RESTful API 的设计与实现
在第九讲中我们介绍了 Node 原生 http 模块的 createServer、请求与响应对象,以及 Web 框架在路由表与中间件之上所解决的那些重复劳动。有了「请求如何进来、如何写出响应」的直觉之后,下一步就是在真正引入框架的中间件管道之前,先把API 本身该怎么设计想清楚:路由如何组织、谁负责处理业务、请求与响应又该遵循怎样的约定。
这部分我们专门讨论 RESTful API 的设计与实现。我们会从「路由设计原则」入手,说明如何用 URL 与 HTTP 方法表达资源与操作;接着界定 Controller 的职责,即它该做什么、不该做什么,以及它与路由层、服务层之间的边界;最后讨论请求与响应模型的设计,包括如何校验入参、如何统一成功与错误的响应格式,以及如何与 HTTP 状态码配合。
路由设计原则
从 if/else 到「资源 + 动词」
在前面我们见过用原生 http 时,根据 req.method 和 req.url 写一连串 if/else 来分发请求的写法。那种写法在路径少时还能接受,一旦接口增多就会难以维护;而且「该用 GET 还是 POST」「路径该写成 /getUser 还是 /users/:id」这类问题没有统一答案,团队协作时容易各写各的。REST 风格的价值,就在于用一套约定把「资源」和「操作」分开表达,让 API 的形态可预期、可复用。
REST(Representational State Transfer)把 Web 上的东西抽象成资源:用户、订单、文章都是资源,每个资源有一个或多个表述(例如 JSON)。对资源的操作不再用 URL 里的动词表达,而是用 HTTP 方法表达:GET 表示获取、POST 表示创建、PUT 或 PATCH 表示更新、DELETE 表示删除。
这样一来,同一个资源路径可以对应多种操作,只是 method 不同;客户端和网关可以根据 method 做缓存、重试、幂等性判断,而不会因为「动词藏在 path 里」而无法统一处理。
例如「用户」这个资源,路径里只有名词和标识符,动词全部由 HTTP 方法承担。可约定如下:
这种设计在 Node 里无论是用原生 http 手写分支,还是用 Express 的 app.get('/users/:id', ...),语义都是一致的;后续加鉴权、限流、日志时,也可以按「资源 + 方法」来配置策略,而不必为每个古怪的 path 单独写规则。
与此相关的是路径层级与资源关系。当资源之间存在从属关系时,用路径层级表达往往比平铺更清晰。例如「某用户的订单」可以写成 GET /users/:userId/orders,表示「在 users 下的某个 user 的 orders 集合」;「某订单下的明细」可以写成 GET /orders/:orderId/items。这样读 URL 就能看出资源之间的包含关系,也便于做权限控制(例如只允许访问当前用户的 orders)。
层级不宜过深,否则 URL 会变得冗长,一般两到三层即可;若关系更复杂,可以用查询参数或单独的资源路径配合关联 ID 来表达。
URL 与查询参数的分工
路径(path)用来标识「是哪个资源或哪一类资源」,查询参数(query)则用来表达过滤、排序、分页等附加维度。例如 GET /users 表示用户列表;若只要状态为活跃的、按创建时间倒序、第二页、每页 20 条,可写成:
http
GET /users?status=active&sort=-createdAt&page=2&limit=20路径保持不变,不同的 query 得到不同的结果;这样既符合「同一资源、多种视图」的语义,又便于客户端和 CDN 做缓存(通常 path 相同、query 不同的请求可以有不同的缓存策略)。
在 Node 里,无论是原生 require('url').parse(req.url) 还是框架提供的 req.query,我们拿到的都是已经解析好的查询对象。路由设计时只需约定好 query 的命名(如 page、limit、sort、filter 的格式),并在 Controller 或中间件里做校验与默认值即可。
不要把「操作类型」放在 query 里(例如用 ?action=delete 配合 GET),那样会破坏「method 即动词」的约定,也不利于缓存与安全;删除就该用 DELETE /users/:id。
路径参数(如 /users/:id 里的 id)表示「资源在集合中的具体哪一个」。设计时要注意:id 应该是稳定的、不常变的标识符,通常对应数据库主键或业务上的唯一键。若用「名称」或「日期」等会变的字段做路径参数,将来重命名或时区变更都会导致 URL 失效,不利于长期维护。404 表示「没有这个资源」,405 表示「该资源存在但当前 method 不允许」;在实现时,先根据 path 和 param 查资源是否存在,再根据 method 判断是否允许该操作,可以给客户端更明确的反馈。
API 版本与一致性
当 API 需要向前兼容地演进时,版本策略会直接影响路由形态。常见做法有两种:在路径里带版本(如 /v1/users、/v2/users)或在请求头里带版本(如 Accept: application/vnd.myapi.v1+json)。路径版本实现简单、易于在网关层按 path 做分流,但 URL 会变长;头版本保持 URL 稳定,但需要中间件或网关解析头并转发到对应实现。无论选哪种,都要在整个项目里统一,避免一部分接口用 path、另一部分用 header,导致客户端难以抽象。
与版本相关的是命名与格式的一致性。资源名用复数还是单数(/users 还是 /user)、字段用 camelCase 还是 snake_case、日期用 ISO 8601 还是时间戳,这些一旦在首版里确定,后续再改就会破坏已有客户端。因此路由设计阶段就要和前端或调用方约定好:路径用复数名词、路径参数用单数含义(/users/:id 表示「其中一个 user」)、JSON 字段风格与日期格式统一。这样在写 Controller 和响应模型时就有据可依,减少返工。
有了路由表,每个路由会落到具体的 handler;这些 handler 的职责该如何划分?下一节讨论 Controller。下面用 Express 风格的路由表把「资源 + 方法」对应关系写出来(下一节会接到 Controller)。
javascript
// 路由表:method + path -> handler(后续会接到 Controller)
app.get('/users', getUsers); // 列表,可带 ?page=&limit=
app.get('/users/:id', getUserById); // 单个
app.post('/users', createUser);
app.patch('/users/:id', updateUser);
app.delete('/users/:id', deleteUser);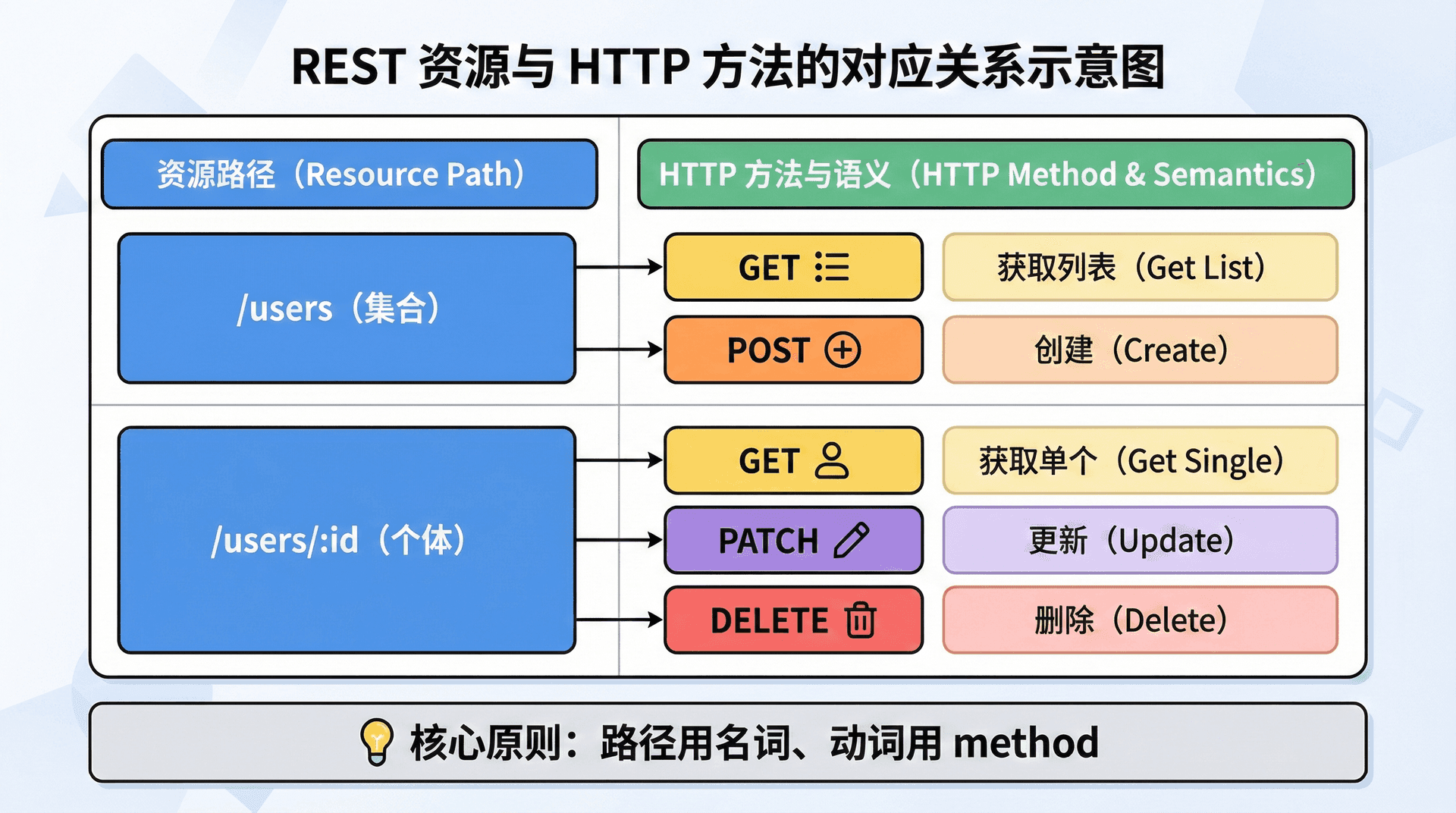
Controller 的职责
只做「入参 → 调服务 → 选状态码与响应」
在有了清晰的路由表之后,每个路由会对应一个或多个 handler,这些 handler 在分层架构里通常被称作 Controller。Controller 的职责应当尽量「薄」:它只负责从请求里拿到已经解析好的参数(路径参数、查询参数、请求体),调用一层服务或模型完成业务逻辑,再根据返回结果决定用哪个 HTTP 状态码、写回怎样的响应体。它不应当直接写 SQL、不应当包含复杂的业务算法、也不应当关心「body 是怎么从流里解析出来的」或「鉴权是怎么做的」——那些属于中间件或更底层的模块。
这样划分的好处是:业务逻辑集中在服务层,可以单独做单元测试或复用到非 HTTP 场景(如定时任务、消息队列消费);Controller 只做「适配 HTTP」的薄薄一层,测试时只需 mock 服务层,看「给定入参是否调用了正确的服务、是否返回了正确的状态码和 body」。若 Controller 里塞满了查库、算价、发通知的代码,就会难以测试、难以复用,也会和下一讲要讲的「中间件」职责重叠——例如鉴权本该在进入 Controller 之前就完成,若写在 Controller 里,每个 handler 都要重复一段「先看 token 再干活」的逻辑。
与此相关的是与路由层、服务层的边界。路由层只做「method + path 匹配到哪个 Controller 方法」,必要时做路径参数与 query 的解析并挂到 req.params、req.query;若使用框架,还会经过「解析 body」「鉴权」「日志」等中间件,Controller 拿到的 req 已经是「干净」的入参。服务层则接收 Controller 传下来的参数(通常是普通对象或 DTO),返回业务结果或抛出领域异常;Controller 根据是「正常结果」还是「未找到」「参数错误」等异常,映射到 200、201、400、404、500 等状态码和统一格式的响应体。
这样,路由、Controller、服务各司其职,后续加缓存、限流、审计时也容易在对应层插入。
单一职责与可测试性
Controller 方法应当「一个方法只对应一个接口」:例如 getUserById 只处理 GET /users/:id,入参就是 req.params.id(以及可选的 req.query),返回就是「查到的用户或 404」。不要在同一个方法里根据 query 或 body 再分支成多种业务,那样会难以命名、难以测试;若确实有多种行为,应拆成不同路由或不同 Controller 方法。
可测试性方面,因为 Controller 只做「调服务 + 写 res」,我们可以用 Node 里常见的「伪造 req/res」的方式做集成测试:构造一个带 params、query、body 的 req 对象和一个能记录 statusCode、setHeader、end 调用的 res 对象,调用 Controller 方法后断言「某服务被以某参数调用了一次」「res 的 statusCode 为 200、end 被传入的 JSON 符合某结构」。若业务逻辑都在服务层,服务层可以用纯函数或类方法做单元测试,不依赖 HTTP;两者结合,就能在少写端到端测试的情况下,仍然保证接口行为正确。
示例:薄 Controller——从 req 取 id,调服务,按结果写状态码与 body(统一响应格式在下一节)。
javascript
async function getUserById(req, res) {
const { id } = req.params;
const user = await userService.getById(id);
if (!user) {
res.status(404).json({ code: 'NOT_FOUND', message: '用户不存在' });
return;
}
res.status
Controller 只负责「入参 → 调服务 → 选状态码与响应体」。业务逻辑放在服务层,鉴权与 body 解析放在中间件,这样每一层职责清晰,也便于测试与复用。
除了职责划分,接口是否好用还取决于入参与出参的约定;下面看请求体校验与响应格式。
请求与响应模型设计
请求体校验与约定
请求一旦经过「body 解析」中间件(例如 express.json()),Controller 拿到的 req.body 通常已经是一个 JavaScript 对象。但客户端传来的数据未必符合预期:可能缺少必填字段、类型错误、或超出业务允许范围。若不做校验就直接传给服务层,轻则得到难以理解的业务错误,重则导致脏数据或安全问题。因此需要在进入核心逻辑之前,对请求体做校验,并形成一层明确的「请求模型」或 DTO(Data Transfer Object)约定。
校验可以放在 Controller 开头,也可以放在单独的「校验中间件」里:例如针对 POST /users 的 body,校验必填的 name、email 以及格式(邮箱正则、长度限制等),不通过则直接返回 400 和明确的错误信息(如「name 不能为空」「email 格式无效」),不调用服务层。这样服务层可以假设「能进来的参数都是合法的」,减少防御性判断。
校验逻辑若用 schema 库(如 Joi、Zod、express-validator)描述,还能自动生成文档或类型,与 TypeScript 配合时也能得到更好的类型推断。
与请求模型相关的是类型与格式的约定。例如日期用 ISO 8601 字符串还是时间戳、数字用整数还是允许浮点、字符串是否允许前后空格,这些若在团队内不统一,不同接口可能行为不一致。在 Node 里没有编译期的类型约束,所以通过 schema 校验和文档明确约定就显得尤为重要;一旦约定好,请求体的结构就可以视为「契约」,前端与后端可以并行开发,只需在联调时确认格式一致。
统一响应结构:成功与错误
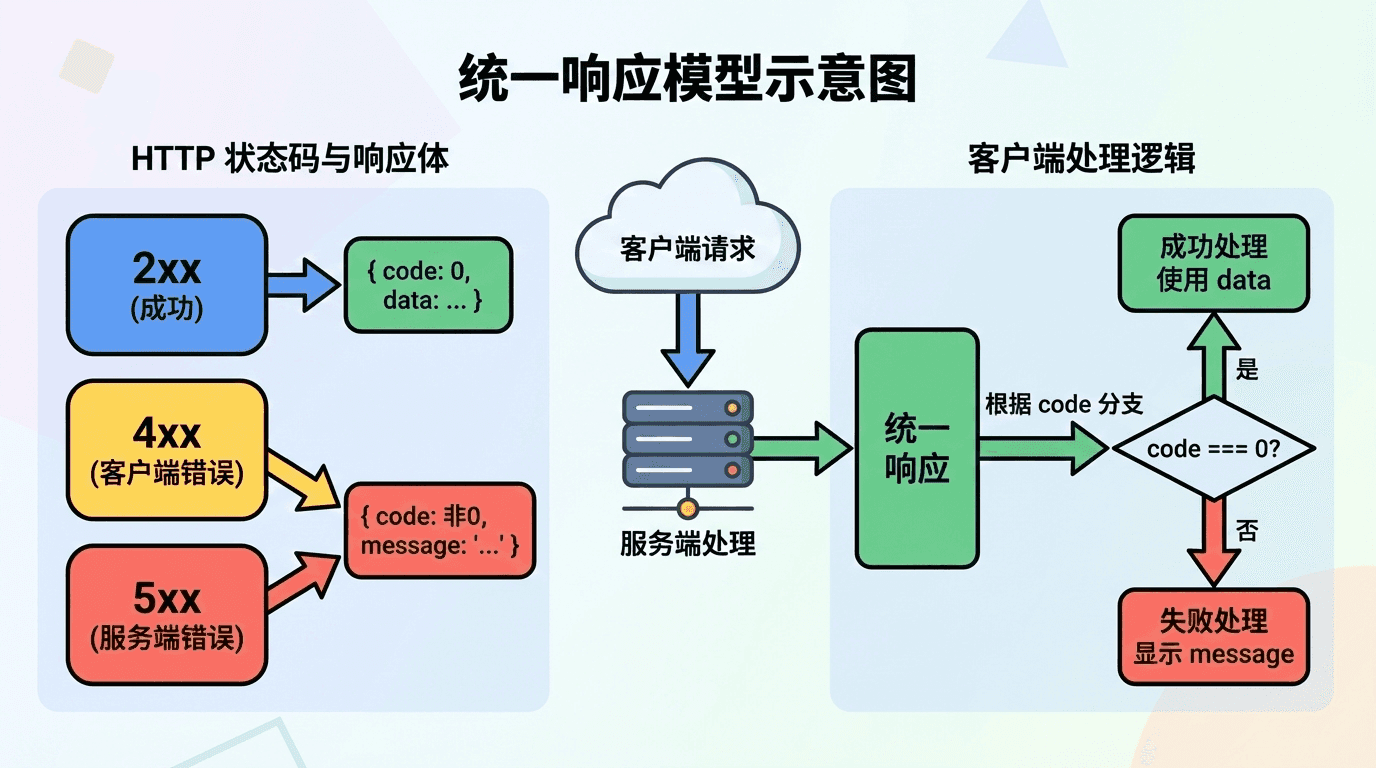
客户端处理响应时,若每个接口的 body 结构都不一样(有的直接是数组、有的是 { list, total }、有的错误时是 { err: string } 有的又是 { message: string }),就会难以抽象成统一的请求封装和错误处理。因此常见做法是约定一个统一的响应外壳(envelope):例如成功时返回 { code: 0, data: ... },失败时返回 { code: 非0, message: '...' } 或再带 errors 数组。这样客户端可以统一判断 response.code === 0 再取 data,否则走错误分支并展示 message。
HTTP 状态码与 body 里的 code 可以配合使用:2xx 表示请求被成功处理,body 里 code 为 0 表示业务成功、data 为实际数据;4xx 表示客户端错误,body 里 code 可对应具体错误类型(如参数错误、未授权、资源不存在),message 给人看;5xx 表示服务端错误,body 里同样用 code + message,但生产环境中 message 往往不暴露内部细节,只给通用提示。
这样既保留了 HTTP 的语义(缓存、重试、网关可根据状态码做策略),又让业务错误有统一的表达方式。
错误响应的格式一旦统一,就可以在「错误处理中间件」里集中完成:Controller 或服务层抛出带类型的异常(如 NotFoundError、ValidationError),中间件捕获后根据类型映射到对应状态码和 body 结构,无需在每个 Controller 里写 if (err) res.status(500).json(...)。第十三讲会专门讨论错误处理与服务健壮性;这里先建立「统一响应模型 + 集中错误映射」的印象。
示例:成功与错误时的 JSON 结构(实际可封装为 res.success / res.fail 或由错误中间件统一写)。
javascript
// 成功
res.status(200).json({ code: 0, data: { id: 1, name: 'Alice' } });
// 业务错误:资源不存在
res.status(404).json({ code: 'NOT_FOUND', message: '用户不存在' });
// 参数错误
res.status(400).json({ code: 'INVALID_INPUT', message: 'email 格式无效', errors: [...] });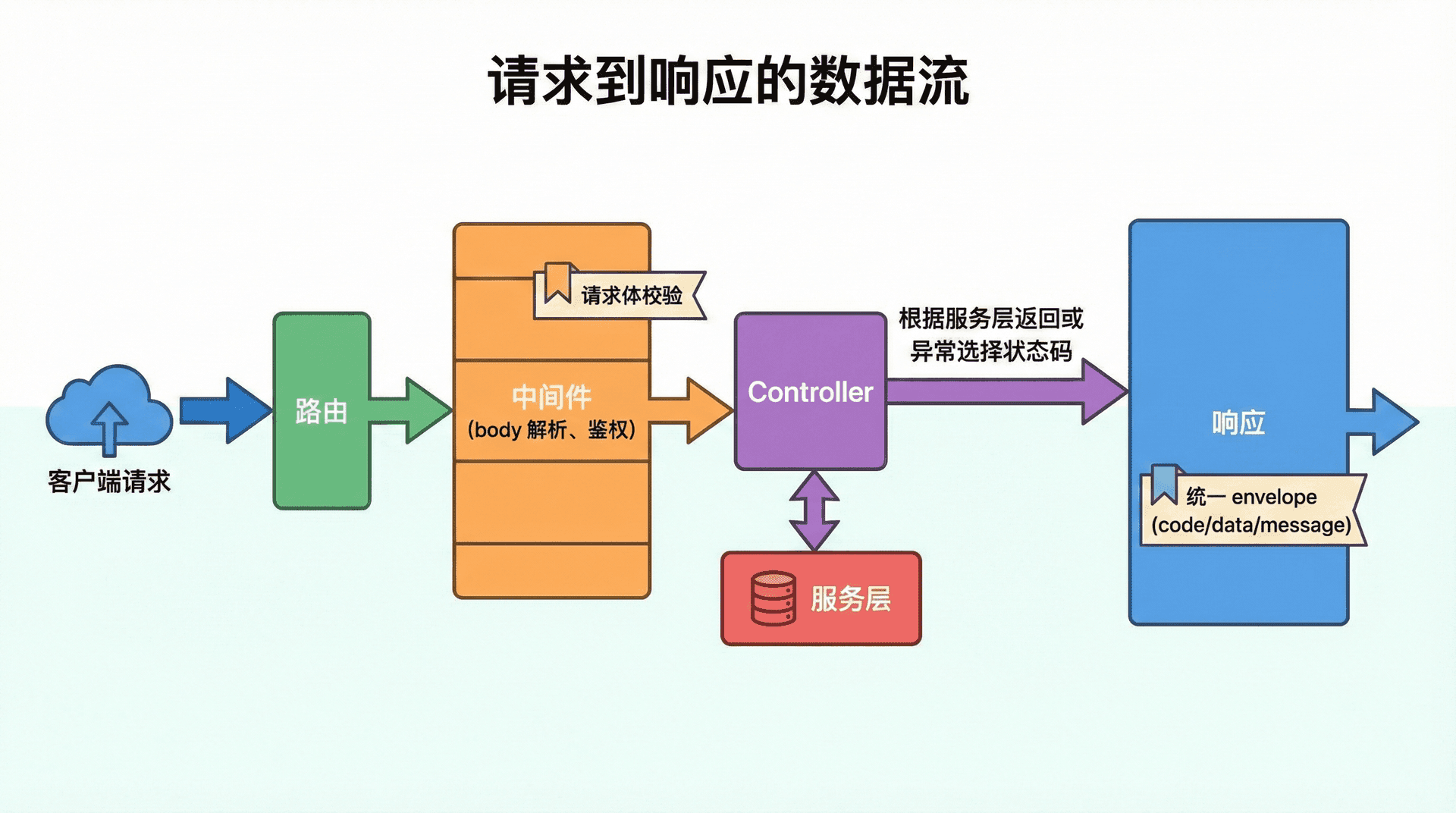
Content-Type 与序列化
我们对外提供的是「API」,通常约定请求与响应都使用 application/json,字符集为 UTF-8。在 Node 里,响应时设置 Content-Type: application/json; charset=utf-8 并用 res.json(obj) 或 res.end(JSON.stringify(obj)) 写出即可;请求体若为 JSON,由 body 解析中间件负责解析,Controller 拿到的已是对象。若将来需要支持表单提交或文件上传,会用到 multipart 或 application/x-www-form-urlencoded,那时再在对应路由挂专门的解析中间件即可;本讲聚焦在常见的 JSON API 设计。
与序列化相关的一点是字段命名风格。若前后端约定用 camelCase,则 Node 里直接 res.json({ userName: user.name }) 即可;若约定用 snake_case(例如与数据库或其它系统一致),可以在序列化时做一层转换,或使用支持命名的 JSON 序列化库。只要在「请求/响应模型设计」阶段定好并文档化,实现时保持一致性即可。
请求体必须在校验通过后再交给服务层;响应体应使用统一的 code/data/message 结构,并与 HTTP 状态码配合,便于客户端统一处理和错误展示。
接下来
这部分我们围绕 RESTful API 的设计与实现 展开了三块内容。在路由设计原则中,我们说明了如何用「资源用名词、动作用 HTTP 方法」来组织 URL,如何用路径层级表达资源关系、用查询参数表达过滤与分页,以及路径参数与 404/405 的语义;同时提到了 API 版本与命名一致性的重要性,并给出了路由表示例。 在 Controller 的职责中,我们强调了「薄 Controller」:只做入参到服务层的转发,再根据结果选择状态码与响应体,不写业务逻辑与数据访问;这样与路由层、服务层边界清晰,也便于测试与复用。 在请求与响应模型设计中,我们讨论了请求体的校验与 DTO 约定、统一响应外壳(code/data/message)与 HTTP 状态码的配合、以及错误响应的集中映射,并简要提到了 Content-Type 与序列化约定。
有了「路由怎么设计、Controller 该干什么、请求响应长什么样」的共识之后,在实际编码中我们还会遇到大量横切逻辑:每个请求都要解析 body、都要鉴权、都要记日志、出错都要转成统一格式。若把这些都写在每个 Controller 里,代码会重复且难维护。
下个部分我们将讨论中间件模式与框架原理:什么是中间件、洋葱模型如何工作、以及 Express 与 Koa 的执行流程。届时你会看到,路由与 Controller 是「管道」中的一环,而 body 解析、鉴权、错误处理等都会以中间件的形式挂在管道上,请求依次经过它们再到达 Controller,响应再沿原路返回;这样,本讲所讲的路由设计、Controller 职责与请求响应模型,就能和中间件管道无缝衔接,形成完整可维护的 Node 后端结构。