奇异值分解与综合应用
前面几章里,矩阵已经出现过很多种身份:它可以表示方程组,可以表示线性变换,可以拉伸面积,可以投影数据,也可以在特征向量方向上做简单缩放。奇异值分解把这些线索收拢到一个入门课也能看懂的图像里:任意矩阵都可以理解成两次正交变换,中间夹着一次沿主轴的缩放。
这一章不把 SVD 当成一套复杂算法。我们先看它在几何上做什么,再看奇异值、主方向和低秩近似,最后把它用到图像压缩、数据降维、推荐系统和噪声过滤中。
先记住一句话:不是每个矩阵都能用特征向量很好地描述,但每个实矩阵都能做奇异值分解。SVD 的核心不是“多背一种分解”,而是给任意矩阵找出最自然的输入方向、输出方向和拉伸长度。
把矩阵拆成三步动作
设 是一个 的实矩阵。SVD 写成:
这里 和 是正交矩阵, 是只在主对角线位置可能非零的矩形矩阵。正交矩阵的作用很温和:它只改变坐标方向,不改变长度和角度。真正改变长度的部分集中在 里。
对一个输入向量 ,矩阵 的作用可以按下面三步理解:
- 先把输入向量转到一套特殊的输入坐标系里。
- 沿这些坐标轴分别缩放,缩放倍数就是奇异值。
- 再把结果转到输出空间中的一套特殊坐标系里。
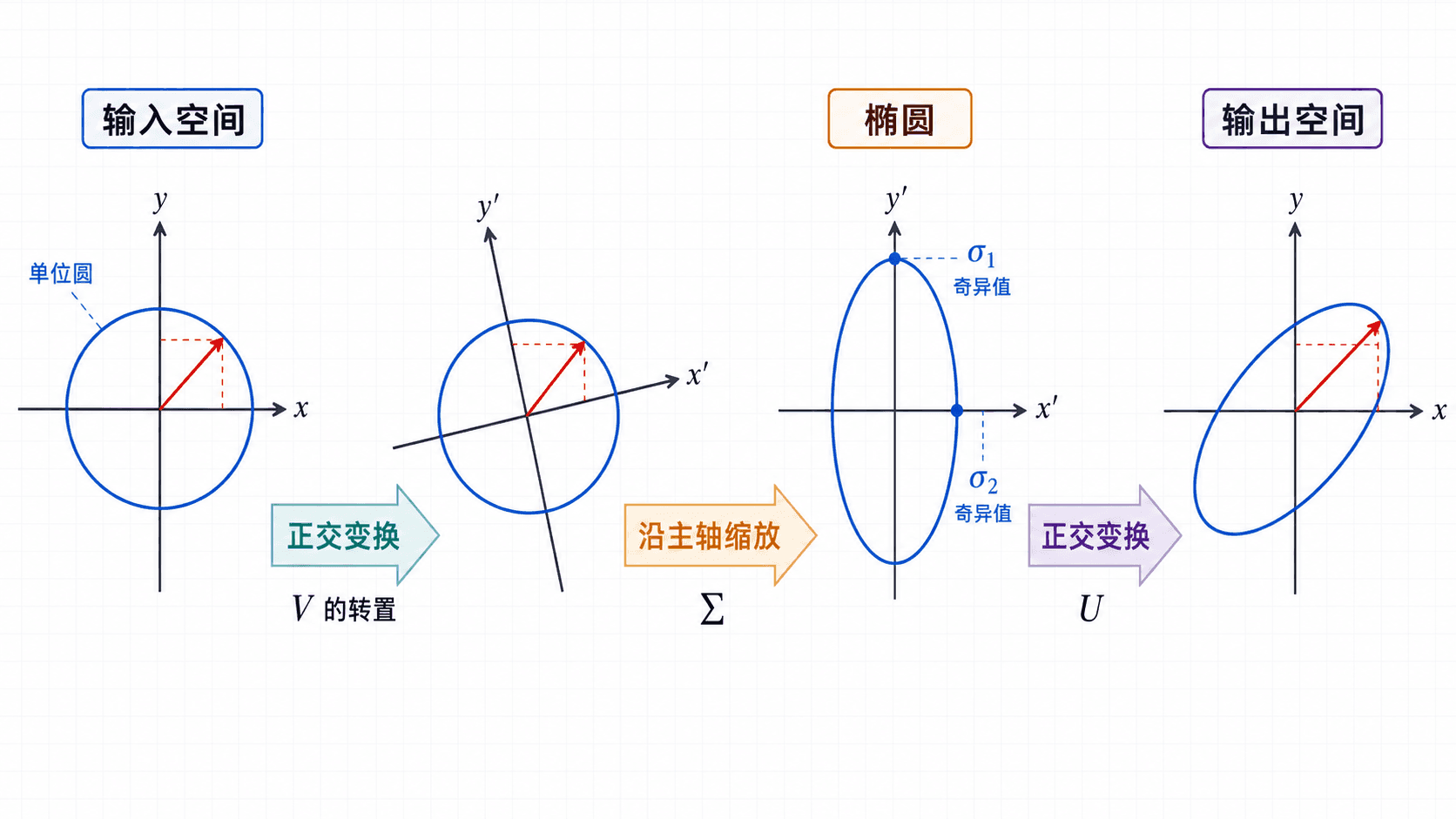
SVD 把矩阵作用拆成“输入正交变换、沿主轴缩放、输出正交变换”三步。
如果 是二维到二维的矩阵,可以把单位圆放进去观察。正交变换只会把圆转一转或翻一翻,圆仍然是圆;中间的缩放会把圆变成椭圆;最后再由另一个正交变换把椭圆放到输出平面中的位置。
这里常见的误解是把 和 都叫作“旋转”。在二维图像里这样说很顺口,但严格地说,正交变换还可能包含反射。它们共同的特点是保持长度和夹角。
奇异值和主方向
SVD 中最重要的公式不是只看 ,而是看它如何作用在一组特殊的单位向量上:
叫作右奇异向量,它们是输入空间中的主方向。 叫作左奇异向量,它们是输出空间中的主方向。 是对应的奇异值,表示沿 输入时,输出长度被放大到多少。
通常把奇异值按从大到小排列:
如果某个方向的奇异值很大,说明矩阵在这个方向上保留或放大了很多信息。如果奇异值为 ,说明这个方向被矩阵压成了零向量,也就是进入了零空间。
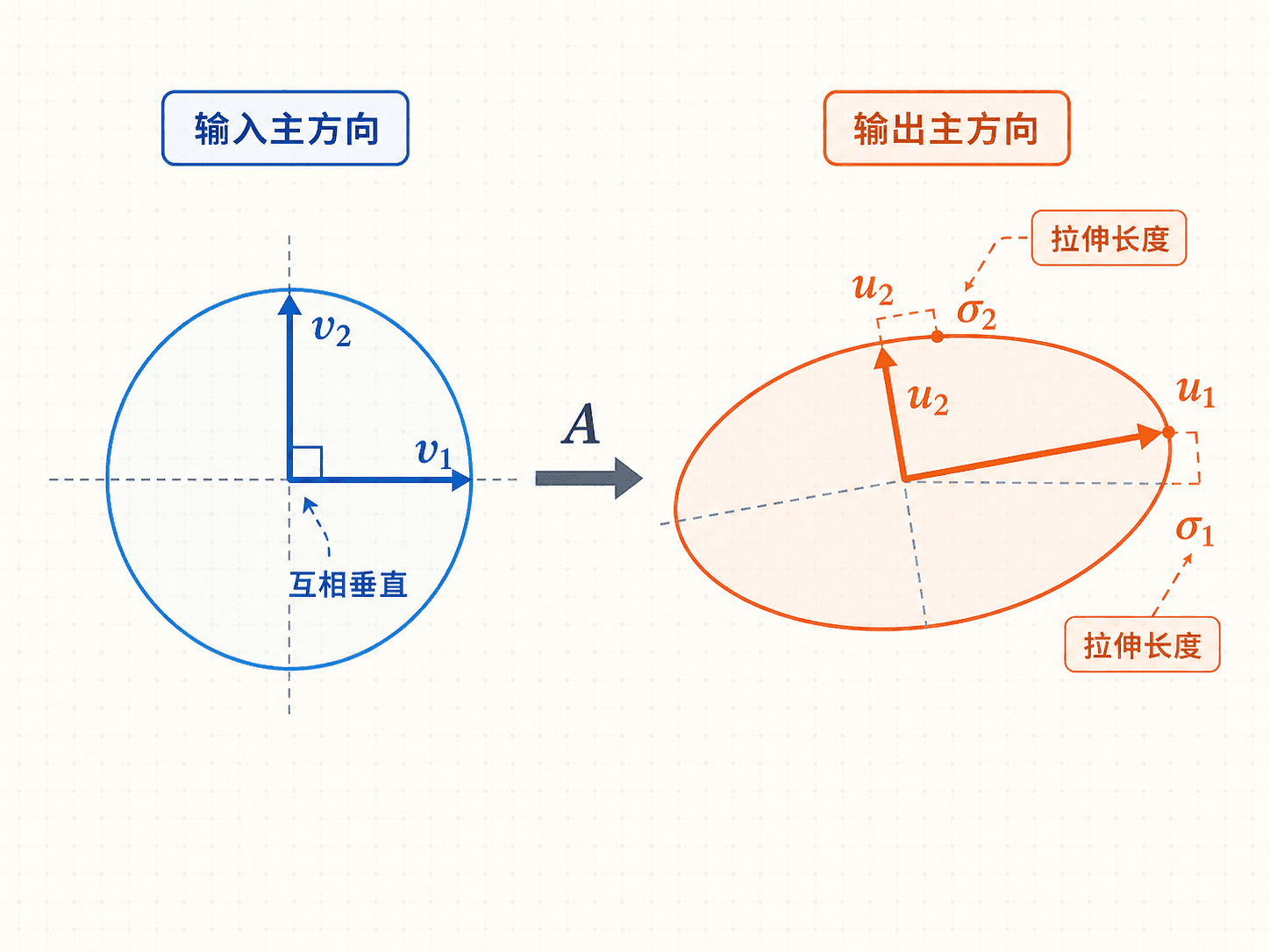
单位圆被矩阵送成椭圆,椭圆的长轴和短轴对应主要的输出方向。
和特征值的连接
SVD 和特征值不是两套完全分开的语言。对任意矩阵 ,矩阵 一定是对称矩阵,因此它有正交特征向量。SVD 中的右奇异向量正是 的特征向量:
当 时,左奇异向量可以由下面的式子得到:
这也解释了为什么奇异值总是非负数:它们来自 的非负特征值的平方根。
矩形矩阵也能分解
特征值方法通常要求矩阵是方阵,但 SVD 不要求。一个 的矩阵可以把 维输入送到 维输出, 就是一个 的矩形“缩放表”。
![]()
矩形矩阵的 SVD 中,非零奇异值的个数等于矩阵的秩。
如果 的秩是 ,那么只有前 个奇异值非零。这个事实把 SVD 和前面学过的秩、列空间、零空间连接了起来:秩说明矩阵真正保留下来的独立方向有多少个。
奇异向量的符号不是唯一的。如果把 和 同时乘以 ,等式 仍然成立。所以看 SVD 时,方向轴本身重要,箭头朝哪一边有时只是约定。
手算一个很小的 SVD
下面用一个二维矩阵看清楚 SVD 的计算链条:
这个矩阵会把输入向量的两个坐标交换到不同位置,并且把其中一个方向放大 2 倍。
先计算 ,因为右奇异向量来自它的特征向量。
这个例子里, 先交换输入坐标, 再把第一个坐标方向放大 2 倍, 没有再改变方向。虽然例子很小,但它已经包含了 SVD 的基本动作。
低秩近似
SVD 的另一个重要写法是把矩阵拆成一层一层的外积:
每一项 都是一个秩为 1 的矩阵。第一层通常抓住最强的整体结构,后面的层逐步补充更细的变化。
![]()
低秩近似保留前几层主要结构,用更少的信息近似原矩阵。
如果只保留前 个奇异值,就得到秩不超过 的近似矩阵:
在所有秩不超过 的矩阵里, 是最接近 的选择之一。用 Frobenius 范数衡量误差时,有:
这句话很适合入门理解:丢掉哪些奇异值,误差就来自哪些奇异值。若后面的奇异值很小,只保留前几个主方向也能得到很好的近似。
保留信息的常用比例可以写成:
低秩近似的价值不只是“少存几个数”。它把数据中最稳定、最强的结构排在前面,让我们可以用可控的损失换取压缩、降噪和更容易解释的表示。
四个应用场景
图像压缩
一张灰度图片可以看成一个矩阵,矩阵中的每个数表示一个像素的亮度。如果图片大小是 ,直接保存需要大约 个亮度数。用秩 的 SVD 近似时,只需要保存前 个奇异值、 个左奇异向量和 个右奇异向量,大约是:
当 远小于 和 时,存储量会明显下降。代价是图片会损失细节,尤其是边缘、纹理和细小文字。
![]()
保留的奇异值越多,低秩重建越接近原图,但需要保存的信息也越多。
数据降维
很多数据集的每一行是一条样本,每一列是一个特征。把中心化后的数据矩阵记为 ,它的 SVD 是:
的前几列给出数据变化最大的方向。把数据投影到这些方向上,就能得到低维表示:
这就是主成分分析中常见的矩阵语言。它不保证低维图像保留所有信息,但它会优先保留整体变化最大的方向。
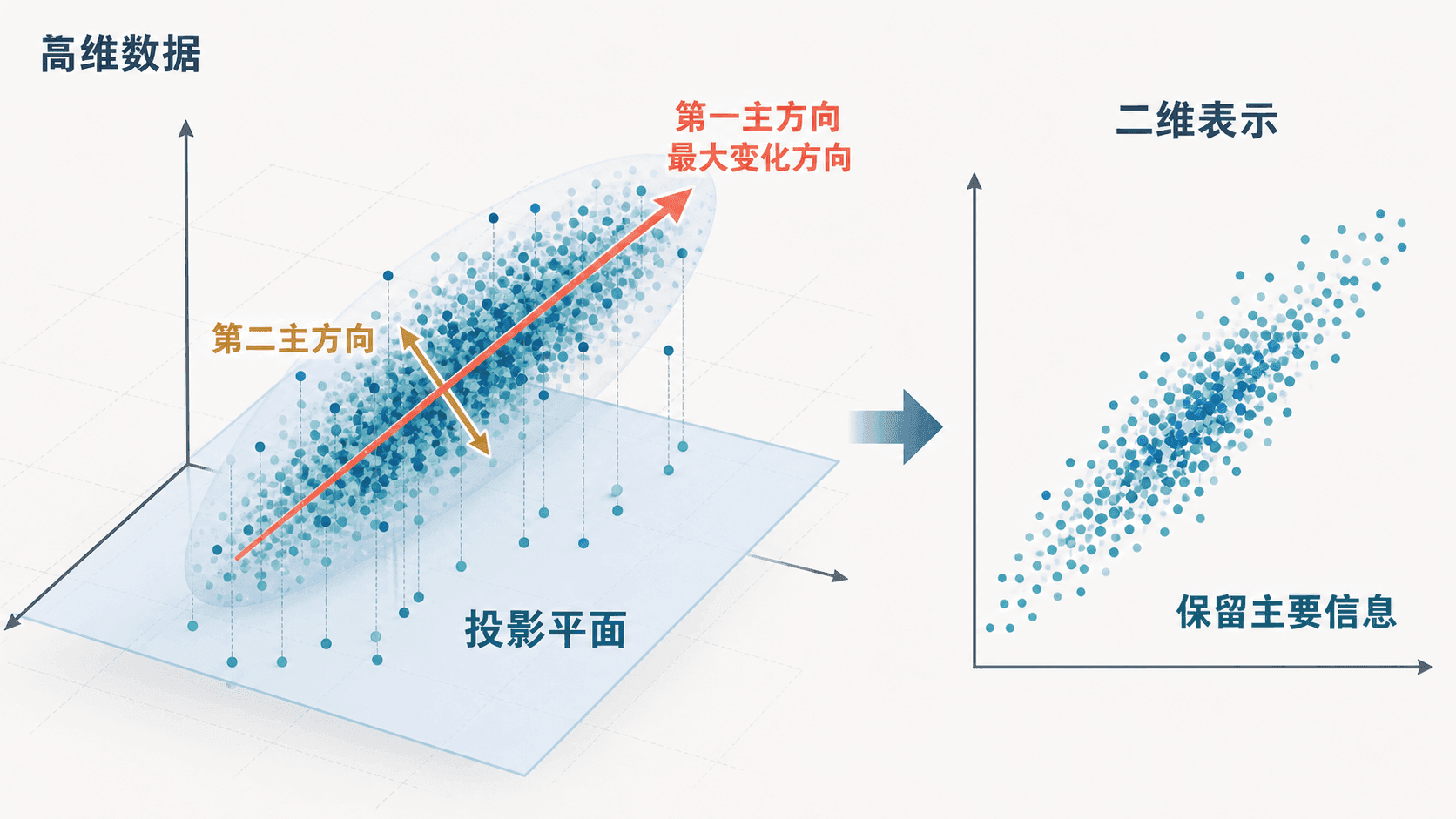
数据降维把高维点云投影到主要变化方向上,用少量坐标保留主要结构。
推荐系统
推荐系统里常见一个用户-物品评分矩阵。行表示用户,列表示电影、课程或商品,矩阵中的数表示评分、点击或购买强度。现实中这个矩阵往往非常稀疏,因为每个用户只接触过少量物品。
低秩思想认为,评分背后可能有少量隐含因素。例如用户可能偏好动作、悬疑、轻松、严肃等维度,物品也可以在这些维度上有不同强度。用户向量和物品向量的点积,就可以给出一个预测评分。
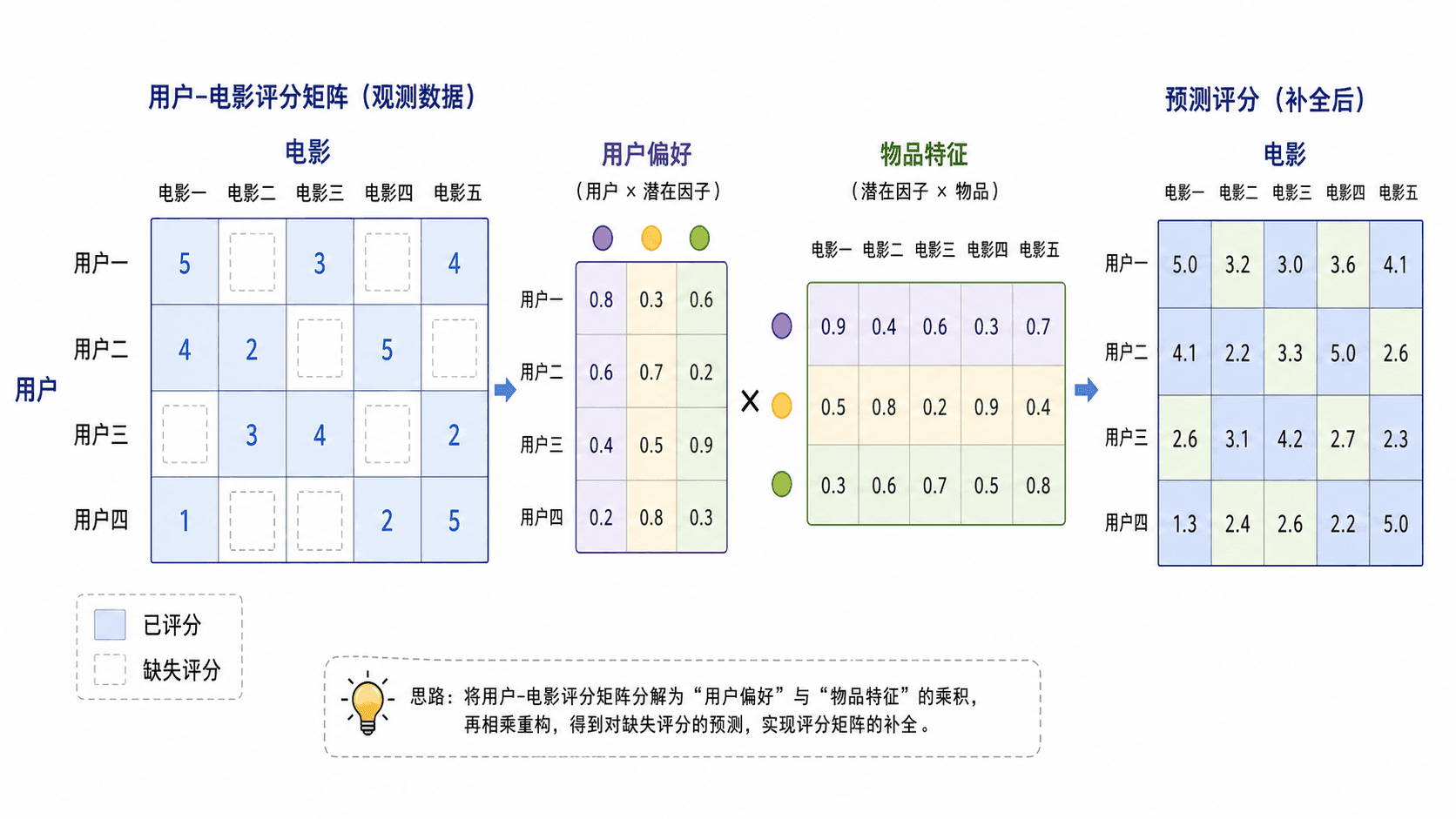
稀疏评分矩阵可以用少量用户偏好因子和物品特征因子来近似。
真实推荐系统通常不会把缺失评分直接当作 0 后做普通 SVD。更常见的做法是只在已观察到的评分上优化低秩因子,同时加入正则化和偏置项。本章只借用低秩分解的思想理解推荐的基本结构。
噪声过滤
在图像、传感器、语音或实验数据里,噪声常常分散在很多弱方向上,而真正的结构会集中在少数较大的奇异值上。因此,可以先做 SVD,再保留较大的奇异值,把很小的奇异值对应的部分丢掉。
不过这个方法不能机械使用。如果原始信号本身就包含细纹理、尖峰或罕见模式,这些信息也可能落在较小的奇异值里。降噪的本质是选择:你要保留稳定的整体结构,还是要保留可能重要的细节。
综合例题与练习
例题:从奇异值判断近似质量
某个矩阵的非零奇异值是:
如果只保留前两个奇异值,求保留信息比例,并给出 Frobenius 误差。
先计算全部平方和。因为信息比例通常用奇异值平方衡量,所以分母是:
这个结果说明前两个奇异值已经占了几乎全部平方能量。若这个矩阵来自一张图片或一个数据集,秩 2 近似很可能已经抓住了主要结构。
练习
- 设
写出 的非零奇异值,并说明它的秩。
这个矩阵本身已经是矩形对角缩放矩阵。非零奇异值是 和 ,所以秩是 。
- 一张 的灰度图像,如果用 的低秩近似保存,大约需要保存多少个数?和原始的 个数相比如何?
低秩近似大约需要保存:
这比原始的 个数少很多,约为原来的 。实际文件大小还会受编码方式、数值精度和格式影响。
- 设
判断 的秩,并猜测它有几个非零奇异值。
两行相同,两列也相同,所以 的秩是 。非零奇异值的个数等于秩,因此它只有一个非零奇异值。事实上,这个非零奇异值是 。
- 为什么说 SVD 比特征值分解更适合处理一般数据矩阵?
特征值分解通常要求矩阵是方阵,而且矩阵还不一定有足够好的特征向量。数据矩阵经常是矩形的,例如“样本数 × 特征数”或“用户数 × 物品数”。SVD 可以用于任意实矩阵,并且把输入方向、输出方向和拉伸长度分开,因此更适合做压缩、降维和近似。
本章收束
SVD 把本课程的几条主线合在了一起。正交矩阵来自点积、长度和正交基;奇异值连接到特征值;低秩近似连接到秩、投影和最小二乘;图像、数据和推荐系统则把矩阵从纸面计算带回真实问题。
学到这里,矩阵不再只是一个数字表。你可以把它看成一个把输入空间重新对齐、按主轴缩放、再放进输出空间的变换。SVD 的威力就在于:即使矩阵不是方阵,即使没有清楚的特征向量,它仍然能给出这幅结构图。