排行榜与排序
计数器与限流之后,我们来看 Redis 在「排序」场景下的典型用法:排行榜。游戏段位、热搜词、活动积分、直播打赏榜……背后都需要「按某个数值排序、取前 N 名、查某人排名」;若用数据库做,往往要 ORDER BY score DESC LIMIT N,数据量一大就慢,且高并发下更新与查询都容易成为瓶颈。
Redis 的 Sorted Set 恰恰为这类需求而生:成员带分数、按分数有序、支持按排名区间取、按分数区间取、以及 O(1) 查某成员的分数与排名。 这部分我们从 Sorted Set 的能力说起,再落到实时排行榜的设计,最后讨论分数、权重与时间如何编码进一个「数值」,让排名既准确又可控。
Sorted Set 的威力
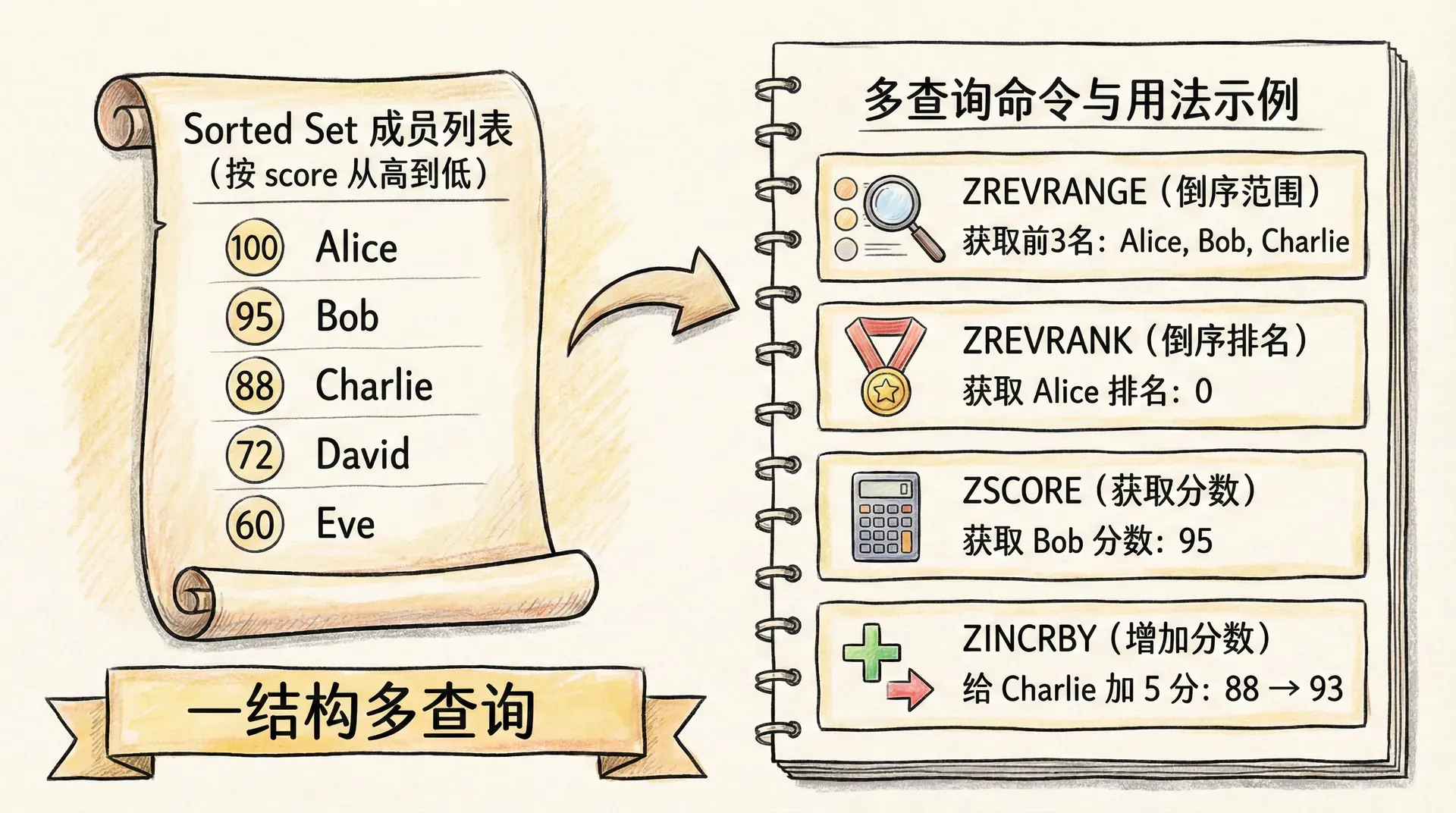
Sorted Set 在第三讲里已经出现过:成员不重复,每个成员关联一个浮点型的 score,集合按 score 排序。它和「排行榜」的语义几乎一一对应:成员是玩家 ID、商品 ID 或词条,score 是积分、热度或销量;ZADD 往榜里加人、ZINCRBY 给人加分、ZREVRANGE 取前 N 名、ZREVRANK 查某人第几名、ZSCORE 查某人分数。这些操作在 Redis 内部要么是 O(log N)(跳表),要么是 O(1)(哈希表查 score),单机百万级成员下仍是毫秒级,而数据库的 ORDER BY + LIMIT 在无合适索引时很容易到百毫秒甚至秒级。
威力不仅在于快,还在于一次结构、多种查询。同一个 ZSET 可以按排名取 Top 10(ZREVRANGE 0 9)、按分数区间取「积分在 80~100 之间的所有人」(ZRANGEBYSCORE)、查某人排名(ZREVRANK)和分数(ZSCORE),无需为每种查询再建索引或冗余表。更新也简单:用户得分变化时 ZINCRBY 一次即可,排名随之更新,无需应用层重算或批量更新。因此,凡是「按一个数排序、需要实时更新、高并发读」的场景,Sorted Set 都是首选;排行榜只是其中最直观的一种,延时队列、滑动窗口限流(上一讲)同样依赖「按 score 有序、按区间删查」的能力。
实时排行榜
「实时」在这里有两层意思:一是数据更新后,排名很快就能反映出来(通常就是下一次查询);二是高并发读写下,仍然能保持低延迟与正确性。用 Sorted Set 做排行榜时,Key 通常按「榜单类型 + 业务维度」设计,例如 rank:game:season1、rank:activity:2024spring;member 存被排序的实体 ID(用户 ID、商品 ID 等),score 存用于排序的数值(积分、销量、热度等)。用户完成一局游戏、获得积分时,调用 ZINCRBY 给该用户在对应榜单上的分数加上本次得分;查 Top 10 时 ZREVRANGE key 0 9 WITHSCORES,查当前用户排名时 ZREVRANK key member,查分数时 ZSCORE key member。写入与查询都落在 Redis 上,无需扫表、无需排序,延迟稳定。
榜单若按时间维度切分(日榜、周榜、总榜),可以为每个维度维护一个 Key,例如 rank:daily:20240203、rank:weekly:2024w05、rank:alltime。日榜、周榜的 Key 可以设置 TTL,到期自动删除或由定时任务归档;总榜长期保留,但需注意单 Key 的成员数量与内存占用。若同一用户可能出现在多个榜单(如多个游戏模式、多个活动),Key 中就要体现「哪个榜」,避免串榜。实时排行榜的难点往往不在 Redis 命令,而在「分数如何定义、同分如何区分、历史数据如何归档」,这些会直接决定 score 的设计。
redis
ZINCRBY rank:game:season1 150 user:10001
ZREVRANGE rank:game:season1 0 9 WITHSCORES
ZREVRANK rank:game:season1 user:10001
ZSCORE rank:game:season1 user:10001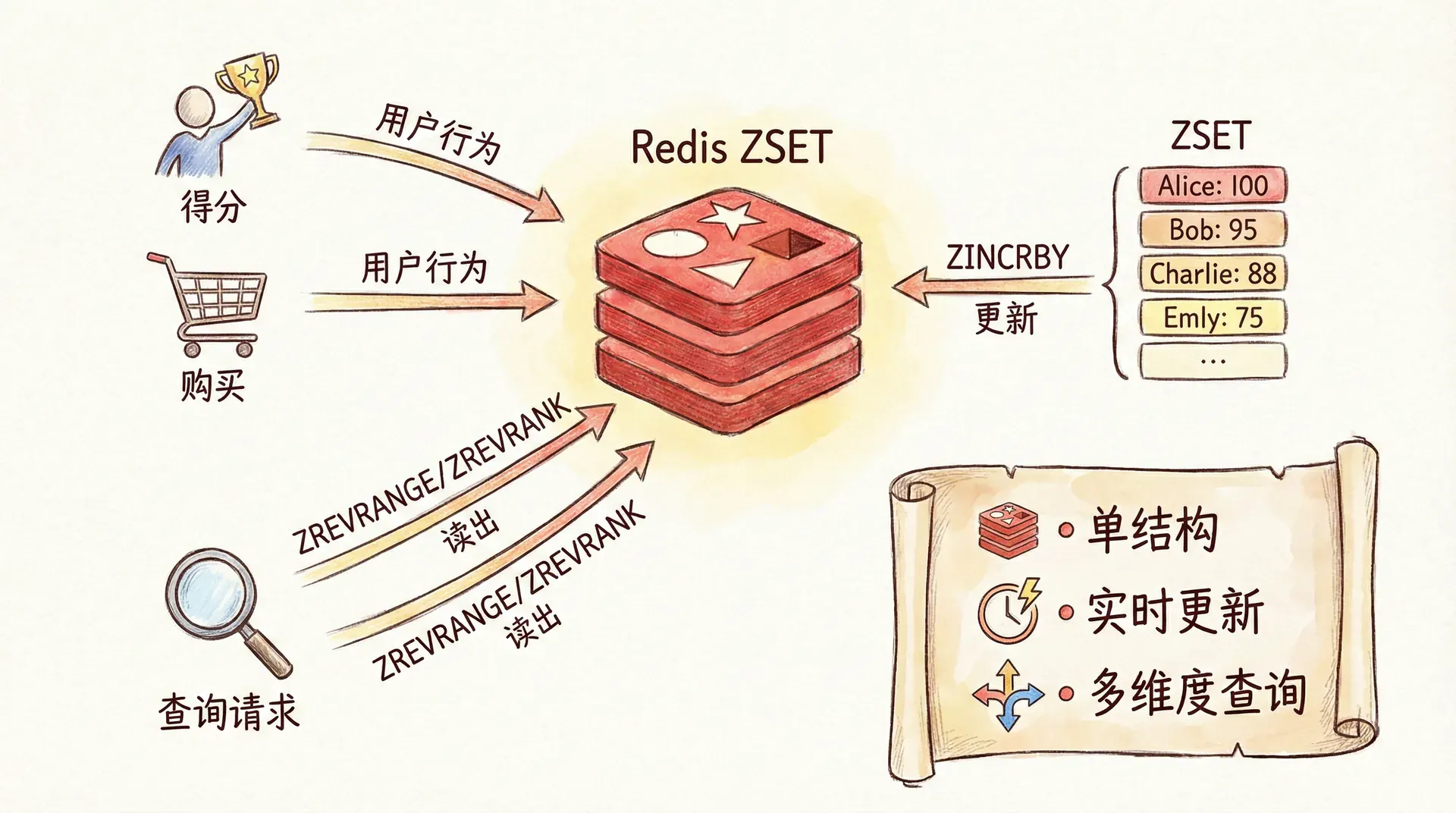
分数、权重与时间
排行榜里经常遇到「先按 A 排,A 相同再按 B 排」的需求,例如先按积分、积分相同再按达成时间(先达成的排前面)。Sorted Set 的 score 只有一个数,默认同分时按 member 的字典序排,往往不符合业务。做法是把「多维度」编码进一个 score:高位放主维度,低位放次维度,这样比较时自然先比主再比次。例如「等级 × 10^10 + 战力」,等级高的必然排在前面,等级相同则战力高的在前;又如「通关层数 × 10^10 + (基准时间 − 通关时间)」,层数高的在前,层数相同则通关越早的在前(时间越小,基准减时间越大,score 越大)。
时间作为「次要排序」时,要避免时间戳直接当 score 导致主维度被淹没。若主维度是积分、积分范围在 0~1e6,可以用「积分 × 10^10 + 时间因子」,时间因子用「大数减时间戳」或「小数」表示「先达成的略大」,这样同分时先达成的排前面。注意 Redis 的 score 是 64 位浮点,有效整数精度大约到 2^53,预留位数时不要溢出;若维度多、范围大,也可以只做「主维度 + 时间」二维,更多维度用业务层二次排序或换方案。
text
复合 score 示例(等级主、战力次):
score = level * 1e10 + power
同分时按时间(先达成略高):
score = main_score * 1e10 + (1 - timestamp / 1e10)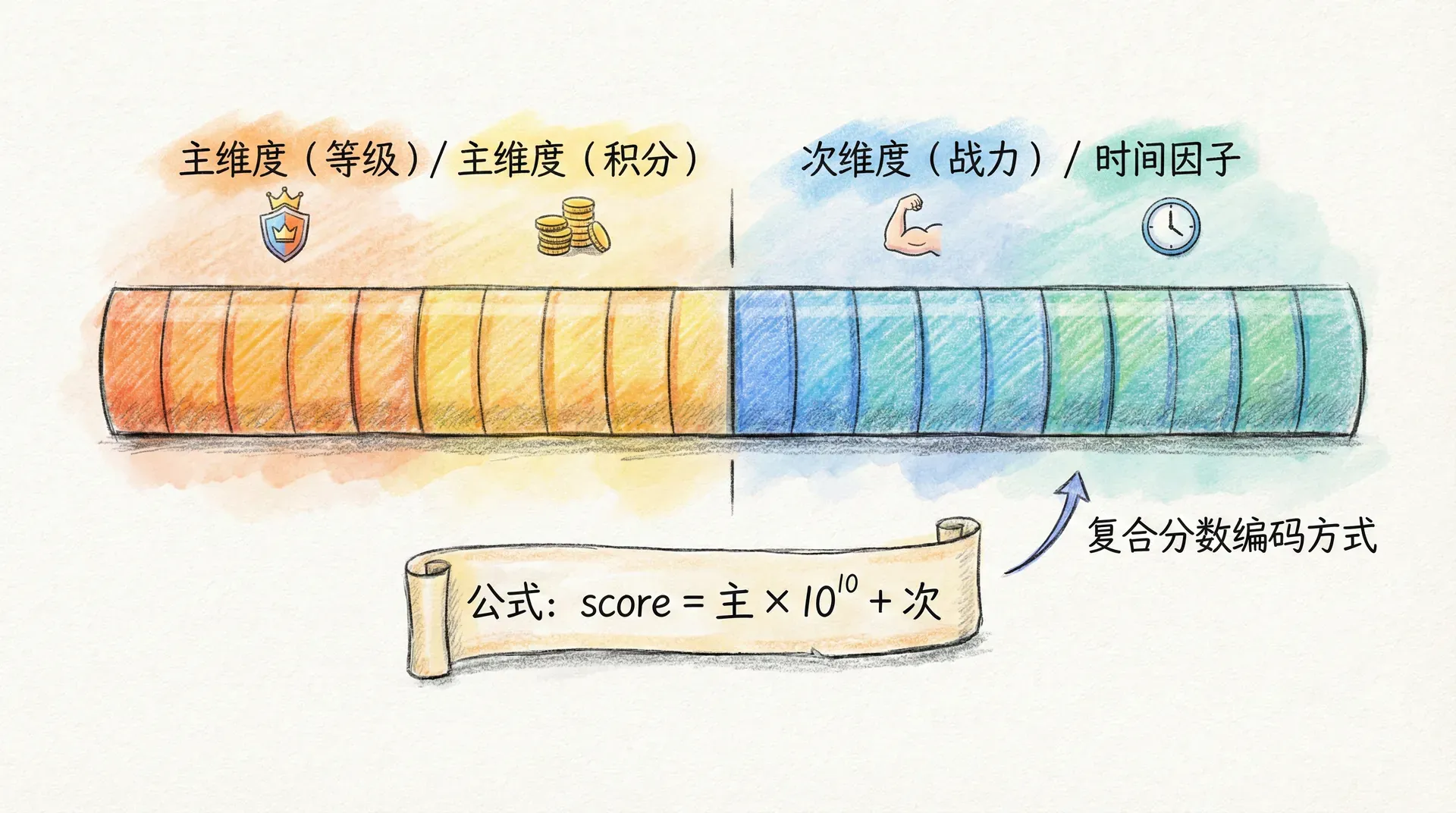
从排行榜延伸出去,Sorted Set 还能支撑「按时间范围取」的延时任务、按热度排序的推荐列表等,本质都是「成员 + 可比较的 score」。下一讲我们会看 Redis 在「消息与异步解耦」里的角色:List 与 Stream 的适用场景、简单消息队列的做法,以及 Redis 与 Kafka 的边界在哪里。