降维
现代数据集常常包含成百上千甚至上万个特征。图像可能有数百万像素,基因数据可能包含数万个基因表达值,文本数据可能有数万个词汇维度。这种高维数据给机器学习带来了巨大挑战——计算开销大、存储需求高、可视化困难、容易过拟合(维度灾难)。
降维(Dimensionality Reduction)技术能够将高维数据映射到低维空间,同时尽可能保留数据的重要信息。降维不仅能加速算法、节省存储,更重要的是能够帮助我们理解数据的内在结构,发现数据中真正重要的模式。
这节课我们将学习最著名的降维算法——主成分分析(PCA)。PCA通过找到数据变化最大的方向,用少数几个主成分来表示原始的高维数据。我们会理解PCA的原理,学习如何实现和应用它,以及何时应该(和不应该)使用降维。
降维的动机
动机一:数据压缩
假设我们测量了飞行员的技能,用两个高度相关的特征:用厘米表示的身高和用英寸表示的身高。这两个特征包含的信息几乎完全重复。我们可以用一个特征(比如厘米)来替代两个,几乎不损失信息。
更通常地来说,高维数据中常常存在冗余。不同特征可能高度相关,实际的有效维度可能远低于名义维度。降维能够移除这种冗余,提取数据的“本质”维度。
好处:
- 减少存储空间
- 加速学习算法
- 便于可视化(降到2维或3维)
动机二:可视化
人类很难直观理解超过3维的数据。但通过降维,我们可以把高维数据投影到2维或3维,画出散点图,直观地观察数据的分布、聚类、异常值等。
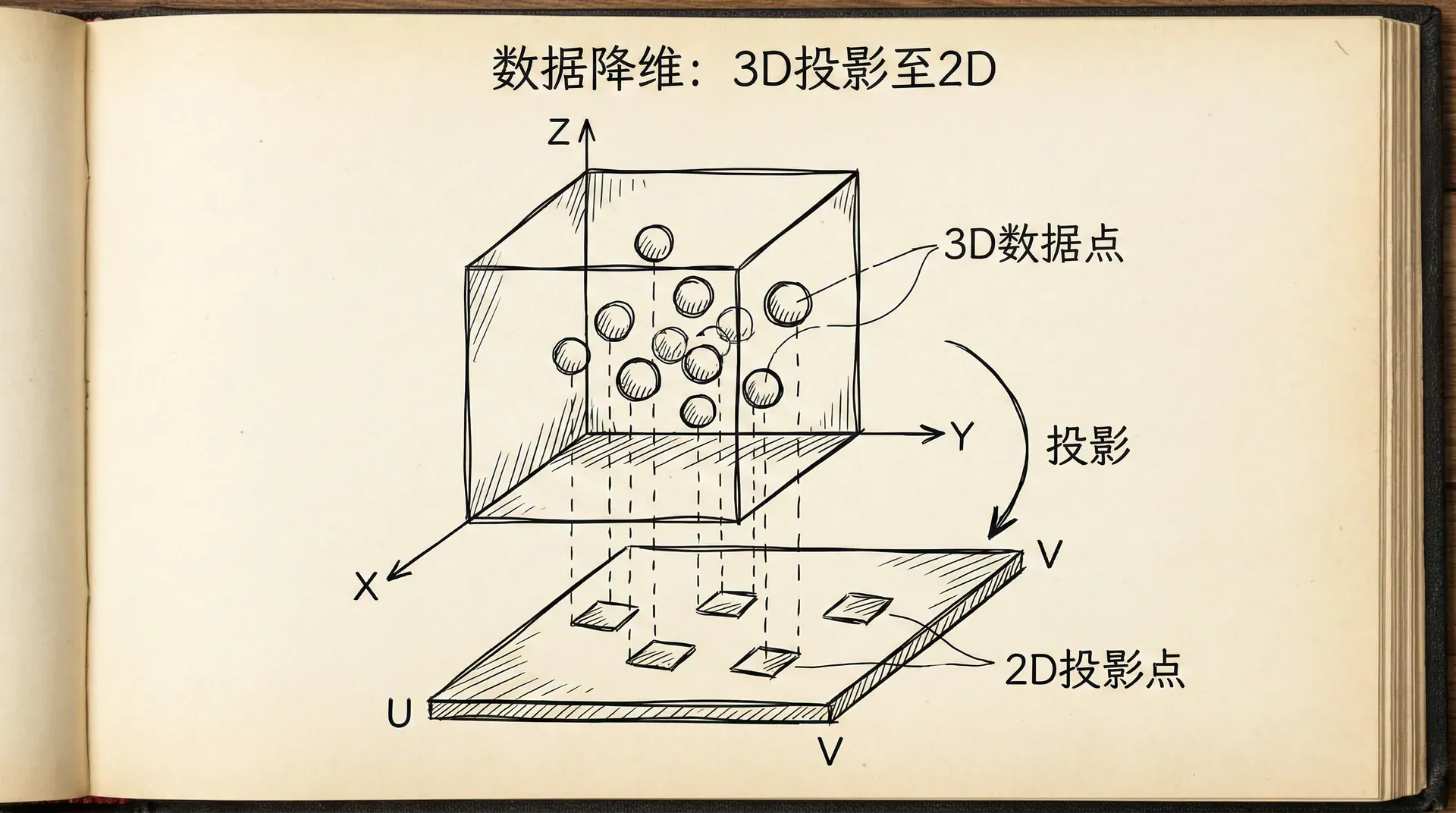
例如,我们有50个国家的统计数据,每个国家有100个特征(GDP、人口、教育水平等)。这是100维数据,无法直接可视化。但如果我们用PCA降到2维,就可以在平面上画出50个点,每个点代表一个国家。我们可能会发现发达国家聚在一起,发展中国家聚在另一边,揭示了数据的结构。
降维是有损的——我们会损失一些信息。关键是找到一个平衡:用尽可能少的维度保留尽可能多的信息。PCA通过数学方法找到这个最优的权衡。
主成分分析(PCA)
PCA是最常用的降维算法。它的核心思想是:找到数据变化最大的方向,把数据投影到这些方向上。
想象你有一堆三维空间中的点,大致分布在一个平面附近(想象一张纸在空间中)。这些点的z坐标变化很小,主要变化在xy平面内。PCA会发现这个平面,把数据投影到这个平面上,从3维降到2维,几乎不损失信息。
更形式化地说,PCA寻找k个方向(主成分),使得数据投影到这k个方向后,方差最大。方差大意味着数据在这个方向上“伸展”得厉害,包含更多信息。
PCA的数学表述:
给定数据集 ,,目标是找到 个方向 (),使得:
- 数据投影到这些方向后方差最大
- 或等价地,数据点到投影的距离平方和最小
步骤0:数据预处理
- 均值归一化:让每个特征的均值为0
python
import numpy as np
def pca(X, k):
"""
主成分分析
X: 数据矩阵 (m x n)
k: 目标维度
返回: 投影矩阵U_reduce, 降维后的数据Z
"""
m, n = X.shape
# 步骤0:均值归一化
mu = np.mean(X, axis=0)
X_norm = X - mu
# 可选:特征缩放
sigma = np.std(X, axis
使用scikit-learn:
python
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 创建PCA对象
pca = PCA(n_components=2)
# 拟合并转换数据
Z = pca.fit_transform(X)
# 查看每个主成分解释的方差比例
print("解释方差比:", pca.explained_variance_ratio_)
print("累积解释方差:", np.cumsum(pca.explained_variance_ratio_))
# 可视化降维后的数据
plt.scatter(Z[:, 0], Z[:, 1])
选择主成分数量k
如何决定保留多少个主成分?这是PCA中的关键问题。
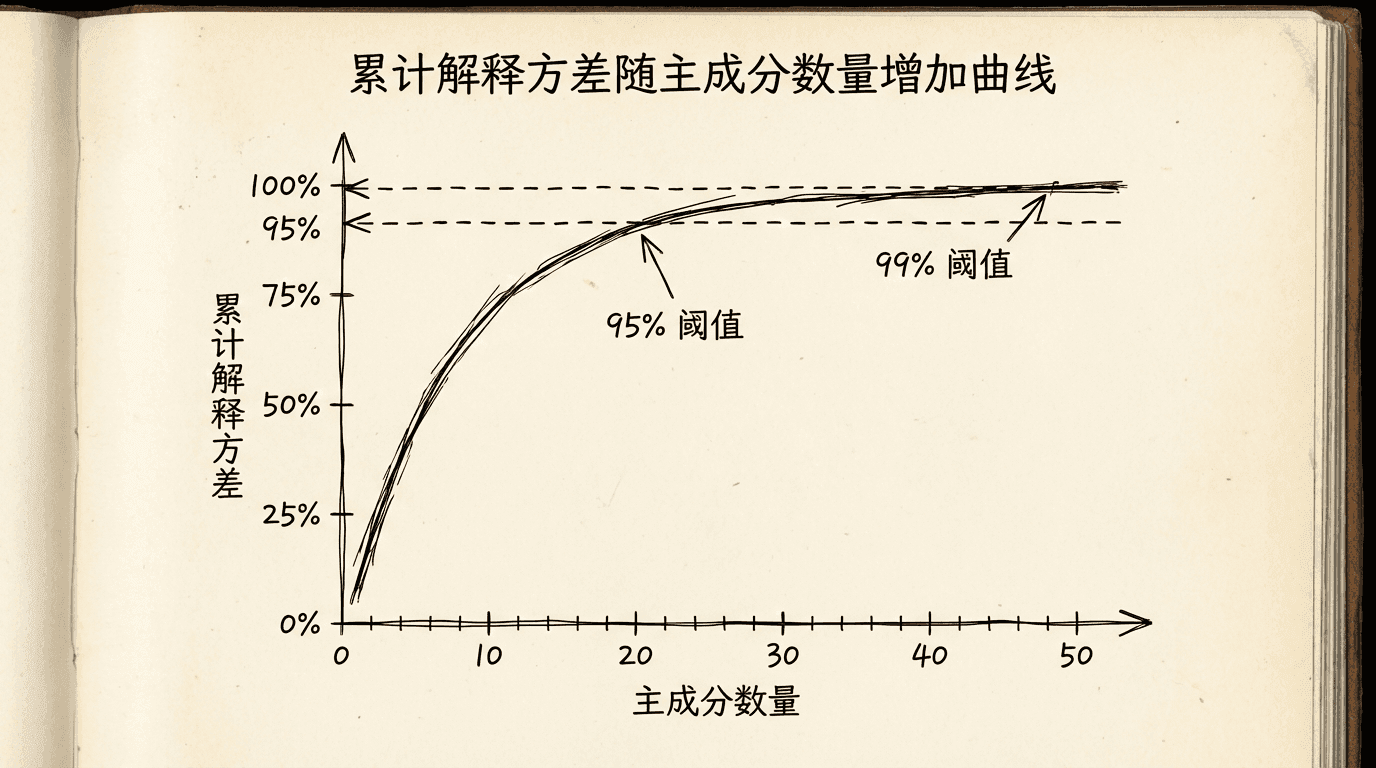
方法1:解释方差比例
每个主成分解释了原始数据中一定比例的方差。前k个主成分累计解释的方差比例:
其中 是第i个特征值(代表第i个主成分的方差)。
我们通常选择k使得累计解释方差达到一定阈值,比如95%或99%。
python
# 计算不同k值下的累计解释方差
pca_full = PCA()
pca_full.fit(X)
cumsum = np.cumsum(pca_full.explained_variance_ratio_)
# 找到达到95%的k
k_95 = np.argmax(cumsum >= 0.95) + 1
print(f"保留95%方差需要 {k_95} 个主成分")
# 画出累计方差图
plt.plot(range(1, len(cumsum)+1), cumsum)
plt.axhline(
方法2:碎石图(Scree Plot)
画出每个主成分解释的方差。寻找"肘部"——方差下降突然变缓的地方。
python
plt.plot(range(1, len(pca_full.explained_variance_)+1),
pca_full.explained_variance_, 'o-')
plt.xlabel('主成分')
plt.ylabel('解释方差')
plt.title('碎石图')
plt.show()方法3:基于下游任务
如果降维是为了后续的监督学习,可以尝试不同的k,看哪个在验证集上表现最好。
数据重建
降维后的数据可以近似重建回原始维度。虽然不能完全恢复(有信息损失),但可以得到一个近似。
重建误差反映了降维损失了多少信息:
python
def reconstructData(Z, U_reduce, mu, sigma):
"""
从降维数据重建原始数据
"""
X_approx = Z @ U_reduce.T
X_approx = X_approx * sigma + mu # 反归一化
return X_approx
# 重建
X_approx = reconstructData(Z, U_reduce, mu, sigma)
# 计算重建误差
reconstruction_error = np.mean(np.sum((X - X_approx)**2, axis=1
PCA的应用
应用1:图像压缩
灰度图像可以看作向量(每个像素一个维度)。对一组图像应用PCA,可以用少数主成分表示每张图像,实现压缩。
python
# 假设有1000张28x28的人脸图像
# X是1000x784的矩阵
pca = PCA(n_components=50) # 用50个主成分
Z = pca.fit_transform(X) # 从784维降到50维
# 压缩率:50/784 ≈ 6.4%
# 重建图像
X_approx = pca.inverse_transform(Z)
# 显示原始和重建的图像
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
for i in range
应用2:数据可视化
将高维数据降到2D或3D进行可视化。
python
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# 加载手写数字数据(64维)
digits = load_digits()
X, y = digits.data, digits.target
# PCA降到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化
plt.figure(figsize=(10, 8))
scatter =
应用3:噪声过滤
PCA可以用来去除数据中的噪声。思想是:信号主要在前几个主成分中,噪声分散在所有维度。保留主要成分、丢弃后面的成分,可以去噪。
应用4:加速学习
在训练监督学习模型前,先用PCA降维可以:
- 加快训练速度
- 减少内存使用
- 有时还能提高性能(通过去除噪声和冗余)
python
# 降维 + 分类
from sklearn.linear_model import LogisticRegression
# 原始数据训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
score_original = clf.score(X_test, y_test)
# PCA降维后训练
pca = PCA(n_components=0.95) # 保留95%方差
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
clf_pca = LogisticRegression()
clf_pca.fit(X_train_pca, y_train)
score_pca =
PCA降维会损失信息。不要期望降维后的性能总是更好。有时候,那些看似不重要的小方差成分中也包含对任务有用的信息。应该通过实验来验证降维是否有益。
接下来
降维是数据科学工具箱中的重要工具。PCA作为最经典的降维方法,简单、高效、理论基础扎实。掌握PCA,你就能处理高维数据的诸多挑战。但记住,降维是手段不是目的,应该根据具体问题决定是否使用、如何使用。
在下一节课中,我们将学习异常检测——识别数据中不寻常的模式。异常检测在很多领域有重要应用,从欺诈检测到设备故障预警。我们会看到,异常检测也是一种无监督学习任务,它与聚类、降维等技术可以结合使用。
小练习
-
问题诊断和解决方案:根据以下情况,诊断问题并提出解决方案。
你训练了一个模型,得到:
- 训练误差:5%
- 验证误差:25%
这是什么问题?应该如何解决?
答案:
诊断:高方差(过拟合)
判断依据:
- 训练误差很低(5%)- 模型在训练集上表现很好
- 验证误差很高(25%)- 模型在新数据上表现差
- 训练误差和验证误差差距大(20%)- 典型的过拟合特征
解决方案(按优先级):
-
获取更多训练数据 ✓ 最有效
- 更多数据能帮助模型学习真实模式而非噪声
-
减少特征数量 ✓
- 手动选择重要特征
- 使用PCA降维
-
增加正则化参数λ ✓
- 增大λ来惩罚复杂模型
-
使用更简单的模型 ✓
- 减少神经网络层数
- 减少多项式次数
不应该做的:
- ✗ 增加特征(会让过拟合更严重)
- ✗ 减小正则化参数(会让过拟合更严重)
- ✗ 训练更长时间(模型已经学得够好了)
Python诊断代码:
python
def diagnose_model(train_error, val_error):
gap = val_error - train_error
if train_error > 0.15: # 高偏差
if gap < 0.05:
return "欠拟合(高偏差)"
else:
-
学习曲线分析:分析以下学习曲线,判断问题类型。
随着训练样本数量增加:
- 训练误差:从10%缓慢上升到18%
- 验证误差:从60%缓慢下降到20%
- 两条曲线在20%附近趋于平缓,但仍有差距
这是什么问题?解决方案是什么?
答案:
诊断:轻度高方差(过拟合),可能混合轻度高偏差
学习曲线特征分析:
-
训练误差上升(10% → 18%)
- 正常现象:更多数据使得完美拟合更难
- 说明模型没有明显欠拟合
-
验证误差下降(60% → 20%)
- 好现象:更多数据改善了泛化能力
- 但最终仍有差距(训练18% vs 验证20%)
-
曲线趋于平缓
- 说明:更多数据的边际收益递减
- 关键问题:曲线平缓但未收敛到理想值
判断:
- 如果目标误差是5%,那么18-20%说明模型偏差也较高
- 训练和验证误差的小差距(2%)表明方差不是主要问题
- 结论:可能需要更复杂的模型(增加特征/提高模型容量)
解决方案:
-
如果目标误差可接受(如15%):
- 当前模型已经不错
- 可以尝试获取更多数据进一步缩小gap
-
如果目标误差更低(如5%):
- 增加特征数量
- 使用更复杂的模型(更多隐藏层/神经元)
- 减小正则化参数λ
- 尝试多项式特征
典型学习曲线模式:
高方差(过拟合):
训练误差:很低且平
验证误差:高且有大gap
解决:更多数据有帮助
高偏差(欠拟合):
训练误差:高且平
验证误差:高且gap小
解决:更多数据帮助不大,需要更复杂模型
理想状态:
两条曲线都低且接近
差距很小