样本空间、事件与概率公理
概率题看起来常常从“算一个数”开始,但真正的第一步是把随机试验说清楚:哪些结果可能出现,哪些结果算作同一类,哪些事件可以被讨论。样本空间和事件给我们一套集合语言,概率公理则规定怎样给这些集合赋值。只要这三件事没有对齐,后面的公式即使算得很熟,也可能是在回答另一个问题。
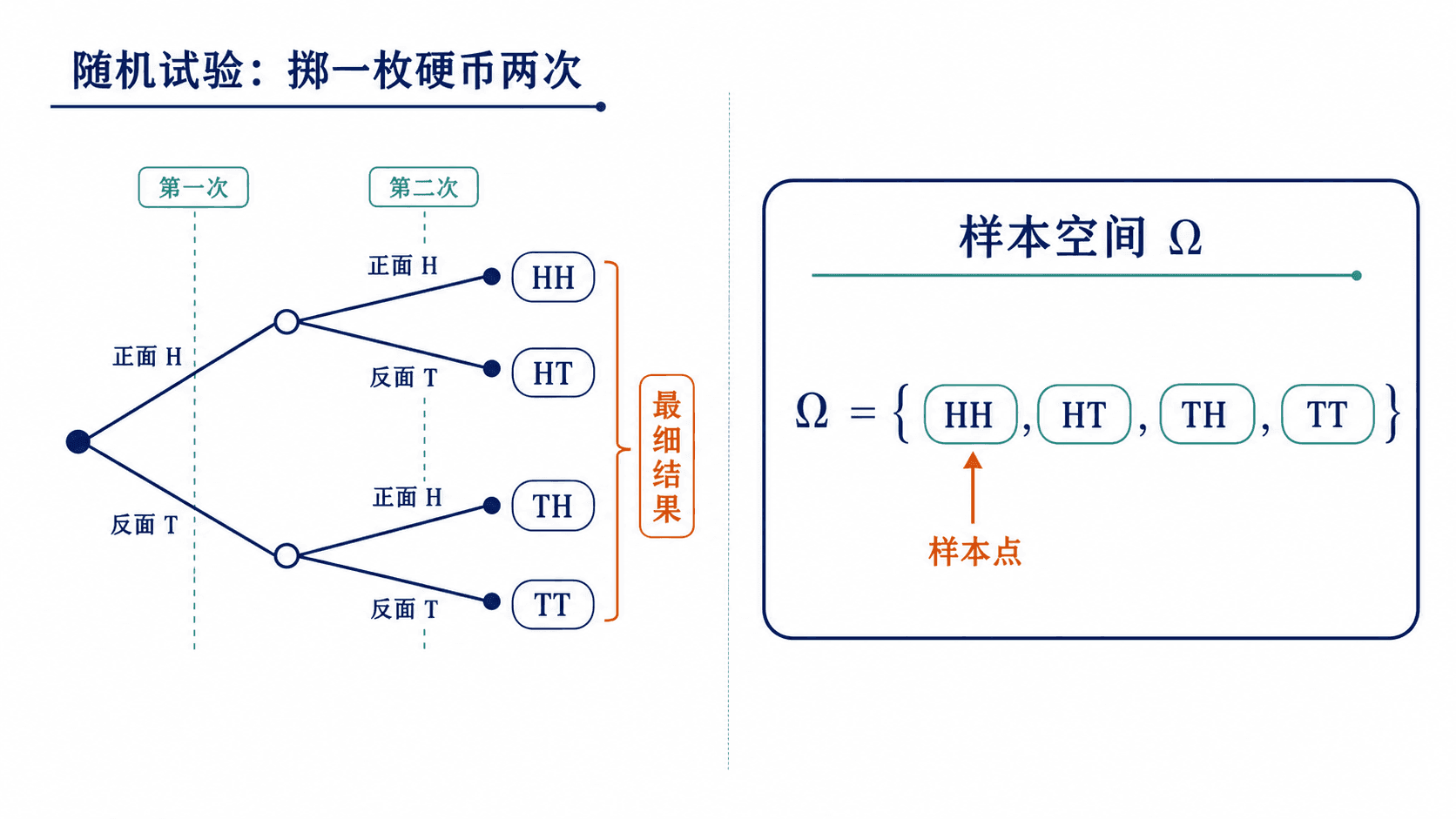 样本空间把随机试验的所有最细结果放在同一个集合中。
样本空间把随机试验的所有最细结果放在同一个集合中。
从随机试验到样本空间
随机试验是结果事先不能确定、但结果范围可以事先描述的过程。掷一枚骰子、记录明天某地是否下雨、观察一台设备的寿命,都可以是随机试验。概率论不直接处理“现实本身”,而是先建立一个概率模型,再在模型中讨论事件和概率。
样本空间通常记为 Ω,它是随机试验所有可能结果组成的集合。样本空间中的单个结果叫样本点,常记为 ω。例如连续抛两次硬币,如果记录每一次的正反面,样本空间可以写成
Ω={HH,HT,TH,TT}
其中 HT 表示第一次正面、第二次反面。事件“恰好一次正面”就是集合 {HT,TH}。
同一个现实过程可以有不止一种样本空间。连续掷两枚骰子,如果关心每枚骰子的点数,可以用有序对
Ω1={(i,j):i,j∈{1,2,3,4,
如果只关心点数和,也可以用
Ω2={2,3,4,…,12}
这两个样本空间都描述“掷两枚骰子”,但它们的样本点粒度不同。Ω1 的 36 个有序对在公平骰子模型中等可能;Ω2 的 11 个点数和却不等可能,因为和为 7 的方式比和为 2 的方式多。样本空间不是越短越好,而是要和问题、数据记录方式、概率赋值方式相匹配。
样本空间不是把所有听起来可能的答案列出来就结束。它还隐含了“哪些结果被看作最细结果”和“这些结果怎样分配概率”。在古典概型里尤其要小心:能数样本点,不代表每个样本点都等可能。
选择样本空间的检查
一个可用的样本空间通常满足四点。第一,覆盖性:试验必然产生其中某个结果。第二,互斥性:一次试验只落在一个样本点上。第三,粒度合适:样本点能区分题目关心的差异。第四,可赋概率:能够根据对称性、频率资料或模型假设给结果赋概率。
例如“随机抽一名学生,记录其本周自习时间”不适合只写成 {少,中,多},除非题目已经规定了分组标准。如果实际记录的是小时数,样本空间可以是非负实数区间的一部分;如果课程只做问卷分组,样本空间才可能是若干离散类别。
事件:样本空间中的集合
事件是样本空间的子集。一次试验得到样本点 ω 后,如果 ω∈A,就说事件 A 发生。必然事件是 Ω,不可能事件是空集 ∅。
集合语言让“或者”“同时”“没有发生”这些说法变得精确。对事件 A 和 B:
- A∪B 表示 A 或 B 至少发生一个。
- A∩B 表示 A 和 B 同时发生。
- 表示 没有发生。
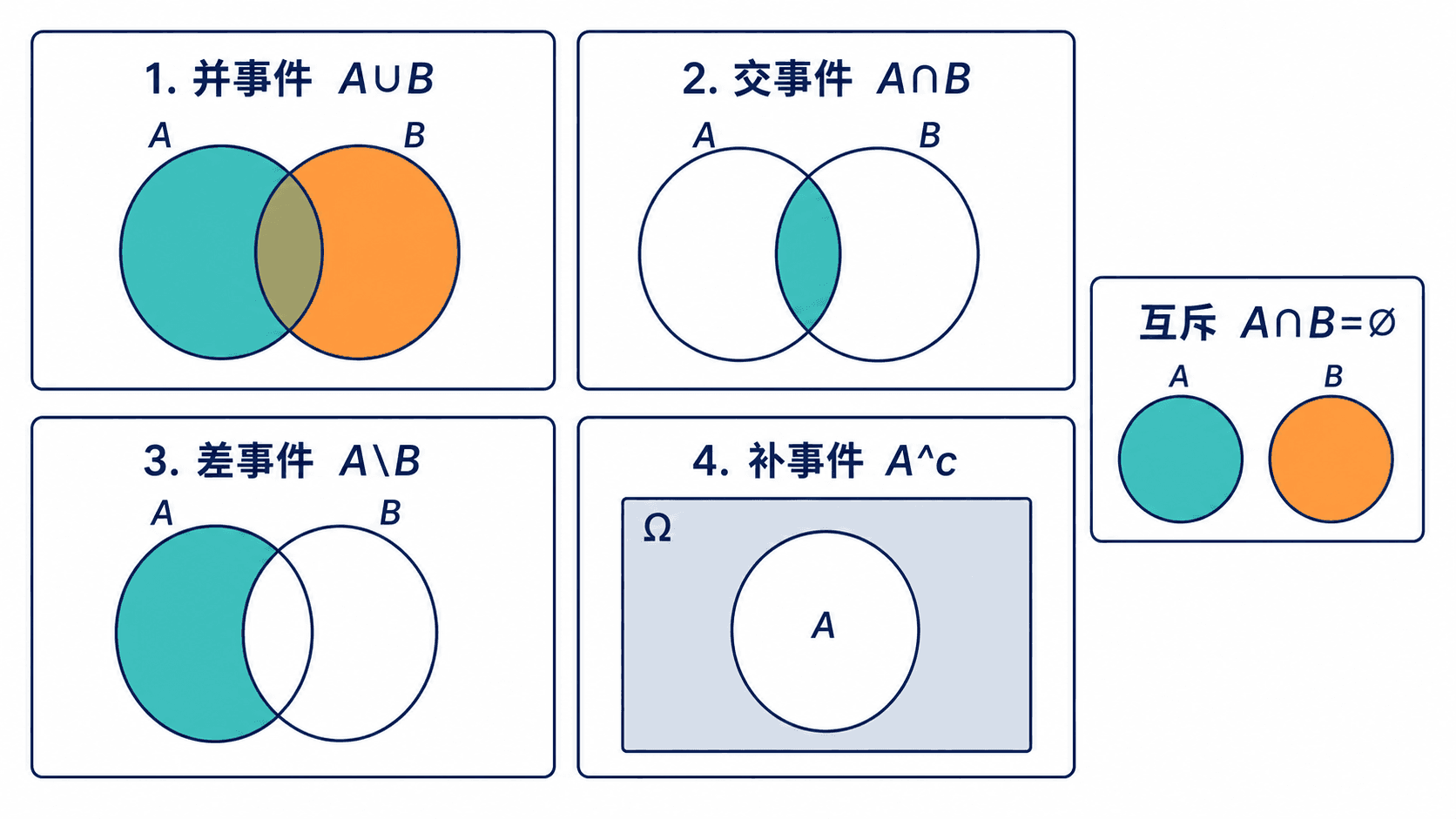 事件运算把自然语言中的“或、且、非”改写成集合关系。
事件运算把自然语言中的“或、且、非”改写成集合关系。
互斥和对立是两个容易混淆的词。若 A∩B=∅,则 A 与 B 互斥;它们不能在同一次试验中同时发生。若 B=Ac,则 与 对立;它们不仅互斥,而且合起来填满整个样本空间:
A∩Ac=∅,A∪Ac=Ω
掷骰子时,“点数为 1”和“点数为 2”互斥,但不是对立,因为还可能掷出 3、4、5、6。“点数为偶数”和“点数为奇数”才是一对对立事件。
概率公理:给事件赋值的规则
在有限样本空间里,我们常把每个子集都看作事件。到了无限样本空间,技术上需要先规定哪些子集可以作为事件;这类事件集合要能承受补集、并集等运算。入门阶段可以先记住一句话:概率不是给单个“说法”随意打分,而是给一族事件集合赋值。
概率函数 P 把事件映到一个数。Kolmogorov 公理把概率函数限制为满足三条规则。
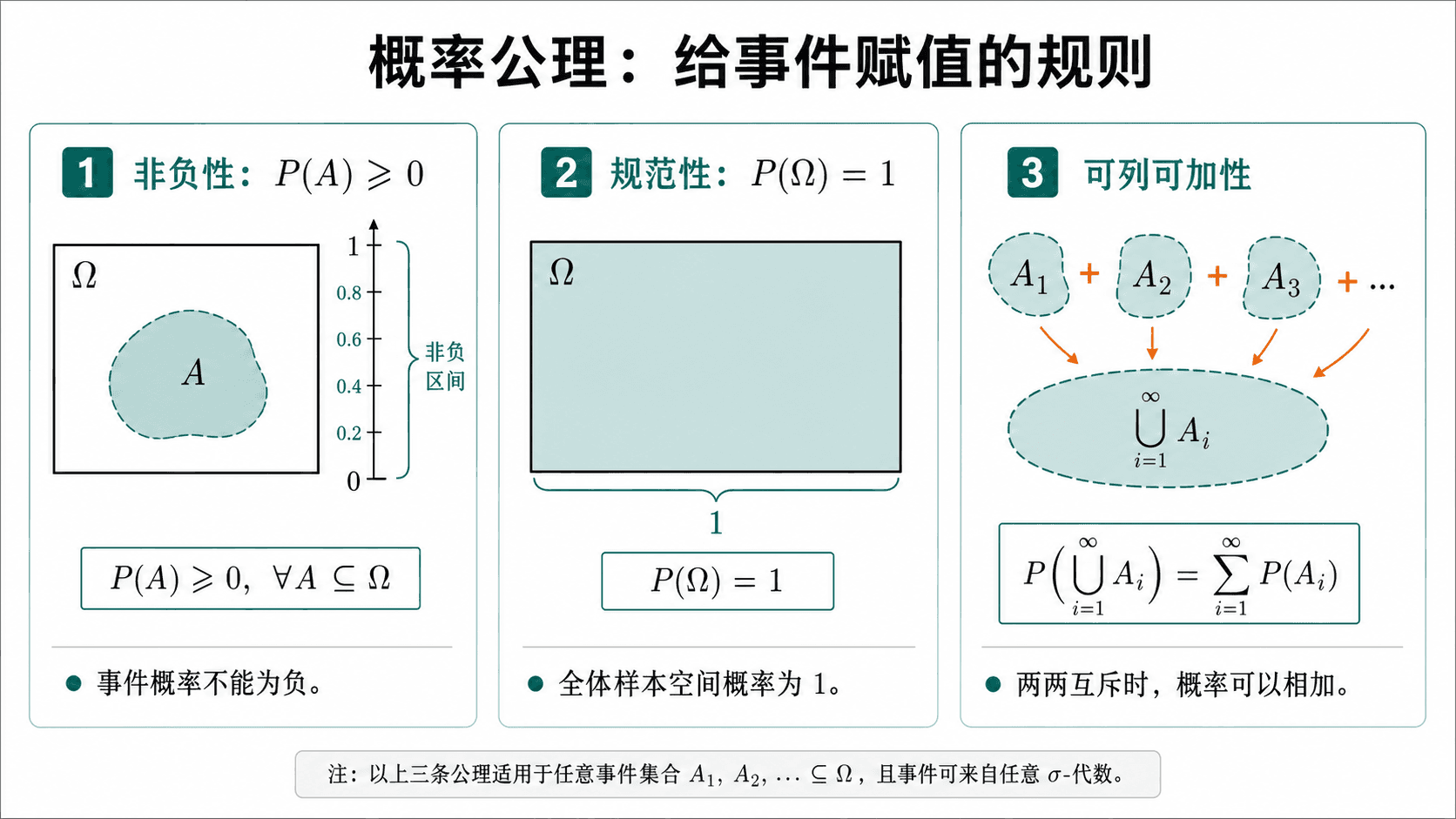 三条公理给概率赋值划出边界:不能为负,总体为一,互斥事件可以相加。
三条公理给概率赋值划出边界:不能为负,总体为一,互斥事件可以相加。
第一,非负性。对任意事件 A,
P(A)≥0
第二,规范性。整个样本空间必然发生,因此
P(Ω)=1
第三,可列可加性。若事件 A1,A2,… 两两互斥,即 Ai∩ 对 成立,则
P(i=1⋃∞Ai)=
有限样本空间中常用的是有限可加性:如果 A 与 B 互斥,那么
P(A∪B)=P(A)+P(B)
公理不是用来告诉我们某个硬币正面概率一定是 1/2。它们规定“什么样的赋值可以称为概率”。至于具体数值来自哪里,要看模型假设、对称性、实验频率或已有资料。
从公理推出常用规则
许多熟悉的概率公式都可以从三条公理推出。这样做的好处是:当题目换成不等可能模型、连续模型或分层模型时,我们仍然知道哪些规则可靠。
空事件和补集
空事件的概率为零:
P(∅)=0
因为 Ω 与 ∅ 的并仍是 Ω,且二者互斥,所以
P(Ω)=P(Ω∪∅)=P(Ω)+P(∅)
两边相减得到 P(∅)=0。
补集公式来自 A 与 Ac 互斥并且并为 Ω:
1=P(Ω)=P(A∪Ac)=P(A)+P(A
因此
P(Ac)=1−P(A)
这个公式常用于“至少一次”“没有一个”“不全是”这类问题。直接列事件很麻烦时,先算补集往往更稳。
单调性和差事件
如果 A⊆B,则 B 可以拆成互斥的两部分:
B=A∪(B∖A)
由可加性,
P(B)=P(A)+P(B∖A)
因为 P(B∖A)≥0,所以
P(A)≤P(B)
同理,A∖B 与 A∩B 互斥,且并为 A,因此
P(A∖B)=P(A)−P(A∩B)
两个事件的加法公式
如果 A 和 B 不互斥,直接把 P(A) 与 P(B) 相加会把交集 A∩B 算两次。修正后得到
P(A∪B)=P(A)+P(B)−P(A∩B)
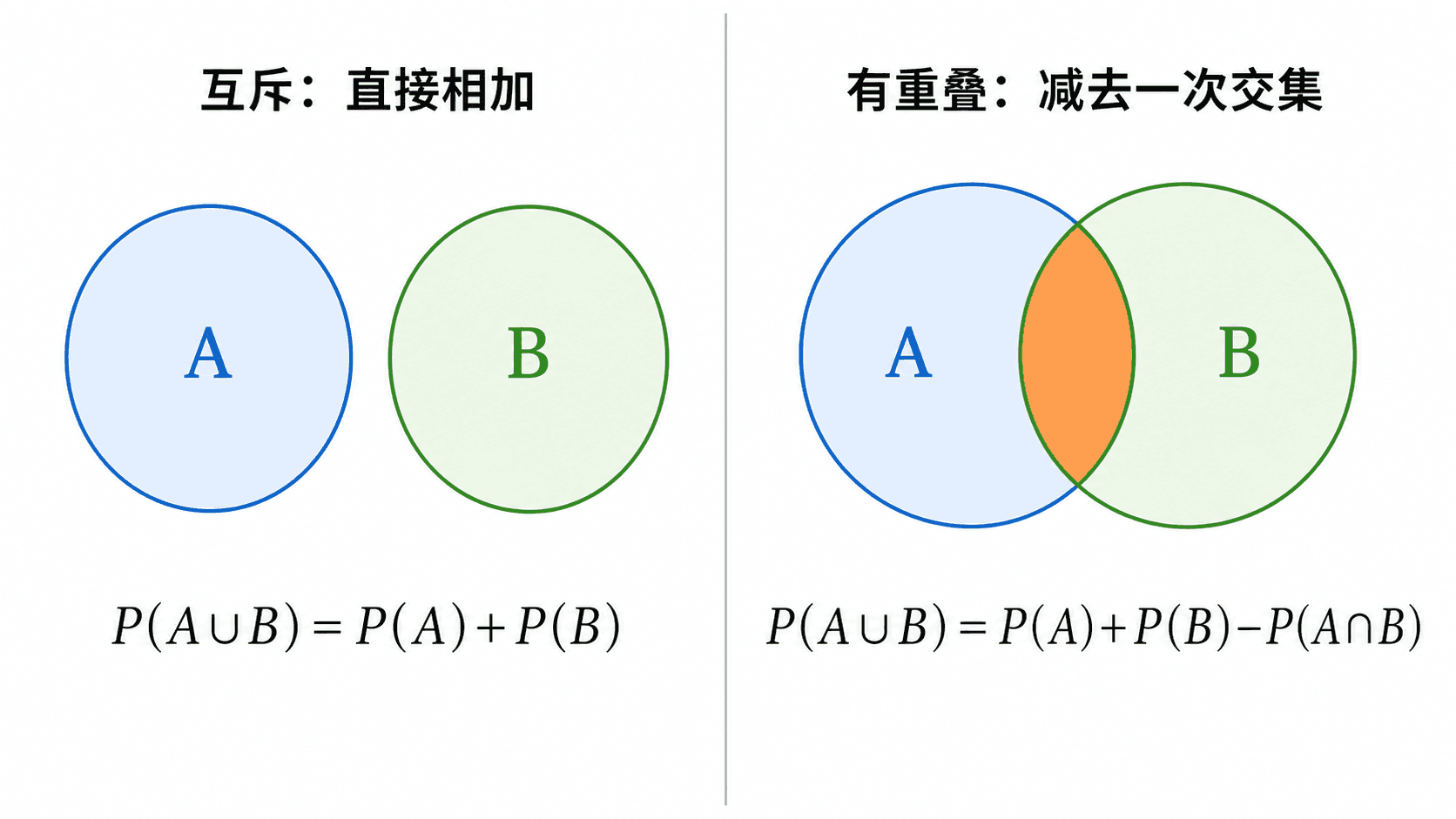 互斥时可以直接相加;有重叠时要扣掉被重复计算的交集。
互斥时可以直接相加;有重叠时要扣掉被重复计算的交集。
先把 A∪B 拆成互斥的三块:A∖B、A∩B、。这三块不会同时发生,合起来正好是 。
容斥:修正重复计数
容斥原理是加法公式的推广。它处理的核心问题很朴素:先把多个事件概率加起来会重复计算交叠区域,于是要逐层修正。
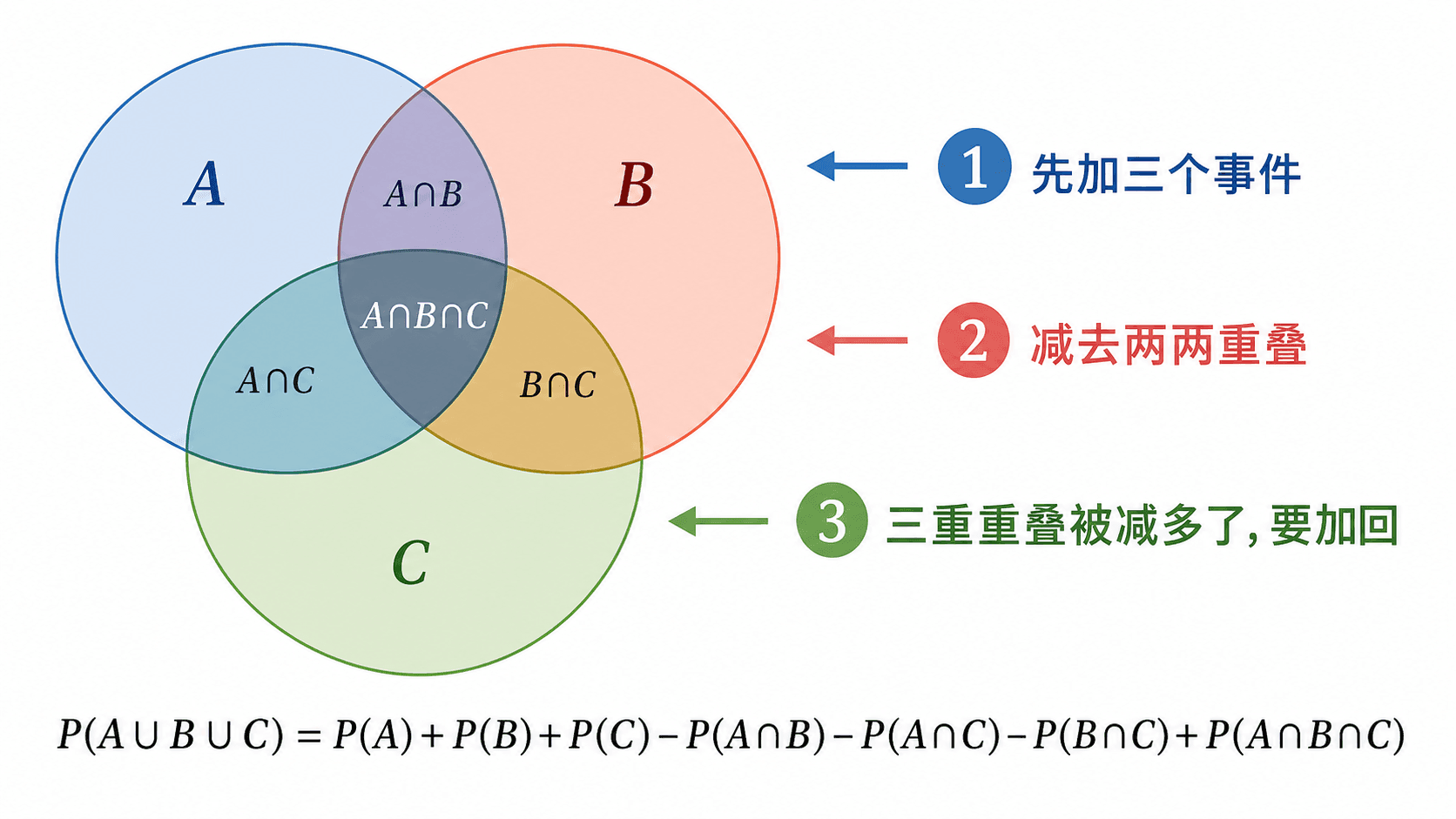 三个事件的容斥要先减去两两交集,再把被减多的三重交集加回。
三个事件的容斥要先减去两两交集,再把被减多的三重交集加回。
三个事件时,
P(A∪B∪C)
为什么最后要加回三重交集?一个同时属于 A、B、C 的样本点,在第一行被加了 3 次;在第二行出现在三个两两交集中,又被减了 3 次。此时它的净次数是 0,但并集中应当数 1 次,所以最后加回一次。
例题:某班 50 人中,30 人参加数学社,22 人参加编程社,12 人两个社团都参加。至少参加一个社团的人数是多少?若随机抽一名学生,抽到至少参加一个社团的概率是多少?
设 A 为“参加数学社”,B 为“参加编程社”。题目给出 ∣A∣=30、∣B∣=、。
古典概型的边界
古典概型是最早也最常见的概率模型之一。若样本空间有限,并且每个样本点等可能,则对任意事件 A,
P(A)=∣Ω∣∣A∣
这个公式非常有用,但它有两个前提:有限、等可能。任何一个前提缺失,都不能直接套“有利情况数除以总情况数”。
 古典概型能数样本点,但前提是样本点确实等可能。
古典概型能数样本点,但前提是样本点确实等可能。
例如掷两枚公平骰子并求“点数和至少为 10”的概率。若使用有序对样本空间,36 个样本点等可能。满足和至少为 10 的有
(4,6),(5,5),(6,4),(5,6),(6,5),(6,6)
所以概率是
366=61
如果改用点数和样本空间 {2,3,…,12},事件看起来是 {10,11,12},但不能写成 3/11,因为 11 个点数和不等可能。样本空间可以换,但概率赋值也必须跟着换。
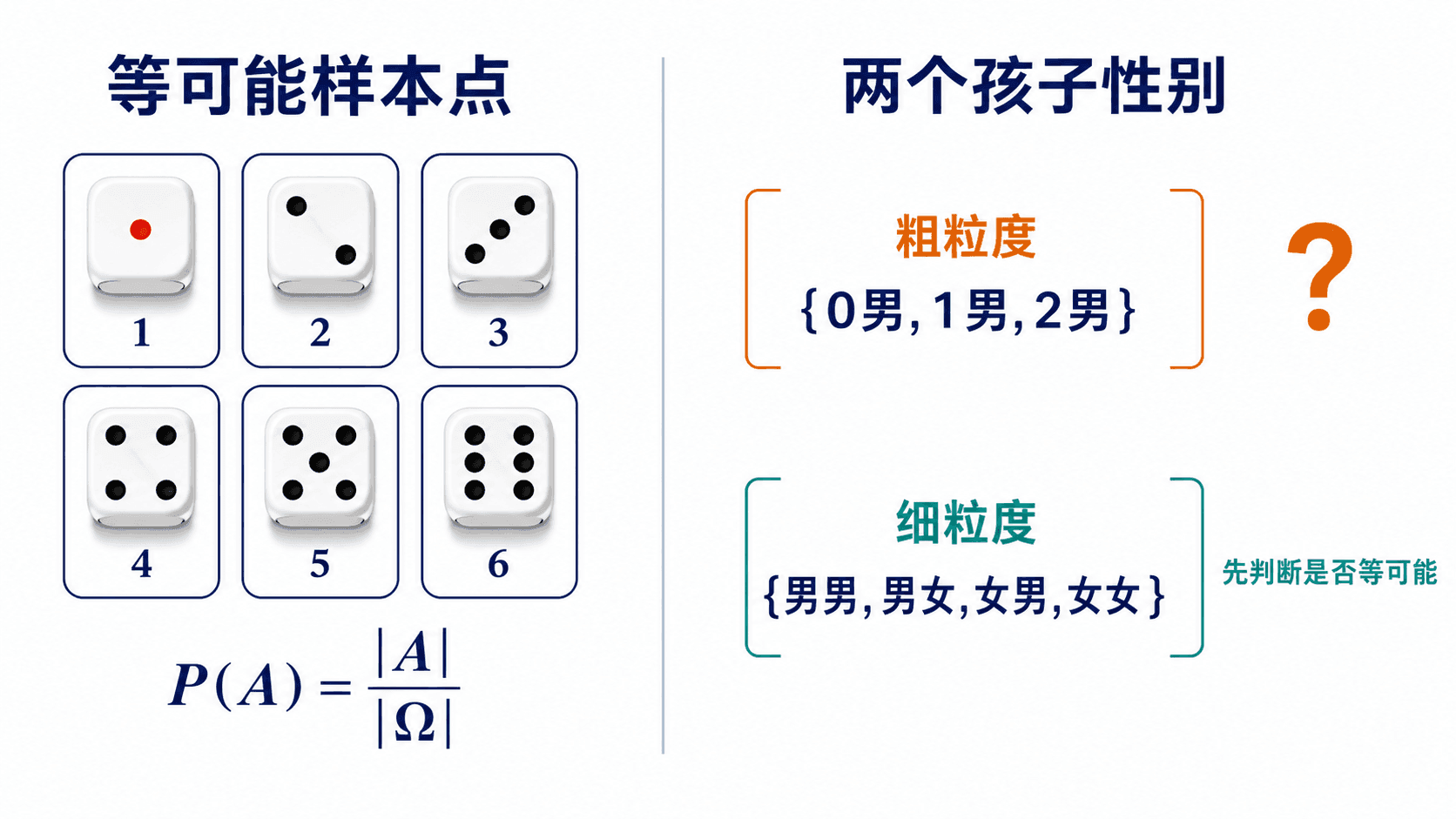
再看“两个孩子性别,至少一个是男孩”的例子。如果模型假设每个孩子男、女概率相同且相互独立,细粒度样本空间是
{男男,男女,女男,女女}
这四个样本点等可能,至少一个男孩的概率是 3/4。若直接用 {0个男孩,1个男孩,2个男孩} 作为样本空间,再把三种情况当作等可能,就会得到错误的 2/3。错误不在样本空间写得粗,而在粗粒度样本点没有等可能。
古典概型的公式不是“只要题目里有有限个选项就能用”。先问两个问题:样本点是否有限?样本点是否等可能?如果答案没有被题目条件或模型假设支持,就需要重新建模。
例题:把语言翻译成集合
至少一次出现 6
连续掷两次公平骰子,求至少一次出现 6 的概率。
用有序对样本空间 Ω={(i,j):i,j∈{1,2,3,共有 36 个等可能样本点。
抽到红牌或人头牌
从一副标准 52 张扑克牌中随机抽 1 张,求“抽到红牌或人头牌”的概率。这里人头牌指 J、Q、K。
设 A 为“红牌”,B 为“人头牌”。有 ∣A∣=26,∣B∣=。
练习
- 连续抛三次硬币,写出样本空间,并写出事件“恰好两次正面”。
样本空间可以写为 {HHH,HHT,HTH,HTT,THH,THT,TTH,TTT}。事件“恰好两次正面”为 。如果硬币公平且三次独立,这个事件概率为 。
- 掷一枚公平骰子,设 A={2,4,6},B={1,2,3}。求 A∪B、、,并判断 和 是否互斥。
A∪B={1,2,3,4,6},A∩B={2},。因为 不是空集,所以 和 不互斥。
- 已知 P(A)=0.63,求 P(Ac)。
由补集公式,P(Ac)=1−P(A)=1−0.63=0.37。
- 已知 P(A)=0.45,P(B)=0.38,P(A∩B)=0.12。求 。
用两事件加法公式,P(A∪B)=0.45+0.38−0.12=0.71。
- 一个有限样本空间有三个样本点 ω1,ω2,ω3。若有人给出 P({、、,这是否是合法的概率模型?
不是。虽然三个数相加为 1,但第三个样本点概率为负,违反非负性公理。概率模型必须同时满足非负性和总概率为 1。
本章检查单
学完本章后,可以用下面几句话检查自己是否真的建好了概率模型。
- 我能说清随机试验记录的是什么,样本点代表什么。
- 我能把自然语言中的“或、且、非、至少、都不”翻译成事件运算。
- 我知道互斥只表示不重叠,对立还要求合起来等于整个样本空间。
- 我能从概率公理推出补集公式、单调性和加法公式。
- 我会在使用古典概型前检查“有限”和“等可能”两个前提。