需求预测
运营管理中的很多决策——采购多少原材料、安排多少生产班次、备多少库存——都需要提前对"未来需要多少"有一个判断。这个判断的过程,就是预测。预测不是占卜,没有人能完全准确地预知未来,但通过系统的方法和历史数据,企业可以将不确定性控制在合理范围内,从而做出更扎实的运营决策。
预测在运营中的作用
一家服装企业在夏季来临前,必须决定备多少件T恤;一家饮料工厂在春节前,要确定生产线的排班计划;一家电商仓库在双十一前90天,就开始测算各品类的备货数量。这些决策的共同起点,都是对未来需求的预测。
预测准确,库存合理,生产顺畅;预测偏高,货物积压,资金被占用;预测偏低,缺货断货,客户流失。两个方向的误差,都会直接损害企业的经营效益。
预测的目标不是追求绝对精准,而是把误差控制在业务可承受的范围内,让决策者有足够的依据采取行动。
预测的类型
根据时间跨度的不同,预测通常分为短期、中期和长期三类。不同时间跨度对应不同的决策场景,适用的方法也有所不同。
短期和中期预测在日常运营中最为常用,要求较高的精度,因为它们直接影响日常的采购和生产安排;长期预测更侧重方向性判断,误差范围相对可以接受更大,但一旦判断失误,损失也往往更为严重。
以中国某家电企业为例:它的短期预测决定了本月工厂排产多少台空调,中期预测决定了今年向核心零部件供应商下多大的年度框架订单,而长期预测则支撑了"是否在东南亚新建一条生产线"这类战略性决策。
定性预测方法
当历史数据不足、市场环境发生剧烈变化,或者需要对全新产品作出预判时,单纯依赖数字计算往往不可靠。这时就需要借助定性方法——依靠人的经验、判断和专业知识来形成预测结论。
专家判断法
专家判断法是最直接的预测方式:由一位或多位行业专家,根据自身经验和对市场的理解,对未来需求作出估计。这种方法速度快、成本低,适合时间紧迫或信息稀缺的场合。
但它的局限也很明显。不同专家的判断可能相差悬殊,且每个人都难以完全摆脱自身立场的影响——销售团队的预测往往偏乐观,因为乐观的数字对他们有利;采购团队则倾向保守,以防备货不足时被追责。
德尔菲法
德尔菲法(Delphi Method)是对专家判断法的系统性改进,专门用来克服个人偏见和群体压力带来的问题。
其核心流程是:组织多轮匿名问卷,收集各位专家的独立判断,将汇总结果匿名反馈给所有参与者,再进行下一轮征询,如此往复,直到专家意见趋于一致。由于全程匿名,权威人士无法通过影响力压制其他声音,每位专家都能基于汇总信息独立修正自己的判断。
国家能源局在制定"十四五"能源发展规划时,多次采用类似德尔菲法的多轮专家征询机制,最终形成对未来能源需求规模的预测结论。
定量预测方法
当企业积累了足够的历史销售数据,就可以用数学方法来进行预测。定量方法逻辑清晰、结果可验证、便于自动化,是运营管理中最常用的预测手段。以下介绍三种核心方法。
简单移动平均法
简单移动平均法的逻辑是:用最近若干期实际数据的平均值,作为下一期的预测值。每过一期,就将最早那期的数据去掉,纳入最新一期的数据,平均值随之"滚动"更新。
计算公式为:
其中 是第 期的预测值, 是第 期的实际销量, 是所选取的期数。
某饮料品牌过去6个月的月销售量(万箱)如下,取 预测第7月的销量:
越小,预测对近期数据变化越敏感,但也更容易受到短期波动的干扰; 越大,预测越平稳,但对趋势变化的反应会滞后。
加权移动平均法
简单移动平均法对每一期数据的权重完全相同,但现实中,越近的数据往往越能反映当前的需求趋势。加权移动平均法允许对不同时期赋予不同权重,越近的数据权重越高。
计算公式为:
其中各期权重之和满足:,且通常 。
沿用上面的例子,取最近3期,权重分别设为0.5、0.3、0.2,则7月预测值为:
与简单移动平均的48万箱相比,加权结果48.6万箱更贴近近期上升的趋势。在中国零售行业,加权移动平均常用于处理存在轻微上升或下降趋势的产品销量预测。
指数平滑法
指数平滑法是一种更加简便高效的加权方法。它只需要两个数据——上一期的实际值和上一期的预测值——就能算出本期的预测值,非常适合数据量大、需要频繁更新的业务场景。
计算公式为:
其中 是平滑系数,取值范围 。
越大,预测对最新实际数据的反应越灵敏,适合需求波动较大的场景; 越小,预测越平稳,适合需求相对稳定的场景。实践中 常取0.1至0.3之间。
某连锁超市6月实际销售额为120万元,6月的预测值为115万元,设 ,则7月预测值为:
指数平滑法在中国连锁零售、电商仓储等领域广泛使用,许多ERP系统的自动补货模块内置了指数平滑算法,企业只需设定合适的 值,系统便会自动滚动更新预测结果。
下面对三种定量方法进行综合对比:
趋势调整与季节性因素
现实中的需求往往不是一条平坦的水平线。有些产品的销量在逐年增长,有些则在下滑;还有很多产品的需求在特定时期(夏季、节假日、开学季)会出现规律性的高峰和低谷。基础的移动平均或指数平滑,单独使用时往往无法捕捉这些特征。
趋势调整是在指数平滑的基础上,加入对持续趋势的修正。如果需求持续上升,普通指数平滑会因为总是追着实际数据跑而系统性地低估;趋势调整则通过额外追踪趋势的变化量,弥补这一偏差,使预测值能够跟上趋势。
季节性调整处理的是周期性波动。常用的做法是计算季节指数,然后将其乘以基础预测值,得到经过季节修正的预测结果。
季节指数的计算公式为:
以某空调品牌的季度销售数据为例,年均季度销量为100万台:
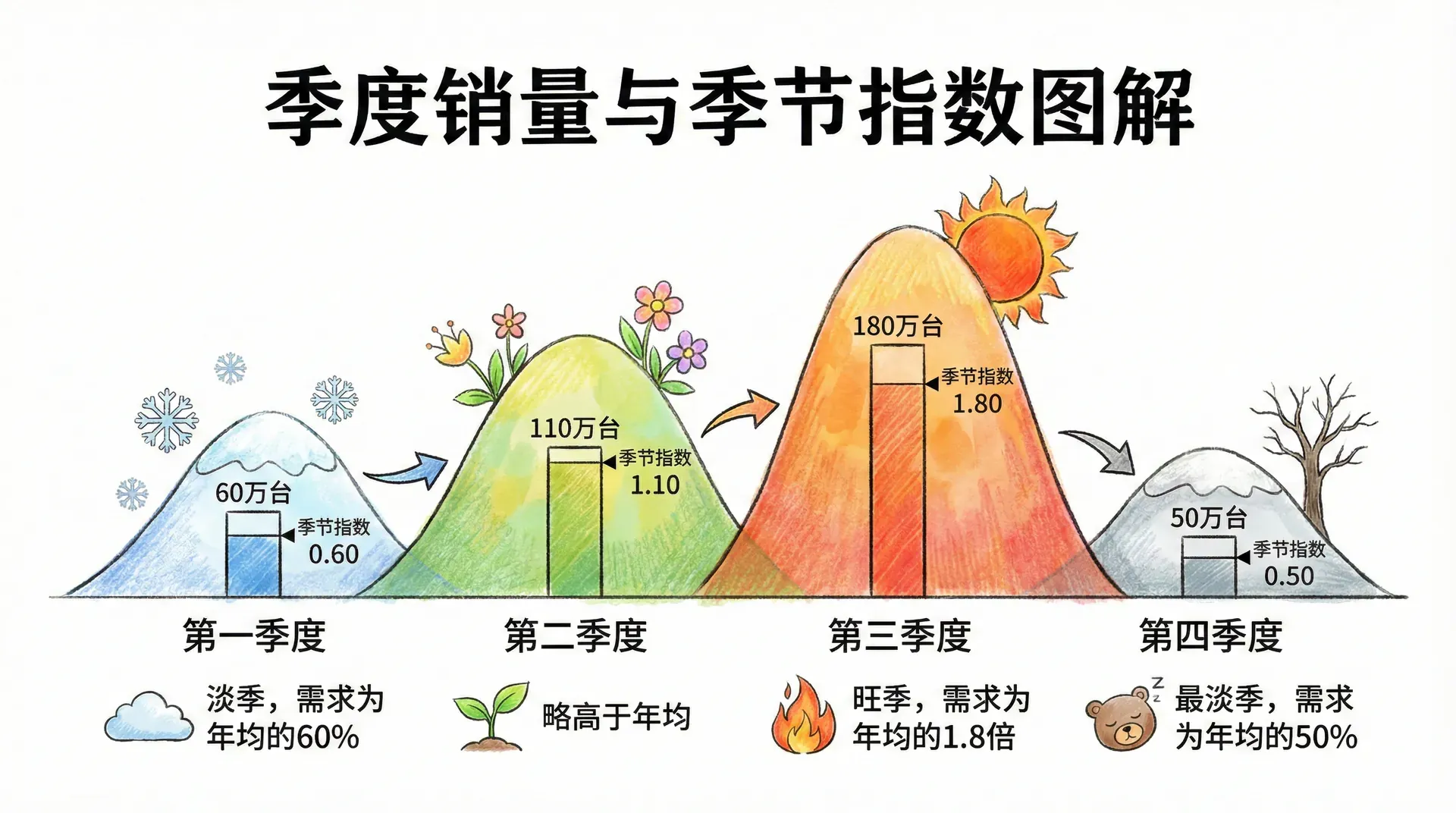
当企业预测下一年第三季度的销量时,只需将基础预测值乘以1.80,即可得到经过季节调整的结果。例如,若基础预测为年均110万台/季度,则第三季度的调整预测为: 万台。
季节性预测的前提是历史数据中存在稳定重复的规律。如果某一年受到重大外部事件影响,该年的数据需要谨慎处理,不能直接纳入季节指数的计算,否则会严重扭曲预测结果。
预测误差的衡量
预测不可能永远完全准确,误差是不可避免的。企业需要一套标准的指标来衡量预测误差的大小,从而判断当前方法是否合适,并找到改进方向。运营管理中最常用的两个误差指标是 MAD 和 MAPE。
平均绝对偏差(MAD,Mean Absolute Deviation)衡量预测误差的平均绝对大小,公式为:
平均绝对百分比误差(MAPE,Mean Absolute Percentage Error)将误差转化为百分比,便于跨产品、跨时期横向比较,公式为:
以某品牌四个月的预测数据为例:
MAPE为4.3%,说明该预测方法的整体精度较好。行业内通常以10%作为基本合格线,5%以下视为高精度预测。
MAD和MAPE的用途略有不同:MAD以实际销量的单位(件、箱、万元)表示,直观但不便于跨品类比较;MAPE使用百分比,无论产品销量大小都可以对比,更适合评估不同预测方法的相对优劣。
MAD适合用于日常监控单一产品的预测精度变化趋势,MAPE则适合横向比较不同产品线或不同预测模型的整体表现。实际工作中,两者结合使用效果更好。
案例:电商平台双十一的需求预测实践
双十一是全球规模最大的电商促销节点,每年11月11日前后,各平台订单量会在极短时间内出现爆发式增长。对于参与其中的品牌商和电商平台,需求预测的准确性直接决定了备货是否充足、物流能否承压、用户体验是否顺畅。
以某大型电商平台的备货决策为例,其预测团队通常提前60至90天启动双十一需求预测工作,整体分为四个环节:
历史数据回溯:对过去三至五年的双十一销售数据,按品类、品牌、地区进行拆解,识别各类目的增长趋势和季节指数,建立基准预测值。这一环节主要依赖移动平均和季节性调整方法。
活动因素修正:结合当年的活动力度(优惠幅度、营销预算投入)、竞争平台动向以及宏观消费趋势,对基础预测值进行调整。这一环节需要销售、运营、市场等多个部门的联合判断,带有明显的定性成分,类似于德尔菲法的多部门意见汇总。
分级备货策略:平台将商品分为三个等级——核心爆款要求预测误差控制在5%以内,次要商品允许10%以内的误差,长尾商品则采取按需补货策略,不做大量备货,以此降低整体库存风险。
实时监控与动态调整:大促开始后,系统实时监控实际销量与预测值的偏差,一旦超出预设阈值,立即触发补货或跨仓库调拨指令,把缺货和积压同时并存的风险降到最低。
这个案例清晰地说明:在实际业务中,没有哪一种预测方法可以单独应对所有复杂情况。定性与定量方法的结合、短期监控与中期规划的配合,才是企业预测工作的真实面貌。
总结
需求预测贯穿于日常运营和战略决策的各个环节,是保障企业资源配置效率、控制风险、提升客户满意度的重要基础。通过结合经验判断与数据分析,企业可以更有效地应对市场波动,把握发展机遇。
实现科学的预测需要多种方法的灵活组合,以及对业务实际情况的持续关注和调整。只有不断回顾与改进,企业才能将预测的主动权牢牢掌握在自己手中,为高质量发展提供有力支撑。