异步 I/O 与系统
这节课我们把「同步与异步」「阻塞与非阻塞」两对概念讲清楚,并看 Node.js 是如何把 I/O 交给操作系统和 libuv 的。理解这些,选型时才能判断该用同步还是异步 API,排查「I/O 卡住」时才能从系统调用和线程池找原因。
同步与异步
调用方何时拿到结果
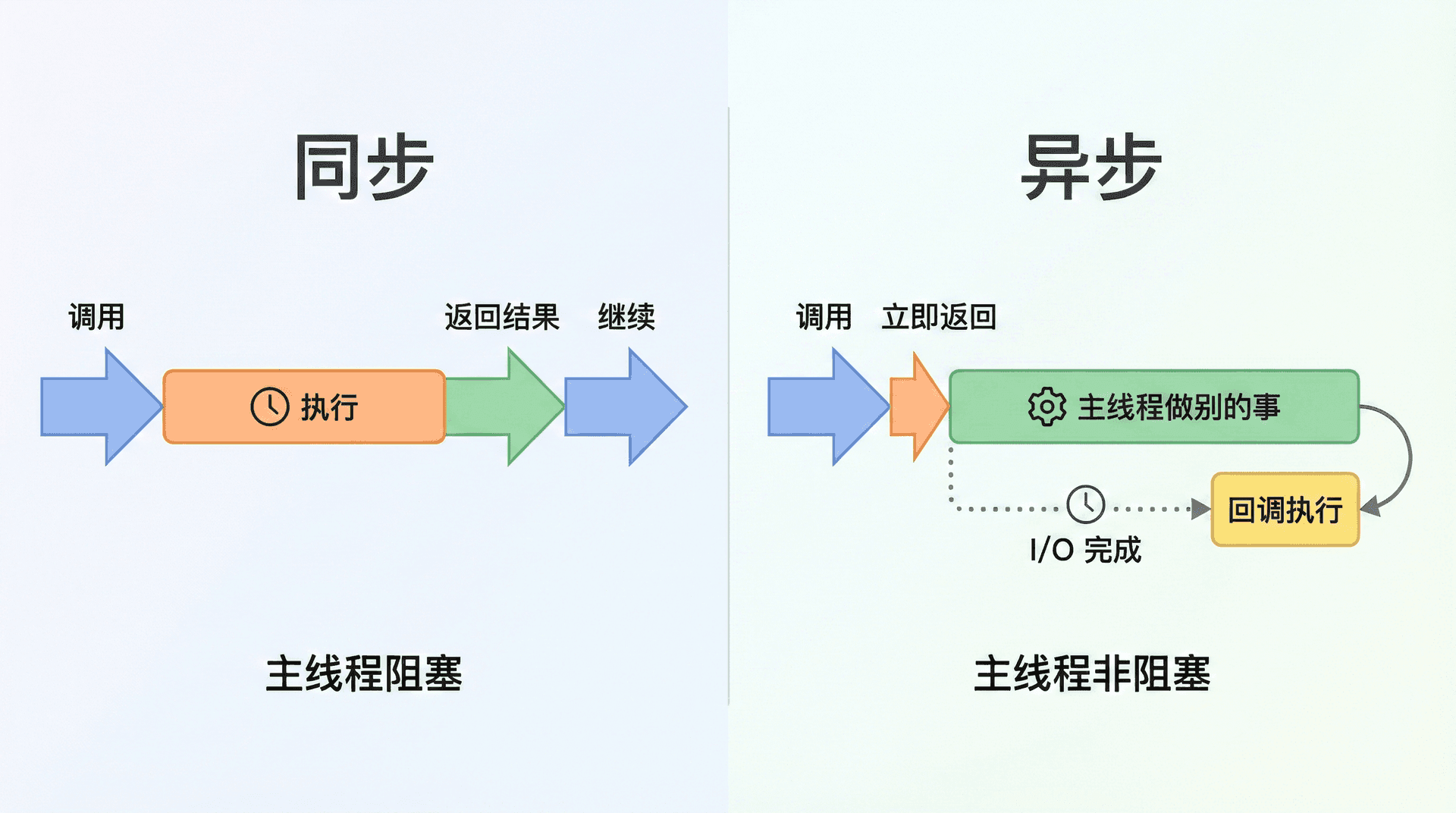
- 同步指:调用方发出调用后,一直等到这次调用做完并拿到返回值,才继续执行后面的代码。从调用方看,「调用」和「拿到结果」是连在一起的。例如
const x = 1 + 2,执行完后x立刻有值,就是同步。 - 异步指:调用方发出调用后,不会立刻拿到结果;调用先返回,结果在「将来的某个时刻」通过回调、事件或 Promise 交回。例如下面这段代码里,
readFile会很快返回,此时文件可能还没读完;等读完后,Node 在事件循环的某一轮调用我们传入的回调,那时才在回调里拿到err和data。
javascript
const fs = require('fs');
fs.readFile('data.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log('文件内容:', data);
});
console.log('readFile 已调用');运行后会先输出「readFile 已调用」,再输出「文件内容: ...」,说明「调用」和「拿到结果」是分开的两步。
理解「同步 = 调用完立刻拿结果」「异步 = 先返回、结果稍后通过回调或 Promise 拿」,有助于区分「这段逻辑会立刻执行完」和「这段逻辑要等回调执行才算完」。 在 Node 里绝大多数 I/O 都是异步的,代码风格是「发起 I/O → 注册回调 → 在回调里处理结果」。异步调用的错误不会在调用那一行抛出,而是在回调被调用时作为第一个参数传入,或通过 Promise 的 catch 处理; 在第六讲和第七讲中我们会系统学习错误处理。
同步与异步和「谁在等」无关
同步与异步描述的是「调用方何时拿到结果」,并没有直接说「等待时能不能干别的事」。「同步」不等于「阻塞」,「异步」也不等于「非阻塞」。例如 fs.readFileSync('data.txt') 是同步且阻塞的:要等读完后才返回,主线程在等的过程中不能执行别的 JavaScript。Node 绝大部分 I/O 提供异步版本(fs.readFile、http.request 等),也提供少量同步版本(如 fs.readFileSync);在请求处理路径上应避免使用同步 API。
异步结果如何交回
在 Node 里主要有三种方式:回调函数(调用时传入函数,I/O 完成时以参数传入结果或错误)、Promise(.then() 或 async/await 在将来拿结果)、事件(流或网络上监听 'data'、'end' 等)。三种方式本质都是把「完成后的逻辑」登记给运行时,等 I/O 完成后由事件循环在某一轮执行。
常见误区:以为「异步」就一定「快」。异步解决的是「在等的过程中主线程能不能干别的事」,并没有让单次 I/O 本身变快。读 100MB 文件,用 readFile 和 readFileSync 在「磁盘读多久」上是一样的;区别只是 readFile 在等时主线程可以去处理别的请求。瓶颈是主线程被阻塞就改异步 API;瓶颈是单次 I/O 太慢就从 I/O 或架构上优化。
阻塞与非阻塞
等待时能不能干别的事
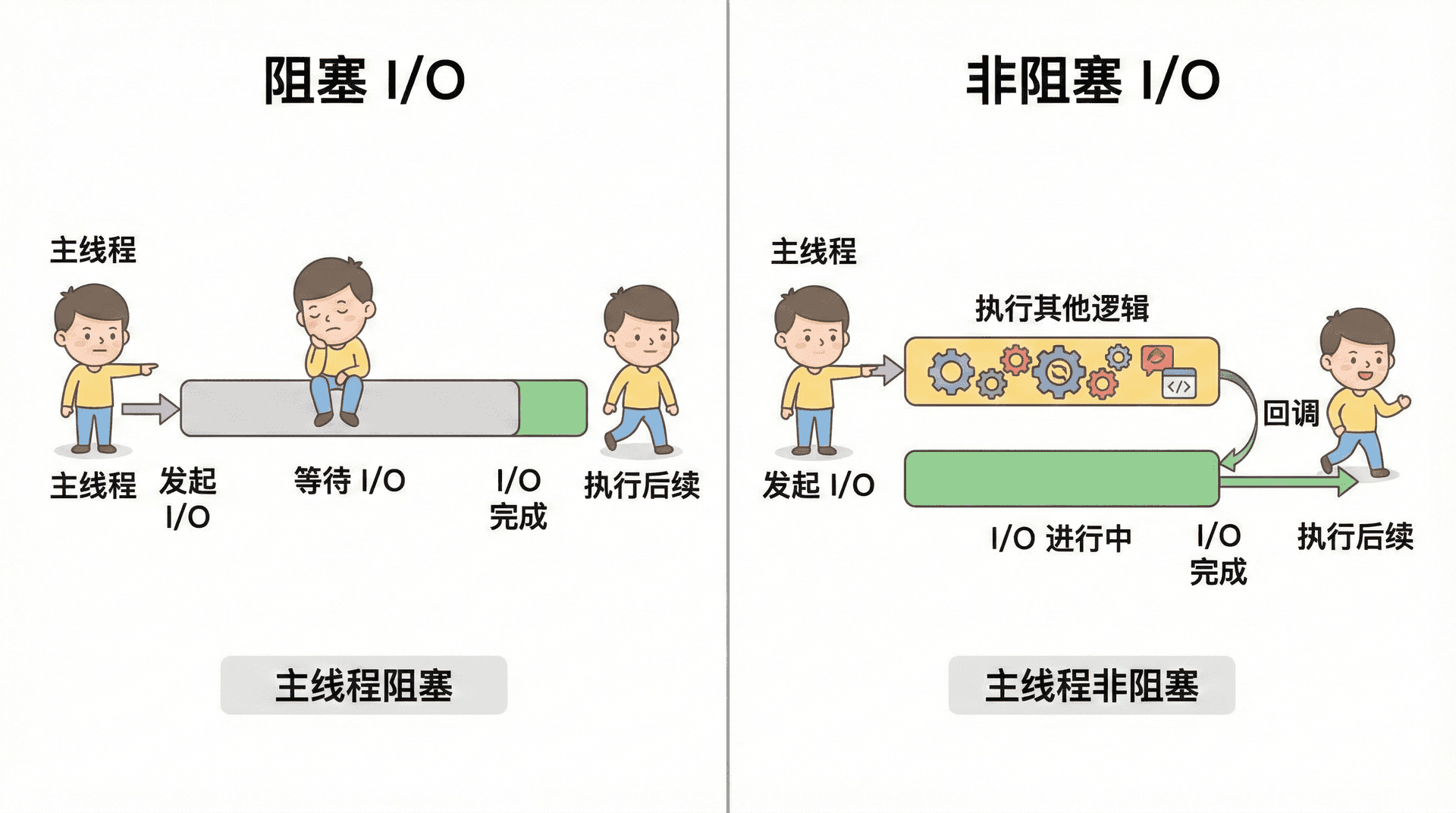
阻塞指:在调用发出后、结果返回前,当前线程一直停在这次调用上,不能执行别的代码。例如主线程调用 fs.readFileSync('data.txt'),会一直等文件读完才执行下一行,事件循环无法执行别的回调,所以 readFileSync 是阻塞的。
非阻塞指:调用发出后立即返回,当前线程不会停在这次调用上等结果,结果通过回调、事件或 Promise 在将来交付。例如 fs.readFile(path, callback) 很快返回,主线程继续执行后面的代码或事件循环里别的任务;等文件读完后,libuv 把 callback 放进队列,事件循环在某一轮执行它。非阻塞 I/O 与「事件驱动」「事件循环」是同一件事的两面:非阻塞保证主线程不会卡在 I/O 上,事件循环保证 I/O 完成后的回调在合适时机被执行。
在操作系统层面,许多 I/O 接口有阻塞/非阻塞两种模式;libuv 利用各平台的非阻塞接口(Linux 的 epoll、macOS 的 kqueue、Windows 的 IOCP),把「等待 I/O」从主线程挪到内核或线程池。
四象限:同步/异步 × 阻塞/非阻塞
四种组合:同步且阻塞(如 fs.readFileSync,主线程等完才返回);异步且非阻塞(如 fs.readFile(path, callback),调用立即返回,结果通过回调拿);同步且非阻塞、异步且阻塞在单次调用的语义下较少见。Node 里绝大部分 I/O API 是「异步且非阻塞」,应避免在请求路径上使用「同步且阻塞」的 API。
阻塞与非阻塞描述的是「等待结果时线程能不能干别的事」。Node 的异步 I/O API(如 fs.readFile + 回调)是非阻塞的;同步 API(如 fs.readFileSync)是阻塞的,应避免在请求处理路径上使用。
用代码感受阻塞与非阻塞
下面这段代码演示异步读文件(非阻塞):主线程在调用 fs.readFile 后立即执行后面的 console.log,不会等文件读完。
javascript
const fs = require('fs');
fs.readFile('package.json', 'utf8', (err, data) => {
if (err) throw err;
console.log('文件内容长度:', data.length);
});
console.log('readFile 已调用');运行后先看到「readFile 已调用」,再看到「文件内容长度: xxx」。若改成 readFileSync,则主线程会等文件读完才执行下一行,输出顺序会反过来。
Node.js 如何把 I/O 交给操作系统
从 JavaScript 到 libuv
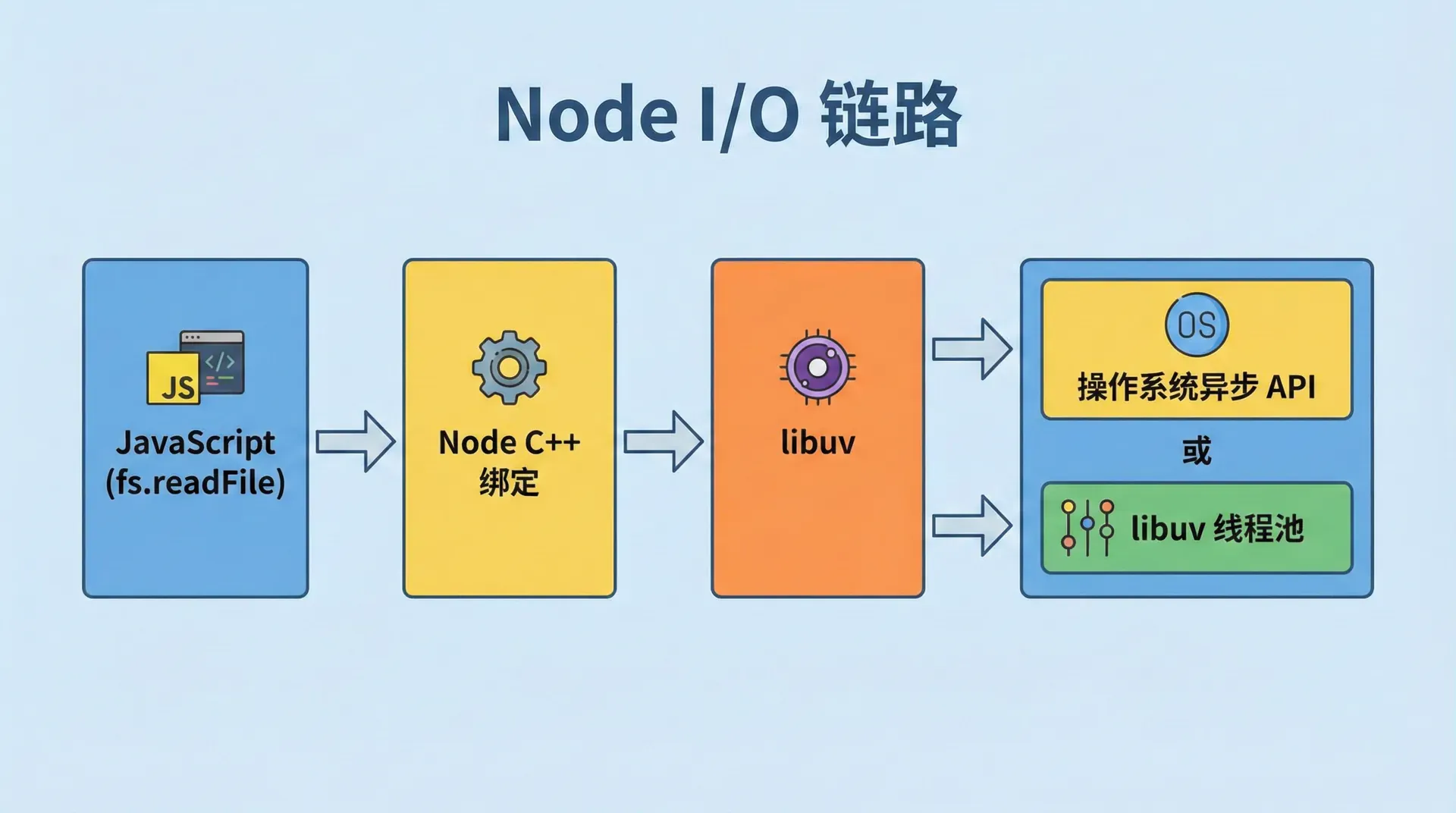
当我们在 Node 里调用 fs.readFile(path, callback) 时,这行 JavaScript 会经过:Node 的 fs 模块 → C++ 绑定 → libuv。libuv 是跨平台的异步 I/O 库,Node 用它在不同系统上统一抽象「提交 I/O 请求」和「I/O 完成后执行回调」。libuv 根据系统能力决定这次读文件是走「操作系统的异步接口」还是「线程池」:若系统有原生异步文件 API(如 Windows 的 Overlapped I/O),libuv 会直接用;若没有(如 Linux 上常见的 POSIX 文件 API 是同步的),libuv 会把读操作放进线程池,由工作线程执行同步读,读完后通过事件循环把回调交回主线程。
不同操作系统的异步 I/O 接口差异很大(Linux 的 epoll、macOS 的 kqueue、Windows 的 IOCP);libuv 把这些差异封装成统一的「提交请求 + 回调」模型,Node 只需和 libuv 打交道。网络 I/O 在多数系统上有原生异步接口,不占用线程池;文件 I/O 在部分系统上会走线程池,大量并发文件 I/O 时线程池可能成为瓶颈。
事件循环与 I/O 完成
libuv 提交 I/O 请求后,依赖操作系统的「就绪通知」机制,而不是主线程轮询。在 Linux 上 libuv 使用 epoll:把需要等待的 fd 注册到 epoll,主线程在 epoll_wait 上等待;当某个 fd 有数据可读或可写时,内核唤醒 epoll_wait,libuv 把对应回调放进队列,供事件循环在 poll 阶段执行。macOS 上类似的是 kqueue,Windows 上是 IOCP。
对于没有原生异步接口的操作(如 Linux 上的文件 read/write),libuv 会提交给线程池,工作线程完成后再通知 libuv,libuv 把回调放进事件循环队列。从主线程视角看,无论是走 epoll 的网络 I/O 还是走线程池的文件 I/O,都是一样的:发起请求后继续执行别的代码,等 I/O 完成后回调在事件循环的某一轮被调度执行。主线程始终不会在 I/O 上阻塞。
线程池与文件 I/O
libuv 默认维护一个线程池,大小约为 4(可通过环境变量 UV_THREADPOOL_SIZE 调整)。在 Linux 等系统上调用 fs.readFile 且底层走线程池时,libuv 从池中取空闲线程执行同步 read;若没有空闲线程,请求会排队。因此同时发起大量文件 I/O 时,完成时间可能拉长。网络 I/O 一般不占线程池;大多数 Web 场景的瓶颈在数据库或外部 API。若有大量并发文件 I/O,可考虑调大 UV_THREADPOOL_SIZE 或从架构上减少对同步文件 API 的依赖。
下面这段代码演示「连续发起多个 I/O、主线程不等待」:两次 readFile 调用后立即执行 console.log,两个回调在文件读完后分别被调用,顺序可能因文件大小和调度而不同。
javascript
const fs = require('fs');
fs.readFile('package.json', 'utf8', (err, data) => {
if (err) throw err;
console.log('第一个文件读完,长度:', data.length);
});
fs.readFile('README.md', 'utf8', (err,
运行后先看到「两次 readFile 都已调用」,再看到两个「第 x 个文件读完」的输出。
接下来
这部分我们区分了「同步与异步」和「阻塞与非阻塞」,并简述了 Node 的 I/O 链路:JavaScript → Node C++ 绑定 → libuv;libuv 把网络 I/O 交给 epoll/kqueue/IOCP,把部分文件 I/O 交给线程池;主线程不会在 I/O 上阻塞,回调由事件循环在 poll 阶段执行。
下一讲我们会进入「Node.js 模块系统与工程化」,学习 CommonJS 模块、require 的加载机制以及项目结构与模块拆分。