聚类
到目前为止,我们学习的都是监督学习算法——我们有标记的数据,知道每个样本应该对应什么输出。但现实世界中,很多数据是没有标签的。假设你有一百万用户的行为数据,你想理解他们有哪些不同的群体;或者你有大量的新闻文章,想自动分组成不同的主题。这些都是无监督学习的应用场景。
聚类(Clustering)是无监督学习中最重要的技术之一。它的目标是将相似的数据点归为一组,使得同一组内的点尽可能相似,不同组之间的点尽可能不同。聚类算法不需要标签,完全基于数据本身的特征来发现结构。
这节课我们将学习K-Means算法——最流行、最简单也最实用的聚类算法。我们会理解它的工作原理,学习如何优化它,以及如何在实际问题中应用它。
无监督学习的特点
无监督学习与监督学习有本质的不同:
- 监督学习:给定 ,学习 的映射。
- 无监督学习:只给定 ,发现数据的内在结构。
没有“正确答案”让我们参考,算法需要自己找出数据的组织方式。这既是挑战,也是机会——我们可能发现我们事先不知道的模式和结构。
聚类的应用:
- 市场细分:根据用户的购买行为、浏览历史等,将用户分成不同群体,针对性地营销。
- 社交网络分析:识别社交网络中的社区和群组。
- 图像压缩:将相似的像素颜色归为一组,用每组的代表色替代,减少需要存储的颜色数量。
- 天文学:将星系根据特征聚类,发现不同类型的星系。
- 基因学:根据基因表达数据聚类,发现功能相似的基因组。
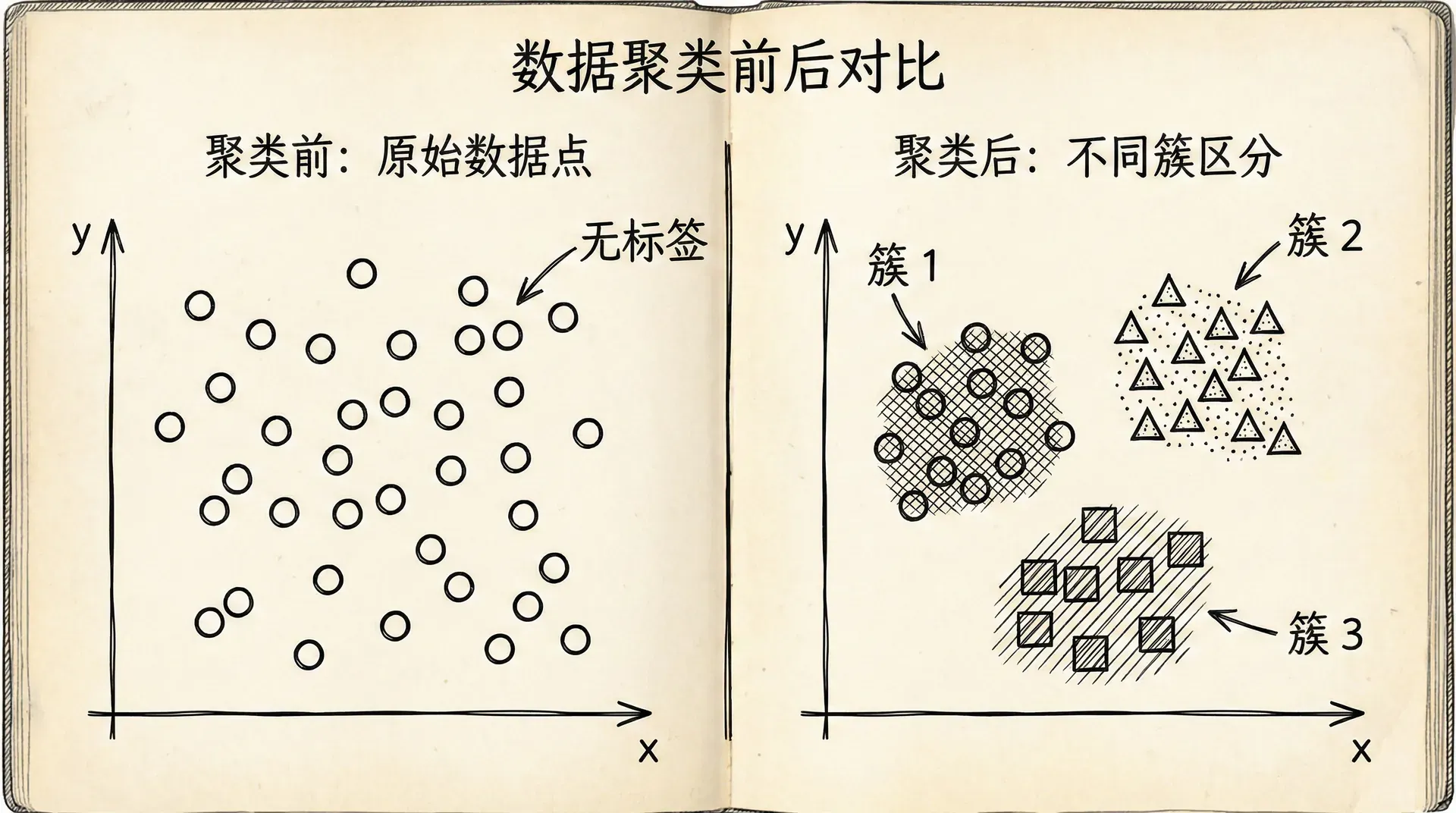
聚类是一种探索性数据分析工具。它不会给你“正确”的分组(因为没有标准答案),而是揭示数据的一种可能的组织方式。不同的聚类算法或不同的参数可能给出不同的结果,都可能有意义。
K-Means算法
K-Means是最著名的聚类算法,思想简单直观,实现容易,在很多问题上效果很好。
假设我们要将数据分成K个簇(cluster)。K-Means通过迭代的方式:
- 随机初始化K个聚类中心(centroids)
- 将每个数据点分配给最近的聚类中心
- 重新计算每个簇的中心(该簇所有点的平均值)
- 重复步骤2-3直到收敛(聚类中心不再变化或变化很小)
输入:
- 数据集
python
import numpy as np
import matplotlib.pyplot as plt
def kmeans(X, K, max_iters=100):
"""
K-Means聚类算法
X: 数据矩阵 (m x n)
K: 聚类数量
max_iters: 最大迭代次数
"""
m, n = X.shape
# 随机初始化聚类中心
random_indices = np.random.choice(m, K, replace=False)
centroids = X[random_indices]
K-Means的优化目标
K-Means虽然是一个启发式算法,但它实际上在优化一个明确的目标函数。
失真函数(Distortion Function),也叫代价函数:
这个函数衡量的是所有点到其所属聚类中心的距离平方和的平均值。
K-Means的两个步骤分别优化这个目标:
- 分配步骤:固定 ,优化 (让每个点选择最近的中心)
- 移动中心步骤:固定 ,优化 (让每个中心移到其簇的均值)
每次迭代都会使 减小(或保持不变),所以算法一定会收敛。但注意:K-Means可能收敛到局部最优,不保证找到全局最优。
监控代价函数可以帮助我们:
- 检查算法是否正常工作(代价应该单调递减)
- 比较不同初始化的结果
- 决定何时停止迭代
python
def computeDistortion(X, centroids, assignments):
"""计算失真函数"""
m = X.shape[0]
distortion = 0
for i in range(m):
distortion += np.sum((X[i] - centroids[assignments[i]])**2)
return distortion / m
# 画出代价函数随迭代的变化
distortions = []
for centroids in centroid_history:
# 重新分配(需要用当时的中心)
随机初始化
K-Means对初始聚类中心的选择很敏感。不好的初始化可能导致:
- 收敛到不好的局部最优
- 某些簇为空
- 需要更多迭代才能收敛
推荐的初始化方法:
随机选择K个训练样本作为初始中心。这是最简单也最常用的方法。
python
def initCentroids(X, K):
"""随机初始化聚类中心"""
m = X.shape[0]
random_indices = np.random.permutation(m)[:K]
return X[random_indices]处理局部最优:多次运行
为了避免陷入不好的局部最优,可以:
- 多次运行K-Means(比如50-1000次),每次随机初始化
- 选择失真函数最小的那次结果
python
def kmeansMultipleRuns(X, K, num_runs=50):
"""
运行K-Means多次,选择最好的结果
"""
best_centroids = None
best_assignments = None
best_distortion = float('inf')
for run in range(num_runs):
centroids, assignments, _ = kmeans(X, K)
distortion = computeDistortion(X, centroids, assignments)
if distortion
K-Means++初始化
这是一个更智能的初始化方法,能够让初始中心分散开:
- 随机选择第一个中心
- 对于每个后续中心,选择距离已有中心最远的点作为新中心
- 重复直到选出K个中心
K-Means++通常能更快收敛到更好的解。大多数库(如scikit-learn)默认使用K-Means++。
即使用了好的初始化方法,K-Means仍可能得到不同的结果(因为随机性)。对于重要的应用,应该多次运行并比较结果。对于K较小(比如2-10),多次运行的开销通常是可接受的。
选择聚类数量K
K是K-Means的超参数,需要事先指定。如何选择合适的K?
肘部法则(Elbow Method)
画出失真函数J随K变化的曲线。随着K增大,J会递减(更多的簇意味着点离中心更近)。寻找曲线的"肘部"——J下降速度明显变慢的那个点。
python
distortions = []
K_range = range(1, 11)
for K in K_range:
centroids, assignments, _ = kmeans(X, K)
distortions.append(computeDistortion(X, centroids, assignments))
plt.plot(K_range, distortions, 'o-')
plt.xlabel('聚类数量 K')
plt.ylabel('失真函数 J')
plt.title('肘部法则')
plt.show()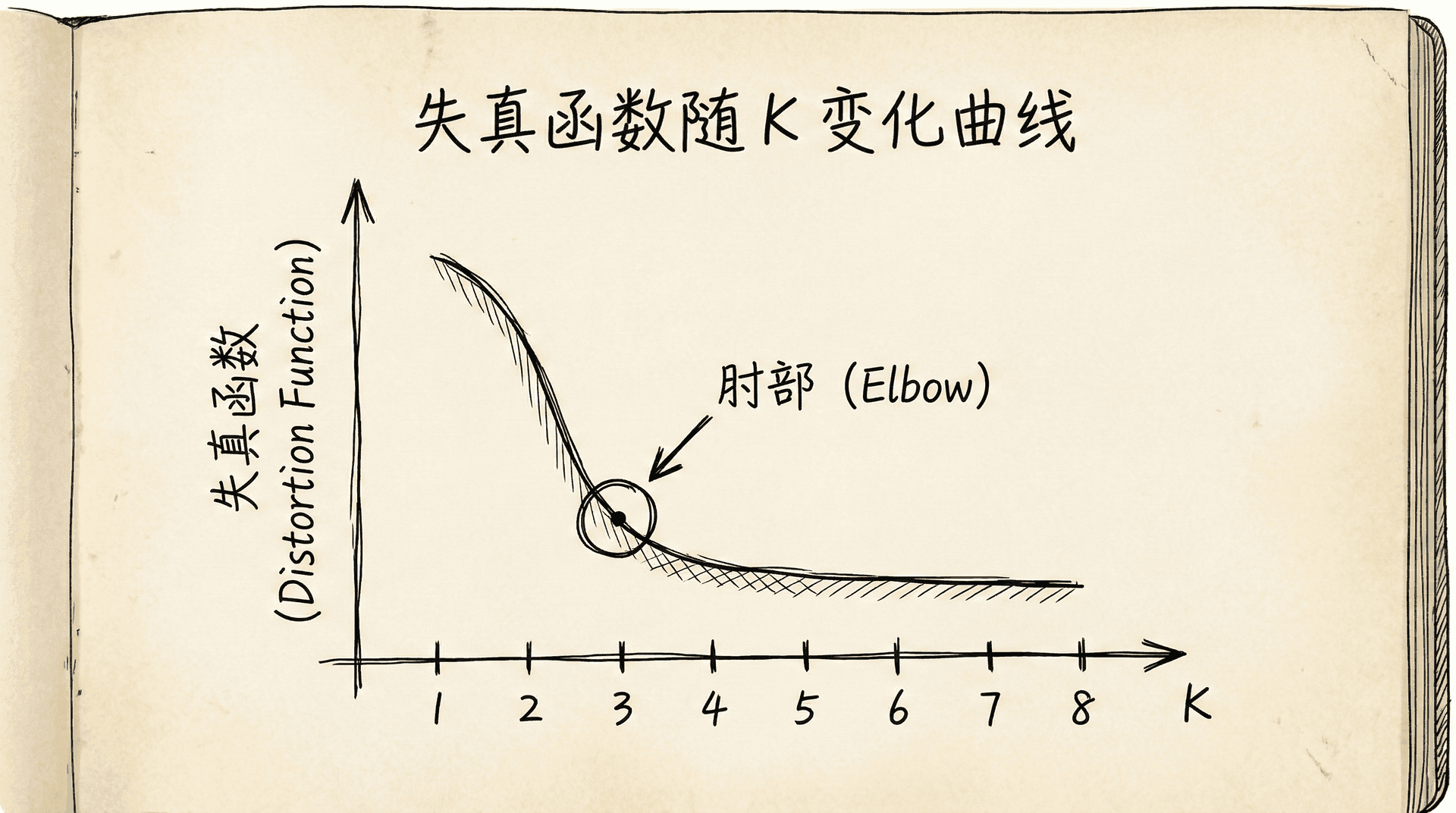
肘部法则的问题是:不是所有数据都有明显的肘部。曲线可能平滑递减,没有明显的拐点。
轮廓系数(Silhouette Coefficient)
对于每个样本,计算:
- :到同簇其他点的平均距离
- :到最近的其他簇的所有点的平均距离
轮廓系数:
接近1表示聚类良好,接近-1表示聚类不当。计算所有样本的平均轮廓系数,选择使其最大的K。
基于应用目标选择
很多时候,K的选择应该基于下游任务的需求,而不是纯粹的统计指标。比如:
- 市场细分:你的营销团队能处理几个不同的用户群体?
- 图像压缩:你想用多少种颜色?
- 推荐系统:你想把用户分成几类来个性化推荐?
这些实际考虑往往比统计指标更重要。
K-Means的应用案例
案例1:图像压缩
彩色图像中每个像素有RGB三个值(24位,可以表示约1600万种颜色)。但很多图像实际只用了少数几种颜色。K-Means可以找出K种代表色,用这K种颜色替代原始颜色,大大减少存储空间。
python
from sklearn.cluster import KMeans
from PIL import Image
# 读取图像
img = Image.open('photo.jpg')
img_array = np.array(img)
# 重塑为(像素数, 3)的矩阵
h, w, c = img_array.shape
pixels = img_array.reshape(-1, 3)
# K-Means聚类
K = 16 # 使用16种颜色
kmeans = KMeans(
案例2:用户分群
电商平台想根据用户行为进行市场细分。特征包括:购买频率、平均订单金额、浏览时长、喜欢的品类等。
python
# 用户特征矩阵
# 每行一个用户,列是特征
user_features = np.array([
# [购买频率, 平均金额, 浏览时长, ...]
[2, 150, 30, ...],
[10, 80, 120, ...],
...
])
# 特征缩放(重要!)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
user_features_scaled = scaler.fit_transform(user_features)
K-Means的局限性:
- 需要指定K:不能自动确定簇的数量
- 对初始化敏感:可能陷入局部最优
- 假设球形簇:对非球形、不同大小或密度的簇效果不好
- 对异常值敏感:使用均值计算中心,容易受极端值影响
- 只能处理数值特征:不能直接处理分类特征
对于这些局限性,有其他聚类算法可以选择:
- 层次聚类:不需要指定K,能发现层次结构
- DBSCAN:能发现任意形状的簇,对异常值稳健
- 高斯混合模型:允许簇有不同的形状和大小
但K-Means因其简单、快速、易于实现,仍然是最常用的聚类算法。
在下节课中,我们将学习降维技术,特别是主成分分析(PCA)。降维也是无监督学习的重要应用,它能帮助我们压缩数据、可视化高维数据、提取主要特征。降维常常与聚类结合使用——先降维再聚类,或者用降维后的数据可视化聚类结果。
小练习
-
问题诊断和解决方案:根据以下情况,诊断问题并提出解决方案。
你训练了一个模型,得到:
- 训练误差:5%
- 验证误差:25%
这是什么问题?应该如何解决?
答案:
诊断:高方差(过拟合)
判断依据:
- 训练误差很低(5%)- 模型在训练集上表现很好
- 验证误差很高(25%)- 模型在新数据上表现差
- 训练误差和验证误差差距大(20%)- 典型的过拟合特征
解决方案(按优先级):
-
获取更多训练数据 ✓ 最有效
- 更多数据能帮助模型学习真实模式而非噪声
-
减少特征数量 ✓
- 手动选择重要特征
- 使用PCA降维
-
增加正则化参数λ ✓
- 增大λ来惩罚复杂模型
-
使用更简单的模型 ✓
- 减少神经网络层数
- 减少多项式次数
不应该做的:
- ✗ 增加特征(会让过拟合更严重)
- ✗ 减小正则化参数(会让过拟合更严重)
- ✗ 训练更长时间(模型已经学得够好了)
Python诊断代码:
python
def diagnose_model(train_error, val_error):
gap = val_error - train_error
if train_error > 0.15: # 高偏差
if gap < 0.05:
return "欠拟合(高偏差)"
else:
-
学习曲线分析:分析以下学习曲线,判断问题类型。
随着训练样本数量增加:
- 训练误差:从10%缓慢上升到18%
- 验证误差:从60%缓慢下降到20%
- 两条曲线在20%附近趋于平缓,但仍有差距
这是什么问题?解决方案是什么?
答案:
诊断:轻度高方差(过拟合),可能混合轻度高偏差
学习曲线特征分析:
-
训练误差上升(10% → 18%)
- 正常现象:更多数据使得完美拟合更难
- 说明模型没有明显欠拟合
-
验证误差下降(60% → 20%)
- 好现象:更多数据改善了泛化能力
- 但最终仍有差距(训练18% vs 验证20%)
-
曲线趋于平缓
- 说明:更多数据的边际收益递减
- 关键问题:曲线平缓但未收敛到理想值
判断:
- 如果目标误差是5%,那么18-20%说明模型偏差也较高
- 训练和验证误差的小差距(2%)表明方差不是主要问题
- 结论:可能需要更复杂的模型(增加特征/提高模型容量)
解决方案:
-
如果目标误差可接受(如15%):
- 当前模型已经不错
- 可以尝试获取更多数据进一步缩小gap
-
如果目标误差更低(如5%):
- 增加特征数量
- 使用更复杂的模型(更多隐藏层/神经元)
- 减小正则化参数λ
- 尝试多项式特征
典型学习曲线模式:
高方差(过拟合):
训练误差:很低且平
验证误差:高且有大gap
解决:更多数据有帮助
高偏差(欠拟合):
训练误差:高且平
验证误差:高且gap小
解决:更多数据帮助不大,需要更复杂模型
理想状态:
两条曲线都低且接近
差距很小