first Callback 以及回调地狱为什么难以维护,为第七讲 Promise 与 async/await 做准备。
建议在本地建一个小项目,用两三个文件练习 require、module.exports 和简单目录划分,再故意制造一次循环依赖,观察执行顺序和导出值,巩固这部分的内容。