随机变量函数、变量变换与卷积
前面几章已经把一个随机变量的分布、两个随机变量的联合分布、条件分布和条件期望铺好了。这一章开始问一个更常见的问题:已有随机变量之后,我们对它做函数运算,会得到什么分布?
这类问题看起来像代数计算,其实核心仍然是概率。函数会把数轴上的区间拉伸、压缩、折叠,也可能把平面上的一块区域扭成另一块区域;概率质量或概率面积不会凭空消失,只是换了坐标、换了位置。变量变换和卷积就是把这件事写成可计算的公式。
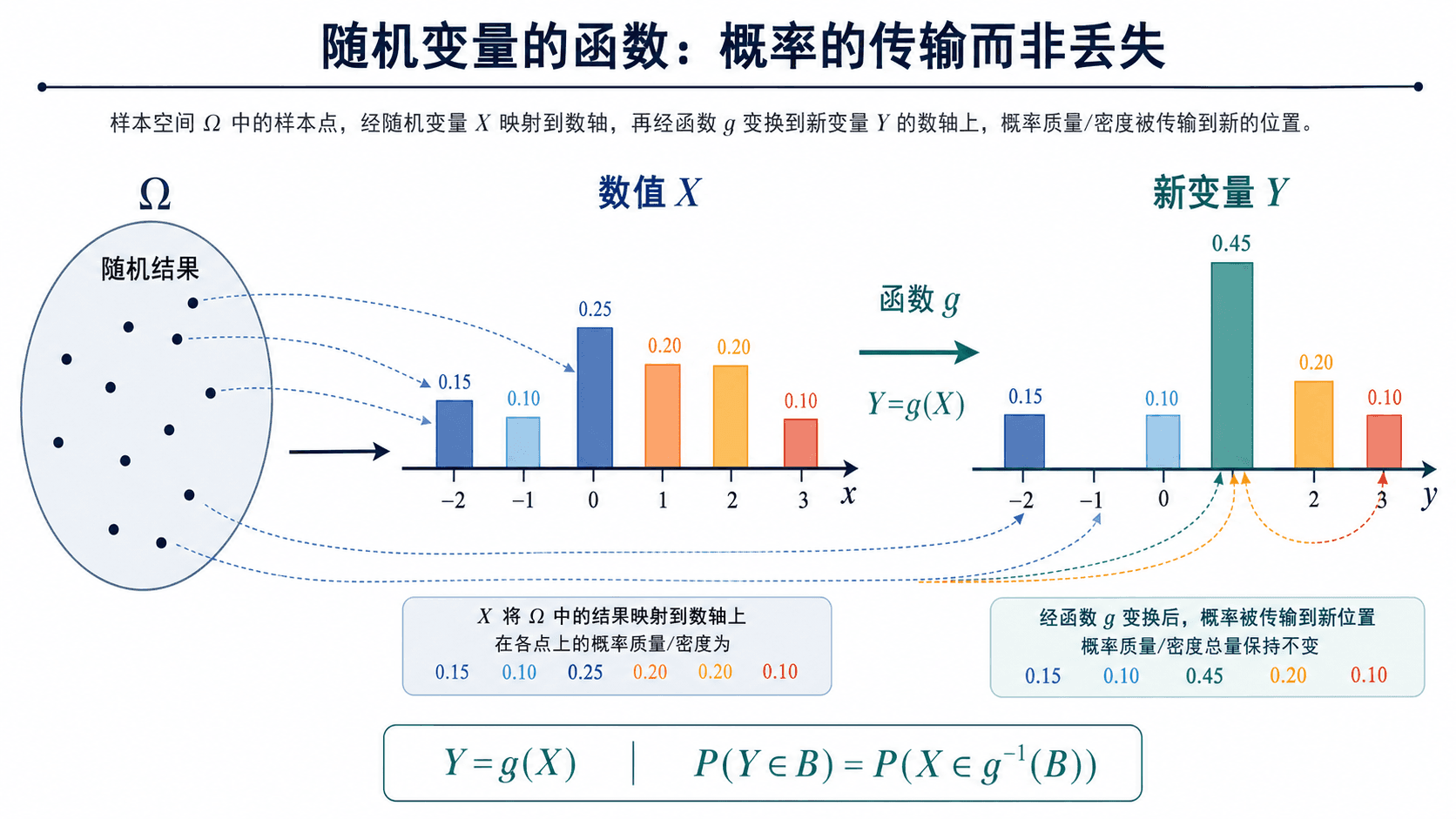 随机变量函数的基本图景:先由随机结果得到 X,再通过函数 g 得到 Y=g(X)。
随机变量函数的基本图景:先由随机结果得到 X,再通过函数 g 得到 Y=g(X)。
这一章解决什么问题
设 X 是一个随机变量,g 是一个普通函数。定义
Y=g(X)
后,Y 也是随机变量。问题是:如果已知 X 的分布,怎样求 Y 的分布?
如果 X 是离散型随机变量,最直接的办法是把落到同一个 y 的所有 x 概率加起来:
P(Y=y)=x:g(x)=y∑P(X=x)
如果 X 是连续型随机变量,就不能用“点概率”来搬运概率,因为 P(X=x)=0。这时要搬运的是区间概率或密度面积。最稳妥的方法有两条:先求分布函数,或者使用变量变换公式。
本章会反复使用一个原则:先找原像,再搬概率。对事件 Y∈B,它在 X 轴上的原像是所有满足 g(x)∈B 的点,因此
P(Y∈B)=P(X∈g−1(B))
这个等式比任何公式都更基础。单调变换、非单调变换、Jacobian、卷积、最大值和最小值,都可以看成它的不同展开。
本章的公式很多,但不要把它们背成互不相关的模板。遇到新变量,先问三个问题:新变量由哪些旧变量决定?给定新变量取某个值时,旧变量可能在哪里?这些旧位置的概率密度要怎样换算到新坐标上?
从分布函数法开始
分布函数法适合几乎所有一维变换。它不要求变换一开始就是单调的,也不要求你马上记住密度公式。设 Y=g(X),则
FY(y)=P(Y≤y)=P(g(X)≤y)
右边只含 X,可以用 X 的分布来算。若最后得到的 FY(y) 可导,再对 y 求导得到 f。
例子:平方会把负半轴折到正半轴
设 X∼Uniform(−1,1),令 Y=X2。因为平方后一定非负,且最大为 1,所以 Y 的支持是 。
当 0≤y≤1 时,
FY(y)=P(Y≤y)=P(X2≤
不等式 X2≤y 等价于 −y≤X,因此
FY(y)=22y
于是
fY(y)=FY′(y)=
完整写成分段形式是
FY(y)=⎩
这个例子提醒我们:平方不是一对一的。一个正的 y 同时来自 x=y 和 x=−。分布函数法自动把两侧都算进去了。
连续变换最容易漏掉支持。上面的密度 2y1 只在 上成立;如果忘记写支持,公式就像一个没有边界的函数,积分也不再等于 。
一维单调变换
如果 g 在 X 的支持上严格单调,并且反函数 h=g−1 可导,那么可以直接写密度变换公式。设 Y=g(X),,则
fY(y)=fX(h(y))∣h
也常写成
fY(y)=fX(x)
这里的 dydx 不是装饰项。它表示 轴上一小段长度对应到 轴上有多长。密度是“单位长度的概率”,长度变了,密度高度就必须反向调整,才能让小区间概率保持一致。
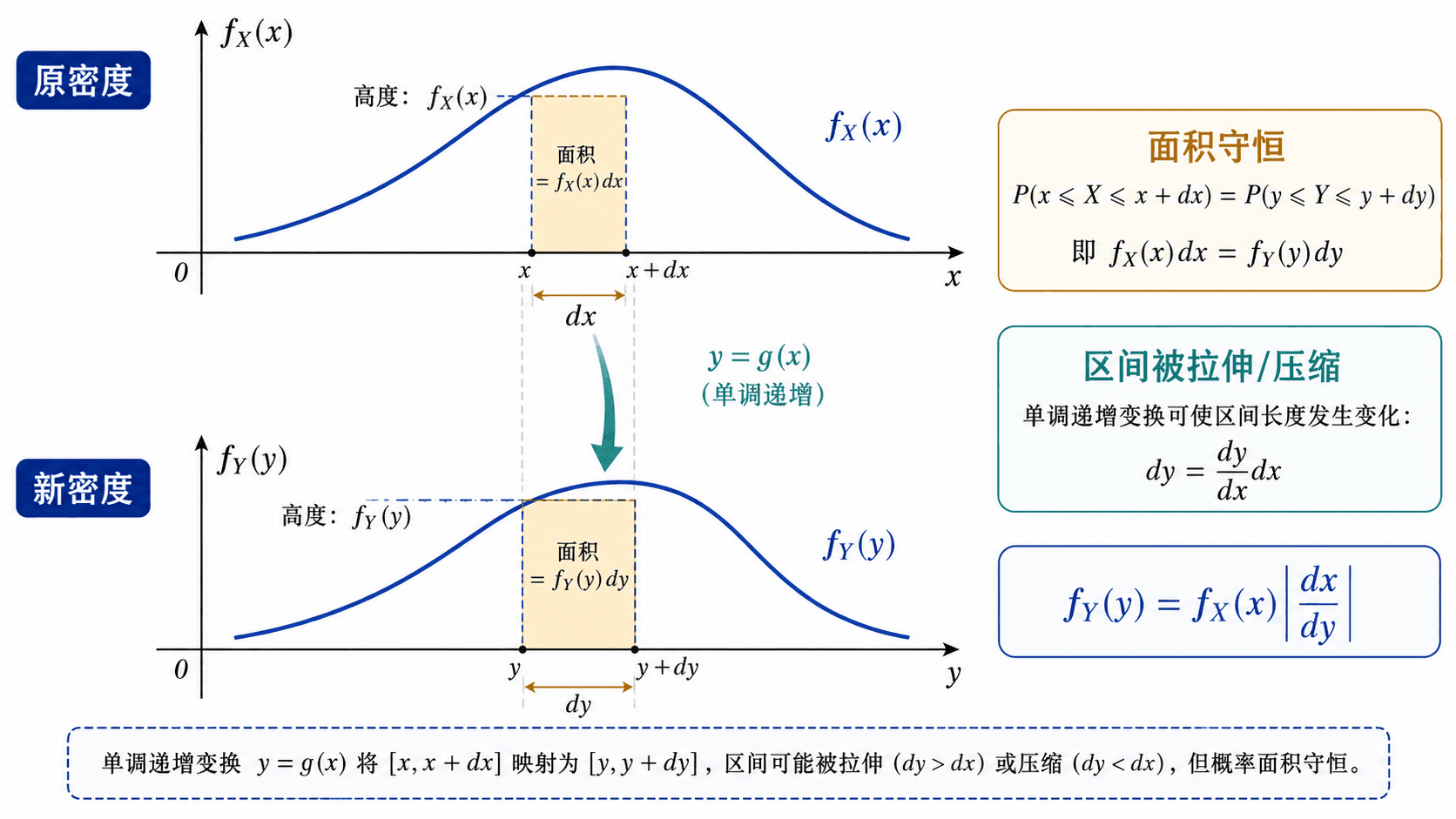 单调变换的核心是面积守恒:fX(x)dx 与 fY(y)dy 表示同一小段概率。
单调变换的核心是面积守恒:fX(x)dx 与 fY(y)dy 表示同一小段概率。
推导:从面积守恒看导数
在 x 附近取一个很短的区间 [x,x+dx],它被 y=g(x) 映到 y 附近的短区间,长度近似为
dy≈g′(x)dx
这两个小区间代表同一批随机结果,所以概率近似相等:
fX(x)dx≈fY(y)dy
代入 dy 与 dx 的关系,得到
fY(y)≈fX(x)
取极限后就是单调变换公式。
例子:指数随机变量的线性缩放
设 X∼Exp(λ),令 Y=aX,其中 a>0。反函数是 x=y,并且
dydx=a1
所以
fY(y)=λe−λy/aa1
这说明 aX 仍然是指数型形状,但速率从 λ 变成 λ/a。当 a 变大时,同样的概率被摊到更长的正半轴上,密度高度下降。
例子:对数变换把正数轴展开成全实轴
设 X∼Exp(λ),令 Y=logX。反函数是 x=ey,导数为 。因此
fY(y)=λe−λeye
注意支持已经从 x>0 变成全部实数。许多建模问题会先对正值变量取对数,再研究新的分布;变量变换公式告诉我们,不能只把 x 替换成 ey,还必须乘上导数因子。
非单调变换
如果 g 不是一对一的,一个 y 可能对应多个 x。这时不能只挑一个反函数分支。假设对给定的 y,方程 g(x)=y 有若干个根 ,并且在这些点附近 ,则
fY(y)=i=1∑kf
这就是“所有原像贡献相加”。单调变换只是 k=1 的特例。
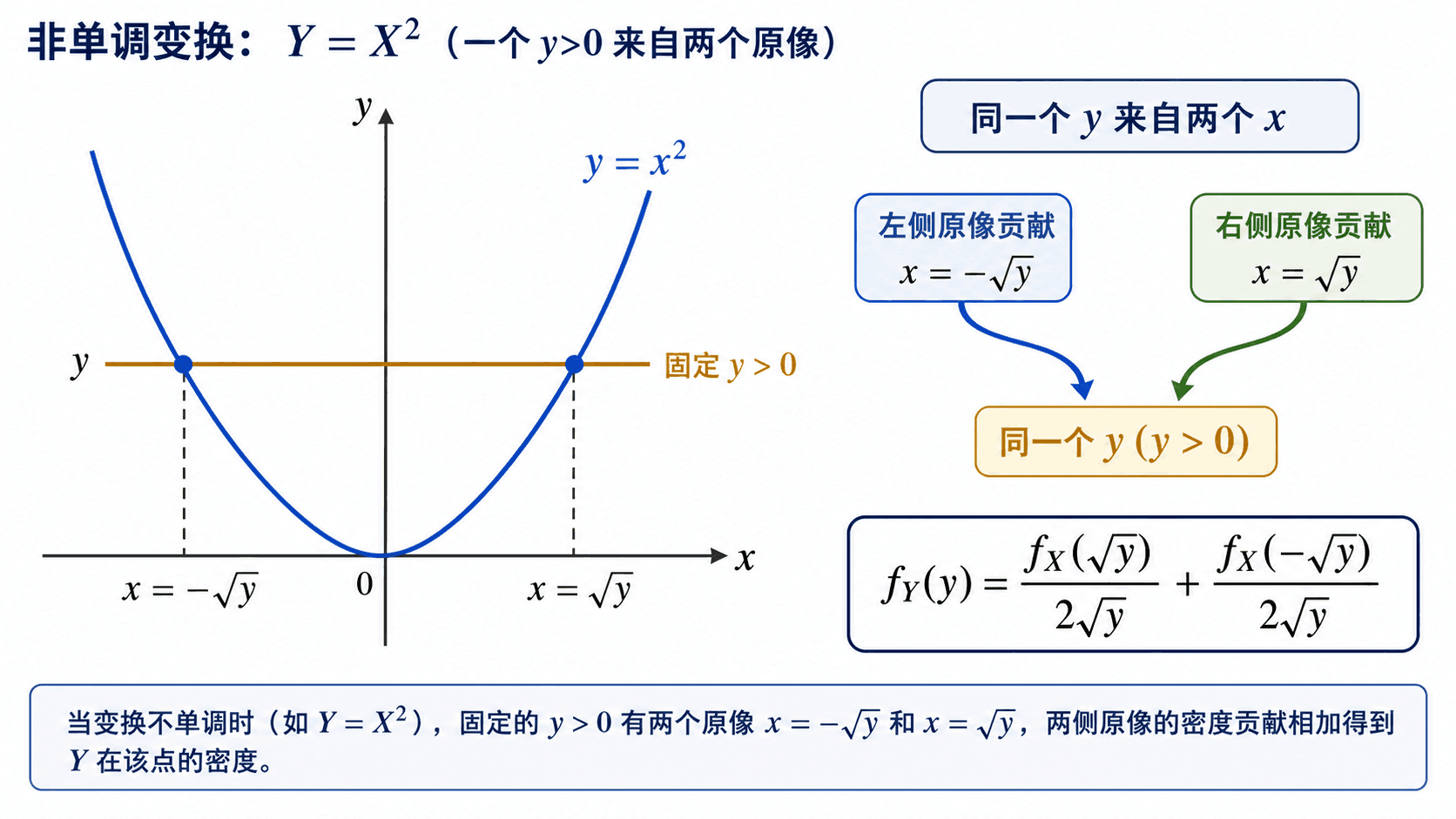 非单调变换要把所有原像的贡献加起来。对 Y=X2,正的 y 通常来自左右两个 x。
非单调变换要把所有原像的贡献加起来。对 Y=X2,正的 y 通常来自左右两个 x。
例子:标准正态的平方
设 X∼N(0,1),令 Y=X2。当 y>0 时,两个原像是 与 。因为 ,
fY(y)=fX(y
标准正态密度关于 0 对称,所以
fY(y)=2πy
这就是自由度为 1 的卡方分布密度。这里最值得看的不是结果名称,而是两个分支如何合并:左侧和右侧的概率都被平方函数折到正半轴。
先确定支持。平方后 Y 不可能小于 0,所以密度只需要在 y>0 上计算。
离散随机变量函数
离散情形没有导数因子。原因是概率集中在一个个点上,函数只是在把这些点重新归类。设 X 的可能取值为 x1,x2,…,定义 Y=g(X。对任意 ,
P(Y=y)=x:g(x)=y∑P(X=x)
例子:掷骰子的平方
设 X 是一次公平骰子的点数,令 Y=(X−3)2。列出对应关系:
x(x−3)
所以
P(Y=0)=61,P(Y=
这里 Y=1 有两个原像 2 和 4,Y=4 有两个原像 1 和 5。这和连续非单调变换的“分支相加”是同一个思想,只是离散点不需要长度换算。
二维变换与 Jacobian
一维变换中的导数因子是长度换算率。二维变换中的 Jacobian 是面积换算率。
设 (X,Y) 有联合密度 fX,Y(x,y)。定义
U=g1(X,Y),V=g2(X,Y
如果变换在关心的区域内一对一,并且可以反解为
x=x(u,v),y=y(u,v)
则
fU,V
这个行列式的绝对值记为 ∂(u,v)∂(x,y)。它告诉我们 平面上一小块面积,对应到 平面上大约有多大。
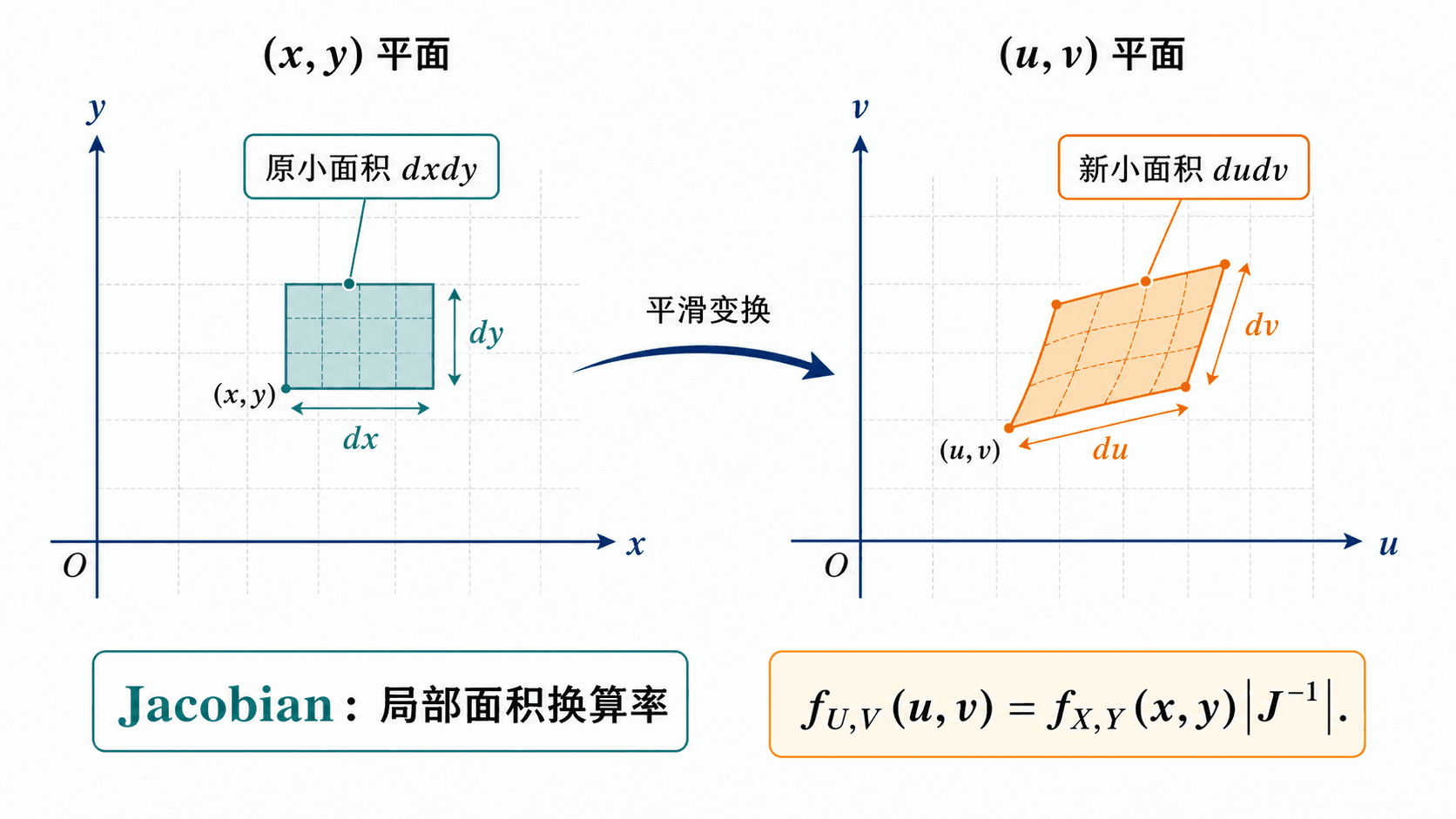 Jacobian 是局部面积换算率。它不是概率本身,而是把密度从一个坐标系换到另一个坐标系时必须乘上的面积因子。
Jacobian 是局部面积换算率。它不是概率本身,而是把密度从一个坐标系换到另一个坐标系时必须乘上的面积因子。
例子:和与比例
设 X 和 Y 独立同分布于 Exp(λ)。令
U=X+Y,V=X+YX
其中 U 表示总量,V 表示 X 在总量中的比例。反解为
X=UV,Y=U(1−V)
支持条件是
u>0,0<v<1
Jacobian 为
det(
因此绝对值是 u。原联合密度为
fX,Y(x,y)=λ2e
代入 x=uv、y=u(1−v) 后,
fU,V(u,v)=λ2e−λ
这个联合密度可以分解为
fU,V(u,v)=(λ2ue−
所以 U 与 V 独立,U∼Gamma(2,λ),V∼Uniform(0,1)。这个结果有清楚的直观含义:两个同速率指数等待时间的总等待时间和比例可以分开描述。
二维变换常见错误是把 Jacobian 写反。若公式使用反函数 x=x(u,v),y=y(u,v),就乘 ;如果你算的是正向变换 ,需要取倒数。
卷积:随机变量和的分布
现在考虑两个随机变量的和:
Z=X+Y
如果 X 和 Y 独立,连续情形下 Z 的密度是
fZ(z)=∫−∞∞f
这个公式叫卷积。它来自同一个原像思想:若 X+Y=z,那么给定 X=x 时,Y 必须等于 z−x。把所有可能的 贡献积分起来,就得到 附近的密度。
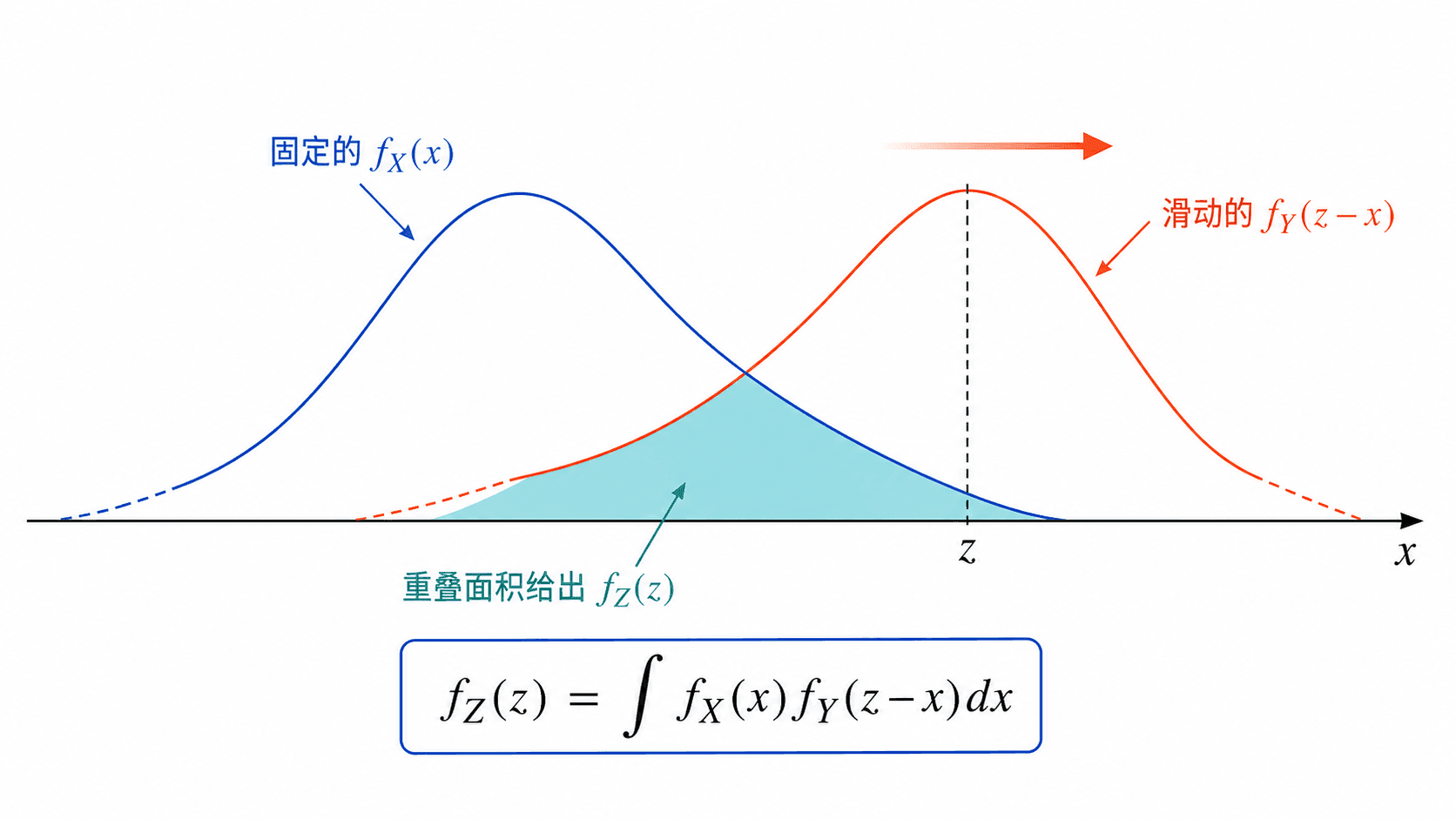 卷积可以看成“滑动相乘再积分”:固定 z,让 fY(z−x) 滑过 fX,重叠越大, 越高。
卷积可以看成“滑动相乘再积分”:固定 z,让 fY(z−x) 滑过 fX,重叠越大, 越高。
离散情形下,积分换成求和:
P(Z=z)=x∑P(X=x)P(Y=z
这里的独立性非常关键。如果 X 和 Y 不独立,不能把联合概率或联合密度拆成两个边缘分布的乘积。
例子:两个均匀分布相加
设 X,Y 独立且都服从 Uniform(0,1),令 Z=X+Y。则
fZ(z)=∫−∞∞1
积分值等于满足
0<x<1,0<z−x<1
的 x 区间长度。第二个不等式等价于 z−1<x<z,所以 x 必须落在
(0,1)∩(z−1,z)
这个交集的长度随 z 改变。于是
fZ(z)=⎩
三角形密度不是凭空出现的。它就是两个长度为 1 的区间滑动重叠时,重叠长度先增加后减少。
用二维变换推导卷积
卷积也可以从二维变量变换得到。令
Z=X+Y,W=X
反解为
X=W,Y=Z−W
Jacobian 为
det
所以
fZ,W(z,w)=fX,Y(w,z
再对 w 积分得到边缘密度:
fZ(z)=∫−∞∞f
若 X,Y 独立,就得到卷积公式。
卷积的积分上下限常写成 −∞ 到 ∞,但真正起作用的是支持的交集。解题时不要机械照抄无穷上下限,可以先找出哪些 x 同时让 fX(x) 和 非零。
最大值、最小值与顺序统计量入口
函数不一定是加法,也可以是最大值和最小值。设 X1,…,Xn 独立同分布,公共分布函数为 F。记
Mn=max(X1,…,X
最大值的分布函数很自然:
P(Mn≤t)=P(X1≤t,…
由独立性,
FMn(t)=F(t)n
如果 F 有密度 f,则
fMn(t)=nF(t)n−1f(t
最小值可以从尾事件看:
P(mn>t)=P(X1>
所以
Fmn(t)=1−(1−F(t))
若可导,
fmn(t)=n(1−F(t))
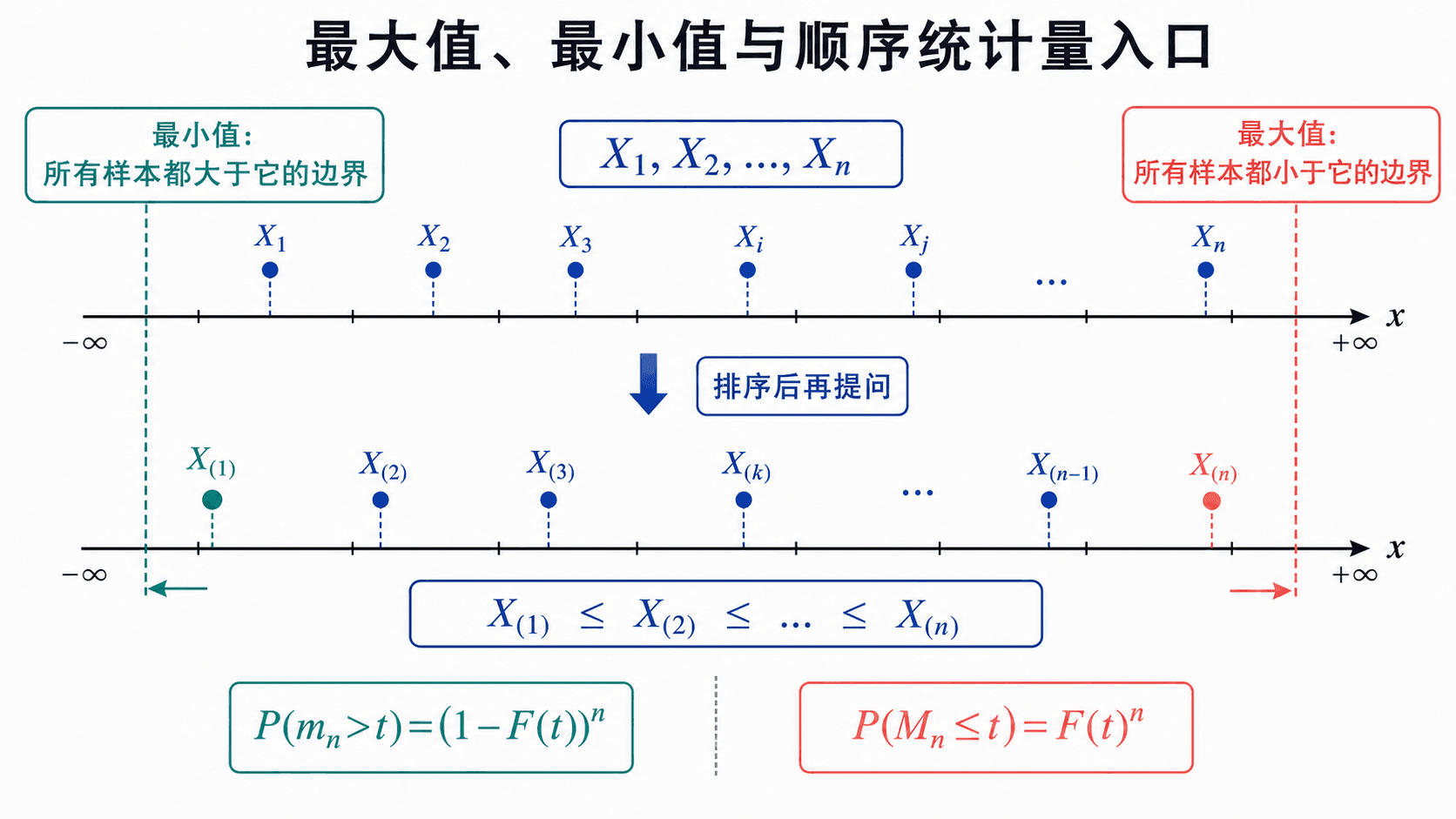 顺序统计量先把样本点从小到大排列,再研究第几个点。最大值和最小值是两端的特殊情形。
顺序统计量先把样本点从小到大排列,再研究第几个点。最大值和最小值是两端的特殊情形。
顺序统计量的一般密度
把样本从小到大排成
X(1)≤X(2)≤⋯≤X
其中 X(k) 是第 k 小的观测。直观上,X(k) 落在 附近,意味着大约有 个样本小于 ,有 个样本大于 ,还有一个样本落在 附近。连续情形下,它的密度是
fX(k)(t)=
当 k=n 时就是最大值密度;当 k=1 时就是最小值密度。
常见误区
把 dy/dx 和 dx/dy 用反
若你从 y=g(x) 出发,直觉上很容易写出 g′(x)。但密度公式需要的是旧坐标长度相对于新坐标长度的换算:
fY(y)=fX(x)
如果只记“乘导数”,就容易乘错方向。可以用一个简单检查:若 Y=2X,区间长度被拉成两倍,密度高度应减半,因此应乘 1/2,不是 2。
漏掉非单调变换的分支
对 Y=X2,正的 y 有两个原像。若只取 x=y,密度积分通常会少掉一部分概率。每次遇到绝对值、平方、三角函数、取整、最大最小值,都应先检查原像是否唯一。
忘记支持随变换改变
如果 X>0,Y=logX 的支持是整个实数轴;如果 X∈(0,1),Y 的支持是 。支持不是公式旁边的附属说明,它决定密度在哪些地方为零。
在不独立时直接卷积
卷积公式
fX+Y(z)=∫fX(x)f
需要 X 与 Y 独立。一般情形应写成
fX+Y(z)=∫fX,Y(x,z
如果题目给的是联合密度、条件分布或相关结构,先判断是否能拆成边缘密度乘积。
只会套公式,不会看事件
最大值和最小值最好从事件理解。Mn≤t 表示所有样本都不超过 t;mn>t 表示所有样本都大于 。先写事件,再用独立性拆开,公式就不会混。
练习
练习一
设 X 的密度为
fX(x)=2x,0<x<1
令 Y=X2。求 Y 的密度。
因为 Y=X2 在 0<x<1 上严格单调,反函数为 x=y,支持为 。由变量变换公式,
练习二
设 X 与 Y 独立,且都服从参数为 λ 的指数分布。用卷积求 Z=X+Y 的密度。
当 z>0 时,只有 0<x<z 有贡献:
f练习三
设 X1,…,Xn 独立同分布于 Uniform(0,1)。求最大值 和最小值 的密度。
对 0<t<1,
FMn(t)=
小结
随机变量函数的分布问题,本质上是在新旧变量之间搬运概率。离散情形把同一新取值的原像概率相加;连续一维变换要用分布函数或导数因子处理长度变化;非单调变换要把所有原像分支加起来;二维变换用 Jacobian 处理面积变化。
卷积是变量变换的一种重要应用。它研究独立随机变量和的分布,也可以从二维变换和边缘化推导出来。最大值、最小值和顺序统计量则提醒我们,函数可以是加法以外的结构;只要先把事件写清楚,再用独立性和分布函数推进,公式会自然出现。