概率不等式、收敛概念与大数定律
前面几章多数问题都在问“分布是什么”“期望和方差怎么算”。这一章开始,问题的形态变了:我们常常并不知道完整分布,只知道均值、方差或凸性;我们也不再只看一个随机变量,而是看一列随机变量 X1,X2,… 在 n 变大时会怎样。
概率不等式给的是保底判断。它通常不精细,却能在信息很少时说明尾部概率不会太大。收敛概念则告诉我们“趋近”可以有不同含义:有时看偏离概率,有时看几乎每条样本路径,有时看平均平方误差,有时只看分布形状。大数定律把两部分接起来,解释样本均值为什么会稳定到总体均值附近。
从精确计算到上界判断
如果知道 X 的完整分布,当然可以直接算 P(X≥a) 或 P(∣X−μ∣≥ε)。但现实中常见的情形更粗:只知道平均损失、测量误差的方差,或一个函数是凸的。概率不等式就是在这种信息不完整的情形下使用的工具。
上界不等式的结论通常长这样:
P(坏事件)≤一个可计算的数
它的意义不是“坏事件概率等于右边”,而是“坏事件概率不超过右边”。当右边很小时,这个结论有力;当右边很大时,它可能只说明不了多少。
本章中的不等式大多是保守估计。它们牺牲精细性,换来条件简单、适用范围宽。读公式时要先问:右边用了哪些信息?这些信息是否足以给出有用的上界?
Markov 不等式:只靠均值也能控制尾部
Markov 不等式适用于非负随机变量。设 X≥0,且 E[X] 存在。对任意 a>0,
P(X≥a)≤aE[X]
这个结论非常朴素:如果 X 经常达到很大的水平,那么平均值不可能太小。反过来,如果平均值很小,那么 X 落在很大阈值以上的概率就受限制。
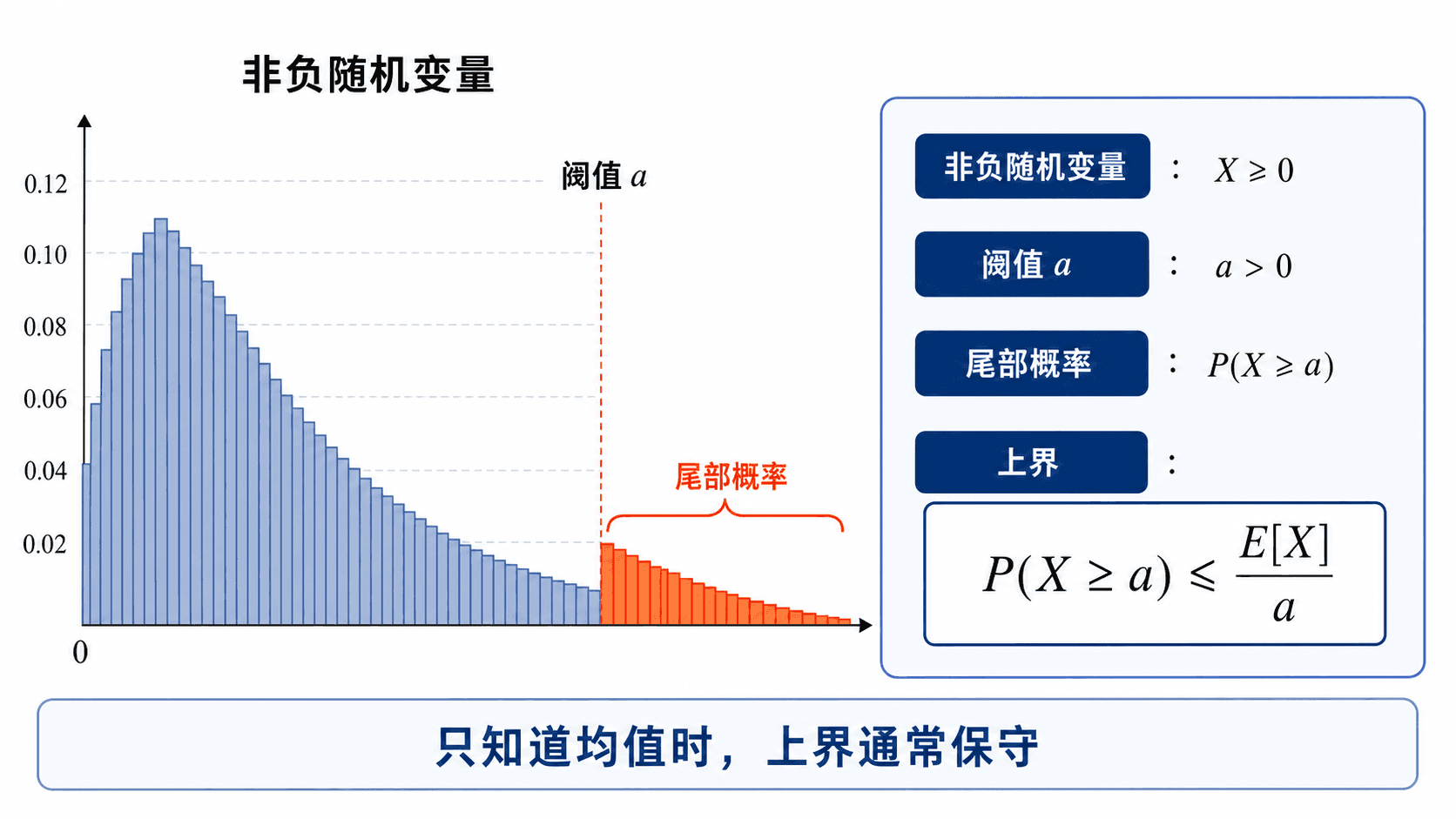 Markov 不等式只使用非负性和均值,因此常常保守,但适用条件很少。
Markov 不等式只使用非负性和均值,因此常常保守,但适用条件很少。
为什么成立
把事件 {X≥a} 的指示变量记为 I{X≥a}。由于 X≥0,当 时有 ,当 时右边为 ,不等式也成立。因此
X≥aI{X≥a}
两边取期望,得到
E[X]≥aE[I{X≥a}]=aP(X≥a)
整理后就是 Markov 不等式。
例题:用平均损失控制大额损失概率
某设备每天的维修损失 X 非负,已知 E[X]=200 元。即使不知道 X 的完整分布,也能得到
P(X≥1000)≤1000200=0.2
这个结论说“大于等于 1000 元”的概率不超过 20%。它不说明真实概率接近 20%,真实概率可能是 1%,也可能是 19%。如果还知道方差、分布形状或更多数据,可以得到更细的结论。
Markov 不等式要求 X 非负。如果变量可能取负值,不能直接把 X 放进公式;常见做法是改看非负变量,例如 ∣X∣、X2 或某个非负损失函数。
Chebyshev 不等式:把方差翻译成偏离概率
Chebyshev 不等式把“方差小”转化成“远离均值的概率小”。设 E[X]=μ,Var(X)=σ2<∞。对任意 ε,
P(∣X−μ∣≥ε)≤ε2σ2
它的证明几乎就是 Markov 不等式:把非负随机变量选成 (X−μ)2。
P(∣X−μ∣≥ε)=P((X−μ)
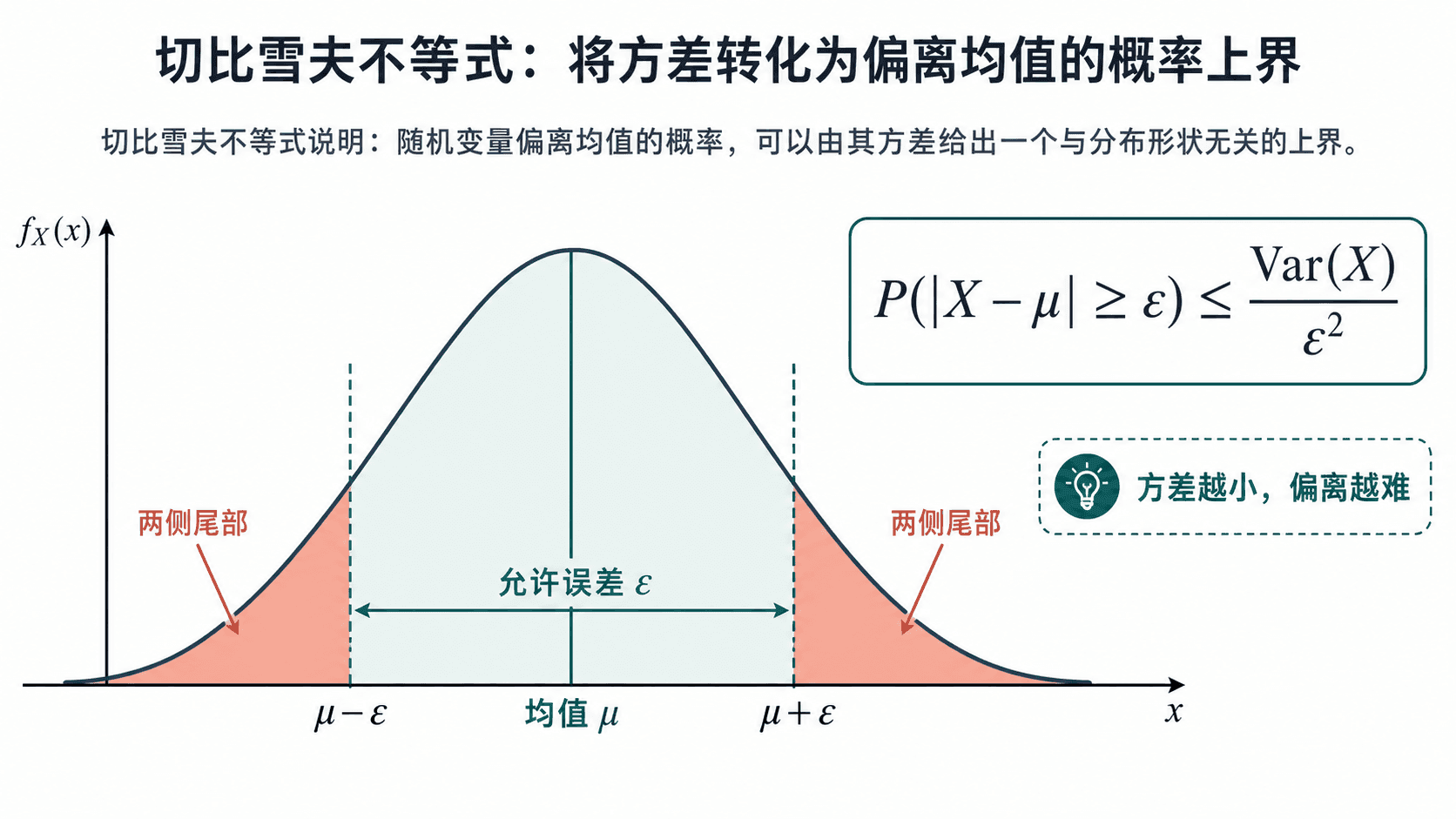 方差越小,随机变量远离均值的概率上界越低;阈值 ε 越大,偏离事件越难发生。
方差越小,随机变量远离均值的概率上界越低;阈值 ε 越大,偏离事件越难发生。
例题:一次测量偏差超过 3 个标准差
如果 E[X]=μ,Var(X)=σ2,则
P(∣X−μ∣≥3σ)≤9σ2σ
这对任何有有限方差的分布都成立,不要求正态。若 X 正态,真实概率约为 0.0027,远小于 1/9。这再次说明 Chebyshev 不等式稳健但保守。
Jensen 不等式:凸性与期望的次序
Jensen 不等式处理的是“先平均再变换”和“先变换再平均”的差别。设 g 是凸函数,且相关期望存在,则
g(E[X])≤E[g(X)]
如果 g 是凹函数,不等号方向反过来。
凸函数的直观含义是:图像在割线下方,或者说中间点的函数值不超过端点函数值的加权平均。随机变量的期望可以看成许多取值的加权平均,所以凸函数会把波动“放大”到期望里。
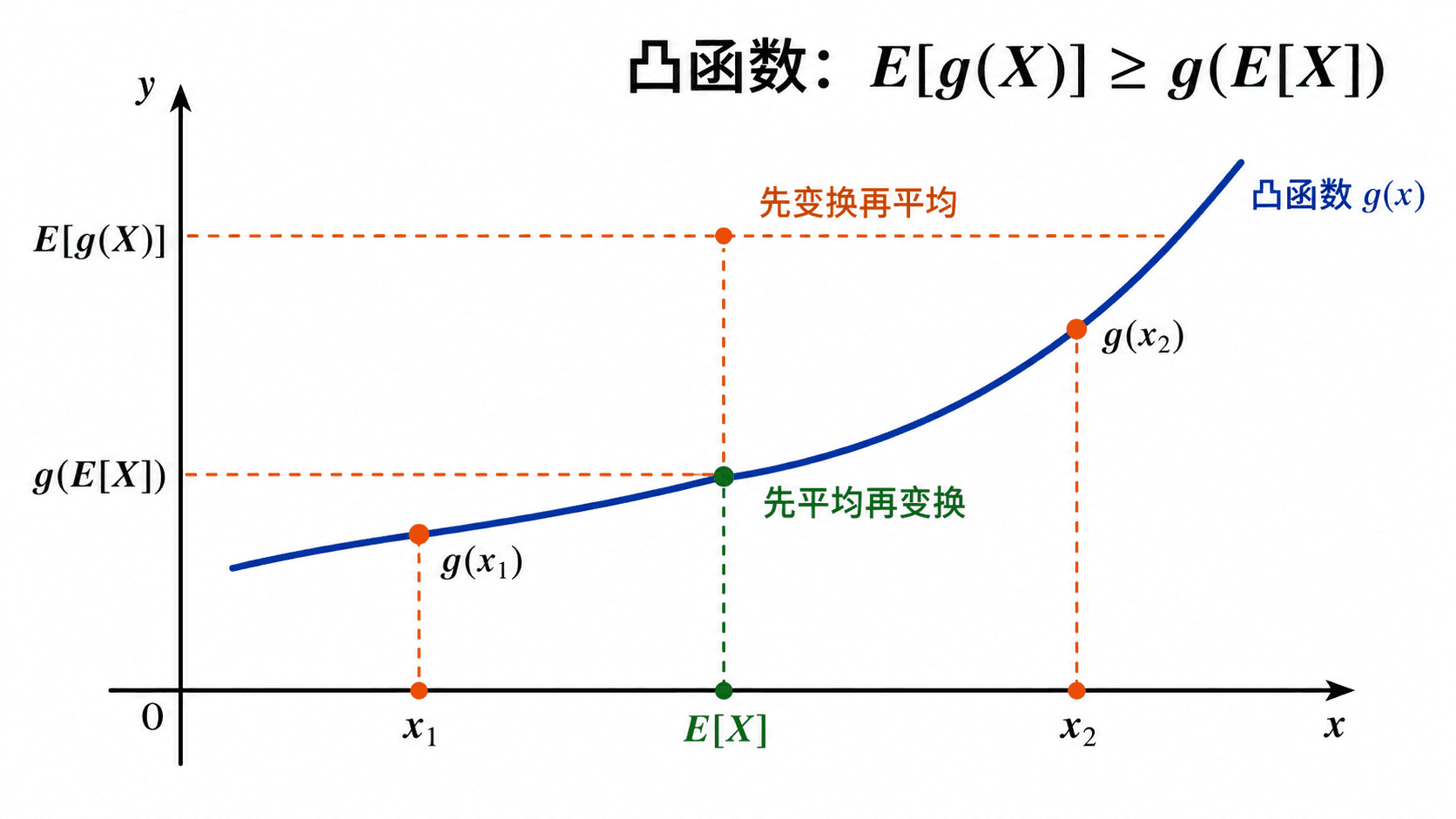 对凸函数,先把随机变量代入函数再取平均,结果不小于先取平均再代入函数。
对凸函数,先把随机变量代入函数再取平均,结果不小于先取平均再代入函数。
常见推论
令 g(x)=x2,它是凸函数,于是
(E[X])2≤E[X2]
这也是方差非负性的另一种表达:
Var(X)=E[X2]−(E[X])2≥0
令 g(x)=ex,得到
eE[X]≤E[eX]
如果 g(x)=logx,它在 x>0 上是凹函数,所以
E[logX]≤logE[X]
这个不等式经常出现在增长率、信息量和风险决策中:同样的平均水平下,波动会降低对数意义下的平均表现。
Jensen 不等式的关键不是“函数看起来弯”,而是凸或凹。使用前要先确认定义域、凸性方向和期望是否存在。尤其是 logX 只能在 X>0 时直接使用。
几种收敛:问题问的不是同一件事
一列随机变量 X1,X2,… 是否“收敛到 X”,要先说明收敛的含义。本科概率论常用四种口径:依概率收敛、几乎处处收敛、均方收敛和分布收敛。它们都在说“靠近”,但看的是不同对象。
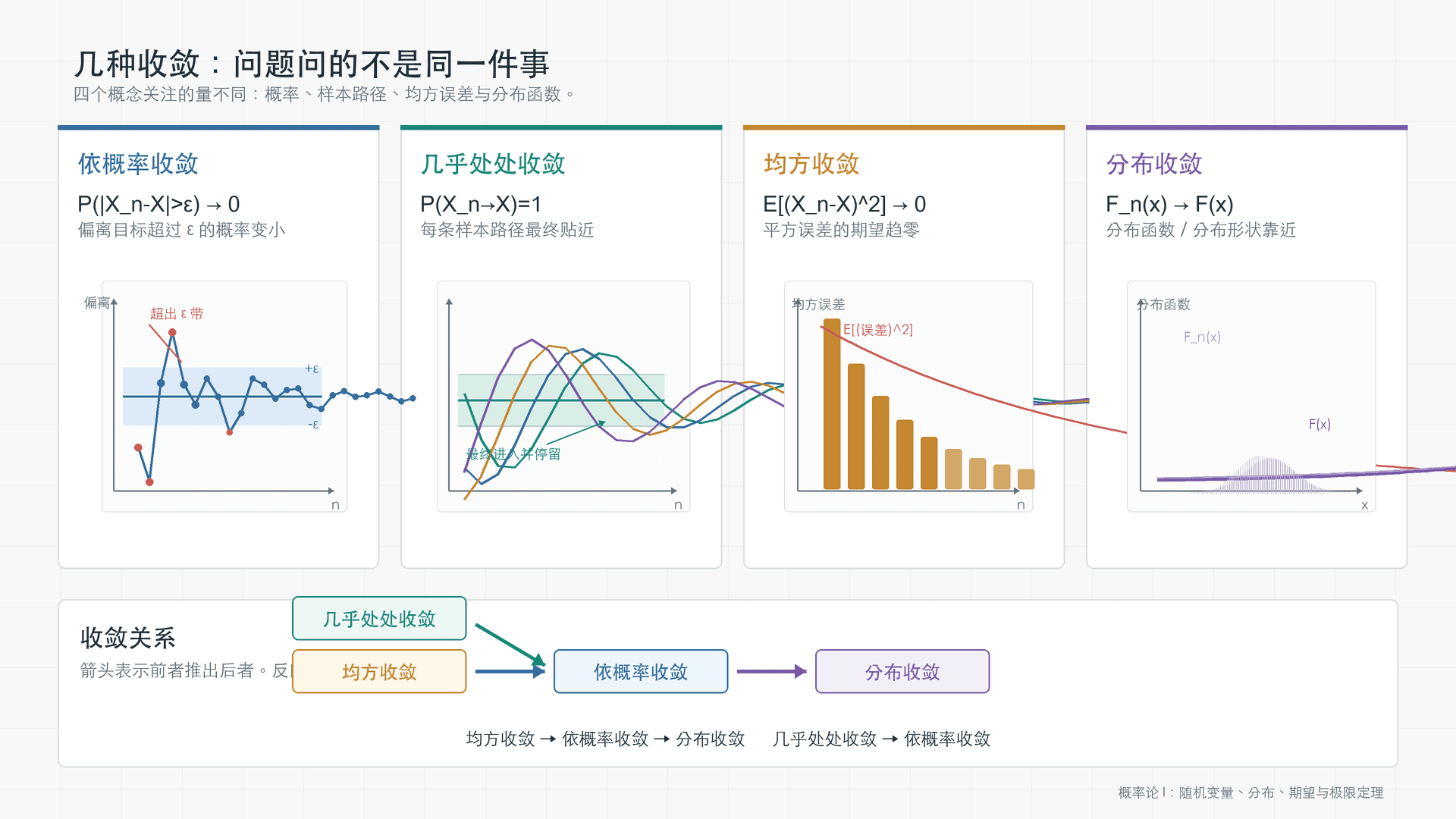 均方收敛和几乎处处收敛都能推出依概率收敛;依概率收敛能推出分布收敛。
均方收敛和几乎处处收敛都能推出依概率收敛;依概率收敛能推出分布收敛。
依概率收敛
如果对任意 ε>0,
P(∣Xn−X∣>ε)→0
则称 Xn 依概率收敛到 X,记作 XnP。
这句话关注的是“偏离目标超过固定误差的概率”。它允许每个 n 都有少数坏情况,只要求坏情况的概率趋于 0。弱大数定律用的正是这种收敛。
几乎处处收敛
如果
P(n→∞limXn=X)=1
则称 Xn 几乎处处收敛到 X,也叫几乎必然收敛,记作 Xna.s。
它看的是样本路径:除了一组概率为 0 的异常结果外,每条路径最终都收敛到 X。强大数定律用的就是这种口径。
均方收敛
如果
E[(Xn−X)2]→0
则称 Xn 均方收敛到 X,也叫 L2 收敛。它要求平均平方误差趋于 0,因此比依概率收敛带有更强的误差控制。
由 Chebyshev 不等式可知,均方收敛推出依概率收敛:
P(∣Xn−X∣>ε)≤ε
分布收敛
如果在 X 的分布函数 FX 的每个连续点 x 上,
FXn(x)→FX(x)
则称 Xn 分布收敛到 X,记作 Xnd。
分布收敛只比较分布形状,不要求 Xn 和 X 定义在同一个样本空间上。中心极限定理使用的就是分布收敛。为了避免混淆,本课把“弱大数定律”的“弱”理解为依概率收敛,不把它与“分布收敛”混用。
常用关系是:均方收敛推出依概率收敛,几乎处处收敛推出依概率收敛,依概率收敛推出分布收敛。反方向一般不成立,除非额外加条件。
弱大数定律:样本均值为什么稳定
设 X1,X2,… 独立同分布,E[Xi]=,。定义样本均值
Xn=n1i=
由于期望线性性,
E[Xn]=μ
由于独立性,
Var(Xn)=Var(
对 Xn 使用 Chebyshev 不等式,任意 ε>0,
P(∣Xn−μ∣≥ε)≤n
于是
XnPμ
这就是一个常见版本的弱大数定律:样本均值依概率收敛到总体均值。
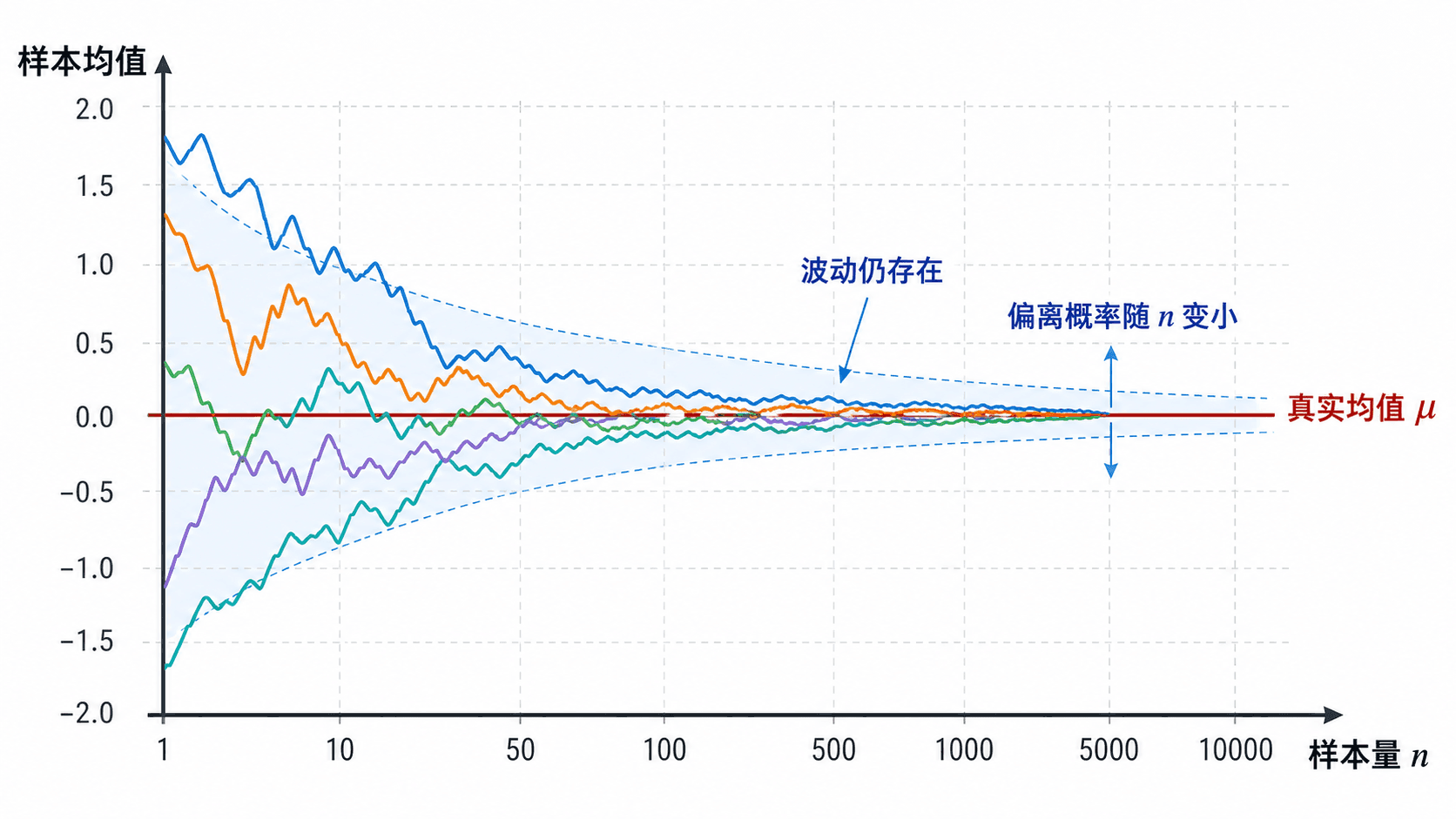 大数定律说的是偏离概率随样本量增大而变小,不是每一条轨迹都单调靠近均值。
大数定律说的是偏离概率随样本量增大而变小,不是每一条轨迹都单调靠近均值。
抛硬币频率的版本
设 Xi 表示第 i 次抛硬币是否为正面,正面为 1,反面为 0,且 P(X。则 是前 次中正面的频率。
这里 E[Xi]=p,Var(Xi)=p(1,所以
P(∣Xn−p∣≥ε)≤
这说明正面频率会稳定到 p 附近。它不保证第 n 次之后频率再也不动,也不保证短期内一定接近 p。
强大数定律:几乎每条长期路径的稳定
弱大数定律说 Xn 依概率收敛到 μ。强大数定律说得更强:在常见条件下,Xn 几乎处处收敛到 。
一个常用表述是:若 X1,X2,… 独立同分布,且 E[∣X1,则
P(n→∞limXn=μ)=
其中 μ=E[X1]。
弱大数定律看的是每个 n 的偏离概率;强大数定律看的是整条无限样本路径最后是否收敛。这个区别很重要:强大数定律并不是把“每个 n 的概率很大”简单相加,而是关于无限序列的更细结论。
大数定律不能说明什么
大数定律经常被误读。它说明样本均值长期稳定,但不说明下面这些事:
- 不说明单个观测值会靠近均值。单次抛硬币仍然是正面或反面,单个指数等待时间仍可能很大。
- 不说明样本均值会单调靠近均值。轨迹可能反复上下波动。
- 不直接给出有限样本下的精确误差概率。Chebyshev 上界给的是保守控制,真实误差需要更多分布信息。
- 不说明所有分布都适用同一个版本。若期望不存在或尾部极重,样本均值可能没有通常意义下的稳定目标。
- 不说明“前面偏少,后面就该补回来”。独立试验没有记忆,长期频率稳定不等于短期补偿。
“试验次数多了,结果会越来越公平”这句话容易误导。正确说法是:在合适条件下,样本均值偏离真实均值超过任意固定误差的概率会趋于 0;强版本还说几乎每条无限路径都会收敛。它不预测下一次会怎样。
例题:用 Chebyshev 证明样本均值稳定
设 X1,…,Xn 独立同分布,E[Xi],。令 为样本均值。求使
P(∣Xn−5∣≥0.5)≤0.01
成立的一个充分样本量。
先计算样本均值的方差。独立同分布给出 Var(Xn)=9/n。
这个样本量可能比实际需要大很多,因为 Chebyshev 不等式没有使用分布形状。但在只知道方差时,它给出了可靠保证。
练习
练习 1 设 X≥0,E[X]=12。用 Markov 不等式给出 P(X≥30) 的上界。
由 Markov 不等式,
P(X≥30)≤30E[X]=30练习 2 设 E[X]=10,Var(X)=16。用 Chebyshev 不等式给出 P(∣X−10∣≥8 的上界。
由 Chebyshev 不等式,
P(∣X−10∣≥8)≤8216=练习 3 设 g(x)=x4。说明为什么 E[X4]≥(E[X]) 不总能直接由 Jensen 不等式得到。
g(x)=x4 在全实数上是凸函数,因此如果 E[X] 和 E[X4] 都存在,Jensen 不等式给出
练习 4 设 XnPμ。这是否意味着每一条样本路径上的 都收敛到 ?
不一定。依概率收敛只要求 P(∣Xn−μ∣>ε)→0,关注的是每个 n 的偏离概率。它不保证每条样本路径最终收敛。要表达“除概率为 的路径外都收敛”,需要几乎处处收敛。
小结
Markov 不等式用非负性和均值控制尾部概率;Chebyshev 不等式用方差控制远离均值的概率;Jensen 不等式用凸性比较 g(E[X]) 与 E[g(X)]。这些工具让我们在不知道完整分布时仍能得到可靠判断。
收敛概念要按问题选择。依概率收敛看偏离概率,几乎处处收敛看样本路径,均方收敛看平均平方误差,分布收敛看分布函数。弱大数定律通常说明样本均值依概率收敛到均值;强大数定律说明样本均值几乎处处收敛。下一章的中心极限定理会进一步回答:样本均值稳定以后,它的随机波动近似呈什么形状。