表格的样式与编辑
数据录入完成只是第一步,一份没有经过样式处理和编辑优化的表格,和一份经过精细打磨的表格,在实际使用中的效率差距是巨大的。工资表里哪些人的绩效低于达标线、销售数据中哪些月份的业绩突然下滑、几千行记录里要找到某一条特定信息——这些需求靠肉眼逐行扫描根本不现实。条件格式能让异常数据自动“亮起来”,排序与筛选能让杂乱无章的数据瞬间变得有序可查,查找替换与定位则是精准锁定目标的利器。这三项能力是从“能用”到“好用”之间的关键跨越。
条件格式的用法
条件格式的核心逻辑是:给单元格设定一个规则,凡是符合规则的单元格,Excel 自动改变其外观(底色、字体颜色、图标等)。数据本身不会被修改,变的只是视觉呈现。当数据更新后,条件格式会自动重新判断,不需要手动刷新。
突出显示单元格规则
这是条件格式中最常用的功能,能够对满足特定条件的单元格自动标色。
一份 200 行的“员工月度考勤表”,D 列是“迟到次数”,要求迟到 3 次及以上的单元格标红底色,方便人事部门一眼识别需要约谈的员工。
选中 D2:D201 整个迟到次数数据区域。
点击“开始”选项卡→“样式”命令组→“条件格式”→“突出显示单元格规则”→“大于”。
在弹出的对话框中,左侧输入框填入“2”(表示大于 2,即 3 次及以上),右侧下拉框选择“浅红填充色深红色文本”,点击“确定”。
设置完成后,D 列中所有数值大于 2 的单元格立刻变成红底红字。如果后续有员工的迟到次数从 2 改为 4,该单元格会自动变红,无需重复操作。
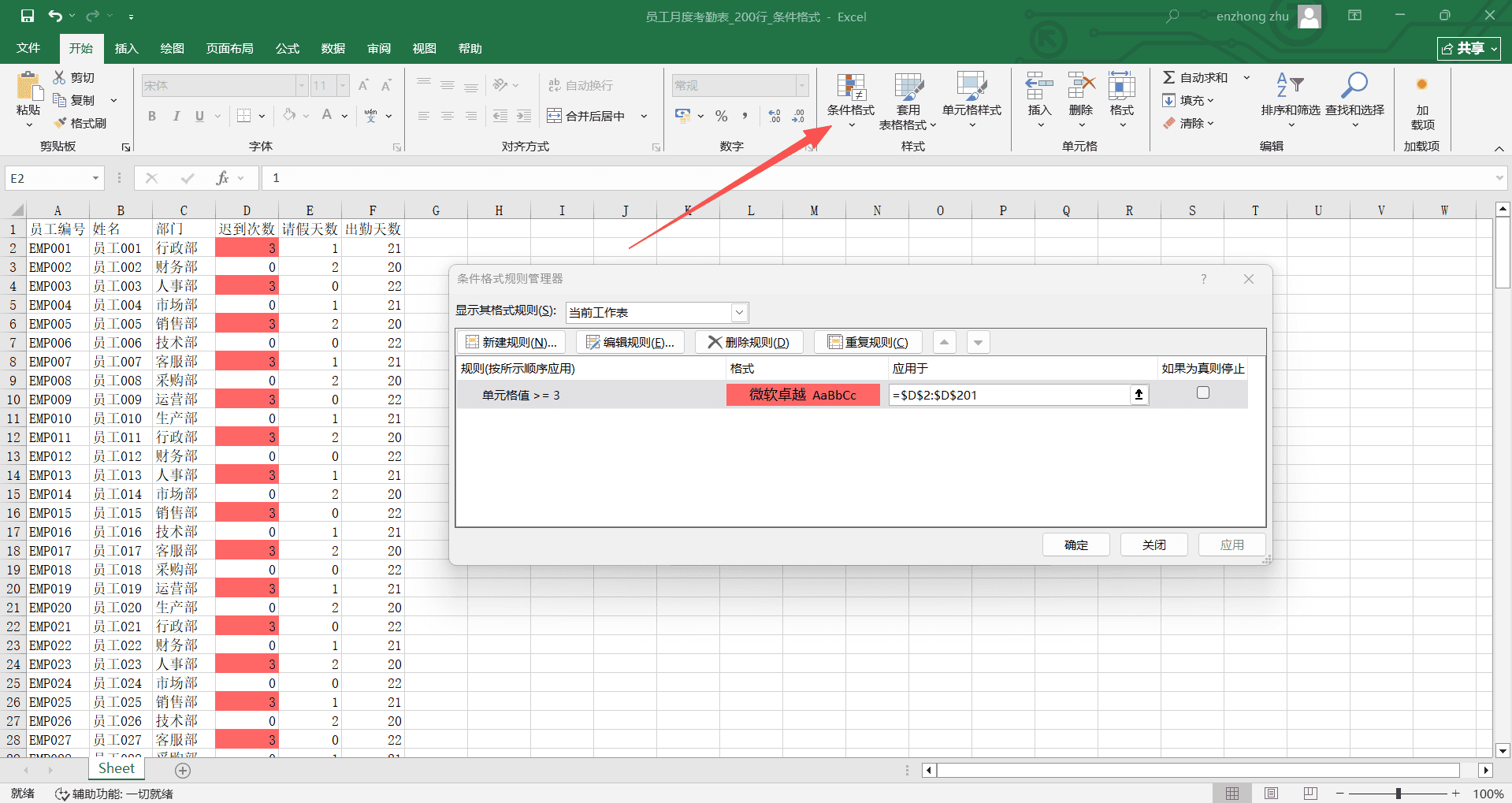
“突出显示单元格规则”提供了多种预设条件,覆盖了日常高频使用场景:
用条件格式查找重复值
人事部门整理一份 500 人的员工花名册,C 列是身份证号码。身份证号不可能重复,但手动录入时难免出现复制粘贴导致的重复。用肉眼在 500 个 18 位数字中找重复,几乎不可能完成。
选中 C2:C501 身份证号列的所有数据。
点击“条件格式”→“突出显示单元格规则”→“重复值”。
在弹出的对话框中,左侧保持默认的“重复”不变,右侧选择一种醒目的格式(如“浅红填充色深红色文本”),点击“确定”。
如果 C 列中有两个或以上完全相同的身份证号,这些单元格会同时标红。直接就能看到哪些号码重复了,省去了逐行核对的时间。
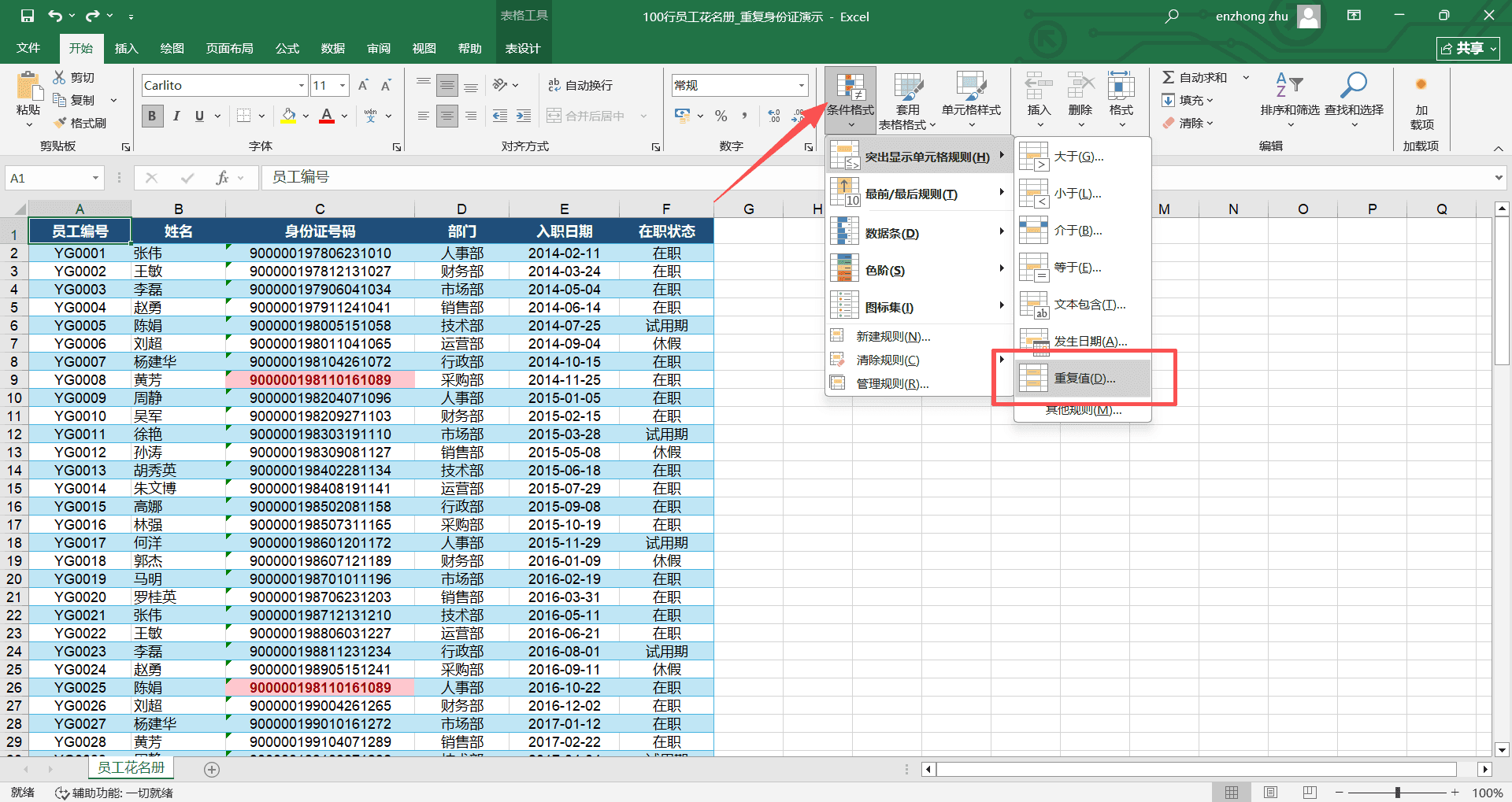
“重复值”功能判断的是完全一致的内容。如果身份证号末尾多了一个空格(比如 320106199503121234 和 320106199503121234+空格),条件格式会认为它们不同,不会标红。数据清洗时要注意先去除多余空格。
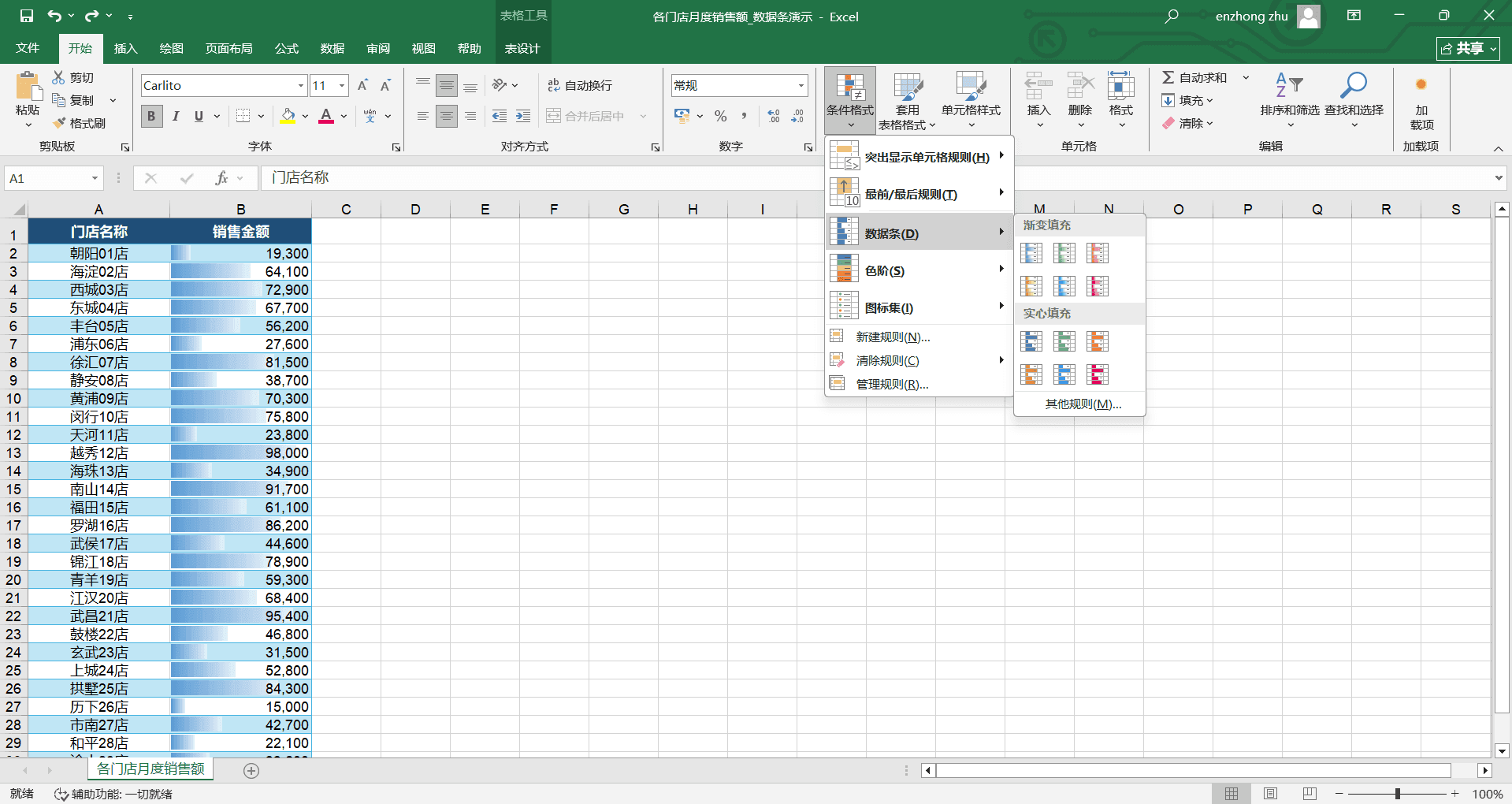
数据条
数据条会在单元格内部绘制一个横向的色条,色条的长度与数值大小成正比——数值越大,色条越长。不需要逐个看数字,扫一眼色条长短就能感知数据的大小分布。
一份“各门店月度销售额”表,B 列是销售金额,数据从 15000 到 98000 不等。选中 B2:B30 后,点击“条件格式”→“数据条”→选择一种渐变填充样式(蓝色渐变比较常用),每个单元格中会出现一个蓝色横条,98000 那个格子的色条几乎占满整个单元格宽度,15000 那个格子只有一小截。哪个门店卖得好、哪个门店业绩差,一目了然。
色阶
色阶用渐变色来反映数值从低到高的变化趋势。和数据条不同的是,色阶改变的是整个单元格的背景色,而不是画一个横条。
一份“学生成绩表”,F 列是总分,需要直观看出成绩的整体分布。选中 F2:F60 后,点击“条件格式”→“色阶”→选择“绿-黄-红色阶”。分数最高的单元格变成深绿色,中等分数的变成黄色,最低分的变成红色。整列数据从上到下看过去,颜色的深浅变化直接反映了成绩的高低分布,不需要排序就能看出哪些学生处于顶端、哪些在底部。
色阶和数据条的区别在于视觉侧重点:数据条适合比较单个数值的绝对大小(看条的长短),色阶适合观察一组数据的整体分布趋势(看颜色的渐变过渡)。两者可以同时作用在不同列上,互不冲突。
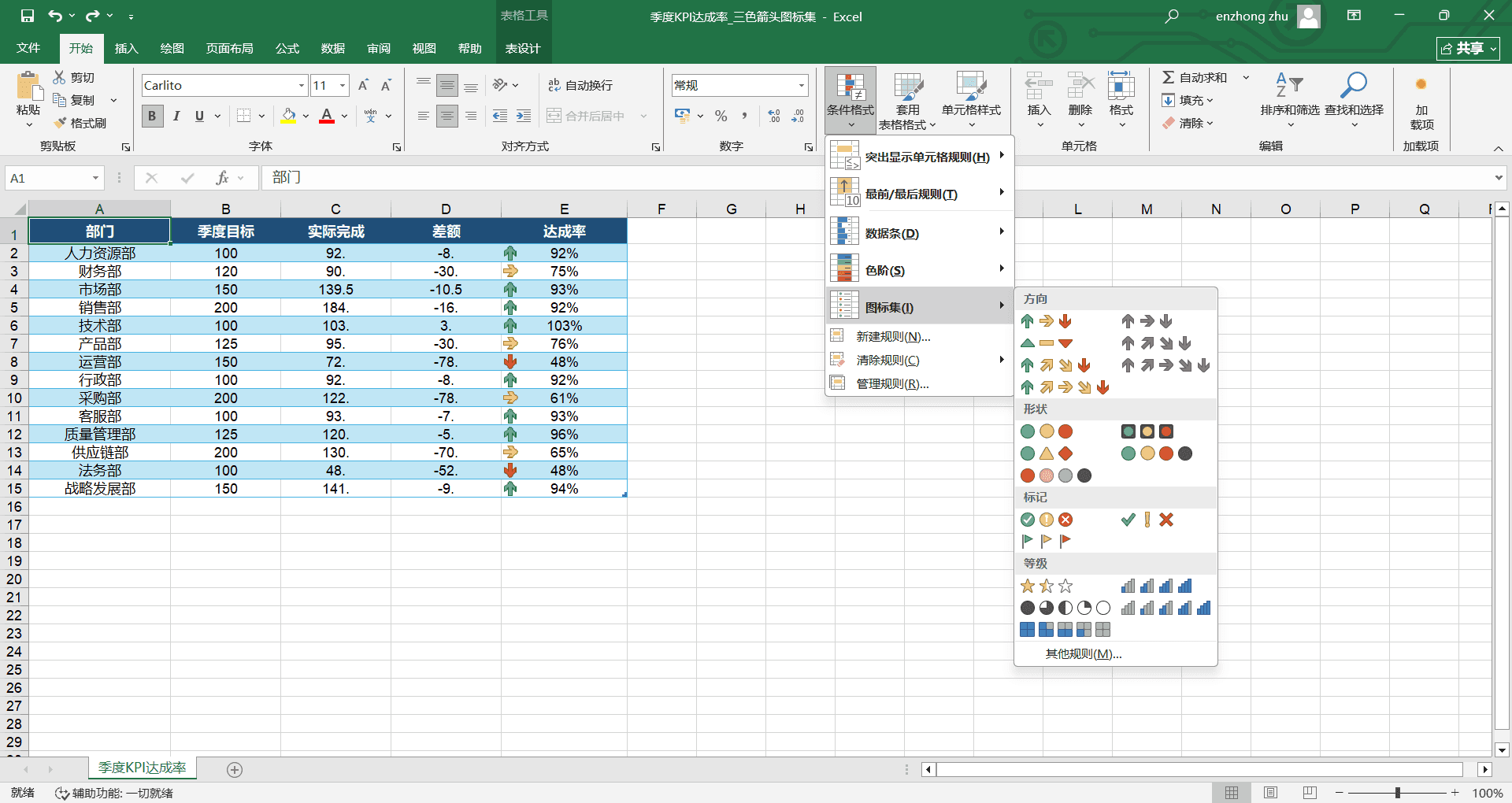
图标集
图标集在单元格内添加一个小图标(箭头、旗帜、红绿灯等),用图标类型来表示数值所在的等级区间。
一份“季度 KPI 达成率”表,E 列是各部门的达成百分比。希望达成率 90% 以上显示绿色上箭头,60% 到 90% 之间显示黄色横箭头,60% 以下显示红色下箭头。
选中 E2:E15 达成率数据区域。
点击“条件格式”→“图标集”→选择“三个箭头(彩色)”。
默认情况下,Excel 会自动将数据等分为三段。如果需要自定义分界点(60% 和 90%),点击“条件格式”→“管理规则”,在弹出的对话框中找到刚设置的图标集规则,点击“编辑规则”。
将绿色上箭头的条件改为“值 >= 90”,类型选“百分比”改为“数字”(因为达成率本身就是百分比);黄色横箭头的条件改为“值 >= 60”。点击“确定”保存。
设置完成后,达成率 92% 的部门旁边出现绿色上箭头,达成率 75% 的旁边是黄色横箭头,达成率 48% 的旁边是红色下箭头。汇报时领导不用看具体数字,扫一眼图标颜色就能判断各部门的完成情况。
清除条件格式
条件格式设置得太多或者需要推倒重来时,需要清除已有的条件格式规则。
点击“条件格式”→“清除规则”,可以选择“清除所选单元格的规则”(只清除当前选中区域的条件格式)或“清除整个工作表的规则”(把整张表的条件格式全部去掉)。
条件格式叠加过多会拖慢 Excel 的运行速度。一张工作表如果设置了十几条甚至几十条条件格式规则,每次编辑数据后 Excel 都要重新计算所有规则,文件打开和操作都会变得迟缓。定期通过“管理规则”检查是否有冗余或过时的规则,及时删除不再需要的条件格式。
条件格式的实战对比
同一份“产品库存表”,不做条件格式处理和做了条件格式处理后的阅读体验差距非常大:
处理前: G 列“当前库存”全是纯数字——120、45、8、230、3、67、15、190……要找出库存低于 10 的产品,需要从头到尾逐行扫描,一旦数据超过 100 行,几乎必然会漏看。
处理后: 对 G 列设置“小于 10”标红底色、“介于 10 到 30”标黄底色,两步操作完成后,滚动表格时红色和黄色的单元格自动跳入视线,3 秒内就能锁定所有需要紧急补货的产品。
排序与筛选
数据录入完成后,原始的排列顺序通常是按录入时间先后排列的,和实际的分析需求完全不匹配。排序可以让数据按照指定的规则重新排列(从大到小、按拼音顺序等),筛选则可以在不删除数据的前提下,只显示符合条件的那部分记录。
单列排序
一份 300 行的“销售订单表”,D 列是“订单金额”,需要找出金额最高的前 20 笔订单。如果数据没有排序,这 20 笔订单分散在 300 行的各个位置,逐行比较非常低效。
点击 D 列中任意一个有数据的单元格(不需要选中整列)。
点击“数据”选项卡→“排序和筛选”命令组→“降序”按钮(Z→A 图标,或数字从大到小图标)。
Excel 自动识别整个数据区域,以 D 列的数值为基准,将所有行按金额从大到小重新排列。排在最前面的就是金额最高的订单。
排序后,前 20 行就是金额最高的 20 笔订单,直接查看即可,不需要任何额外操作。
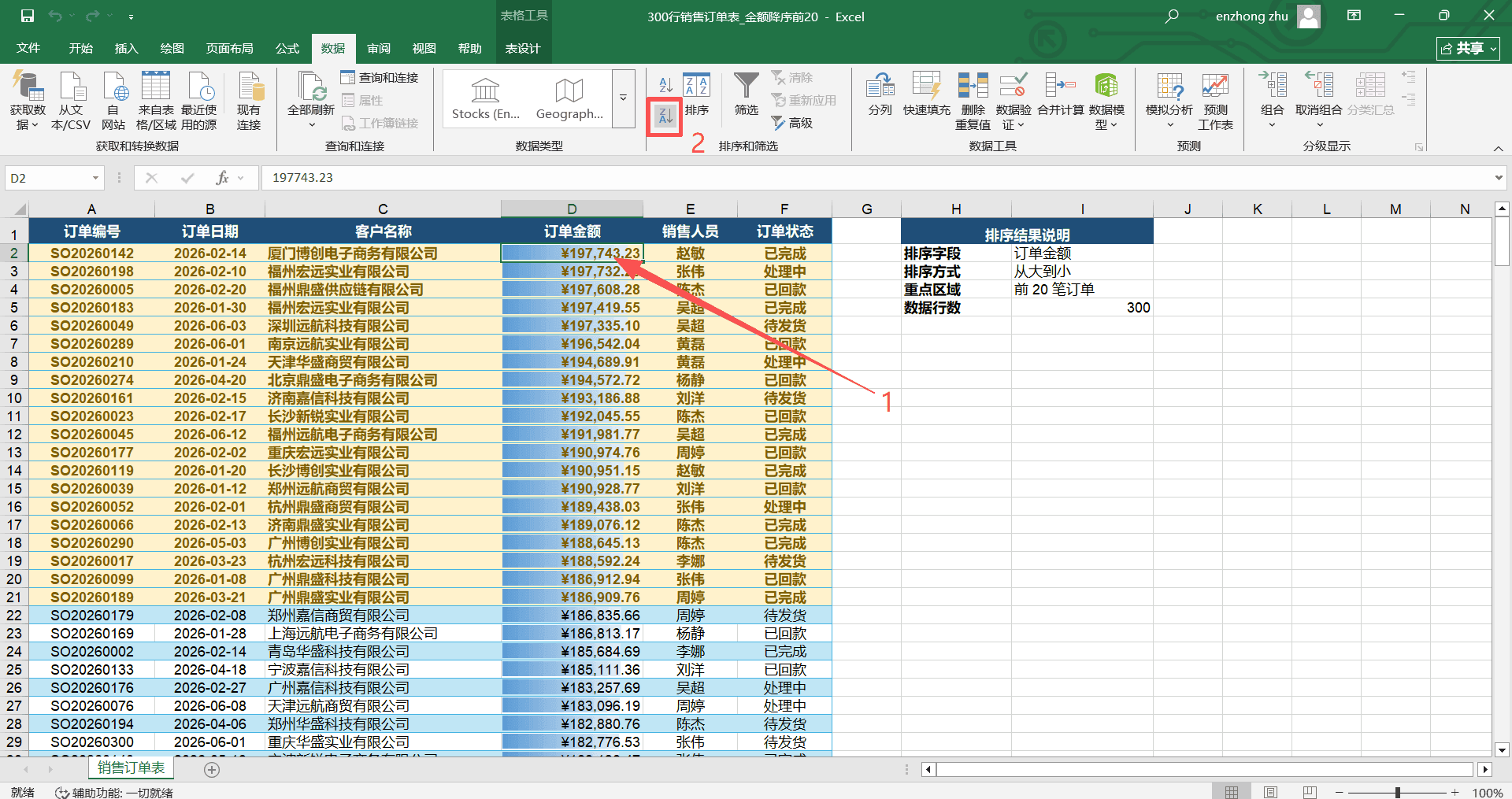
排序操作会改变数据的物理位置,也就是说行的上下顺序会真正发生变化。如果需要保留原始的录入顺序以备后用,建议在排序前先增加一列“序号”(用 1、2、3……填充),排序后想恢复原始顺序时,再按“序号”列升序排列即可。
多条件排序
单列排序只能按一个维度排列,但实际工作中经常需要多级排序。
一份“员工花名册”,需要先按“部门”分组排列(同一个部门的人排在一起),同一部门内再按“入职日期”从早到晚排列。
点击数据区域中的任意单元格。
点击“数据”选项卡→“排序”按钮(不是直接点升序或降序,而是点击完整的排序对话框按钮)。
在弹出的“排序”对话框中,“主要关键字”选择“部门”,排序依据选“单元格值”,次序选“升序”。
点击“添加条件”,“次要关键字”选择“入职日期”,排序依据选“单元格值”,次序选“升序(最旧到最新)”。
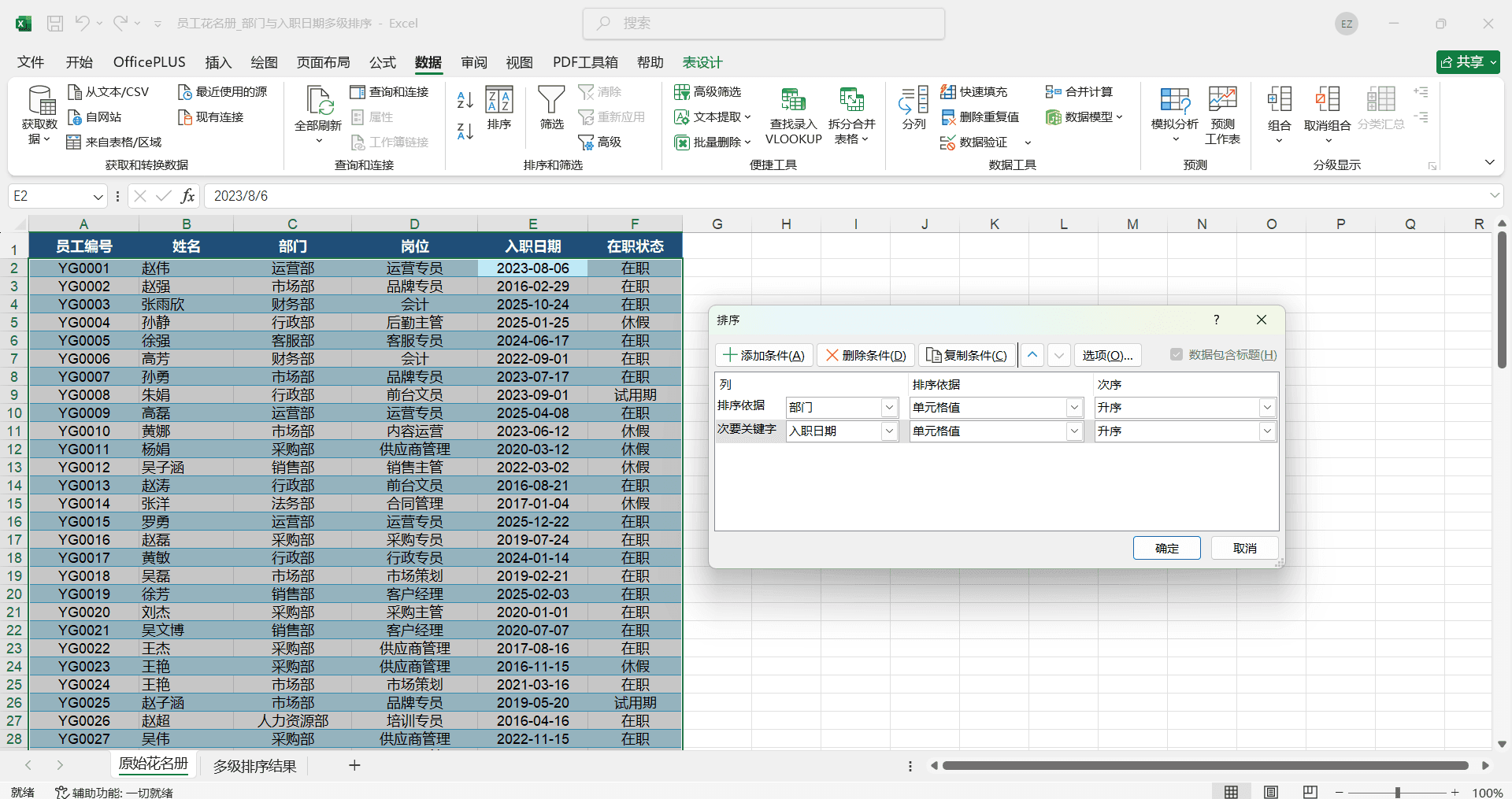
排序后的效果是:财务部的所有员工排在一起,按入职先后从上到下排列;接下来是技术部的员工,同样按入职先后排列;再往下是人事部、市场部……整份花名册既有组织架构的分组感,又有时间维度的先后顺序。
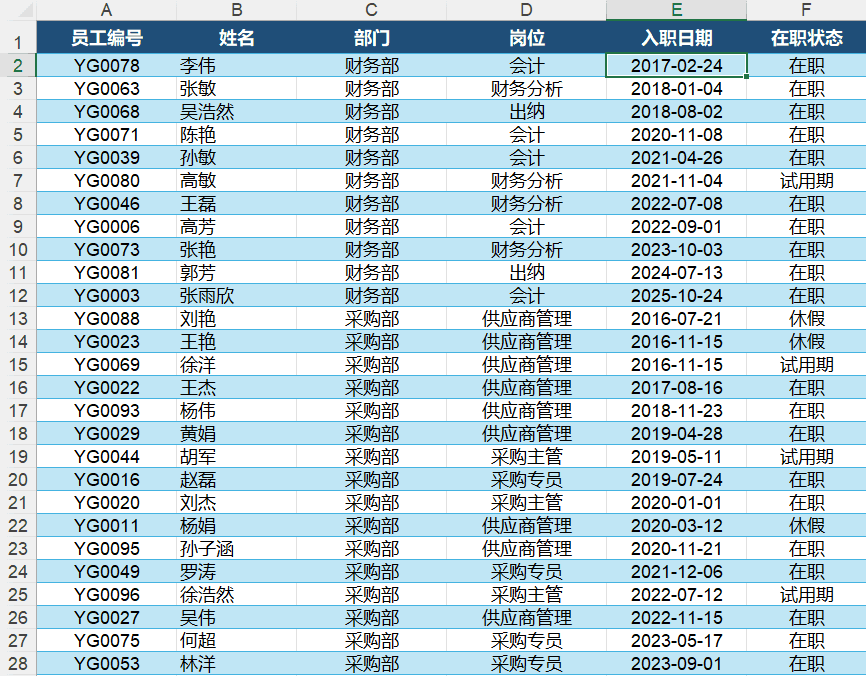
按颜色排序
如果前面已经用条件格式给某些单元格标了底色(红色标注异常、黄色标注待确认),可以直接按颜色排序,把同颜色的行集中排列在一起。
操作方式:右键点击带颜色的单元格,选择“排序”→“将所选单元格颜色放在最前面”。Excel 会把所有带该底色的行排到表格最顶部,其余行排在下方。
这在审核数据时特别有用——先用条件格式标出异常数据,再按颜色排序把异常行集中到一起,逐行处理完毕后再恢复原始排序。
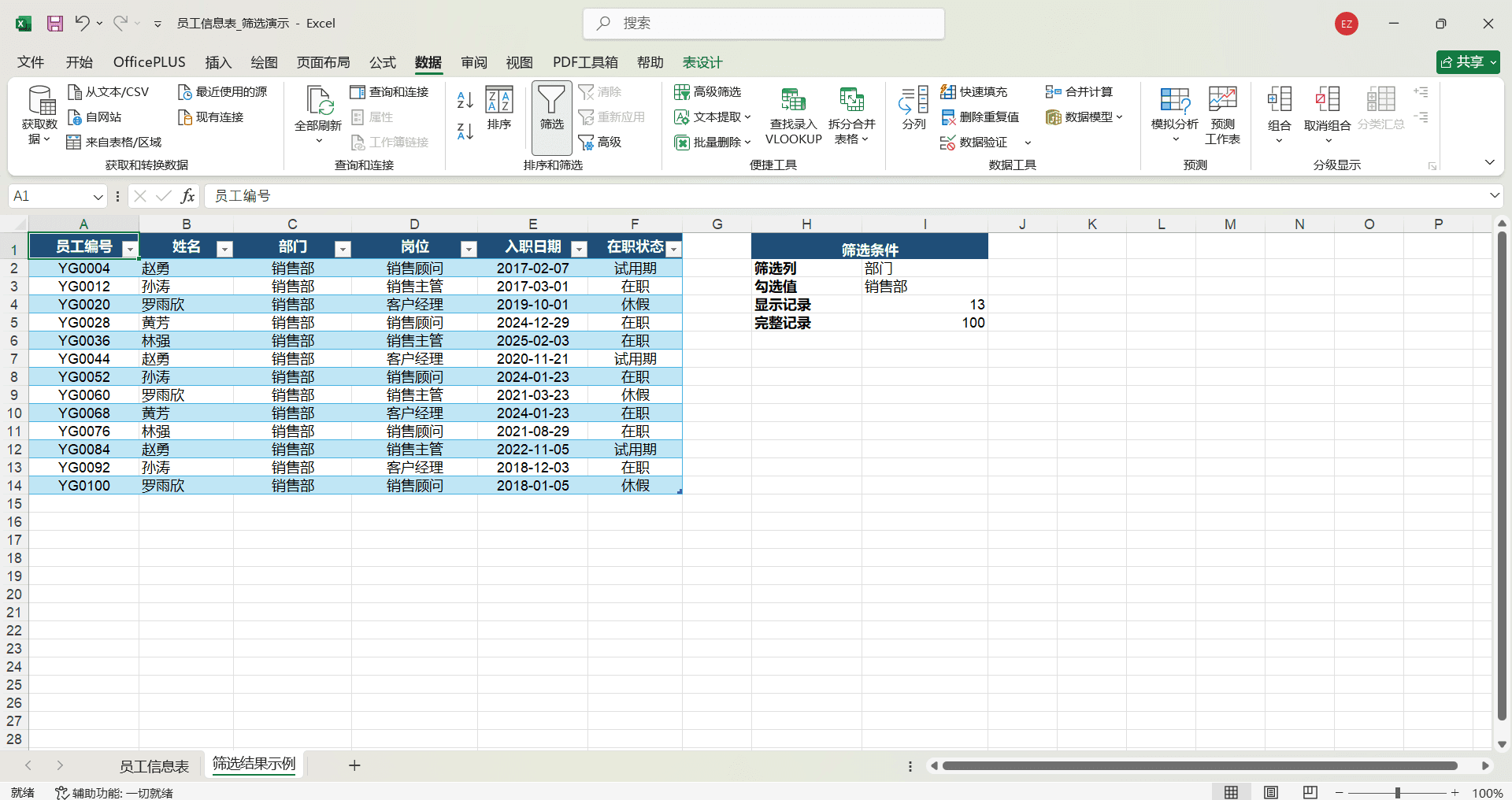
自动筛选
筛选和排序不同,排序是改变数据的排列顺序,筛选是把不符合条件的行暂时隐藏,只显示符合条件的数据。被隐藏的数据并没有被删除,取消筛选后会全部恢复。
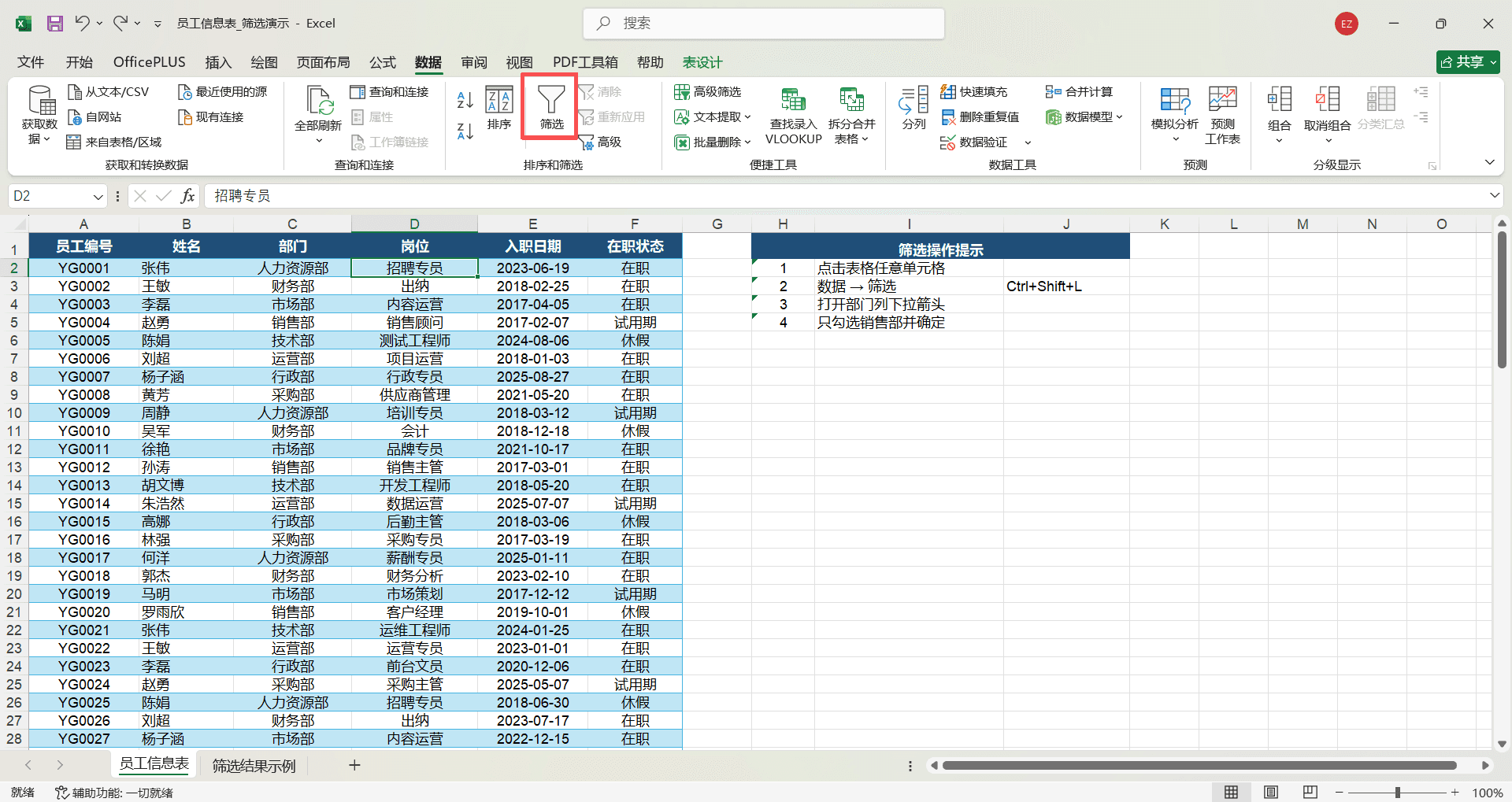
点击数据区域中的任意单元格。
点击“数据”选项卡→“筛选”按钮(或使用快捷键 Ctrl+Shift+L),表头行的每个单元格右下角出现一个下拉箭头。
点击需要筛选的列的下拉箭头,弹出筛选面板。
筛选面板中列出了该列所有不重复的值,每个值前面都有一个复选框。取消勾选“全选”后,只勾选需要显示的值,点击“确定”,表格中只显示该列值等于勾选项的行,其余行全部隐藏。
数值筛选与文本筛选
自动筛选面板底部还有“数字筛选”或“文本筛选”选项(根据列中数据类型自动显示对应选项),提供了更精细的筛选条件。
数值筛选的常用条件:
文本筛选的常用条件:
实际操作:一份 800 行的“客户信息表”,E 列是“联系地址”,需要筛选出所有广州市天河区的客户。点击 E 列筛选下拉箭头→“文本筛选”→“包含”,输入“天河区”后确定,表格中只剩下地址包含“天河区”字样的客户记录。
按日期筛选
当列中的数据是日期格式时,筛选面板会自动按照“年-月-日”的层级结构展示。
一份“合同台账”,A 列是“签约日期”,数据从 2023 年 1 月到 2025 年 6 月。点击 A 列的筛选下拉箭头,面板中自动按年份折叠显示:2023、2024、2025 三个节点。展开“2024”节点,下面列出 1 月到 12 月,再展开某个月,列出该月每一天的日期。
如果只需要查看 2024 年第四季度的合同,把“2023”“2025”取消勾选,展开“2024”后只勾选 10 月、11 月、12 月,点击确定,表格中就只显示这个时间段内的合同。
按日期筛选的前提是日期列的数据必须是真正的日期格式,而不是文本。可以在编辑栏中点击某个日期单元格查看:如果显示的是“2024/10/15”并且编辑栏中也是日期序列号,就是日期格式;如果编辑栏显示的就是一段文字“2024年10月15日”,那它实际上是文本格式,筛选面板不会按年月层级展示,只能用文本筛选的方式处理。
取消筛选与恢复全部数据
筛选状态下,行号会变成蓝色,表示当前有行被隐藏。要恢复全部数据有两种方式:
-
点击已筛选列的下拉箭头,选择“从……中清除筛选”,只清除该列的筛选条件,其他列的筛选保持不变。
-
点击“数据”选项卡→“清除”按钮(漏斗图标旁边的橡皮擦),一次性清除所有列的筛选条件。
-
再次点击“筛选”按钮(或 Ctrl+Shift+L),直接关闭筛选功能,表头的下拉箭头消失,所有数据恢复显示。
筛选隐藏的行在复制粘贴时需要注意:如果直接 Ctrl+C 复制筛选后的可见行,粘贴到其他位置后只会粘贴可见的行——隐藏行不会被复制。这个特性在需要“只导出筛选结果”时非常方便,但在不知情的情况下容易造成数据遗漏。
查找替换与定位
排序和筛选是对整列数据做批量处理,查找替换与定位则是针对具体内容的精准操作。在几千行的数据中找到某个特定的值、把所有出现的旧名称统一替换为新名称、一次性选中所有空白单元格——这些操作靠肉眼和手动逐格处理根本不现实,但用对工具后几秒钟就能完成。
查找功能
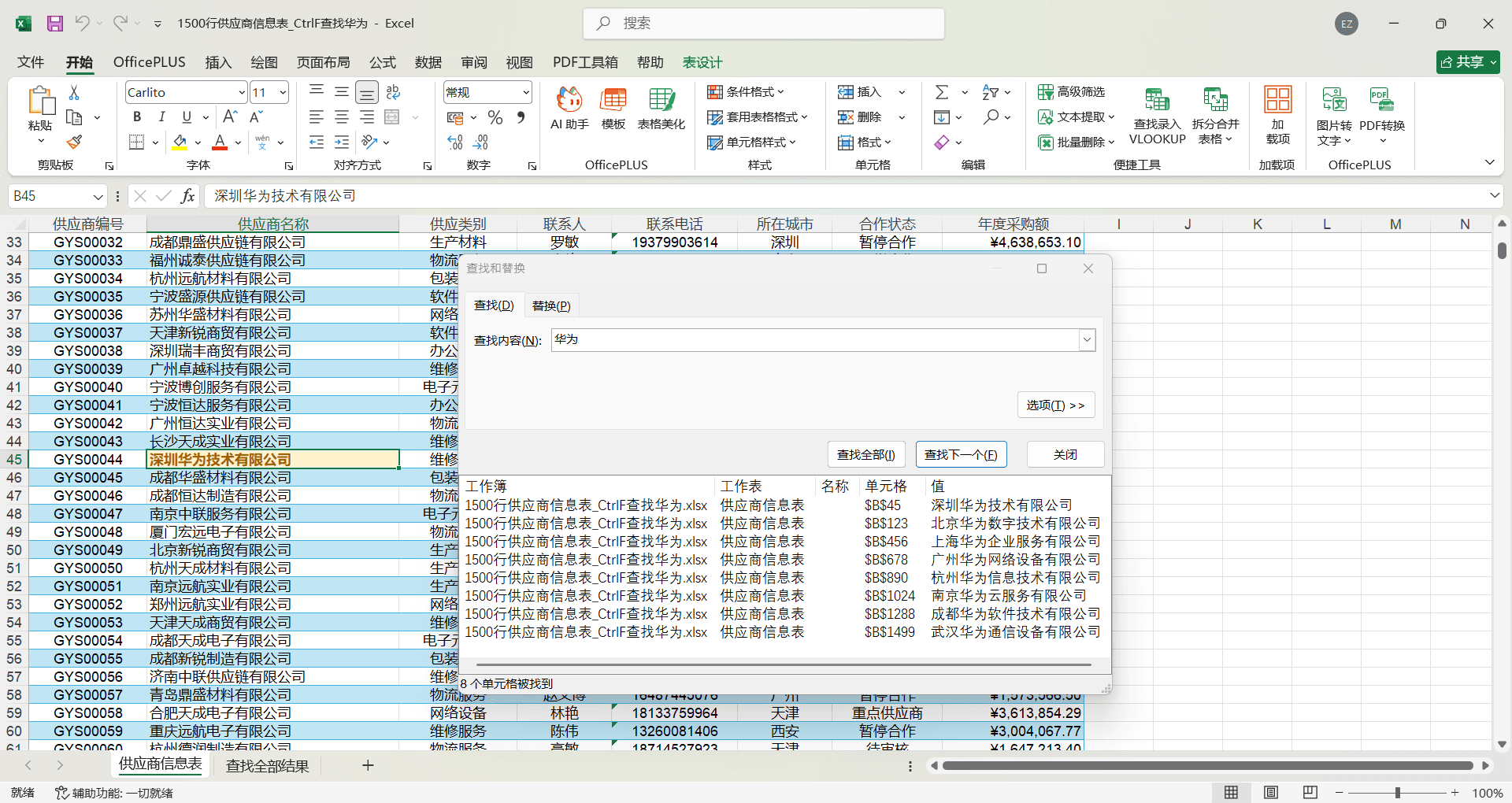
按 Ctrl+F 打开查找对话框,输入要查找的内容后点击“查找下一个”,Excel 自动跳转到第一个匹配的单元格。再次点击“查找下一个”,跳到第二个匹配的单元格,依次类推。点击“查找全部”则会在对话框底部列出所有匹配的单元格地址和内容,点击列表中的任意一条就能跳转到对应位置。
一份 1500 行的“供应商信息表”,需要找到名称中含有“华为”的供应商。按 Ctrl+F,输入“华为”,点击“查找全部”,底部列出 8 条匹配结果,分别位于第 45 行、第 123 行、第 456 行等位置。点击任意一条即可跳转查看详细信息。
查找的高级选项
点击查找对话框中的“选项”按钮,会展开更多设置:
实际场景:一份表格中“市场部”和“市场部(华南)”“市场部(华北)”同时存在,只需要找到精确等于“市场部”的单元格,不要带括号后缀的。勾选“单元格匹配”后,只有内容完全是“市场部”三个字的单元格才会被命中,“市场部(华南)”不会出现在结果中。
替换功能
按 Ctrl+H 打开替换对话框(也可以在查找对话框中切换到“替换”选项卡),上方输入要查找的内容,下方输入要替换成的新内容。
一份“组织架构表”,因为公司架构调整,原来的“市场部”统一更名为“品牌营销中心”。这张表里“市场部”出现了 47 次,分布在不同的列和行中。
按 Ctrl+H 打开替换对话框。
“查找内容”栏输入“市场部”,“替换为”栏输入“品牌营销中心”。
点击“全部替换”,Excel 弹出提示“已完成 47 处替换”。整张表中所有的“市场部”瞬间全部变成了“品牌营销中心”。
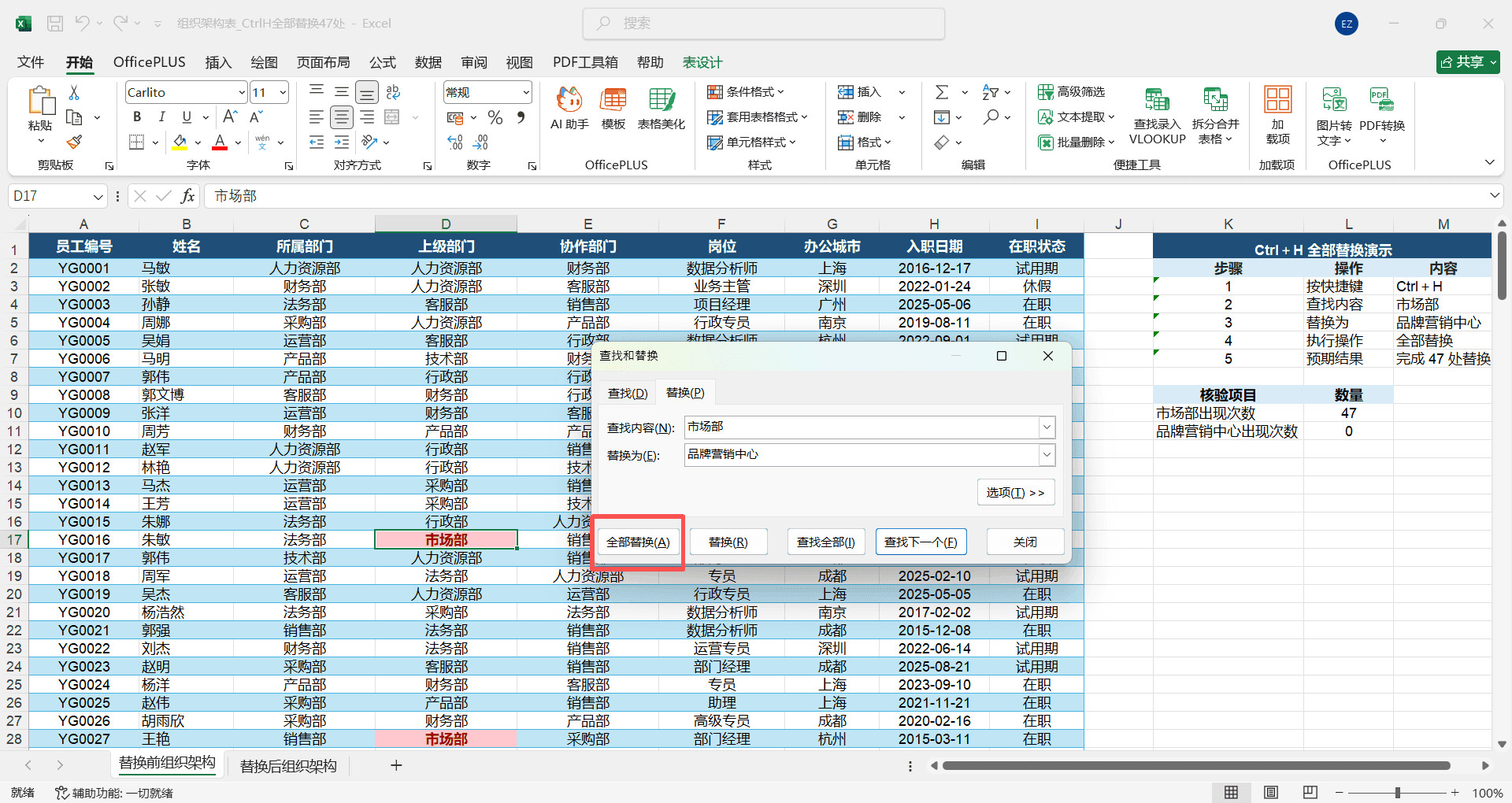
“全部替换”是不可预览的批量操作,一旦执行就会修改所有匹配项。如果“市场部(华南)”不应该被替换,但因为它包含“市场部”三个字也会被替换成“品牌营销中心(华南)”。操作前建议先点击“查找全部”,确认所有匹配项都是真正需要替换的,再执行“全部替换”。更稳妥的方式是勾选“单元格匹配”,确保只替换完全等于“市场部”的单元格。
替换的进阶用法
替换功能不仅能替换文字,还能用来批量修改格式,或者用空内容替换来实现批量删除。
批量删除特定字符: 一份从系统导出的数据,电话号码列中每个号码前面都带着国际区号前缀“+86”,要去掉所有号码前面的“+86”。打开替换对话框,“查找内容”输入“+86”,“替换为”留空(什么都不输),点击“全部替换”,所有号码前面的“+86”被删除,只留下 11 位手机号码。
批量替换换行符: 从网页或其他系统复制过来的数据,某些单元格内部含有换行符(Alt+Enter 产生的),导致行高参差不齐。要把这些换行符全部去掉,在“查找内容”栏按 Ctrl+J(代表换行符,输入后查找栏看起来像是空的,实际上已经输入了一个不可见字符),“替换为”留空或输入一个空格,点击“全部替换”,所有单元格内的换行符被清除。
定位功能
定位(快捷键 Ctrl+G 或 F5)能够一次性选中工作表中满足特定条件的所有单元格,是排序和筛选之外的第三种批量处理入口。
按 Ctrl+G 打开“定位”对话框后,点击左下角的“定位条件”按钮,弹出一个条件选择面板,常用的定位条件包括:
用定位功能批量填充空白单元格
从财务系统导出一份“部门费用明细表”,A 列是“部门名称”,但系统导出时做了合并单元格的效果——“财务部”只在第一行出现,下面属于财务部的 4 行数据 A 列都是空白的;接着“技术部”出现一次,下面 6 行又是空白的。如果要对这份数据做排序或筛选,空白行会导致分组错乱。需要把每个空白单元格都填上它对应的部门名称。
手动逐格填写 A 列的空白单元格,200 行数据至少要点击几十次。用定位功能可以一次性完成:
选中 A 列的数据区域(如 A2:A200)。
按 Ctrl+G 打开“定位”对话框,点击“定位条件”,选择“空值”,点击“确定”。
A 列中所有的空白单元格被同时选中(呈蓝色高亮)。此时不要点击任何地方,直接在编辑栏中输入公式 =A2(即引用当前空白单元格正上方的那个单元格)。
按 Ctrl+Enter(不是普通回车),公式会同时填入所有被选中的空白单元格。每个空白格都引用了它上方的单元格,从而继承了对应的部门名称。
- 点击下载: 定位空值后批量填充的操作效果
整个过程从打开定位到填充完成,不超过 30 秒,替代了原本可能需要 10 分钟的逐格手动输入。
Ctrl+Enter 是“对所有选中单元格同时执行输入”的快捷键,和 Enter 的区别在于:Enter 只对当前活动单元格生效,Ctrl+Enter 对所有被选中的单元格同时生效。这个快捷键在定位功能中使用频率极高,是批量填充的核心操作。
定位可见单元格
筛选数据后,需要把筛选结果复制到另一张工作表中。直接选中筛选后的区域 Ctrl+C 复制,粘贴后可能会意外包含被隐藏的行(在某些版本中会出现这种情况)。
更保险的做法是:筛选后先选中目标区域,按 Ctrl+G→“定位条件”→“可见单元格”,再 Ctrl+C 复制,这样确保只复制了屏幕上可见的行,隐藏行绝对不会被带过去。快捷键 Alt+;(分号)也可以直接选中可见单元格,省去打开定位对话框的步骤。
查找替换与定位的配合使用
实际工作中,这三个功能经常配合使用,形成一套完整的数据处理流程。
一份从外部系统导入的“客户订单表”存在以下问题:部分手机号码前面带有“+86”前缀、部分单元格是空白的需要补充、地址栏中的“广州”需要统一改为“广州市”。
处理流程:
先用替换功能(Ctrl+H),查找“+86”替换为空,清除所有手机号码的前缀。
再用替换功能,查找“广州”替换为“广州市”。替换前先点击“查找全部”确认没有“广州市”被替换成“广州市市”的情况(如果已经有“广州市”存在,需要先处理这个问题——可以先把“广州市”替换为临时占位符“GZ_TEMP”,再把“广州”替换为“广州市”,最后把“GZ_TEMP”替换回“广州市”)。
最后用定位功能(Ctrl+G→定位条件→空值),一次性选中所有空白单元格,根据业务规则统一填入默认值或引用上方单元格的值。
- 点击下载: 查找替换与定位的配合使用
三步操作完成后,一份格式混乱的导入数据变成了规范统一的标准数据,整个清洗过程不超过两分钟。