回调函数与异步编程
在第四讲中我们区分了同步与异步,并提到异步结果通过回调、Promise 或事件交回;第五讲建立了模块化与 require 的基础。
这节课我们需要把「回调」单独讲清楚:什么是回调函数模式、Node 社区为何采用 Error-first 约定、以及回调嵌套为何会变成「回调地狱」难以维护。只有理解这些,才能明白后续学习中的 Promise 与 async/await 要解决什么问题。
回调函数模式
什么是回调
当我们把一段逻辑「留给别人在合适的时机调用」时,这段逻辑通常以函数的形式存在;若这个函数是作为参数传给另一个函数、由后者在「某件事完成后」再调用,我们就称它为回调函数。从调用方看,发出调用时并不立刻拿到结果,而是把一个「收到结果后该怎么处理」的函数交出去;等结果就绪时,被调用方会调用这个函数,并把结果(或错误)作为参数传入。这种「先登记、后执行」的模式,与第四讲里「异步结果如何交回」完全对应:在 Node 里,绝大多数异步 API 都接受一个回调函数,在 I/O 完成或事件发生时由事件循环在某一轮执行该回调。
与此相关的是「谁在什么时候调用回调」。在同步世界里,我们调用一个函数,函数执行完返回,我们拿到返回值;在异步世界里,我们调用一个函数并传入回调,函数很快返回,但真正的「结果」要等到回调被调用时才会出现。因此,写异步代码时心里要清楚:当前这段代码执行完后,还有多少逻辑被「登记」在回调里、尚未执行;这些逻辑会在事件循环的后续轮次中被执行,而不是紧跟在当前代码后面。理解这一点,有助于我们在第三讲事件循环的基础上,把「调用栈」「任务队列」和「回调何时执行」串起来。
在 Node I/O 中的用法
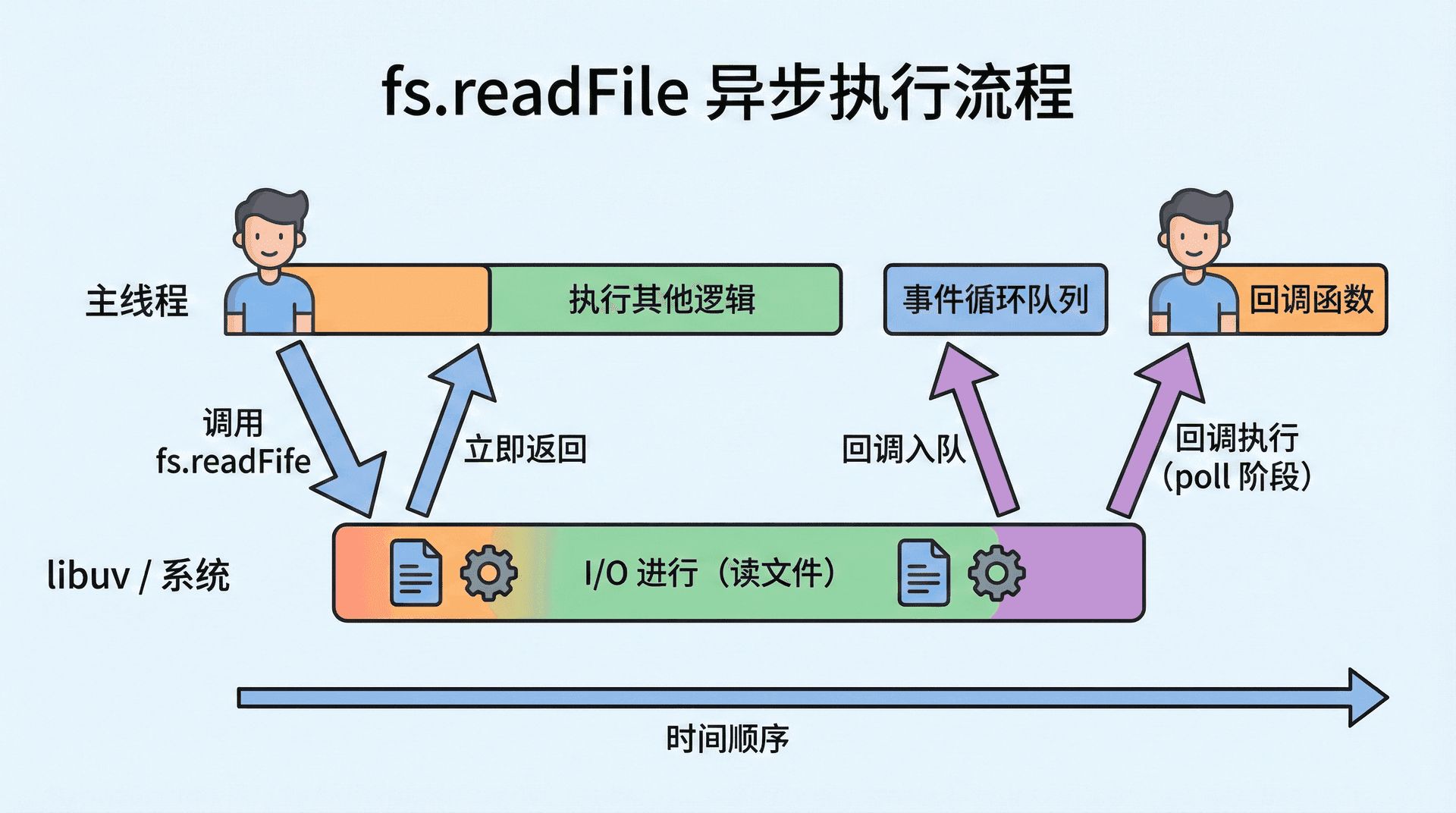
在 Node 里,回调最常见的用法就是与 I/O 绑定。例如 fs.readFile(path, options, callback) 会在读文件完成后调用我们传入的 callback,并把错误(若有)和文件内容作为参数传入;http.request(options, callback) 会在请求发出后,在收到响应时调用 callback,并把响应对象传入。这些 API 的共性是:调用时立即返回,不会阻塞主线程;真正耗时的 I/O 由 libuv 和操作系统在背后完成,等 I/O 完成后,libuv 把我们的回调放进事件循环的队列,主线程在 poll 阶段(或相应阶段)取出并执行。这与第四讲「非阻塞 I/O」和第三讲「事件循环与 I/O 完成」是一致的:主线程不会停在 readFile 上等磁盘,而是去执行别的代码;等磁盘读完后,回调在事件循环的某一轮被调度执行。
另一种常见用法是定时与延迟。例如 setTimeout(callback, ms) 会在指定毫秒数之后把 callback 放进队列,由事件循环执行;setImmediate(callback) 会在当前轮次 I/O 回调之后、下一轮次之前执行 callback。这些 API 同样不阻塞:调用 setTimeout 后立即返回,callback 在将来由事件循环执行。无论是文件 I/O、网络 I/O 还是定时器,Node 里「异步结果交回」的主流历史方式都是回调;Promise 和 async/await 是后来才加入的语法糖,底层仍然依赖事件循环和「登记回调、稍后执行」的机制。
从事件循环的角度看,当我们调用 fs.readFile(path, callback) 时,当前正在执行的是「调用 readFile 的那一段同步代码」;readFile 内部会向 libuv 提交读请求、把我们的 callback 登记到某个结构上,然后返回。此时主线程继续执行 readFile 之后的代码(例如下一行的 console.log),直到当前「任务」执行完、调用栈清空,事件循环才会进入下一阶段。当 libuv 在背后完成读文件后,会把我们登记的回调放进事件循环的队列;在之后的某一轮(通常是 poll 阶段或 check 阶段),主线程会从队列里取出这个回调、推入调用栈执行。所以「回调何时执行」完全由事件循环的调度决定,我们无法假设回调一定在「下一行代码」之后立刻执行;它可能在同一轮循环的稍后阶段执行,也可能在几轮之后,取决于 I/O 完成的时间和队列里其他任务的多少。理解这一点,有助于我们在第三讲「宏任务与微任务」「poll 阶段」的基础上,把「发起 I/O → 登记回调 → 事件循环调度 → 回调执行」这条链路串起来。
用代码感受一下
下面这段代码演示异步读文件时「先返回、结果在回调里拿到」的流程。
javascript
const fs = require('fs');
fs.readFile('package.json', 'utf8', (err, data) => {
if (err) throw err;
console.log('文件内容长度:', data.length);
});
console.log('readFile 已调用');运行后会先输出「readFile 已调用」,再输出「文件内容长度: xxx」,说明调用与拿到结果发生在不同时刻,且结果是在回调里拿到的。与第四讲中的示例一致:异步调用的错误不会在 readFile 那一行抛出,而是在回调被调用时通过第一个参数传入;所以我们才需要在回调里先写 if (err) throw err(或做其他处理),再使用 data。若文件不存在或路径错误,err 会是一个 Error 对象,此时 data 为 undefined,若不先判 err 就访问 data.length 会得到运行时错误;这就是下一节 Error-first 约定要规范的事情。
Error-first Callback
约定是什么
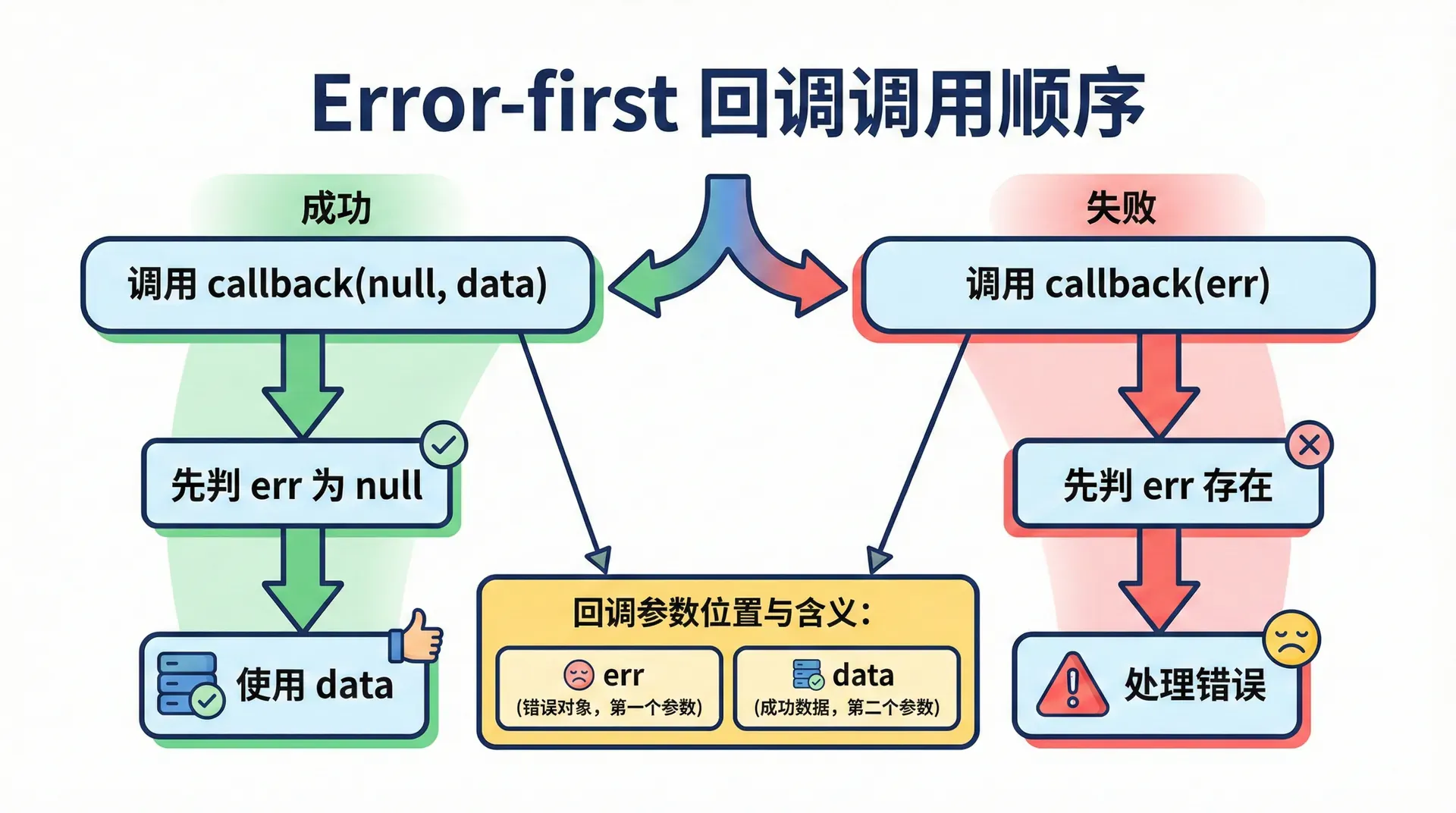
在 Node 里,绝大多数接受回调的异步 API 都遵循同一种约定:回调函数的第一个参数表示错误,第二个参数(及以后)表示成功时的结果。这种约定被称为 Error-first Callback(或 Node-style callback)。具体来说:若操作成功,第一个参数为 null 或 undefined,第二个参数为结果数据(如 fs.readFile 的 data);若操作失败,第一个参数为一个 Error 对象(或至少是 truthy 的值),此时第二个参数通常为 undefined 或不可靠。调用方在回调里应先检查第一个参数,若有错误则处理错误并返回,否则再使用第二个参数。Node 内置模块(如 fs、http、child_process)以及大量历史第三方库都采用这一约定,因此写 Node 代码时默认就按 Error-first 来写回调。
与此相关的是「为什么是第一个参数而不是最后一个」。把错误放在第一位,有一个实际好处:我们写 (err, data) => { ... } 时,若先判断 if (err),逻辑上「错误分支」和「成功分支」可以在一开始就分开,不会出现「先用了 data 再想起来检查 err」的疏漏。若错误放在最后,回调可能被写成 (data, err),开发者容易先写对 data 的处理而忽略 err;把 err 放在第一位,相当于强制我们「先看有没有错,再看结果」。
下面是一段符合 Error-first 约定的写法:先判 err,有错则处理并 return,再使用 data。
javascript
const fs = require('fs');
fs.readFile('config.json', 'utf8', (err, data) => {
if (err) {
console.error('读文件失败:', err.message);
return;
}
const config = JSON.parse(data);
console.log(
为什么这样设计
在异步世界里,错误不会在调用那一行抛出。若我们写 fs.readFile('不存在的文件', (err, data) => { ... }),readFile 会立即返回,真正的读操作在背后进行;若文件不存在,要等到 I/O 完成、回调被调用时,我们才会在回调里收到一个表示「文件不存在」的 Error。因此,同步代码里常用的 try/catch 无法捕获「在回调内部发生的错误」:try/catch 只能捕获当前执行栈上的异常,而回调是在事件循环的后续轮次中执行的,执行时已经脱离了当初调用 readFile 的那条栈。Error-first 约定把错误和结果一起放进回调参数,让调用方在回调内部统一处理「成功」和「失败」两条路径,避免错误被静默吞掉或无法传递。
另一种情况是多个异步步骤串联。若第一步成功后才发起第二步,我们必须在第一步的回调里检查 err,若有错则不再继续、并选择向上传递错误或做统一处理;若没有错,再在回调里发起第二步,第二步的回调同样要检查 err。这样,错误处理就分散在每一层回调里;我们稍后会看到,当步骤变多、嵌套变深时,这种分散会带来「回调地狱」的问题。Error-first 本身并没有解决嵌套问题,但它至少保证了「每一层都能收到并处理错误」,不会出现「错误发生了但没人检查」的情况。
同步的 try/catch 无法捕获回调内部抛出的错误,因为回调是在事件循环的后续轮次中执行的,执行时已经脱离了当初调用 readFile 的那条栈。例如下面这段代码里,throw err 发生在回调内部,外层的 try/catch 捕获不到,进程可能直接退出或触发 uncaughtException。
javascript
const fs = require('fs');
try {
fs.readFile('不存在的文件.txt', 'utf8', (err, data) => {
if (err) throw err; // 这里的 throw 不会被上面的 try 捕获
console.log(data);
});
} catch (e) {
console.error('捕获不到', e); // 不会执行
正确写法与常见错误
正确的写法是:在回调里先判断第一个参数,若存在则表示出错,应处理错误(打印、记录、向上传递或返回)并终止当前分支的逻辑;若第一个参数为 null 或 undefined,再使用第二个参数作为结果。这种写法在 Node 文档和社区示例中随处可见:打开任意一个 fs 或 http 的示例,几乎都是 if (err) { ... return; } 再使用 data。养成习惯后,写新代码时会自然先写 err 分支,再写成功分支;审查代码时也可以快速检查「每个回调是否都先判 err」,避免遗漏。例如读文件后写文件,应先检查 readFile 的回调里是否有 err,有则直接 return 或把 err 传给上层;无则再在回调里调用 writeFile,并在 writeFile 的回调里同样先检查 err。若忘记检查 err 就直接使用 data,当文件不存在或权限不足时,data 可能是 undefined,后续代码可能报错(如「无法读取 undefined 的 length」),此时错误信息往往不如「先 if (err) 再处理」清晰;更糟的是,若我们把 err 误当成 data 使用,逻辑会完全错乱。
常见错误包括:只在控制台打印 err 却不 return,导致继续执行了成功分支的代码;或者用 if (!err) 判断成功,却忽略了「err 为 0 或空字符串」等 falsy 但非 null 的边界(在 Node 里通常 err 要么是 null/undefined,要么是 Error 对象,但养成「先判 err 再使用 result」的习惯更安全)。另一种错误是「在回调外使用结果」:例如在调用 readFile 之后立刻用 console.log(data),此时回调还没执行,data 并不存在;所有对结果的依赖都必须写在回调内部,或通过下一层回调/Promise 传递。
错误示例: 不检查 err 就用 data,或只在控制台打印 err 却不 return,会继续执行后面的「成功」逻辑,导致难以排查的 bug。
javascript
fs.readFile('可能不存在的文件.txt', 'utf8', (err, data) => {
console.error(err); // 打印了 err 但没有 return
console.log(data.length); // 若出错,data 为 undefined,这里会抛错
});错误示例: 在回调外使用「结果」——readFile 是异步的,下一行执行时回调还没被调用,data 并不存在。
javascript
let data;
fs.readFile('a.txt', 'utf8', (err, content) => {
if (!err) data = content;
});
console.log(data); // 一定是 undefined,因为回调还没执行正确示例: 读文件后写文件,每一步都先判 err 再继续。
javascript
const fs = require('fs');
fs.readFile('input.txt', 'utf8', (err, content) => {
if (err) return console.error('读失败:', err.message);
fs.writeFile('output.txt', content, (err2) => {
if (err2) return console.error
在实际项目中,我们还会遇到「把回调封装成可复用函数」的需求。例如写一个 readJson(path, callback),内部调用 fs.readFile,在回调里先检查 err、再 JSON.parse(data) 并调用外层的 callback(null, parsed);若 parse 失败,则调用 callback(parseError)。这样,上层代码只需面对「readJson 的 Error-first 回调」,而不必每次都写 readFile + parse。封装时要注意:内层 API 的 err 要原样或包装后传给外层 callback,不能吞掉;成功时只传一层结果,保持 (err, result) 的约定。
javascript
const fs = require('fs');
function readJson(path, callback) {
fs.readFile(path, 'utf8', (err, data) => {
if (err) return callback(err);
try {
const parsed = JSON.parse(data);
callback(
Error-first 约定要求回调的第一个参数为错误对象(成功时为 null/undefined),第二个参数为结果。在回调内应先判断 err,若有错则处理并返回,再使用 result;避免未检查 err 就使用 result,否则在 I/O 失败时容易得到难以排查的异常。
回调地狱为什么不可维护
嵌套与执行顺序
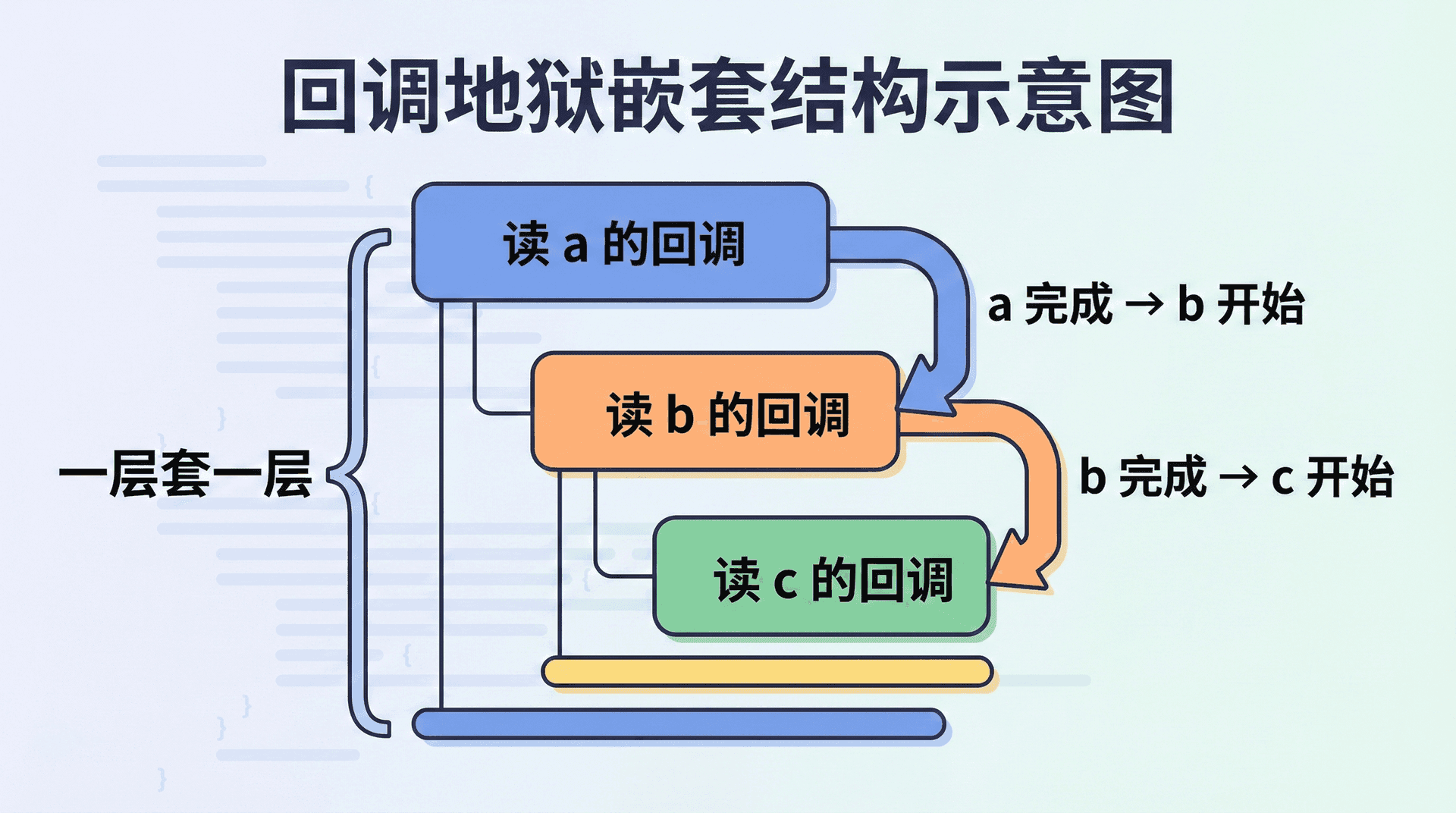
当我们需要「先做 A,A 完成后再做 B,B 完成后再做 C」时,若每一步都是异步的且只提供回调 API,很自然的写法就是把 B 写在 A 的回调里、把 C 写在 B 的回调里。例如先读配置文件,再根据配置读数据文件,再根据数据发请求:读配置的回调里调用读数据,读数据的回调里再调用发请求。这样,逻辑在代码结构上就变成一层套一层的嵌套;每多一步,就多一层缩进,代码会迅速向右「长出去」,形成所谓的回调地狱(callback hell)。执行顺序本身是正确的——先 A 再 B 再 C——但阅读顺序和修改成本会随着层数增加而急剧上升。
与此相关的是「横向扩展」与「纵向扩展」的差异。若多个异步操作彼此独立、可以同时发起(例如同时读三个文件),我们不需要嵌套,只需在顶层连续写三个 readFile,在各自的回调里处理结果即可;这时回调之间是平级的,不会形成金字塔。下面这段代码是「平级」写法:三个读文件同时发起,各自在回调里处理,没有嵌套。
javascript
const fs = require('fs');
fs.readFile('a.txt', 'utf8', (err, a) => {
if (err) return console.error('a 失败', err);
console.log('a:', a);
});
fs.readFile('b.txt', 'utf8', (err
回调地狱特指「串行依赖」的场景:下一步依赖上一步的结果,所以下一步必须写在上一步的回调里,从而造成嵌套。一旦业务逻辑需要「先查用户、再查订单、再查物流」,就会自然形成三层嵌套;若再加强制校验、日志、错误统一处理,层数还会增加。
错误处理分散
在嵌套回调中,每一层都要写一遍「if (err) ...」。若我们在最内层才统一处理错误,外层若发生错误,必须通过 return 或调用上层传入的「错误回调」把 err 传上去,否则内层无法得知外层已失败。若每一层都自己处理 err(例如打印并 return),则错误处理逻辑会分散在每一层,难以统一(例如统一上报、统一日志格式)。与第十三讲「异步错误」相关的是:同步代码可以用一个 try/catch 包住整段逻辑,异步回调则无法用 try/catch 包住「所有可能出错的回调」,因为每个回调是在不同时刻、不同调用栈上执行的;Error-first 让我们在每一层都能拿到 err,但「在每一层都写一遍 if (err)」本身就增加了重复和遗漏的风险。
另一种情况是「部分失败」。若我们串行执行三步,第二步失败,我们通常希望停止后续步骤并清理或回滚;在回调嵌套里,我们必须在第二步的回调里判断 err 后不再调用第三步,并手动执行清理逻辑。若步骤更多,清理逻辑会散落在多个分支里,难以保证「无论在哪一层失败,都能执行同一套清理」。Promise 和 async/await 在后文会提供「链式 then」和「单层 try/catch」,从写法上缓解这些问题;本讲我们只需要建立「回调地狱下错误处理分散、难以统一」的图景。
为何难以维护
深层嵌套带来的直接问题是可读性差:逻辑被「右括号」和缩进拆散,一眼看不出「这段代码在什么条件下执行」。若要在一串回调中间插入一步(例如在「读配置」和「读数据」之间加一步「校验配置」),就要在已有嵌套里再塞进一层,缩进继续加深。复用和单测也会受影响:若「读配置 → 读数据」被写在一个巨大的嵌套里,我们很难单独抽出一个函数只测「读数据」;若想复用「读数据 → 发请求」这段逻辑,要么复制粘贴整块回调,要么费力把回调拆成命名函数再组合,可读性和可维护性都不理想。
因此,Node 社区和 ECMAScript 标准后来引入了 Promise 与 async/await,从语法和流程上把「串行异步」写成近似同步的线性结构,错误也可以通过链式 catch 或单层 try/catch 统一处理。第七讲我们会专门讲 Promise 与 async/await 的设计动机和用法;本讲我们只需要明确:回调模式是异步编程的起点,Error-first 是 Node 的约定,而回调地狱是这种写法在「串行多步」场景下的自然结果,理解这一点有助于我们明白后续语法为何被设计出来。
在纯回调时代,一种常见的缓解手段是把嵌套拆成「命名函数」:例如把「读 b 的逻辑」抽成函数,在「读 a 的回调」里调用;再把「读 c 的逻辑」抽成独立函数。这样代码在结构上变平了,可读性会好一些,但「串行依赖」和「错误在每一层处理」的本质没变。下面用命名函数改写「先读 a 再读 b 再读 c」的串行逻辑,与上面的嵌套写法对比即可看出「平铺」后的样子。
javascript
const fs = require('fs');
function readA(cb) {
fs.readFile('a.txt', 'utf8', (err, data) => cb(err, data));
}
function readB(errA, dataA, cb) {
if (errA) return cb(errA);
另一种手段是使用「async 库」这类工具,通过 async.waterfall 或 async.series 把多个步骤写成数组形式;Promise 和 async/await 则从语言层面提供线性写法。学完本讲后,在第七讲中我们会直接使用这些语法,届时可以对比「同一段逻辑用回调和用 async/await」的差异。
下面这段代码演示两层串行读文件形成的嵌套:先读 a.txt,再在其回调里读 b.txt,运行后能正确得到两个文件的内容,但嵌套结构已经显现,若再增加步骤会继续加深。
javascript
const fs = require('fs');
fs.readFile('a.txt', 'utf8', (err, dataA) => {
if (err) throw err;
console.log('a:', dataA);
fs.readFile('b.txt', 'utf8', (err2, dataB) => {
接下来
这节课我们介绍了回调函数模式、Error-first Callback 以及回调地狱为何难以维护。回调是 Node 中异步结果交付的主要历史方式,绝大多数 I/O API 都接受一个在「完成时」被调用的回调;Error-first 约定统一了错误与成功两条路径,要求在回调内先判断 err 再使用 result。 当多个异步步骤串行依赖时,回调会自然嵌套成「地狱」结构,错误处理分散在每一层,可读性和可维护性都会下降;下一节课我们将学习 Promise 与 async/await,从语法和流程上改善异步写法。
建议在本地用 fs.readFile 串行读两个文件(先读第一个,在其回调里再读第二个),体会嵌套和 Error-first 的写法;再尝试在每一层都先写 if (err) return console.error(err),再处理 data,巩固「先判 err 再使用 result」的习惯。下一讲见。