假设检验与模型选择

在前面的学习中,我们掌握了如何使用最小二乘法估计回归模型的参数,以及如何进行预测。现在,我们要学习线性回归模型的第三个重要用途:假设检验。这标志着我们从简单的参数估计进入了更深层次的科学推断领域。
如果你是中国人民银行的经济学家,正在研究货币政策对经济增长的影响,建立了一个包含利率、通胀率、GDP增长率等变量的回归模型。现在面临的关键问题不再是“这些变量的系数是多少”,而是“利率变化真的对经济增长有显著影响吗?”、“通胀率的影响是否可以忽略?”、“这个模型是否比其他竞争模型更适合解释中国的经济现实?”
假设检验的核心价值在于:它为我们提供了一套科学的方法来评估理论假说是否得到数据的支持,从而将经济学研究从主观猜测转向客观验证。
假设检验不仅仅是统计技巧,更是经济学研究的基本方法论。它帮助我们回答以下关键问题:
- 某个经济变量是否真的重要?
- 两个竞争理论哪个更符合现实?
- 我们的模型设定是否正确?
- 如何在多个候选模型中做出选择?
假设检验的基本思想
从艺术品拍卖说起
假设我们研究艺术品拍卖市场,想知道绘画的尺寸 () 是否会影响成交价格。我们设立如下回归模型:
直觉告诉我们,也许尺寸会有影响,但细想后发现,世界著名画作如《蒙娜丽莎》尺寸仅为 英寸,达利的《记忆的永恒》更只有 英寸。尺寸究竟重不重要?要不要“凭感觉”就下结论?这正是统计推断要回答的问题。
于是,我们设立如下假设检验问题:
- 原假设(H₀):(尺寸对价格无显著影响)
- 备择假设(H₁):(尺寸有显著影响)
即:
假设检验的核心逻辑
假设检验实际遵循着一套严密且简明的步骤:
提出假设:明确研究问题、设立 与 。
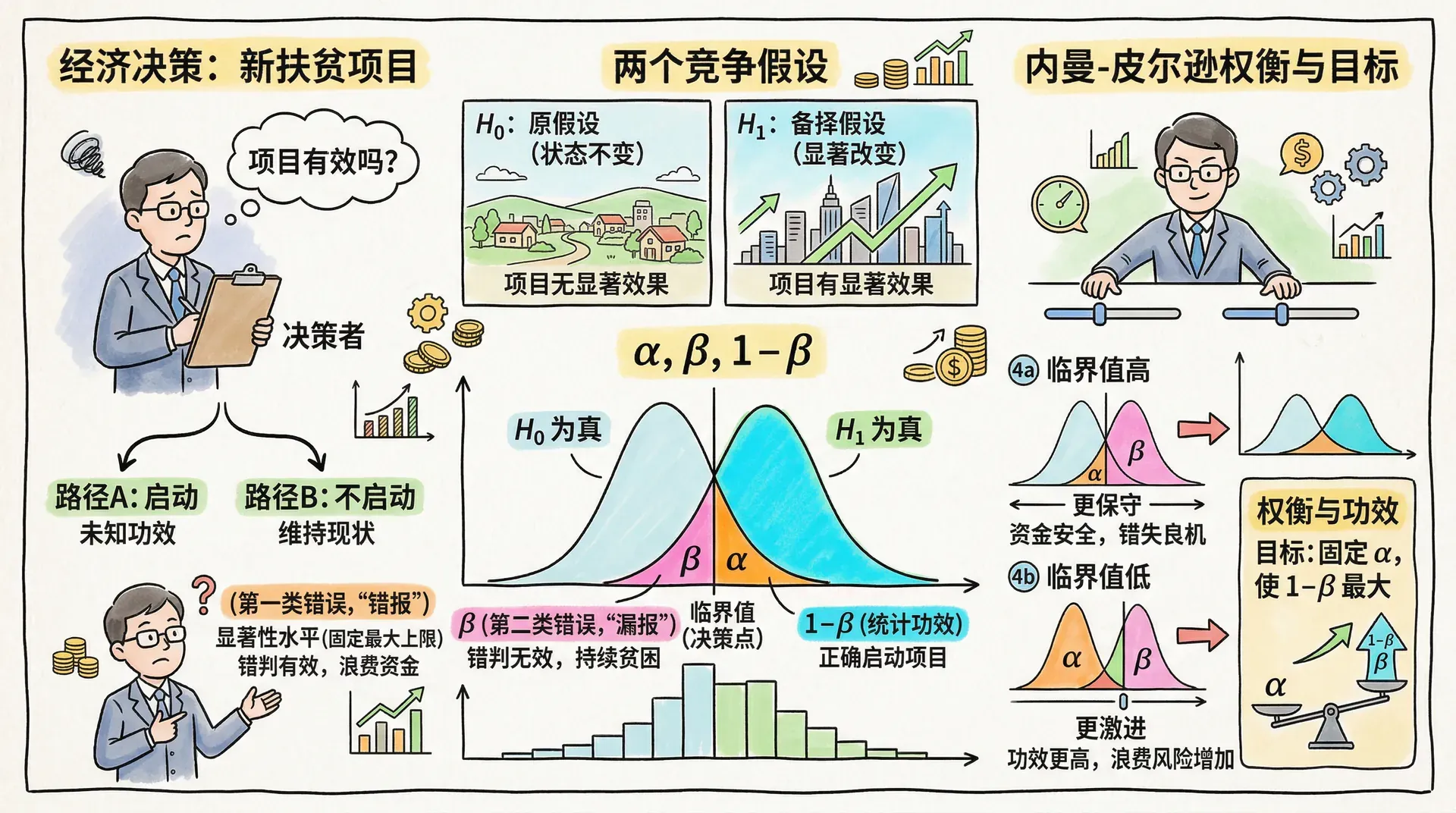
上图展示了双侧假设检验的概率密度和拒绝域。以常见的 显著性水平为例,左右拒绝域分别对应 ,其临界值为 和 。若观测到的 统计量落在红色拒绝域 ,我们就有理由怀疑 的正确性,从而“拒绝原假设”。
两类错误与检验的权衡
在假设检验过程中,无法避免犯两种类型的错误。理解这两类错误对于科学决策至关重要:
检验功效(power)即 ,代表在 错误时,正确识别出错误并作出决策的能力。在政策分析、医疗试验等领域,高功效是确保科学决策的重要保障。
假设检验的艺术在于平衡这两种错误:降低第一类错误(,即“冤枉好人”)的风险,通常会提高第二类错误(,即“放过坏人”)的概率。选择合适的显著性水平 (如 5% 或 1%)是研究者需要根据实际问题和后果权衡做出的判断。
例如,在药物审批中,第一类错误风险()控制得非常低,以防止将无效或有害新药批准上市。但这样做会提高将有效药物错杀(第二类错误)的概率。
嵌套模型与非嵌套模型
在比较不同经济模型时,有必要区分“嵌套模型”和“非嵌套模型”:
嵌套模型:一个模型是另一个更一般模型的特例。更具体地说,模型 在某些参数取特定值时,能变为模型 。
考虑如下投资行为的两个回归模型:
- 无限制模型:
这实际上对 加入了约束:,即投资者只考虑实际利率,而忽略名义利率和通胀的分离影响。
非嵌套模型:两个模型都不能通过参数约束变成对方。例如,
- 模型A: 只包含通胀率对投资的解释
- 模型B: 只包含名义利率对投资的解释
它们的变量选择完全不同,互为平行而非可嵌套。
嵌套模型比较时,通常采用 检验或似然比检验等经典假设检验方法。而非嵌套模型则需要用 J 检验、Vuong 检验或信息准则(如 AIC/BIC)等方法辅助判断哪一个更优。
假设检验方法论
Neyman-Pearson 框架
现代假设检验的理论基础是 Neyman-Pearson 框架。这个方法论强调在进行检验前,严格预先设定各项规则,根据客观的数据和标准来做出机械式决策,而不是事后主观判断。
基本步骤如下:
设定假设:首先提出原假设 (通常是“无效/无作用/无差异”)和备择假设 (存在某种作用或差异)。
常用公式举例(双侧 检验):
拒绝域通常形式为:
这一系列机械的步骤确保了检验的结果具有客观性和可重复性。
检验的一致性
一个理想的统计检验应当具备一致性(consistency)。所谓一致性,是指当实际 为假、样本量 时,检验犯第二类错误(即没有拒绝 )的概率 会收敛到 ,即强有力地识别出假设错误;而当 为真时,第一类错误概率 能始终受控于你设定的水平。
其数学表达式为:
- 若 为假,(功效趋近于 )
这意味着:
- 如果 为假,随着样本量 增加,概率几乎一定能正确地拒绝 。
- 如果 为真,样本量再大也不会让错误拒绝 的风险()失控。
图形说明:随着样本量 增加,检验功效 显著提升,趋近于 ,而第一类错误概率 总是控制在你预先设定的水平(如 )不变。这正是一致性假设检验的精髓和优越性。
经典方法论与贝叶斯方法论
在统计假设检验中,经典(频率学派)和贝叶斯方法常被对比。各有优劣,平台选择取决于实际问题背景与研究者偏好。
经典方法(如Neyman-Pearson)的特征:
- 只基于样本和分布,给出“拒绝/不拒绝” 的非概率性推断
- 只在设定的 水平控制第一类错误概率
- 不引入先验概率——只有样本数据本身,不涉主观信念
- 不太容易解释“ 成立的概率是多少”这种问题
贝叶斯方法的特征:
- 先输入主观或外部信息(先验),通过观测数据更新为后验概率
- 能直接回答“ 成立的概率是多少”这类问题
- 结果以概率描述,更便于解释和决策
- 可整合不同来源、不同阶段的证据,提高累积性
例如,经典 值反映的是“在 成立下观测到的数据或更极端的概率”,并不是“ 成立的概率”;而贝叶斯方法可以直接计算 。
在实际研究中,如果检验统计量(如 值或 值)非常接近临界值,比如 而临界值为 ,此时结果极其接近边界,要格外小心。建议完整报告 值甚至置信区间,供读者自行判断证据强度和实际意义。
线性假设的一般形式

在经济学和计量经济学的实证实践中,针对回归模型参数的各种复杂理论检验,往往都可以转化为“线性约束”的矩阵化表达。采用通用的矩阵记号,可以统一处理单一参数、参数组,乃至参数线性关系等多样命题。这对于后续的统计推断和模型解释极为便利,也有助于理论假设与实际推断的对接。
假设的矩阵表示法
最常见的线性假设可以形式化为如下矩阵表达式:
这里:
- :为 的已知矩阵, 表示约束数量(即有多少条独立假设),为模型参数个数。
- :为 的参数(未知,不同变量的回归系数)。
通过这个框架,各种常见和复杂的经济假设都能兼容。例如:
例如:
- 单一系数检验:若检验 ,则 取一行,第 个元素为 ,其余为 ;。
更多常见线性假设及其矩阵化举例
无论是对单参数还是多参数的线性组合,都可以很直观地嵌入上面的 、 框架。这为后续联合检验与约束检验提供了极大灵活性。
中国实证场景下的假设设定举例
比如我们关注中国城乡消费行为的计量模型如下:
典型的经济理论假设可能有:
-
财富效应为零
表示:财富变量对消费无独立影响。
-
利率影响中性
这些假设对应着具体的经济学理论问题。借由 和 的设定,你可以在实证研究中灵活搭建结构性假设框架,对中国经济问题作有力检验。
Wald 检验法
Wald 检验是经典线性模型参数约束检验中最基础也最常用的方法之一,也叫“显著性检验”。其核心思路是:若原假设成立,则参数估计值与假设值应非常接近,若偏离显著,则可怀疑原假设不成立。
Wald 检验可以用于单个参数、参数差值甚至参数线性组合的显著性考察。
单参数的 Wald(t)统计量
以单一参数为例,Wald 检验统计量其实就是我们熟悉的“t 统计量”,具体公式为:
其中:
- 为某参数的估计值
- 为假设下的值(往往为 )
- 为 的标准误
进一步地,对于单参数的双侧检验,当 超过临界值时(通常在 的水平( 显著性)),说明观测值与假设值之间偏差很大,可以拒绝原假设。
t 检验实感例:教育收益率
以中国教育收益率回归为例:
假设已回归得到下列结果:
- 教育收益率:
- 标准误差:
那么 t 统计量为:
直观地, 远大于双侧检验 临界值 ,我们强烈拒绝原假设,即“教育对收入无影响”并不成立。
置信区间与假设检验的等价性
值得强调的是,t 检验与置信区间其实反映的是同一问题的两种表述方法:
- t 检验角度:若 ,在 显著性水平下拒绝 。
- 置信区间角度:若 不在 置信区间内,也同样拒绝 。
也就是说,这两种检验逻辑是等价的,只是信息表达角度不同。
中国艺术品市场的回归检验
假如你已回归了以下模型(430 幅莫奈画作的拍卖数据):
(标准误分别为 )
逐项检验:
-
面积效应:
强烈拒绝 。买家对尺寸显著关心。
该例子说明:同一个回归模型中,变量对因变量影响的显著性可能大相径庭。借助检验,能够为变量对经济结果的重要程度,提供客观、可度量的证据。
单侧检验与双侧检验
有时经济理论假设拥有方向性(单侧),比如效应“是否大于”某一值。例如,检验面积弹性是否大于 1:
此为右尾单侧检验,此时临界值约为 (而不是)。
在艺术品例子中,带入数值得:
可见 超出单侧临界值,故拒绝 ,即面积弹性显著大于 。这意味着艺术品市场具有“尺寸溢价”的特殊经济现象。
多重约束的联合检验
F统计量的构造
当我们需要同时检验多个约束条件时,单靠逐项 检验已不够。此时应使用 检验来判断多个参数是否可以联合成立。 统计量基于 Wald 距离度量,可写作:
其中:
- 为 的约束矩阵( 为约束个数, 为回归参数个数),
- 为估计参数向量,
- 为约束值,
- 为回归残差方差的估计值。
统计量刻画了样本估计值与假设值之间的加权距离,反映了所有 个约束同时成立的证据强度。
F检验的经济学直觉与判定标准
检验主要关注的问题是:“这 个约束可以同时成立吗?” 即便每一个约束对应的 检验均不显著,它们的联合效应有时依然可能显著。
下图展示了 检验的决策过程, 分布的临界值将拒绝域和接受域清楚划分。当观测 值落入红色 “拒绝域” 时,应拒绝原假设。
如果观测的 值大于临界值(即落入红色“拒绝域”),我们就拒绝原假设 ,认为约束不合理。
投资方程的联合检验
考虑中国投资函数的估计,我们想检验“投资者只关心实际利率”这一理论。具体模型:
理论假设为:
假设使用 1950-2000 年季度数据,估计结果为:
- ,
- ,
检验步骤:
- 约束的估计值:
因此,我们不能拒绝原假设,数据结果支持“投资者只关心实际利率”的理论。这个例子展示了联合检验在宏观经济政策分析中的实际应用,结果支持了实际利率理论,为货币政策制定提供了依据。
基于拟合优度的F检验
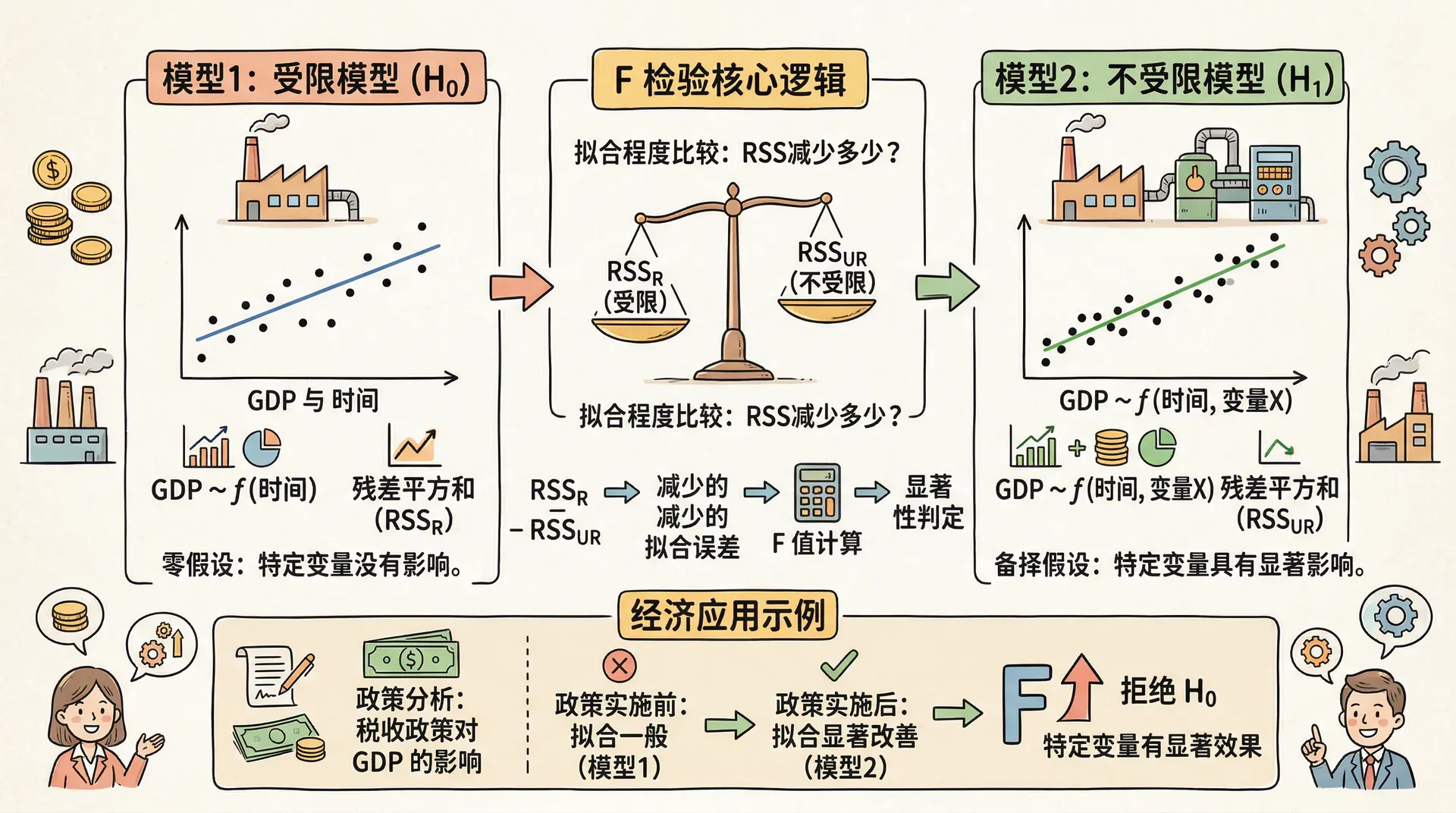
如果我们不关注参数本身,而关注约束对模型整体拟合的影响——此时更直观的做法是直接比较“有无约束模型”的拟合优度变化。若约束成立,加以约束后拟合优度 不会明显下降。
拟合优度损失的测量与F统计量
对 进行比较, 检验统计量形式如下:
其中:
- 为无约束模型的拟合优度,
- 为加约束后的拟合优度,
- 为约束个数,
- 为样本容量, 为回归参数个数(含常数)。
如果 降低很少,说明约束成立是可以接受的;若降低明显,则约束不成立。
F检验直觉图示
如果引入参数约束后导致拟合优度()损失太大,说明被施加的限制与数据特点严重冲突,此时 检验统计量会显著升高,通常超出临界值,从而拒绝原假设。也就是说, 检验正在帮助我们量化判断:“应用这些约束,是否会让模型表现明显变差?” 如果是,则说明这些理论假设在当前数据下并不成立。
整体显著性检验
特别重要的一个 检验是整体显著性检验:检验除常数项外所有系数是否均为零。
其 统计量为
其中 是除常数项外参数数目。
收入方程的整体显著性
例如,考虑中国已婚女性的收入模型:
假设有 个观测、
则
查表临界值 ,因为 ,拒绝原假设。
结论:、、、 四个变量联合对收入显著。
整体显著性检验是回归分析的“第一道关”。如果连这个检验都难以通过,则模型结构可能存在根本性问题。
约束最小二乘估计及其性质
有时我们还要在约束条件下求参数——即约束最小二乘(Constrained OLS)估计。它的数学目标是
利用拉格朗日法,约束下的参数估计为
此处 是无约束OLS估计, 是约束下的估计。
方差特性:可以证明,约束估计的方差总是小于等于无约束估计:
直观理解:约束本身相当于加入了“额外信息”,提升了估计效率。但如果约束是错误的,则可能引入偏差。
生产函数实证:F检验的实际应用
例如对生产函数类型的判定,常见柯布-道格拉斯(Cobb-Douglas)与超对数生产函数的比较。
柯布-道格拉斯模型:
更一般的超对数形式:
假设检验:
若
- 超对数模型 ,残差平方和 SSE = 0.680
- 柯布-道格拉斯 ,SSE = 0.852
则
查表 ,,不拒绝原假设。
结论:数据支持柯布-道格拉斯生产结构,无需复杂化为超对数型。
线性约束单项检验
另有一种重要的线性约束检验——规模报酬。对于生产函数:
这是单约束,可用 检验,或 。如:
(),不拒绝规模报酬不变的假设。
规模报酬检验是产业组织、宏观经济等领域的重要工具。检验结果影响我们对市场结构、产业监管的理解与政策建议。
非嵌套模型的比较
在实际应用和理论研究中,我们经常会遇到如何在多个互不包含的理论框架间进行抉择的问题。这些理论基础下建立的模型往往是非嵌套模型,即它们既不是彼此的特例,也无法通过调整参数彼此转换。这种情况下,传统的检验并不适用,需要更为灵活的方法。
非嵌套模型的挑战
设想如下两个关于中国居民消费行为的理论假说:
理论A(收入-滞后收入模型):
理论B(收入-滞后消费模型):
上述两种模型都包含三个参数,但变量结构完全不同。例如,理论A包含而理论B则包含。由于无法直接通过特殊化使一个模型变成另一个,二者即为典型的非嵌套情况。这在实际中非常常见,如不同企业定价理论、不同通货膨胀决定理论等。
J检验:非嵌套模型的比较工具
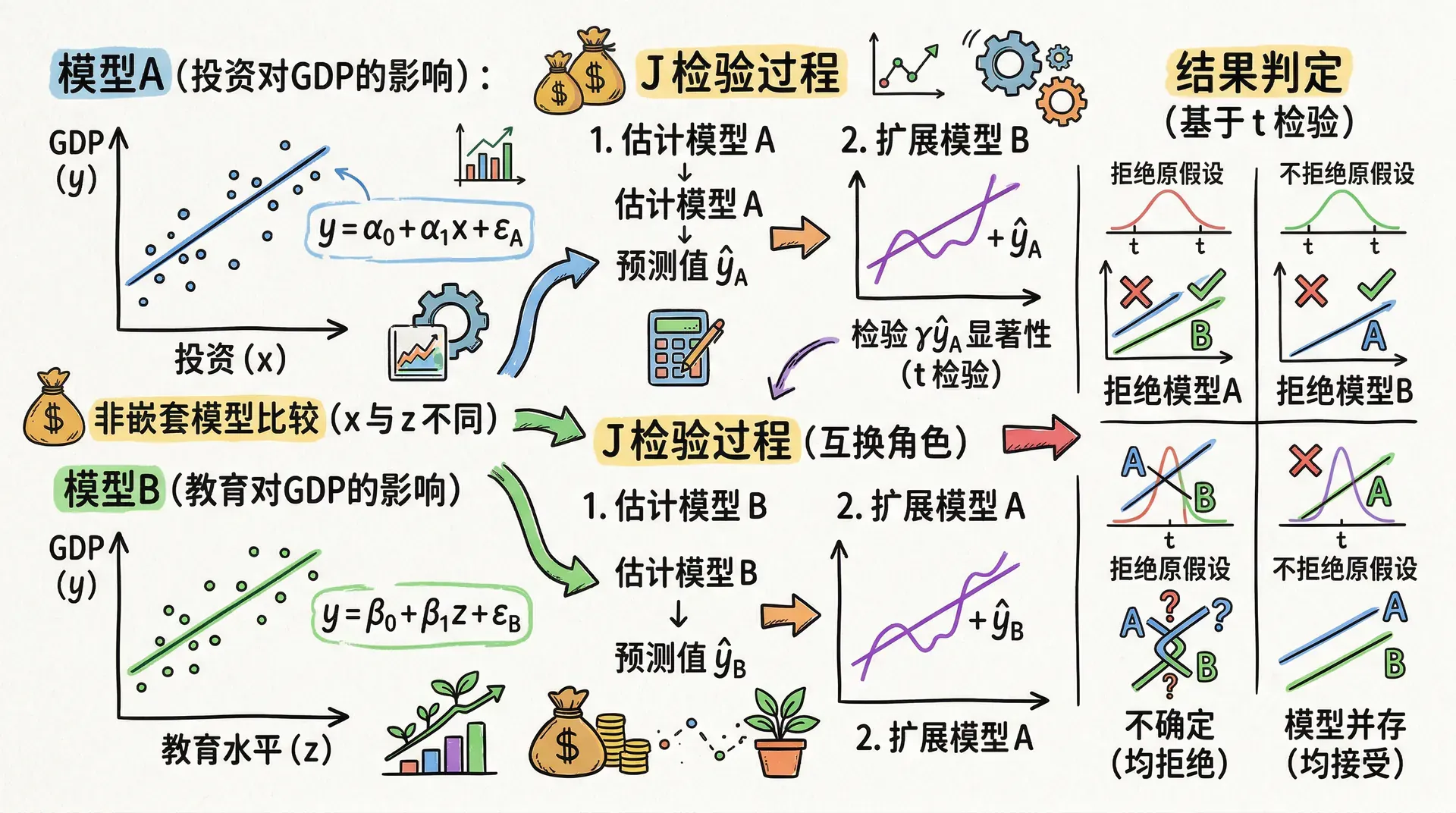
戴维森和麦金农提出的检验为非嵌套模型的比较提供了一套系统方法。基本思想可以归纳为:
分别独立估计两个竞争模型,得到各自的拟合值(模型A预测)与(模型B预测)。
若显著不为零,说明模型A的拟合结果包含了对的解释能力,即模型B存在遗漏信息。因此,我们可据此拒绝模型B。反过来亦然,可互换模型角色进行检验。
消费函数的J检验实证
以中国1950-2000年季度消费数据为例,利用检验判定上述两种模型优劣:
检验“模型A vs 模型B”:
- ,统计量
- 极为显著,说明模型A的信息无法由模型B捕捉,模型B被拒绝
检验“模型B vs 模型A”:
- ,统计量
- 显著拒绝模型A
检验结果可能有四种:拒绝A、拒绝B、同时拒绝两者、或两者都不拒绝。当二者皆被拒绝时,往往暗示真实的数据生成机制比任一理论模型更为复杂,值得探索新的模型设定。
这种现实中的“双拒绝”十分常见,表明我们可能需要融合不同理论机制,构建更全面的综合模型。
模型选择准则
信息准则的基本思想
科学模型选择不仅看拟合优度,更应惩罚无谓的复杂性。信息准则(Information Criterion) 为我们提供了在多个备选模型间进行理性权衡的“客观打分表”。这些准则通常包含两部分:一是残差(拟合误差),二是关于参数个数的惩罚项。
常用信息准则
其中为参数数,为样本量,为残差平方和。(Akaike信息准则)对复杂度惩罚较轻,倾向选择更“灵活”的模型;而(贝叶斯信息准则)惩罚项随增长,偏好更“简洁”的模型。
信息准则对比
如上图所示,与的最优点(最小值)可能位于不同模型复杂度:往往在变量较少时最优,则允许更复杂模型以提高拟合优度。信息准则告诉我们:模型并不是越复杂越好,应该追求在拟合与简洁之间的平衡。
实质性模型选择策略
在实际研究中,推荐如下模型选择流程:
- 理论优先:先用经济理论筛选合理候选模型,避免毫无根据的“数据挖掘”。
- 多准则验证:结合、、调整等多种标准交叉检查结果。
- 样本外检验:利用未参与拟合的样本,检验模型预测能力(如RMSE、MAPE等)。
- 稳健性分析:考察变量选择、样本变动、误差设定等变化对模型结果的影响。
“一般到特殊”建模法的优势
现代计量建模越来越鼓励“从一般到特殊”(general-to-specific, GETS)的逐步简化流程:
“特殊到一般”(传统):
- 先建简单模型,逐步加入变量
- 容易低估真实结构复杂性,产生遗漏变量偏差
“一般到特殊”(现代):
- 起步即纳入所有合理变量
- 利用统计检验去除冗余
- 更能捕捉复杂经济现象,减少设定误差
从“一般到特殊”的策略虽然对计算资源要求较高,但在现代数据与计算能力下,已成为建模主流,可更好发现数据中的真实结构。
预测电影票房的模型选择
以实际案例说明信息准则的应用。假定我们收集62部2009年中国电影的数据,比较以下两种票房预测模型:
- 传统模型:
- 网络热度模型:
将这两者在不同准则下进行对比:
结果解读:
- 提高(从到),和均明显下降
此案例表明,信息准则、预测能力与理论解释应综合考量。互联网影响在当前电影票房预测中已不容忽视。
大样本检验与稳健性
非正态下检验的有效性
在实际数据分析中,误差项常常违背正态分布假定。但根据中心极限定理,当样本量足够大时,许多统计量(如统计量、统计量)依然近似服从标准正态或卡方分布。
大样本近似过程:
- 统计量标准正态分布
- 统计量卡方分布/自由度
稳健性检验的若干问题
计量检验在实践中需格外关注如下稳健性问题:
- 样本量效应:小样本重视正态性假定,大样本则可依赖渐近理论。
- 异方差问题:数据中误差方差不恒定时,要用稳健标准误差(如White-校正)。
- 序列相关性:时间序列或面板数据常见序列相关,需要特别处理(如Newey-West标准误)。
- 模型设定风险:检验结果对模型变量选取、函数形式等可能敏感,应做稳健性考察。
实际应用的建议与注意事项
汇总上述分析,现实数据分析流程应把理论、数据和方法牢牢结合:
总结
我们已经建立了一套完整的假设检验理论框架,涵盖不同限制形式及适用的统计工具。
- 检验:适用于单个线性约束。其统计量形式为 ,服从 分布。
- 检验:用于同时检验多个线性约束。统计量格式为 ,服从 分布。
在实际的经济学应用中,假设检验与模型选择应紧密结合理论与实际需求。首先,设定约束和检验命题必须以明确的经济学理论为基础,而非简单的数据驱动。此外,为确保结论的稳健性,建议结合多种检验方法交叉验证,避免只依赖单一显著性指标。同时,研究者不仅应该关注统计显著性,更要考察其经济现实中的实际意义与解释力,将分析结果与政策建议紧密结合起来,增强应用价值。
对于模型选择,现代经济学强调包容性和客观性。通常建议先以较大的模型为起点,以防遗漏关键变量造成偏差,并利用如AIC、BIC等信息准则作为客观标准进行模型筛选。不仅要关注模型对样本内数据的拟合,也要注重样本外的预测能力。同时应承认,模型选择中不可避免会有一定的主观性和偶然性存在。假设检验与模型选择共同构成了实证经济学分析的基础工具,帮助我们将经济理论高效地同现实数据和政策分析衔接起来,是现代经济学工作的核心内容。