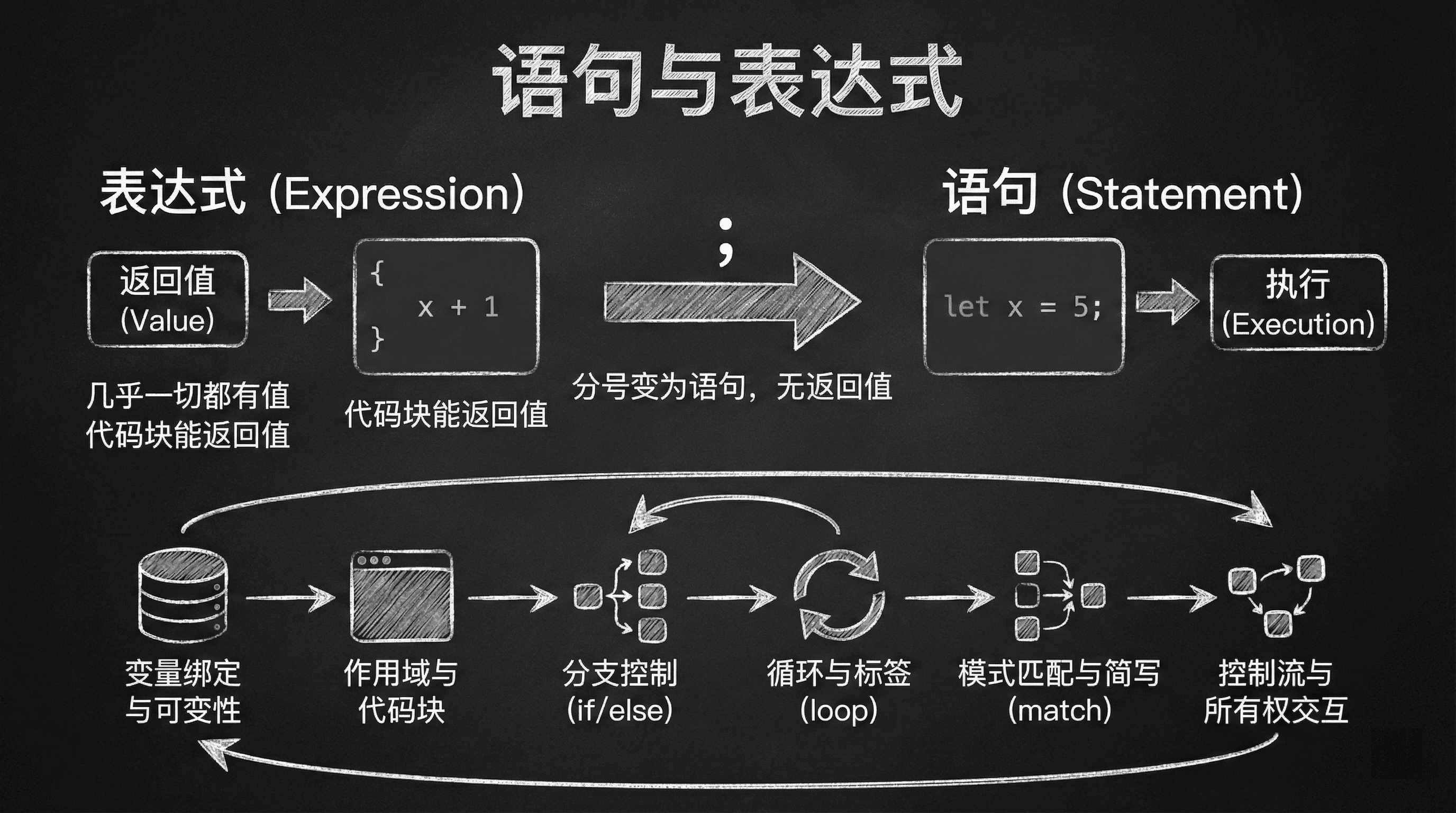
语句与表达式
在 Rust 中,语句与表达式构成了代码的基本骨架。Rust 更偏向表达式风格:几乎一切都有值,代码块也能返回值; 但与此同时,分号会把表达式变为语句,从而影响返回值与类型推断。掌握这些基础,我们才能在后续内容中自如地组合控制流、设计函数返回、组织模式匹配与错误传播。
这节课我们围绕变量绑定与可变性、作用域与代码块、分支控制、循环与标签、模式匹配与简写、分号与返回值、控制流中的所有权交互等主题展开,形成系统的表达式直觉。
变量绑定与可变性
Rust 采用“默认不可变”的绑定策略,这是一个深思熟虑的设计决定。当我们声明一个变量时,除非显式标记为可变,否则它就是不可变的。这种策略带来了多重好处: 首先,它让代码更容易推理。当我们看到一个变量绑定后,就能确信它的值不会在后续代码中被意外修改。这极大地减少了心智负担,特别是在阅读复杂函数或调试问题时。 其次,不可变性是并发安全的基础(我们会在并发部分详细介绍)。不可变数据天然就是线程安全的,因为没有竞态条件的风险。
通过 let 关键字我们可以创建变量绑定。Rust 会根据使用情况自动推断类型,但我们也可以显式标注:
rust
fn main() {
let x = 10; // 不可变绑定
let mut y = 3; // 可变绑定
println!("x = {x}, y = {y}");
y += 4;
println!("after: x = {x}, y = {y}");
}text
x = 10, y = 3
after: x = 10, y = 7遮蔽(Shadowing)机制
遮蔽(shadowing)是 Rust 中一个强大而优雅的特性,它允许我们使用同一个名字重新声明变量。这种机制既保持了"默认不可变"设计的安全性,又为我们提供了灵活的数据转换能力。 遮蔽的核心优势在于:它创建了全新的变量绑定,而不是修改原有变量的值。这意味着每次遮蔽都可以改变类型,同时保持变量名的一致性,让代码更加清晰易读。
与可变变量不同,遮蔽允许我们在类型转换的同时保持不可变性。比如,我们可能需要将字符串解析为数字,然后对数字进行计算。使用遮蔽,整个过程中的每个步骤都是不可变的,但我们可以逐步"演进"数据的形态。 另一个重要特点是作用域行为:新的遮蔽变量会在当前作用域内生效,当离开作用域时,之前的绑定会重新可见。
rust
fn main() {
let v = "42"; // &str
let v: i32 = v.parse().unwrap(); // 遮蔽为 i32
let v = v * 2; // 再次遮蔽为新的数值
println!("v = {v}");
}text
v = 84作用域与代码块(block)
代码块的双重身份
在 Rust 中,大括号 {} 包裹的代码块具有双重身份:它既是作用域的边界,也是一个表达式。这种设计让我们能够以更加优雅和函数式的方式组织代码。
作为作用域边界:代码块为变量绑定创建了独立的生命周期。在块内声明的变量只在该块内可见,一旦离开块的范围,这些变量就会被销毁。这种机制帮助我们:
- 控制变量的可见性,避免意外的变量访问
- 减少变量间的意外依赖关系
- 让代码的逻辑边界更加清晰
- 提供内存管理的自动化支持
作为表达式:代码块可以产生值,这个值由块中最后一个表达式决定。关键在于理解"表达式"与"语句"的区别:
- 表达式(Expression):产生值的代码,如
5 + 3、x * 2 - 语句(Statement):执行操作但不产生值的代码,如
let x = 5;
如果代码块的最后一行是一个不带分号的表达式,那么这个表达式的值就成为整个块的值。如果最后一行带有分号,或者是一个语句,那么块的值就是单元类型 ()。
代码块作为表达式的特性在实际编程中非常有用,特别是在需要进行复杂计算或条件逻辑时:
rust
fn main() {
let outer = 10;
let result = {
let inner = outer * 2;
inner + 5 // 注意:无分号,块的返回值
};
println!("result = {result}");
}text
result = 25如果在末尾加上分号,块就不再返回该表达式的值,而是返回 ()(单元类型)。这个细节会直接影响函数返回与类型推断。
if:分支也是表达式
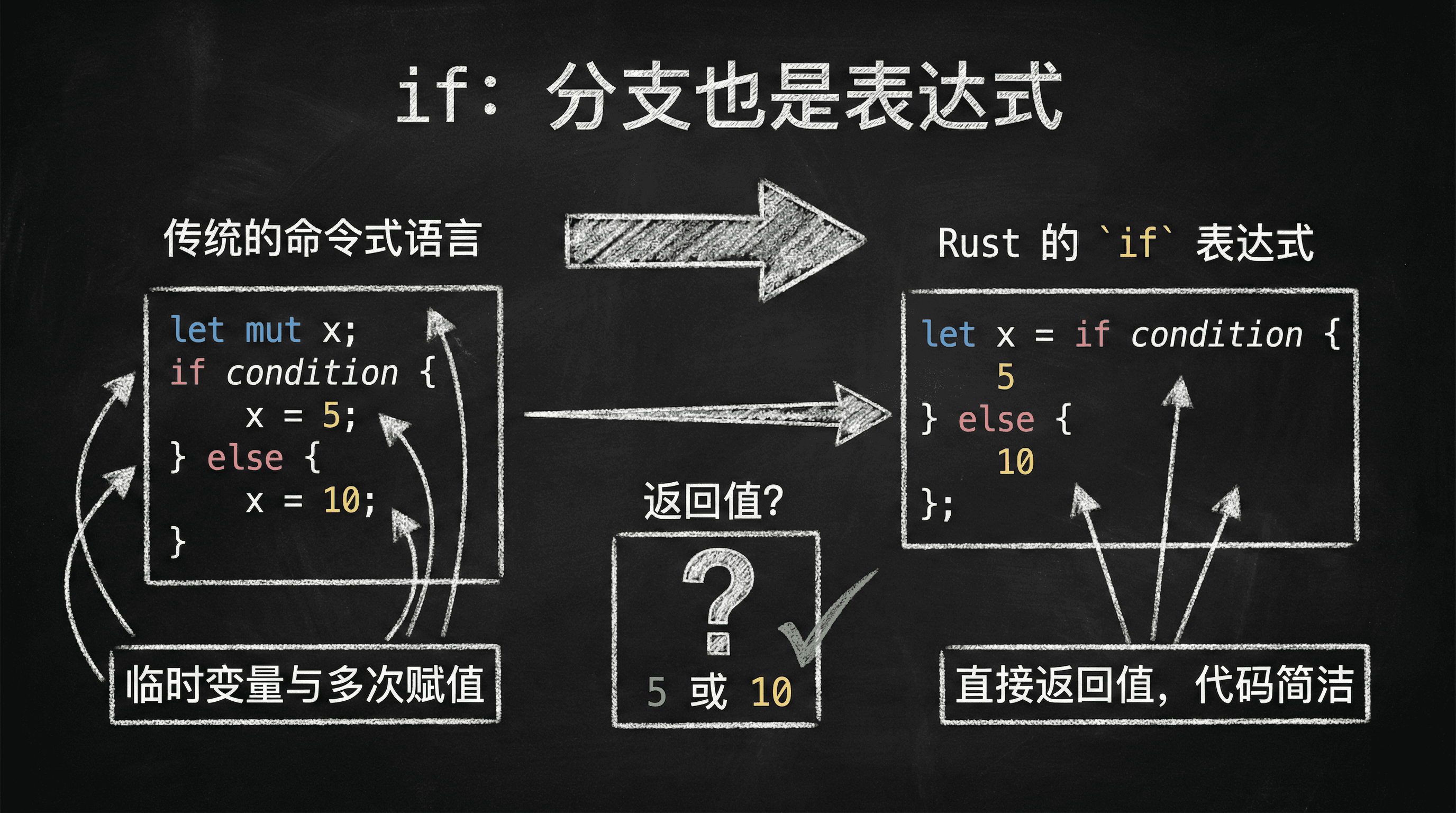
Rust 的 if 语句本质上是一个表达式,这意味着它不仅能控制程序流程,还能产生并返回值。这种设计哲学源于函数式编程的理念,让我们能够以更加简洁和直观的方式编写代码。
传统的命令式语言通常需要我们先声明一个变量,然后在不同的条件分支中为这个变量赋值。而在 Rust 中,我们可以直接让 if 表达式的结果赋值给变量,避免了引入不必要的临时变量和多次赋值操作。
条件必须明确为布尔类型:Rust 要求 if 的条件部分必须是 bool 类型,不接受任何形式的隐式类型转换。这与一些语言中"非零即真"的约定不同。例如,你不能写 if 5 { ... },必须写成 if x != 0 { ... } 这样的明确比较。这种严格性虽然增加了一些代码量,但大大减少了因类型混淆而产生的逻辑错误。
表达式特性的实际应用:当 if 作为表达式使用时,每个分支都必须返回相同类型的值(或者能够被编译器统一的类型)。这确保了无论程序执行哪个分支,最终的结果类型都是确定和一致的。如果某个分支没有显式返回值,编译器会将其视为返回单元类型 ()。
rust
fn main() {
let score = 86;
let grade = if score >= 90 {
'A'
} else if score >= 80 {
'B'
} else {
'C'
};
println!("grade = {grade}");
}text
grade = B分支的返回类型必须一致或能统一,否则编译器无法推断。表达式风格要求每个分支的值类型对齐,以保证求值确定性。
match
Rust 的 match 表达式是一个功能强大且严谨的控制流工具,它通过模式匹配机制能够精确识别和区分值的不同形态、范围以及结构特征。
与其他语言中相对宽松的 switch 语句不同,Rust 的 match 强制实行“穷尽匹配”原则,这意味着我们必须为所有可能出现的值情况提供对应的处理分支。
当我们为某个类型的所有可能取值都提供了匹配分支时,编译器就能在编译阶段确保程序的完整性和安全性,保证运行时不会遇到未处理的情况。 相反,如果遗漏了某些可能的值或模式,编译器会立即报错,强制我们重新审视代码逻辑,考虑那些可能被忽略的边界情况和异常状态。
rust
fn describe(n: i32) -> &'static str {
match n {
0 => "zero",
1 | 2 => "one or two",
3..=9 => "three to nine",
_ => "others",
}
}
fn main() {
for
text
0: zero
2: one or two
5: three to nine
42: others在 match 分支体中,同样遵循表达式规则:最后一个无分号表达式作为分支值,所有分支的值类型必须一致。
循环:loop、while 与 for
Rust 提供了三种基本的循环构造,每种都有其特定的使用场景和设计理念。
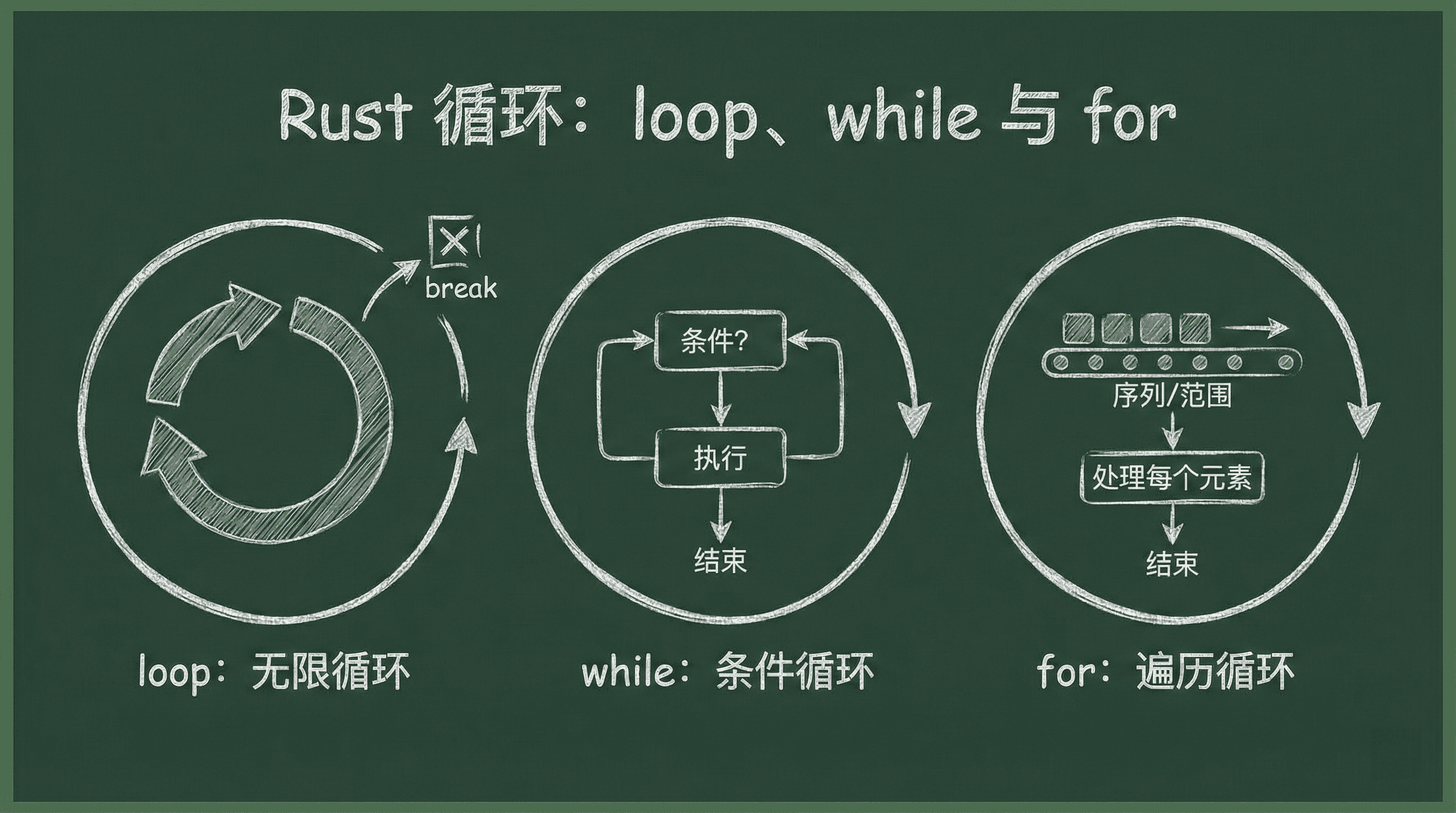
loop 关键字创建一个无条件的无限循环,它会持续执行直到程序主动使用 break 语句终止。这种循环的独特之处在于它可以通过 break 语句返回一个值,让循环本身成为一个表达式。
这种设计使得我们可以在循环内部计算出某个结果,然后将这个结果作为整个循环表达式的值传递给外部变量。
while 循环则是条件驱动的循环结构,它会在每次迭代开始前检查给定的布尔表达式。只
要条件为真,循环就会继续执行;一旦条件变为假,循环立即终止。这种循环适合那些需要在某个状态满足时持续执行的场景。
for 循环是 Rust 中最常用也是最安全的迭代方式,它专门用于遍历实现了迭代器 trait 的数据结构。
相比于传统的索引访问方式,for 循环天然避免了数组越界等常见错误,同时提供了更清晰和表达力更强的代码。
它不仅可以遍历数组和切片,还能处理各种集合类型以及任何实现了 IntoIterator trait 的自定义类型。
rust
fn main() {
// loop + break 返回值
let mut cnt = 0;
let value = loop {
cnt += 1;
if cnt == 3 { break cnt * 10; }
};
println!("value from loop = {value}");
// while 条件循环
let mut n =
text
value from loop = 30
5 4 3 2 1 go!
Rust循环标签与多层跳转
当我们遇到多层循环嵌套时,单纯使用 break 或 continue 只能作用于最近的一层循环。如果想要直接跳出外层循环或者控制特定层级的循环流程,Rust 提供了“循环标签”机制。
我们可以在循环前加上一个以单引号 ' 开头的标签(比如 'outer:),然后在循环体内通过 break 'outer 跳出对应的循环,或者用 continue 'outer 直接进入外层循环的下一轮。
这种方式让我们在复杂的嵌套结构中也能清晰、精准地控制流程,避免了冗长的标志变量和混乱的逻辑判断。
举个例子:假设我们有两层循环,内层循环遇到某个条件时希望直接跳出外层循环,这时就可以用标签来实现。如果不用标签,break 只能终止内层循环,外层还会继续执行;而有了标签,我们可以一行代码直接跳出所有需要的循环层级。
rust
fn main() {
'outer: for i in 1..=3 {
for j in 1..=3 {
if i * j == 4 {
println!("i={i}, j={j}, break outer");
break 'outer;
}
}
}
println!(
text
i=2, j=2, break outer
done模式匹配的简写:if let 与 let-else
有时候我们只想处理某种特定的匹配情况,比如只在解析成功时才继续后续逻辑,这时用 if let 能让代码变得更简洁,省去了完整 match 的冗余结构。if let 让我们可以直接针对关心的分支写处理逻辑,忽略其他情况。
到了 Rust 1.65,let-else 语法进一步提升了表达力:我们可以在变量绑定时直接写出匹配条件,如果不满足就立刻返回或提前退出,这样一来,遇到不符合预期的情况时,代码会自动帮我们“早退”,让主流程更聚焦于成功路径,错误分支也更清晰。
rust
fn parse_even(input: &str) -> Result<i32, String> {
if let Ok(n) = input.parse::<i32>() {
if n % 2 == 0 { Ok(n) } else { Err("not even".into()) }
text
Ok(10)
Err("not even")
Ok(12)
Err("empty slice")分号的语义
在 Rust 里,分号的作用是把一个表达式变成一条语句,这样它的值就不会被后续代码使用了。
我们在写函数时,通常会让函数体的最后一行是一个没有分号的表达式,这样这个表达式的值就会作为整个函数的返回值。
如果最后一行加了分号,返回的就不是我们期望的值,而是空元组 (),这往往会导致类型不匹配的编译错误。
这种设计和 Rust 把代码块当作表达式的理念是一致的,也就是说,代码块的最后一个没有分号的表达式决定了整个块的值。
rust
fn add(a: i32, b: i32) -> i32 {
a + b // 无分号:作为返回值
}
fn add_wrong(a: i32, b: i32) -> i32 {
a + b; // 有分号:返回 (),与签名不匹配,编译报错
0
}
fn main() {
println!(
text
5提前返回与控制流:return、break、continue
在 Rust 的表达式风格代码中,我们依然可以通过 return 语句实现函数的提前返回,这样一旦遇到特定条件,函数就会立刻结束并返回指定的值。
在循环体内部,如果我们想要直接跳出整个循环,可以使用 break,而且在 Rust 里,break 还允许我们带上一个值作为循环表达式的结果。
至于 continue,它的作用是立即结束本轮循环,直接进入下一次迭代。合理地运用这些控制流语句,能够让我们的意图表达得更加清晰,代码结构也会更加直观易懂。
rust
fn find_first_even(nums: &[i32]) -> Option<i32> {
for &n in nums {
if n % 2 == 0 { return Some(n); }
}
None
}
fn main() {
println!("{:?}", find_first_even(&
text
None
Some(4)表达式中的所有权与借用
在 Rust 的表达式语境下,变量的所有权会随着分支或代码块的不同路径发生转移或者被借用。编译器会严格追踪每个值的所有权流向,确保我们不会在值被移动之后还继续使用它。 如果我们在 if 或 match 的某个分支里把一个变量的所有权转移出去了,那么在后续代码中,这个变量就不能再被访问了。 假如我们希望在分支之后还能继续用到原来的值,就需要提前考虑,是不是应该只借用它,或者在需要的时候进行克隆。这样既能保证代码的安全性,也能让所有权的流转更加清晰可控。
rust
fn choose_str(cond: bool) -> String {
let a = String::from("A");
let b = String::from("B");
let chosen = if cond { a } else { b }; // 移动其中一个所有权
chosen
}
fn main() {
println!
在上例中,a 或 b 会被移动到 chosen,不可再用。若我们只想读取它们而不移动,可借用:
rust
fn choose_ref<'a>(cond: bool, a: &'a str, b: &'a str) -> &'a str {
if cond { a } else { b } // 借用,避免移动
}
fn main() {
let s1 = String::from("hello"
text
hello world -> hello在 Rust 里,if 或 match 这样的分支表达式,要求所有分支最终都要产生同一种类型的值。比如 if 的 true 分支和 false 分支,或者 match 的每个分支,类型都要一致。 否则,编译器就无法推断出整个表达式的类型。如果我们遇到分支类型不一致的情况,可以通过类型转换(比如 as 关键字),或者把不同类型包裹进同一个枚举、特征对象等方式, 让它们在类型上统一起来。只有这样,编译器才能顺利通过类型检查,整个表达式才能作为一个值被使用。
rust
fn main() {
let flag = true;
let value = if flag { 10 } else { 20 }; // 两边同为 i32,OK
println!("{value}");
}当两个分支类型不同,可以显式统一:
rust
fn main() {
let flag = true;
let value: Box<dyn std::fmt::Display> = if flag {
Box::new(10)
} else {
Box::new("ten")
};
println!("{}"
match 的绑定与守卫
在 Rust 的模式匹配中,我们不仅可以通过模式直接提取出值,还能在匹配的同时把某些部分绑定到变量上,方便后续使用。 如果我们希望对某个分支增加额外的判断条件,还可以在模式后面加上 if 语句,这就是所谓的“守卫”。 这样,只有当模式匹配且守卫条件成立时,这个分支才会被选中。通过绑定和守卫的结合,我们可以灵活地对数据进行分类和处理,让 match 表达式既简洁又强大。
rust
fn classify(n: i32) -> &'static str {
match n {
x if x < 0 => "neg",
0 => "zero",
x if x % 2 == 0 => "pos-even",
_ => "pos-odd",
}
}
text
-2: neg
-1: neg
0: zero
3: pos-odd
4: pos-even当我们用模式匹配结构体或枚举时,可以直接在模式中拆解出各个字段的值。这样不仅能方便地访问内部数据,还能灵活选择是获取所有权、可变借用还是只读借用。 例如,我们可以只借用某个字段,避免整个对象被移动,从而继续在后续代码中使用原始变量。这种解构方式让我们在处理复杂数据类型时既高效又安全。
rust
#[derive(Debug)]
struct User { id: u32, name: String, active: bool }
fn name_if_active(u: &User) -> Option<&str> {
let User { name, active, .. } = u; // 借用字段
if *active { Some(name.
let-模式与解构绑定
在 Rust 里,let 语句不仅仅是简单地给变量赋值,更是一种模式匹配和绑定的工具。我们可以利用 let 直接把元组、结构体或者枚举的内部数据拆解出来,并分别绑定到新的变量上,这样后续就能方便地单独使用每一部分的数据。
rust
fn main() {
let pair = (3, "hi");
let (a, b) = pair;
println!("a={a}, b={b}");
}表达式中的错误传播:?
在 Rust 里,? 运算符让我们能够在遇到错误时自动把错误返回给调用者,而不是手动去判断和处理每一步的错误。
这样写出来的代码既简洁又符合 Rust 一贯的表达式风格。只要某个操作返回 Result,我们在后面加上 ?,如果成功就继续往下执行,如果出错就会立刻把错误返回出去,整个过程非常自然地融入到函数的控制流中。
rust
use std::fs;
use std::io;
fn load_conf(path: &str) -> Result<String, io::Error> {
let content = fs::read_to_string(path)?; // 失败则提前返回 Err
Ok(content)
}
fn main() {
match
习题
- 在Rust中,声明变量使用哪个关键字?
- 在Rust中,if表达式的特点是什么?
- 在Rust中,用于模式匹配的关键字是?
- 在Rust中,match表达式的要求是什么?
- 在Rust中,如何从loop循环返回值?
- 在Rust中,用于模式匹配失败时早退的模式是?
- 在Rust中,什么符号决定表达式是否返回值?
- 在Rust中,用于单一模式匹配的语法是?
9. if表达式赋值练习
使用if表达式直接赋值,而不是先定义可变变量再在分支里赋值。
rust
fn main() {
let score = 85;
// 方式1:使用if表达式直接赋值(推荐)
let grade = if score >= 90 {
"A"
} else if score >= 80 {
"B"
} else if score >= 70 {
"C"
} else {
"D"
10. match表达式和守卫条件练习
使用match表达式匹配三态枚举,要求穷尽匹配,并加入守卫条件。
rust
#[derive(Debug)]
enum Status {
Success,
Warning(i32), // 带数据的变体
Error(String),
}
fn status_to_string(status: Status) -> String {
match status {
Status::Success => "成功".to_string(),
Status::
11. loop + break返回值练习
使用loop循环和break返回值,统计直到遇到第一个负数之前的非负数个数。
rust
fn count_until_negative(numbers: &[i32]) -> usize {
let mut count = 0;
let result = loop {
if count >= numbers.len() {
break count; // 没有负数,返回总数
}
if numbers[count] < 0 {
12. let-else模式练习
使用let-else在函数开头对输入进行快速校验,未满足条件则早退。
rust
fn process_number(input: Option<i32>) -> Result<String, String> {
// 使用let-else进行快速校验
let Some(value) = input else {
return Err("输入为空".to_string());
};
// 继续处理,value已经解构出来
if value < 0 {
return