大分子识别的特异性
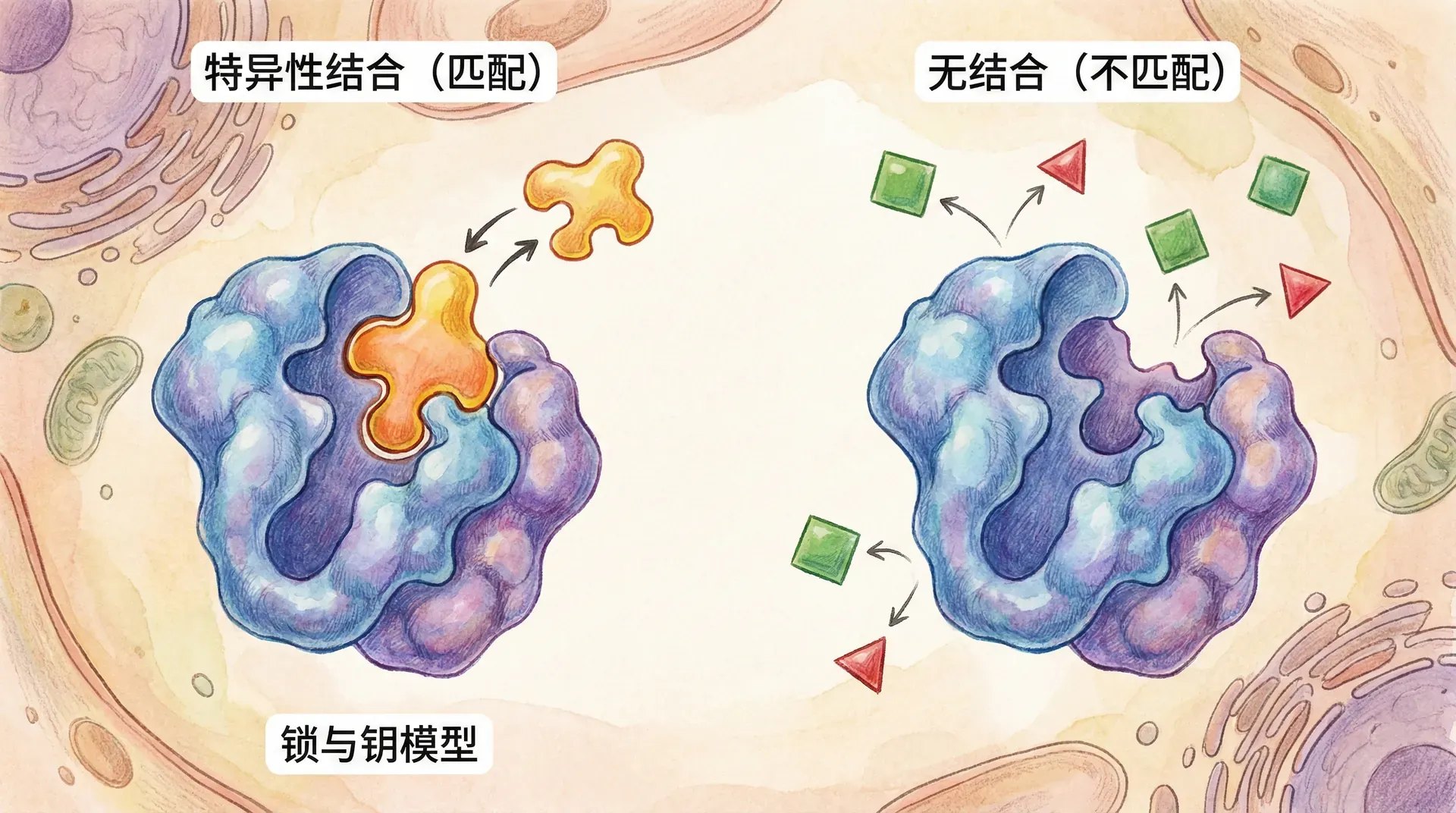
在生命系统中,分子之间实现高度专一的识别(即“特异性识别”)是维持正常生理活动的核心基础。试想,在人口众多的城市中,人们依靠姓名或长相迅速准确地找到自己的亲朋好友,而不会把陌生人错认成家人。类似地,成千上万种蛋白质、DNA、RNA等大分子在高度复杂和拥挤的细胞内环境中,仍能凭借各自“分子的识别密码”,专一找到彼此理想的结合对象,这种能力即为分子识别的特异性。
特异性描述的是生物大分子如何在众多极为相似的分子中,准确锁定并结合其独特目标。这一概念和结合的紧密度(亲和力)并非等同:亲和力关注结合紧密与否,而特异性强调在海量类似分子的环境下能否“认准”对象。高亲和力不必然带来高特异性,反之亦然。
分子的高特异性识别不仅决定了蛋白质的正确功能,还影响着信号转导、基因调控、免疫应答等重要生命过程。例如,抗体对抗原的精准识别、转录因子区分特定DNA片段、激素受体筛选信号分子,都是依赖于识别的专一性。本章将从原理到实例,系统探讨支撑大分子识别特异性的机制及其在生理和疾病中的意义。
特异性与亲和力的区别
特异性的定量描述及其意义
许多初学者容易将“特异性”和“亲和力”混淆。亲和力描述的是某一分子与其结合对象之间的结合强度,常用解离常数(Kd,越小表示结合越强)表示。但“特异性”强调的是:在一堆潜在结合对象中,分子能否“选择性”地、更偏好地与特定目标结合。
科学上,特异性通常用目标和非目标之间解离常数的比值来衡量:
比值越高,表示分子对目标的识别选择性越强。例如,一个抗体如果能将特定抗原的 控制在 nM 量级,而对其他分子的结合 为 μM 以上,那么它的特异性就很高。
配体浓度对特异性表现的影响
在天然生物环境中,分子的真实浓度远非无限。实际中,配体的浓度直接影响特异性的实际表现。特别是在低浓度条件下,即使目标的结合亲和力不是最高,但结合的选择性(特异性)会使稀有目标分子更有概率被准确捕获。
例如,如果某蛋白与目标伙伴的 ,但对其他非特异性对象的 ,那么只有在配体浓度低于 时,特异性才能得以凸显。如果浓度过高,则非特异性结合也会不可避免地增多。
让我们看一下浓度如何影响结合特异性:
如图可见,在较低的配体浓度下(比如 以内),特异性结合的比例远超非特异性结合,生物体系能够最大程度地利用自身分子的高选择性。在高浓度条件下,非特异性结合随之增加,特异性优势下降。这也解释了为什么大部分信号转导、调节机制都发生在较低浓度范围内,从而维持高效和有序的分子识别系统。此外,通过调节分子浓度,细胞可以灵活地回应环境刺激,高效分配资源,使得信号传递既迅速又精确。
因此,生物分子的特异性识别是分子层面生命活动精确性的保障,是功能分化和分子信号网络有序运行的核心基础。
蛋白质识别结构域的组合策略
SH2结构域的特异性机制
在人类细胞中,复杂而精密的信号传导网络依赖于极高的分子识别特异性,才能在成千上万种潜在相互作用中实现精确的信息传递。以SH2(Src Homology 2)结构域为代表,这类结构域广泛存在于各种信号蛋白中,起着“分子邮差”的作用——能够精准识别磷酸化酪氨酸(pY)及其相邻氨基酸序列,从而决定细胞的命运和行为。
SH2结构域的高特异性并非来自单一结构,而是多种分子机制协同贡献的结果。其主要特异性机制包括:
在细胞内,SH2结构域可以防止错误信号扩散,从而保证了信号通路的单向性和准确性。例如,在生长因子受体激活下,只允许被正确磷酸化的底物与下游信号分子结合,防止信号串扰。
多模块组合增强特异性
现代蛋白质往往并非单一识别结构域。许多信号蛋白通过串联多个模块(如SH2、SH3、PH、PDZ、WW等结构域),通过空间和序列上的协作作用,极大提高整体特异性。这种“多因子验证机制”类似于生活中的双重或多重身份验证:只有同时满足多种条件时,识别与激活过程才会发生。
单个SH2结构域的识别特异性约为100倍(区分目标/背景的能力),但当两个SH2结构域以模块化组合出现在同一蛋白质中时,整体特异性理论上可以“乘法级放大”至10,000倍(100 × 100),大幅提升了信号识别的选择性。
例如,哺乳动物Grb2蛋白拥有两个SH3和一个SH2结构域,能够桥接多种信号组分,仅在特定时空条件下形成信号复合物,保证细胞响应的精确性和有限性。
蛋白质
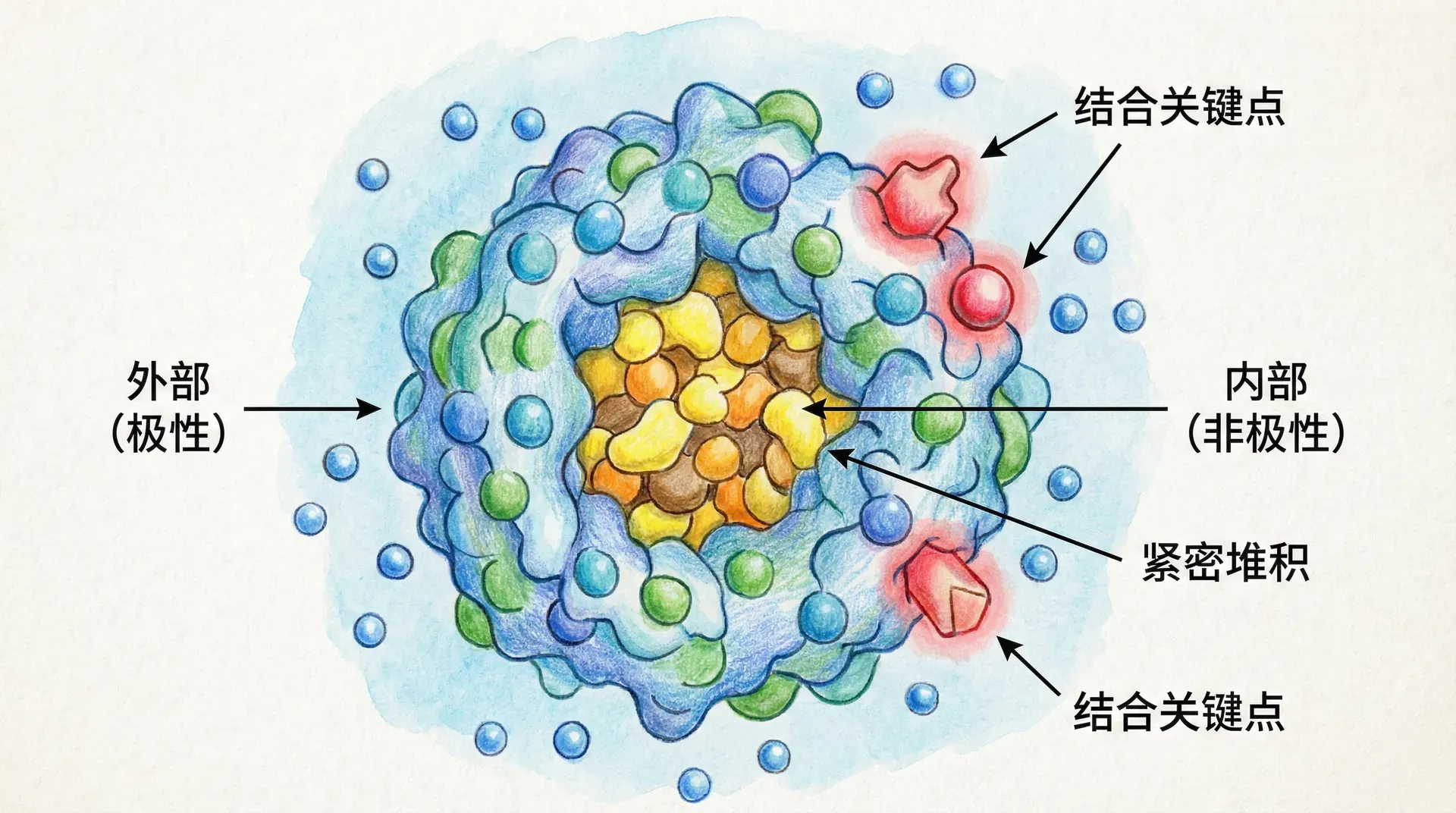
热点残基与疏水核心
蛋白质-蛋白质相互作用界面往往面积广阔,包含上百个残基,但实际上,只有极少数残基——即“热点残基”——对稳定复合物和赋予特异性起决定性作用。这一性质也被称为“能量分布不均匀定律”。
热点残基的关键特征和作用:
- 结构特征:热点通常埋藏在界面的疏水核心,被部分暴露、部分包埋,形成与对方蛋白结构高度互补的小型“能量锁”。
- 能量贡献:实验显示,一处或少数几个热点残基的突变即可导致结合自由能ΔG下降超过2 kcal/mol,映射至结合亲和力即Kd可增加10~100倍,结合几乎完全丧失。
- 进化保守性:这些热点通常进化上极为保守,对蛋白质识别和功能至关重要,如果突变则可能造成信号传导障碍甚至致病。
- 分布规律:热点沿界面非均匀分布,约占全部结合能量的50-75%,而大部分表面残基的贡献微乎其微。
下方是热点残基在能量贡献上的“不均匀性”图表:
如图所示,大多数界面残基(蓝色小柱)的能量贡献小于0.5 kcal/mol,属于“辅助填充”角色,而少数热点残基(用红色标注)能量贡献巨大(>2.5 kcal/mol),主导复合物的形成与维系。
热点残基在疾病和药物设计中的意义
- 疾病关联:许多遗传病、肿瘤驱动突变往往发生在热点残基,如p53肿瘤抑制蛋白的常见突变位点,直接削弱其与DNA或其他蛋白的结合。
- 药物靶向:当前新一代蛋白-蛋白相互作用抑制剂的设计思路,就是用小分子或肽类专门“狙击”热点残基,实现高度特异性干扰,兼具较高亲和力和选择性。
- 未来展望:利用AI和结构生物学方法预测和修饰热点残基,有望推动精准药物和蛋白工程的发展。
总体而言,对热点残基识别和机制的挖掘,是深入理解蛋白质识别特异性本质、破解复杂生物调控网络的关键一环。
DNA序列识别的分子机制
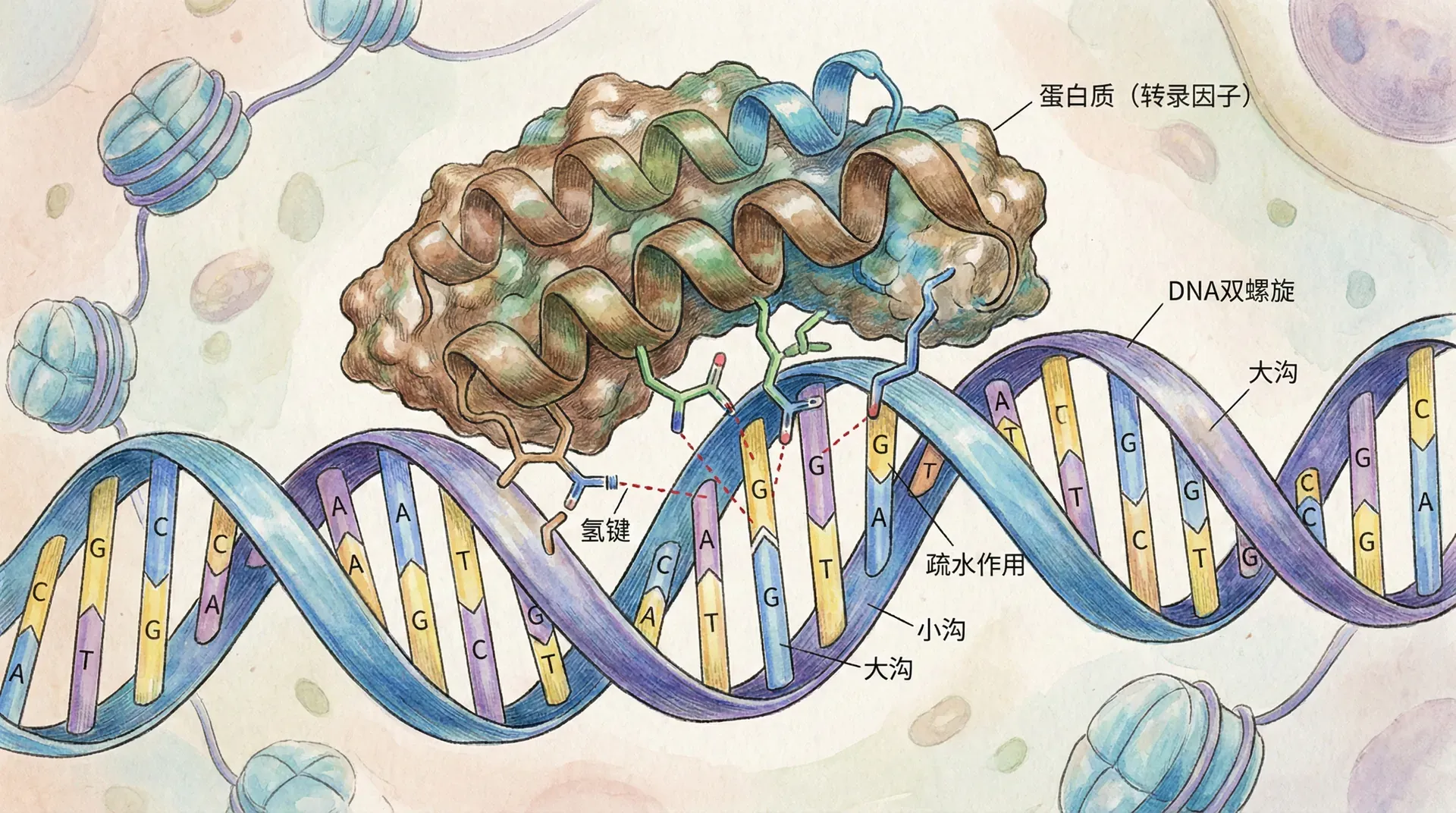
DNA序列的精准识别是生命活动高度精确化的根本。蛋白质如何从海量近似的核苷酸序列中准确识别出“目标片段”,关乎基因调控、细胞分化和应激反应等关键生物过程。不同于蛋白质-蛋白质识别,蛋白-DNA间的信息解读高度依赖于序列和结构的双重代码。
直接接触与构象诱导
转录因子识别特定DNA序列的机制,是分子生物学中最精巧和高度特异的分子识别之一。这种识别主要通过两种互补机制联合作用:
直接接触机制
转录因子中的氨基酸残基通过其侧链伸入DNA的大沟、小沟,直接与碱基形成氢键、疏水作用和范德华力。这些直接接触带来高精度的序列判别——每个碱基对因其在大沟中的化学基团分布不同,使蛋白能够“读取”序列。例如,碱基A-T和G-C在大沟中暴露出不同的氢键供体/受体,转录因子可据此辨识哪一对碱基处于何位置。
另外,不同的蛋白-DNA结合模块(如锌指、螺旋-转角-螺旋、亮氨酸拉链)通过不同的构象和表面电荷分布,实现多样化且高度特异的识别。例如锌指蛋白可以“逐字逐句”顺序扫描DNA,精确判定上游多个碱基对。
构象诱导机制
DNA结合并非静态锁钥:转录因子与DNA结合时,两者会发生细微但关键的结构重塑。例如,蛋白中的某些“柔性”结构块会因接触特定DNA而折叠成活跃构象,反过来DNA的小沟宽度、螺距甚至主链构型也会受蛋白诱导发生改变。这种“诱导契合”机制极大增强了识别的专一性。理想目标序列能够诱发蛋白形成最适宜结合的构象。而仅有部分碱基匹配时,这种契合无法顺利完成——因此错误的DNA序列极少被误识。
此外,构象变化还为生物系统提供了动态调控窗口——如某些转录因子在细胞受到刺激后才改变空间结构,只有那时才能识别DNA启动子,因而系统灵活应对外界变化。
水分子的特异性贡献
长期以来,传统观念认为蛋白质-DNA识别的特异性主要源自直接分子接触。但近年来高分辨率结构和动力学研究表明,水分子作为“分子桥梁” 同样深度参与识别网络,成为提高辨析力的重要角色。
生物学研究显示,某些转录因子-DNA复合物中,超过30%的特异性识别由水分子介导的氢键网络实现。这些水分子稳定且位置有选择性,是复合物不可或缺的结构组分,而非简单充当“溶剂”角色。
水介导识别的分子优势主要体现在:
实际案例中,如TATA结合蛋白(TBP)识别启动子时,既依靠氨基酸与TATA盒的直接接触,也高度依赖于水分子桥的介入。对这些关键水分子的移除或位置轻微扰动,即可显著损害结合能力和选择性。
二聚化与特异性增强
协同效应的数学基础
在遗传调控元件中,常见转录因子的结合能力由二聚体、三聚体乃至高阶寡聚体实现——这大幅提升了序列选择性。该策略的增强效果可以用数学模型直观说明:
假设单个蛋白分子的识别特异性为S₁,则n聚体整体特异性激增为S₁^n。哪怕每个单体的特异性不高,通过二聚、三聚后的“积效应”,系统的总体特异性成指数级增长。例如,单体特异性为10倍时,二聚体即可实现100倍选择性,三聚体达1000倍,依此类推。
下方图表展现了这一协同增长模式:
这一指数增长模式不仅解释了复杂基因调控区为何常含有多个结合位点,也提示通过人为设计多聚化结合模块,可大幅提高人工蛋白或药物分子的专一性。
实际生物系统中的例子
在中国和全球科学家的诸多研究中,二聚体/多聚体在控制特异性方面屡现佳例:
- p53转录因子:“基因组守护者”p53通过四聚体结构结合DNA,能实现高达数千倍的目标区分率,确保在DNA损伤时才被高特异性激活,防止对正常DNA造成误判激活而导致无意义的细胞死亡。
- STAT家族转录因子:许多STAT家族成员作为磷酸化二聚体进入细胞核后,只有同时结合到两个彼此特定间距、方向的DNA元件时,才可稳定调控目标基因,极大提升识别准确性。
- 核受体及异源二聚体:某些情况下两个不同蛋白只有协同结合同一DNA区段才能激活下游通路,阻止信号“串台”。
此外,在疾病、进化与人工设计领域,调控蛋白质多聚化状态成为精细调节基因表达特异性的有效切入点。
总之,DNA识别的分子机制综合体现了生命系统在结构层面和动力学层面的多层次调控,以实现对基因表达、信号网络的最高级精度掌控。
总结
大分子识别的特异性是生物系统得以精准、有序运行的核心。本章系统梳理了特异性和亲和力的本质区别,强调特异性应通过解离常数(Kd)比值定量评估,而不能仅以亲和力高低论断。我们分析了不同配体浓度下特异性的动态表现,并解释了生命系统为何普遍选择低浓度环境以获得更高专一性。
在分子机制层面,多模块(如SH2结构域等)组合与协作极大提升了识别特异性,赋予生物分子复杂且可靠的决策能力;而蛋白质界面上的“热点残基”则体现了结合能与特异性的高度不均匀分布,为药物设计和工程改造提供了理论基础。DNA识别不仅有蛋白-碱基的直接接触,还需要考虑构象诱导、水分子等间接调控因素,共同塑造了分子识别的精准性。
综上,二聚化、多聚化等集体行为及协同效应能够实现特异性的指数级增强,为我们理解生物系统的信息处理极限与创新应用提供了独特视角。上述机制揭示了生命运作的严密逻辑,也持续为药物开发和生物工程带来新的机遇,推动人类不断探索生命的本质。