查找函数与 Subtotal 函数
表格越大,“找数据”这件事就越费劲。人事拿着一个工号要在几百行的员工表里翻出对应的月薪,采购要按订货数量在折扣表里对出该用几折结算,客服要从一长串邮箱地址里截出用户名,销售主管筛选出华东区的订单后还想看一眼筛选结果的金额小计。这些需求靠眼睛扫、靠 Ctrl+F 一个个搜,数据一多就顶不住了。本章介绍两类专门解决这些问题的函数:一类是查找定位函数——VLOOKUP、MATCH、FIND、SEARCH,负责在表格和文本中把目标“捞”出来;另一类是 SUBTOTAL,负责在筛选和隐藏行的场景下做只统计可见数据的汇总。
VLOOKUP 函数
VLOOKUP 是 Excel 中使用频率最高的查找函数。它的工作方式是:拿一个值,去一个区域的第一列里从上往下找,找到后返回同一行中指定列的内容。
函数语法:
text
=VLOOKUP(查找值, 查找区域, 返回列号, 匹配方式)
查找值必须位于查找区域的第一列。VLOOKUP 只能“从左往右”返回——如果要返回的内容在查找列的左边,VLOOKUP 无能为力,需要用后面介绍的 INDEX 加 MATCH 组合。
精确查找:按工号查月薪
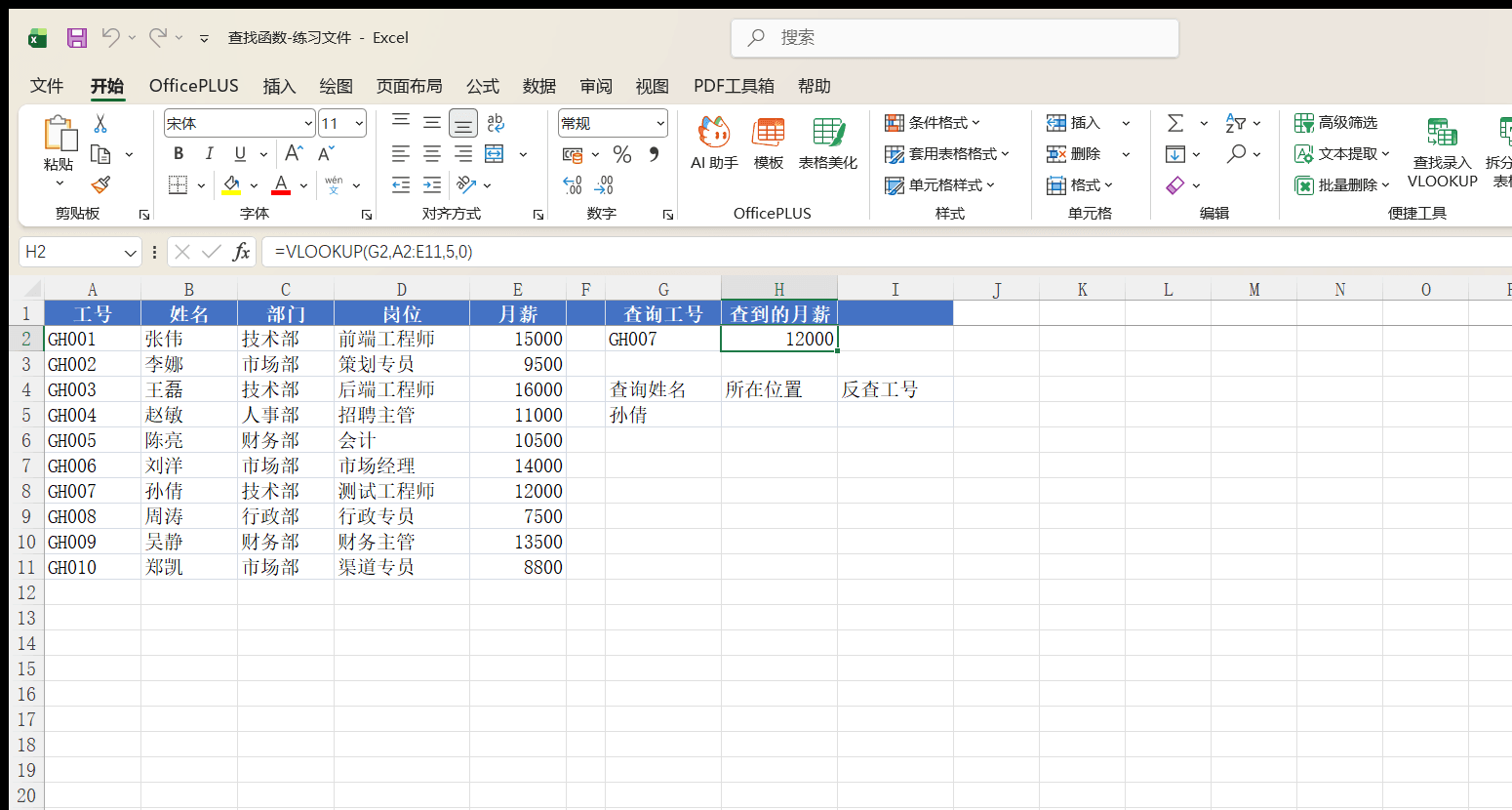
练习文件的“员工工资表”中,A1:E11 存放了 10 名员工的信息:
现在要查工号 GH007 的月薪。G2 中输入查询工号“GH007”,在 H2 中写公式:
text
=VLOOKUP(G2, A2:E11, 5, 0)
公式的执行过程:拿 G2 中的“GH007”,到 A2:A11(查找区域的第一列)从上往下找,在第 7 行找到;月薪在区域的第 5 列,于是返回该行第 5 列的值 12000。
第四个参数写 0,表示精确匹配——工号必须一模一样才算找到。查工号、查姓名、查产品编码这类场景,一律用精确匹配。
点击下载模板:VLOOKUP查找-练习模板.xlsx
近似查找:按采购数量匹配折扣率
第四个参数写 1 或 TRUE 时,VLOOKUP 变成近似匹配:找不到完全相等的值时,返回小于等于查找值的最大值所在行。这种模式专门用来做“区间匹配”。
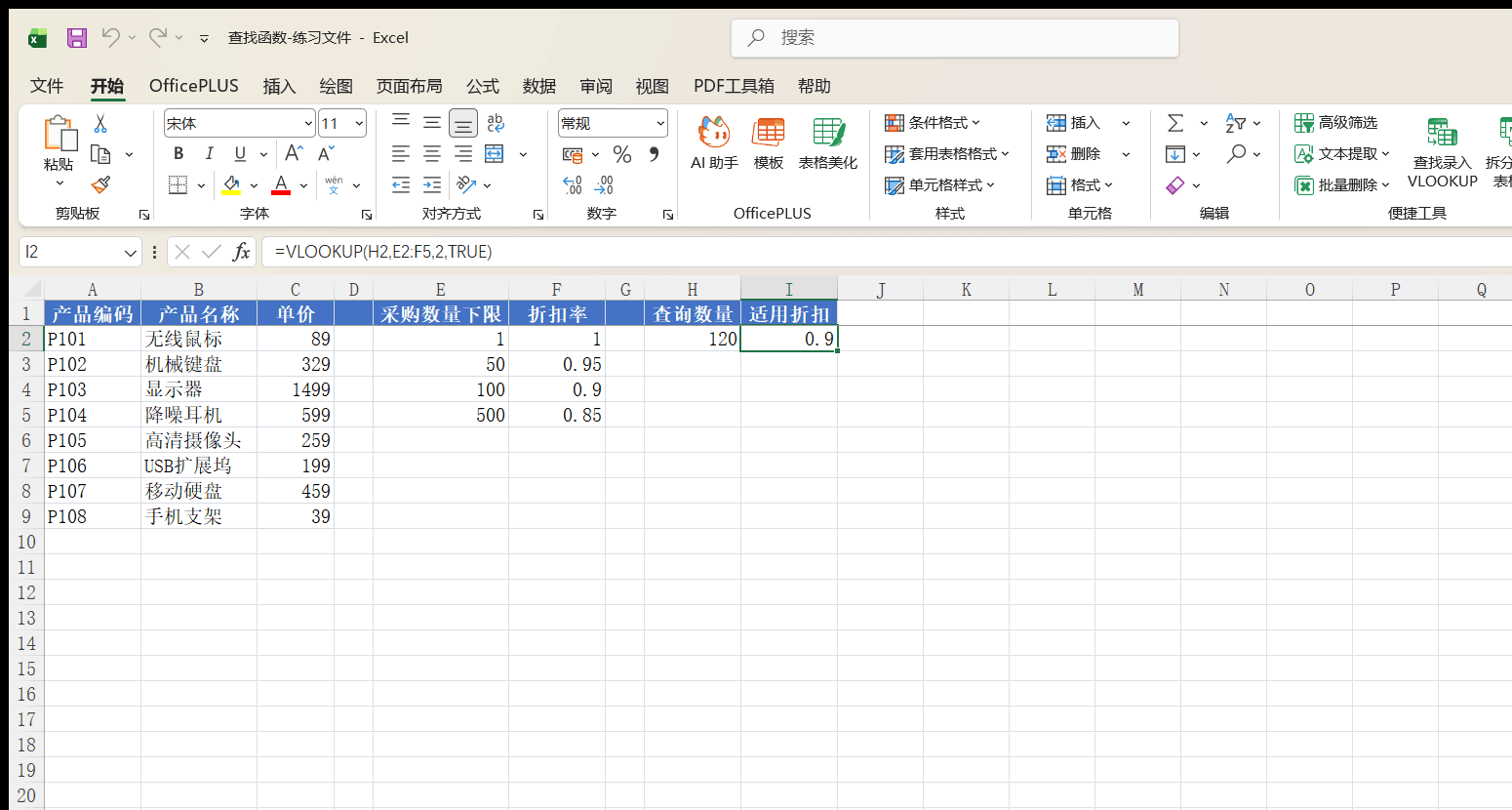
“产品价格表”的 E1:F5 是一张阶梯折扣表,采购数量越大折扣越低:
客户这次要采购 120 件,H2 中输入数量 120,在 I2 中写公式:
text
=VLOOKUP(H2, E2:F5, 2, TRUE)
区间表里没有 120 这个值,近似匹配返回小于等于 120 的最大值——也就是 100 那一行,结果是 0.9,按九折结算。如果采购 49 件,小于等于 49 的最大值是 1,返回 1,不打折。
近似匹配要求查找区域的第一列必须按升序排列。上面的区间表是 1、50、100、500 从小到大排的,所以结果正确;如果顺序打乱,VLOOKUP 不会报错,但返回的折扣率是错的。这种“不报错但结果错”的问题比 #N/A 更难发现。
点击下载模板:VLOOKUP区间匹配-练习模板.xlsx
常见错误:#N/A 的排查
VLOOKUP 用得多,翻车也多。最常见的错误是 #N/A——精确匹配模式下在第一列没找到查找值。逐条排查:
另一个高频失误是第四个参数漏写。参数省略时默认为近似匹配,如果数据没排序,公式会安静地返回错误行的数据,全程不报错。养成习惯:只要是精确查找,第四个参数明确写 0。
找不到时不想看到 #N/A 刺眼地趴在报表里,可以用 IFERROR 包一层:
text
=IFERROR(VLOOKUP(G2, A2:E11, 5, 0), "未找到")
查不到时单元格显示“未找到”,不影响后续的求和统计。
MATCH 函数
VLOOKUP 返回的是找到的“值”,MATCH 返回的是找到的“位置”——目标在区域中排第几个。
函数语法:
text
=MATCH(查找值, 查找区域, 匹配方式)
查找区域只能是一行或一列。匹配方式与 VLOOKUP 类似:0 为精确匹配,1 为近似匹配(要求升序,默认值),-1 为近似匹配(要求降序)。日常使用几乎都写 0。
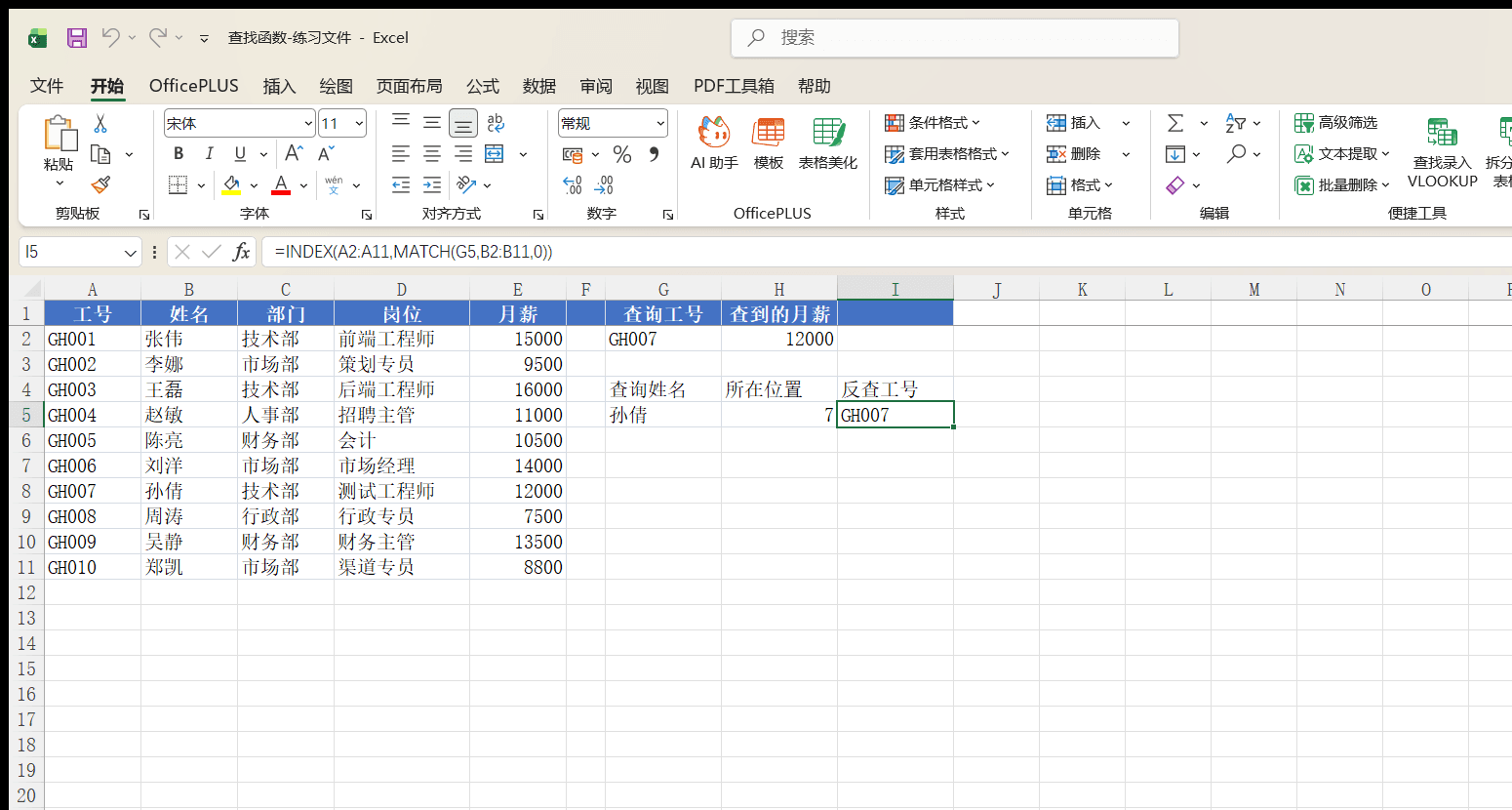
还是员工工资表,G5 中输入姓名“孙倩”,在 H5 中写公式:
text
=MATCH(G5, B2:B11, 0)
结果是 7——孙倩在 B2:B11 这一列的第 7 个位置。注意返回的是相对位置而不是行号:区域从 B2 开始数,所以第 7 个对应的是工作表第 8 行。
单独一个位置数字用处有限,MATCH 的真正价值在于给别的函数“导航”。
与 VLOOKUP 配合:反向查找
VLOOKUP 有个硬限制:只能从查找列往右返回。员工表里工号在 A 列、姓名在 B 列,“按工号查姓名”没问题,反过来“按姓名查工号”就卡住了——工号在姓名的左边。
INDEX 加 MATCH 的组合不受方向限制。INDEX 的作用是“从区域里取第几个”,MATCH 负责算出“第几个”:
text
=INDEX(A2:A11, MATCH(G5, B2:B11, 0))
在 I5 中输入这个公式,执行分两步:MATCH 先在 B2:B11 中找到“孙倩”的位置 7,INDEX 再从 A2:A11 中取出第 7 个值,返回 GH007。查找列在左在右都无所谓,两个区域行数对齐就行。
点击下载模板:MATCH定位-练习模板.xlsx
MATCH 还有一个常见用法是给 VLOOKUP 的第三个参数“返回列号”导航。表格列很多时,手动数“月薪是第几列”容易数错,可以写成 =VLOOKUP(G2, A2:E11, MATCH("月薪", A1:E1, 0), 0),让 MATCH 自动算出“月薪”在标题行的第 5 列。以后表格插入新列,公式也不会失效。
FIND 与 FINDB 函数
VLOOKUP 和 MATCH 在单元格之间找,FIND 在一个单元格内部的文本里找——返回一段字符在另一段字符中第一次出现的位置。
函数语法:
text
=FIND(要找的文本, 在哪找, 起始位置)
第三个参数可省略,省略时从第 1 个字符开始找。找不到时返回 #VALUE! 错误。
“文本查找”工作表的 A 列存放客户邮箱。邮箱地址的用户名长度不固定,没法用固定位数的 LEFT 直接截取,但“@”符号的位置可以用 FIND 定位。A2 是 linda2024@example.com,在 B2 中写公式:
text
=FIND("@", A2)
结果是 10——“@”是第 10 个字符。位置有了,用户名就是“@”前面的 9 个字符,配合 LEFT 提取,在 C2 中写:
text
=LEFT(A2, FIND("@", A2) - 1)
结果是“linda2024”。公式下拉后每一行都按自己的“@”位置截取,长短不一的邮箱全部处理正确。这套“FIND 定位+LEFT/MID 提取”的组合,是处理不定长文本的标准做法。
FINDB 是 FIND 的字节版。FIND 把每个字符都数成 1,FINDB 把中文字符数成 2 个字节、英文和数字数成 1 个字节。D2 是“销售部张伟Zhang Wei”,对比两个函数找大写“Z”的结果:
text
=FIND("Z", D2)
返回 6——前面有 5 个汉字,“Z”是第 6 个字符。
text
=FINDB("Z", D2)
返回 11——5 个汉字占 10 个字节,“Z”从第 11 个字节开始。日常场景用 FIND 就够了,FINDB 只在需要按字节处理中英混合文本时出场,下一节会看到它的搭档 SEARCHB 的实际用法。
SEARCH 与 SEARCHB 函数
SEARCH 的语法和 FIND 完全相同:
text
=SEARCH(要找的文本, 在哪找, 起始位置)
两个函数的差别只有两点,但正是这两点决定了什么时候该用谁:
先看大小写。某单元格的内容是“Excel入门Ch12.xlsx”,要找“ch”:
text
=FIND("ch", "Excel入门Ch12.xlsx")
返回 #VALUE!——FIND 区分大小写,文本里只有大写开头的“Ch”,没有小写的“ch”。换成 SEARCH:
text
=SEARCH("ch", "Excel入门Ch12.xlsx")
返回 8,“Ch”在第 8 个字符的位置被匹配到。查英文内容时大小写往往不重要,这种情况直接用 SEARCH 更省心。
再看通配符。A7 的邮箱是 vip.club@mail.cn,用“m?il”找:
text
=SEARCH("m?il", A7)
问号匹配任意一个字符,“mail”符合这个模式,返回 10。如果要找的就是问号或星号本身,在字符前加波浪号,写成~?/~*。
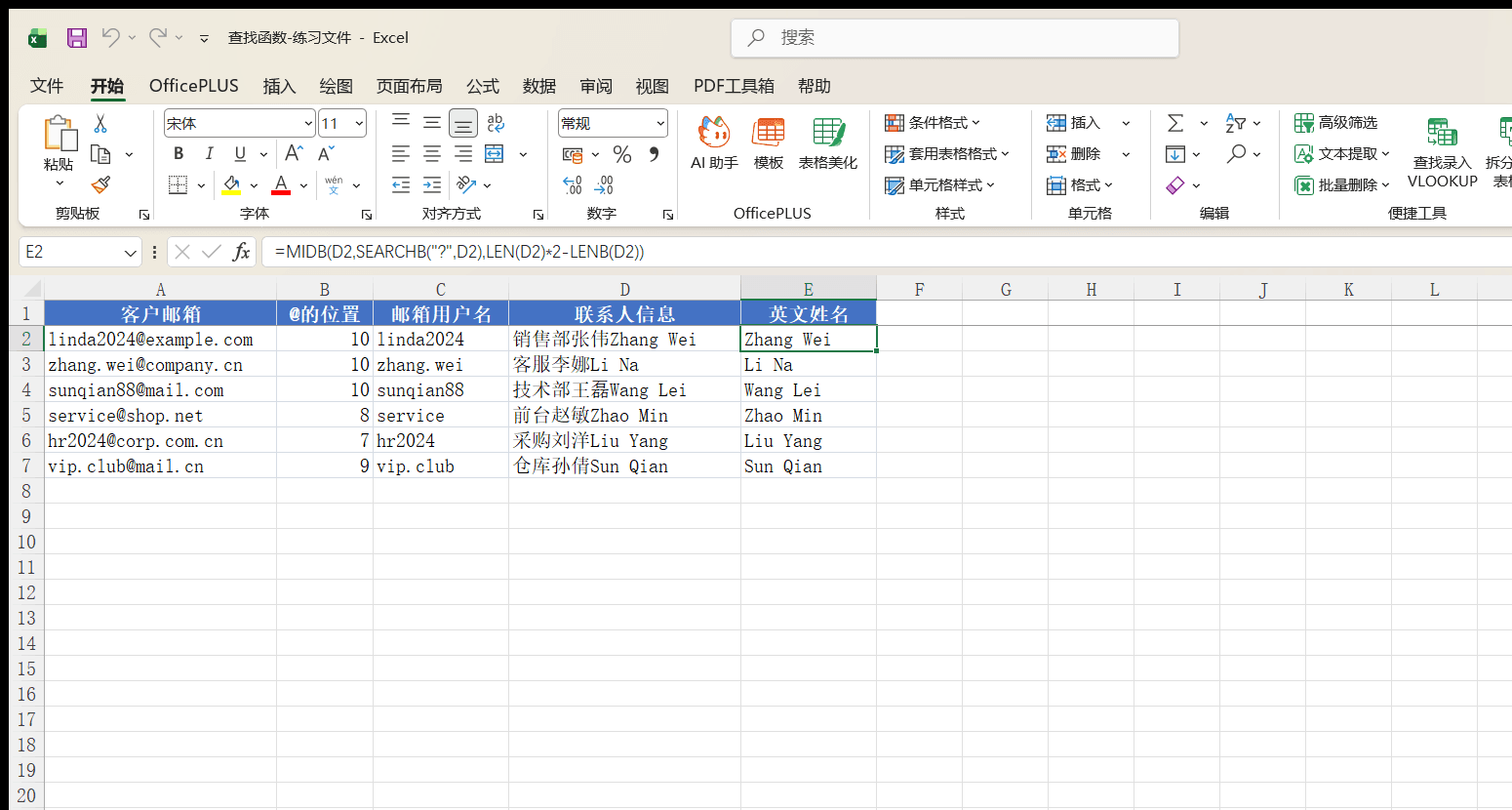
SEARCHB 按字节计数且支持通配符,两个特性合起来能解决一个实际问题:从中英混合的文本里把英文部分提出来。D 列的联系人信息是“部门+中文姓名+英文姓名”连在一起的,比如 D2 的“销售部张伟Zhang Wei”,中英文之间没有分隔符,英文起始位置也不固定。在 E2 中写公式:
text
=MIDB(D2, SEARCHB("?", D2), LEN(D2) * 2 - LENB(D2))
结果是“Zhang Wei”。拆开看这个公式:SEARCHB("?", D2) 用单字节通配符找到第一个英文字符的字节位置 11(前面 5 个汉字占 10 个字节);LEN(D2)\*2-LENB(D2) 算出英文部分的字节长度——D2 共 14 个字符、19 个字节,14×2−19=9,正好是“Zhang Wei”的字节数;MIDB 从第 11 个字节开始截取 9 个字节,英文姓名就出来了。公式下拉,每行的英文姓名全部提取成功。
点击下载模板:FIND与SEARCH-练习模板.xlsx
选函数的判断顺序很简单:需要区分大小写,用 FIND;需要通配符做模糊查找,用 SEARCH;需要按字节处理中英混合文本,换成对应的 FINDB 或 SEARCHB。语法四个函数完全一样,记住一个就等于记住了四个。
SUBTOTAL 函数
月底对账时有个很典型的场景:销售流水表筛选出“华东”区域的订单后,想看筛选结果的金额合计。如果直接用 SUM,会发现结果纹丝不动——SUM 不管行是不是被筛选隐藏了,照单全收。SUBTOTAL 就是为这种场景准备的:它只统计可见的行。
函数语法:
text
=SUBTOTAL(功能代码, 数据区域)
第一个参数是功能代码,决定 SUBTOTAL 做哪种计算。常用代码对照:
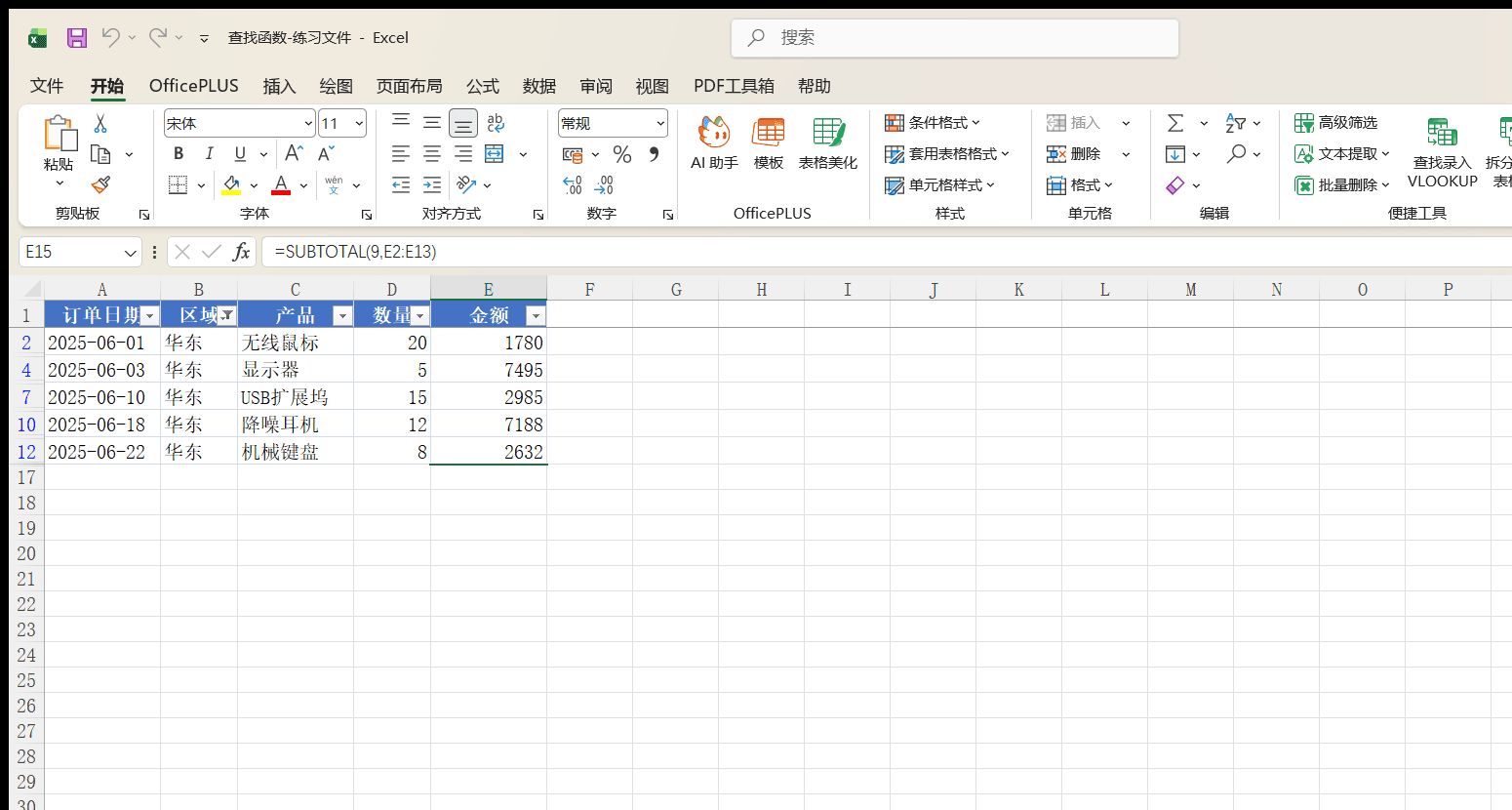
“销售流水”工作表的 A1:E13 是 6 月的 12 笔订单,金额合计 48397 元。表格下方 E15 和 E16 分别写了两个公式:
text
=SUBTOTAL(9, E2:E13)
text
=SUM(E2:E13)
没有筛选时,两个公式都返回 48397,看不出差别。给 A1:E13 加上筛选,把区域筛成“华东”——可见的只剩 5 笔订单,这时 E15 的 SUBTOTAL 变成 22080(1780+7495+2985+7188+2632),E16 的 SUM 依然是 48397。筛掉的行 SUBTOTAL 自动排除,SUM 全部算进去,这就是两者的根本区别。
点击下载模板:SUBTOTAL筛选小计-练习模板.xlsx
9 与 109 的区别
代码 9 和 109 都是求和,差别在对“手动隐藏”的行的态度上。行被隐藏有两种方式:一种是筛选筛掉的,另一种是选中行右键“隐藏”手动藏起来的。两种代码的处理规则:
筛选场景下用 9 还是 109 结果一样。区别出现在手动隐藏时:比如领导要求汇总时暂时剔除某几笔待核实的订单,把那几行右键隐藏后,SUBTOTAL(9, ...) 的结果不变,SUBTOTAL(109, ...) 的结果会把隐藏行扣掉。要做“所见即所得”的汇总——看到多少算多少——用 109 更符合直觉。
SUBTOTAL 还有一个贴心的特性:它会自动忽略数据区域里其他 SUBTOTAL 公式的结果。分部门做了多个小计行之后,在最底部再写一个 SUBTOTAL 算总计,中间的小计行不会被重复累加。用 SUM 做同样的事就会把小计也加进去,总计直接翻倍。
SUBTOTAL 只对“行”的隐藏生效,是为垂直数据设计的。如果数据横着排、需要忽略隐藏的列来求和,SUBTOTAL 帮不上忙。日常表格尽量按“一行一条记录”的竖排结构组织数据,这也是所有筛选、统计功能的前提。
本章的几个函数各管一段:VLOOKUP 在表格里按值找值,MATCH 找位置并给 INDEX、VLOOKUP 导航,FIND 和 SEARCH 深入单元格内部定位字符,SUBTOTAL 负责筛选和隐藏之后的“可见汇总”。把它们组合起来,“从大表里捞数据、对文本做拆解、对筛选结果做小计”这三类日常需求就都有了标准解法。