随机变量与分布函数
前几章一直在样本空间里讨论事件。抛两枚硬币时,我们可以说样本空间是 Ω={HH,HT,TH,TT},也可以讨论“至少出现一个正面”这样的事件。可是很多问题真正关心的不是原始结果本身,而是一个数:正面个数、点数和、等待时间、损失金额、测量误差。
随机变量就是完成这一步转换的工具。它把随机试验的结果映射成实数,于是事件运算可以和数轴上的区间、函数、图像接上。分布函数则把一个随机变量的全部概率信息压缩进一个函数里。
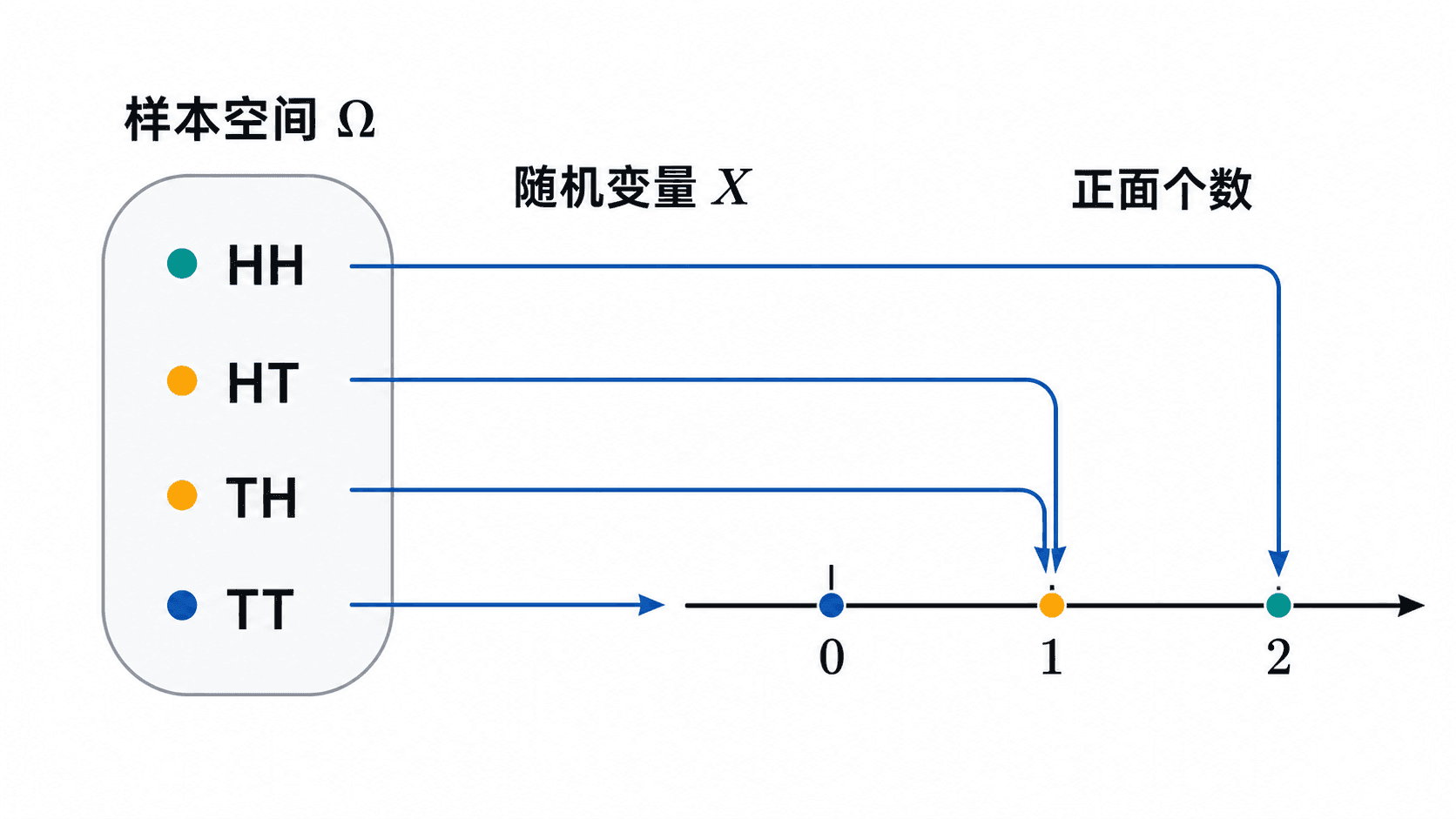 随机变量可以看作从样本空间到数轴的函数:每个随机结果对应一个数值。
随机变量可以看作从样本空间到数轴的函数:每个随机结果对应一个数值。
从随机结果到数值对象
随机变量 X 是定义在样本空间 Ω 上、取实数值的函数。也就是说,每个样本点 ω 都会被 X 指派一个数 X(ω)。
X:Ω→R
这句话容易被读得太抽象。看一个具体例子:抛两枚硬币,令 X 表示正面个数。那么
X(HH)=2,X(HT)=1,X(TH)=1,X(TT)
在这个例子里,HT 和 TH 是两个不同的样本点,但它们被同一个随机变量映射到同一个数 1。这很常见:随机变量会保留研究问题关心的信息,也会主动丢掉一些不关心的细节。
随机变量的“随机”来自输入的样本点还没有确定;随机变量本身是一条确定的规则。试验一旦发生,样本点确定下来,随机变量才给出一个具体观测值。
随机变量把原来写在样本空间里的事件改写成数轴上的事件。例如“正面个数至少为 1”可以写成
{X≥1}={ω∈Ω:X(ω)≥1}
在抛两枚硬币的例子中,这个事件就是 {HH,HT,TH}。以后我们常会直接写 P(X≥1),它的完整含义是“样本点落在使 X(ω)≥1 成立的那部分样本空间中的概率”。
例题:把事件翻译成随机变量语言
抛两枚公平硬币,令 X 为正面个数。求 P(X=1) 和 P(X≤1)。
先写出样本空间:Ω={HH,HT,TH,TT}。四个样本点等可能,每个概率都是 1/4。
这个例题看起来很小,但它包含本章的核心动作:先定义函数 X,再把关于数值的条件翻译回样本空间中的事件,最后计算概率。
分布函数如何读
随机变量有很多可能取值。我们需要一种统一方式描述“它落在各处的概率安排”。最稳定的工具是分布函数,也叫累积分布函数,记作 CDF。
FX(x)=P(X≤x),−∞<x<∞
对任意实数 x,FX(x) 都回答同一个问题:随机变量 X 取到不超过 x 的值的概率是多少。
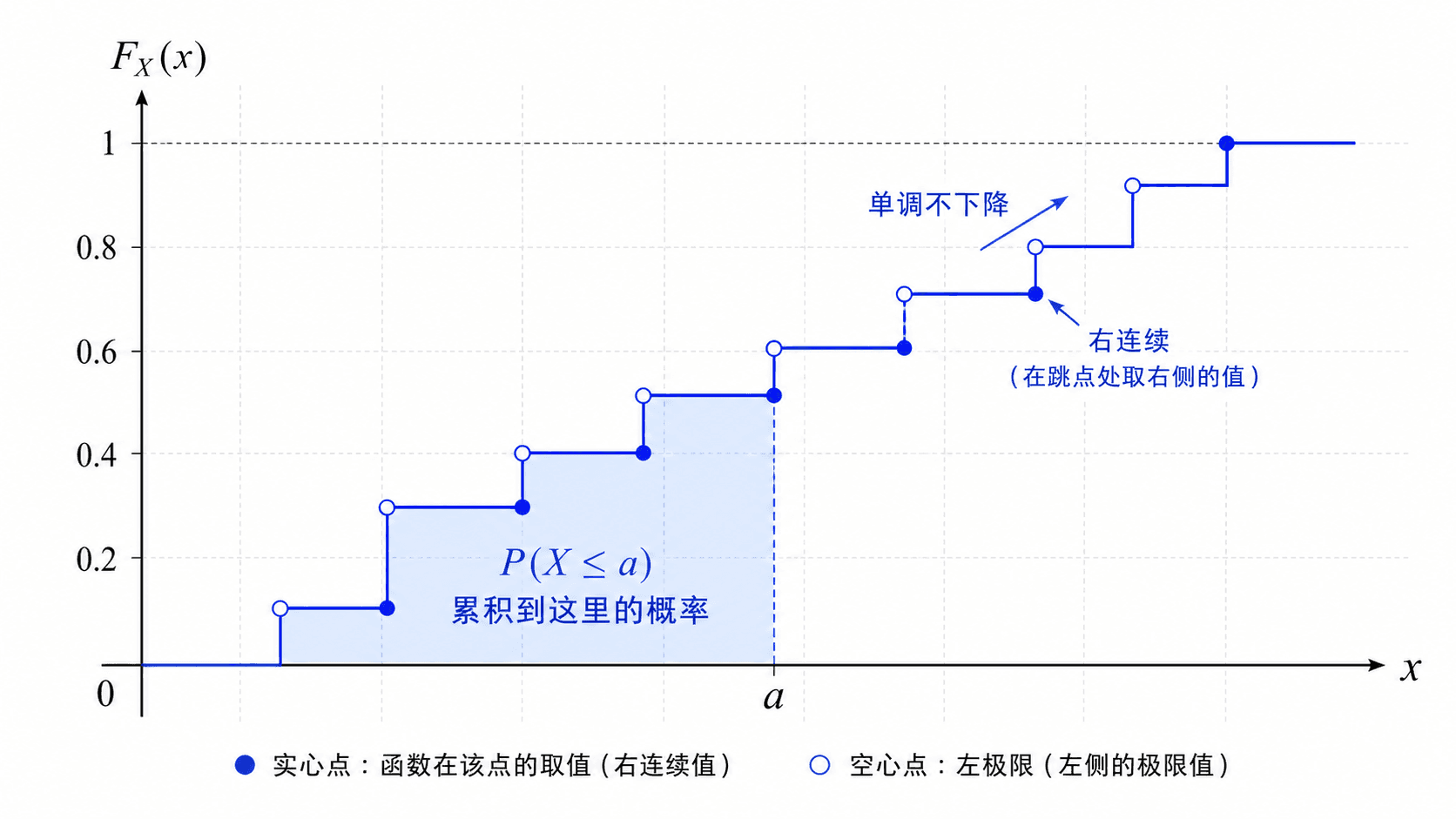 分布函数 FX(x) 表示随机变量取值不超过 x 的累积概率;图中阴影部分为 P(X≤a)。
分布函数 FX(x) 表示随机变量取值不超过 x 的累积概率;图中阴影部分为 P(X≤a)。
CDF 的图像要从“累积”去读。横轴上的 x 往右移动时,事件 {X≤x} 只会变大,不会变小,所以 FX(x) 单调不下降。它最左边趋近于 0,最右边趋近于 :
x→−∞limFX(x)=0,
CDF 还有一个本科概率论里经常用到的性质:它是右连续的。直观地说,当 x 从右侧非常靠近某个点时,FX(x) 的值会靠近该点处的函数值。
t↓xlimFX(t)=FX(x
右连续性在离散随机变量中尤其明显。若 X 在某点 a 有正概率,CDF 会在 a 处跳一下。因为定义使用的是 X≤a,所以跳跃后的高度才是 FX(a)。
从 CDF 读区间概率时,要留意端点。一般有 P(a<X≤b)=FX(b)−F。如果想算 ,还要把 的概率补进去,除非已经知道 。
CDF 可以统一离散与连续
CDF 的好处是它不要求随机变量必须离散或连续。只要 X 是随机变量,FX(x)=P(X≤x) 就有意义。后面我们会分别学习 PMF 和 PDF,但它们都可以回到 CDF:
- 对离散随机变量,CDF 是把每个点上的概率向左累加。
- 对连续随机变量,CDF 是把密度曲线从左到右积分。
- 对混合型随机变量,CDF 可能同时有平滑上升和跳跃。
本章先重点处理前两类,混合型分布等到条件分布和随机变量变换中再遇到。
离散随机变量与概率质量函数
如果随机变量 X 的可能取值是有限个或可列无限个,就称 X 为离散随机变量。此时最直接的描述方式是概率质量函数,记作 PMF:
pX(x)=P(X=x)
PMF 把每个可能取值上的概率列出来。它必须满足两件事:
pX(x)≥0
并且所有可能取值上的概率和为 1:
x∑pX(x)=1
这里的求和只对 X 可能取到的值求和;不可能取到的点可以看作概率质量为 0。
 PMF 读取点上的概率,PDF 通过曲线下小区间面积表示概率,CDF 表示随机变量不超过某值的累积概率。
PMF 读取点上的概率,PDF 通过曲线下小区间面积表示概率,CDF 表示随机变量不超过某值的累积概率。
离散随机变量的 CDF 可以由 PMF 累加得到:
FX(x)=t≤x∑pX(t)
反过来,若 X 在 a 处有可能取值,则这个点的概率等于 CDF 在 a 处的跳跃大小:
P(X=a)=FX(a)−FX(a
其中 FX(a−) 表示从左边逼近 a 时的极限。
例题:两枚骰子的点数和
掷两枚公平骰子,令 S 表示点数和。S 的可能取值是 2,3,…,12,但这些值不是等可能的。
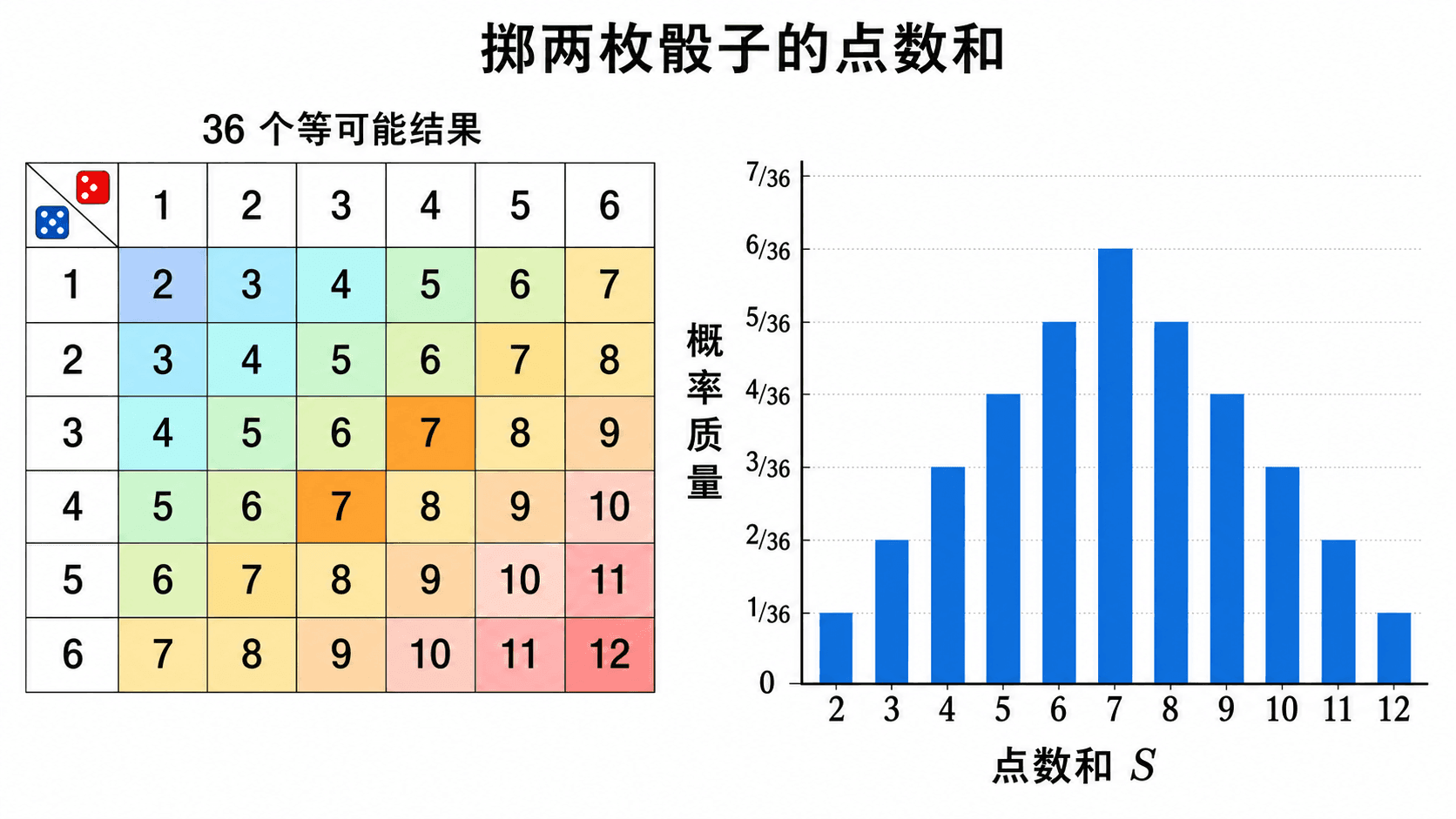 掷两枚骰子时,点数和 S 的分布由 36 个等可能结果汇总得到,7 的概率质量最大。
掷两枚骰子时,点数和 S 的分布由 36 个等可能结果汇总得到,7 的概率质量最大。
点数和为 7 的结果最多:
(1,6),(2,5),(3,4),(4,3),(5,2),(6,1)
所以
P(S=7)=366=61
完整的 PMF 是
P(S=s)=
从这个 PMF 可以立即算 CDF。例如
FS(5)=P(S≤5)=361
而
P(5<S≤8)=FS(8)−F
常见误区:把取值等可能当成结果等可能
骰子的 36 个有序结果等可能,但点数和的 11 个取值不等可能。把“样本点等可能”误读成“随机变量的取值等可能”,会把 P(S=7) 错算成 1/11。
判断一个随机变量的取值是否等可能,不能只看取值列表有多长。要看每个取值背后对应多少个样本点,以及这些样本点本身的概率是否相同。
连续随机变量与密度的第一眼
有些随机变量的取值不适合逐点列出。例如公交等待时间、电子元件寿命、测量误差等,常用连续模型描述。连续随机变量的一个典型特征是:单个点的概率通常为 0,但区间概率可以是正的。
如果存在非负函数 fX(x),使得对任意 a<b 都有
P(a<X≤b)=∫abfX
那么 fX 称为 X 的概率密度函数,记作 PDF。
密度函数也必须满足归一化条件:
fX(x)≥0,∫−∞∞f
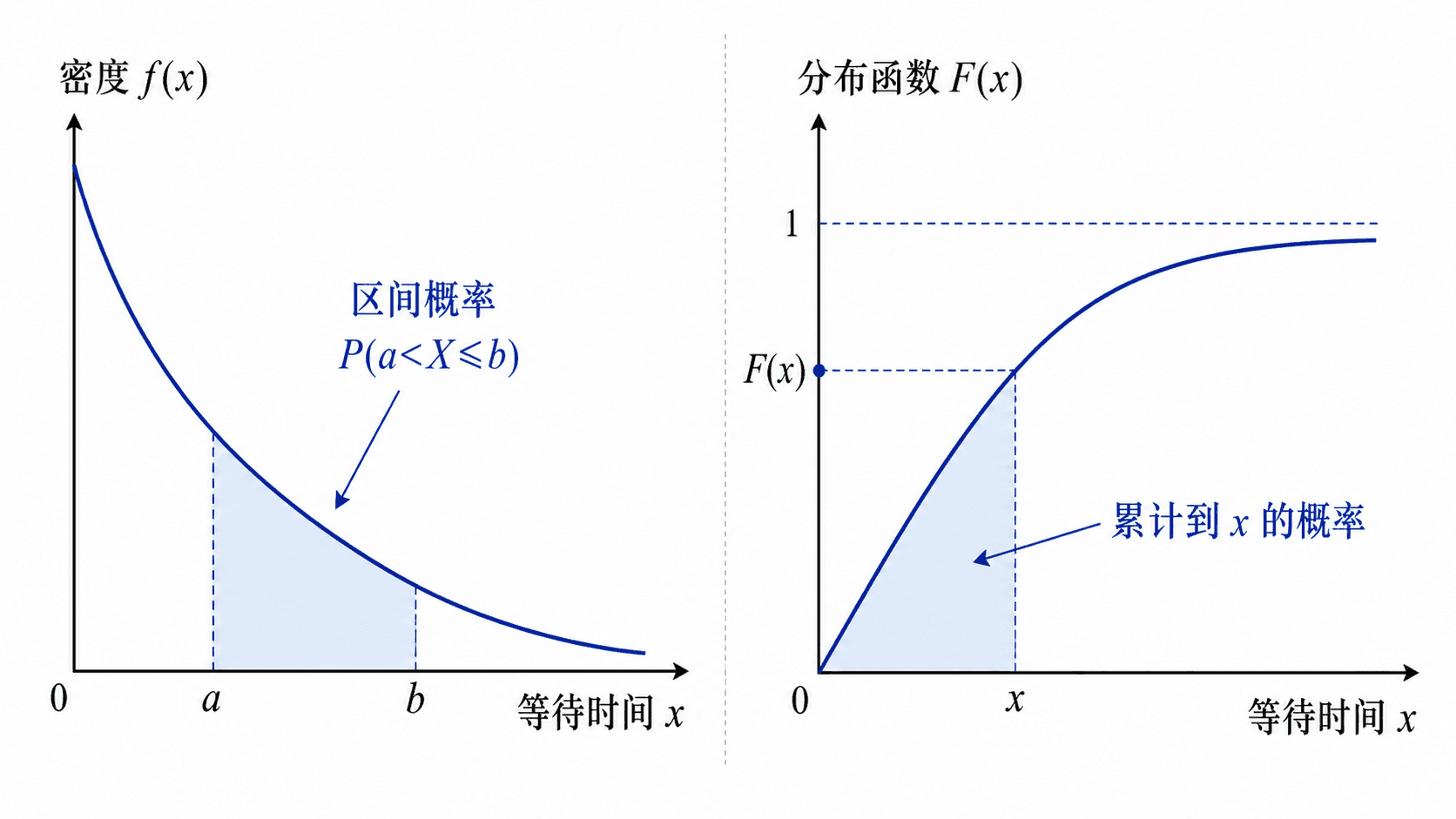 等待时间型连续随机变量的密度函数与分布函数关系:区间面积对应区间概率,分布函数对应累计概率。
等待时间型连续随机变量的密度函数与分布函数关系:区间面积对应区间概率,分布函数对应累计概率。
PDF 与 CDF 的关系可以写成
FX(x)=P(X≤x)=∫−∞
在 FX 可导的点上,也有
fX(x)=FX′(x)
这里要小心一句话:fX(x) 不是 P(X=x)。密度可以大于 1,也不直接表示概率;区间下方的面积才是概率。
例题:一个简单连续模型
假设等待时间 T 在 0 到 10 分钟之间均匀分布。直观上,每个长度相同的时间区间有相同概率。它的密度函数是
fT(t)={10
于是等待不超过 3 分钟的概率是
FT(3)=P(T≤3)=∫03
等待时间落在 4 到 7 分钟之间的概率是
P(4<T≤7)=∫47101
而某个精确时刻,比如恰好 4 分钟,概率为
P(T=4)=∫44101dt
这不是说“恰好 4 分钟不可能发生”,而是说在连续模型中,单个点没有长度,概率被分配到区间上。
随机变量不是一次观测值
实际使用中,很多混乱来自把三个对象混在一起:随机变量、分布、观测值。
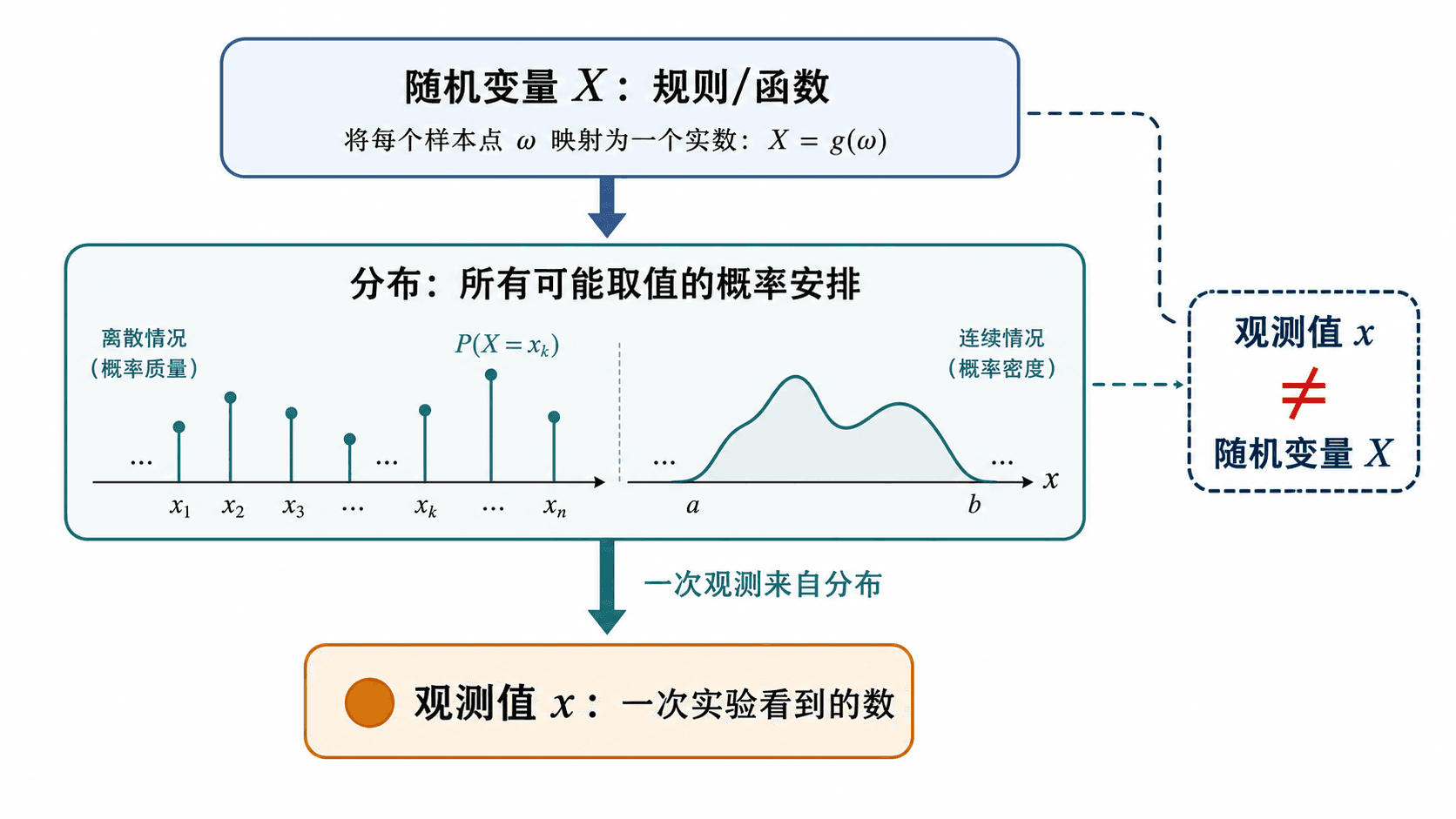 一次观测值 x 来自分布,但不等于整个随机变量 X。
一次观测值 x 来自分布,但不等于整个随机变量 X。
随机变量 X 是规则。它说明一次随机试验的结果如何被转成数。分布描述 X 的所有可能取值以及相应概率。观测值 x 是一次试验之后看到的具体数。
例如测量某零件长度误差时,可以令 X 表示“测量误差”。在测量之前,X 是随机变量;我们可能用一个以 0 为中心的连续分布描述它。测量之后得到 x=0.03 毫米,这是一次观测值。一次观测值不能代表整个分布,也不能反过来改变随机变量的定义。
大写字母 X 常用于随机变量,小写字母 x 常用于它的一个可能取值或一次观测值。这只是记号习惯,却能帮你避免把“规则”“概率安排”和“实际看到的数”混在一起。
同一个试验可以定义多个随机变量
一次随机试验可以派生出多个随机变量。掷两枚骰子,除了点数和 S,还可以定义最大点数 M、是否出现至少一个 6 的指示变量 I、两枚点数差的绝对值 D。
这些随机变量共享同一个样本空间,但分布不同。选择哪个随机变量,取决于问题问的是什么。
I={1,0,至少出现一个 6,没有出现 6.
这里 I 是一个只取 0 和 1 的随机变量。它把复杂样本点压缩成“事件是否发生”的数字表达。后面学习期望时,指示随机变量会非常有用。
怎样从题目中建立随机变量
建立随机变量时,不要急着套分布名称。先把“试验是什么”“数值规则是什么”“概率如何分配”分开。
先确认样本空间。题目中的基本随机结果是什么?是一次抽样的名单、一串硬币结果、两个骰子的有序点数,还是一个连续时间?
再定义随机变量。把每个样本点映射成题目真正关心的数,并明确记号,例如 X 表示成功次数,T 表示等待时间。
接着判断类型。若可能取值可以列出来,优先考虑 PMF;若用区间和面积描述更自然,可能需要 PDF 与 CDF。
一个小型建模例子
某网站记录用户从打开页面到点击按钮的等待时间。若我们只关心“是否在 5 秒内点击”,可以定义指示随机变量
I={1,0,5 秒内点击,超过 5 秒或未点击.
这时 I 是离散随机变量。若我们关心精确等待时长,则可以定义 T 为点击等待时间,这通常需要连续或带有混合成分的模型。两个随机变量来自同一批行为数据,但回答的问题不同。
本章小结
随机变量把样本空间中的随机结果变成数轴上的对象。定义随机变量时,先想清楚它是一条从 Ω 到 R 的规则,而不是试验后看到的那个数。
分布函数 FX(x)=P(X≤x) 是描述随机变量分布的统一工具。离散随机变量可以用 PMF 描述,CDF 是 PMF 的累加;连续随机变量可以用 PDF 描述,CDF 是 PDF 的积分。读图时记住:离散 CDF 的跳跃大小给出点概率,连续 PDF 的面积给出区间概率。
后续章节会分别展开常见离散分布和连续分布。本章的任务不是记住很多分布名称,而是把“样本空间、随机变量、分布函数、PMF、PDF”之间的关系摆正。
练习
练习一
抛三枚公平硬币,令 X 表示正面个数。写出 X 的 PMF,并求 FX(1)。
三枚硬币共有 8 个等可能结果。正面个数为 0,1,2,3 的结果数分别是 1,3,3,1,所以
练习二
某离散随机变量 Y 的 PMF 为
P(Y=0)=0.2,P(Y=2)=0.5,P(Y=5)=
求 FY(1)、FY(2) 和 P(1<。
因为 Y≤1 只包含取值 0,所以
FY(1)=0.2因为 Y≤ 包含取值 和 ,所以
练习三
设连续随机变量 Z 的密度为
fZ(z)={2z,0,
求 FZ(z) 在 0≤z≤1 上的表达式,并求 P(0.3<Z。
当 0≤z≤1 时,
FZ(z)=∫练习四
判断下面说法是否正确:如果一个连续随机变量的密度在 x=2 处等于 1.4,那么 P(X=2)=1.4。
这个说法不正确。密度函数的高度不是点概率,连续随机变量在单点处的概率通常为 0。密度为 1.4 只说明在 x=2 附近很短的小区间内,概率大约等于密度高度乘以区间长度。真正的概率来自面积,而不是单点高度。