异步控制流与并发管理
在第七讲中我们掌握了 Promise 与 async/await:用 then 链或 await 把「先做 A、A 完成后再做 B」写成线性结构,错误用 catch 或 try/catch 统一处理。
但真实业务里往往不只有「一条链」——我们可能要对多份数据依次做同一套处理、可能同时发起多个彼此独立的请求再汇总结果、也可能在「同时进行数」上设限以免压垮下游或耗尽资源。
从这一部分开始,我们专门讨论异步控制流与并发管理:何时该串行、何时该并行、以及如何用「并发限制」与「限流」思想既保证吞吐又保护系统。只有把这三块弄明白,后续在写 HTTP 服务、调下游接口、做批量任务时,才能既高效又不至于把数据库或第三方服务打挂。
串行执行
何时需要串行
当后一步依赖前一步的结果时,我们别无选择:必须等前一步完成,拿到结果,再发起下一步。例如「先根据用户 ID 查用户,再根据用户信息里的部门 ID 查部门,再根据部门信息发通知」:每一步的输入都来自上一步的输出,顺序不能颠倒,也不能「同时进行」。这种「一个接一个、前一个完成再启动下一个」的执行方式,就是串行执行。
在第七讲里我们已经用 then 链和 async/await 写过「读 a 再读 b 再读 c」这类串行逻辑;那里的每一步都依赖上一步(至少依赖「上一步已完成」这一事实)。与串行相对的是并行:若多个任务彼此独立、谁也不依赖谁,我们就可以同时发起它们,等全部(或部分)完成后再继续,从而在 I/O 等待时间上「重叠」,缩短总耗时。
串行与并行的选择,取决于任务之间是否存在依赖关系:存在依赖就用串行,不存在依赖且希望缩短总时间就用并行。下面我们先巩固串行的几种写法,再在下一节展开并行。
for 循环与 await
当我们要对「多份数据」依次做同一套异步操作时,例如对数组里的每个 URL 依次请求(且下一次请求可能依赖上一次的解析结果),或对一批文件依次读取、依次处理,可以用 for 循环 + await 把多步串起来。
在 async 函数里,每次循环执行到 await 时,当前函数会挂起,等该 Promise 落定后再继续下一轮循环;因此循环体里的多个 await 在时间上是严格顺序的,先完成第一个,再完成第二个,依此类推。
下面这段代码演示「对多个文件路径依次读文件、依次打印」:在 async 函数里用 for...of 遍历路径数组,每次循环内 await readFile,这样读文件的操作会一个接一个执行,不会出现「同时发起多个读请求」。若某一步读文件失败,await 会抛出异常,若外层有 try/catch 会在这里接住,后续路径不会再执行。
javascript
const fs = require('fs');
const { promisify } = require('util');
const readFile = promisify(fs.readFile);
async function readFilesInOrder(paths) {
for (const path of paths) {
const data = await readFile(path, 'utf8');
console.log(path, ':', data.length, 'chars');
}
}
readFilesInOrder(['a.txt', 'b.txt', 'c.txt']).catch((err) => {
console.error('读文件失败:', err.message);
});与此等价的是用 then 链:若步骤数量固定,可以写 readFile('a').then(a => readFile('b').then(b => ...)),或像第七讲那样链式 then,每一步 return 下一个 readFile 的 Promise。当步骤数量由动态数据决定(例如数组长度不定)时,用 for 循环 + await 更合适,因为链的「长度」在运行时才确定,用循环写起来更清晰;若步骤固定且只有两三步,then 链或连续 await 都可以。
另一种写法是用 reduce:用 array.reduce((prev, path) => prev.then(() => readFile(path, 'utf8').then(handle)), Promise.resolve()) 把「上一个 Promise 完成后执行下一个」串成一条链。reduce 的写法在函数式风格里常见,但可读性往往不如 for + await,实际项目中 for + await 更常用。
从事件循环的角度看,串行执行时每次 await 都会挂起当前 async 函数,等该 Promise 落定后由微任务恢复;主线程在等待期间可以去执行别的请求的回调或定时器,只是当前这条「链」上的下一步要等上一步完成才会启动,因此从这条链的视角看,步骤是严格顺序的。
串行执行在时间线上的形态是「任务 A 完成 → 任务 B 开始 → 任务 B 完成 → 任务 C 开始」,总耗时约为各任务耗时之和。与并行对比时,若三个任务各需 1 秒,串行需要约 3 秒,并行则可以在约 1 秒内全部完成(假设资源允许同时进行)。下面用一张图概括串行与并行在时间线上的差异,便于后面讨论并行时对照。

典型场景
串行执行的典型场景除了「读 a 再读 b 再读 c」这类文件或 I/O 链,还有依次调用多个接口且后一个依赖前一个结果的流水线。例如先调登录接口拿到 token,再用该 token 调用户信息接口,再根据用户信息里的权限调不同的业务接口;每一步的请求体或请求头依赖上一步的响应,只能串行。
另一种场景是按顺序写日志或写库:若要求操作日志严格按发生顺序落盘,可以用一个队列加一个「消费者」循环,每次 await 一次写操作,再处理下一条,这样从整体上看就是串行写入。
在 Node 里,由于单线程与事件循环,我们说的「串行」指的是「这些异步操作在逻辑上一个接一个启动、一个完成再启动下一个」,而不是「同一时刻只允许一个 I/O」——同一时刻可能还有其他请求的回调在执行,只是当前这条「链」上的步骤是串行的。串行时若某一步抛出异常或返回 rejected Promise,错误会沿 then 链或 await 向上冒泡;若在 async 函数内用 try/catch 包住整段串行逻辑,任一步失败都会进入 catch,后续步骤不会执行,这与第七讲里异步错误处理的方式一致。
并行执行
何时需要并行
当多个任务彼此独立、谁也不依赖谁的结果时,若仍用串行——先等 A 完成再启动 B、再等 B 完成再启动 C——总耗时就是各任务耗时之和,大部分时间都浪费在「等待」上。例如同时请求三个不同的 API 获取用户、订单、商品信息,这三个请求之间没有数据依赖,完全可以同时发出;等三个请求都返回后,再在业务里合并使用。这种「同时发起、等全部(或部分)完成再继续」的执行方式,就是并行执行。
注意:在 Node 里我们只有单线程,所谓「并行」指的是并发地发起多个 I/O 操作,让它们在操作系统和 libuv 层面同时进行,而不是说有多条线程同时在跑 JavaScript;主线程仍然是一个接一个地执行回调,但 I/O 的等待时间重叠了,所以总耗时可以接近「最慢的那个任务」而不是「所有任务之和」。
在 JavaScript 里,若我们写 await taskA(); await taskB(); await taskC();,三个任务会是串行的:先等 A 完成,再等 B,再等 C。若要并行,就不能用三个连续的 await,而要把「同时发起」和「等全部完成」分开表达:先同时发起 A、B、C(调用三个异步函数会得到三个 Promise,此时三个请求都已经发出),再等它们都完成。实现「等它们都完成」的 API 就是 Promise.all。
Promise.all:同时发起、全部完成再继续
Promise.all(iterable) 接受一个可迭代对象(通常是数组),里面每个元素都是 Promise(或会被当作 Promise 的值)。它会等所有 Promise 都变为 fulfilled,然后返回一个数组,数组里每个元素是对应 Promise 的 fulfilled 值,顺序与传入的 iterable 一致。若其中任意一个 Promise 变为 rejected,Promise.all 返回的那个「总 Promise」会立刻变为 rejected,并且带上第一个被 reject 的原因;其余 Promise 的结果不再关心(它们可能还在进行中,但 all 已经失败)。因此,Promise.all 的语义是「全部成功才成功,一个失败就失败」。
在 async 函数里,我们通常这样用:先构造一个 Promise 数组(例如 [fetchUser(), fetchOrders(), fetchProduct()],调用时就已经发起了三个请求),再 const [user, orders, product] = await Promise.all([...]),这样三个请求并行进行,主线程在 await 处挂起,等三个都完成后解构得到结果,总耗时约为最慢的那个请求。
下面这段代码演示「同时读三个文件、等全部读完再打印」:三个 readFile 在进入 Promise.all 时就已经被调用,三个读请求同时发出;await Promise.all 会等三个 Promise 都 resolve,然后 results 里按顺序是 a、b、c 的内容。
javascript
const fs = require('fs');
const { promisify } = require('util');
const readFile = promisify(fs.readFile);
async function readThreeParallel() {
const [dataA, dataB, dataC] = await Promise.all([
readFile(
Promise.all 与事件循环的关系是:当我们执行到 Promise.all([...]) 时,传入的多个异步操作已经启动,它们的回调会在未来的不同时刻被放入任务队列;主线程在 await 处挂起,等「总 Promise」被 resolve(即所有子 Promise 都 fulfilled)后,当前 async 函数从 await 后恢复,拿到结果数组。整个过程主线程没有阻塞,只是「登记」了「等这些 Promise 都完成后再继续」的逻辑,与第七讲里单个 await 的机制一致。

错误处理:Promise.all 与 Promise.allSettled 的取舍
使用 Promise.all 时,只要有一个子 Promise 被 reject,总 Promise 会立刻变为 rejected,其余子 Promise 的结果不再被使用(它们可能还在进行中)。这种「一个失败就全失败」的语义适合「全部成功才有意义」的场景,例如同时拉取用户、订单、商品三块数据,缺一不可;若其中一块拉取失败,整体就失败,便于在 catch 里统一重试或返回错误。
若我们希望「即使有失败也要等全部落定、再统一处理成功和失败」,就要用 Promise.allSettled。
Promise.allSettled 与 Promise.race
有时我们不想「一个失败就全失败」,而是希望等所有任务都落定(无论成功还是失败),再根据每个任务的结果做处理。例如批量校验一批用户 ID 是否有效,有的 ID 可能查不到、会失败,但我们希望拿到「每个 ID 对应成功还是失败」的完整结果,而不是在第一个失败处就整体报错。这时要用 Promise.allSettled(iterable)。
它等所有 Promise 都落定(fulfilled 或 rejected),然后返回一个数组,数组里每个元素是一个对象:若对应 Promise 是 fulfilled,对象为 { status: 'fulfilled', value: ... };若对应 Promise 是 rejected,对象为 { status: 'rejected', reason: ... }。这样我们就可以遍历结果,对 status 为 fulfilled 的取 value,为 rejected 的取 reason 做错误处理或忽略。
下面这段代码演示 Promise.allSettled 的用法:对多个 URL 发起请求,等全部落定后遍历结果,对 status 为 fulfilled 的取 value 使用,为 rejected 的取 reason 记录或忽略,这样即使部分请求失败也能拿到完整的结果集合。
javascript
async function fetchAllSettled(urls) {
const results = await Promise.allSettled(
urls.map((url) => fetch(url).then((r) => r.json()))
);
const succeeded = [];
const failed = [];
for (
Promise.race(iterable) 的语义是「谁先落定用谁」:只要有一个 Promise 变为 fulfilled 或 rejected,race 返回的那个「总 Promise」就立刻跟随它——若先落定的是 fulfilled,总 Promise 就 resolve 该值;若先落定的是 rejected,总 Promise 就 reject 该原因。其余 Promise 的结果被忽略(它们可能还会完成,但 race 已经结束)。
典型用法是「带超时的请求」:把「业务请求的 Promise」和「一个 setTimeout 包装成的 Promise」放进 race,若超时先完成,我们就按超时处理;若业务请求先完成,我们就用业务结果。例如用 Promise.race([fetch(url), new Promise((_, reject) => setTimeout(() => reject(new Error('timeout')), 5000))]) 实现 5 秒超时。
注意:race 不会取消其他未完成的 Promise,它们仍在背后执行,只是结果不再被使用;若需要「取消」,要依赖具体 API 是否支持取消(如 AbortController)。
并行与事件循环、单线程
并行执行不会「多开几条线程」跑 JavaScript;Node 仍然是单线程,同一时刻只有一段同步代码在执行。并行的效果来自于「同时发起多个 I/O」:当我们调用 readFile('a'), readFile('b'), readFile('c') 时,三次调用会依次在同步阶段执行完,每次调用都会向 libuv 提交一个读请求并返回一个 Promise,然后主线程继续;在背后,操作系统可以同时处理多个读请求(或由 libuv 调度),等某个读请求完成时,对应的回调被放入队列,事件循环在某一轮取出执行。
因此,从「主线程」的角度看,我们只是「登记了多个异步操作」并「等它们都完成」;从「总耗时」的角度看,多个 I/O 的等待时间重叠了,所以总耗时可以接近最慢的那个,而不是三者之和。理解这一点,有助于我们在后面讨论「并发限制」时明白:限制的是「同时进行中的异步任务数量」,而不是「线程数」。
在实际业务中,串行与并行常常混合使用:例如先串行调登录接口拿到 token,再并行拉取用户信息、订单列表、推荐列表三块数据(用 Promise.all),再根据这三块数据串行做后续处理;或者先并行拉取多份配置,再根据配置串行执行一系列初始化步骤。掌握「串行用 for + await、并行用 Promise.all、限流用池子或 p-limit」这三类模式,就能组合出大部分后端场景下的异步控制流。
并发限制与限流思想
为何要限制并发
并行能缩短总耗时,但若不加限制地同时发起大量异步操作,会带来问题。例如对一千个 URL 做请求,若用 Promise.all 同时发一千个请求,会在一瞬间占用大量连接、内存和文件描述符,可能把本机或下游服务压垮;数据库连接池通常也有最大连接数,若每个请求都占一个连接且同时请求很多,会耗尽连接池导致新请求失败。
因此,在实际系统中我们往往需要限制「同时进行」的数量:例如最多同时进行 10 个请求,第 11 个要等前面某一个完成后再启动,这样从任意时刻看「在飞」的请求数不超过 10,既利用了并行带来的提速,又不会超过下游或本机的承受能力。这种思想就是并发限制。
与「并发限制」相关的是限流(rate limiting):有时我们不仅要限制「同时进行数」,还要限制「单位时间内的请求数」或「请求的速率」,例如每秒最多 5 次调用、或每毫秒最多 1 次,避免在短时间内对下游造成突发流量。限流和并发限制经常一起使用:并发限制控制「同时在飞」的任务数,限流控制「发起速度」。限流的常见实现思路有「令牌桶」和「滑动窗口」:令牌桶维护一个固定容量的桶,按固定速率往桶里放令牌,每次发起请求前先取一个令牌,取不到就等待或拒绝;滑动窗口则在时间轴上统计最近一段时间内的请求数,超过阈值就拒绝或排队。本节重点讲并发限制的实现思路,限流的思想会顺带提及,具体实现可在后续课程或实际项目中按需深入。
「同时进行数」与「无限并行」的区别
若任务总数很少(例如三五个),用 Promise.all 全部同时发起通常没问题。若任务总数很大(例如成百上千),全部同时发起的「无限并行」会带来:连接数暴增、内存中同时存在大量未完成的 Promise 和中间数据、下游服务或数据库压力过大甚至拒绝服务。
通过并发限制,我们保持「同时进行」的任务数在一个上限 N 以内:一开始启动 N 个,每当有任务完成就从等待队列里取一个补上,这样任意时刻最多只有 N 个任务在进行,总任务数可以很大,但系统负载可控。从时间线上看,无限并行是「所有任务同时开始、各自结束」;并发限制是「一批一批地执行,同一批内并行、批与批之间通过完成-补位衔接」,有时也被比喻为「池子」:池子里最多 N 个任务在跑,完成一个就从队列里放一个进来。
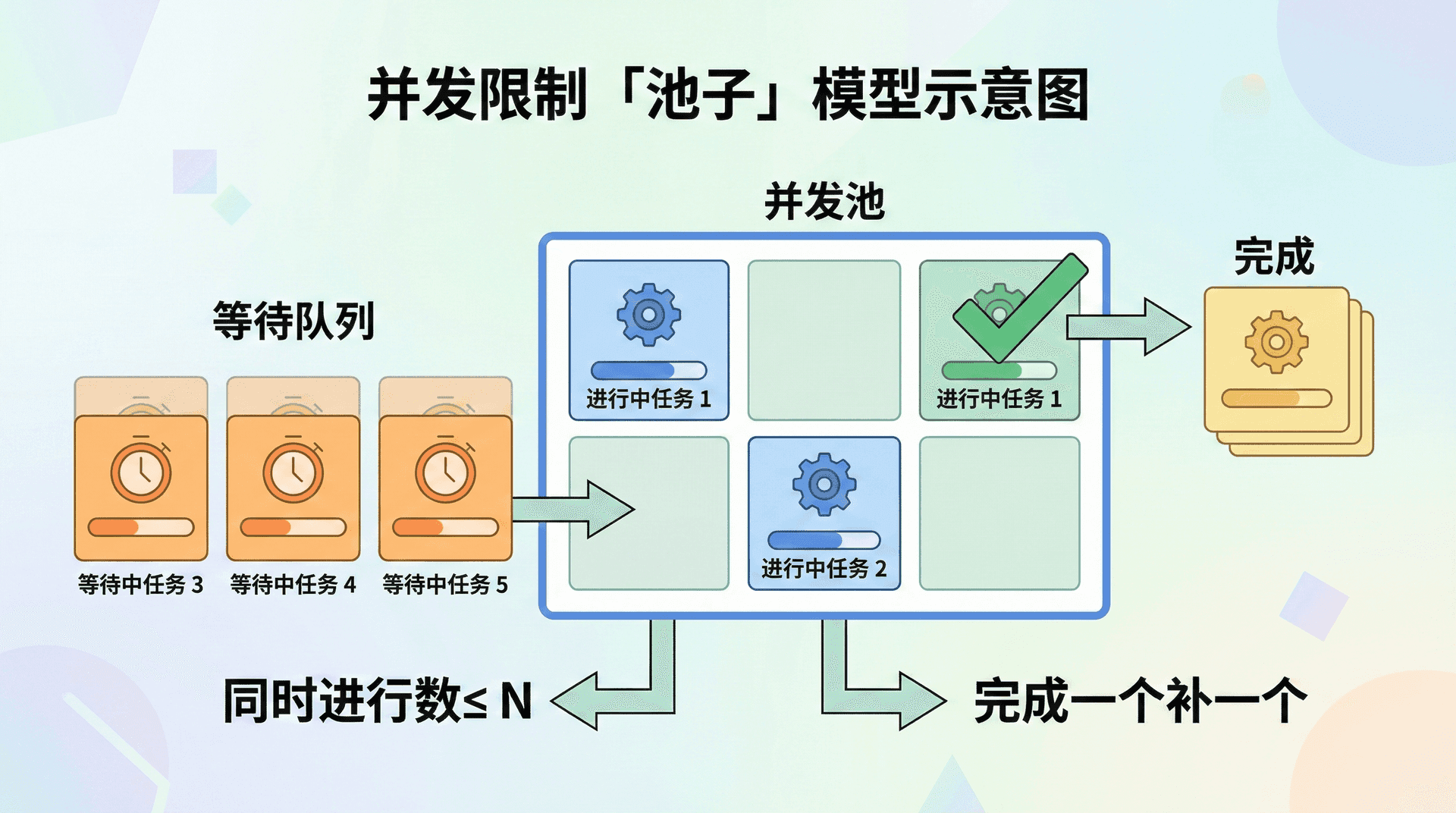
实现思路:并发池与 p-limit
并发限制的一种直观实现是维护一个「当前进行数」和一个「等待队列」:每次要启动新任务时,若当前进行数小于上限 N,就立即启动该任务,并在任务完成时(在 then/finally 里)将进行数减一、并尝试从队列里取下一个任务启动;若当前进行数已达到 N,就把该任务放入队列,等将来有任务完成时再取出并启动。这样,任意时刻「在飞」的任务数不会超过 N。
在代码上,可以封装一个 runWithLimit(tasks, limit):tasks 是返回 Promise 的函数数组,limit 是并发上限;内部用一个队列,每次「有空位」就从 tasks 里取一个执行,该 Promise 在 finally 里触发「检查队列、补位」的逻辑,直到所有任务都执行完。
社区里常用的库如 p-limit 提供了现成的「限制并发数」的封装:先 const limit = pLimit(10) 创建一个最多 10 个并发的限制器,再把要执行的异步函数用 limit(fn) 包一层,例如 limit(() => fetch(url)),这样无论我们调用多少次 limit(...),内部只会同时运行最多 10 个 fn,其余排队。其实现思路与上面说的「进行数 + 队列」一致,只是 API 更易用。
在 Node 后端中,调用下游 HTTP 接口、批量写库、批量读文件时,若数量可能很大,建议使用并发限制,避免一次性打满连接或压垮下游;具体 N 取多少要根据下游的承载能力和业务容忍的延迟来调优。例如在 BFF 层同时请求用户服务、订单服务、推荐服务时,若每个请求内部又要请求多个子接口,可以对「请求下游」这一层做并发限制,保证同一时刻最多 N 个请求在飞,既不会把下游打挂,又能利用并行缩短单次请求的耗时。
下面这段代码演示一个简易的「并发限制」实现:runWithConcurrencyLimit(tasks, maxConcurrent) 接受一组返回 Promise 的函数和最大并发数,返回一个 Promise,在所有任务完成后 resolve 为结果数组;同时进行的不超过 maxConcurrent。内部用 running 计数和 queue 队列,每次启动任务时 running++,任务在 finally 里 running-- 并尝试从 queue 里取下一个执行;用 Promise 和 resolve/reject 记录「全部完成」或「某次失败」的状态,供外部 await。
javascript
function runWithConcurrencyLimit(tasks, maxConcurrent) {
const queue = [...tasks];
const results = [];
let running = 0;
let index = 0;
return new Promise((resolve, reject) => {
function runNext() {
更完整的实现还可以支持「某次 reject 时是否立即 reject 整体」或「仅收集错误、全部完成再 resolve」等策略,与 Promise.all 和 Promise.allSettled 的取舍类似。
使用 p-limit 时,可以这样写:先 npm install p-limit,再 const limit = pLimit(2); await Promise.all(urls.map(url => limit(() => fetch(url)))),这样最多同时 2 个请求,其余排队,既利用了并行又限制了并发。
并发限制控制的是「同时进行」的任务数,而不是任务总数。用「池子」或 p-limit 把同时进行数压在上限 N 以内,可避免无限并行带来的连接与资源压力,同时保持一定吞吐。
接下来
这部分我们区分了串行执行与并行执行:当后一步依赖前一步结果时,用 for 循环 + await 或 then 链把多步串起来; 当多任务彼此独立时,用 Promise.all 同时发起、等全部完成再继续,总耗时接近最慢的那个任务。 在并行中我们还区分了 Promise.all(全部成功才成功、一个失败就失败)、Promise.allSettled(等全部落定再按结果分别处理)和 Promise.race(谁先落定用谁,常用于超时)。
在此基础上,我们讨论了并发限制与限流思想:当任务总数很大时,无限并行会压垮系统或下游,因此要限制「同时进行」的数量,用「池子」或 p-limit 维持最多 N 个在飞,完成一个再补一个; 限流则进一步控制「单位时间内的请求数」或「发起速率」,与并发限制配合使用。 串行、并行与限流三者结合,就能在 Node 服务里既写出清晰的控制流,又避免资源与稳定性风险。