HTTP 在 Node.js 中的实现
在第八讲中我们区分了串行执行与并行执行,并讨论了如何用并发限制与限流思想在保证吞吐的同时保护系统。这些能力最终都要落在「真实服务」上:在 Node 里写 Web 服务、调下游接口、做批量任务,无一不需要与 HTTP 打交道。
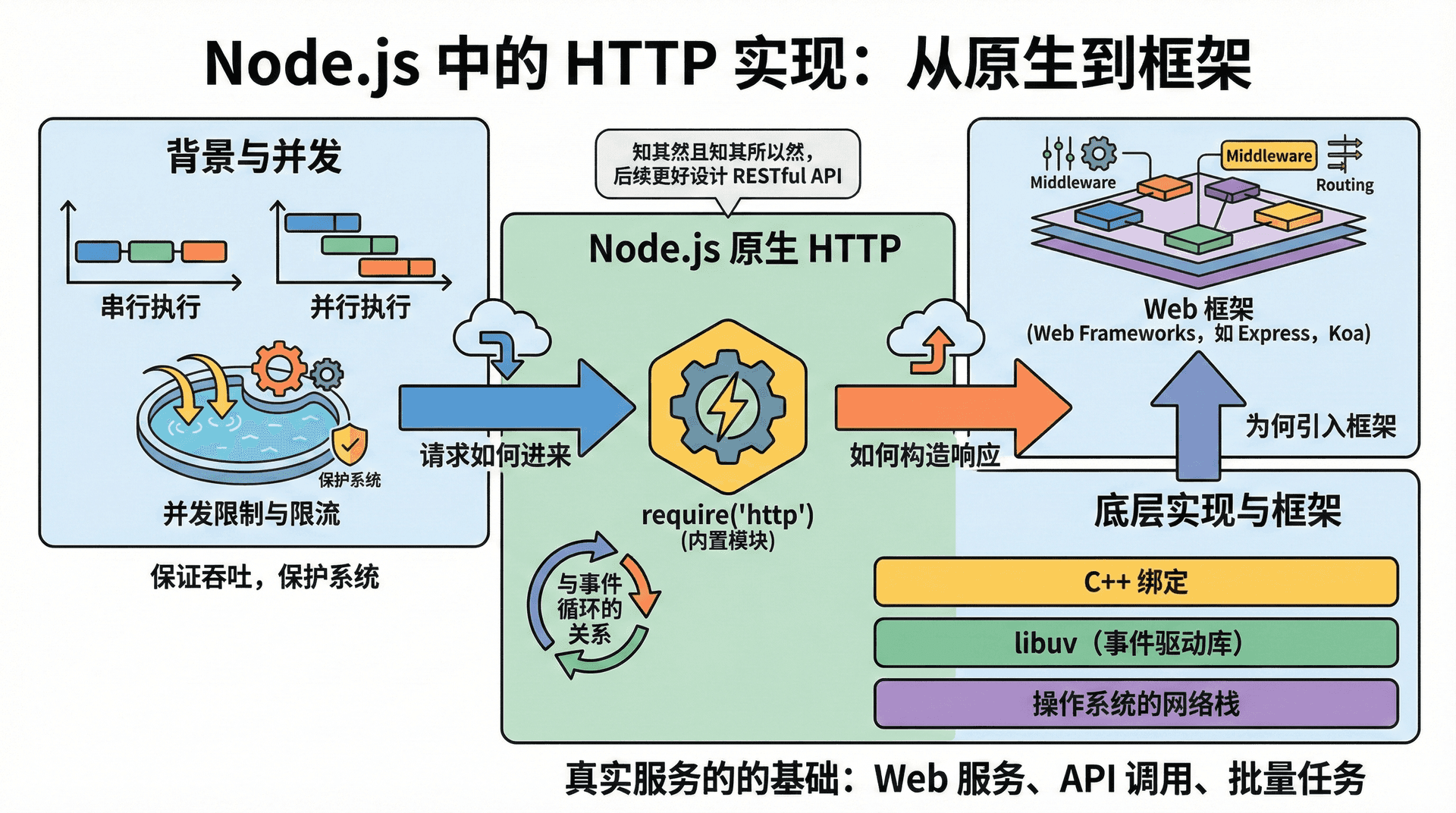
从这一讲开始,我们专门讨论HTTP 在 Node.js 中的实现:请求如何进来、如何构造响应、与事件循环的关系,以及为何在实际项目中我们往往会在原生能力之上再引入 Web 框架。
只有把原生 http 模块和请求与响应对象弄明白,后续在设计 RESTful API、使用中间件时,才能知其然且知其所以然。
在 Node 里写 Web 服务的第一步,就是理解原生 http 模块。它不依赖任何第三方包,随 Node 安装即可使用;我们通过 require('http') 拿到的是 Node 内置的 HTTP 服务能力,底层由 C++ 绑定和 libuv 与操作系统的网络栈协作完成。
原生 http 模块
createServer 与 listen
Node 的 http 模块提供了创建 HTTP 服务的能力。我们通过 http.createServer([options], requestListener) 创建一个 HTTP 服务器对象。其中 requestListener 是一个函数,签名为 (req, res) => { ... }:每当有 HTTP 请求被解析完成,Node 就会调用这个回调,并传入两个参数——req 代表「进来的请求」,res 代表「要写回的响应」。
从语义上看,createServer 注册的是「有 TCP 连接建立并且已经解析出一份 HTTP 请求」之后要执行的回调;因此,每收到一个完整的 HTTP 请求,就会触发一次该回调。
HTTP 是建立在 TCP 之上的应用层协议:客户端与服务器先建立 TCP 连接,再在连接上发送符合 HTTP 格式的文本(请求行、请求头、空行、可选的请求体),服务器解析后按同样格式写回响应。
Node 的 http 模块封装了「监听 TCP 端口」「按 HTTP/1.1 解析请求」「构造 req/res 对象」「在适当时机调度我们的回调」这一整条链路;我们不需要自己解析字节流或拼接请求行,只需在回调里使用已经解析好的 method、url、headers,并按需读取 body 流即可。
这种「协议解析由底层完成、业务只关心语义对象」的设计,与第四讲中「I/O 交给操作系统、我们只登记回调」的思路一脉相承。
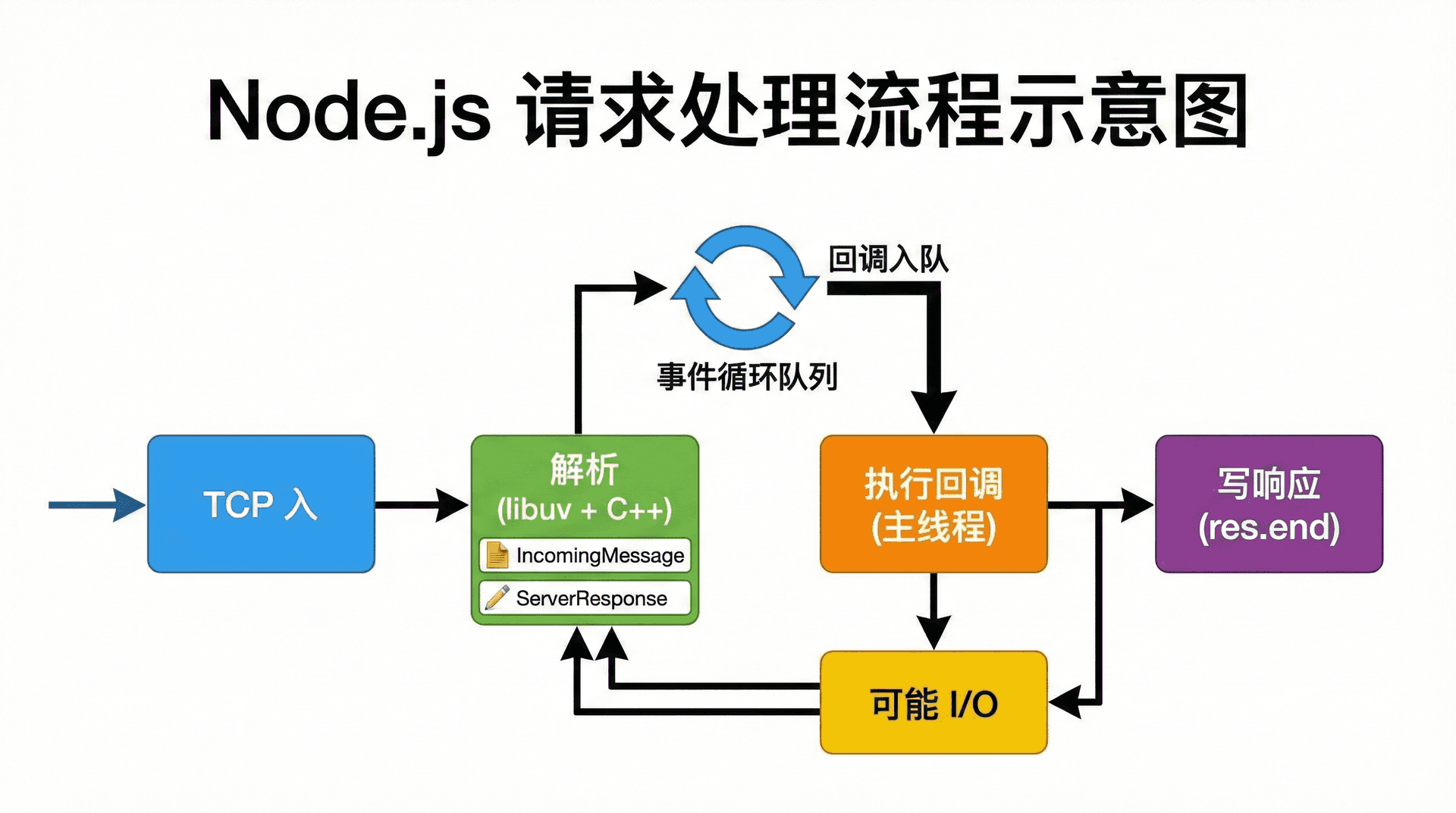
在底层,Node 会监听指定端口的 TCP 连接;当有连接建立时,由 C++ 层和 libuv 处理 TCP 字节流,按照 HTTP 协议解析出请求行、请求头,必要时还有请求体。解析完成后,会构造出 JavaScript 层的 req(IncomingMessage)和 res(ServerResponse)对象,并把这次请求的回调放入事件循环的任务队列。
因此,从我们写代码的视角看,每次「有请求进来」就对应一次 (req, res) => { ... } 的调用;从事件循环的视角看,这与第三讲里「I/O 完成 → 回调入队 → 主线程取出执行」完全一致,只是这里的「I/O」是网络上的 TCP 数据到达。
调用 server.listen(port[, host][, callback]) 会让服务器开始监听指定端口(以及可选的主机地址)。listen 本身是异步的:绑定端口、向操作系统注册监听,这些由 libuv 和系统调用完成,不会阻塞主线程。
若传入 callback,则会在服务器开始监听后被调用,常用于在控制台打印「Server running at ...」之类的信息。一旦 listen 成功,之后到达该端口的 HTTP 请求就会按上述流程触发 createServer 里注册的回调。
下面这段代码演示一个最简的 HTTP 服务:在 3000 端口监听,对任意请求都返回 200 和一段纯文本。与第一讲中的 Hello 示例一致,这里可以看到「require http → createServer → listen」的完整链路。
javascript
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain; charset=utf-8' });
res.end('Hello from Node.js\n');
});
server.listen(3000, () => {
console.log('Server running at http://localhost:3000/');
});若我们希望根据请求的路径或方法做不同处理,就要在回调里读取 req 的属性并分支。例如只对 GET / 返回欢迎页,对 GET /health 返回健康检查结果,其余返回 404。
这样写下去,路由逻辑会变成一连串 if/else 或 switch,在路径较多时难以维护;下一讲我们会讨论如何用「路由表」和 Controller 来组织这类逻辑,这里先建立「请求进来 → 读 req.method、req.url → 写 res」的直觉。
javascript
const http = require('http');
const server = http.createServer((req, res) => {
if (req.method === 'GET' && req.url === '/') {
res.writeHead(200, { 'Content-Type': 'text/plain; charset=utf-8' });
res.end('Welcome
从「一个请求从进来到 res.end 出去」的完整生命周期看,与第三讲事件循环、第四讲异步 I/O 的对应关系是:请求数据到达时由操作系统和 libuv 处理,解析完成后将「执行 (req, res) 回调」放入队列;主线程在某一轮循环中取出该回调并执行。
若回调里有异步操作(例如读文件、调数据库),则发起 I/O 后立即返回,等 I/O 完成后再通过新的回调写回响应。因此,用原生 http 写出的服务天然是非阻塞的,不会因为某个请求在等 I/O 而阻塞其他请求的处理。
若我们在回调里做的是纯 CPU 计算(例如复杂加密、大量 JSON 序列化),主线程会一直被占用,这段时间内其他请求的回调无法执行;因此,对于 CPU 密集型的请求,要考虑拆到子进程或 Worker 里,或限制并发(见第八讲)。
对于典型的 Web API(读库、调下游、读文件),I/O 等待时间远大于 CPU 时间,单线程 + 事件循环已经能支撑较高并发;只有在压测或实际流量下发现 CPU 成为瓶颈时,再考虑多进程或集群(第十五讲)。
本讲重点在「HTTP 在 Node 中的实现」,即请求如何进来、如何写出响应;性能与扩展性留待后续专题讨论。
与事件循环、单线程的关系
如前所述,HTTP 服务器的回调与事件循环的关系和第七讲、第八讲中的异步回调一致:每次请求对应一次回调的调度,回调执行期间若遇到 await 或 then 里的异步操作,主线程会去处理其他请求或定时器,等该异步操作完成后再回来继续。
因此,单线程下仍然可以并发处理大量 HTTP 请求,只要每个请求的回调里不长时间占用 CPU 或阻塞式等待 I/O。
与 listen 相关的一点是:listen 成功后,服务器会持续监听端口,直到调用 server.close() 或进程退出。close 同样是异步的,会等待已有连接处理完毕后再触发 close 事件。
在实际部署中,我们通常还会配合进程管理器(如 PM2)或集群模式(第十五讲会讨论 Cluster)来利用多核或做平滑重启,但就单进程单服务器而言,createServer + listen 已经足以支撑「请求进来 → 回调执行 → 响应写出」的完整链路。
Node 还提供 https 模块,用于创建 HTTPS 服务。用法与 http 类似:https.createServer(options, requestListener),其中 options 里需要传入证书和私钥(如 key、cert),以便在 TCP 之上建立 TLS 连接。建立连接后,应用层仍然是 HTTP 协议,因此 req 和 res 的用法与 http 模块一致。
在生产环境中,我们通常用 Nginx 或负载均衡器在边缘做 TLS 终结,把解密后的 HTTP 请求转发给 Node 进程,这样 Node 只需监听内网端口、使用 http 即可;若需要在 Node 内直接提供 HTTPS,则使用 https 模块并配置证书。本讲以 http 为主,https 的配置细节可在部署与运维相关课程中按需学习。
历史上,Node 刚出现时,很多开发者正是用原生 http 模块快速搭建简单的 API 或代理;随着项目规模增大,路由和横切逻辑越来越多,社区才逐渐抽象出 Express 等框架,把「路由表」「中间件」等模式固化下来。
理解原生 http,有助于我们明白「框架在包装什么」:当我们在 Express 里写 app.get('/users', handler) 时,底层仍然是 Node 在某个时刻调用了我们的 handler(req, res),只是 req 和 res 可能被框架包装过,增加了例如 req.params、res.json() 等便捷 API。下一节我们详细看 req 和 res 在原生层究竟长什么样,这样在使用框架时就能分清「哪些是 Node 自带的、哪些是框架扩展的」。
请求与响应对象
IncomingMessage:请求对象 req
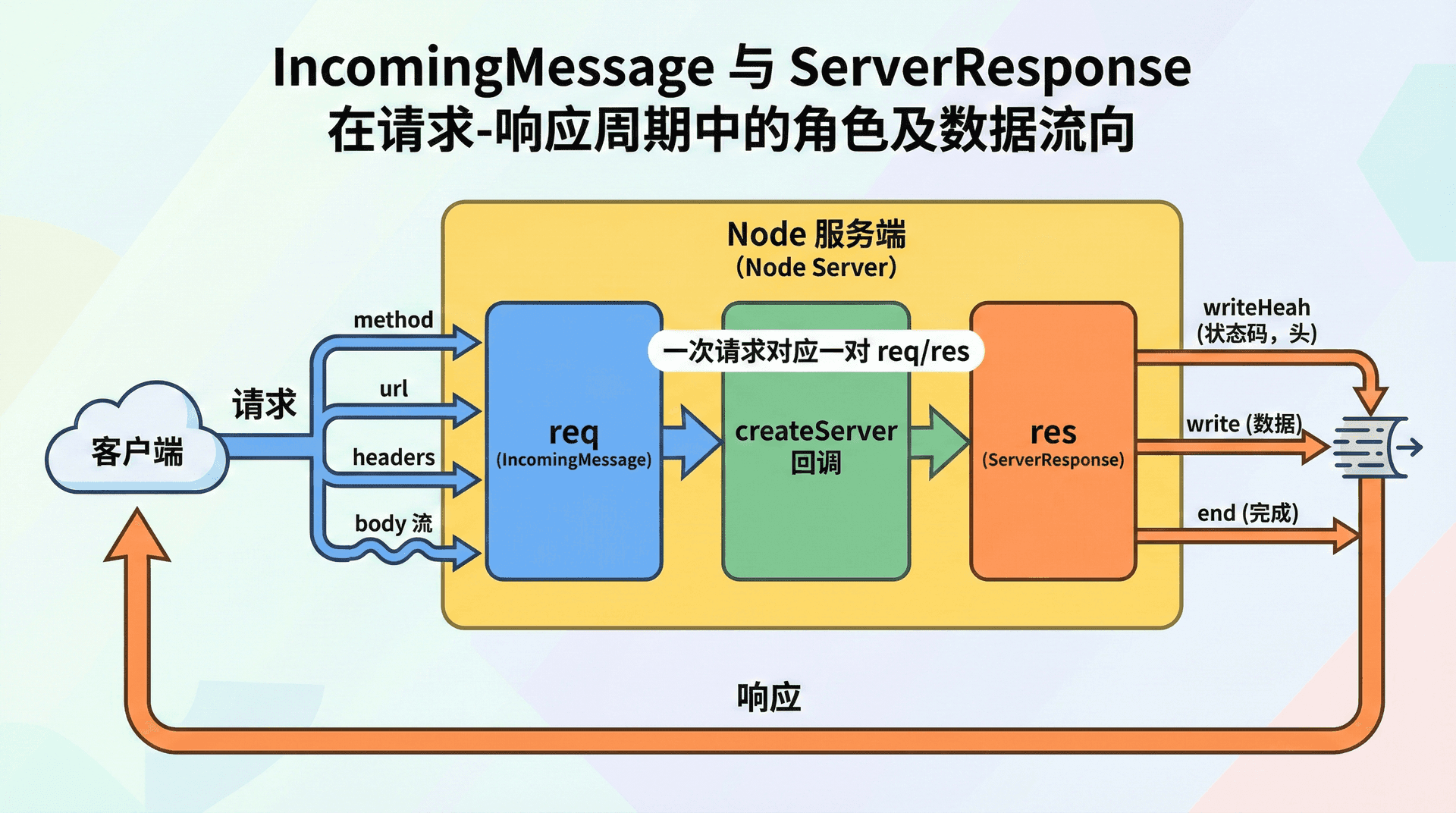
req 是 http.IncomingMessage 的实例,代表「当前这次 HTTP 请求」。它同时实现了可读流(Stream)接口,因此请求体(若有)可以通过流的方式读取。
在 Node 的文档里,IncomingMessage 既用于客户端收到的响应(如 http.request 返回的 res),也用于服务器收到的请求(即 createServer 回调里的 req);这里我们只讨论「服务器收到的请求」这一种用法,即 createServer 的 req 参数。
与「请求行」和「请求头」相关的常用属性有:req.method 表示 HTTP 方法(如 'GET'、'POST');req.url 表示请求的 URL 路径与查询字符串(如 '/api/users?page=1'),注意这里不包含协议和主机,只是 path + query;req.headers 是一个对象,键为请求头名称的小写形式,值为对应字符串(若同一头出现多次,值可能是用逗号拼接的字符串,具体以 Node 文档为准)。通过这三者,我们可以知道「谁在请求、请求什么、带了什么头」,从而在回调里做路由和鉴权。
请求体(body)不会自动解析到某个属性上,因为 body 可能很大(如上传文件),用流的方式按需读取更省内存。
当请求带有 body 时(如 POST、PUT),我们可以通过 req.on('data', chunk => { ... }) 和 req.on('end', () => { ... }) 来读取:每次收到一块数据会触发 data,全部收完后触发 end。若要把 body 拼成字符串再解析 JSON,可以在 data 里把 chunk 拼到缓冲区,在 end 里再 JSON.parse(buffer)。
注意:若不在回调里消费 req 的流,Node 会缓冲数据,但若我们既不读也不销毁流,可能影响连接复用或背压;在只关心 method/url/headers 而不要 body 的场景,可以调用 req.resume() 把数据「排空」,让底层知道我们不消费 body。
与连接相关的还有 req.socket(底层 TCP socket)、req.httpVersion(如 '1.1')等,在需要做更底层控制或调试时会用到。对大多数 Web API 而言,method、url、headers 以及按需读取的 body 已经足够。
有时我们需要从 req.url 里拆出「路径」和「查询字符串」。Node 内置的 url 模块提供了 new URL(req.url, 'http://localhost') 或旧版 require('url').parse(req.url) 的用法,可以拿到 pathname、search、searchParams 等;在原生 http 里我们通常自己解析或引入 url 模块,而框架一般会把这些挂到 req 上(如 req.path、req.query)。
鉴权时常用 req.headers.authorization 读取 Bearer token 或 Basic 认证信息;若请求来自代理,可能还要看 req.headers['x-forwarded-for'] 等。这些细节在后续讲安全与认证时会再展开,这里先建立「请求信息都在 req 上、按需读取」的印象。
ServerResponse:响应对象 res
res 是 http.ServerResponse 的实例,代表「要发回给客户端的响应」。我们通过它设置状态码、响应头,并写入响应体。ServerResponse 继承自可写流(Writable Stream),因此 res.write 和 res.end 在底层就是向流里写数据;写完后由 Node 和操作系统负责把数据发到 TCP 连接上。
从调用方的视角看,我们只需按顺序调用 writeHead、write(可选)、end,不必关心底层如何分片、如何拥塞控制。
设置状态码和响应头可以用 res.writeHead(statusCode[, statusMessage][, headers]),其中 headers 是一个对象,键为头名称,值为字符串或字符串数组。例如 res.writeHead(200, { 'Content-Type': 'application/json' }) 表示 200 OK 且返回 JSON。在调用 writeHead 之后,就不能再修改状态码和已发送的头;若在 writeHead 之前调用了 res.write() 或 res.end(),Node 会先发送一个默认的 200 和头,再发送我们写的内容,因此一般建议先 writeHead 再写 body。
写响应体可以用 res.write(chunk[, encoding][, callback]) 和 res.end([data][, encoding][, callback])。write 可以多次调用,每次追加一块数据;end 表示「写完并结束本次响应」。若只返回一段固定内容,通常直接 res.end(data) 即可,end 会隐式发送并关闭响应。一旦调用了 end,就不能再对本次响应调用 write 或 end,否则会报错。
因此,在回调的每条分支里,都要保证「要么调 res.end,要么在异步完成后再调 res.end」,否则客户端会一直等待,连接也会占用不释放。这与「为什么要在业务里显式 end」直接相关:Node 不会替我们决定「响应已经写完了」,只有我们调用了 end,底层才会关闭响应流并可能复用连接(在 HTTP/1.1 keep-alive 下)。
若我们不调用 end,客户端会一直等待响应完成,服务器端也会保留该连接和对应的资源;若在异步回调(如读文件、查数据库)里忘记调用 end,就会造成请求「挂住」和连接泄漏。因此,在写原生 http 服务时,要养成「每条路径最终都 res.end」的习惯,或在顶层用 try/catch 和错误分支统一调用一次 end(例如 500 错误时 res.end(JSON.stringify({ error: '...' })))。
状态码和 Content-Type 的选择会直接影响客户端如何解析响应。例如返回 JSON 时通常设 Content-Type: application/json 和 200;资源不存在时返回 404;参数错误时返回 400;服务器内部错误时返回 500。若我们返回 HTML 或纯文本,也要相应设置 Content-Type 和 charset,避免客户端按错误编码解析。
writeHead 只能调用一次,之后不能再改状态码和已发送的头;若需要根据异步结果再决定状态码,就要在异步回调里调用 writeHead 和 end,而不能在回调外先 writeHead 再在回调里 end(否则可能已经发过 200 了)。这些约定在框架里往往被封装成 res.status(404).json({ error: '...' }) 之类的 API,但底层仍然是「先写头、再写体、最后 end」。
下面这段代码演示如何读取 POST 请求的 body 并写回 JSON:在 end 里拼好 buffer 后解析 JSON,再根据解析结果写回不同状态码和 body;若解析失败则返回 400。注意这里用了 req.on('data') 和 req.on('end'),且每条分支都调用了 res.end。
javascript
const http = require('http');
const server = http.createServer((req, res) => {
if (req.method !== 'POST' || req.url !== '/echo') {
res.writeHead(404);
res.end();
return;
}
const
流、keep-alive 与连接复用
req 是可读流、res 是可写流,这与第四讲中「Node 用流处理 I/O」的设计一致:数据一块一块地来、一块一块地写,不必一次性把整个 body 读进内存。对于大文件上传或大响应,流式处理能显著降低内存占用。
在 HTTP/1.1 下,默认支持 keep-alive:同一 TCP 连接上可以连续发送多个请求、接收多个响应,而不必每次请求都新建连接。
Node 的 http 服务器在发送完响应(res.end)后,若客户端没有关闭连接,该连接会保留在池中,供下一次请求复用。因此,从「连接」的视角看,一次 TCP 连接可能对应多对 (req, res);每一对对应一次 HTTP 请求-响应。res 的 close 事件在底层连接关闭时触发,可用于统计或清理;若我们总是正确调用 res.end,且客户端也按协议关闭或复用连接,就不会出现连接泄漏。
与可读流、可写流相关的还有「背压」问题:若客户端接收很慢,而我们不断 res.write,数据会在内核缓冲区堆积,最终可能占满内存。Node 的流接口提供了 res.write(chunk, callback),callback 会在 chunk 被写入底层缓冲区(或发送出去)后被调用;若我们根据 callback 的节奏来写下一块,就能实现背压传递,避免写端过快。
对于小响应或一次性 res.end(data),通常不必关心;对于大文件或流式响应,就要注意监听 drain 事件或 write 的 callback,与第四讲中流的用法一致。本节重点在「请求与响应对象」的职责与常用 API,流式响应的细节可在实际项目中按需深入。
Web 框架存在的意义
只用原生 http 时的痛点
在理解了 createServer、req 和 res 之后,我们已经可以用原生 http 写出完整的 Web 服务。但当路径增多、需要解析 JSON body、需要统一错误处理和状态码、需要静态资源或模板时,纯手写 if/else 和 req.on('data') 会变得冗长且易错。
路由方面,若每个路径都写一层 if (req.method === 'GET' && req.url === '/...'),代码会迅速膨胀;而且 url 可能带查询字符串,需要自己用 require('url').parse(req.url) 或正则来解析 pathname 和 query。
请求体方面,每次 POST 都要手写「收集 chunk → 拼 buffer → JSON.parse」,并处理异常和超时;若还要支持表单、文件上传,就更复杂。
响应方面,每次都要记得 writeHead、Content-Type、res.end,稍有遗漏就会挂住或返回错误格式。
错误处理方面,若回调里抛出异常,默认会导致未捕获异常,进程可能退出;若用 try/catch 包住,又要决定如何把错误转换成 500 和统一格式的 JSON。这些重复劳动和细节,正是 Web 框架要解决的问题。
与此相关的是「代码组织」:当路由和业务逻辑混在一个 createServer 回调里时,很难按功能拆成多个文件;若把「解析 path」「解析 query」「解析 body」「查库」「写响应」都堆在一起,可读性和可测试性都会下降。
框架通过「路由表 + Controller」把「匹配路径」和「处理逻辑」分开,通过「中间件」把「解析 body」「鉴权」「日志」等横切逻辑抽离,这样每个 handler 只关心「拿到 req 里已经解析好的数据、返回 res」,代码结构更清晰。第十三讲会讨论错误处理与服务健壮性,届时会再涉及「未捕获异常」「异步错误如何统一转成 500」等;这里先建立「框架能减少重复、改善结构」的印象。
框架提供了什么
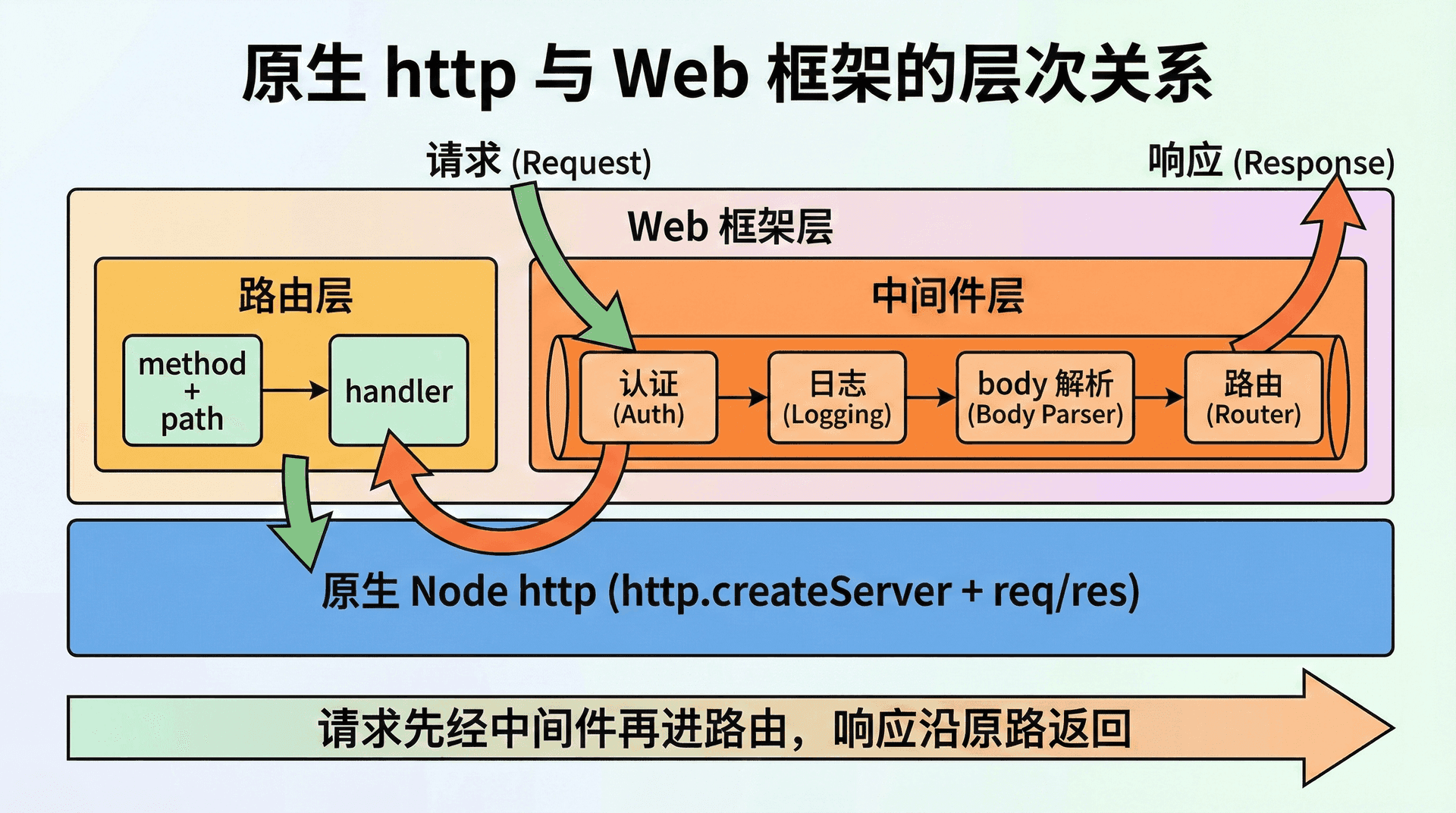
Express、Koa、Fastify 等 Web 框架,在底层仍然使用 Node 的 http(或 https)模块:它们自己调用 createServer,把收到的 req/res 包装后,交给「路由」和「中间件」管道处理。因此,框架并没有替换掉 Node 的 HTTP 能力,而是在其之上增加了一层约定和工具。
路由方面,框架通常提供「路由表」:把 method + path 映射到处理函数(或 Controller 方法),这样我们只需写「GET /users 对应 getUsers」「POST /users 对应 createUser」,而不必在 createServer 的回调里写一大串 if/else。有的框架还支持路径参数(如 /users/:id)、查询解析、请求体解析(JSON、form、multipart)等,开箱即用。
中间件方面,框架会把多个「中间件」串成一条管道:请求依次经过认证、日志、body 解析、路由等,每个中间件可以修改 req/res、调用 next() 把控制权交给下一个、或直接结束响应。这样,我们可以把「解析 body」「统一错误处理」「记录访问日志」等横切逻辑拆成独立中间件,与业务路由解耦。第十一讲会专门讨论中间件模式和洋葱模型,这里先建立「框架 = 原生 http + 路由 + 中间件 + 生态」的印象。
生态方面,围绕 Express 或 Koa 有大量现成的中间件:静态文件服务、会话、认证、限流、请求日志等。使用框架后,很多能力只需引入对应包并挂到管道上即可,不必从零用原生 http 实现。同时,框架的文档和社区也能降低「如何组织路由、如何统一错误格式」等工程问题的成本。
Express 诞生于 2010 年前后,最初的目标就是「在原生 http 之上提供路由和中间件」,让开发者用 app.get、app.post、app.use 等 API 组织代码,而不必手写 if/else。Koa 由 Express 原班人马打造,采用更轻量的「洋葱模型」中间件和 async/await 友好设计,把很多能力留给上层中间件(如 koa-router、koa-bodyparser)实现。Fastify 则强调性能和类型安全,底层仍基于 Node 的 http。
无论选哪种,底层都是「createServer + req/res」;理解原生层,能帮助我们在框架出问题时(例如「为什么这个请求没进我的 handler」「为什么 res 已经 end 了还报错」)快速定位到是路由没匹配、中间件顺序不对,还是原生 res 被重复调用了。
何时用原生、何时用框架
对于学习和小型脚本(如内网工具、健康检查端点),直接用原生 http 即可,依赖少、行为透明。对于对外提供 API 或页面的正式服务,使用 Express、Koa 等框架能显著提高开发效率和可维护性,同时底层仍然是 Node 的 HTTP 与事件循环,前面几讲里学的异步、并发限制等依然适用。理解原生 http,有助于我们在用框架时知道「req/res 从哪来、中间件在什么时候被调用」,从而写出更可靠、更易调试的代码。
Web 框架是在原生 http 之上的一层约定与工具,不改变底层仍是 createServer + req/res。理解原生请求与响应对象,能帮助我们在使用框架时更好地排查问题和设计中间件。
接下来
这部分我们介绍了 HTTP 在 Node.js 中的实现:通过原生 http 模块的 createServer 与 listen,可以监听端口并针对每个请求执行回调;回调收到的 req(IncomingMessage)和 res(ServerResponse)分别表示请求与响应。
我们可以通过 method、url、headers 和可读流读取请求信息,通过 writeHead、write、end 写出响应,并注意在每条路径上正确调用 end 以避免连接挂住。
在此基础上,我们说明了 Web 框架存在的意义:在原生 http 之上提供路由表、中间件管道和生态,减少手写 if/else、body 解析和错误处理的重复劳动,同时底层仍基于 Node 的 HTTP 与事件循环。
有了对原生 http 和 req/res 的理解,下一部分我们将讨论如何设计 RESTful API、如何划分路由与 Controller 的职责,以及请求与响应的模型设计。