需求预测
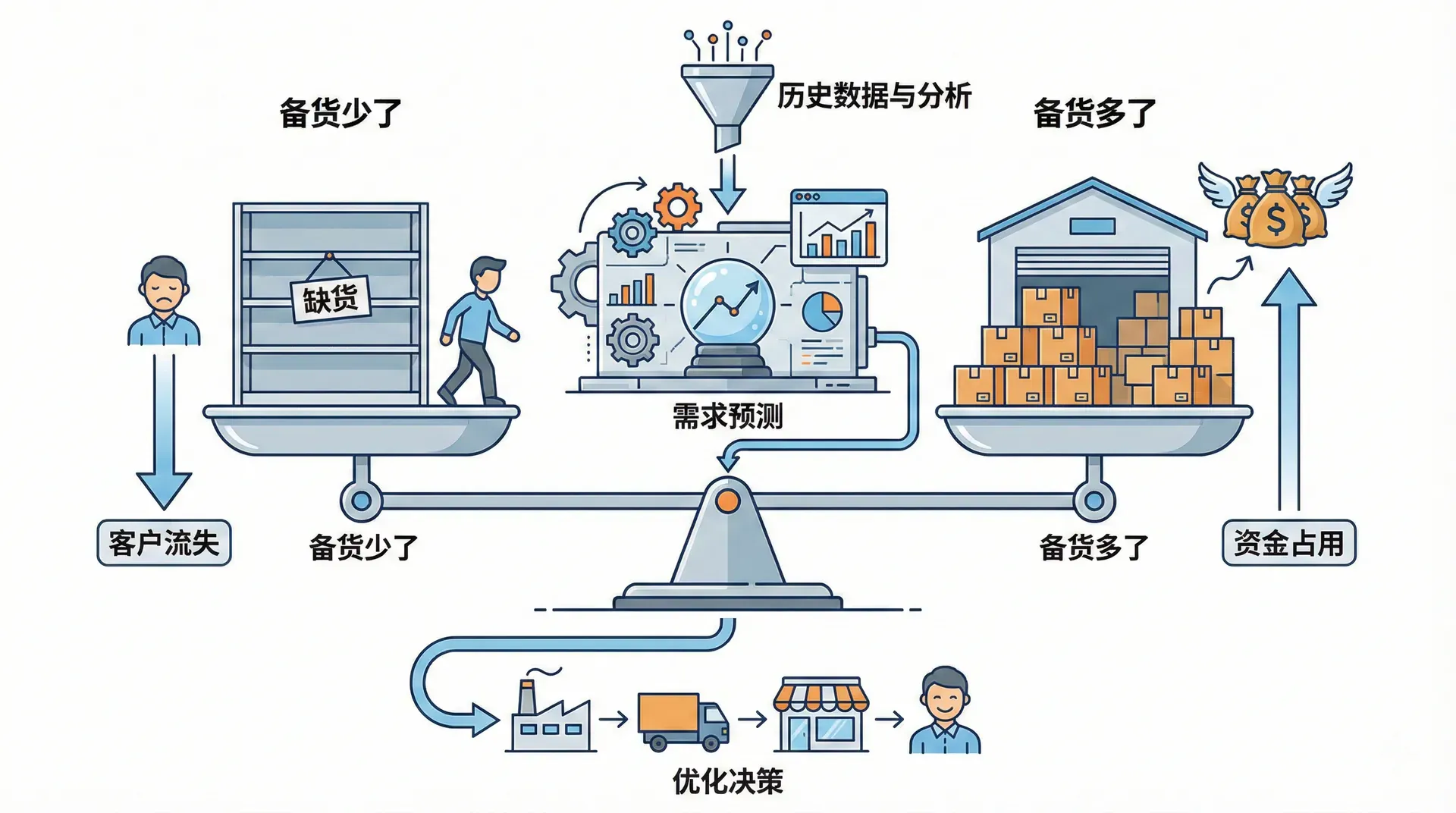
某快消品公司的采购经理曾说过一句话:"我们最大的问题不是成本,而是不知道下个月要卖多少货。"备货少了,货架空了,客户流失;备货多了,仓库积压,资金占用。这个两难困境,是供应链管理中最常见、也最难解决的挑战之一。预测,就是在不确定的未来中,用历史数据和分析方法,给决策提供一个尽可能可靠的数字依据。
需求预测贯穿供应链管理的每一个环节:生产计划、采购备货、库存设置、人员排班,全部依赖于对未来需求的判断。预测不可能做到百分之百准确,但好的预测方法可以把误差控制在可接受的范围内,这正是本章要解决的问题。
预测的基本概念与时间序列构成
预测的原材料是历史数据。当一家企业记录了过去几年每个月的销售量时,这些按时间顺序排列的数据,就构成了一条时间序列(Time Series)。时间序列中隐藏着规律,而预测的核心工作,就是从这些规律中推断未来的走向。
一条时间序列通常由四种成分叠加而成:
以某连锁超市的月度饮料销售数据为例,可以直观感受这四种成分:总体上看,销售额每年缓慢增长(趋势成分);每年6月至8月明显冲高(季节成分);2020年因特殊外部环境出现了大幅波动(随机成分)。在实际预测中,趋势和季节是最有规律可循的成分,也是定量方法重点处理的对象;随机成分则是任何方法都无法完全消除的预测残差。
时间序列的四种成分中,趋势和季节是可以通过历史数据识别和建模的;循环成分周期长、难以精确估计;随机成分是不可预测的噪声。好的预测模型能够捕捉趋势和季节规律,同时对随机波动保持足够的鲁棒性。
短期预测、中期预测与长期预测的区别
预测的时间跨度不同,适用的方法也不同。一般而言,预测窗口越长,不确定性越大,误差也越难控制。
定性预测方法
并非所有的预测问题都能用历史数据解决。当一款全新产品尚无销售记录、一个新兴市场尚无可参考数据时,就需要依靠专家判断与市场调研来形成定性预测。
德尔菲法(Delphi Method)
德尔菲法是一种通过多轮专家匿名问卷来达成预测共识的方法。它的基本流程是:组织者向多名专家独立发放问卷,收集各自对未来需求的预测意见;汇总后将统计结果(不透露具体姓名)反馈给所有专家,进行第二轮问卷;如此循环2至4轮,直到专家意见趋于收敛,取最终中位数或平均值作为预测结果。
这个方法的核心价值在于"匿名"二字。若专家面对面讨论,往往会出现资历高者主导意见、其他人随声附和的现象。匿名反馈让每位专家都能坚持独立判断,减少群体压力带来的偏差。
某新能源汽车企业在推出一款新型电池产品前,组织了8位行业专家进行德尔菲预测,三轮问卷的结果如下:
市场调研
市场调研是通过消费者访谈、问卷调查或试销测试来估计市场需求。对于消费品行业,调研可以直接获得潜在购买意愿;对于工业品,则通常调研采购商的计划采购量。市场调研的优点是贴近真实市场反应,缺点是成本高、周期长,且消费者的"说法"与"做法"之间往往存在差距。
定性方法的预测结果不能直接与定量方法的结果相加平均,两类方法应当作为互相验证的工具:定量方法给出基准数字,定性方法检验这个数字是否符合市场实情,必要时做出修正。
简单移动平均与加权移动平均
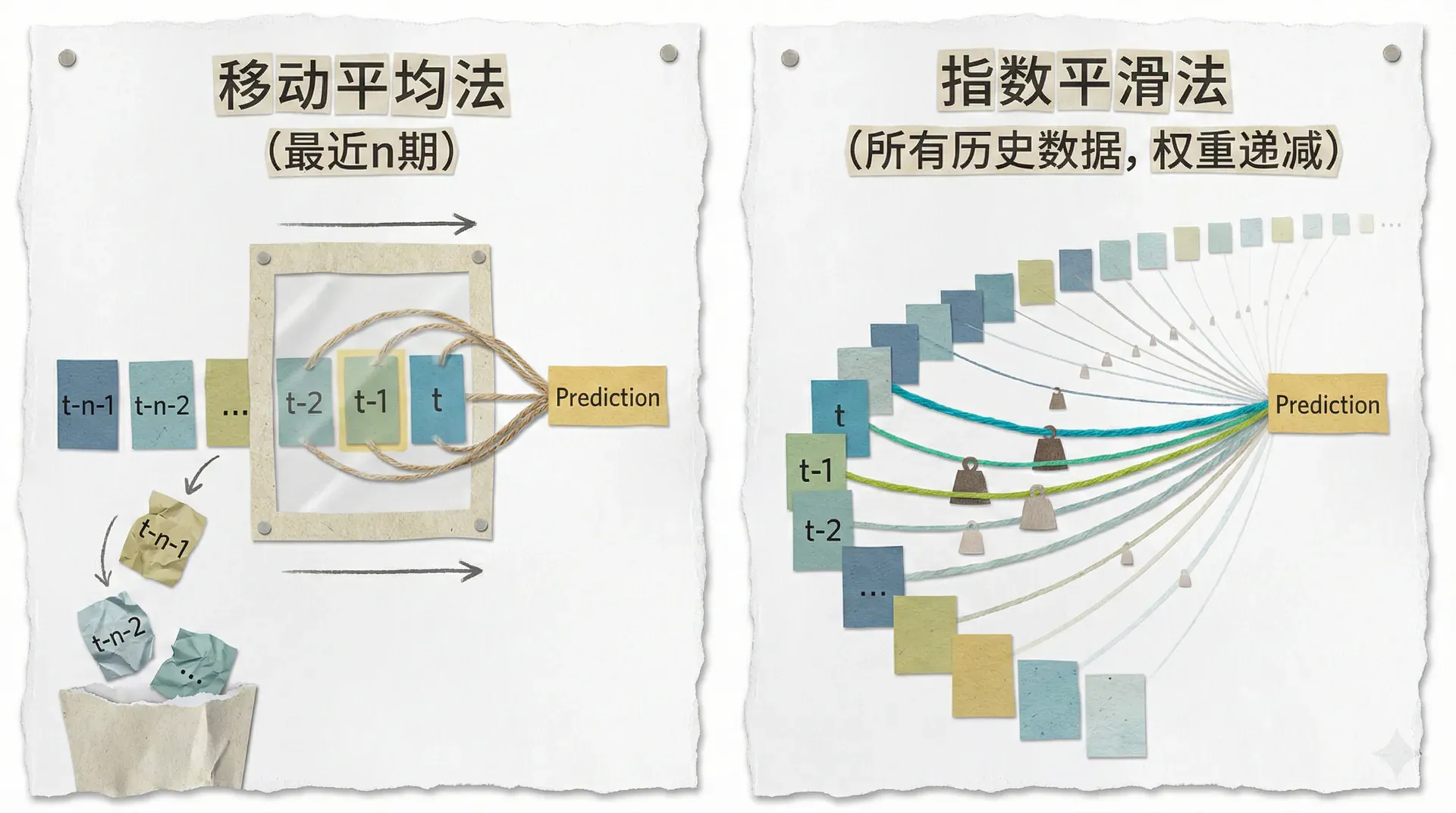
移动平均法是最基础也最直观的短期预测工具。其核心思路是:用最近若干期的实际数据的平均值,作为下一期的预测值。
简单移动平均(Simple Moving Average,SMA)
设移动平均的期数为 (n),则第 (t+1) 期的预测值为:
以某超市某款洗发水过去8个月的销售量(单位:件)为例,用3期移动平均预测第9个月的销量:
期数 (n) 的选择是移动平均法的核心参数。(n) 越小,预测值对近期变化越敏感,追踪趋势快,但受随机波动影响也大;(n) 越大,预测值越平滑,但对趋势变化的反应滞后。销售波动剧烈的品类适合较小的 (n),销售稳定的品类适合较大的 (n)。
加权移动平均(Weighted Moving Average,WMA)
简单移动平均对所有历史期赋予相同权重,而加权移动平均允许对近期数据赋予更高的权重,使预测值更贴近最新趋势。
仍用上表数据,以权重 (w_1=0.5, w_2=0.3, w_3=0.2)(最近月权重最高)做3期加权移动平均:
与简单移动平均的262件非常接近,但在趋势变化更明显的数据中,加权移动平均会表现出更强的追踪能力。
指数平滑法
移动平均法有一个明显的局限:每次预测只用最近 (n) 期数据,而 (n) 期之前的历史数据被完全丢弃。指数平滑法解决了这一问题——它将所有历史数据都纳入考虑,但对越久远的数据赋予越小的权重,权重按指数规律衰减。
简单指数平滑(Simple Exponential Smoothing)
预测公式如下,其中 (\alpha) 为平滑系数((0 < \alpha < 1)):
这个公式表明:下一期的预测值,等于本期实际值与本期预测值的加权组合。(\alpha) 越大,本期实际值的权重越高,预测值越"跟手";(\alpha) 越小,历史平均的影响越大,预测值越平稳。
以某电商平台某类商品月销售额(万元)为例,令初始预测 (\hat Y_1 = Y_1 = 80),分别用 (\alpha=0.3) 和 (\alpha=0.7) 进行预测:
可以看出,(\alpha=0.7) 的预测值更快地跟上了上涨趋势,而 (\alpha=0.3) 的预测值更保守。实际使用中,通常通过比较不同 (\alpha) 对应的预测误差来选择最优平滑系数。
趋势调整指数平滑(Trend-Adjusted Exponential Smoothing)
简单指数平滑在数据存在明显趋势时会系统性地滞后——当销量持续上升时,预测值总是低于实际值。趋势调整指数平滑在原公式基础上加入趋势估计项 (T_t),弥补这一不足:
其中 (\beta) 为趋势平滑系数((0 < \beta < 1)),(m) 为预测期数。这个方法在销量持续增长的品类(如近年来的新能源汽车、智能家居产品)中表现明显优于简单指数平滑。
指数平滑法的核心优势在于:它用一个参数 α 优雅地解决了"历史数据应该保留多少"的问题。α 越大,记忆越短;α 越小,记忆越长。这个机制比移动平均法更灵活,也更节省数据存储空间——只需保留上一期的预测值,就能完成下一期的预测。
线性趋势模型
当数据呈现出明显的线性增长或下降趋势时,用一条直线来拟合时间序列,是最直接的方式。线性趋势模型将时间 (t) 作为自变量,销量 (Y) 作为因变量,建立以下方程:
以某家电品牌近6年的年度销售额(亿元)数据为例:
(\bar t = 3.5),(\bar Y = 113/6 \approx 18.83)
趋势方程为 (\hat Y_t = 9.13 + 2.77t)。预测第7年((t=7))的销售额为:
这意味着按照历史趋势,该品牌第7年的销售额预计约为28.5亿元,每年平均增长约2.77亿元。
回归分析在预测中的应用
线性趋势模型只用时间 (t) 来预测销量,而现实中影响销量的因素往往不止时间一个。回归分析将多个可能影响需求的变量纳入模型,找到它们之间的数量关系,从而做出更准确的预测。
回归分析中有一个容易被忽视的原则:相关不等于因果。两个变量之间存在高度相关,不代表其中一个是另一个的原因。在建立预测模型时,纳入的变量应当有合理的业务逻辑支撑,而不仅仅是因为统计上相关系数高。
预测误差与精度评估
无论使用哪种方法,预测都不可能百分之百准确。评估一种预测方法的好坏,需要用历史数据来衡量它的预测误差。常用的三个指标是MAE、MSE和MAPE。
平均绝对误差(MAE,Mean Absolute Error)
MAE是所有期预测误差绝对值的平均,反映预测偏离实际的平均幅度,单位与原数据相同(如"件"或"万元"),直观易懂。
均方误差(MSE,Mean Squared Error)
MSE对误差平方求均值,放大了大误差的惩罚力度。若两种方法MAE相近但MSE差异显著,说明其中一种偶尔出现极端偏差,而另一种误差更均匀。
平均绝对百分误差(MAPE,Mean Absolute Percentage Error)
MAPE将误差转化为百分比,可以跨越不同量级的数据进行比较。一个MAPE=8%的预测模型,表示平均偏差约为实际值的8%,无论实际销量是100件还是10万件,这个指标都有同等含义。
以某方便面品牌7月份的预测为例,对比三种方法的精度:
三项指标均显示方法B的预测精度最高,这是选用方法B做后续预测的定量依据。
在实际工作中,MAPE是最常用的精度指标,因为它的百分比形式便于非专业人员理解和沟通。一般认为,MAPE低于10%属于预测精度良好,低于5%属于优秀;若MAPE超过20%,则预测结果的参考价值有限,需要重新审视模型或数据质量。
预测在供应链中的应用
需求预测的最终价值不在于数字本身,而在于它如何驱动供应链的实际决策。
库存计划中的应用
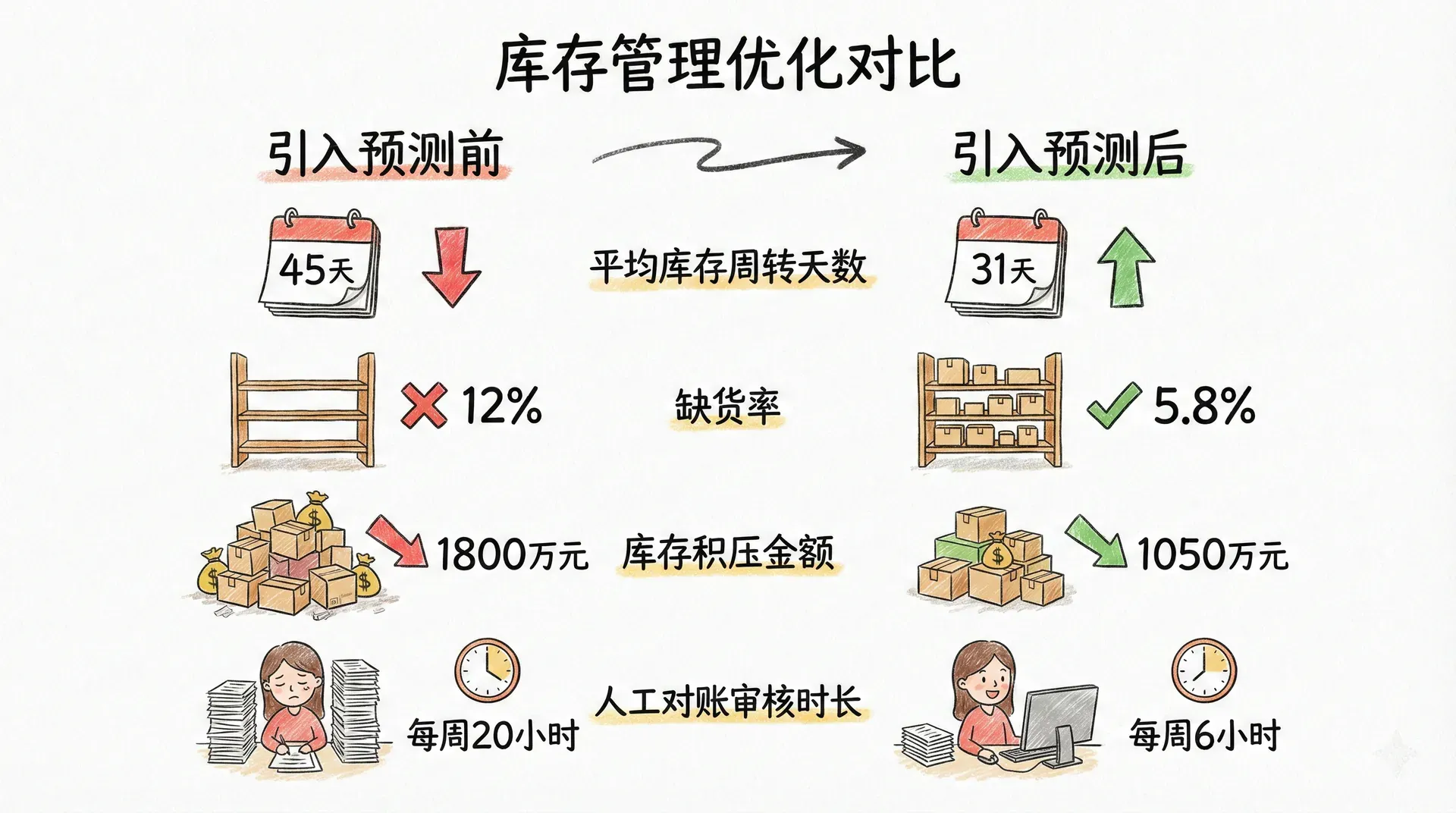
备货量的基础是对未来销量的预测。一家3C零售商每季度前需要决定各SKU的备货量,过高则积压资金、面临折价风险,过低则错失销售机会。通过对每个SKU建立指数平滑预测模型,可以为数千个品类自动生成下季度的建议备货量,大幅减少人工逐一判断的工作量。
某电商平台将指数平滑预测引入库存系统后,针对200个核心SKU的效果如下:
生产计划中的应用
制造企业的生产排程依赖于对未来需求的预判。需求预测结果直接决定了:下个月需要生产多少件成品、原材料需要提前多少天采购、设备产能是否需要临时扩充。
某服装企业在传统经验排产模式下,旺季常出现30%以上的产能浪费或缺货并存的情况。引入趋势调整指数平滑模型后,对主力款式的销量预测MAPE从18%降至7%,生产计划的执行准确率从71%提升至89%,旺季库存周转效率提高了近40%。
协同预测(CPFR)的理念
现代供应链管理中,有一个重要实践叫做协同计划、预测与补货(Collaborative Planning, Forecasting and Replenishment,CPFR)。其核心思路是:品牌商与零售商共享销售数据、促销计划和库存信息,双方联合做出统一的需求预测,而不是各自独立预测。
沃尔玛与宝洁之间是CPFR实践的经典案例:宝洁可以直接查看沃尔玛各门店的实时库存与销售数据,据此安排生产和配送;沃尔玛则提前告知宝洁即将执行的促销活动计划。双方协同的结果是,补货周期从数周压缩至数天,缺货率和库存积压率均大幅改善。这种模式打破了供应链各环节"各自为政"的信息壁垒,将预测的准确性提升到了单一企业无法独立实现的水平。
需求预测的价值不仅取决于模型的精度,还取决于预测结果是否被正确地传导到采购、生产、物流等各个执行环节。一个MAPE=6%的优秀预测,若无法被计划团队及时获取并使用,其价值与没有预测无异。
小结
需求预测是供应链管理的"第一张牌",所有后续的库存、采购、生产决策,都建立在预测的基础上。以下内容从时间序列的基本结构出发,系统介绍了从定性到定量的预测方法体系,并通过误差指标建立了客观评价预测精度的标准。
精度评估三项指标各有侧重:MAE衡量平均绝对偏差,MSE放大极端误差惩罚,MAPE提供跨量级的可比性。实际工作中,三者结合使用,才能全面评判一种预测方法的适用性。需求预测的结果将直接成为库存控制模型的输入参数,两个模块之间形成紧密的逻辑承接关系。