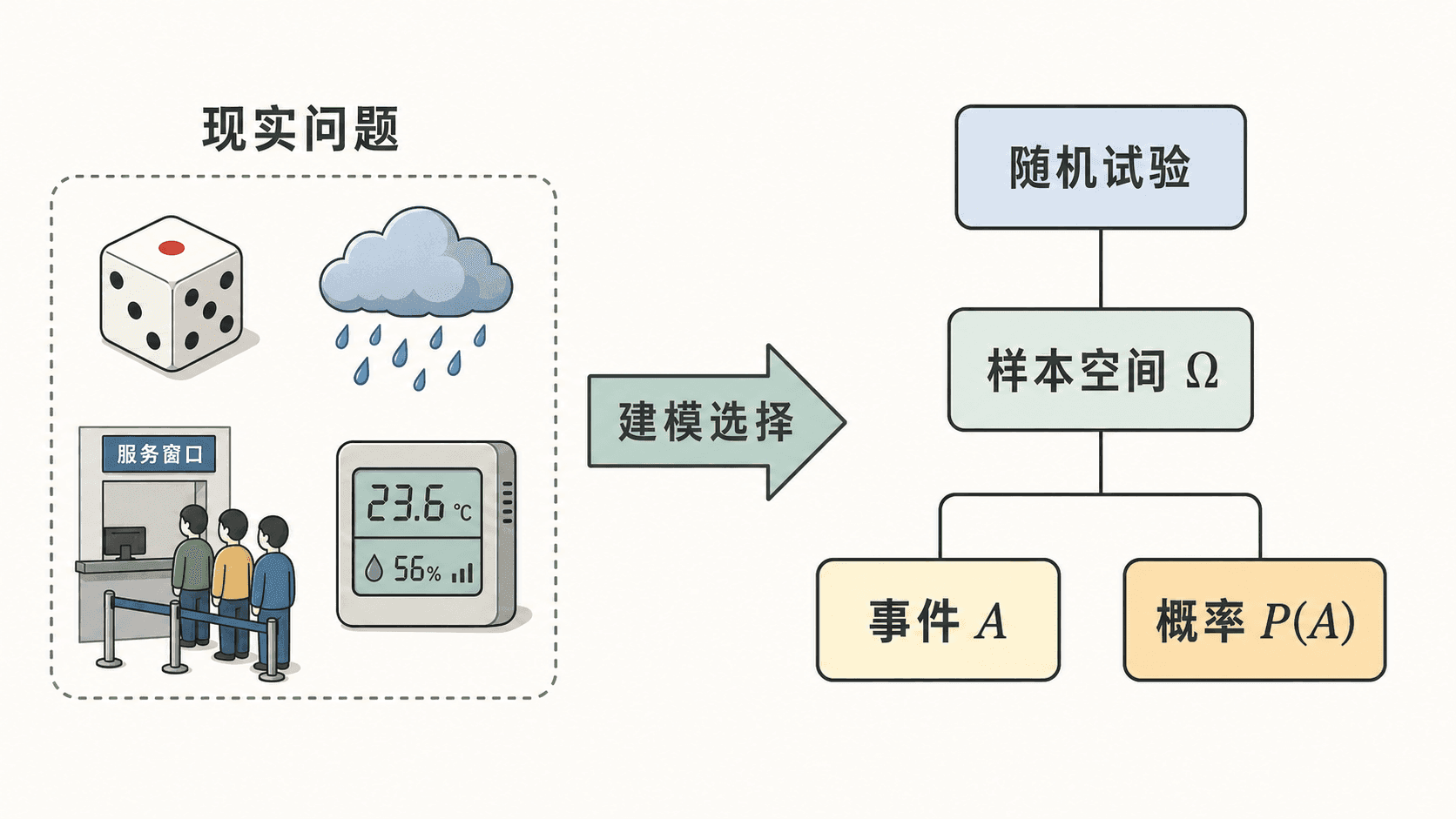
概率论研究什么:随机性、模型与不确定性
概率论研究的不是“会不会发生奇怪的事”,而是当结果不能事先确定时,怎样用清楚的数学对象描述可能结果、关心的事件和事件发生的可能程度。
这门课会一步步建立随机变量、分布、期望、方差和极限定理。第一章先不急着计算复杂概率,而是回答一个更靠前的问题:面对一个现实中的不确定现象,我们究竟在建什么模型?
从随机试验开始
概率论通常从随机试验开始。这里的“试验”不是一定要在实验室里做,它指一种可以在相近条件下重复观察的过程。掷一枚硬币、抽取一件产品、记录明天是否下雨、观察一位顾客的等待时间,都可以看成随机试验。
一个随机试验有三个基本特征:它可以重复;一次试验的具体结果事先不能确定;所有可能结果至少可以被列出或描述。
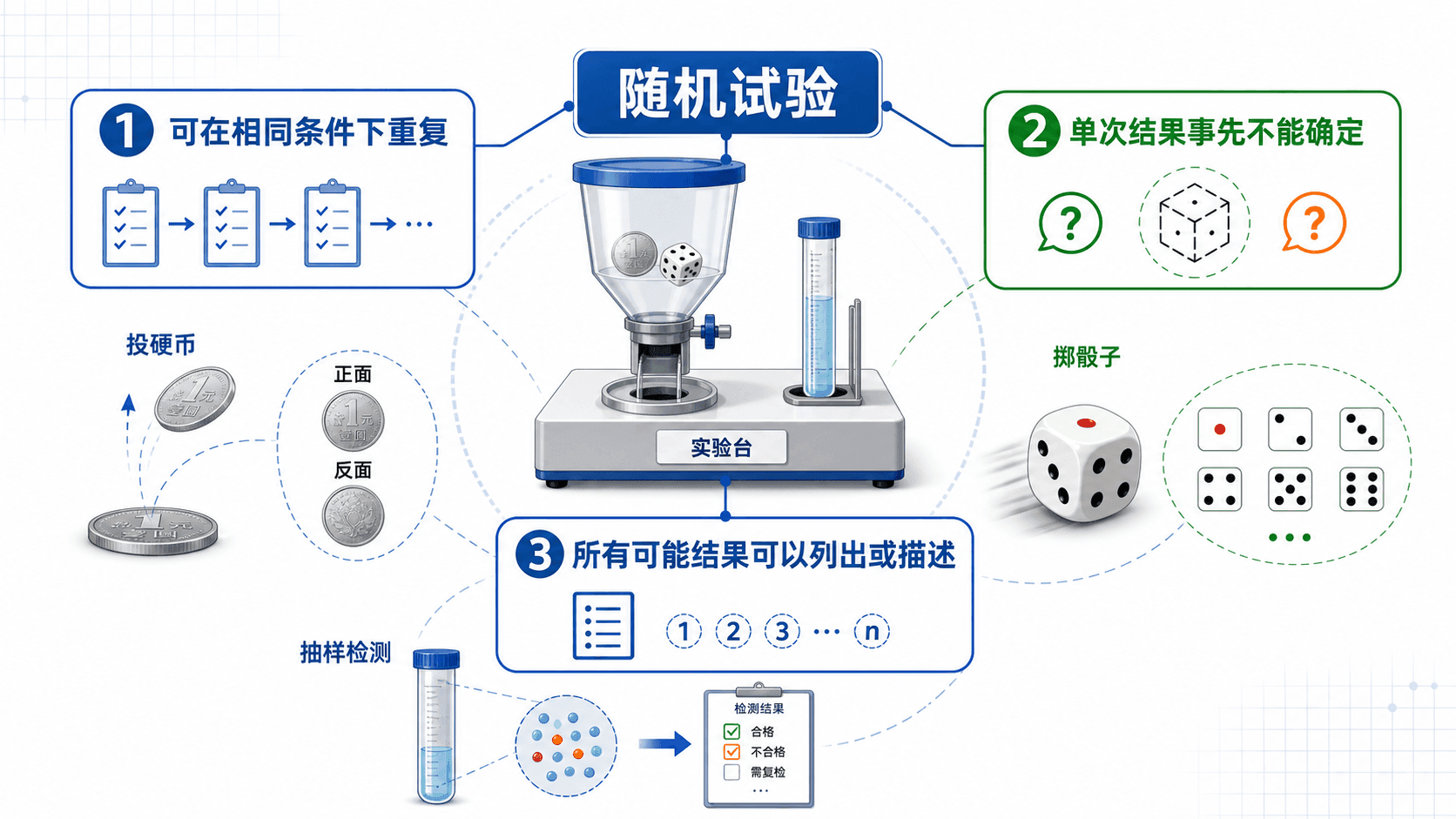
这三个特征缺一不可。只说“明天会发生什么”太宽泛,因为可能结果没有被清楚描述;只说“这枚硬币已经落地,结果是正面”也不是概率问题,因为结果已经知道;只说“这位同学未来的人生轨迹”也很难直接建模,因为可重复条件和结果边界都不清楚。
下面几个例子展示了“随机试验”在不同语境下的含义。
随机试验不是现实本身,而是我们为了回答某个问题而选出的观察方式。换一个问题,同一个现实过程就可能变成另一个随机试验。
样本空间是模型的边界
随机试验的所有可能结果组成样本空间,通常记作 。样本空间不是从现实里自动掉出来的,它由研究问题决定。
比如掷同一枚骰子,如果我们关心点数,那么样本空间可以写成:
如果我们只关心点数是奇数还是偶数,那么样本空间可以改成:
如果我们只关心是否大于 4,那么样本空间又可以写成:
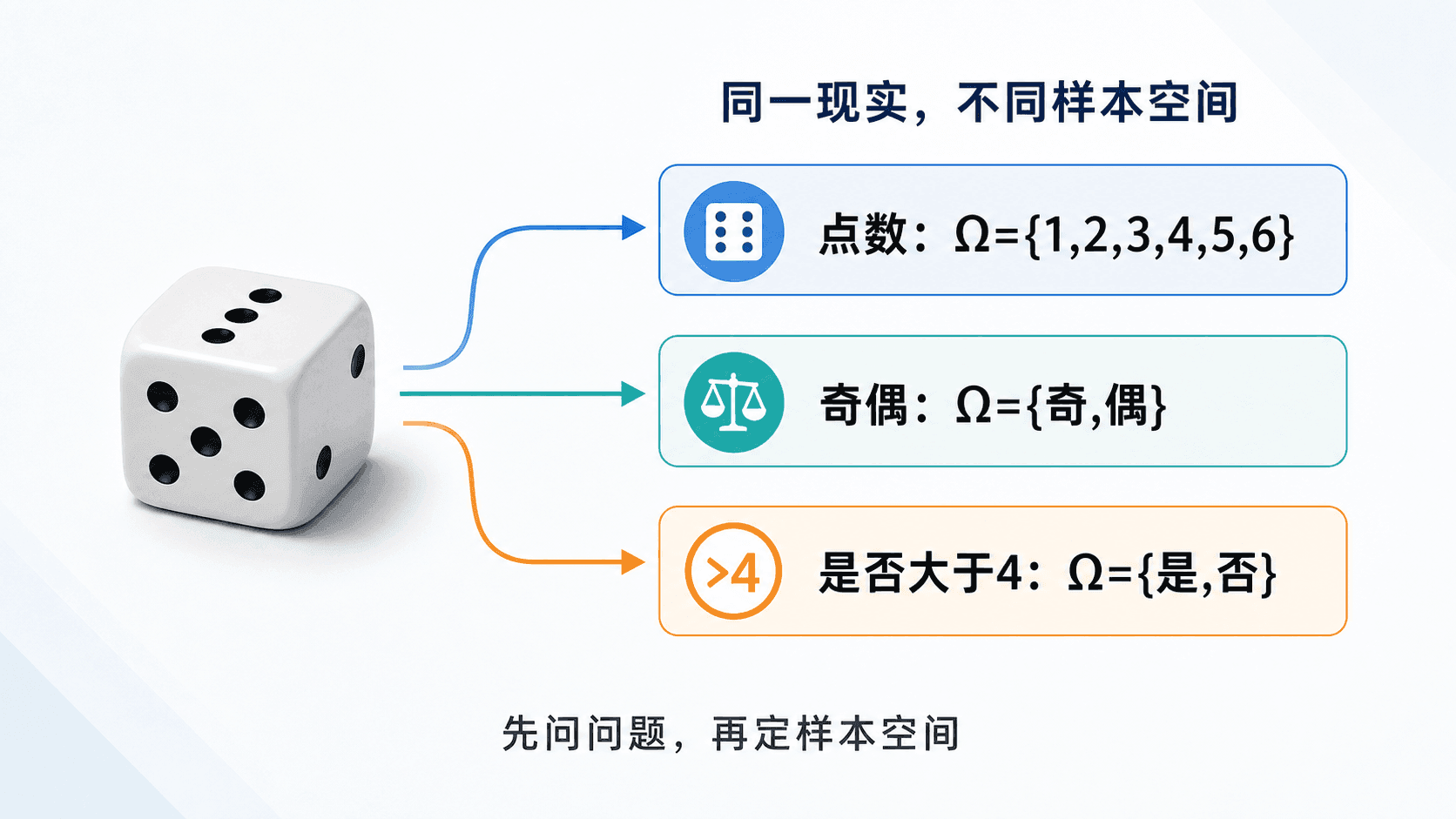
这就是概率建模的第一步:先决定要保留哪些信息,也要承认哪些信息被舍弃。样本空间越细,能回答的问题越多,但模型也可能更复杂;样本空间越粗,模型越简洁,但它不能回答被你合并掉的问题。
事件是样本空间中的一部分结果。若掷骰子的样本空间是 ,那么“点数为偶数”这个事件可以写成:
若样本空间已经被简化为 ,同一个意思就变成了事件 。两种写法都可以,但它们属于不同的模型。
初学时常见的错误,是先套公式,再想样本空间。正确顺序应当是:先说清楚一次试验记录什么,再写出样本空间,最后才谈事件和概率。
概率模型由三件事组成
一个概率模型至少要交代三件事:样本空间 、我们允许讨论的事件,以及给事件赋值的概率规则 。在本章可以先把事件理解为“样本空间中一类我们关心的结果”;更严格的事件系统会在后面章节中逐步出现。
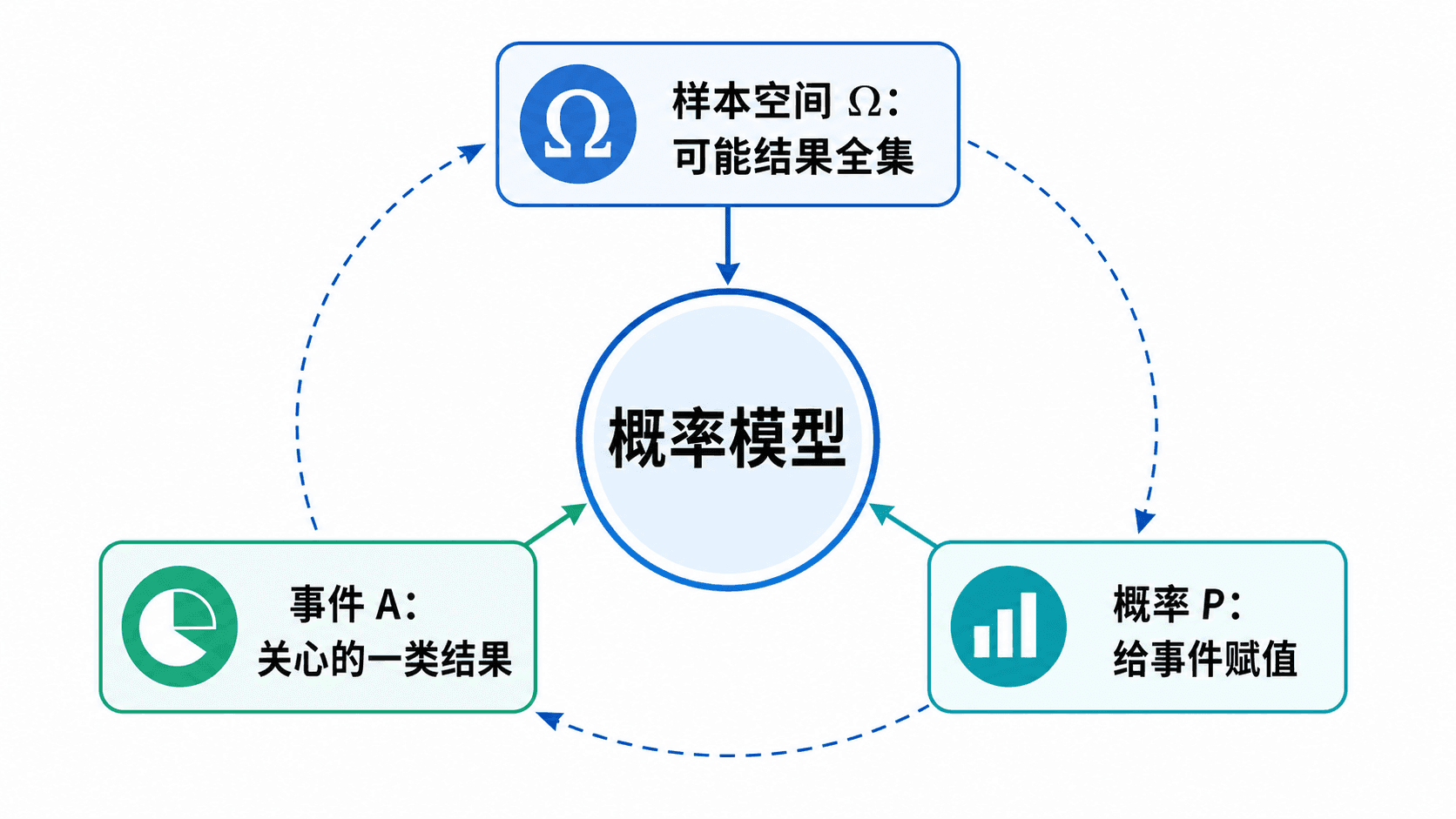
概率赋值的意思是:对每个可讨论的事件 ,给出一个数 ,表示事件 在模型中的可能程度。这个数必须在 0 和 1 之间。事件不可能发生时概率是 0;事件必然发生时概率是 1。
本课程后面会正式学习概率公理。现在只需要先记住一个朴素版本:概率不是随便填的分数,它要和事件之间的包含、互斥、合并关系相容。例如,如果 和 不可能同时发生,那么“ 或 发生”的概率应当由两者的概率相加得到:
这个公式的条件是 与 互斥。省掉这个条件,公式就会出错。
等可能只是一个特殊模型
很多人第一次接触概率,会把概率直接理解成“有几个有利结果除以几个总结果”。这种算法只适用于等可能模型。掷一枚均匀骰子时,6 个点数通常被建成等可能结果,所以“点数为偶数”的概率可以写成:
但现实中很多样本空间并不等可能。比如“明天是否下雨”的样本空间可以是 ,但这不意味着下雨概率就是 。两个结果不等于两个结果等可能。
先写研究问题。比如“随机抽取一件产品,它是否合格?”这个问题只关心合格状态,不关心产品编号、生产时间和颜色。
再写随机试验。一次试验是从当前批次中按约定方式抽取一件产品,并记录它的检测结果。
接着写样本空间。若只记录合格状态,可以取 。
频率稳定给模型校准
概率模型给的是对不确定性的描述。它不是在承诺下一次结果一定怎样,而是在描述大量重复下的稳定结构。
假设事件 在前 次重复试验中出现了 次,则事件 的相对频率是:
如果模型认为 ,我们并不要求前 10 次、前 20 次的相对频率都非常接近 0.5。短期里,相对频率可能摇摆很大。重复次数增加后,如果试验条件保持相近,相对频率通常会在模型概率附近稳定下来。
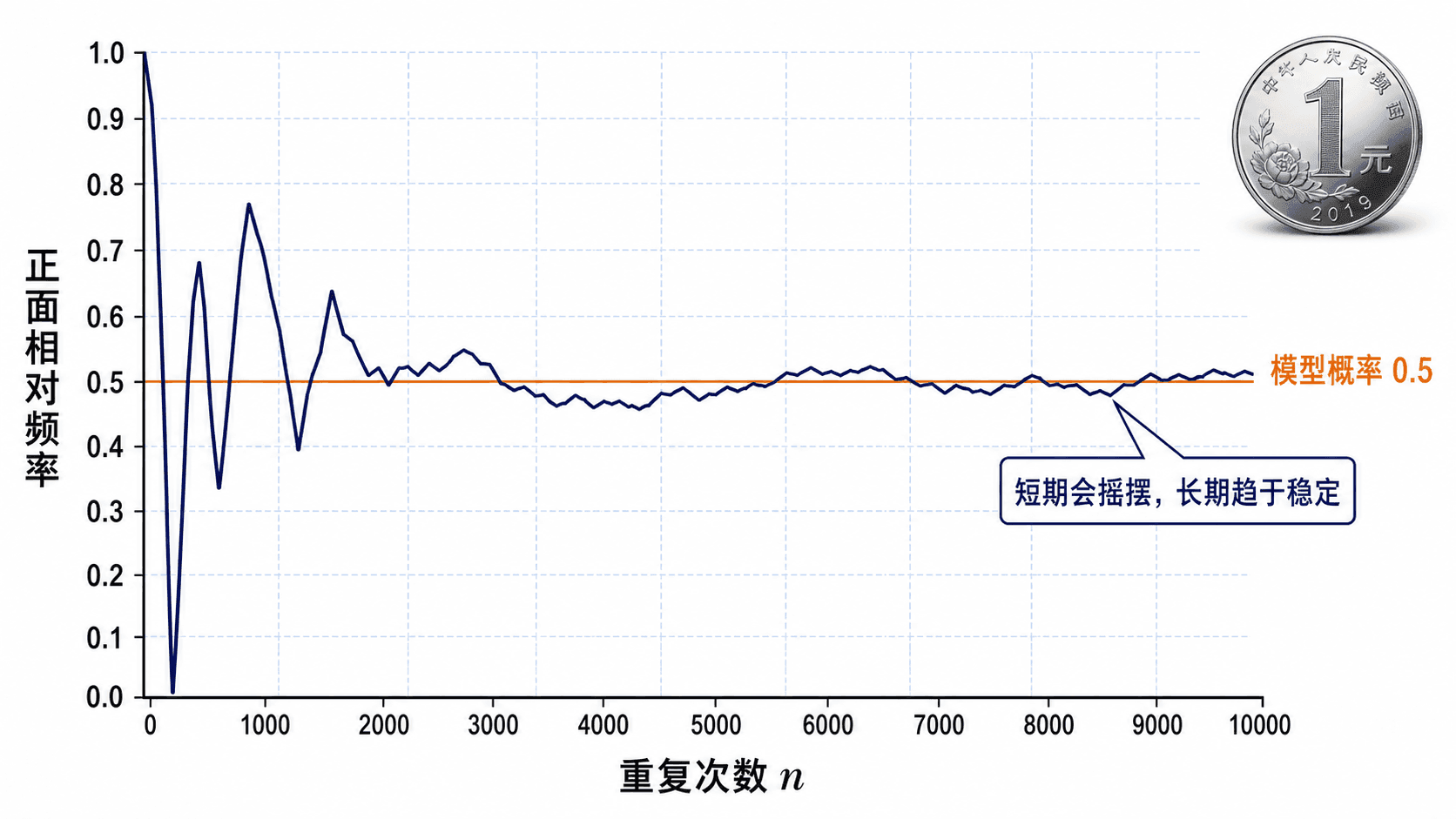
频率稳定很重要,因为它让概率模型有了可以检验的抓手。若一个硬币模型声称正面概率是 0.5,但在严格控制条件下抛了 10000 次,正面只出现约 3000 次,我们就有理由怀疑硬币、抛掷机制或记录方式出了问题。
不过,频率稳定不能被读成“短期补偿”。如果一枚均匀硬币已经连续出现 5 次反面,下一次正面的概率仍然是 0.5。长期稳定不是靠下一次结果“必须补回来”,而是靠很多次独立重复的平均效果逐渐显现。
“最近反面太多,下一次正面概率应该更大”是典型误解。除非模型本身发生改变,过去的短期波动不会自动改变下一次试验的概率。
不确定性不只一种
概率论里的不确定性可以来自不同地方。有些不确定性来自系统本身,比如放射性衰变的时间;有些来自我们掌握的信息不足,比如不知道明天某地具体天气;有些来自观测误差,比如传感器读数有噪声;还有些来自模型简化,比如我们把复杂的人群行为压缩成“支持”和“不支持”两类结果。
这些不确定性在数学上都可以用概率来表达,但建模含义不同。
因此,概率不是一种单一语气的“猜”。在长期重复的场景中,概率常常和频率稳定联系在一起;在一次性决策中,概率也可以表达基于当前信息的合理信念;在科学测量中,概率还能描述误差和置信程度。本课程主要学习共同的数学语言,让这些场景都能被清楚计算和比较。
同一个概率数值,在不同场景中可能有不同解释。课程中的数学规则保持一致,但建模时要说明概率来自对称性、历史频率、物理机制、数据估计,还是主观信息。
模型假设不是现实本身
概率模型要有假设。假设不是装饰,而是模型能够计算的原因。我们常见的假设包括独立性、同分布、等可能、概率稳定、抽样代表性和测量误差可忽略。
比如抽样调查中,我们可能想估计某城市居民对一项政策的支持率。若样本只来自某个社交平台的活跃用户,这个样本很可能不能代表全体居民。此时,即使样本量很大,模型也可能偏离问题本身。
再比如网页 A/B 测试中,我们可能假设每个用户的点击行为相互独立。但如果用户之间会互相推荐、同一个人反复访问、或者不同时间段流量结构不同,独立同分布的假设就需要重新检查。
判断一个模型是否合适,不是看它有没有公式,而是看它回答的问题是否和现实问题一致,假设是否可以接受,数据是否能校准它。
一个建模检查清单
面对新的概率问题,可以按下面的顺序检查。
说清楚现实问题。不要先写公式,而要先写“我想预测、比较、控制或解释什么”。
定义一次随机试验。一次试验到底观察一个人、一件产品、一天、一次点击,还是一段时间内的总数。
写出样本空间和事件。样本空间规定模型保留哪些结果,事件规定你真正关心哪些结果。
说明概率从哪里来。它可能来自对称性、长期频率、历史数据、专家判断或一个更深层的物理机制。
一个完整例子
考虑一个简单问题:某工厂要估计一批零件的不合格概率,并决定是否需要调整生产线。
这个问题听起来像质量管理,但它的概率结构很清楚。一次随机试验可以定义为“从当前批次中按规定方式抽取一件零件,并记录检测结果”。如果只关心合格状态,可以取样本空间:
令事件 。模型中真正关心的是 ,也就是一件随机抽取零件不合格的概率。
如果过去稳定生产时,不合格比例大约在 1% 到 2% 之间,那么一个初始模型可能设为 。随后抽检 500 件,若发现 26 件不合格,则相对频率是:
这个结果明显高于 0.015。它不自动证明模型“错了”,但会提出具体问题:这 500 件是否真的是随机抽取?检测标准是否变化?生产线是否换了材料或设备?是否存在同一批次内部相关性?概率论不替我们回答这些工程问题,但它把问题定位得更清楚。
好的概率模型不是把现实变简单就结束,而是把“哪里不确定、如何观察、用什么假设、怎样校准”写清楚。计算只是这个过程的一部分。
练习
- 一个应用显示“明天本地降雨概率为 70%”。如果明天没有下雨,这是否说明这个概率预报一定错误?
不一定。概率为 70% 表示在模型和当前信息下,下雨被认为更可能,但仍然允许不下雨发生。要评价预报质量,通常需要看很多相似预报的长期校准情况,例如所有报 70% 的日子中,实际下雨比例是否接近 70%。
- 掷一枚骰子,只关心“点数是否为 6”。请写出一个合适的样本空间和事件。
可以取样本空间 ,其中“是”表示点数为 6,“否”表示点数不是 6。事件 。也可以用更细的样本空间 ,此时事件 。两个模型都能回答这个问题。
- 某人说:“明天要么下雨,要么不下雨,所以明天下雨概率是 。”这句话的问题在哪里?
它把“两种可能结果”误当成“两种结果等可能”。样本空间有两个结果,只说明模型把结果分成了两类;概率赋值还需要天气系统、历史频率、预报模型和当前观测等信息支持。
- 连续抛一枚均匀硬币 8 次都出现正面。第 9 次出现反面的概率是否大于 ?
在“每次抛掷独立且硬币均匀”的模型下,第 9 次出现反面的概率仍是 。前 8 次结果会让相对频率偏离 0.5,但不会改变下一次试验的概率。
- 一个学校想通过午餐时间在食堂门口访问 200 名学生,估计全校学生每天平均自习时长。这个概率模型最需要先检查什么假设?
最需要检查样本代表性。午餐时间在食堂门口出现的学生,可能和全校学生在作息、年级、专业、住宿情况上不同。若样本不能代表总体,后续即使用复杂公式,结论也可能偏离原问题。
小结
本章的主线可以压缩成一句话:概率论先把现实中的不确定现象改写成随机试验、样本空间、事件和概率赋值,再用频率稳定与数据检查模型是否合适。
后面的章节会把这些对象变得更精确。下一章会正式学习事件运算和概率公理,也就是给本章的“概率模型”补上严格规则。