中心极限定理、正态近似与综合建模
前面几章一直在问单个随机变量或几个随机变量的分布。本章换一个角度:如果有许多相互独立、结构相似的小随机量,把它们加起来,会发生什么?
中心极限定理给出一个很强的回答。只要每个小随机量的均值和方差是稳定的,标准化后的总和常常会靠近正态分布。这个结论解释了为什么正态分布会反复出现在测量误差、抽样均值、计数近似和模拟误差中。
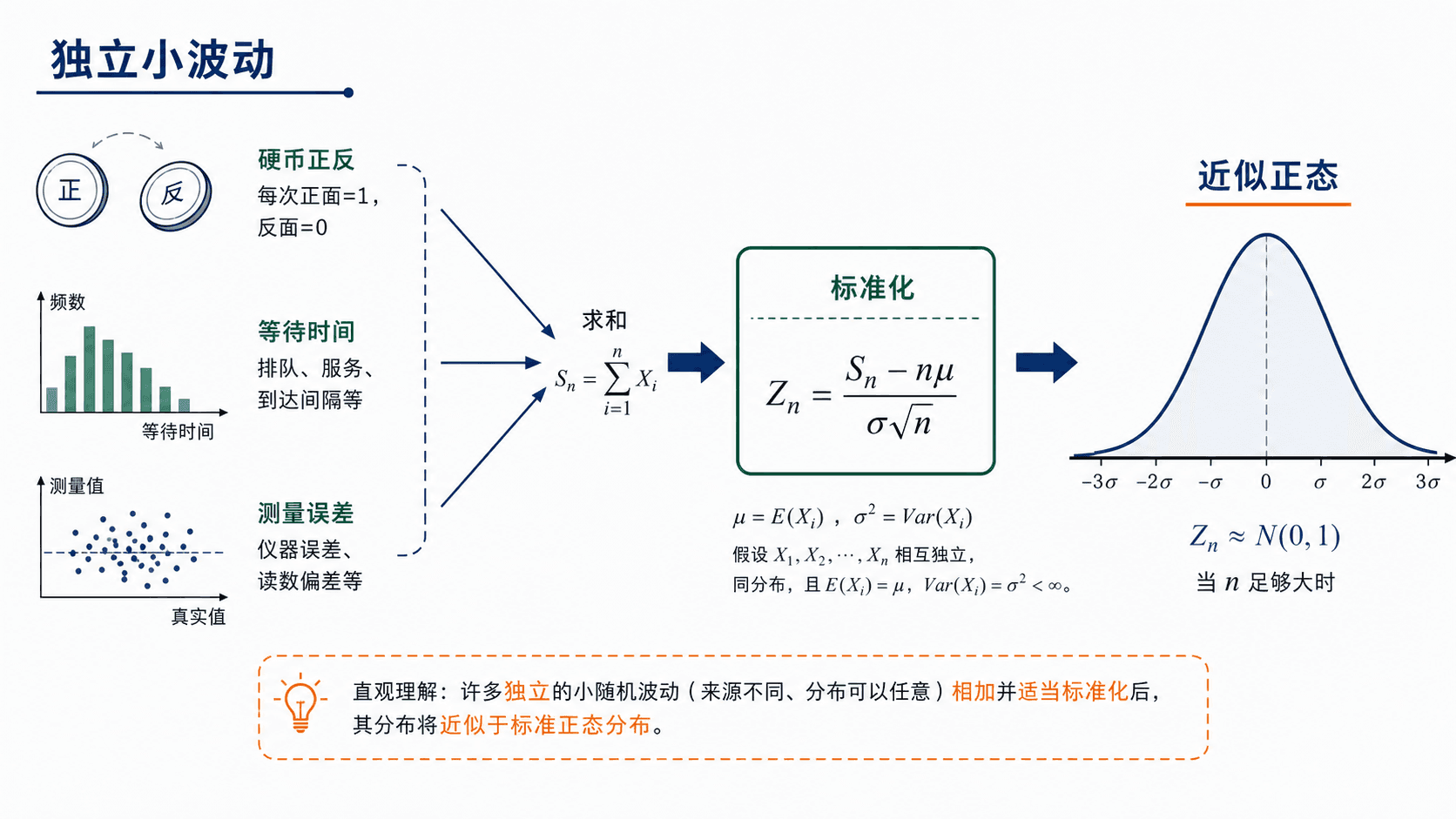 许多独立小随机波动相加后,经标准化得到的变量会逐渐接近正态钟形曲线。
许多独立小随机波动相加后,经标准化得到的变量会逐渐接近正态钟形曲线。
本章要回答的问题
大数定律告诉我们,样本均值 Xˉn 会靠近真实均值 μ。它回答的是“长期平均值会不会稳定下来”。中心极限定理回答的是另一个问题:当 Xˉn 已经很靠近 μ 时,剩下的随机波动大约长什么样。
这两个问题容易混在一起。样本量变大时,Xˉn 的分布会越来越集中;但如果把它减去 μ,再除以它自己的标准差,它的形状常常会越来越像标准正态分布。
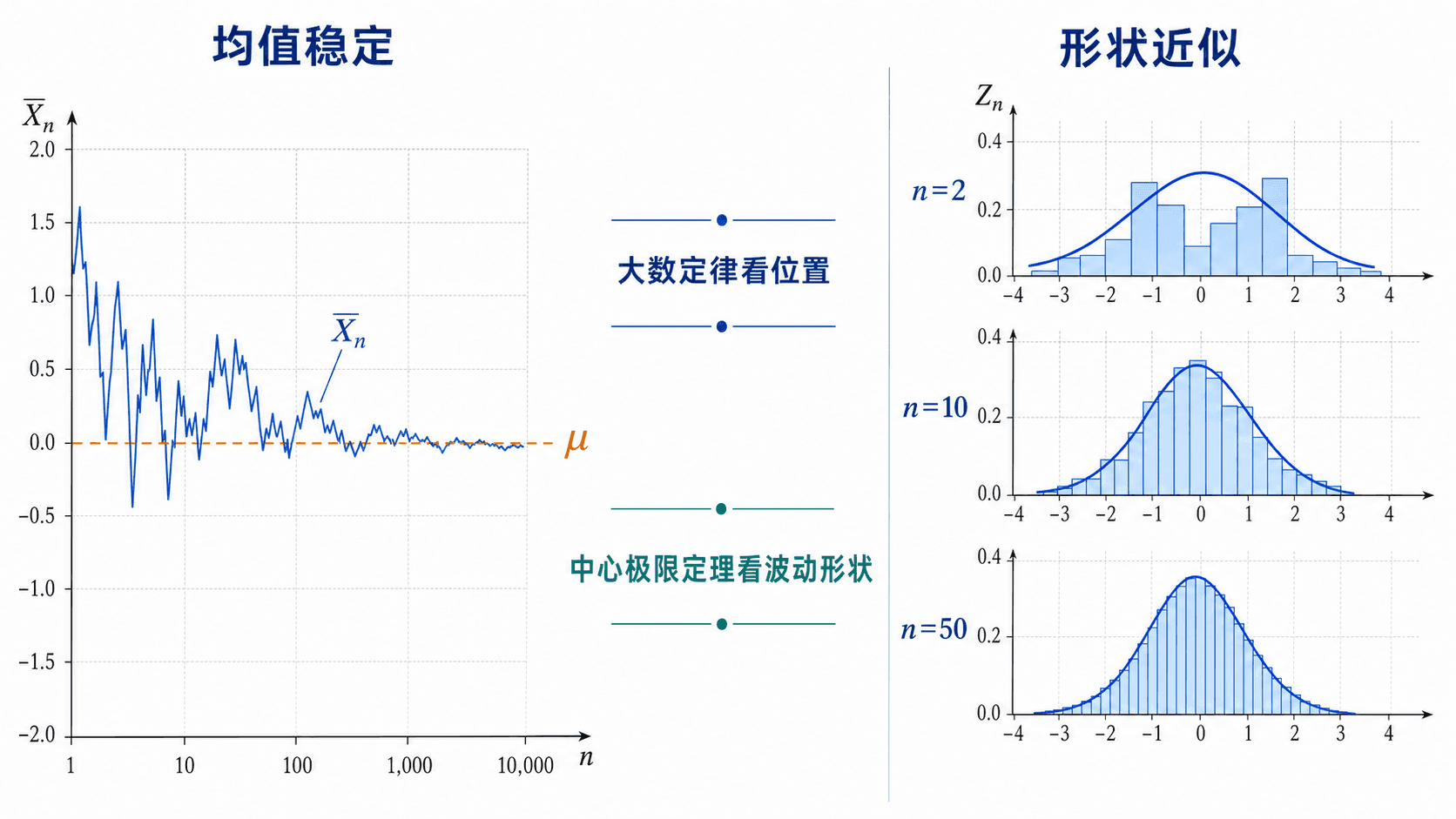 大数定律关注均值位置是否稳定,中心极限定理关注标准化波动的形状是否近似正态。
大数定律关注均值位置是否稳定,中心极限定理关注标准化波动的形状是否近似正态。
本章会把这件事落实到三类计算中:
- 用中心极限定理近似样本均值或随机变量和的概率。
- 用正态分布近似二项分布和 Poisson 分布,并处理连续性修正。
- 用中心极限定理理解蒙特卡洛估计的标准误差。
正态近似不是说原始数据一定正态,也不是说样本量大时所有问题都自动准确。它说的是,在合适条件下,标准化后的“和”或“均值”的分布可以用正态分布近似。
从和与均值开始
设 X1,X2,…,Xn 是独立同分布随机变量,公共均值和方差为
E(Xi)=μ,Var(Xi)=σ
其中 0<σ2<∞。记总和与样本均值为
Sn=X1+X2
由期望线性性和独立性可得
E(Sn)=nμ,Var(Sn)=nσ
以及
E(Xˉn)=μ,Var(Xˉ
这几条公式本身已经说明了两个尺度:总和的典型波动量级是 σn,样本均值的典型波动量级是 σ/n。中心极限定理正是沿着这个尺度去标准化。
标准化
标准化的目的,是把不同中心、不同尺度的随机量放到同一条标准正态尺上。对于总和,定义
Zn=σn
对于样本均值,同一个量也可以写成
Zn=σ/n
这两个写法完全等价。前者从总和出发,后者从均值出发。做概率计算时,常常根据题目问的是 Sn 还是 Xˉn 来选择更顺手的形式。
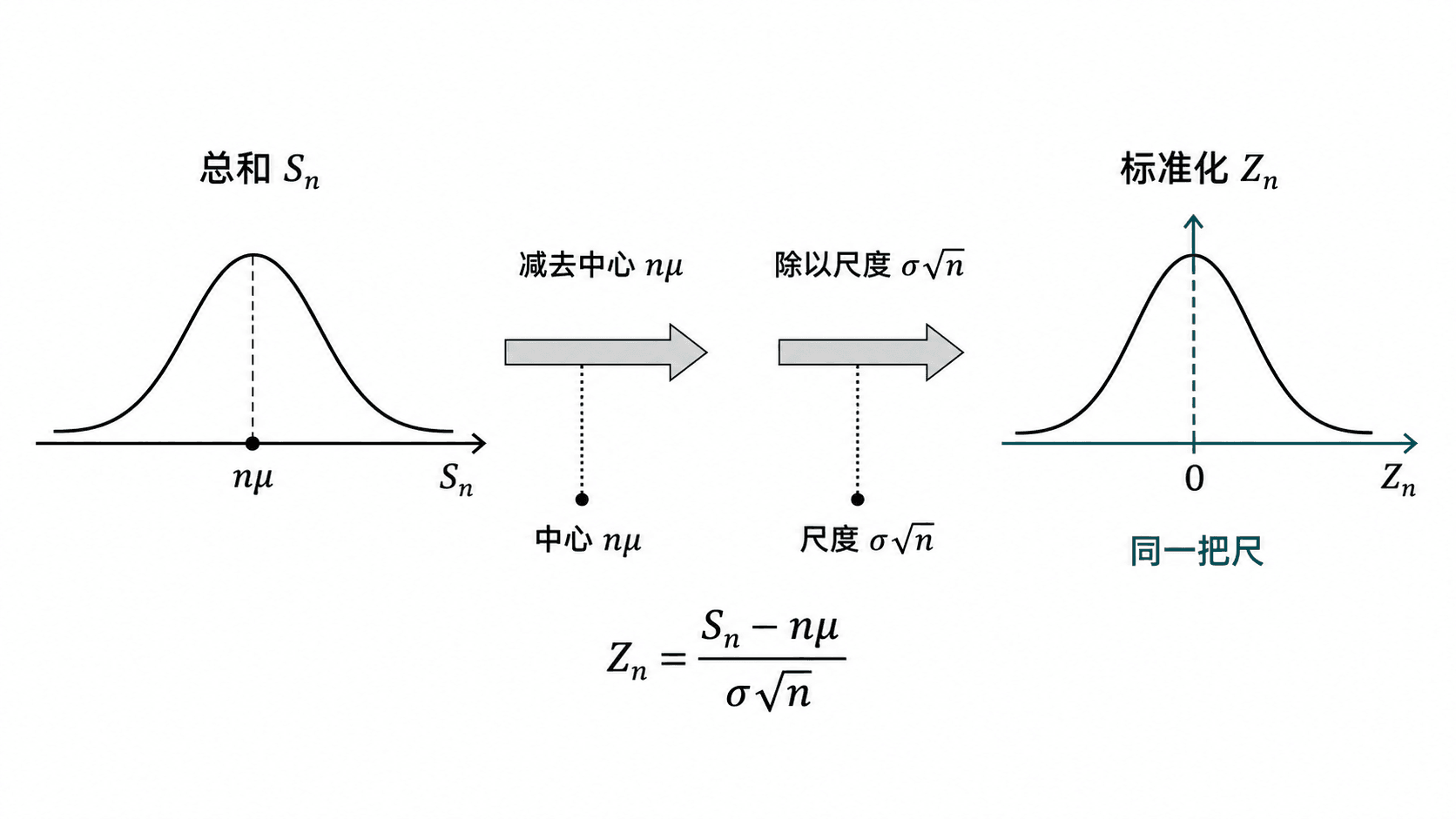 标准化把不同尺度的总和转换到同一把尺上的 Z 变量。
标准化把不同尺度的总和转换到同一把尺上的 Z 变量。
标准化时最常见的错误,是把 Sn 的标准差和 Xˉn 的标准差混用。总和的标准差是 σ,样本均值的标准差是 。
中心极限定理
中心极限定理的基本形式可以这样表述:
若 X1,X2,… 独立同分布,且 E(Xi)=、,其中 ,则
σnSn
等价地,
σ/nX
这里的 d 表示依分布收敛。它的含义是,对标准正态分布函数 Φ 的连续点 x,有
P(σnS
这不是一个关于样本均值数值极限的命题,而是关于分布形状的命题。它告诉我们,当 n 足够大时,可以近似写成
P(σnS
为什么这个结论有用
很多现实随机量本身并不正态。一次排队时间可能偏斜,一次点击行为可能是 0 或 1,一次测量误差可能有轻微偏态。可是当我们关心许多次独立重复的总和或平均值时,中心极限定理提供了一个统一近似。
以 Bernoulli 随机变量为例,若 Xi 表示第 i 次试验是否成功,成功概率为 p,则 Sn 是成功次数,满足 。中心极限定理给出
np(1−p)S
这个近似就是二项分布正态近似的来源。
大数定律与中心极限定理的区别
大数定律说
XˉnPμ
它关心 Xˉn 是否靠近 μ。中心极限定理说
σ/nX
它关心 Xˉn−μ 经过自然尺度放大后的形状。前者说明均值会稳定,后者说明稳定过程中的随机误差怎样分布。
如果把这两句话放在一起理解,就能看清样本量的作用:n 增大时,Xˉn 离 μ 的典型距离约为 σ/n;把这个距离除掉后,剩下的标准化误差近似服从 。
把中心极限定理用于计算
中心极限定理用于计算时,通常按一个固定流程走。不要先急着查正态表,先把随机变量、均值和方差弄清楚。
明确题目问的是总和 Sn、样本均值 Xˉn,还是某个计数变量。这个选择决定使用 还是 。
例题:包装重量的平均值
某工厂每袋产品的重量 X 的均值为 500 克,标准差为 12 克。随机抽取 64 袋,近似计算样本平均重量落在 497 克到 503 克之间的概率。
这里问的是样本均值 Xˉ64。它的均值和标准差近似为
E(Xˉ64)=500,SD(Xˉ
于是
P(497≤Xˉ64≤503)=P(
即
P(497≤Xˉ64≤503)≈P(−2≤Z
查标准正态分布可得
P(−2≤Z≤2)≈0.9545
所以样本平均重量落在这个区间内的概率约为 95.45%。这个结果依赖两个条件:抽样近似独立,且单袋重量的方差稳定。如果生产批次之间存在系统性漂移,计算就会低估实际波动。
二项分布的正态近似
若 X∼Bin(n,p),则可以把 X 看成 n 个 Bernoulli 随机变量的和。它的均值和方差为
E(X)=np,Var(X)=np(1−p)
当 np 和 n(1−p) 都不太小时,有近似
np(1−p)X−np
常用经验是检查 np≥10 且 n(1−p)≥10。这不是定理中的硬边界,而是提醒你:如果成功或失败一侧太稀少,二项分布会明显偏斜,正态近似容易变差。
连续性修正
二项分布是离散分布,只在整数上取值;正态分布是连续分布。用连续曲线近似整数柱子时,边界要向外扩半格。
例如
P(a≤X≤b)
通常近似为
P(a−0.5≤Y≤b+0.5)
其中
Y∼N(np,np(1−p))
如果要求 P(X≥a),连续性修正后使用 P(Y≥a−0.5);如果要求 P(X≤b),使用 。
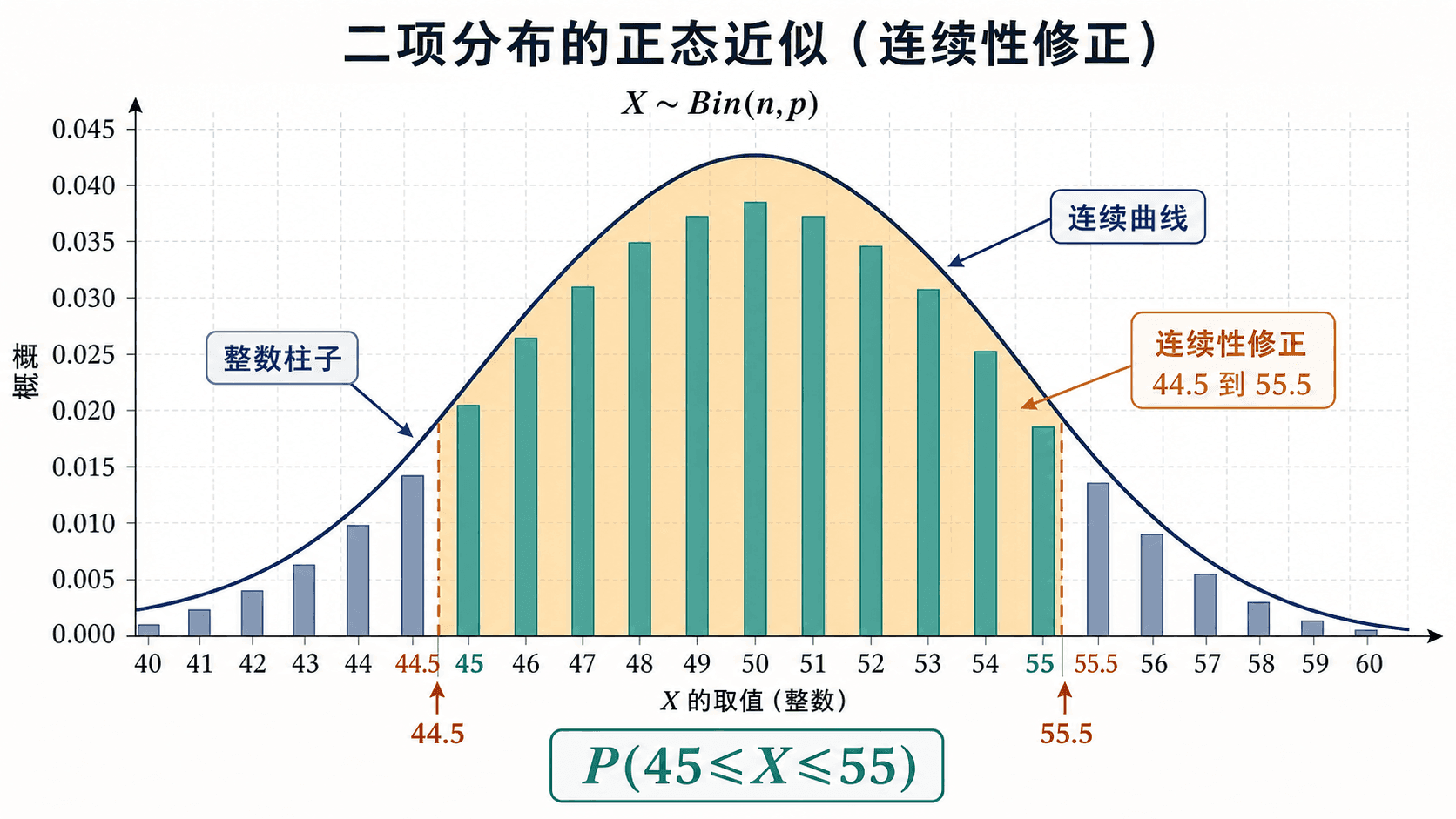 二项分布的正态近似用连续区间近似整数事件,边界通常向外扩半个单位。
二项分布的正态近似用连续区间近似整数事件,边界通常向外扩半个单位。
例题:投票支持人数
某候选人的真实支持率近似为 p=0.52。在 400 名独立抽样选民中,支持人数记为 X。近似计算支持人数至少为 220 的概率。
这里
X∼Bin(400,0.52)
所以
E(X)=208,SD(X)=400⋅0.52⋅0.48
事件 X≥220 经连续性修正为 Y≥219.5,于是
P(X≥220)≈P(Z≥9.99219.5−208)
也就是
P(X≥220)≈P(Z≥1.15)≈0.125
所以近似概率约为 12.5%。如果不用连续性修正,会把边界放在 220 而不是 219.5,得到的结果会略小。
Poisson 的正态近似
Poisson 分布常用于单位时间、单位空间内的事件计数。若 X∼Pois(λ),则
E(X)=λ,Var(X)=λ
当 λ 较大时,X 可以用正态分布近似:
X≈N(λ,λ)
也就是
λX−λ≈N(0,
Poisson 分布同样是离散分布,所以计算区间概率时也常使用连续性修正。
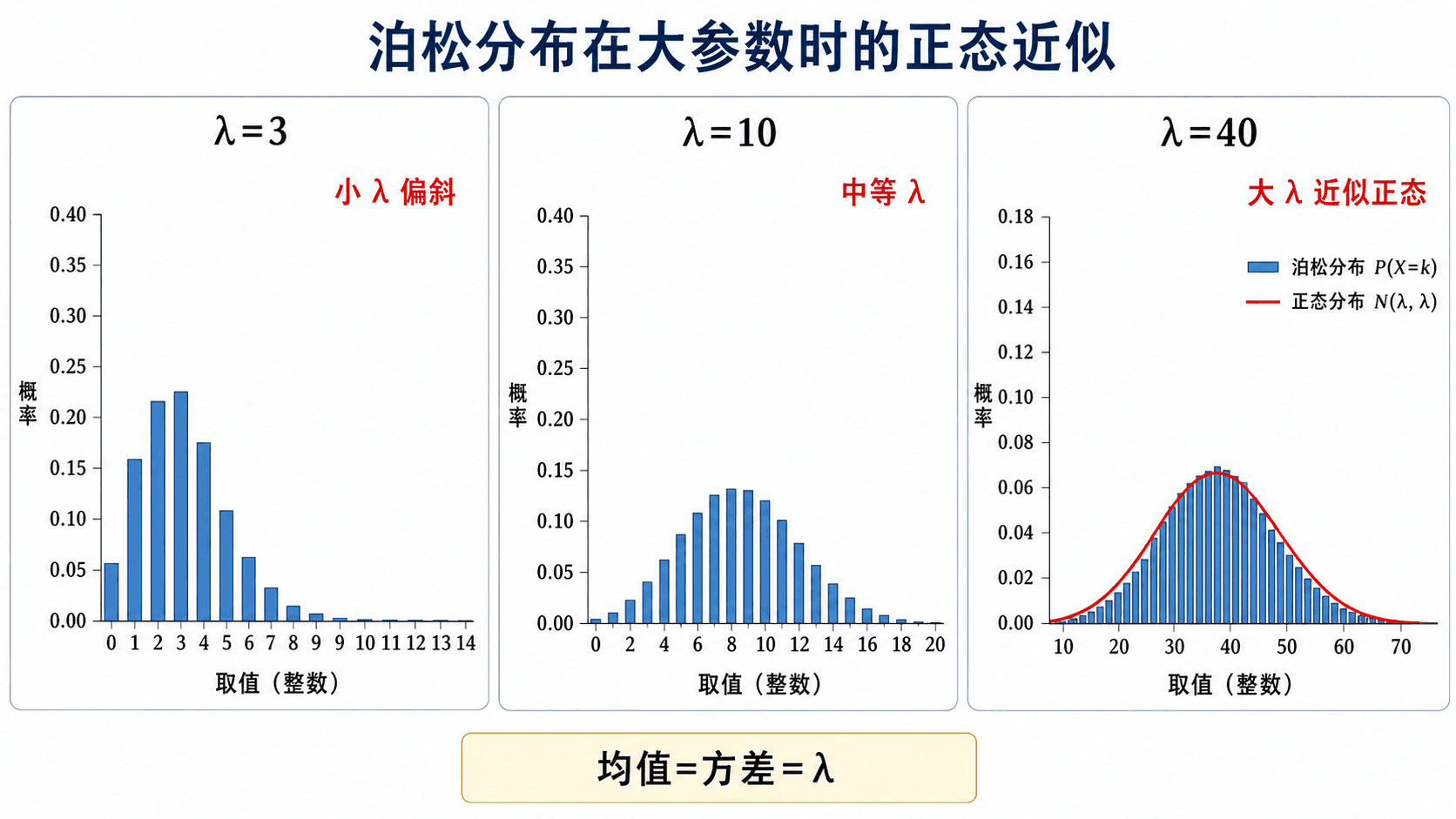 Poisson 分布的大参数正态近似:当 λ 增大时,分布形状逐渐接近正态,且均值等于方差。
Poisson 分布的大参数正态近似:当 λ 增大时,分布形状逐渐接近正态,且均值等于方差。
例题:一分钟来电数
某客服中心一分钟内来电数近似服从 Pois(36)。近似计算一分钟内来电数至少为 45 的概率。
使用正态近似 Y∼N(36,36)。事件 X≥45 经连续性修正为 Y≥44.5,因此
P(X≥45)≈P(Z≥644.5−36)
即
P(X≥45)≈P(Z≥1.42)≈0.078
这个概率约为 7.8%。若 λ 只有 3 或 4,Poisson 分布偏斜明显,此类正态近似就不应作为首选。
近似误差与常见误区
中心极限定理说明近似会在极限中成立,但它没有说某个具体样本量下一定足够准确。有限样本下的误差取决于原分布的偏斜程度、尾部厚度、独立性和所计算的概率位置。
一个有用的定性判断是:如果原随机变量的三阶绝对中心矩有限,则 Berry-Esseen 型结果会给出 1/n 量级的分布函数误差界:
xsup∣P(Zn≤x)−Φ(x)∣
不需要在本课记住常数 C。这条式子的教学价值在于,它提醒我们两件事:样本量增大通常能改善近似;原分布越偏斜或尾部越重,达到同样精度可能需要更大的样本量。
不要把“样本量大”当成万能许可。若观测之间强相关、方差不存在、样本来自几个不同机制的混合,或者目标概率在极端尾部,简单正态近似可能给出很自信但错误的答案。
使用前的检查清单
做正态近似前,可以按下面几项快速检查:
- 随机量是否能表示成许多小贡献的和或均值。
- 小贡献之间是否近似独立,至少没有强烈共同波动。
- 单个贡献的均值和方差是否稳定,是否存在极端重尾。
- 如果是二项分布,np 与 n(1−p) 是否都不小。
- 如果是离散计数,是否需要连续性修正。
- 计算的是中心附近概率还是很远的尾部概率。
蒙特卡洛模拟
蒙特卡洛方法用随机数估计难以直接计算的概率或期望。设目标量是
θ=E(Y)
我们独立模拟 Y1,Y2,…,Ym,用样本均值
θ^m=m1i=
估计 θ。如果 Y 的方差为 τ2,中心极限定理给出
τ/mθ^
实际计算时 τ 通常未知,就用模拟样本标准差 s 替代。于是标准误差估计为
SE(θ^m)≈m
这条公式解释了一个常见经验:想把蒙特卡洛误差减半,重复次数大约要增加到原来的 4 倍。
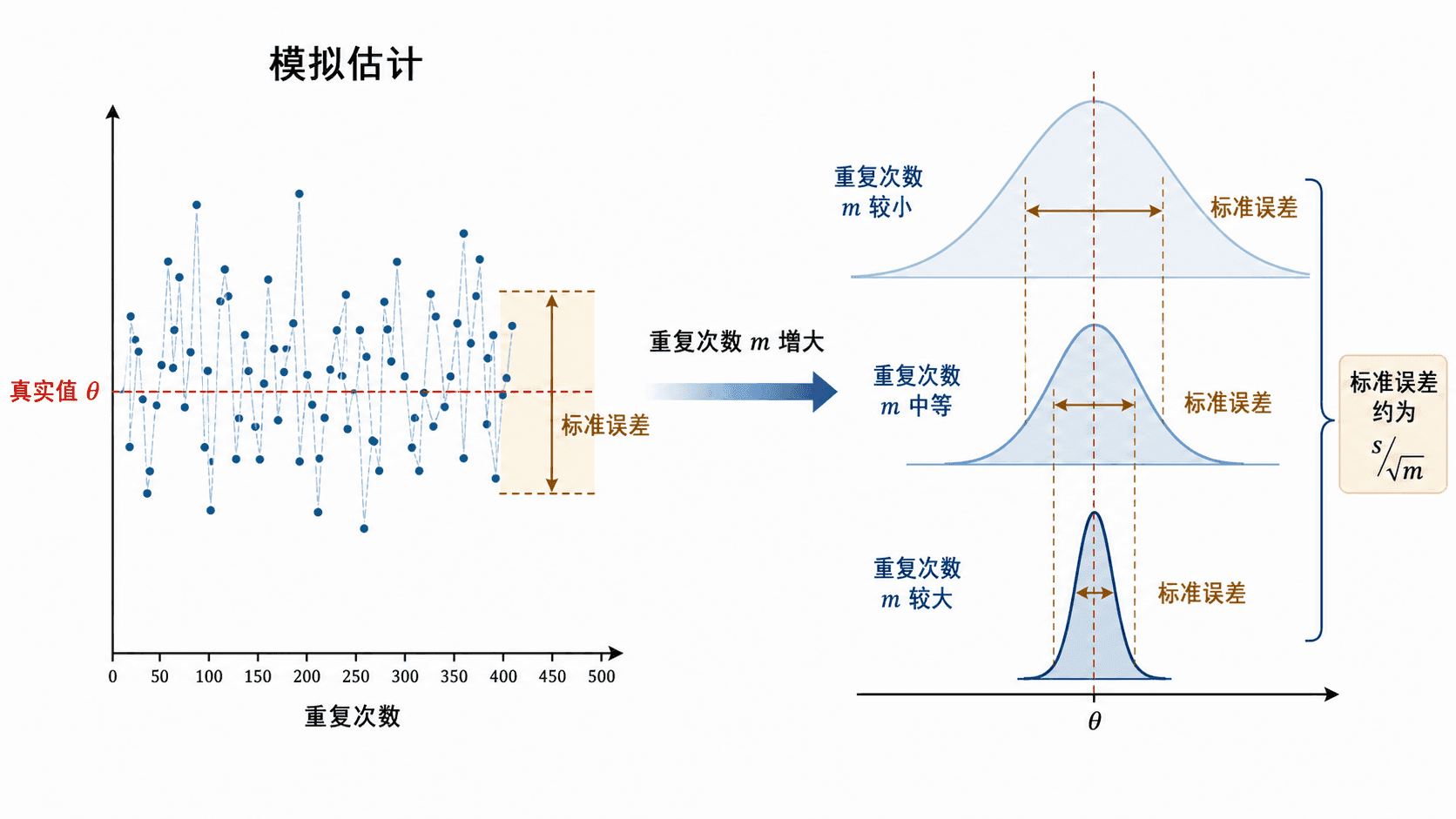 蒙特卡洛估计的标准误差随重复次数增加而减小。
蒙特卡洛估计的标准误差随重复次数增加而减小。
模拟误差和建模误差
蒙特卡洛重复次数 m 增大,能降低的是模拟误差。它不能修正错误模型带来的偏差。
例如你用模拟估计排队系统的平均等待时间。如果到达过程、服务时间分布和独立性假设本身接近真实系统,增大模拟次数会让估计更稳定;如果模型把高峰期到达当成均匀到达,模拟再久也只会稳定地估计一个错误模型。
综合建模
中心极限定理最适合处理“许多小贡献叠加”的问题。建模时不要从正态分布开始,而是先找出随机贡献、单位、均值、方差和独立性来源。
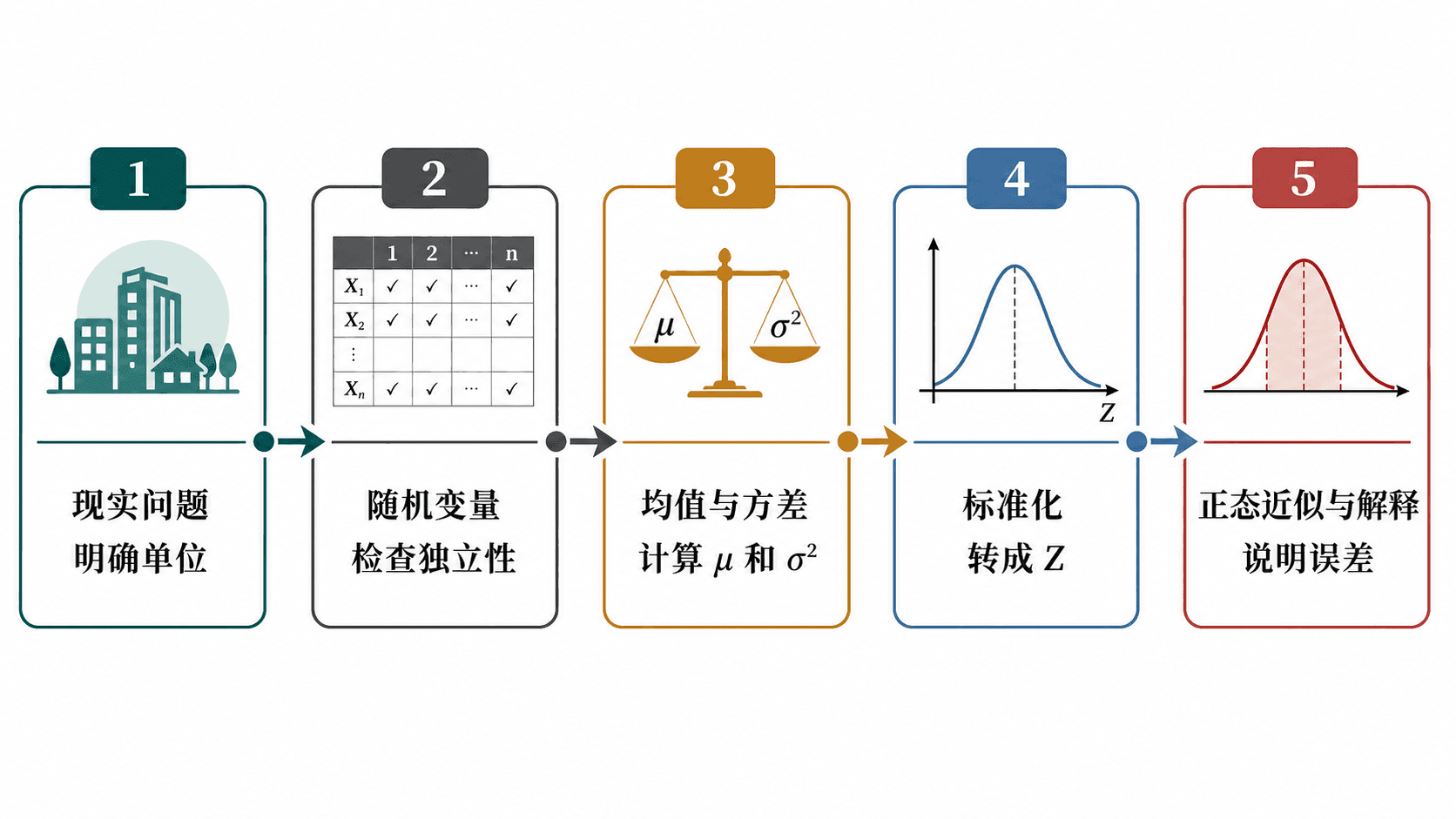 用中心极限定理从现实问题出发,建立随机变量模型并完成正态近似解释。
用中心极限定理从现实问题出发,建立随机变量模型并完成正态近似解释。
例题:保险赔付总额
某保险组合包含 500 份相似保单。单份保单一年赔付额 X 的均值为 120 元,标准差为 600 元。假设不同保单赔付额近似独立,估计一年总赔付额超过 80000 元的概率。
设总赔付额为
S500=X1+⋯+X500
则
E(S500)=500⋅120=60000
且
SD(S500)=500⋅600
用中心极限定理近似,
P(S500>80000)≈P(Z>13416
即
P(S500>80000)≈P(Z>1.49)≈0.068
所以超过 80000 元的概率约为 6.8%。这个答案不是“保险赔付额服从正态分布”,而是“500 份近似独立保单的总额可用正态近似”。如果保单之间受同一灾害强烈影响,独立性假设会失效,总风险会被低估。
综合建模的好答案通常包括三层内容:随机变量怎么定义,均值和方差怎么来,近似条件是否合理。只给最后一个正态概率,往往不足以说明模型可信。
练习
概念判断
判断下列说法是否正确,并说明理由。
- 只要 n 很大,X1 的分布就会接近正态分布。
- 若 Xi 独立同分布且方差有限,则 X 的标准差是 。
第 1 句错误。中心极限定理讨论的是标准化后的和或均值,不是单个 X1。第 2 句正确,这是样本均值方差公式。第 3 句错误,单侧概率也常需要连续性修正,例如 P(X≥a) 对应 P(Y≥a−0.5。第 4 句正确,重复模拟只能让估计更稳定,不能改变被模拟的模型。
样本均值计算
某零件长度的均值为 20 毫米,标准差为 0.4 毫米。抽取 100 个零件,近似计算样本平均长度超过 20.06 毫米的概率。
样本均值的标准差为 0.4/100=0.04。标准化得
z=二项近似
设 X∼Bin(250,0.08)。用正态近似并加连续性修正,估计 P(X≤15)。
均值为 np=20,标准差为
250⋅0.08⋅0.92≈4.29事件 修正为 。因此
Poisson 近似
设一分钟内某接口请求数 X∼Pois(64)。用正态近似估计 P(55≤X≤75)。
用 Y∼N(64,64) 近似。连续性修正后,
P(55≤X≤75)≈P(54.5≤Y蒙特卡洛标准误差
一次模拟输出随机变量 Y,用 m=10000 次模拟估计 θ=E(Y)。模拟样本均值为 2.37,样本标准差为 5.8。估计标准误差,并给出一个粗略的 误差范围。
标准误差估计为
SE≈100005.8=0.058建模题
一家仓库每天处理 900 个独立订单。单个订单的处理时间均值为 4.2 分钟,标准差为 3 分钟。若一天可用处理时间为 3900 分钟,近似估计总处理时间超过可用时间的概率。说明你的假设。
设第 i 个订单处理时间为 Xi,总时间为 S900。若近似独立同分布,则
E
小结
中心极限定理把前面学过的独立性、期望、方差、随机变量和收敛概念连在一起。它告诉我们,许多独立小贡献的和,在合适标准化后会出现稳定的正态形状。
使用这个工具时,关键不是背一句“样本量大近似正态”,而是能写出研究对象、中心、尺度和近似条件。二项分布和 Poisson 分布的正态近似来自同一条思想;蒙特卡洛标准误差也是中心极限定理在模拟中的直接应用。
到这里,概率论 I 的主线已经闭合:从样本空间和事件开始,经由随机变量、分布、期望、联合结构、变换和不等式,最后到达大数定律与中心极限定理。后续进入统计推断、随机过程或机器学习概率基础时,本章的标准化和误差尺度会反复出现。